
Few-Shot Object Detection on Remote Sensing Images via Shared Attention Module and Balanced Fine-Tuning Strategy


Abstract
:
1. Introduction
1.1. Background
1.2. Related Work
1.3. Problems and Motivations
1.4. Contributions and Structure
2. Preliminaries
2.1. Characteristics of Remote SENSING Images
2.2. Few-Shot Fine-Tuning
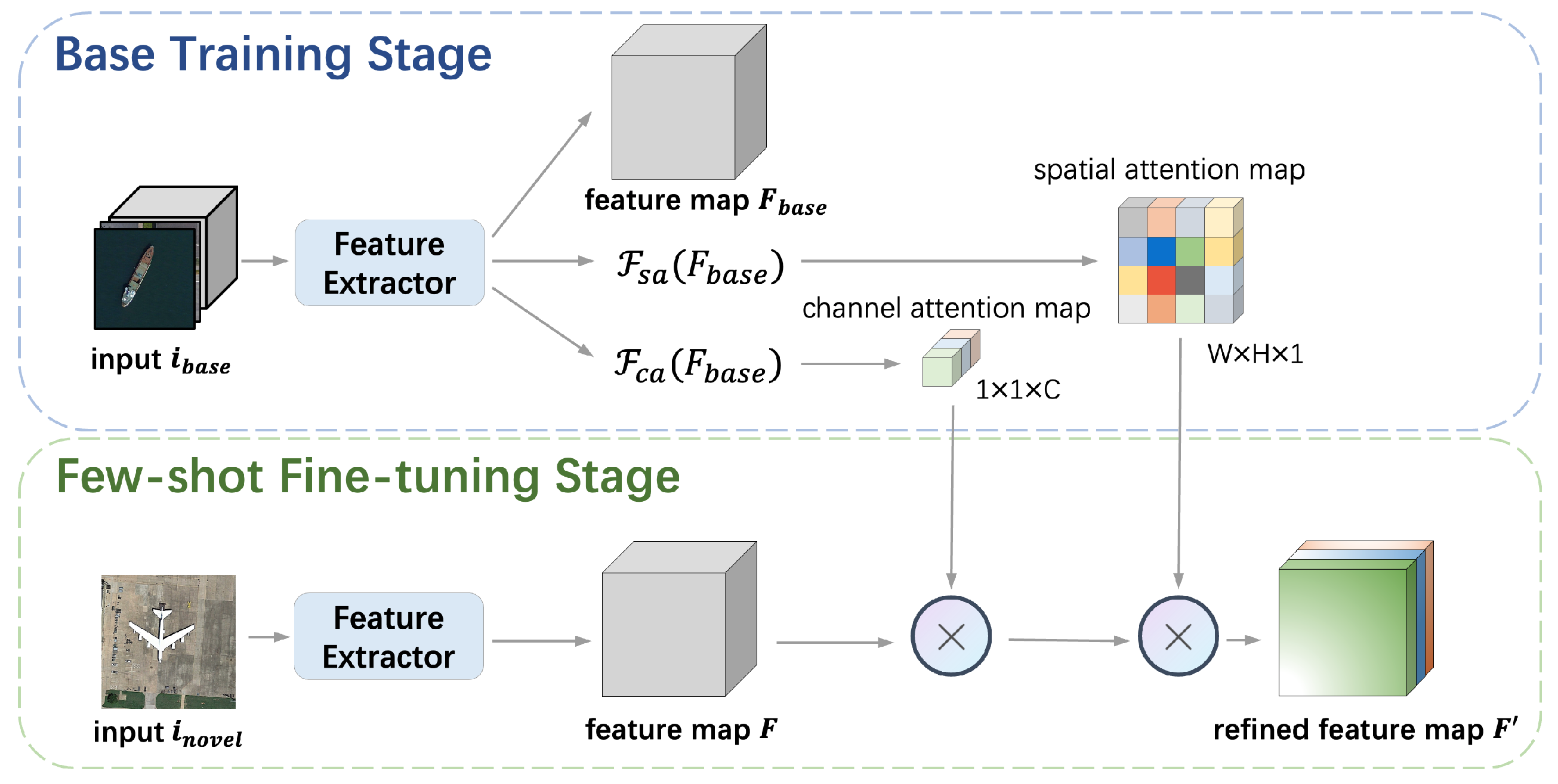
3. Proposed Method
