
Detection of Abnormal Vibration Dampers on Transmission Lines in UAV Remote Sensing Images with PMA-YOLO


Abstract
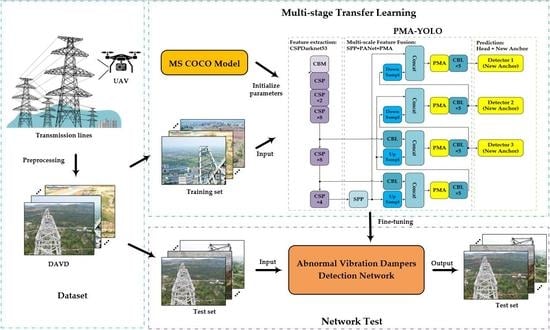
:
1. Introduction
- We constructed a data set of abnormal vibration dampers called DAVD using images of transmission lines obtained by UAVs. DAVD contains four types of vibration dampers: FD (cylindrical type), FDZ (bell type), FDY (fork type), and FFH (hippocampus type), and each vibration damper may be rusty, defective, or normal.
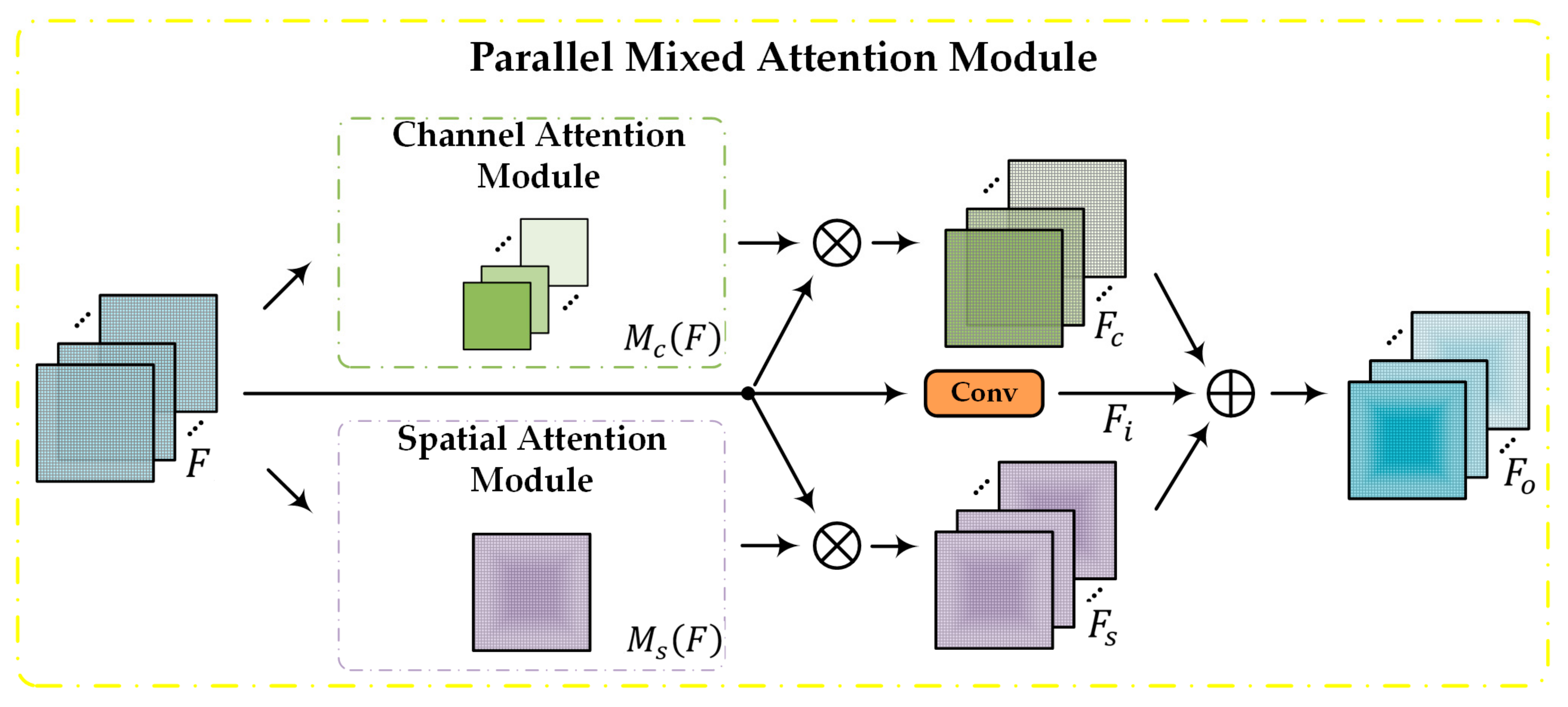
- We proposed a detection method for abnormal vibration dampers called PMA-YOLO. More specifically, we introduced and integrated a PMA module into YOLOv4 [14] to enhance the critical features of abnormal vibration dampers in images with complex