
Integrating Normal Vector Features into an Atrous Convolution Residual Network for LiDAR Point Cloud Classification

 , ,
, ,
Abstract
:1. Introduction
- 1.
- An atrous convolution is integrated into the residual structure. The atrous convolution can amplify the receptive field of the convolution layer without increasing the network parameters and can avoid the problem of feature loss caused by traditional methods, such as the pooling layer.
- 2.
- The normal vector of the point cloud is embedded into the feature extraction module of the point cloud classification network, which improves the utilization of the spatial information of the point cloud and enables the network to fully capture the rich context information of the point cloud.
- 3.
- A reweighted loss function is proposed to solve the problem of uneven distribution of point clouds, and it is an improved loss function based on the cross-entropy loss function.
- 4.
- To verify the effectiveness of the proposed algorithm, we conducted experiments on the 3D semantic dataset of urban Vaihingen in Germany. The experimental results show that the proposed algorithm can effectively capture the geometric structure of 3D point clouds, realize the classification of LiDAR point clouds, and improve classification accuracy.
2. Related Work
2.1. Classification Based on Handcrafted Features
2.2. Classification Based on Deep Learning
2.2.1. Two-dimensional Multiview Method
2.2.2. Three-Dimensional Voxelization Method
2.2.3. Neighborhood Feature Learning
2.2.4. Graph Convolution
2.2.5. Optimizing CNN
3. Materials and Methods
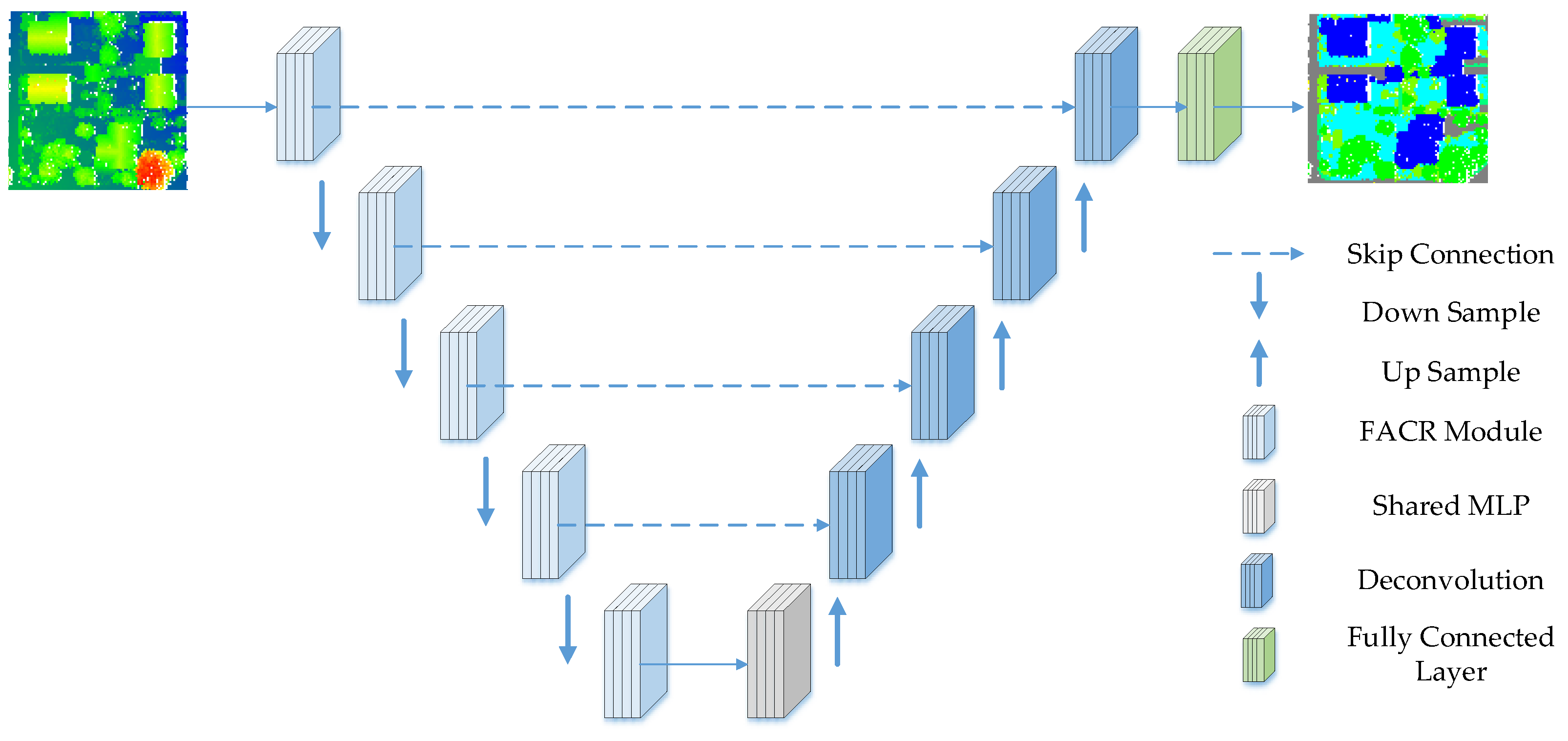
3.1. FACR (Fusion Atrous Convolution Residual) Module
3.2. Normal Vector Calculation of the Point Cloud
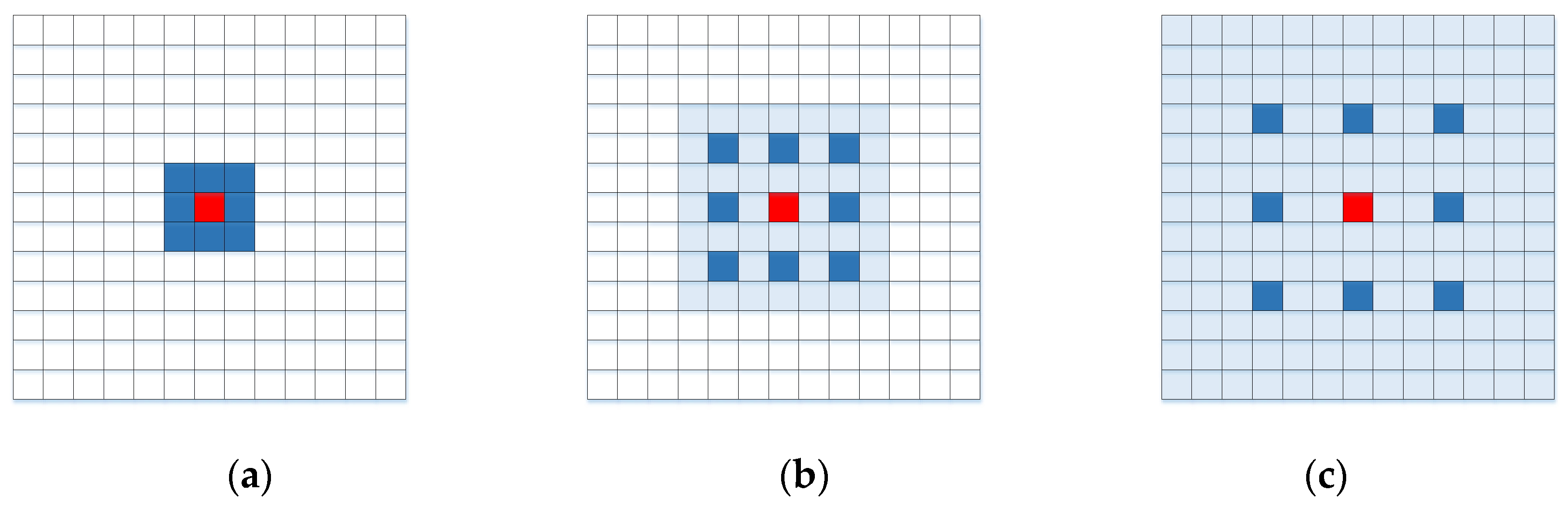
3.3. Atrous Convolution
3.4. Reweighted Loss Function
4. Experimental Results and Analysis
4.1. Experimental Data
4.2. Experimental Setup
4.3. Classification Performance Evaluation
4.4. Experiments and the Analysis
4.4.1. Comparison and Analysis with the ISPRS Competition Method
4.4.2. Comparison with Other Deep Learning Classification Methods
4.5. Ablation Study
4.5.1. Effectiveness of the Normal Vector of the Point Cloud
4.5.2. Effectiveness of Atrous Convolution
4.5.3. Effectiveness of the Reweighted Loss Function
4.5.4. Comparison of Computational Load
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Xu, Y.; Ye, Z.; Yao, W.; Huang, R.; Tong, X.; Hoegner, L.; Stilla, U. Classification of LiDAR point clouds using supervoxel-based detrended feature and perception-weighted graphical model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 13, 72–88. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Y.; Wang, J. Map-based localization method for autonomous vehicles using 3D-LIDAR. IF AC-Pap. 2017, 50, 276–281. [Google Scholar]