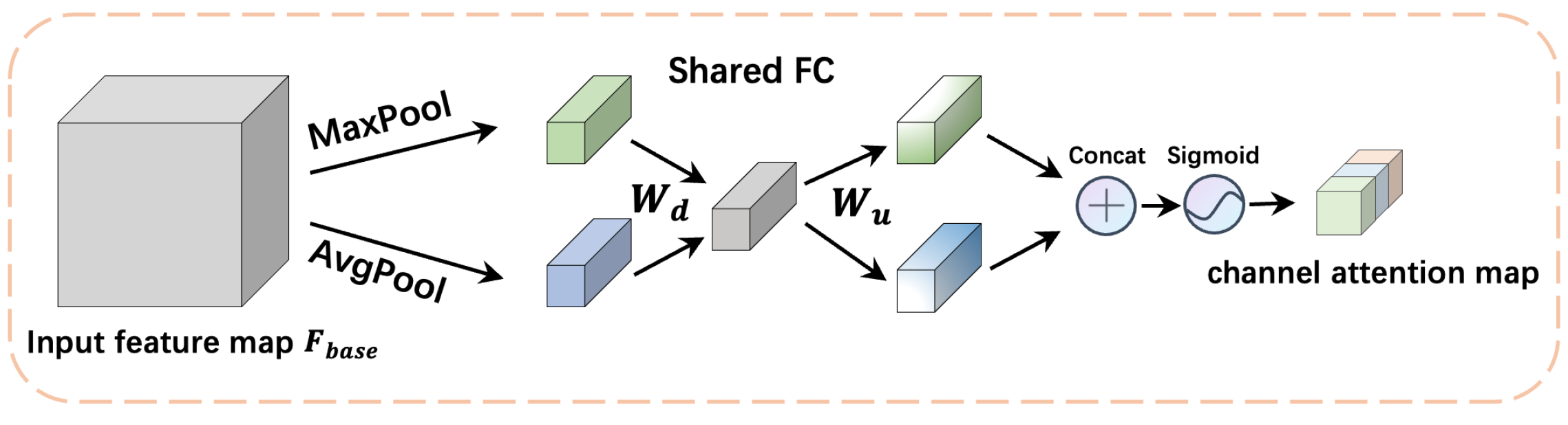
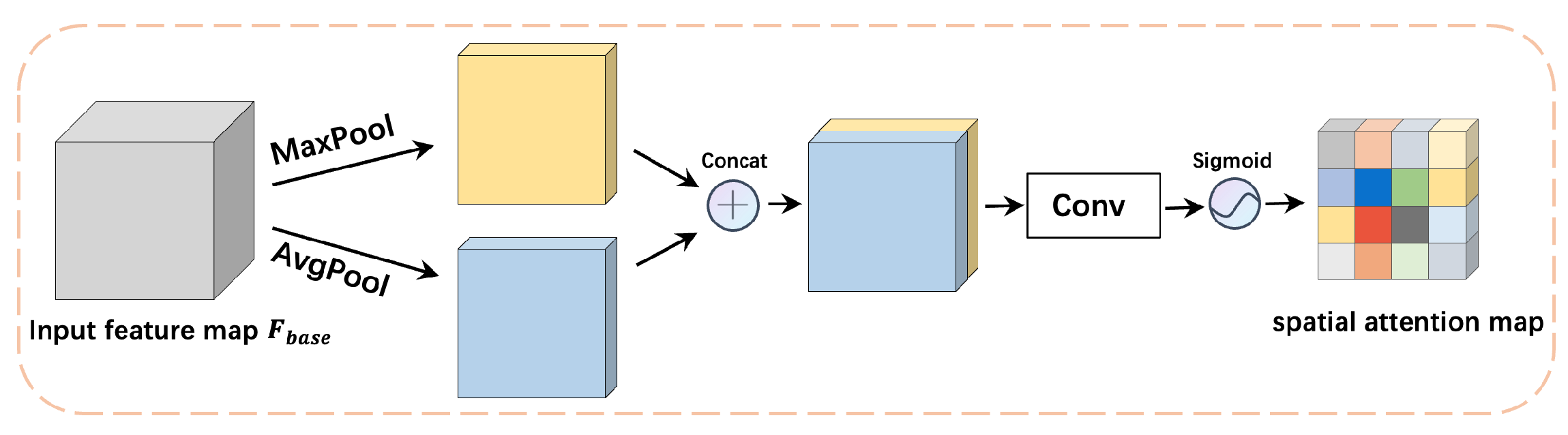
3.1. Shared Attention Module
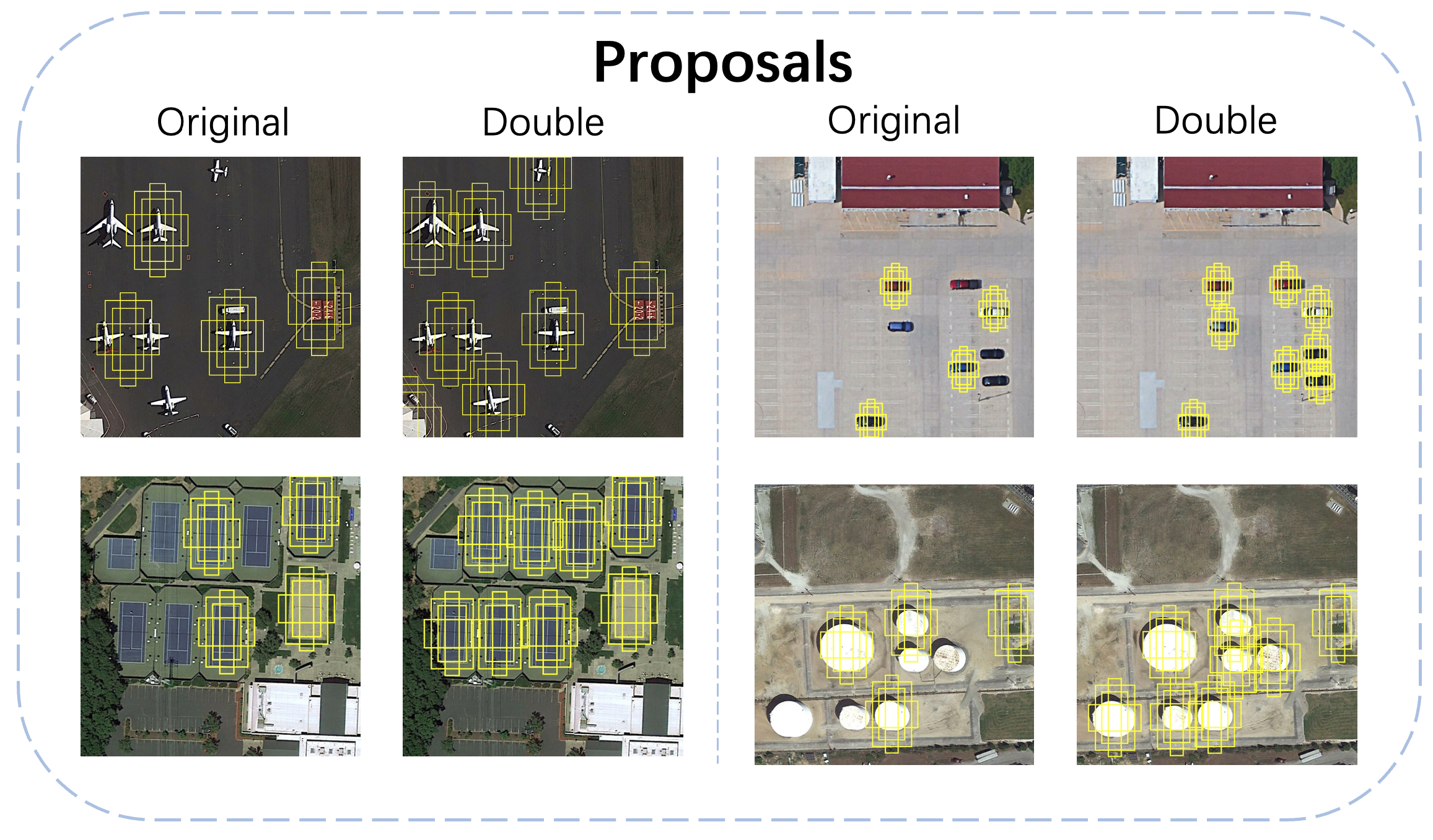
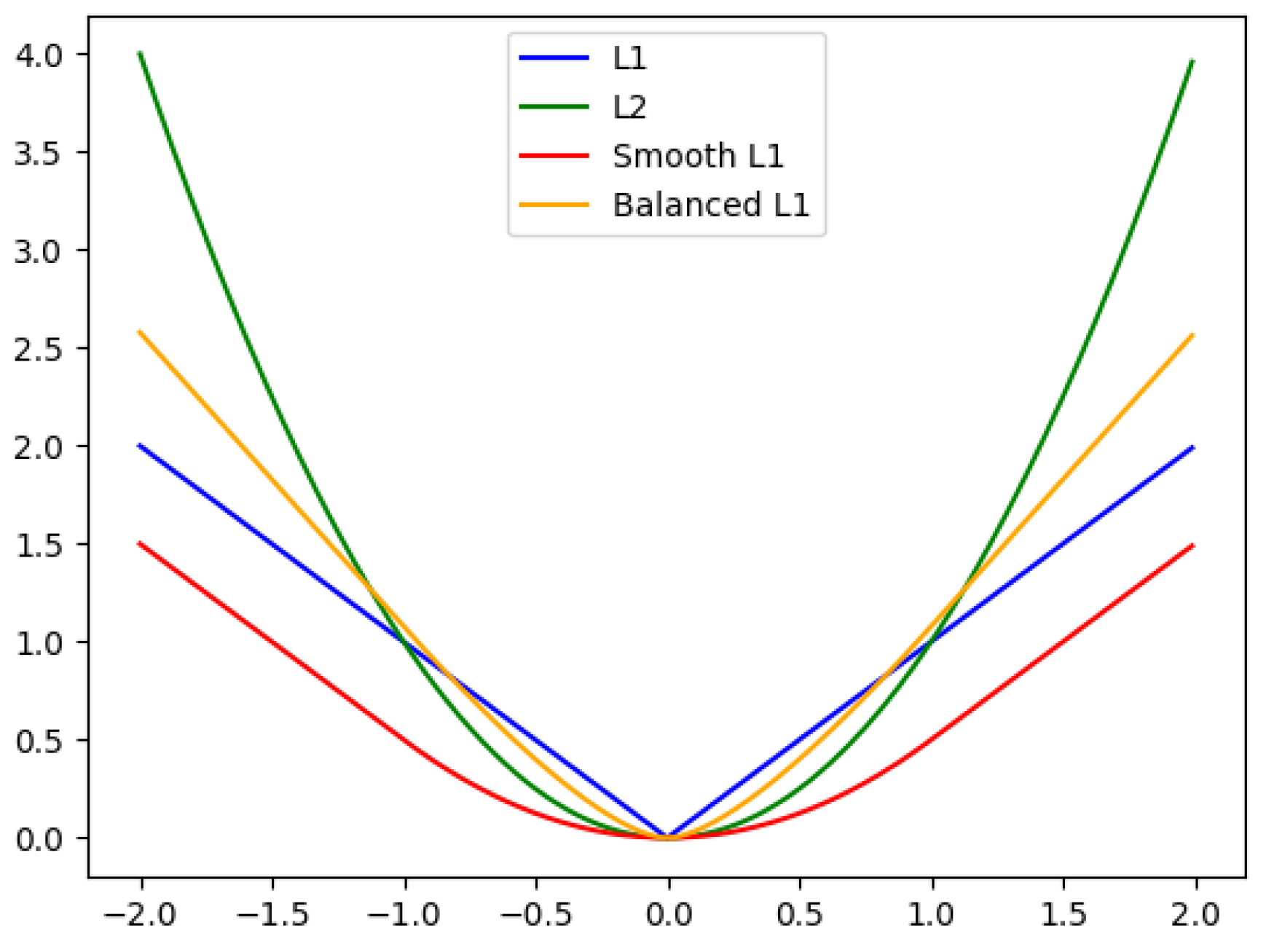
3.2. Balanced Fine-Tuning Strategy
4. Experiments and Results
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Implementation Details
4.1.3. K-Shot Evaluation Metrics
- True Positives (TP): Correctly predicted positive samples.
