2.1. Structure Design of Learnable Activation Function
Convolution operation and pooling operation in convolution neural networks are linear operations, which only can solve linear problems. However, most of the practical problems are nonlinear. If just stacking the convolution layer and the pooling layer directly, the neural network will only be suitable for the linear problem. This is why CNN needs to add an activation function layer whose role is to inject nonlinear factors into the neural network so that the network can fit all kinds of curves and be able to handle practical problems. The common activation functions are as follows: logistic function (also known as Sigmoid function) [
52], hyperbolic tangent function (Tanh) [
53], and rectified linear units (ReLU) [
54]. The expressions of the three functions are as follows:
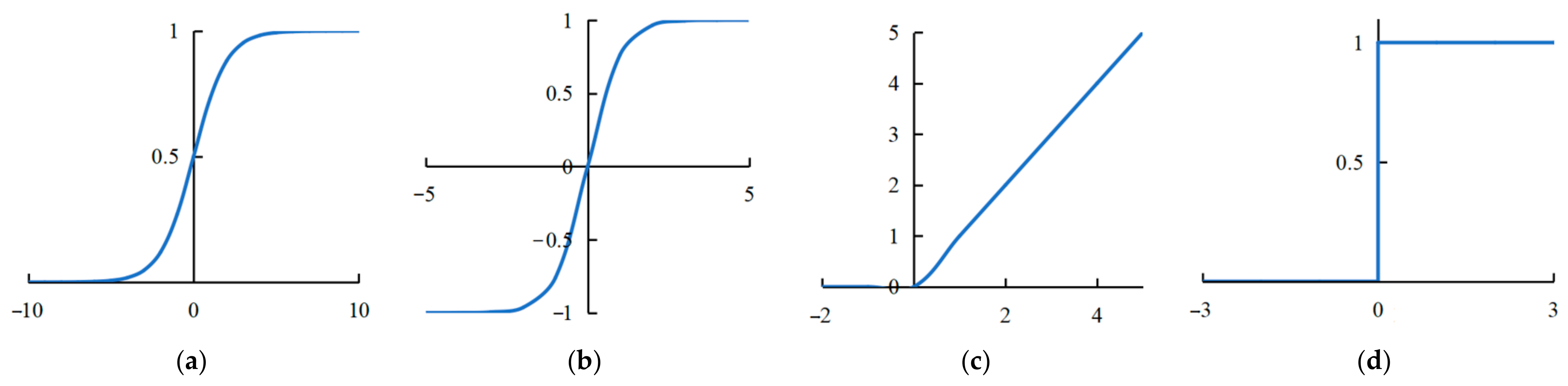
It can be seen from
Figure 1 that the Sigmoid function can compress the input signal into the interval [0, 1] [
52]. Since the data are compressed to the interval [0, 1], this function is mainly used to transform the input into a form of probability that also ranges from 0 to 1. However, when the input is large or small enough, the output approaches 1 or 0 after compression, which results in gradient dispersion. The Tanh function can be obtained by scaling and translating the Sigmoid function [
53]. The mean value of the Tanh is 0, and its convergence speed is faster than that of the Sigmoid function, but it still cannot solve the problem of gradient vanishing. Therefore, the ReLU function is the most commonly used activation function, which has strong sparsity and greatly reduces the number of parameters. In addition, the ReLU function solves the problem of gradient vanishing in the positive interval, and its convergence speed is much faster than the Sigmoid and the Tanh functions. However, the ReLU function is difficult to update for some parameters in the negative interval. To solve the above mentioned problems, there are also some improved versions of ReLU functions, such as the parametric rectified linear unit (PReLU), ELU, etc. These improved functions exist to make up for the defects of the ReLU function.
Although there are different kinds of convolutional neural network structures, their structures are basically similar, mainly composed of convolution and activation functions. From a mathematical point of view, the relationship between layer
k and layer
k + 1 is as follows:
where
x is the
k-layer input,
Wk is the convolution operation,
bk is the bias term,
f (
·) is the nonlinear activation function, and
xk+1 is the layer input.
Taking the ReLU activation function as an example, the nonlinear operation of the function satisfies
f (0) = 0, and the input of layer
k + 1 in Equation (4) can be converted into:
The symbol
in the formula is the Hadamard product, that is, the product of the corresponding elements of two matrices.
gk represents the weight mapping related to
zk, which is defined as follows:
where
gk is 0 when
zk is 0.