- Hebel, M.; Arens, M.; Stilla, U. Change detection in urban areas by object-based analysis and on-the-fly comparison of multi-view ALS data. ISPRS J. Photogramm. Remote Sens. 2013, 86, 52–64. [Google Scholar] [CrossRef]
- Bassier, M.; Vergauwen, M. Topology reconstruction of BIM wall objects from point cloud data. Remote Sens. 2020, 12, 1800. [Google Scholar] [CrossRef]
- Polewski, P.; Yao, W.; Heurich, M.; Krzystek, P.; Stilla, U. Detection of fallen trees in ALS point clouds using a normalized cut approach trained by simulation. ISPRS J. Photogramm. Remote Sens. 2015, 105, 252–271. [Google Scholar] [CrossRef]
- Pan, Y.; Dong, Y.; Wang, D.; Chen, A.; Ye, Z. Three-dimensional reconstruction of structural surface model of heritage bridges using UA V-based photogrammetric point clouds. Remote Sens. 2019, 11, 1204. [Google Scholar] [CrossRef] [Green Version]
- Ene, L.T.; Erik, N.; Gobakken, T.; Bollandsås, O.; Mauya, E.; Zahabu, E. Large-scale estimation of change in aboveground biomass in miombo woodlands using airborne laser scanning and national forest inventory data. Remote Sens. Environ. 2017, 188, 106–117. [Google Scholar] [CrossRef]
- Jiang, H.; Yan, F.; Cai, J.; Zheng, J.; Xiao, J. End-to-end 3D point cloud instance segmentation without detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 16–18 June 2020; pp. 12796–12805. [Google Scholar]
- Yang, B.S.; Liang, F.X.; Huang, R.G. Research progress, challenges and trends of 3D laser scanning point cloud data processing. J. Surv. Mapp. 2017, 46, 1509–1516. [Google Scholar]
- Lalonde, J.F.; Unnikrishnan, R.; Vandapel, N.; Hebert, M. Scale selection for classification of point-sampled 3D surfaces. In Proceedings of the Fifth International Conference on 3-D Digital Imaging and Modeling, Ottawa, ON, Canada, 16–18 June 2005; pp. 285–292. [Google Scholar]
- Gao, Z.H.; Liu, X.W. Support vector machine and object-oriented classification for urban impervious surface extraction from satellite imagery. In Proceedings of the IEEE 2014 Third International Conference on Agro-Geoinformatics, Beijing, China, 11–14 August 2014; IEEE: New York, NY, USA, 2014; pp. 1–5. [Google Scholar]
- Miao, X.; Heaton, J.S. A comparison of random forest and Adaboost tree in ecosystem classification in east Mojave Desert. In Proceedings of the IEEE 2010 18th International Conference on Geoinformatics, Beijing, China, 18–20 June 2010; IEEE: New York, NY, USA, 2010; pp. 1–6. [Google Scholar]
- Wang, C.S.; Shu, Q.Q.; Wang, X.Y.; Guo, B.; Liu, P.; Li, Q. A random forest classifier based on pixel comparison features for urban LiDAR data. ISPRS J. Photogramm. Remote Sens. 2019, 48, 75–86. [Google Scholar] [CrossRef]
