1. Introduction
Synthetic aperture radar (SAR) is an important method for Earth observation sensors with a wide range of applications [
1]. Among the many applications of SAR, automatic target recognition (ATR) technology is a critical means of SAR image interpretation [
2,
3,
4]. ATR technology has been greatly improved during the past decade because of the vigorous development of machine learning algorithms.
Among machine learning algorithms, feature extraction and classifier algorithms have made the most significant contributions. Feature extraction algorithms, including principal component analysis [
5,
6,
7], non-negative matrix factorization [
8], and linear discriminant analysis [
9,
10], can extract numerous features with discriminative information. The support vector machine (SVM) [
11,
12] has successfully maximized the target classification margin by selecting support vectors, and it has also had great success in ATR technology. In addition, the popularity of deep learning algorithms has risen due to their significant advantages when applied to recognition techniques. Based on the inspiration of AlexNet, Kechagias-Stamatis et al. proposed a high-performance SAR ATR model, which demonstrated excellent performance [
13]. Pei et al. utilized deep neural networks for multi-view SAR ATR [
14], and Zhang et al. extended deep neural networks to the field of character recognition [
15].
Unfortunately, all of the aforementioned algorithms are data-driven methods, which often rely on the size of the dataset [
16]. Generally speaking, the performance of state-of-the-art ATR algorithms is acceptable in scenarios where sufficient SAR target samples are available for training the recognition model [
17]. However, the assumption of sufficient SAR target samples is not always satisfied when the above methods are adopted to solve SAR ATR tasks. Therefore, the above algorithms are difficult to achieve the desired performance under this premise. In general, the purpose of the ATR model is to minimize the expected risk of the recognition result to the target sample set. Since the posterior probability cannot be easily obtained, the ATR model usually obtains an empirical risk from the training sample set to replace it. However, the small sample dataset must be incomplete, and the empirical risk for a small sample dataset cannot be equated to the empirical risk for a complete dataset, which leads to misrecognition of certain target samples by the ATR model. In addition, this is a problem that the above data-driven algorithms cannot avoid. It is necessary to establish a method that can apply the ATR model even when the number of SAR target samples is insufficient.
There are usually two kinds of methods to solve the problem of insufficient SAR target samples [
18]. First, it is feasible to develop an algorithm that can effectively extract SAR target sample features from extremely limited datasets. In this regard, the extensive application of transfer learning in the field of optics provides an alternative approach [
19,
20]. Huang et al. utilized the transfer learning method to perform ATR with limited labeled SAR target samples, but the method still uses other unlabeled SAR target sample information [
21]. However, pre-training large-scale neural networks using homogeneous datasets is a challenge when implementing actual SAR ATR tasks. Second, an effective and direct approach would be to increase the size of the SAR target sample dataset by generating more data. This type of method is more suitable for situations involving extremely limited SAR target sample datasets without other information sources. A common method of increasing the size of the SAR target sample dataset is data augmentation, such as rotation, flipping, or random cropping. However, the algorithms involved always apply geometric transformations to expand the size of the dataset. Geometric transformations cannot improve the data distribution determined by high-level features, as they only lead to an image-level transformation through depth and scale [
22]. Therefore, these methods still fail to improve the performance of the SAR ATR model to an acceptable level under the condition of a small sample set.
In recent years, a variety of methods for improving the performance of the ATR model using generated data has been proposed. Malmgren et al. used simulated SAR target samples through data augmentation to improve the performance of ATR models by transfer learning [
23]. Zhong et al. also utilized data augmentation to perform person re-identification with a small sample set [
24]. Guo et al. proposed an innovative simulation technology based on generative adversarial networks (GANs), which was proposed to address the lack of accuracy of computer-aided drawing (CAD) models [
25]. The rapid development of GANs has led to an increasing number of applications in SAR ATR in the past few years. Gao et al. used the discriminator of deep convolutional generative adversarial networks (DCGAN) to implement the ATR task [
26]. Schwegmann et al. proposed information maximizing generative adversarial networks (InfoGAN) to perform SAR ship recognition [
27]. Although previous studies on GANs have addressed the performance of semi-supervised learning in the recognition task, research has yet to explore whether the generated SAR target samples can be moved from the generation architecture and used in other available ATR frameworks [
28]. Cui et al. used a label-free SAR target sample generation method to increase the size of a small sample set. However, it is time intensive to label a large number of unlabeled target samples [
29]. Choe et al. sought to address this issue in the field of optics by utilizing the generated samples to solve face recognition problems with a small sample set [
18]. Tang et al. also used generated samples to implement person re-identification [
30]. All of the aforementioned literature has proven the boundless potential of GANs in relation to the SAR ATR task.