- False Positives (FP): Falsely predicted positive samples.
- True Negatives (TN): Correctly predicted negative samples.
- False Negatives (FN): Falsely predicted negative samples.
4.1.4. Comparing Methods
4.2. Results
4.3. Ablation Studies
- (1)
- Whether to use the single-stage training strategy or the few-shot fine-tuning strategy (FS-ft) for the few-shot training.
- (2)
- Insert the shared attention module (SAM).
- (3)
- Modify the few-shot fine-tuning stage with the balanced fine tuning strategy (BFS).
5. Discussion
5.1. Performance on Novel Classes
5.2. Visualization of the Loss Curves
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| RSI | Remote sensing image |
| TFA | Two-stage fine tuning approach |
| CNN | Convolutional neural network |
| RPN | Region proposal network |
| RoI | Region of interest |
| mAP | Mean average precision |
| SAM | Shared attention module |
| BFS | Balanced fine tuning strategy |
References
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, W.; Yang, W.; Zhang, H.; Hua, G. Geospatial object detection in high resolution satellite images based on multi-scale convolutional neural network. Remote Sens. 2018, 10, 131. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Luo, B.; Hong, H.; Su, X.; Wang, Y.; Liu, J.; Wang, C.; Zhang, J.; Wei, L. Object detection based on global-local saliency constraint in aerial images. Remote Sens. 2020, 12, 1435. [Google Scholar] [CrossRef]
- Alganci, U.; Soydas, M.; Sertel, E. Comparative research on deep learning approaches for airplane detection from very high-resolution satellite images. Remote Sens. 2020, 12, 458. [Google Scholar] [CrossRef] [Green Version]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4080–4090. [Google Scholar]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9577–9586. [Google Scholar]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Meta-learning to detect rare objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9925–9934. [Google Scholar]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-shot object detection via feature reweighting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 8420–8429. [Google Scholar]
- Li, X.; Deng, J.; Fang, Y. Few-Shot Object Detection on Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. Lstd: A low-shot transfer detector for object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Wang, X.; Huang, T.; Gonzalez, J.; Darrell, T.; Yu, F. Frustratingly Simple Few-Shot Object Detection. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 9919–9928. [Google Scholar]
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-scale positive sample refinement for few-shot object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 456–472. [Google Scholar]
- Karlinsky, L.; Shtok, J.; Harary, S.; Schwartz, E.; Aides, A.; Feris, R.; Giryes, R.; Bronstein, A.M. Repmet: Representative-based metric learning for classification and few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5197–5206. [Google Scholar]