- Schmidt, A.; Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of full waveform lidar data in the Wadden Sea. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1614–1618. [Google Scholar] [CrossRef]
- Shapovalov, R.; Velizhev, A.; Barinova, O. Non-associative Markov networks for 3D point cloud classification. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2010, XXXVIII, 103–108. [Google Scholar]
- Zhu, Q.; Li, Y.; Hu, H.; Wu, B. Robust point cloud classification based on multi-level semantic relationships for urban scenes. ISPRS J. Photogramm. Remote Sens. 2017, 129, 86–102. [Google Scholar] [CrossRef]
- Hatt, M.; Parmar, C.; Qi, J.; Naqa, I. Machine (deep) learning methods for image processing and radiomics. IEEE Trans. Radiat. Plasma Med Sci. 2019, 3, 104–108. [Google Scholar] [CrossRef]
- Li, W.; Zhu, J.; Fu, L.; Zhu, Q.; Xie, Y.; Hu, Y. An augmented representation method of debris flow scenes to improve public perception. Int. J. Geogr. Inf. Sci. 2021, 35, 1521–1544. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans. Smart Grid 2017, 10, 841–851. [Google Scholar] [CrossRef]
- Sokkhey, P.; Okazaki, T. Development and optimization of deep belief networks applied for academic performance prediction with larger datasets. IE Trans. Smart Process. Comput. 2020, 9, 298–311. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–25 July 2017; IEEE: New York, NY, USA, 2017; pp. 652–660. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Markham, A. RandLA-Net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Zuo, Z.; Zhang, Z.; Zhang, J. Urban LIDAR point cloud classification method based on regional echo ratio and topological recognition model. China Lasers 2012, 39, 195–200. [Google Scholar]
- Brodu, N.; Lague, D. 3D terrestrial lidar data classification of complex natural scenes using a multi-scale dimensionality criterion: Applications in geomorphology. ISPRS J. Photogramm. Remote Sens. 2012, 68, 121–134. [Google Scholar] [CrossRef] [Green Version]
- Becker, C.; Häni, N.; Rosinskaya, E.; d’Angelo, E.; Strecha, C. Classification of aerial photogrammetric 3D point clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 84, 287–295. [Google Scholar] [CrossRef] [Green Version]
- Guo, B.; Huang, X.; Zhang, F.; Wang, Y. Jointboost point cloud classification and feature dimension reduction considering spatial context. Acta Surv. Mapp. 2013, 42, 715–721. [Google Scholar]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogramm. Remote. Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U.; Heipke, C. Hierarchical higher order crf for the classification of airbone lidar point clouds in urban areas. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2016, 41, 655–662. [Google Scholar] [CrossRef] [Green Version]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 945–953. [Google Scholar]