The ReLU curve in
Figure 1c is derived, and the following formulas can be obtained:
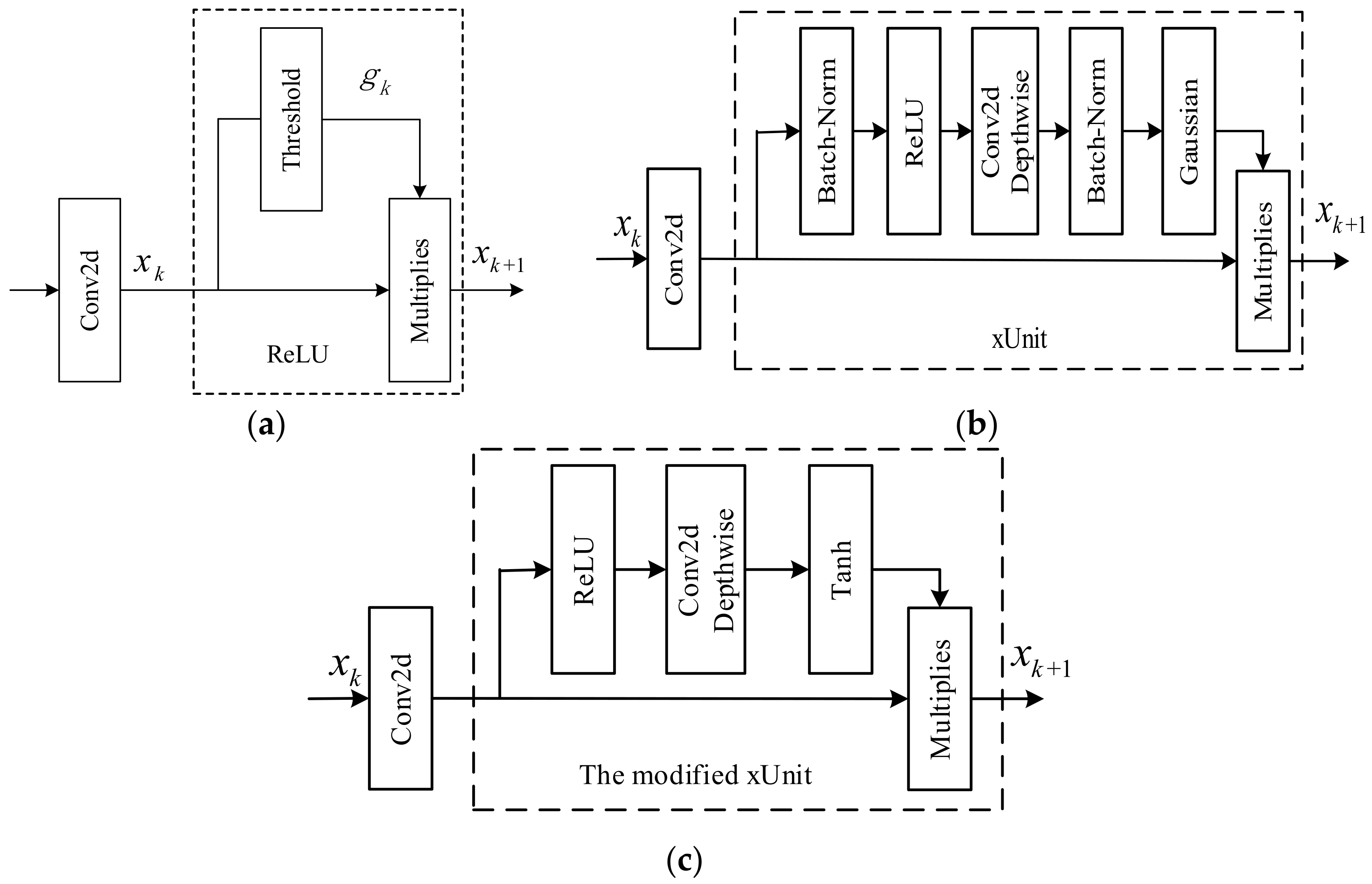
Although the CNNs of various complex structures are proposed to improve the denoising performance in SAR image speckle suppression tasks, these network structures cannot avoid a large number of network parameters. Here, a modified xUnit activation is proposed and incorporated into ID-CNN structure to further improve the denoising performance. According to the characteristics of the ReLU shown in
Figure 1c, a ReLU derivative curve shown in
Figure 1d can be obtained. At this point, the ReLU activation function can be considered as a threshold unit (0 or 1) shown in
Figure 2a, where
gk denotes the threshold unit (0 or 1), and
xk and
xk+1 respectively represent the ReLU functions of input and output. By contrast, a learnable spatial activation function is proposed to construct a weight map in the range [0, 1] so that each element is related to the spatial neighborhood of its corresponding input element [
51].