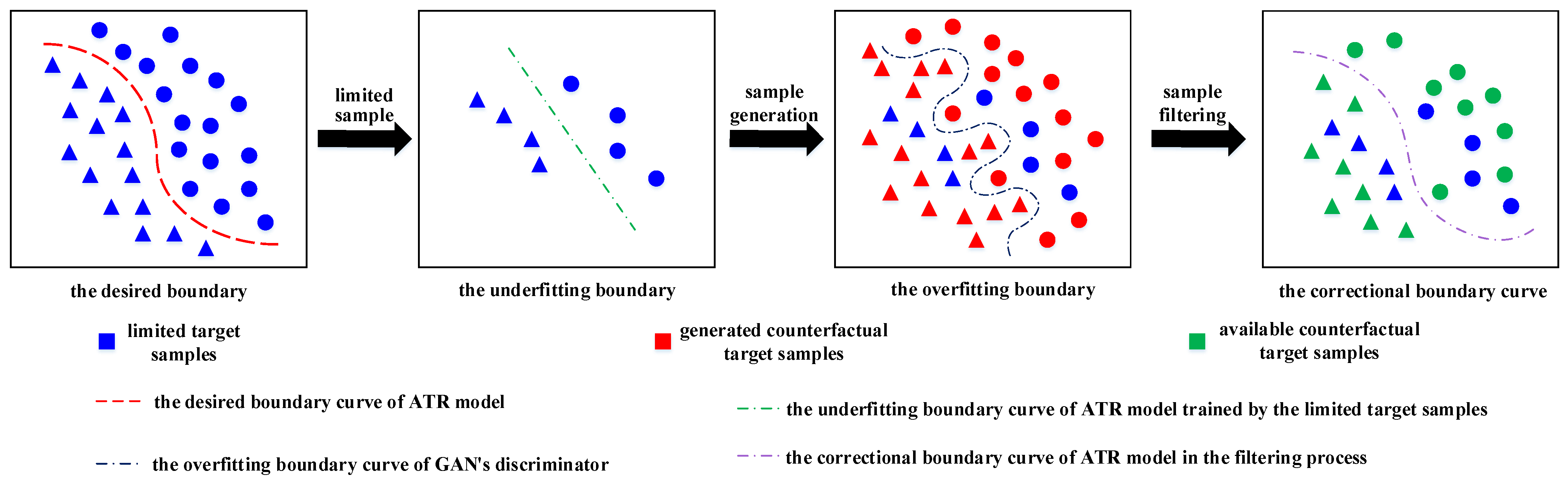
However, when GANs-based methods were used to generate SAR target samples, it is easy to create a counterfactual target sample due to the characteristics of SAR target data. This interesting phenomenon is shown in
Figure 1. As shown in
Figure 1, despite the fact that some generated sample looks no different from the real target sample, it may cause a significant decrease in the performance of the ATR model. We refer to such target samples as counterfactual samples in this paper. The effect of counterfactual target sample on the ATR model may be opposite to the effect perceived by the naked eye.
It means that the target samples generated by the GANs-based method cannot be directly used for the training of the ATR model. The generated target samples may damage the performance of the ATR model if the generated samples are not filtered. Although optical imagery has been successful in applying generated sample sets in other frameworks, the interpretability of SAR images is poorer than that of optical images, which increases the difficulty of using the SAR ATR model with small sample sets. Zhang et al. used a pre-filtering method to address the low interpretability problem with generated SAR target samples and demonstrated the necessity for pre-filtering these samples [
31]. However, the premise of this pre-filtering method is still based on the assumption that many training samples are available, which is contrary to the assumption of the SAR ATR model with a small sample set. This shows that the current pre-filtering method has certain limitations for target samples generated by small sample sets. At the same time, it also means that some counterfactual samples that do not look the same as real samples were also ignored in the previous pre-filtering work. Moreover, there is little relevant research paying attention to the filtering of generated samples at present, especially for the filtering of counterfactual samples.
In this paper, we focus on solving the small sample set problem in the SAR ATR model via a counterfactual target sample. An integrated counterfactual sample generation and filtering approach is proposed to alleviate the impact of a small sample set. Counterfactual samples are target samples that can reasonably expand the data space and are difficult to find in the real world. The proposed method makes full use of the overfitting characteristics of GANs, which ensures the generation of counterfactual target samples. Then, the generated counterfactual samples that are beneficial to the ATR model are filtered by learning different ATR functions. As the proposed method continuously generates counterfactual target samples, it can also dynamically improve the recognition performance of the ATR model. More importantly, the proposed method adopts an innovative way of using generated counterfactual target samples, which significantly improves the recognition performance of the SAR ATR model under the condition of a small sample set.
3. The Proposed Approach
3.1. Some Important Motivations about the Proposed Approach
General recognition algorithms tend to suffer from the problem of overfitting when the size of the training set is too small. The GAN is a complex model composed of a deconvolution network and a convolution network. When GANs are trained with limited samples, their risk of overfitting is likely to increase. Conversely, an ATR model with lower complexity trained with limited samples is prone to underfitting. Therefore, the motivation for implementing the proposed approach is introduced in this subsection. An interesting aspect of the proposed approach is that it takes advantages of the GANs tendency to overfit a small sample set to solve the limited samples problem.