- Alonso, I.; Riazuelo, L.; Montesano, L.; Murillo, A. 3D-MiniNet: Learning a 2D representation from point clouds for fast and efficient 3D LIDAR semantic segmentation. IEEE Robot. Autom. Lett. 2020, 5, 5432–5439. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. Voxnet: A 3D convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; IEEE: New York, NY, USA, 2015; pp. 922–928. [Google Scholar]
- Meng, H.Y.; Gao, L.; Lai, Y.K.; Manocha, D. VV-Net: Voxel VAE net with group convolutions for point cloud segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; IEEE: New York, NY, USA, 2019; pp. 8500–8508. [Google Scholar]
- Hegde, V.; Zadeh, R. FusionNet: 3D Object Classification Using Multiple Data Representations. arXiv 2016, arXiv:1607.05695. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Lu, C. PointSIFT: A SIFT-like network module for 3D point cloud semantic segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. PointWeb: Enhancing Local Neighborhood Features for Point Cloud Processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach Convention & Entertainment Center, Los Angeles, CA, USA, 15–21 June 2019; IEEE: New York, NY, USA, 2019; pp. 5565–5573. [Google Scholar]
- Wang, C.; Samari, B.; Siddiqi, K. Local spectral graph convolution for point set feature learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 52–66. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with super point graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4558–4567. [Google Scholar]
- Li, Y.Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution on χ-transformed points. Adv. Neural Inf. Process. Syst. 2018, 31, 820–830. [Google Scholar]
- Xu, Y.F.; Fan, T.Q.; Xu, M.Y.; Zeng, L.; Qiao, Y. SpiderCNN: Deep learning on point sets with parameterized convolutional filters. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 87–102. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; IEEE: New York, NY, USA, 2016; pp. 770–778. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), Caribe Hilton, San Juan, Puerto Rico, 2–4 May 2016; IEEE: New York, NY, USA; pp. 1–13. [Google Scholar]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; pp. 9260–9269. [Google Scholar]
- Wen, C.; Yang, L.; Li, X.; Peng, L.; Chi, T. Directionally constrained fully convolutional neural network for airborne LiDAR point cloud classification. ISPRS J. Photogramm. Remote Sens. 2020, 162, 50–62. [Google Scholar] [CrossRef] [Green Version]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–3 November 2019; IEEE: New York, NY, USA, 2020; pp. 6411–6420. [Google Scholar]
