
A Deep Learning-Based Framework for Automated Extraction of Building Footprint Polygons from Very High-Resolution Aerial Imagery




Abstract
:
1. Introduction
2. Methodology
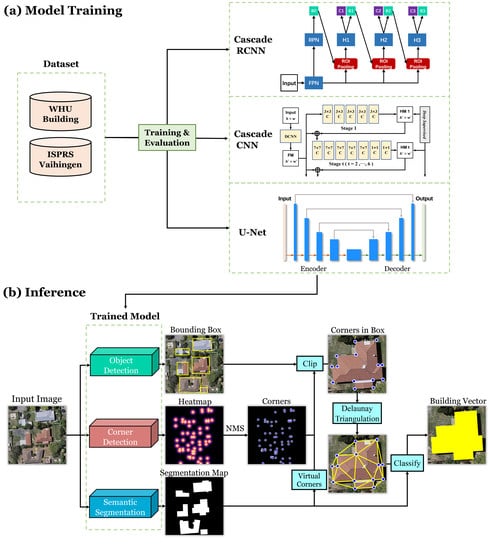
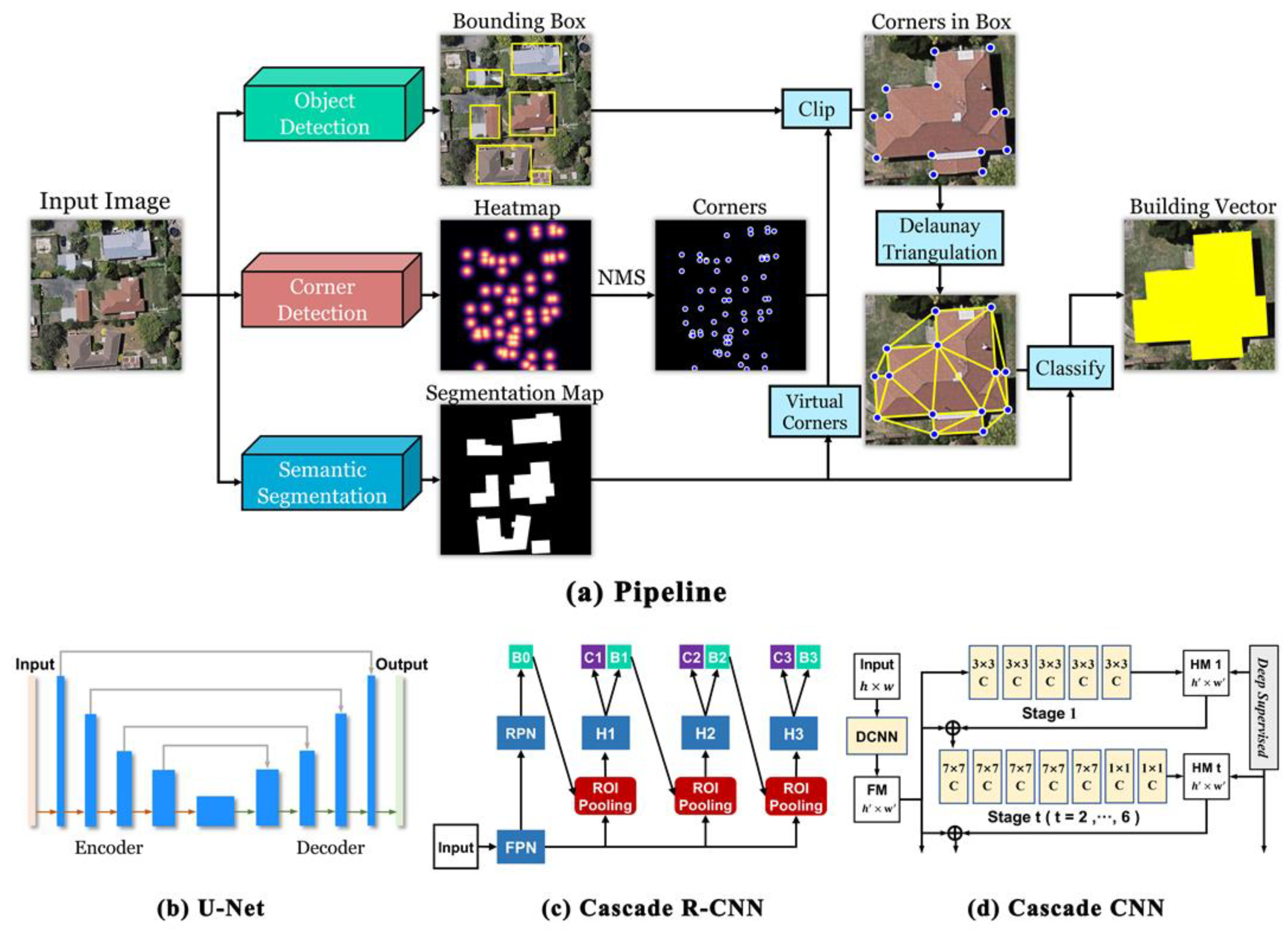
2.1. Overview
2.2. Building Segmentation
2.3. Building Object Localization
2.4. Corner Detection
2.5. Polygon Construction
3. Experiment Setup
3.1. Dataset
3.2. Implementation Details
3.3. Comparative Methods
3.4. Ablation Studies
3.5. Evaluation Metrics
4. Results
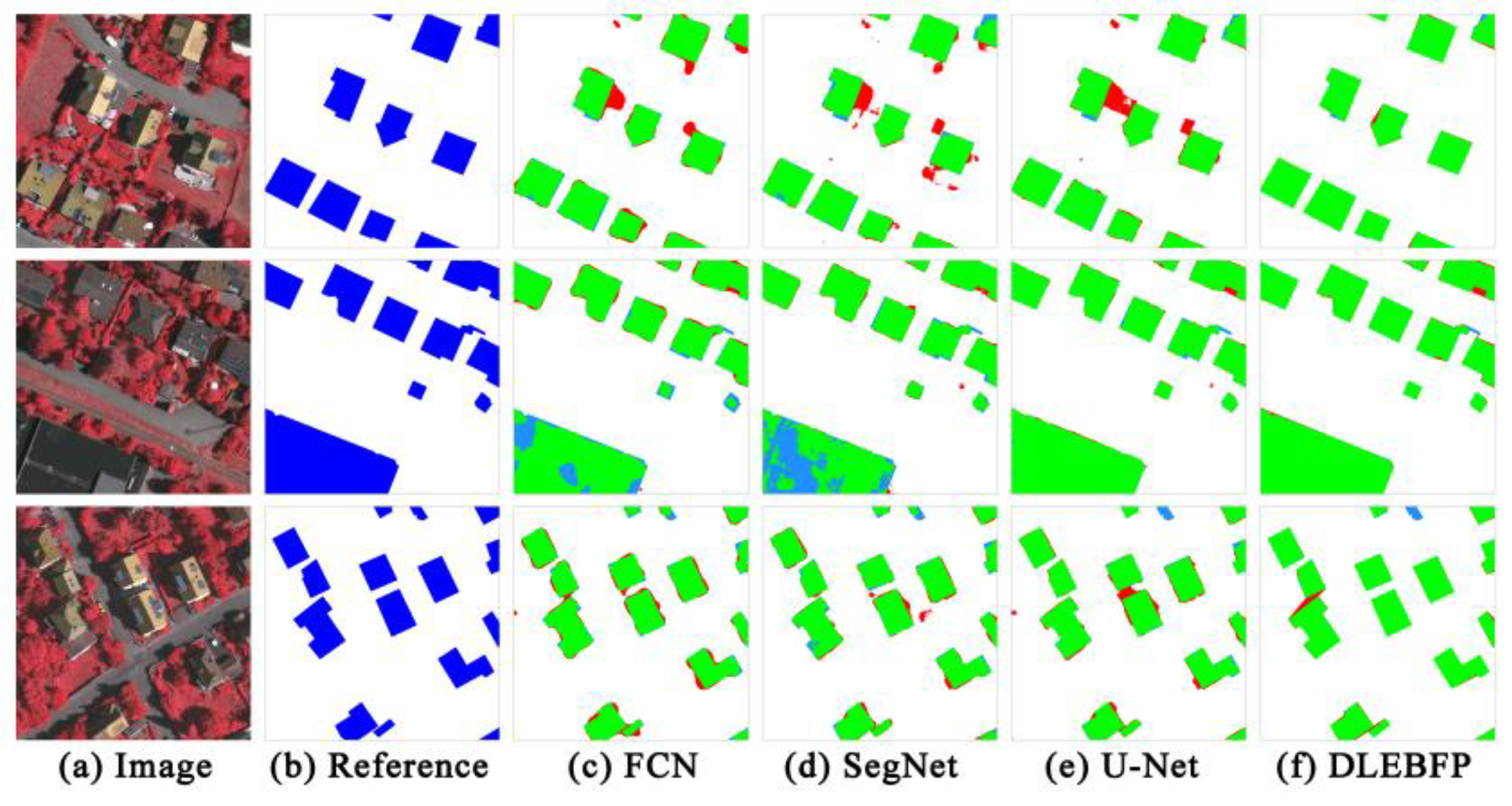
4.1. Results on WHU Dataset
4.2. Results on Vaihingen Dataset
4.3. Ablation Studies
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tong, X.; Lin, X.; Feng, T.; Xie, H.; Liu, S.; Hong, Z.; Chen, P. Use of shadows for detection of earthquake-induced collapsed buildings in high-resolution satellite imagery. ISPRS J. Photogramm. Remote Sens. 2013, 79, 53–67. [Google Scholar] [CrossRef]
- Jensen, J.R.; Cowen, D.C. Remote sensing of urban/suburban infrastructure and socio-economic attributes. Photogramm. Eng. Remote Sens. 1999, 65, 611–622. [Google Scholar]
- Turker, M.; Koc-San, D. Building extraction from high-resolution optical spaceborne images using the integration of support vector machine (SVM) classification, Hough transformation and perceptual grouping. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 58–69. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Liasis, G.; Stavrou, S. Building extraction in satellite images using active contours and colour features. Int. J. Remote Sens. 2016, 37, 1127–1153. [Google Scholar] [CrossRef]
- Rottensteiner, F.; Trinder, J.; Clode, S.; Kubik, K. Building detection by fusion of airborne laser scanner data and multi-spectral images: Performance evaluation and sensitivity analysis. ISPRS J. Photogramm. Remote Sens. 2007, 62, 135–149. [Google Scholar] [CrossRef]
