DR-Net: An Improved Network for Building Extraction from High Resolution Remote Sensing Image

Abstract
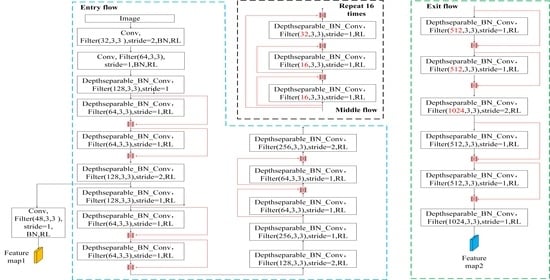
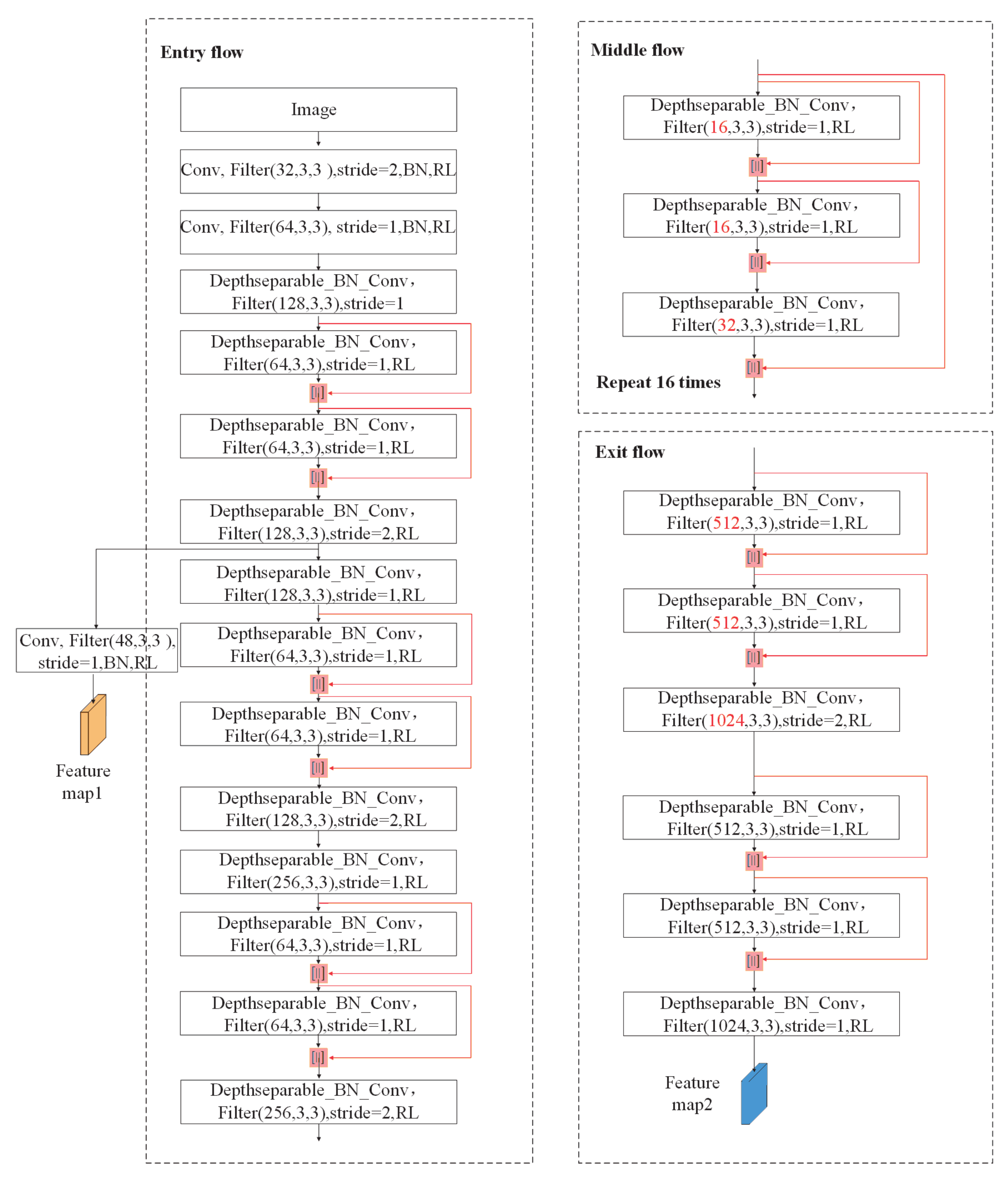
:
1. Introduction
2. Materials and Methods
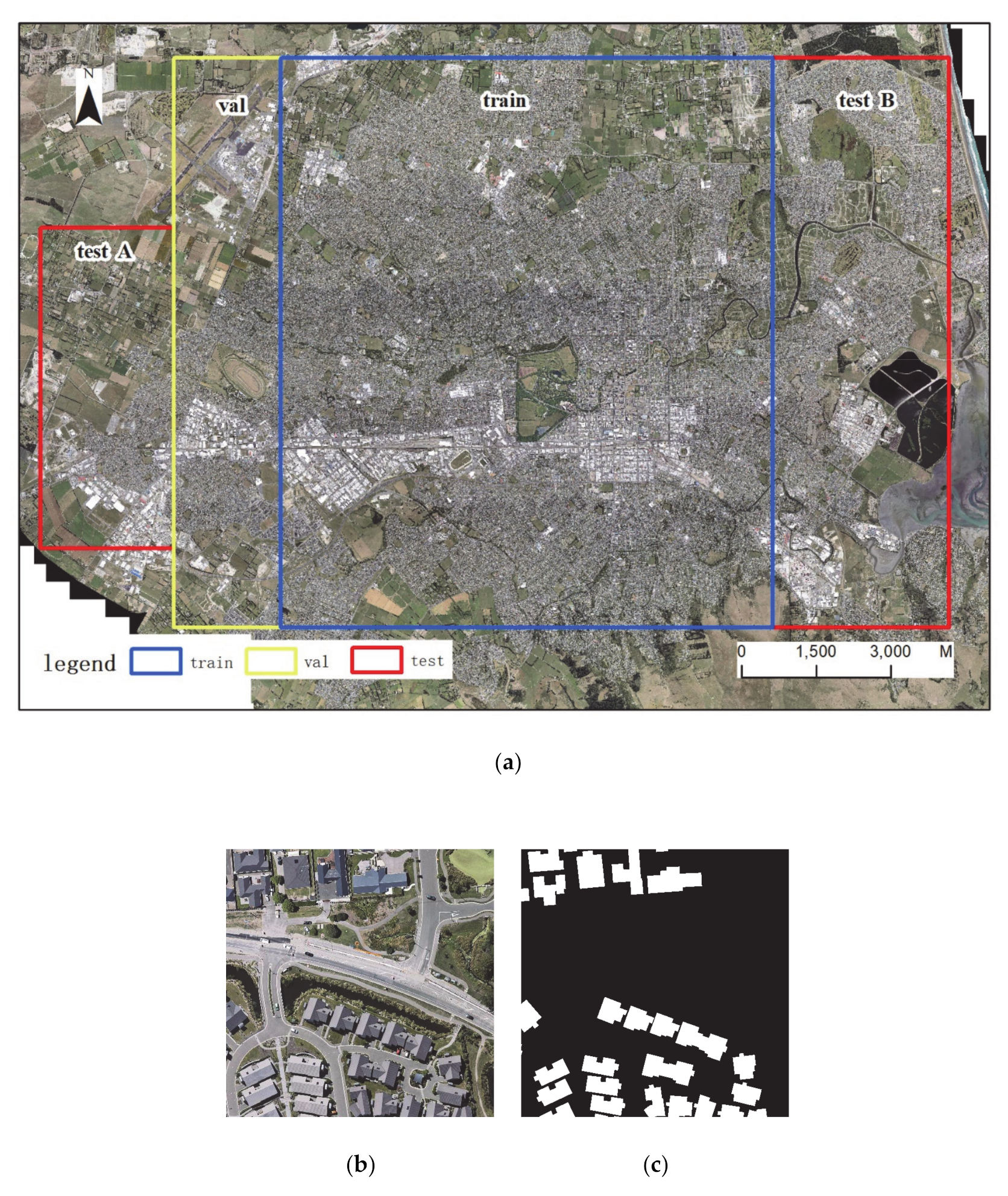
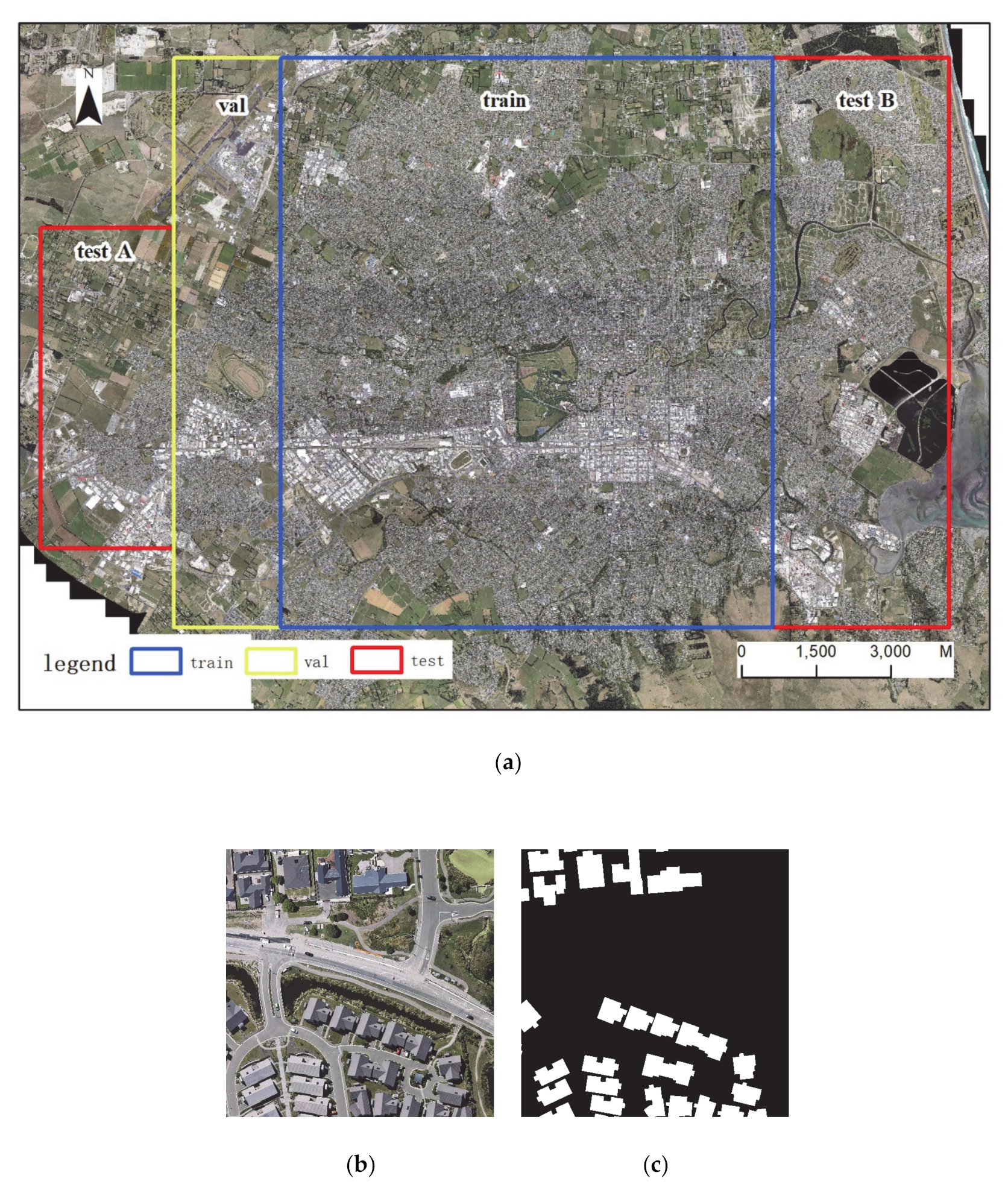
2.1. Data
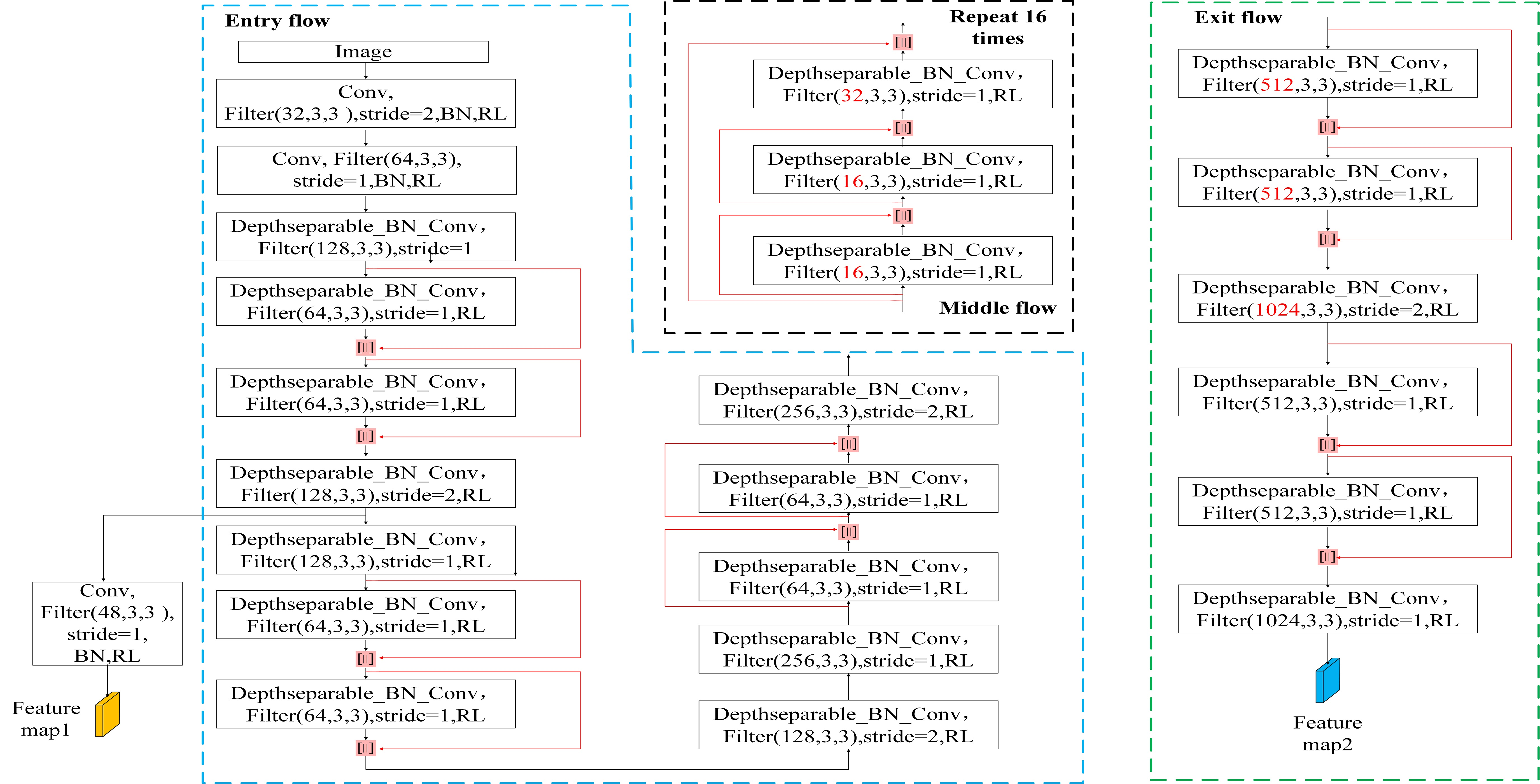
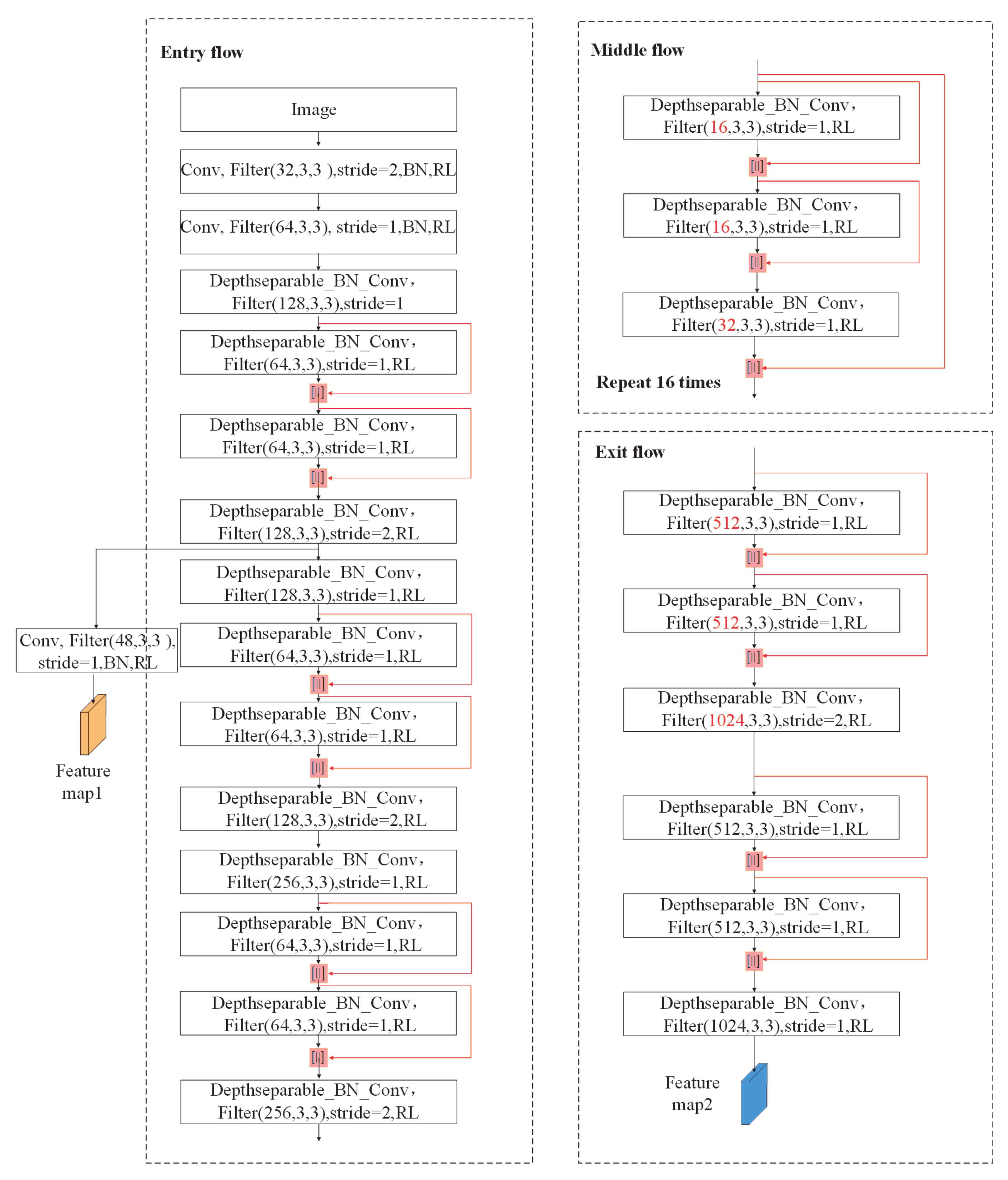
2.2. Densely Connected Neural Network
2.3. Residual Neural Network
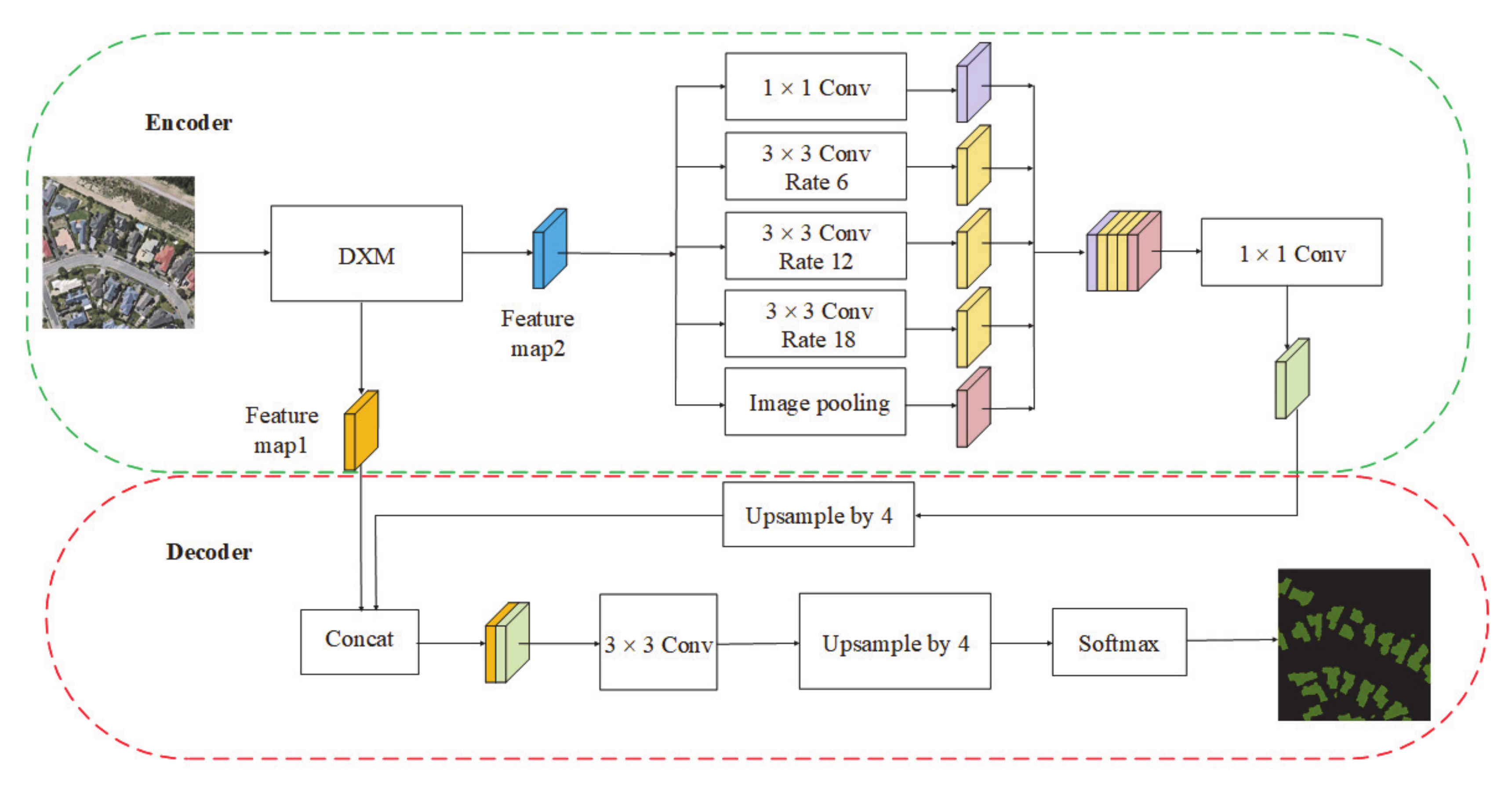
2.4. Dense Residual Neural Network
2.5. Loss Function
2.6. Evaluation Metrics
3. Experiments and Results
3.1. Experiment Setting
3.2. Comparison of Different Loss Functions
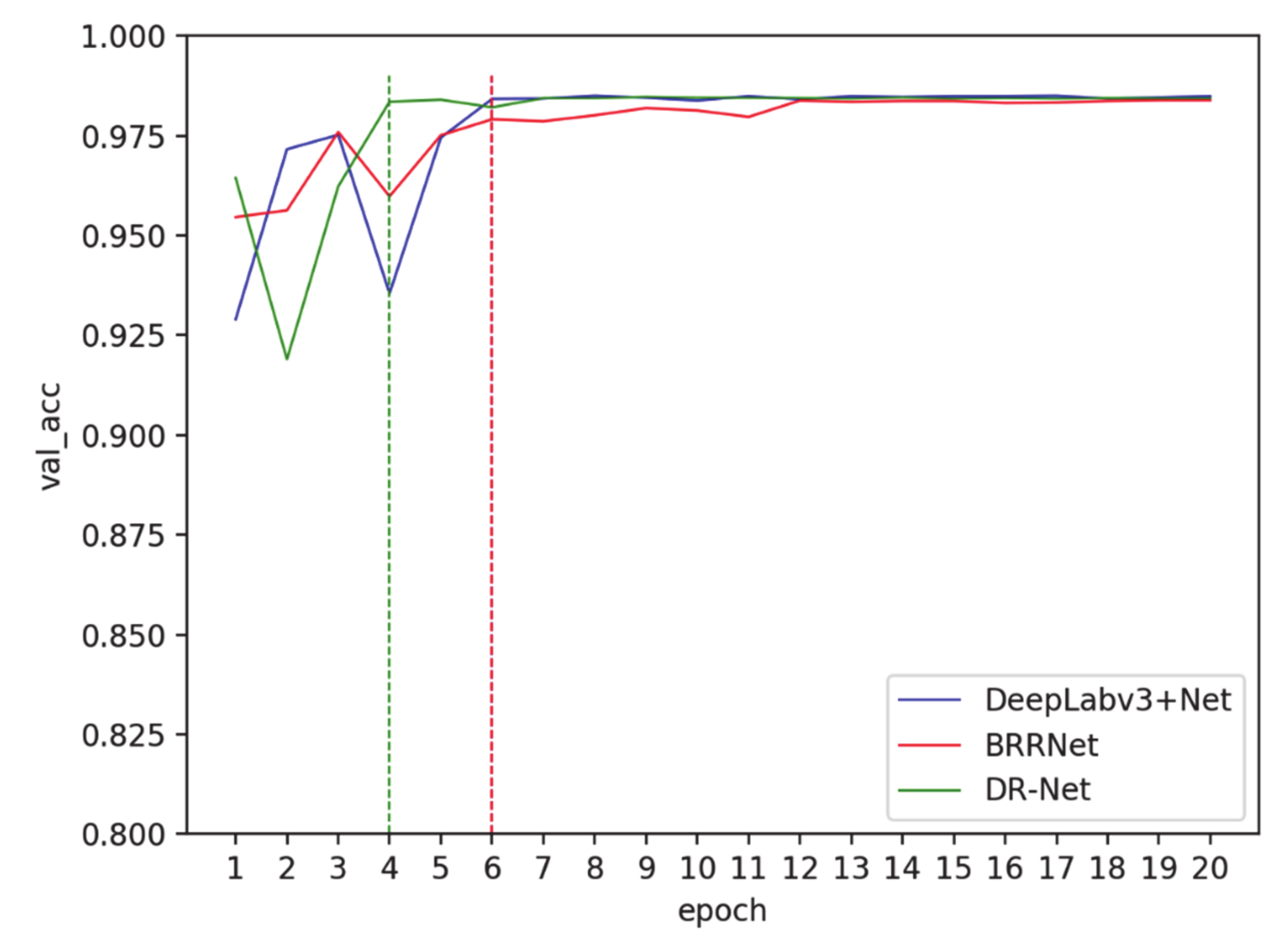
3.3. Comparison of Different Networks
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A




References
- Blaschke, T. Object based image analysis for remote sensing. J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Papandreou, G.; Kokkinos, I.; Savalle, P.