backgrounds. This module combined a channel attention block, a spatial attention block, and the convolution results from the input feature map in parallel. In addition, given the small sizes of abnormal vibration dampers in images, we used the K-means algorithm to re-cluster the new anchors for abnormal vibration dampers, which reduced the rate of missed detection.
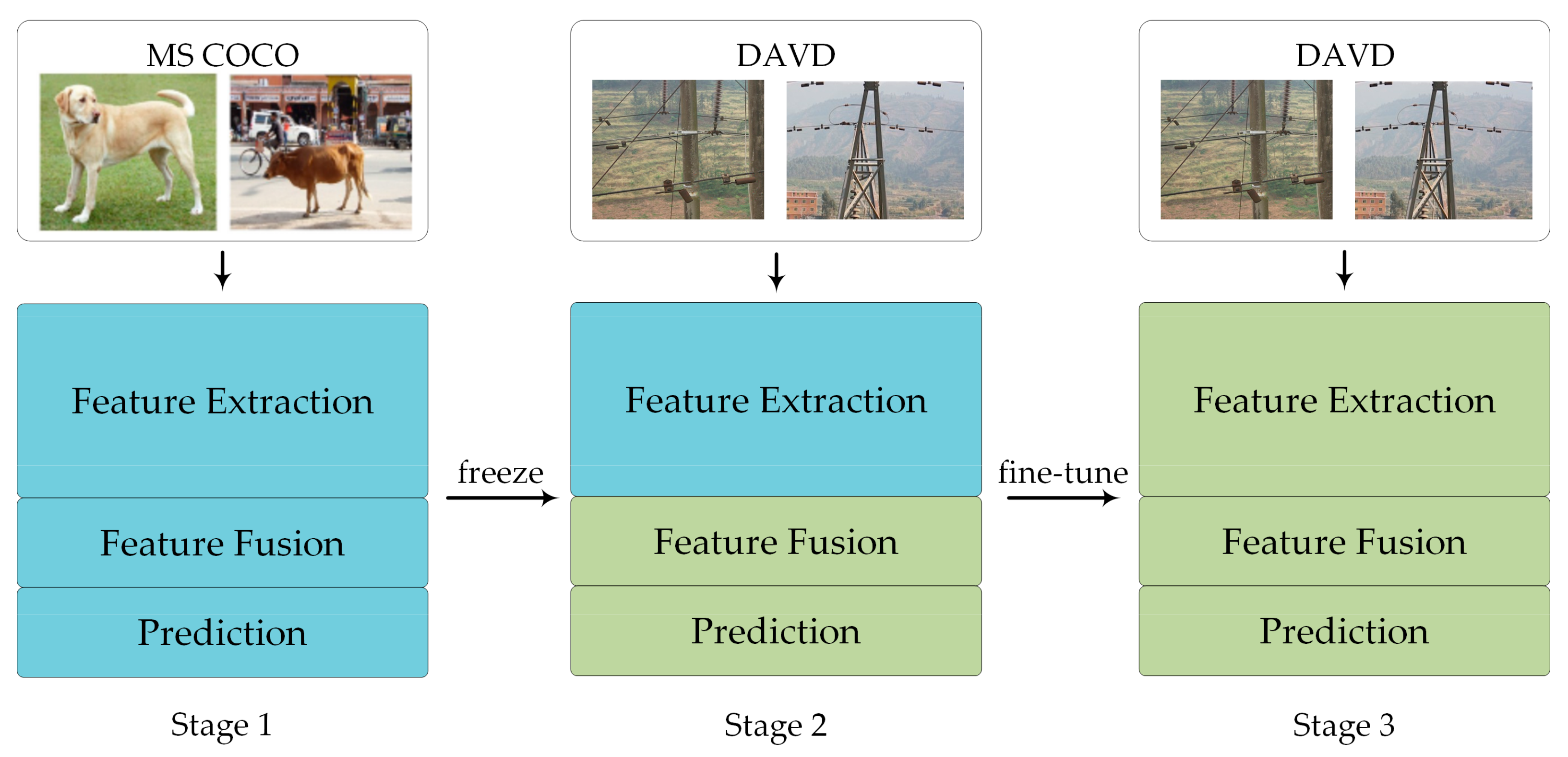