- Li, Y.; Shao, Z.; Huang, X.; Cai, B.; Peng, S. Meta-FSEO: A Meta-Learning Fast Adaptation with Self-Supervised Embedding Optimization for Few-Shot Remote Sensing Scene Classification. Remote Sens. 2021, 13, 2776. [Google Scholar] [CrossRef]
- Zeng, Q.; Geng, J.; Huang, K.; Jiang, W.; Guo, J. Prototype Calibration with Feature Generation for Few-Shot Remote Sensing Image Scene Classification. Remote Sens. 2021, 13, 2728. [Google Scholar] [CrossRef]
- Li, H.; Cui, Z.; Zhu, Z.; Chen, L.; Zhu, J.; Huang, H.; Tao, C. RS-MetaNet: Deep Metametric Learning for Few-Shot Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6983–6994. [Google Scholar] [CrossRef]
- Zhang, P.; Bai, Y.; Wang, D.; Bai, B.; Li, Y. Few-shot classification of aerial scene images via meta-learning. Remote Sens. 2021, 13, 108. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | mAP | ||||
|---|---|---|---|---|---|---|
| 1-Shot | 2-Shot | 3-Shot | 5-Shot | 10-Shot | ||
| Scratch | ResNet101 | 0.0 | 1.7 | 6.3 | 15.1 | 34.3 |
| Joint | ResNet101 | 4.3 | 13.3 | 20.9 | 33.0 | 48.8 |
| TFA | ResNet101 | 3.3 | 10.1 | 14.1 | 16.1 | 25.3 |
| FR [19] | YOLOv2 | - | - | 12.0 | 24.7 | 40.0 |
| FSODM [19] | YOLOv3 | - | - | 32.3 | 52.7 | 65.3 |
| Ours | ResNet50 | 16.2 | 33.3 | 45.6 | 60.4 | 75.1 |
| Ours | ResNet101 | 16.4 | 36.3 | 47.0 | 61.6 | 74.9 |
| Method | Backbone | mAP | ||
|---|---|---|---|---|
| 5-Shot | 10-Shot | 20-Shot | ||
| Scratch | ResNet101 | 8.2 | 16.2 | 28.4 |
| Joint | ResNet101 | 17.7 | 28.1 | 32.9 |
| TFA | ResNet101 | 24.5 | 32.6 | 37.5 |
| FR [19] | YOLOv2 | 22.2 | 27.8 | 34.0 |
| FSODM [19] | YOLOv3 | 24.6 | 32.0 | 36.6 |
| Ours | ResNet50 | 38.4 | 46.5 | 50.1 |
| Ours | ResNet101 | 38.3 | 47.3 | 50.9 |
| FS-ft | SAM | BFS | mAP | ||||
|---|---|---|---|---|---|---|---|
| 1-Shot | 2-Shot | 3-Shot | 5-Shot | 10-Shot | |||
| 4.3 | 13.3 | 20.9 | 33.0 | 48.8 | |||
| √ | 3.8 | 19.1 | 32.0 | 45.4 | 62.0 | ||
| √ | √ | 15.9 | 33.2 | 42.5 | 57.5 | 71.5 | |
| √ | √ | √ | 16.4 | 36.3 | 47.0 | 61.6 | 74.9 |
| FS-ft | SAM | BFS | mAP | ||
|---|---|---|---|---|---|
| 5-Shot | 10-Shot | 20-Shot | |||
| 17.7 | 28.1 | 41.9 | |||
| √ | 33.0 | 43.6 | 46.9 | ||
| √ | √ | 35.5 | 44.5 | 49.8 | |
| √ | √ | √ | 38.3 | 47.3 | 50.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; He, B.; Tong, M.; Wang, D.; He, C. Few-Shot Object Detection on Remote Sensing Images via Shared Attention Module and Balanced Fine-Tuning Strategy. Remote Sens. 2021, 13, 3816. https://doi.org/10.3390/rs13193816
Huang X, He B, Tong M, Wang D, He C. Few-Shot Object Detection on Remote Sensing Images via Shared Attention Module and Balanced Fine-Tuning Strategy. Remote Sensing. 2021; 13(19):3816. https://doi.org/10.3390/rs13193816
Chicago/Turabian StyleHuang, Xu, Bokun He, Ming Tong, Dingwen Wang, and Chu He. 2021. "Few-Shot Object Detection on Remote Sensing Images via Shared Attention Module and Balanced Fine-Tuning Strategy" Remote Sensing 13, no. 19: 3816. https://doi.org/10.3390/rs13193816