
A Coarse-to-Fine Contour Optimization Network for Extracting Building Instances from High-Resolution Remote Sensing Imagery


 , , ,
, , , (This article belongs to the Section AI Remote Sensing)
Abstract
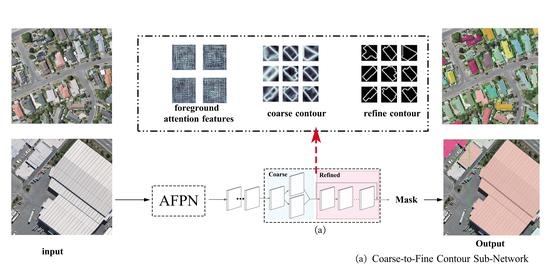
:
1. Introduction
- A coarse-to-fine contour sub-network is developed for better-capturing building contour, which employs a significant loss in an iteration learning way and achieves great improvement in the refinement of building contour;
- An AFPN sub-network is designed to introduce an attention mechanism into the feature pyramid network (FPN [8]) and improve the ability to detect small buildings;
- A new metric index contour score (CS) is derived from the differences between predicted contours and ground truths to evaluate model performance further. The CS provides a new exploration in assessing the performance of image instance segmentation models;
- Experiments on three diverse building extraction datasets, two public datasets (WHU aerial image dataset [3] and CrowdAI mapping challenge dataset [CrowdAI] [9]) and a self-annotated dataset are conducted. Experimental results demonstrate that the proposed method shows advantages over existing state-of-the-art instance segmentation methods.
2. Related Work
2.1. Building Extraction Based on Semantic Segmentation
2.2. Building Instances Extraction Based on Instance Segmentation
3. Methodology
3.1. AFPN Sub-Network
3.2. Coarse-to-Fine Contour Sub-Network
3.2.1. Coarse Contour Branch
3.2.2. Refined Contour Branch
3.2.3. Loss Function
4. Experiments
4.1. Datasets
4.1.1. WHU Aerial Image Dataset
4.1.2. CrowdAI
4.1.3. Self-Annotated Building Instance Segmentation Dataset
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Baselines
5. Results
5.1. Evaluation with the WHU Aerial Image Dataset
5.2. Evaluation with CrowdAI
5.3. Evaluation with the Self-Annotated Building Instance Segmentation Dataset
6. Discussion
6.1. Ablation Study
6.2. Effect of Edge Detection Operators
6.3. Effect of Contour Loss
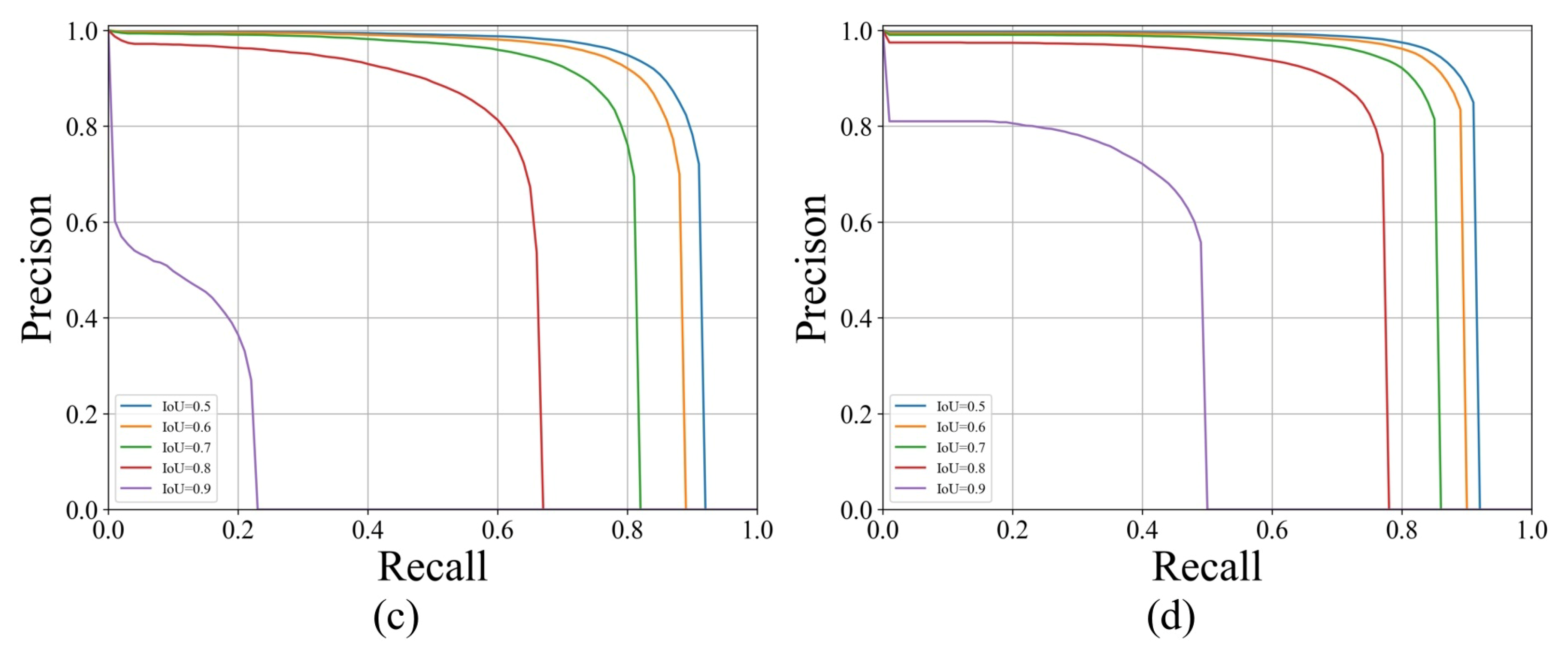
6.4. More Experiments with Different Thresholds
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mayer, H. Automatic object extraction from aerial imagery—A survey focusing on buildings. Comput. Vis. Image Underst. 1999, 74, 138–149. [Google Scholar] [CrossRef] [Green Version]
- Shrestha, S.; Vanneschi, L. Improved fully convolutional network with conditional random fields for building extraction. Remote Sens. 2018, 10, 1135. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Zhao, K.; Kang, J.; Jung, J.; Sohn, G. Building extraction from satellite images using mask R-CNN with building boundary regularization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 247–251. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Wen, Q.; Jiang, K.; Wang, W.; Liu, Q.; Guo, Q.; Li, L.; Wang, P. Automatic building extraction from Google Earth images under complex backgrounds based on deep instance segmentation network. Sensors 2019, 19, 333. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Chen, D.; Ma, A.; Zhong, Y.; Fang, F.; Xu, K. Multiscale U-Shaped CNN Building Instance Extraction Framework With Edge Constraint for High-Spatial-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6106–6120. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Mohanty, S.P.; Czakon, J.; Kaczmarek, K.A.; Pyskir, A.; Tarasiewicz, P.; Kunwar, S.; Rohrbach, J.; Luo, D.; Prasad, M.; Fleer, S.; et al. Crowdai Mapping Challenge 2018: Baseline with Maskrcnn. Front. Artif. Intell. 2020, 3. Available online: https://www.crowdai.org/challenges/mapping-challenge/dataset_files (accessed on 26 July 2021).
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A fully convolutional neural network for automatic building extraction from high-resolution remote sensing images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef] [Green Version]
- Ma, W.; Wan, Y.; Li, J.; Zhu, S.; Wang, M. An automatic morphological attribute building extraction approach for satellite high spatial resolution imagery. Remote Sens. 2019, 11, 337. [Google Scholar] [CrossRef] [Green Version]
- Wagner, F.H.; Dalagnol, R.; Tarabalka, Y.; Segantine, T.Y.; Thomé, R.; Hirye, M.C. U-net-id, an instance segmentation model for building extraction from satellite images—Case study in the Joanopolis City, Brazil. Remote Sen. 2020, 12, 1544. [Google Scholar] [CrossRef]
- Yang, G.; Zhang, Q.; Zhang, G. EANet: Edge-aware network for the extraction of buildings from aerial images. Remote Sens. 2020, 12, 2161. [Google Scholar] [CrossRef]
- Peng, J.; Zhang, D.; Liu, Y. An improved snake model for building detection from urban aerial images. Pattern Recognit. Lett. 2005, 26, 587–595. [Google Scholar] [CrossRef]
- Shackelford, A.K.; Davis, C.H.; Wang, X. Automated 2-D building footprint extraction from high-resolution satellite multispectral imagery. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Anchorage, AK, USA, 20–24 September 2004; Volume 3, pp. 1996–1999. [Google Scholar]
- Zhang, Q.; Huang, X.; Zhang, G. Urban area extraction by regional and line segment feature fusion and urban morphology analysis. Remote Sens. 2017, 9, 663. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Cui, S.; Yan, Q. Building extraction from high resolution satellite imagery based on multi-scale image segmentation and model matching. In Proceedings of the International Workshop on Earth Observation and Remote Sensing Applications (EORSA), Beijing, China, 30 June–2 July 2008; pp. 1–7. [Google Scholar]
- Liu, C.; Huang, X.; Zhu, Z.; Chen, H.; Tang, X.; Gong, J. Automatic extraction of built-up area from ZY3 multi-view satellite imagery: Analysis of 45 global cities. Remote Sens. Environ. 2019, 226, 51–73. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Ye, Z.; Fu, Y.; Gan, M.; Deng, J.; Comber, A.; Wang, K. Building extraction from very high resolution aerial imagery using joint attention deep neural network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef] [Green Version]