Figure 2 illustrates the above concept to provide an easier understanding.
GANs encounter overfitting, which means that the boundary curve of
D is also overfitted under the condition of limited samples. The role of
D is to determine whether the target sample generated by
G is real or not. As shown in
Figure 2, when GANs overfit the data,
G generates some new samples, which include some counterfactual target samples. In addition,
D also treats these generated counterfactual samples as real target samples. Therefore, GANs generate counterfactual target samples that they considers to be real samples. However, GANs generate counterfactual target samples with more information by overfitting them, and the overfitting also introduces more redundancy and erroneous counterfactual samples.
The proposed generation model generates many counterfactual target samples with different discrimination information. This means that some of the counterfactual samples are beneficial to the ATR model, while others may be harmful. Overall, this is the inevitable cost of increasing the discrimination information. However, the proposed method is designed to use counterfactual target samples that are beneficial to the ATR model to improve the model performance. This reflects the necessity of filtering the counterfactual target samples. It is also the core idea of the proposed integrated method. First, we make full use of the advantages of generation model overfitting to obtain counterfactual samples with more redundant information. Next, we need to filter counterfactual samples that are beneficial to the ATR model to improve its recognition performance. Finally, the ATR model can utilize these filtered counterfactual samples to compensate for part of the discrimination information missing from the small sample set.
The feature extraction module is also another important motivation for developing the method presented in this manuscript. The proposed generation model generates a large number of counterfactual samples with redundant information. Therefore, the feature extraction module is different from the general feature extraction process, as it is more similar to a filtering process. The feature extraction module needs to constantly update the discrimination information that can be used to improve the ATR model from the generated redundant information. The significance of the feature extraction module can be explained in conjunction with the desired filtering process.
In the case of limited information, the recognition model needs more discrimination information to effectively improve performance. The proposed generation model generates counterfactual samples with other redundant information. However, the redundant information contains valid discrimination information and erroneous information. Therefore, the updated discrimination information is different from the information accumulated after the sample gradually increases. It includes information filtering and information accumulation simultaneously. However, the feature extraction module cannot be independent of the proposed framework. The update of discriminant information requires the following steps to be realized: feature extraction→recognition→verification→selection→feature extraction. As shown in
Figure 1, we use limited information to continuously train a new recognition model under the premise of utilizing different counterfactual samples. Although not all of these new ATR models learn the correct information, they can learn more discriminant information than the original model. The recognition models with more discriminative information can provide samples with higher-confidence recognition results. According to the recognition result, we rely on the proposed verification and selection strategy to obtain reliable counterfactual samples. Then, we realize the feature selection and feature accumulation of the counterfactual samples in this process. Finally, we move the correctional boundary curve of the ATR model closer to the desired boundary curve by using different counterfactual samples. The detailed architecture of the proposed method is introduced in the rest of this section.
3.2. The Generation of Counterfactual Target Samples
According to the aforementioned information, the proposed generation model should have the ability to stably generate counterfactual target samples by category. Any target sample input to
D may come from the real SAR target sample distribution
or the generated sample distribution
. Moreover, the discriminator usually uses cross-entropy loss to calculate the loss of target samples from the two distributions. Therefore, the contribution of any sample to the generation model is as follows:
assume that the derivative of Equation (
5) with respect to
is 0. Then, the optimal discriminator
is obtained as follows:
when the discriminator of the GANs is trained to reach the optimal status, the optimal discriminator is substituted into Equation (
2). Then, the loss function of the GANs is transformed into the following form:
At this time, the generation of SAR target samples is transformed into the problem of minimizing the Jensen-Shannon divergence between
and
. When the support set of
and
is a low-dimensional manifold in a high-dimensional space, the probability that the measure of the overlap between
and
is 0 is 1 [
35]. Moreover, the support set of
and
is obviously a low-dimensional manifold in X-dimensional space, where X is the number of pixel space dimensions of the target sample. Therefore,
and
barely overlap. The Jensen-Shannon divergence between
and
is
if
and
barely overlap, and this phenomenon often occurs in real ATR tasks. At this moment, it is worthless to utilize the optimization algorithm to derive a constant at. It is also easy to understand the reason that GANs cannot stably generate counterfactual target samples during the generation of the SAR target sample.
Therefore, the loss function of the generation model utilizes the Wasserstein distance to replace the Jensen-Shannon divergence as a distance measurement between
and
. The loss function of the generation model is formulated as follows:
where
means that Equation (
8) is established when the Lipschitz constant
of
D does not exceed the constant
K. The parameters of
D are represented by
.
Moreover, although the selection of the Wasserstein distance measurement prevents the occurrence of a collapse mode, it still exposes the generation model to the risk of the gradient explosion problem. Therefore, the proposed generation model also needs to impose the 1-Lipschitz gradient penalty constraint on the Wasserstein distance. Then, the loss function of the generation model is formulated as follows:
where
is calculated by
, and
is a gradient penalty constant. Thus far, the proposed generation model can stably generate counterfactual target samples.