-A. Modeling Local and Global Deformations in Deep Learning: Epitomic Convolution, Multiple Instance Learning, and Sliding Window Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 390–399. [Google Scholar]
- Dai, J.F.; Li, Y.; He, K.M.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Grauman, K.; Darrell, T. The pyramid match kernel: Discriminative classification with sets of image features. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; pp. 1458–1465. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z.H. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Ball, J.; Anderson, D.; Chan, C.S. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 042609. [Google Scholar] [CrossRef] [Green Version]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Gupta, S.; Girshick, R.; Arbelaez, P.; Malik, J. Learning rich features from rgb-d images for object detection and segmentation. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Zurich, Switzerland; pp. 345–360. [Google Scholar]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. An object-based convolutional neural network (ocnn) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Du, S.; Emery, W.J. Object-based convolutional neural network for high-resolution imagery classification. IEEE J. Sel. Top. Appl. Earth Observ. 2017, 10, 3386–3396. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building footprint extraction from high-resolution images via spatial residual inception convolutional neural network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef] [Green Version]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.J.; Wu, L.L.; Tang, X.; Liu, F.; Zhang, X.R.; Jiao, L.C. Building extraction of aerial images by a global and multi-scale encoder-decoder network. Remote Sens. 2020, 12, 19. [Google Scholar] [CrossRef]
- Liu, Y.H.; Gross, L.; Li, Z.Q.; Li, X.L.; Fan, X.W.; Qi, W.H. Automatic building extraction on high-resolution remote sensing imagery using deep convolutional encoder-decoder with spatial pyramid pooling. IEEE Access 2019, 7, 128774–128786. [Google Scholar] [CrossRef]