- Li, W.; Wang, F.D.; Xia, G.S. A geometry-attentional network for ALS point cloud classification. ISPRS J. Photogramm. Remote Sens. 2020, 164, 26–40. [Google Scholar] [CrossRef]
- Li, X.; Wang, L.; Wang, M.; Wen, C.; Fang, Y. DANCE-NET: Density-aware convolution networks with context encoding for airborne LiDAR point cloud classification. ISPRS J. Photogramm. Remote Sens. 2020, 166, 128–139. [Google Scholar] [CrossRef]
- Wen, C.; Li, X.; Yao, X.; Peng, L.; Chi, T. Airborne LiDAR point cloud classification with global-local graph attention convolution neural network. ISPRS J. Photogramm. Remote Sens. 2021, 173, 181–194. [Google Scholar] [CrossRef]
- Özdemir, E.; Remondino, F.; Golkar, A. An efficient and general framework for aerial point cloud classification in urban scenarios. Remote Sens. 2021, 13, 1985. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Train | Test |
|---|---|---|
| Powerline | 546 | 600 |
| Low vegetation | 180,850 | 98,690 |
| Impervious surfaces | 193,723 | 101,986 |
| Car | 4614 | 3708 |
| Fence/Hedge | 12,070 | 7422 |
| Roof | 152,045 | 109,048 |
| Facade | 27,250 | 11,224 |
| Shrub | 47,605 | 24,818 |
| Tree | 135,173 | 54,226 |
| F1 Score | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Power Line | Low Vegetation | Surfaces | Car | Fence | Roof | Facade | Shrub | Tree | OA | Average F1 |
| UM | 0.461 | 0.790 | 0.891 | 0.477 | 0.052 | 0.920 | 0.527 | 0.409 | 0.779 | 0.808 | 0.590 |
| WhuY2 | 0.319 | 0.800 | 0.889 | 0.408 | 0.245 | 0.931 | 0.494 | 0.411 | 0.773 | 0.810 | 0.586 |
| WhuY3 | 0.371 | 0.814 | 0.901 | 0.634 | 0.239 | 0.934 | 0.475 | 0.399 | 0.780 | 0.823 | 0.616 |
| LUH | 0.596 | 0.775 | 0.911 | 0.731 | 0.340 | 0.942 | 0.563 | 0.466 | 0.831 | 0.816 | 0.684 |
| BIJ_W | 0.138 | 0.785 | 0.905 | 0.564 | 0.363 | 0.922 | 0.532 | 0.433 | 0.784 | 0.815 | 0.603 |
| RIT_1 | 0.375 | 0.779 | 0.915 | 0.734 | 0.180 | 0.940 | 0.493 | 0.459 | 0.825 | 0.816 | 0.633 |
| NANJ2 | 0.620 | 0.888 | 0.912 | 0.667 | 0.407 | 0.936 | 0.426 | 0.559 | 0.826 | 0.852 | 0.693 |
| WhuY4 | 0.425 | 0.827 | 0.914 | 0.747 | 0.537 | 0.943 | 0.531 | 0.479 | 0.828 | 0.849 | 0.692 |
| Ours | 0.938 | 0.975 | 0. 990 | 0.982 | 0.946 | 0.992 | 0.917 | 0.930 | 0.977 | 0.979 | 0.961 |
| F1 Score | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Power line | Low vegetation | Surfaces | Car | Fence | Roof | Facade | Shrub | Tree | F1 | Average F1 |
| PointNet | 0.526 | 0.700 | 0.832 | 0.112 | 0.075 | 0.748 | 0.078 | 0.246 | 0.454 | 0.657 | 0.419 |
| PointNet++ | 0.579 | 0.796 | 0.906 | 0.661 | 0.315 | 0.916 | 0.543 | 0.416 | 0.770 | 0.812 | 0.656 |
| PointnetSIFT | 0.557 | 0.807 | 0.909 | 0.778 | 0.305 | 0.925 | 0.059 | 0.444 | 0.796 | 0.822 | 0.677 |