It can deduce that
gk is a threshold unit related to
zk. The formula is as follows:
Equation (8) represents the redefined ReLU activation function, and its structure is shown in
Figure 2a. Multiplies represents the product of corresponding elements, namely the Hadamard product.
As can be seen from
Figure 2a, the input
xk is convoluted to get
zk. The ReLU function can be regarded as setting the threshold unit
gk value according to each element value of
zk and multiplying it to get the output
xk+1.
According to
Figure 2a, the
gk value of the M-xUnit function in this section is not only related to the corresponding element of
zk but is also related to the spatial adjacent elements. The basic idea is to construct a weight mapping in which the weight of each element depends on the corresponding spatial adjacent input elements. This relationship can be realized by convolution operation. As shown in
Figure 2c, the constructed weight mapping realizes nonlinear operation through a ReLU activation function, then successively going through the deep convolution and the Tanh function, and, finally, the weight range is mapped between [−1, 1]. Among these operations, the employment of deep convolution ensures that the weight of each element is related to its corresponding spatial adjacent elements. The introduction of Tanh solves the problem that the output of ReLU is not zero-centered and makes up for the defect that the element value is zero by ReLU when it is less than or equal to zero, which avoids the phenomenon that some units will never be activated.
In
Figure 2c,
gk of M-xUnit activation unit is defined as:
where
Hk represents deep convolution, while
dk represents the output of deep convolution.
To enable xUnit shown in
Figure 2b to perform better in the ID-CNN architecture and the task of SAR despeckling, the Gaussian function was replaced with a hyperbolic tangent function (Tanh), and two batch normalization (BN) [
55] layers were removed. Tanh function can map the dynamic range to [−1, 1] so that the mean value of the output distribution is zero and resembles the identity function when input remains around zero. As shown, the BN layers cannot improve the denoising performance of the SAR image, and the possible reason is that the output of the hidden layer is normalized by BN, which destroys the distribution of the original space [
39,
56]. The modified xUnit is shown in