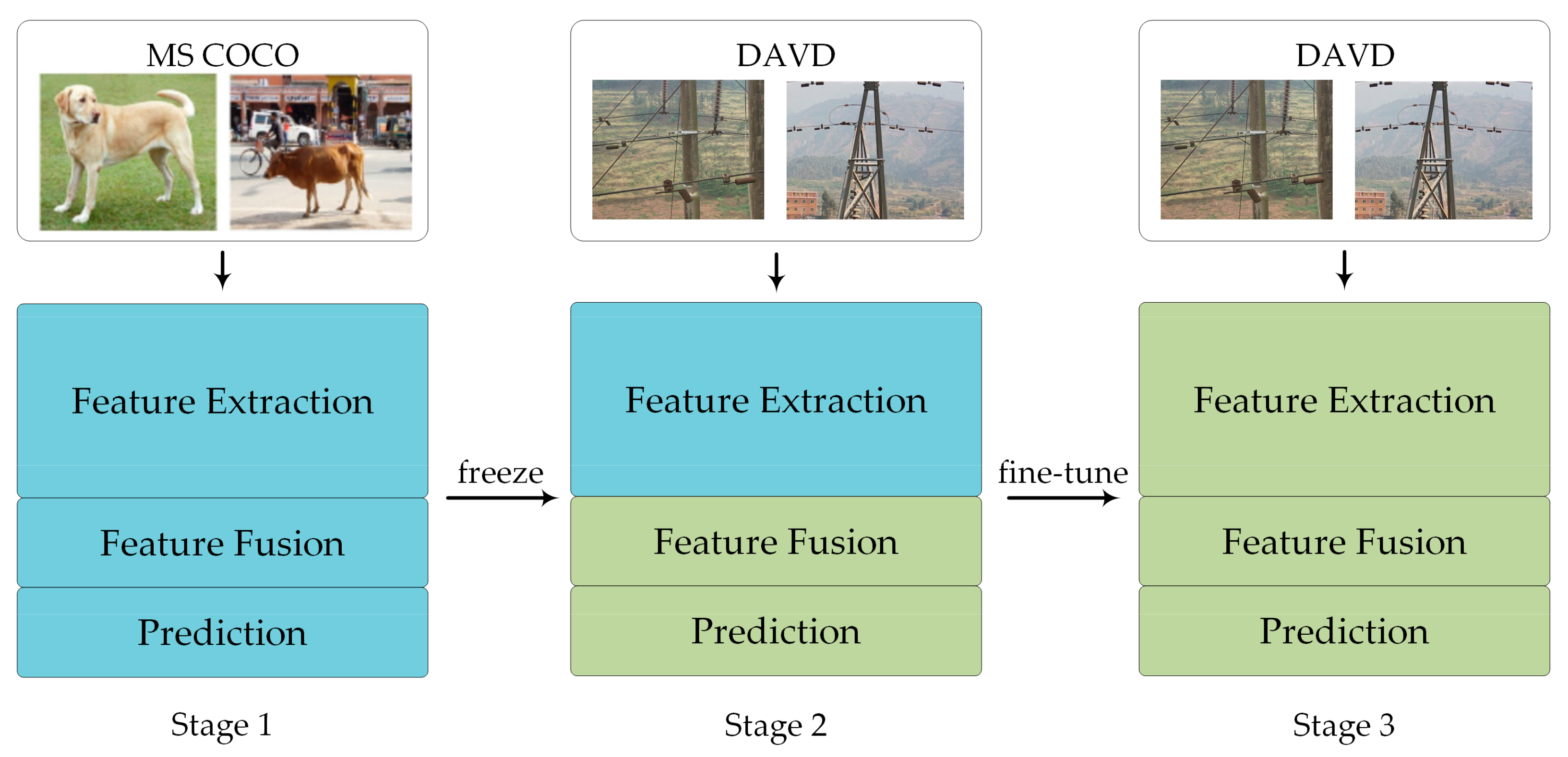
- We introduced a multi-stage transfer learning strategy, which was combined with freezing and fine-tuning methods, to improve the training efficiency and prevent overfitting by the network. Compared with other mainstream object detection methods, the proposed method significantly improved the detection accuracy of abnormal vibration dampers.