In addition, the proposed generation model also needs to generate counterfactual samples by category. This means that the proposed generation model also needs to use category information during the generation process. Therefore, the loss function adopted in the proposed generation model is formulated as follows:
where the target category information is represented by
y.
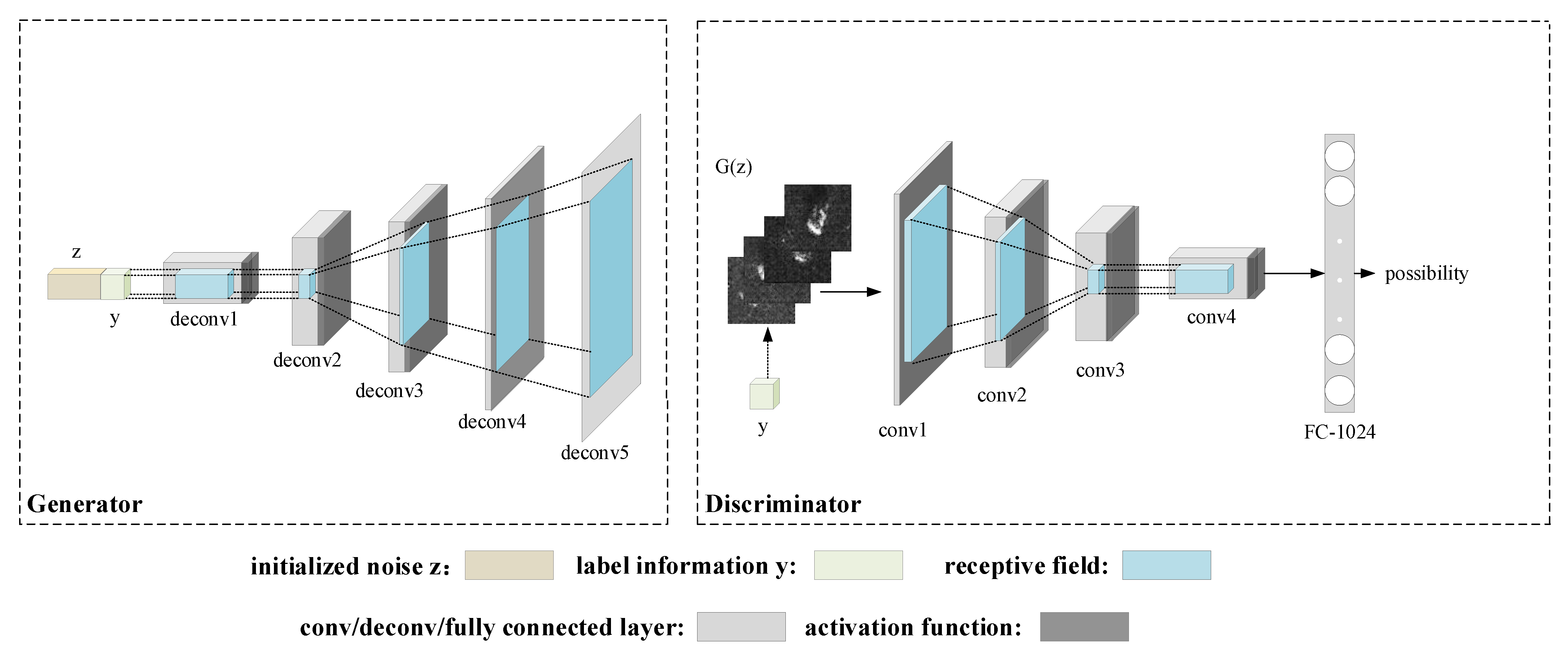
Next, the proposed architecture of the generation model is explained. The architecture overview of the proposed generation model is shown in
Figure 3. The generator only consists of deconvolution layers, and no fully connected or pooling layers are utilized in
G. Moreover, strided deconvolutions are used to replace the pooling layer to ensure that the generation model can generate images and of the correct size. The discriminator is composed of several convolutional layers and a fully connected layer. The fully connection layer is used to replace the sigmoid function in the last layer. Moreover, the original GANs utilizes the sigmoid function to judge whether or not the SAR target sample is real. However, the purpose of the discriminator in the proposed generation model has been changed to minimize the Wasserstein distance between
and
. Therefore, it is reasonable to remove the sigmoid function for solving regression tasks.
3.3. The Filtering of Counterfactual Target Samples
The proposed generation model can stably generate counterfactual target samples by category. However, merely generating counterfactual samples cannot alleviate the difficulty in the SAR ATR model when it encounters a small sample set. The proposed generation model generates many counterfactual target samples with more discrimination information. It is worth noticing that the counterfactual samples with more discrimination information are obtained by the GANs overfitting a small sample set. Therefore, the proposed method also needs to be able to filter the counterfactual target samples that are beneficial to the ATR model. Moreover, the proposed filtering method needs to conform to the premise of a small sample set. By implementing the generation and filtering of counterfactual samples simultaneously, it becomes feasible to improve the performance of the ATR model through counterfactual target samples.