- Duan, Y.; Sun, L. Buildings Extraction from Remote Sensing Data Using Deep Learning Method Based on Improved U-Net Network. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3959–3961. [Google Scholar]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building footprint extraction from high-resolution images via spatial residual inception convolutional neural network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Volume 9351, pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; He, C.; Fang, J.; Zheng, J.; Fu, H.; Yu, L. Semantic segmentation-based building footprint extraction using very high-resolution satellite images and multi-source GIS data. Remote Sens. 2019, 11, 403. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, M.; Wu, J.; Liu, L.; Zhao, W.; Tian, F.; Shen, Q.; Zhao, B.; Du, R. Dr-net: An improved network for building extraction from high resolution remote sensing image. Remote Sens. 2021, 13, 294. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wu, T.; Hu, Y.; Peng, L.; Chen, R. Improved anchor-free instance segmentation for building extraction from high-resolution remote sensing images. Remote Sens. 2020, 12, 2910. [Google Scholar] [CrossRef]
- Lee, Y.; Park, J. Centermask: Real-time anchor-free instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13906–13915. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Kittler, J. On the accuracy of the Sobel edge detector. Image Vis. Comput. 1983, 1, 37–42. [Google Scholar] [CrossRef]
- Peng, S.; Jiang, W.; Pi, H.; Li, X.; Bao, H.; Zhou, X. Deep snake for real-time instance segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8530–8539. [Google Scholar] [CrossRef]
- Cheng, T.; Wang, X.; Huang, L.; Liu, W. Boundary-preserving mask R-CNN. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 660–676. [Google Scholar]
- Deng, R.; Shen, C.; Liu, S.; Wang, H.; Liu, X. Learning to predict crisp boundaries. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 562–578. [Google Scholar]
- Fang, F.; Wu, K.; Zheng, D. A dataset of building instances of typical cities in China [DB/OL]. Sci. Data Bank 2021. [Google Scholar] [CrossRef]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4974–4983. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. SOLOv2: Dynamic, faster and stronger. arXiv 2020, arXiv:2003.10152. [Google Scholar]
- Wang, X. Laplacian operator-based edge detectors. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 886–890. [Google Scholar] [CrossRef]
- Ding, L.; Goshtasby, A. On the Canny edge detector. Pattern Recognit. 2001, 34, 721–725. [Google Scholar] [CrossRef]
- Zhang, C.C.; Fang, J.D.; Atlantis, P. Edge Detection Based on Improved Sobel Operator. In Proceedings of the 2016 International Conference on Computer Engineering and Information Systems, Gdansk, Poland, 11–14 September 2016; Volume 52, pp. 129–132. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | |||||
|---|---|---|---|---|---|
| Mask R-CNN [5] | 0.601 | 0.884 | 0.473 | 0.649 | 0.685 |
| HTC [43] | 0.643 | 0.900 | 0.511 | 0.688 | 0.760 |
| CenterMask [32] | 0.658 | 0.830 | 0.514 | 0.695 | 0.739 |
| SOLOv2 [44] | 0.614 | 0.878 | 0.454 | 0.661 | 0.737 |
| Proposed model | 0.698 | 0.906 | 0.574 | 0.743 | 0.795 |
| Model | |||||
|---|---|---|---|---|---|