- Shi, Y.; Li, Q.; Zhu, X.X. Building footprint generation using improved generative adversarial networks. IEEE Geosci. Remote Sens. Lett. 2018, 16, 603–607. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Zhang, L. A Multidirectional and Multiscale Morphological Index for Automatic Building Extraction from Multispectral GeoEye-1 Imagery. Photogramm. Eng. Remote Sens. 2011, 77, 721–732. [Google Scholar] [CrossRef]
- Ok, A.O.; Senaras, C.; Yuksel, B. Automated Detection of Arbitrarily Shaped Buildings in Complex Environments From Monocular VHR Optical Satellite Imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1701–1717. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. A scale robust convolutional neural network for automatic building extraction from aerial and satellite imagery. Int. J. Remote Sens. 2018, 40, 3308–3322. [Google Scholar] [CrossRef]
- Yuan, J. Learning Building Extraction in Aerial Scenes with Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2793–2798. [Google Scholar] [CrossRef]
- Du, S.; Zhang, F.; Zhang, X. Semantic classification of urban buildings combining VHR image and GIS data: An improved random forest approach. ISPRS J. Photogramm. Remote Sens. 2015, 105, 107–119. [Google Scholar] [CrossRef]
- Wu, G.; Shao, X.; Guo, Z.; Chen, Q.; Yuan, W.; Shi, X.; Xu, Y.; Shibasaki, R. Automatic Building Segmentation of Aerial Imagery Using Multi-Constraint Fully Convolutional Networks. Remote Sens. 2018, 10, 407. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Yang, M.; Xie, M.; Guo, Z.; Li, E.; Zhang, L.; Pei, T.; Wang, D. Accurate Building Extraction from Fused DSM and UAV Images Using a Chain Fully Convolutional Neural Network. Remote Sens. 2019, 11, 2912. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Du, S. Learning multiscale and deep representations for classifying remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2016, 113, 155–165. [Google Scholar] [CrossRef]
- Ye, Z.; Fu, Y.; Gan, M.; Deng, J.; Comber, A.; Wang, K. Building Extraction from Very High Resolution Aerial Imagery Using Joint Attention Deep Neural Network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Wegner, J.D.; Galliani, S.; Schindler, K.; Datcu, M.; Stilla, U. Semantic segmentation of aerial images with an ensemble of CNSS. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 473–480. [Google Scholar] [CrossRef] [Green Version]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef] [Green Version]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Rottensteiner, F.; Sohn, G.; Gerke, M.; Wegner, J.D.; Breitkopf, U.; Jung, J. Results of the ISPRS benchmark on urban object detection and 3D building reconstruction. ISPRS J. Photogramm. Remote Sens. 2014, 93, 256–271. [Google Scholar] [CrossRef]
- Dey, E.K.; Awrangjeb, M.; Stantic, B. Outlier detection and robust plane fitting for building roof extraction from LiDAR data. Int. J. Remote Sens. 2020, 41, 6325–6354. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Gilani, S.A.N.; Siddiqui, F.U. An effective data-driven method for 3-d building roof reconstruction and robust change detection. Remote Sens. 2018, 10, 1512. [Google Scholar] [CrossRef] [Green Version]
- Gilani, S.A.N.; Awrangjeb, M.; Lu, G. Segmentation of Airborne Point Cloud Data for Automatic Building Roof Extraction. GIScience Remote Sens. 2018, 55, 63–89. [Google Scholar] [CrossRef] [Green Version]
- Mahmud, J.; Price, T.; Bapat, A.; Frahm, J.-M. Boundary-aware 3D building reconstruction from a single overhead image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 441–451. [Google Scholar]
- Wang, M.; Yuan, S.; Pan, J. Building detection in high resolution satellite urban image using segmentation, corner detection combined with adaptive windowed hough transform. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium-IGARSS, Melbourne, Australia, 21–26 July 2013; pp. 508–511. [Google Scholar]
- Qin, X.; He, S.; Yang, X.; Dehghan, M.; Qin, Q.; Martin, J. Accurate Outline Extraction of Individual Building From Very High-Resolution Optical Images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1775–1779. [Google Scholar] [CrossRef]
- Girard, N.; Tarabalka, Y. End-to-end learning of polygons for remote sensing image classification. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2083–2086. [Google Scholar]