Though the counterfactual target samples are generated by the proposed generation model, the problem of using the SAR ATR model with a small sample set is not solved immediately. Among the generated counterfactual samples, some samples may improve the performance of the ATR model, and others may degrade it. At this time, the difficulty in the SAR ATR model with a small sample set is transformed into the following problem: a large number of counterfactual target samples and a small number of real SAR target samples are used to train the ATR model, where the counterfactual SAR target samples require filtering. In other words, all generated counterfactual samples that have been labeled need to be relabeled. Fortunately, the co-training algorithm uses a small number of labeled samples and a large number of unlabeled samples to improve the performance of the recognition model.
When the co-training algorithm is used to improve the performance of the ATR model, its strict constraints on the dataset cannot be ignored. Therefore, it is necessary to use the existing dataset to construct application scenarios for the co-training algorithm. First, the SAR target sample data are generally recognized from the pixel perspective. Thus, it is difficult for the existing dataset to meet the co-training algorithm’s requirement of two “views”. At this point, the proposed filtering approach needs to manufacture differences between multiple weak ATR models to satisfy this requirement of co-training. Second, it is impossible to guarantee sufficient “view” information due to the influence of a small sample set. In other words, the different weak ATR models may result in the misrecognition of some SAR target samples, which is contrary to the premise that different views conform to the compatibility requirement. Therefore, the different weak ATR models need verification when they add pseudo-labels to the counterfactual target samples, which can alleviate the limitations of insufficient views. In this regard, the category information provided by the counterfactual target samples during the generation process can be used as verification.
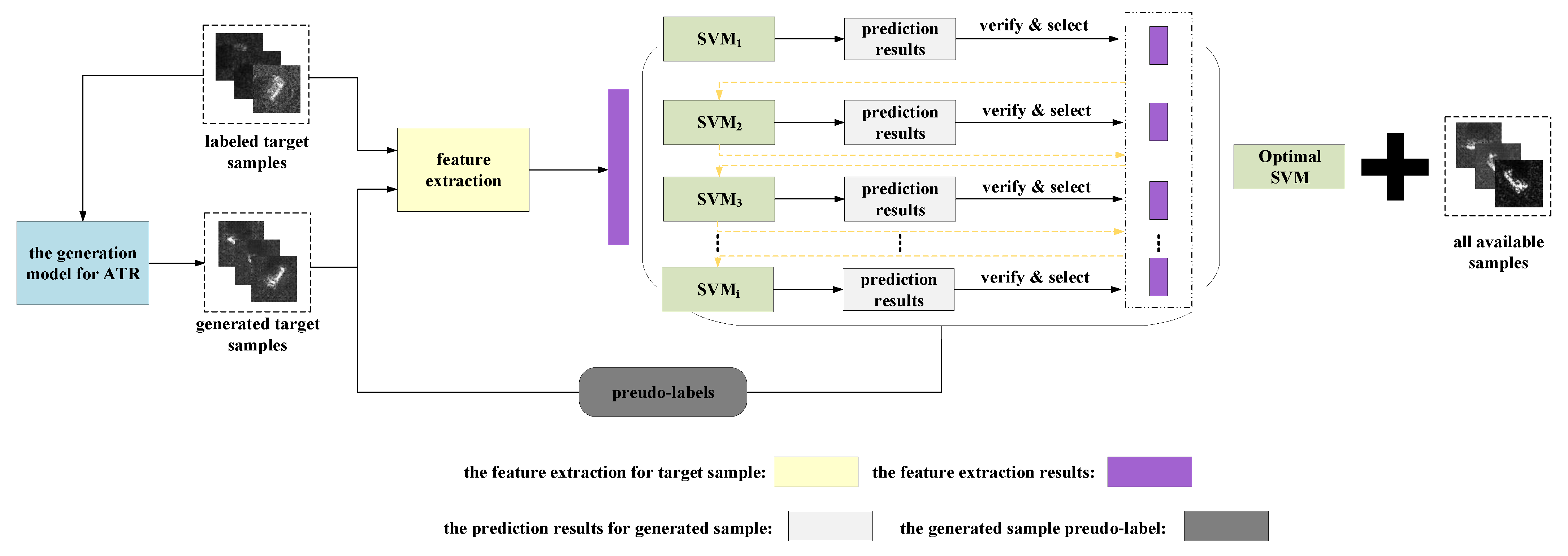
According to the above requirements, the architecture of the proposed generation model is shown in
Figure 4. The proposed approach integrates a generation model and a batch of SVMs for filtering. The generation model is capable of continuously generating counterfactual target samples and applying them to a subsequent filtering process. Then, a batch of SVMs is trained by different counterfactual target samples sets to manufacture the significant differences between them. The filtering process that utilizes and labels the counterfactual target samples is an important component of the proposed approach.