Figure 2c, where Conv2d represents the operation of convolution, and Conv2d Depthwise denotes deep convolution [
57] whose kernel size is set as 9 × 9.
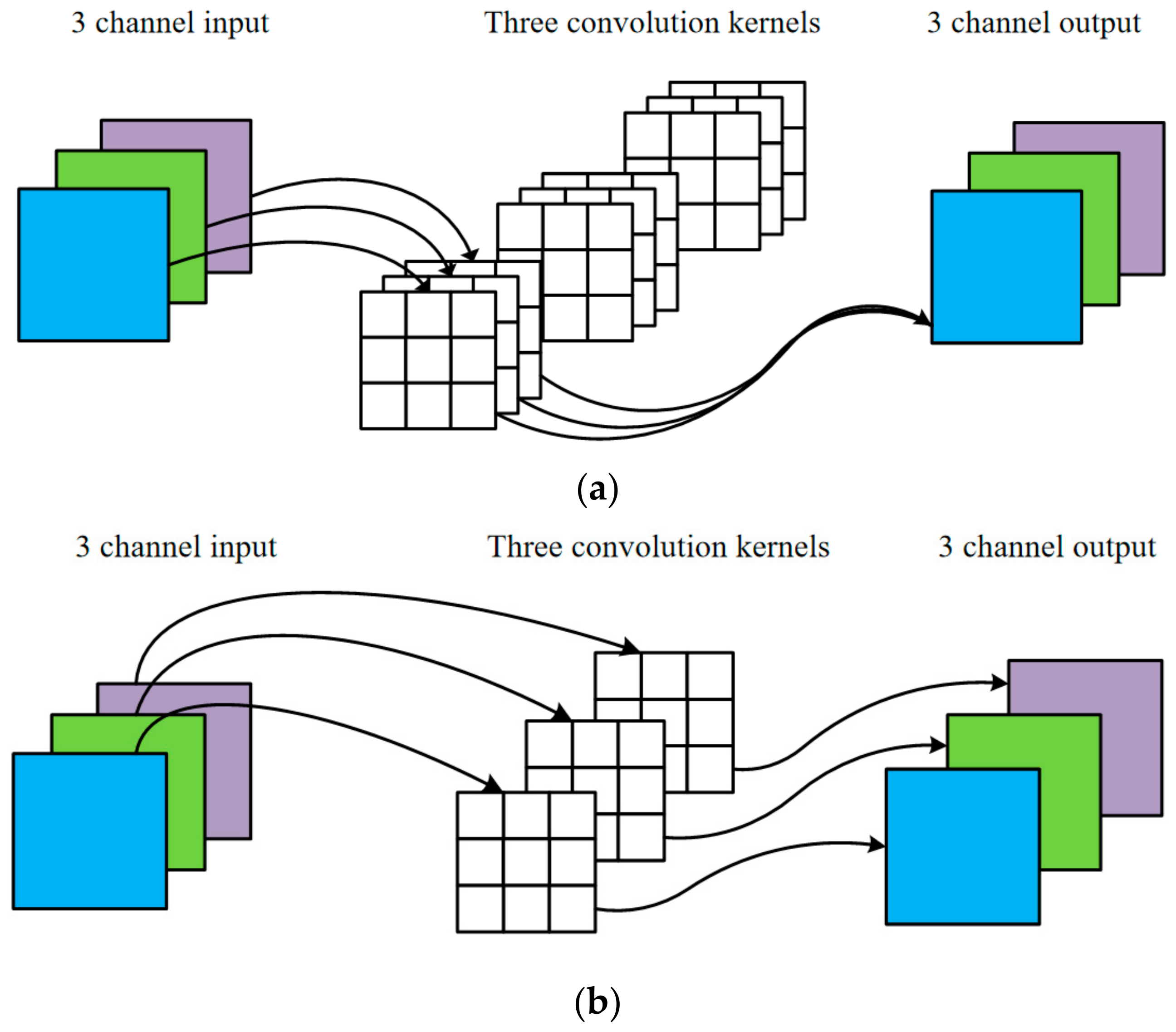
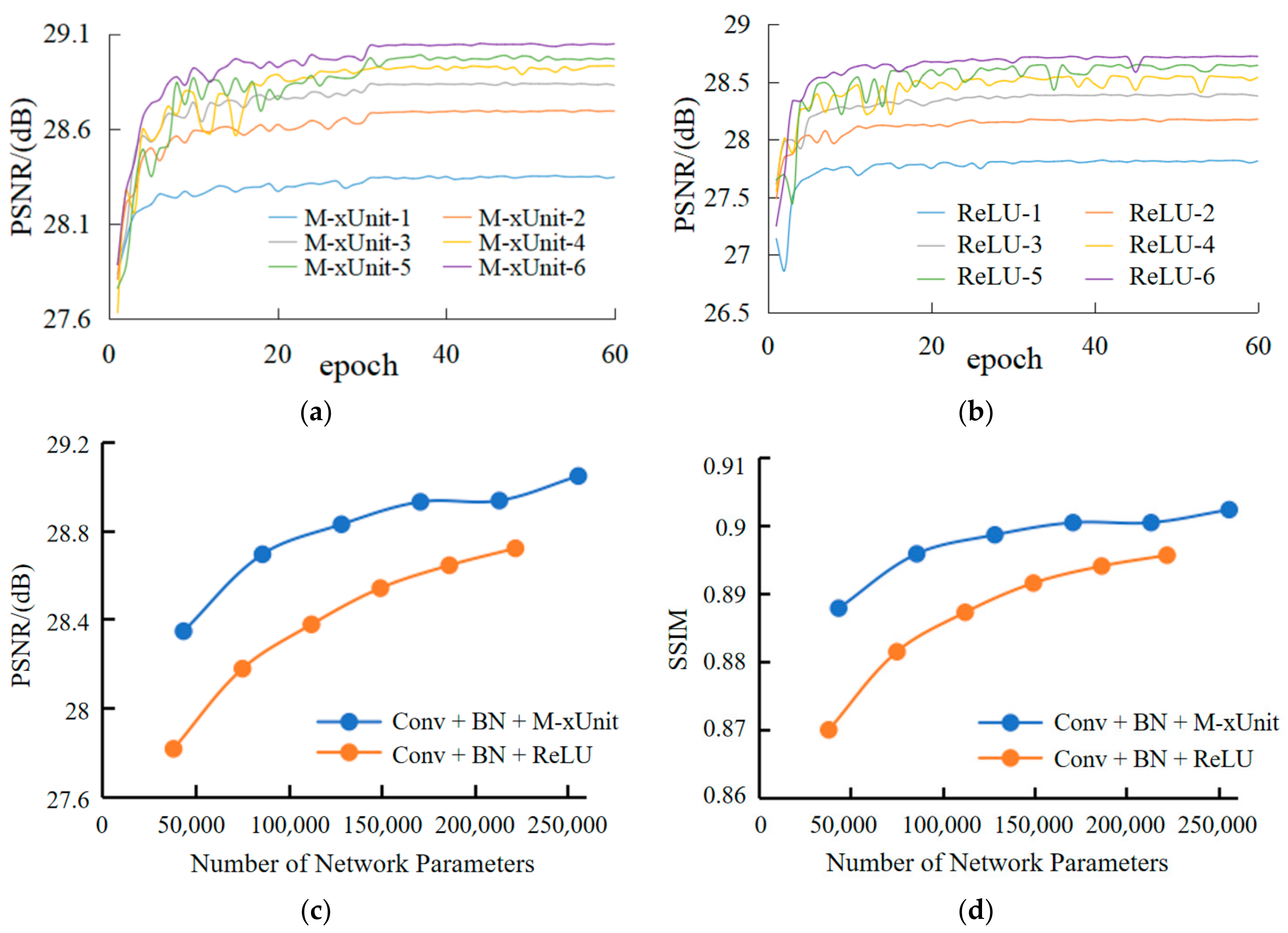
Figure 3 shows the difference between deep convolution and ordinary convolution. One convolution kernel of deep convolution corresponds to one channel, and each channel can only be convoluted by one kernel. The number of output channels generated in this process is the same as the number of input channels. Compared with ordinary convolution, deep convolution has lower parameters and lower operation cost, which is the main reason why M-xUnit has fewer parameters. Although the number of parameters for a function increases, compared with the parameters of the whole network, the increase of parameters is quite limited. At the same time, the speckle suppression performance of the network is also improved.
Assume the size of the input image is
with m channels, the size of the convolution kernel is
, and the number of kernels is n. As is shown in
Figure 3, for ordinary convolution, each output channel is convoluted by m kernels, thus the computational complexity is
, while for deep convolution, each output channel is convoluted by only one kernel, thus its computational complexity is
. It can be seen that the computation cost of deep convolution is
times that of ordinary convolution.
However, deep convolution cannot expand the feature maps, and because the input channels are convoluted separately, it cannot effectively use the feature information of different channels in the same spatial position. Therefore, it is necessary to employ pointwise convolution to combine the feature maps generated by deep convolution into a new feature map. The combination of the two convolutions forms a deep separable convolution, which is very suitable for the lightweight network of the mobile terminal. This is also the core of Mobilenet [
57] and Xception [
58]. However, the basic idea of the M-xUnit activation function in this section is to correlate the weight mapping with the corresponding spatial adjacent elements of the input elements. This only requires a convolution operation and does not need to consider whether or not to effectively use the feature information of the same spatial position between channels. Therefore, this section only adds one layer of deep convolution to the M-xUnit activation unit.