- Wu, G.; Guo, Z.; Shi, X.; Chen, Q.; Xu, Y.; Shibasaki, R.; Shao, X. A Boundary Regulated Network for Accurate Roof Segmentation and Outline Extraction. Remote Sens. 2018, 10, 1195. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- Liao, C.; Hu, H.; Li, H.; Ge, X.; Chen, M.; Li, C.; Zhu, Q. Joint Learning of Contour and Structure for Boundary-Preserved Building Extraction. Remote Sens. 2021, 13, 1049. [Google Scholar] [CrossRef]
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartogr. Int. J. Geogr. Inf. Geovis. 1973, 10, 112–122. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Müller, J.-C. Line generalization based on analysis of shape characteristics. Cartogr. Geogr. Inf. Syst. 1998, 25, 3–15. [Google Scholar] [CrossRef]
- Zhou, S.; Jones, C.B. Shape-aware line generalisation with weighted effective area. In Developments in Spatial Data Handling; Springer: Berlin/Heidelberg, Germany, 2005; pp. 369–380. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Polygonization of remote sensing classification maps by mesh approximation. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 560–564. [Google Scholar]
- Song, W.; Zhong, B.; Sun, X. Building corner detection in aerial images with fully convolutional networks. Sensors 2019, 19, 1915. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention, Pt Iii; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Lecture Notes in Computer Science: Munich, Germany, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Jaturapitpornchai, R.; Matsuoka, M.; Kanemoto, N.; Kuzuoka, S.; Ito, R.; Nakamura, R. Newly built construction detection in sar images using deep learning. Remote Sens. 2019, 11, 1444. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1302–1310. [Google Scholar]
- Pfister, T.; Charles, J.; Zisserman, A. Flowing ConvNets for Human Pose Estimation in Videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1913–1921. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. Arxiv Prepr. 2014, arXiv:1409.1556. Available online: https://arxiv.org/abs/1409.1556 (accessed on 1 February 2021).