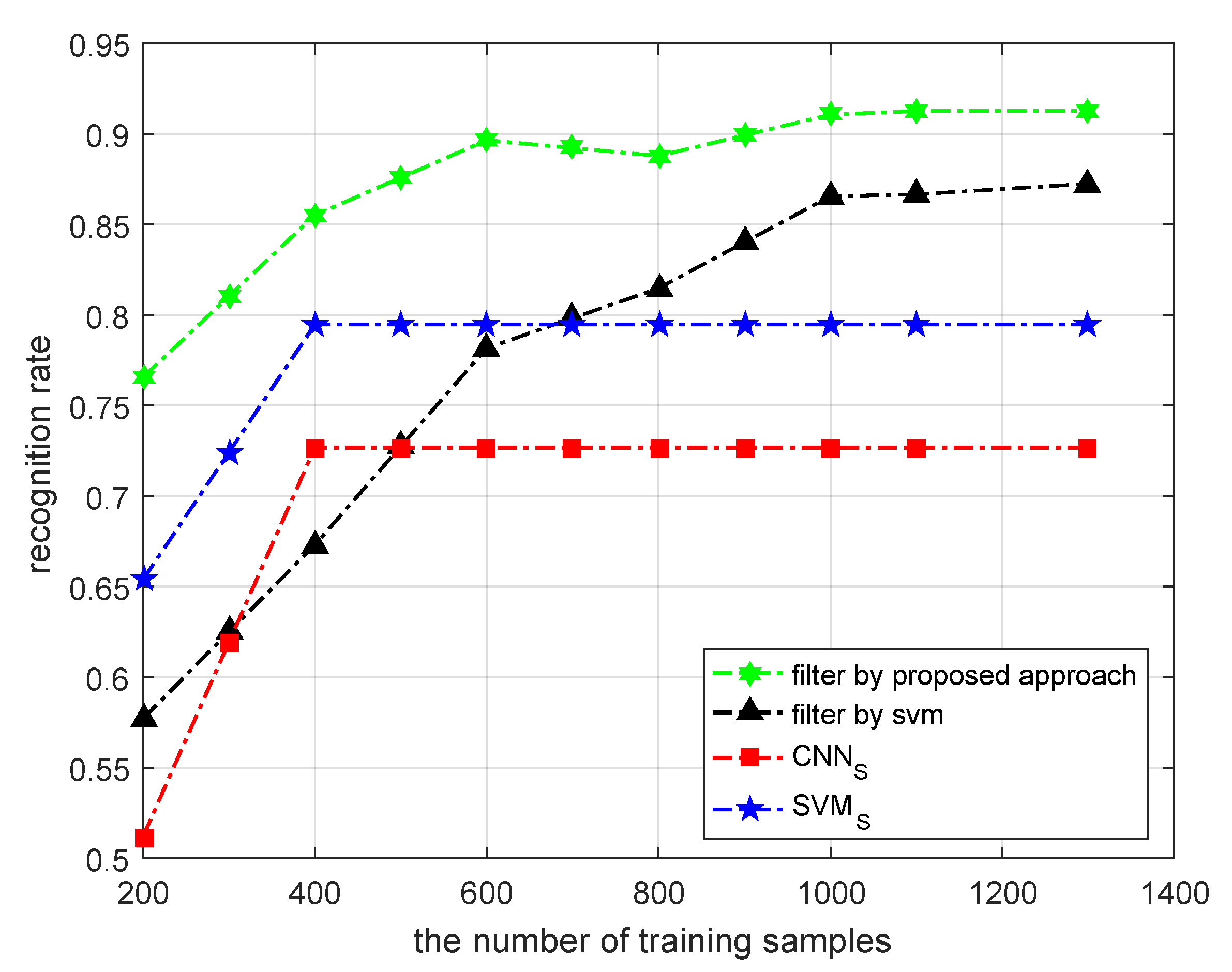
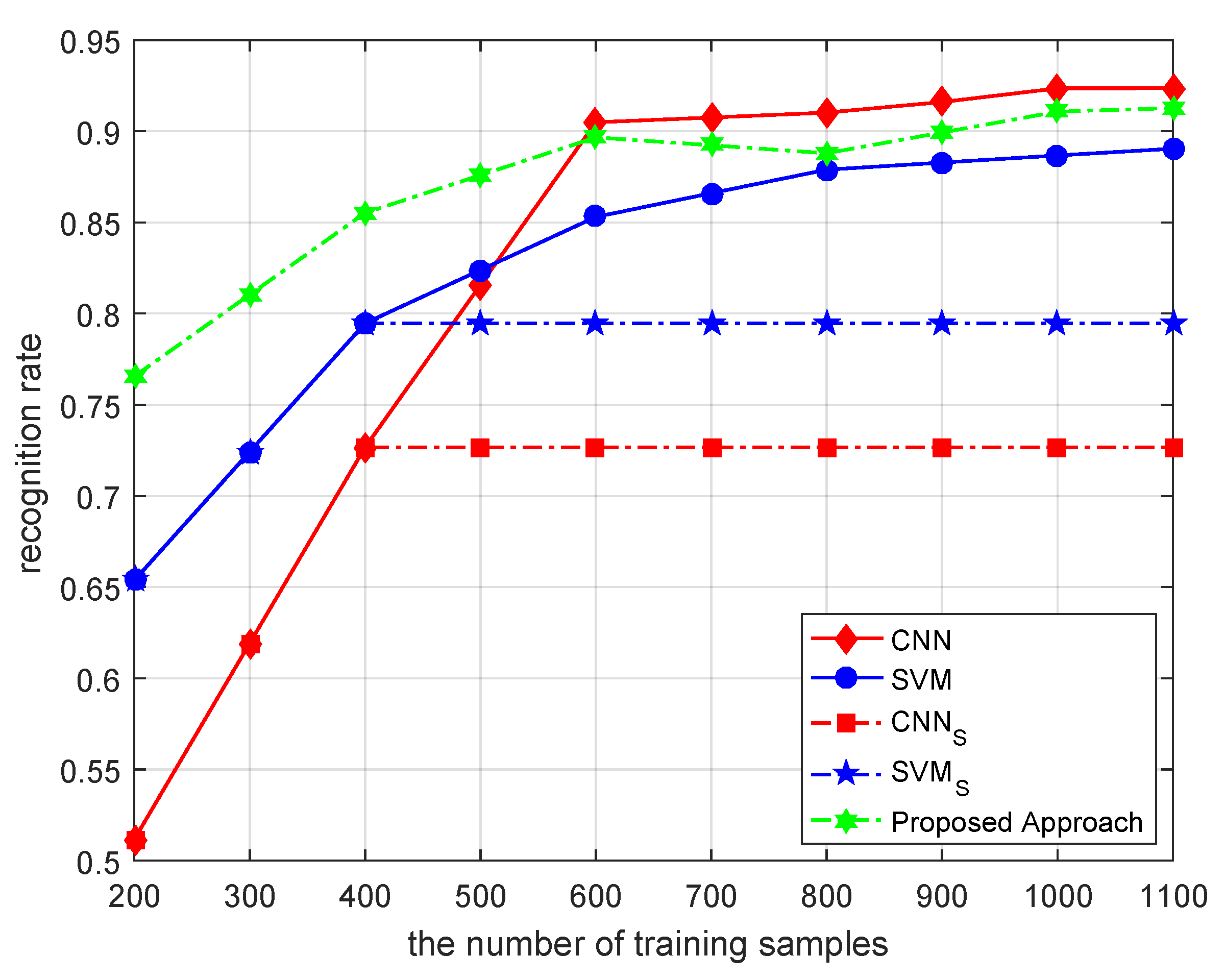
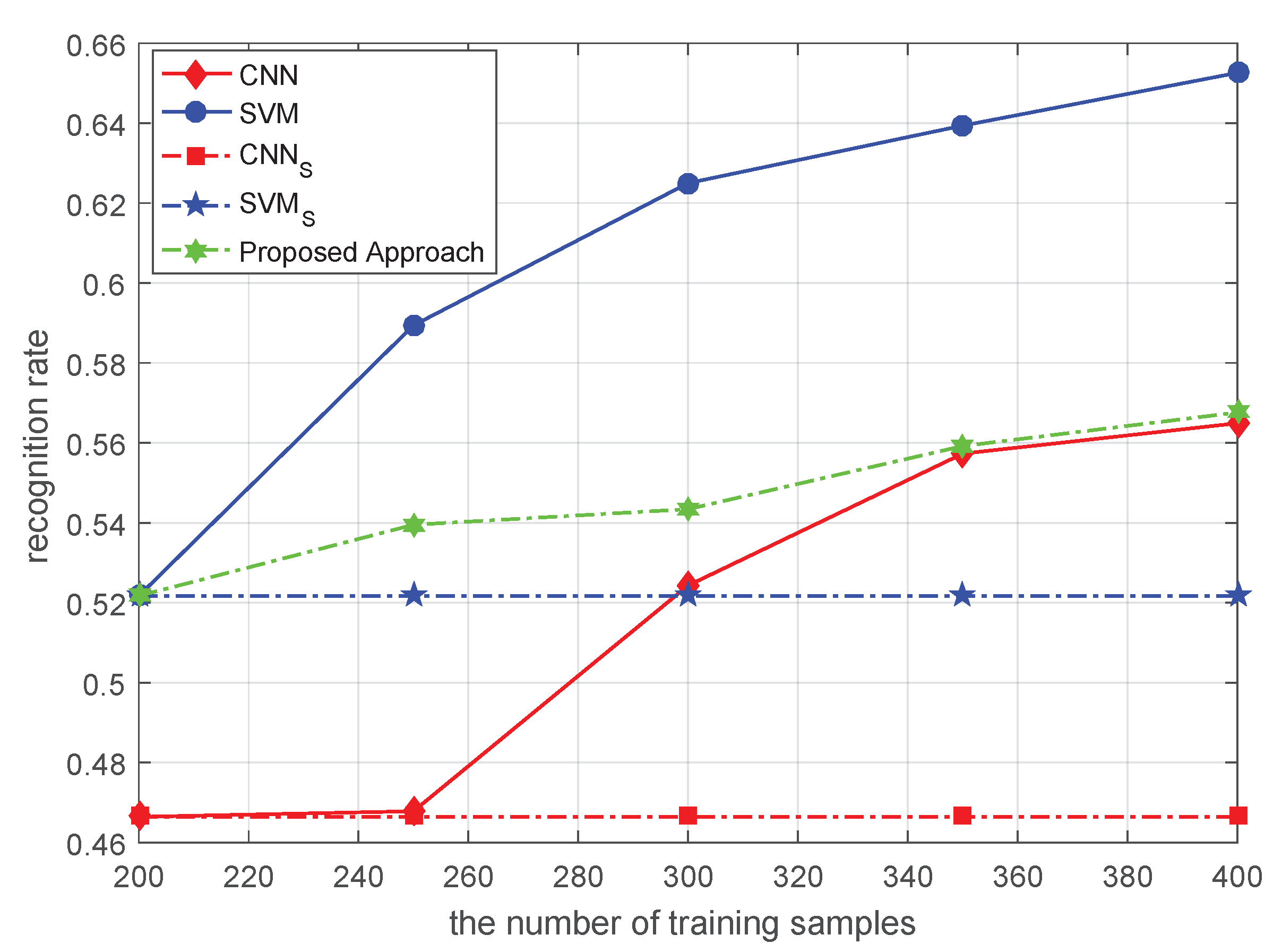
In a loop of the proposed filtering process, support vector machines are trained in order. However, different counterfactual target samples sets with pseudo-labels are not provided in order. The filtered counterfactual target samples are not the filter results of the last support vector machine. Regardless of whether the support vector machine or a filtered counterfactual target sample contain all of the knowledge accumulated during the iteration process, the previous SVM is first trained by the collected SAR target samples. Once the SVM is trained using the SAR target samples, it can filter the newly counterfactual target samples. Then, the filtered counterfactual target samples are used to update the existing training sample set, and the updated training sample set leads to the training of a new SVM. At this time, the new SVM can re-filter the previously filtered counterfactual target samples but not the original SAR target sample set, allowing it to be trained using a combination of the previous training sample set and the latest batch of filtered samples. Thus, the recognition performance of the new SVM is higher than that of the previous SVM. The re-filtering process also improves recognition performance. Once the SAR target samples are filtered, they enter the next loop of the proposed filtering process, or the re-filtering process, where both the SVM and the training