2.3. Evaluation Index of SAR Image Speckle Suppression
It can be carried out from two aspects—subjective evaluation and objective evaluation—to judge the quality of the denoised images. Subjective evaluation is to observe, analyze, and judge the result of speckle suppression from human vision, which is mainly reflected in the preservation of image texture and detail information. Objective evaluation uses undistorted images as evaluation, and the commonly used indexes are peak signal to noise ratio (PSNR) [
61], structural similarity index (SSIM) [
62], equivalent numbers of looks (ENL) [
63], mean value [
64], and standard deviation [
65]. In this paper, PSNR and SSIM are used to evaluate the simulated SAR experiment, and ENL is used to evaluate the real SAR image experiment.
- (1)
PSNR
PSNR is the most widely used objective evaluation index based on the error between corresponding pixels, which is often defined by mean square error (MSE). MSE is defined as follows:
where
X and
Y represent two images of
m ×
n sizes, respectively.
The PSNR formula is defined as follows:
where
MAX represents the maximum pixel value of the image. The higher the PSNR value is, the better the effect of noise suppression is.
- (2)
SSIM
SSIM mainly measures the similarity between the denoised image and the reference image, which is mainly reflected in brightness, contrast, and structure. The interval range of SSIM value is generally between 0 and 1. The closer it is to 1, the higher the similarity between the two images is, which results in better image processing. The calculation method is as follows:
where
m and
n are two images,
and
are the mean values of image
m and image
n,
and
are the variances of image
m and image
n, and
is the covariance.
and
are constants to avoid division by zero.
- (3)
ENL
ENL is a generally accepted speckle reduction index in the field of SAR image speckle suppression. It can measure the smoothness of the homogeneous region. The larger the value is, the smoother the region is and the better the noise suppression effect is as well. The formula can be defined as:
where
is a constant related to the SAR image format, and if it is a SAR image with intensity format,
. If the SAR image is in amplitude format, then
.
and
represent the mean and the variance of the region, respectively.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}