- Liu, H.; Luo, J.; Huang, B.; Hu, X.; Sun, Y.; Yang, Y.; Xu, N.; Zhou, N. De-net: Deep encoding network for building extraction from high-resolution remote sensing imagery. Remote Sens. 2019, 11, 2380. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. Brrnet: A fully convolutional neural network for automatic building extraction from high-resolution remote sensing images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef] [Green Version]
- Wei, S.; Ji, S.; Lu, M. Toward automatic building footprint delineation from aerial images using cnn and regularization. IEEE Trans. Geosci. Remote Sensing 2020, 58, 2178–2189. [Google Scholar] [CrossRef]
- Liu, Y.H.; Zhou, J.; Qi, W.H.; Li, X.L.; Gross, L.; Shao, Q.; Zhao, Z.G.; Ni, L.; Fan, X.W.; Li, Z.Q. Arc-net: An efficient network for building extraction from high-resolution aerial images. IEEE Access 2020, 8, 154997–155010. [Google Scholar] [CrossRef]
- Yi, Y.N.; Zhang, Z.J.; Zhang, W.C.; Zhang, C.R.; Li, W.D.; Zhao, T. Semantic segmentation of urban buildings from vhr remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 19. [Google Scholar] [CrossRef] [Green Version]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Ye, Z.; Fu, Y.; Gan, M.; Deng, J.; Comber, A.; Wang, K. Building extraction from very high resolution aerial imagery using joint attention deep neural network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef] [Green Version]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Semantic segmentation on remotely sensed images using an enhanced global convolutional network with channel attention and domain specific transfer learning. Remote Sens. 2019, 11, 83. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.P.; Wei, S.Q.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sensing 2019, 57, 574–586. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollar, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Sudre, C.H.; Li, W.Q.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised Dice overlap as a deep learning loss function for highly unbalanced segmentations. arXiv 2017, arXiv:1707.03237. [Google Scholar]