- Li, J.; Su, W.; Wang, Z. Simple pose: Rethinking and improving a bottom-up approach for multi-person pose estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11354–11361. [Google Scholar]
- Deng, M.; Liu, Q.; Cheng, T.; Shi, Y. An adaptive spatial clustering algorithm based on Delaunay triangulation. Comput. Environ. Urban Syst. 2011, 35, 320–332. [Google Scholar] [CrossRef]
- He, X.; Zhang, X.; Xin, Q. Recognition of building group patterns in topographic maps based on graph partitioning and random forest. ISPRS J. Photogramm. Remote Sens. 2018, 136, 26–40. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, L.; Wu, Y.; Wu, G.; Guo, Z.; Waslander, S.L. Aerial imagery for roof segmentation: A large-scale dataset towards automatic mapping of buildings. ISPRS J. Photogramm. Remote Sens. 2019, 147, 42–55. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Shi, W.; Cheung, C. Performance evaluation of line simplification algorithms for vector generalization. Cartogr. J. 2006, 43, 27–44. [Google Scholar] [CrossRef]
- He, H.; Zhou, J.; Chen, M.; Chen, T.; Li, D.; Cheng, P. Building extraction from UAV images jointly using 6D-SLIC and multiscale Siamese convolutional networks. Remote Sens. 2019, 11, 1040. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Wang, L.; Waslander, S.L.; Liu, X. An end-to-end shape modeling framework for vectorized building outline generation from aerial images. ISPRS J. Photogramm. Remote Sens. 2020, 170, 114–126. [Google Scholar] [CrossRef]
- Heckbert, P.S.; Garland, M. Survey of Polygonal Surface Simplification Algorithms; Carnegie-Mellon Univ Pittsburgh PA School of Computer Science: Pittsburgh, PA, USA, 1 May 1997. [Google Scholar]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef] [Green Version]
- Ienco, D.; Interdonato, R.; Gaetano, R.; Minh, D.H.T. Combining Sentinel-1 and Sentinel-2 Satellite Image Time Series for land cover mapping via a multi-source deep learning architecture. ISPRS J. Photogramm. Remote Sens. 2019, 158, 11–22. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yang, H.L.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building Extraction at Scale Using Convolutional Neural Network: Mapping of the United States. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2600–2614. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Shi, Y.; Huang, X.; Zhu, X.X. Building footprint generation by integrating convolution neural network with feature pairwise conditional random field (FPCRF). IEEE Trans. Geosci. Remote Sens. 2020, 58, 7502–7519. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Scene 1 | Scene 2 | Scene 3 | Scene 4 | Scene 5 | Test Dataset | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | IoU | Precision | Recall | IoU | Precision | Recall | IoU | Precision | Recall | IoU | Precision | Recall | IoU | Precision | Recall | IoU | |
| FCN | 0.941 | 0.941 | 0.889 | 0.925 | 0.921 | 0.857 | 0.918 | 0.942 | 0.868 | 0.942 | 0.917 | 0.868 | 0.938 | 0.909 | 0.858 | 0.932 | 0.897 | 0.841 |
| SegNet | 0.941 | 0.959 | 0.905 | 0.887 | 0.957 | 0.853 | 0.898 | 0.957 | 0.864 | 0.951 | 0.941 | 0.898 | 0.922 | 0.940 | 0.870 | 0.911 | 0.925 | 0.848 |
| U-Net | 0.945 | 0.970 | 0.917 | 0.908 | 0.956 | 0.872 | 0.907 | 0.964 | 0.879 | 0.947 | 0.949 | 0.902 | 0.933 | 0.954 | 0.893 | 0.917 | 0.933 | 0.861 |
| DLEBFP | 0.959 | 0.970 | 0.932 | 0.943 | 0.939 | 0.886 | 0.935 | 0.954 | 0.895 | 0.950 | 0.941 | 0.896 | 0.932 | 0.949 | 0.887 | 0.926 | 0.914 | 0.851 |