| PointnetCNN | 0.615 | 0.827 | 0.918 | 0.758 | 0.359 | 0.927 | 0.578 | 0.491 | 0.781 | 0.833 | 0.695 |
| D-FCN | 0.704 | 0.802 | 0.914 | 0.781 | 0.370 | 0.930 | 0.605 | 0.460 | 0.794 | 0.822 | 0.707 |
| KPConv | 0.631 | 0.823 | 0.914 | 0.725 | 0.252 | 0.944 | 0.603 | 0.449 | 0.812 | 0.837 | 0.684 |
| GADH-Net | 0.668 | 0.668 | 0.915 | 0.915 | 0.350 | 0.946 | 0.633 | 0.498 | 0.839 | 0.850 | 0.717 |
| Ours | 0.938 | 0.975 | 0. 990 | 0.982 | 0.946 | 0.992 | 0.917 | 0.930 | 0.977 | 0.979 | 0.961 |
| Method | OA | Average F1 |
|---|---|---|
| baseline | 0.954 | 0.910 |
| baseline + normal | 0.969 | 0.948 |
| baseline + normal + atrous Conv | 0.972 | 0.951 |
| baseline + normal + atrous Conv + reweighted loss function | 0.979 | 0.961 |
| Method | OA | Average F1 |
|---|---|---|
| K = 10 | 93.22 | 88.95 |
| K = 20 | 96.16 | 93.04 |
| K = 30 | 96.92 | 94.76 |
| K = 40 | 95.88 | 91.93 |
| K = 50 | 94.84 | 90.44 |
| Method | OA | Average F1 |
|---|---|---|
| Rate = 2 | 0.954 | 0.939 |
| Rate = 5 | 0.972 | 0.951 |
| Rate = 8 | 0.960 | 0.930 |
| Rate = 11 | 0.935 | 0.889 |
| Method | OA | Average F1 |
|---|---|---|
| Cross entropy | 0.972 | 0.949 |
| Weighted cross-entropy | 0.972 | 0.951 |
| Reweighted cross-entropy | 0.979 | 0.961 |
| Method | Training Time (Hours) | GPU Memory | OA | GPU |
|---|---|---|---|---|
| DANCE-Net | 10 | 24 GB | 0.839 | Nvidia Tesla K80 |
| GADH-Net | 7 | 2 × 12 GB | 0.850 | 2 × Nvidia Titan Xp |
| GACNN | 10 | 12 GB | 0.832 | Nvidia Titan Xp |
| 3DCNN | 0.5 | 11 GB | 0.806 | Nvidia RTX 2080Ti |
| Ours | 1.5 | 11 GB | 0.979 | Nvidia RTX 2080Ti |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Xu, S.; Jiang, T.; Liu, J.; Liu, Z.; Luo, A.; Ma, Y. Integrating Normal Vector Features into an Atrous Convolution Residual Network for LiDAR Point Cloud Classification. Remote Sens. 2021, 13, 3427. https://doi.org/10.3390/rs13173427
Zhang C, Xu S, Jiang T, Liu J, Liu Z, Luo A, Ma Y. Integrating Normal Vector Features into an Atrous Convolution Residual Network for LiDAR Point Cloud Classification. Remote Sensing. 2021; 13(17):3427. https://doi.org/10.3390/rs13173427
Chicago/Turabian StyleZhang, Chunjiao, Shenghua Xu, Tao Jiang, Jiping Liu, Zhengjun Liu, An Luo, and Yu Ma. 2021. "Integrating Normal Vector Features into an Atrous Convolution Residual Network for LiDAR Point Cloud Classification" Remote Sensing 13, no. 17: 3427. https://doi.org/10.3390/rs13173427
APA StyleZhang, C., Xu, S., Jiang, T., Liu, J., Liu, Z., Luo, A., & Ma, Y. (2021). Integrating Normal Vector Features into an Atrous Convolution Residual Network for LiDAR Point Cloud Classification. Remote Sensing, 13(17), 3427. https://doi.org/10.3390/rs13173427