- Drozdzal, M.; Vorontsov, E.; Chartrand, G.; Kadoury, S.; Pal, C. The Importance of Skip Connections in Biomedical Image Segmentation. arXiv 2016, arXiv:1608.04117. [Google Scholar]
- Novikov, A.A.; Lenis, D.; Major, D.; Hladuvka, J.; Wimmer, M.; Buhler, K. Fully convolutional architectures for multiclass segmentation in chest radiographs. IEEE Trans. Med. Imaging 2018, 37, 1865–1876. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5229–5238. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Recall | Precision | IoU | |
|---|---|---|---|---|
| DR-Net and celoss | 0.907 | 0.943 | 0.860 | 0.925 |
| DR-Net and dice loss | 0.922 | 0.927 | 0.860 | 0.925 |
| Methods | Batch size | Recall | Precision | IoU | |
|---|---|---|---|---|---|
| BRRNet | 1 | 0.913 | 0.935 | 0.859 | 0.924 |
| Deeplbv3+Net | 1 | 0.911 | 0.923 | 0.858 | 0.923 |
| DR-Net | 1 | 0.922 | 0.927 | 0.860 | 0.925 |
| Deeplabv3+Net | DR-Net | BRRNet | |
|---|---|---|---|
| Total params (million) | 41 | 9 | 17 |
| Time (min/epoch) | 45 | 37 | 68 |
| Epochs | 11 | 9 | 12 |
| Method | Batch size | Recall | Precision | IoU | |
|---|---|---|---|---|---|
| DR-Net and dice loss | 2 | 0.933 | 0.943 | 0.883 | 0.938 |
| Methods | Batch Size | WHU Data | Massachusetts | ||
|---|---|---|---|---|---|
| IoU | IoU | ||||
| BRRNet and dice loss | 1 | 0.859 | 0.924 | 0.116 | 0.208 |
| Deeplabv3+Net and dice loss | 1 | 0.858 | 0.923 | 0.202 | 0.336 |
| DR-Net and dice loss | 1 | 0.860 | 0.925 | 0.112 | 0.201 |
| DR-Net and dice loss | 2 | 0.883 | 0.938 | 0.101 | 0.184 |
| Methods | Batch Size | Massachusetts | WHU Set | ||
|---|---|---|---|---|---|
| IoU | IoU | ||||
| BRRNet and dice loss | 1 | 0.579 | 0.733 | 0.401 | 0.572 |
| Deeplabv3+Net and dice loss | 1 | 0.614 | 0.761 | 0.389 | 0.561 |
| DR-Net and dice loss | 1 | 0.630 | 0.773 | 0.279 | 0.437 |