SAR target sample set are gradually improved and refined. Finally, when the recognition rate of the SVM no longer significantly improves with the change in the counterfactual target samples set, the proposed filtering process ends all loops.
In a word, the essence of the filtering process of counterfactual target samples is the framework of the co-training algorithm. Just as the co-training algorithm relied on the discrimination information of unlabeled data, the proposed filtering component also relied on the discrimination information provided by the generated target samples. The proposed approach continuously produced counterfactual target samples by generation models, and manufactured the difference between any two SVMs, which laid a foundation for improving the performance of the recognition model. The proposed filtering process is also a double iteration process. The favorable counterfactual target samples set trains support vector machines to achieve better recognition performance. In turn, a support vector machine with stronger recognition performance can filter the favorable counterfactual target samples more accurately. The favorable counterfactual target samples and the performance of the recognition model are improved synchronously in the above iteration process.
It is necessary to provide a special explanation of how to verify and select the favorable counterfactual target samples during the filtering process. The new recognition models with more discrimination information provide the counterfactual target samples with higher-confidence recognition results. However, under the condition of limited information, the discrimination information of the ATR model is only increased compared with the information before updating. In other words, the discrimination information possessed by the recognition model is still insufficient. The recognition model still faces the risk of making mistakes when it filters favorable counterfactual target samples. From the co-training algorithm perspective, the current dilemma is a single “view” training problem with insufficient information. In this regard, the proposed approach needs to verify the recognition results to alleviate the difficulty of insufficient discrimination information in the ATR model. At this time, the condition information used to generate the model also plays a verification role. There is no threshold comparison during the proposed filtering process. Such counterfactual target samples can only be selected to update the feature when the recognition results of counterfactual target samples are consistent with the condition information of the generation model. Moreover, the filtered counterfactual target samples are filtered again after the ATR model is updated. Because the discrimination information of the ATR model gradually increases in the process of updating features, different ATR models may have different perceptions of the same batch of counterfactual target samples.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}