| Method | IoU Based on the Raster Data | IoU Based on the Vector Data | Changing Rate | Number of Reference Buildings | Number of Extracted Buildings | Number of Reference Vertices | Number of Extracted Vertices | VertexF0.5 | VertexF1.0 |
|---|---|---|---|---|---|---|---|---|---|
| DLEBFP | 0.851 | 0.850 | 0.1% | 15,675 | 14,687 | 134,246 | 135,623 | 0.668 | 0.744 |
| U-Net | 0.861 | 0.858 | 0.3% | 15,675 | 18,302 | 134,246 | 7,990,152 | 0.022 | 0.025 |
| U-Net + Douglas–Peucker (d = 0.1 m) | 0.861 | 0.858 | 0.3% | 15,675 | 18,302 | 134,246 | 1,138,969 | 0.114 | 0.134 |
| U-Net + Douglas–Peucker (d = 0.5 m) | 0.861 | 0.851 | 1.0% | 15,675 | 18,302 | 134,246 | 278,541 | 0.229 | 0.309 |
| U-Net + Douglas–Peucker (d = 1.0 m) | 0.861 | 0.840 | 2.1% | 15,675 | 18,302 | 134,246 | 250,132 | 0.216 | 0.295 |
| Model | Precision | Recall | IoU | VertexF0.5 | VertexF1.0 |
|---|---|---|---|---|---|
| FCN | 0.883 | 0.950 | 0.844 | 0.024 | 0.040 |
| SegNet | 0.910 | 0.932 | 0.854 | 0.023 | 0.030 |
| U-Net | 0.932 | 0.942 | 0.881 | 0.037 | 0.043 |
| U-Net + DP0.1 | 0.932 | 0.941 | 0.879 | 0.198 | 0.245 |
| U-Net + DP0.5 | 0.936 | 0.929 | 0.874 | 0.404 | 0.555 |
| U-Net + DP1.0 | 0.938 | 0.917 | 0.865 | 0.417 | 0.562 |
| DLEBFP | 0.947 | 0.922 | 0.876 | 0.731 | 0.782 |
| Model | Scene 1 | Scene 2 | Scene 3 | Scene 4 | Scene 5 | Test Dataset | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | IoU | Precision | Recall | IoU | Precision | Recall | IoU | Precision | Recall | IoU | Precision | Recall | IoU | Precision | Recall | IoU | |
| Baseline | 0.885 | 0.776 | 0.705 | 0.891 | 0.771 | 0.704 | 0.875 | 0.792 | 0.712 | 0.869 | 0.702 | 0.635 | 0.906 | 0.817 | 0.753 | 0.882 | 0.736 | 0.670 |
| Baseline + BB | 0.958 | 0.737 | 0.714 | 0.943 | 0.743 | 0.711 | 0.926 | 0.736 | 0.694 | 0.941 | 0.653 | 0.627 | 0.927 | 0.790 | 0.743 | 0.918 | 0.706 | 0.664 |
| Baseline + VC | 0.914 | 0.954 | 0.877 | 0.911 | 0.890 | 0.820 | 0.909 | 0.954 | 0.871 | 0.896 | 0.931 | 0.840 | 0.925 | 0.946 | 0.879 | 0.905 | 0.911 | 0.832 |
| Baseline + BB + VC | 0.959 | 0.970 | 0.932 | 0.943 | 0.939 | 0.886 | 0.935 | 0.954 | 0.895 | 0.950 | 0.941 | 0.896 | 0.931 | 0.949 | 0.887 | 0.926 | 0.914 | 0.851 |
| Model | Inference Time (ms) | Post-Processing Time (ms) | File Size (MB) |
|---|---|---|---|
| FCN | 153.11 | 11.29 | 95.6 |
| SegNet | 131.43 | 21.22 | 129.7 |
| U-Net | 185.64 | 37.94 | 141.8 |
| U-Net + DP0.1 | 185.64 | 141.37 | 26.4 |
| U-Net + DP0.5 | 185.64 | 135.95 | 10.9 |
| U-Net + DP1.0 | 185.64 | 135.05 | 9.9 |
| DLEBFP | 523.49 | 351.52 | 3.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Xin, Q.; Sun, Y.; Cao, M. A Deep Learning-Based Framework for Automated Extraction of Building Footprint Polygons from Very High-Resolution Aerial Imagery. Remote Sens. 2021, 13, 3630. https://doi.org/10.3390/rs13183630
Li Z, Xin Q, Sun Y, Cao M. A Deep Learning-Based Framework for Automated Extraction of Building Footprint Polygons from Very High-Resolution Aerial Imagery. Remote Sensing. 2021; 13(18):3630. https://doi.org/10.3390/rs13183630
Chicago/Turabian StyleLi, Ziming, Qinchuan Xin, Ying Sun, and Mengying Cao. 2021. "A Deep Learning-Based Framework for Automated Extraction of Building Footprint Polygons from Very High-Resolution Aerial Imagery" Remote Sensing 13, no. 18: 3630. https://doi.org/10.3390/rs13183630
APA StyleLi, Z., Xin, Q., Sun, Y., & Cao, M. (2021). A Deep Learning-Based Framework for Automated Extraction of Building Footprint Polygons from Very High-Resolution Aerial Imagery. Remote Sensing, 13(18), 3630. https://doi.org/10.3390/rs13183630