| Mask R-CNN [5] | 0.600 | 0.886 | 0.367 | 0.649 | 0.724 |
| HTC [43] | 0.630 | 0.903 | 0.394 | 0.684 | 0.746 |
| CenterMask [32] | 0.623 | 0.903 | 0.378 | 0.686 | 0.753 |
| SOLOv2 [44] | 0.612 | 0.888 | 0.377 | 0.658 | 0.734 |
| Proposed model | 0.649 | 0.905 | 0.407 | 0.706 | 0.776 |
| Model | |||||
|---|---|---|---|---|---|
| Mask R-CNN [5] | 0.392 | 0.611 | 0.121 | 0.558 | 0.489 |
| HTC [43] | 0.414 | 0.655 | 0.163 | 0.520 | 0.520 |
| CenterMask [32] | 0.400 | 0.670 | 0.160 | 0.520 | 0.517 |
| SOLOv2 [44] | 0.413 | 0.674 | 0.136 | 0.563 | 0.527 |
| Proposed model | 0.437 | 0.683 | 0.191 | 0.570 | 0.546 |
| Model | |||||
|---|---|---|---|---|---|
| Mask R-CNN [5] | 0.601 | 0.884 | 0.473 | 0.649 | 0.685 |
| +attention | 0.647 | 0.901 | 0.536 | 0.690 | 0.763 |
| +Coarse contour branch | 0.663 | 0.897 | 0.546 | 0.701 | 0.771 |
| +Refined contour branch | 0.698 | 0.906 | 0.565 | 0.737 | 0.795 |
| Method | |||||
|---|---|---|---|---|---|
| Sobel [35] | 0.698 | 0.906 | 0.574 | 0.743 | 0.795 |
| Laplace [45] | 0.691 | 0.898 | 0.565 | 0.737 | 0.787 |
| Canny [46] | 0.675 | 0.864 | 0.541 | 0.716 | 0.770 |
| Loss | |||||
|---|---|---|---|---|---|
| no contour loss | 0.659 | 0.860 | 0.516 | 0.695 | 0.752 |
| BCE loss | 0.671 | 0.881 | 0.543 | 0.701 | 0.768 |
| Dice loss | 0.691 | 0.898 | 0.556 | 0.737 | 0.787 |
| both Dice and BCE loss () | 0.696 | 0.905 | 0.563 | 0.743 | 0.793 |
| both Dice and BCE loss () | 0.695 | 0.904 | 0.562 | 0.741 | 0.792 |
| both Dice and BCE loss () | 0.698 | 0.906 | 0.565 | 0.743 | 0.795 |
| Model | CS | ||||||
|---|---|---|---|---|---|---|---|
| Mask R-CNN [5] | 0.601 | 0.886 | 0.845 | 0.758 | 0.561 | 0.077 | 0.685 |
| HTC [43] | 0.643 | 0.902 | 0.875 | 0.812 | 0.667 | 0.213 | 0.760 |
| CenterMask [32] | 0.658 | 0.830 | 0.823 | 0.790 | 0.712 | 0.361 | 0.739 |
| SOLOv2 [44] | 0.614 | 0.878 | 0.864 | 0.787 | 0.613 | 0.113 | 0.737 |
| Proposed model | 0.699 | 0.906 | 0.891 | 0.846 | 0.749 | 0.396 | 0.795 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, F.; Wu, K.; Liu, Y.; Li, S.; Wan, B.; Chen, Y.; Zheng, D. A Coarse-to-Fine Contour Optimization Network for Extracting Building Instances from High-Resolution Remote Sensing Imagery. Remote Sens. 2021, 13, 3814. https://doi.org/10.3390/rs13193814
Fang F, Wu K, Liu Y, Li S, Wan B, Chen Y, Zheng D. A Coarse-to-Fine Contour Optimization Network for Extracting Building Instances from High-Resolution Remote Sensing Imagery. Remote Sensing. 2021; 13(19):3814. https://doi.org/10.3390/rs13193814
Chicago/Turabian StyleFang, Fang, Kaishun Wu, Yuanyuan Liu, Shengwen Li, Bo Wan, Yanling Chen, and Daoyuan Zheng. 2021. "A Coarse-to-Fine Contour Optimization Network for Extracting Building Instances from High-Resolution Remote Sensing Imagery" Remote Sensing 13, no. 19: 3814. https://doi.org/10.3390/rs13193814
APA StyleFang, F., Wu, K., Liu, Y., Li, S., Wan, B., Chen, Y., & Zheng, D. (2021). A Coarse-to-Fine Contour Optimization Network for Extracting Building Instances from High-Resolution Remote Sensing Imagery. Remote Sensing, 13(19), 3814. https://doi.org/10.3390/rs13193814