| DR-Net and dice loss | 2 | 0.660 | 0.795 | 0.288 | 0.447 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.; Wu, J.; Liu, L.; Zhao, W.; Tian, F.; Shen, Q.; Zhao, B.; Du, R. DR-Net: An Improved Network for Building Extraction from High Resolution Remote Sensing Image. Remote Sens. 2021, 13, 294. https://doi.org/10.3390/rs13020294
Chen M, Wu J, Liu L, Zhao W, Tian F, Shen Q, Zhao B, Du R. DR-Net: An Improved Network for Building Extraction from High Resolution Remote Sensing Image. Remote Sensing. 2021; 13(2):294. https://doi.org/10.3390/rs13020294
Chicago/Turabian StyleChen, Meng, Jianjun Wu, Leizhen Liu, Wenhui Zhao, Feng Tian, Qiu Shen, Bingyu Zhao, and Ruohua Du. 2021. "DR-Net: An Improved Network for Building Extraction from High Resolution Remote Sensing Image" Remote Sensing 13, no. 2: 294. https://doi.org/10.3390/rs13020294
APA StyleChen, M., Wu, J., Liu, L., Zhao, W., Tian, F., Shen, Q., Zhao, B., & Du, R. (2021). DR-Net: An Improved Network for Building Extraction from High Resolution Remote Sensing Image. Remote Sensing, 13(2), 294. https://doi.org/10.3390/rs13020294