2. Related Work
2.1. Image Processing-Based Detection Methods
2.2. Classical Machine Learning-Based Detection Methods
2.3. Deep Learning-Based Detection Methods
3. Data Set
3.1. Screening of UAV Remote Sensing Images
3.2. Preprocessing of UAV Remote Sensing Images
3.3. Annotation of UAV Remote Sensing Images
- If there was corrosion on the surface of the vibration damper, it was annotated as “rusty”;
- If the head of the vibration damper had fallen off or the steel strand was bent, it was annotated as “defective”;
- If the vibration damper did not have either of these two faults, it was annotated as “normal”.
4. Method
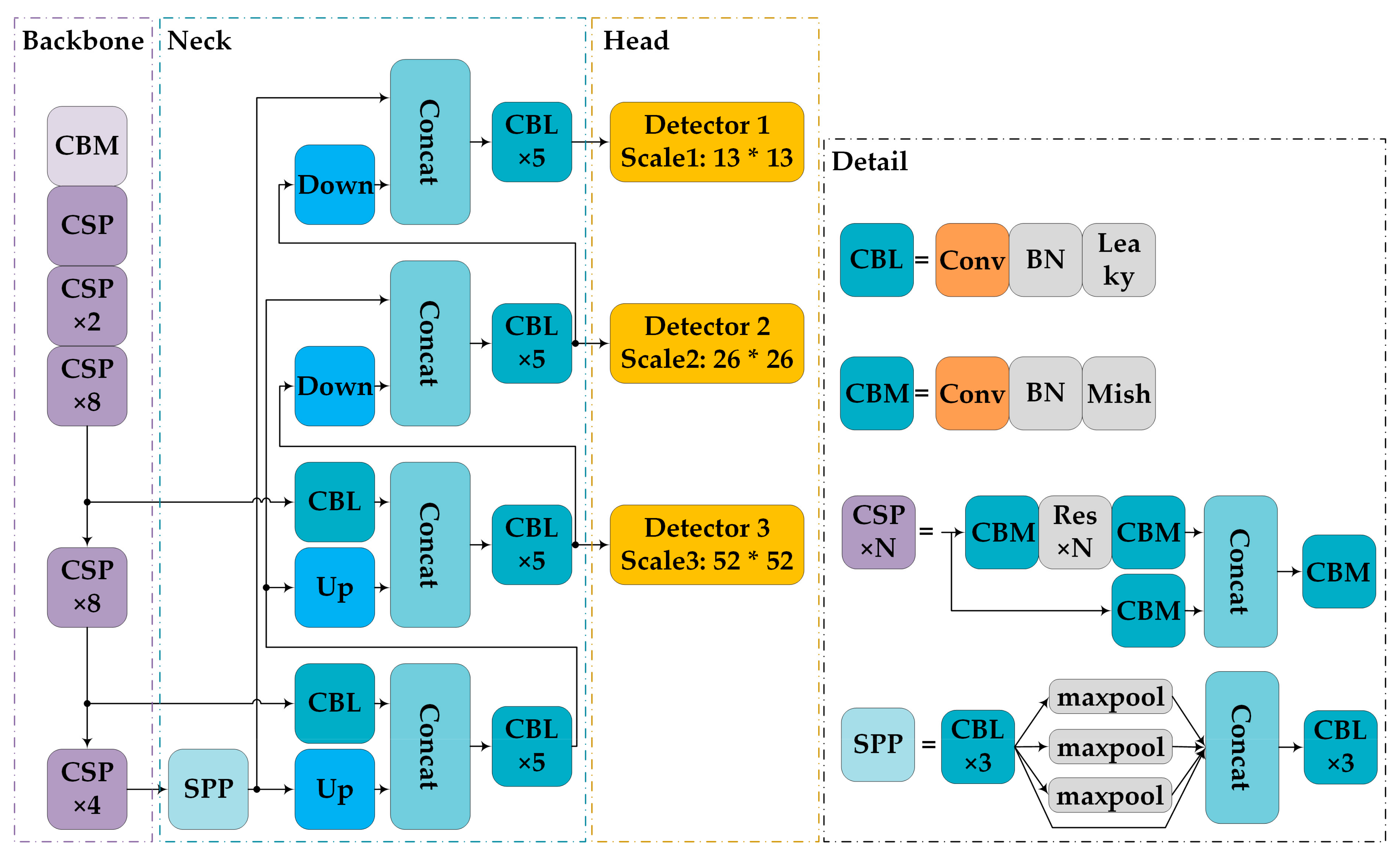
4.1. YOLOv4 Network Architecture
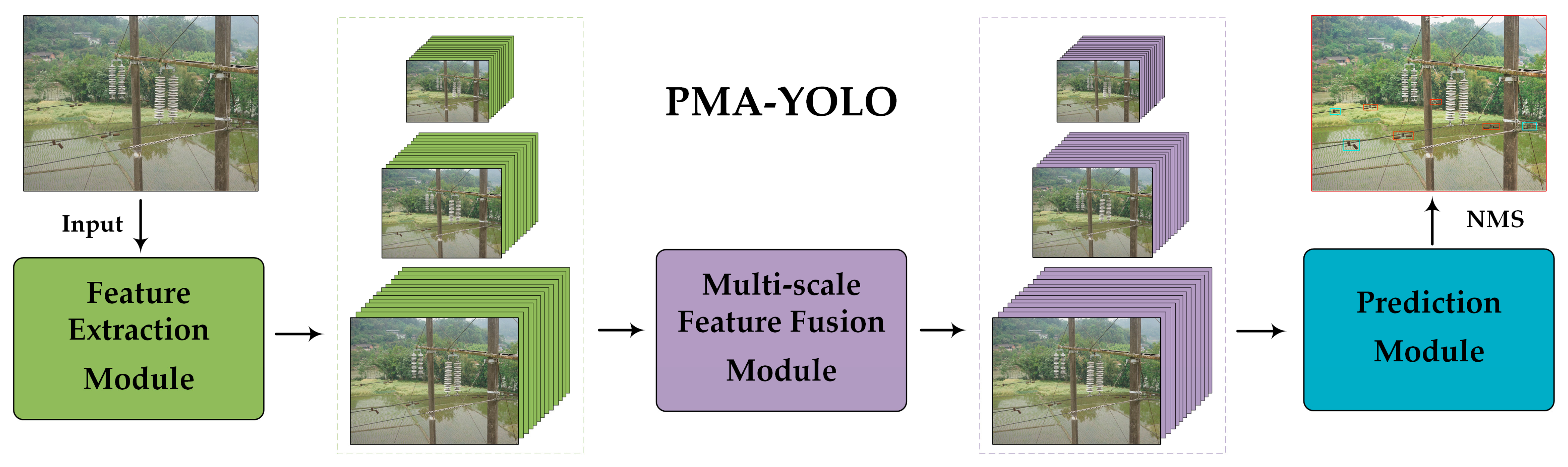
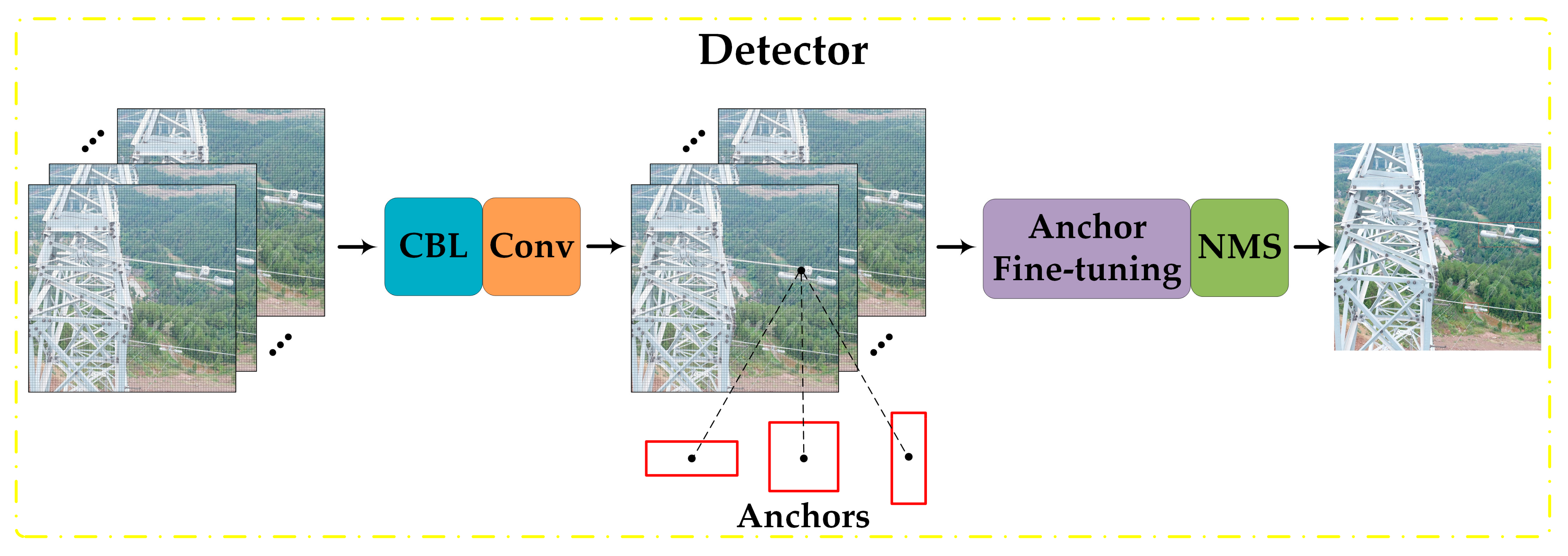
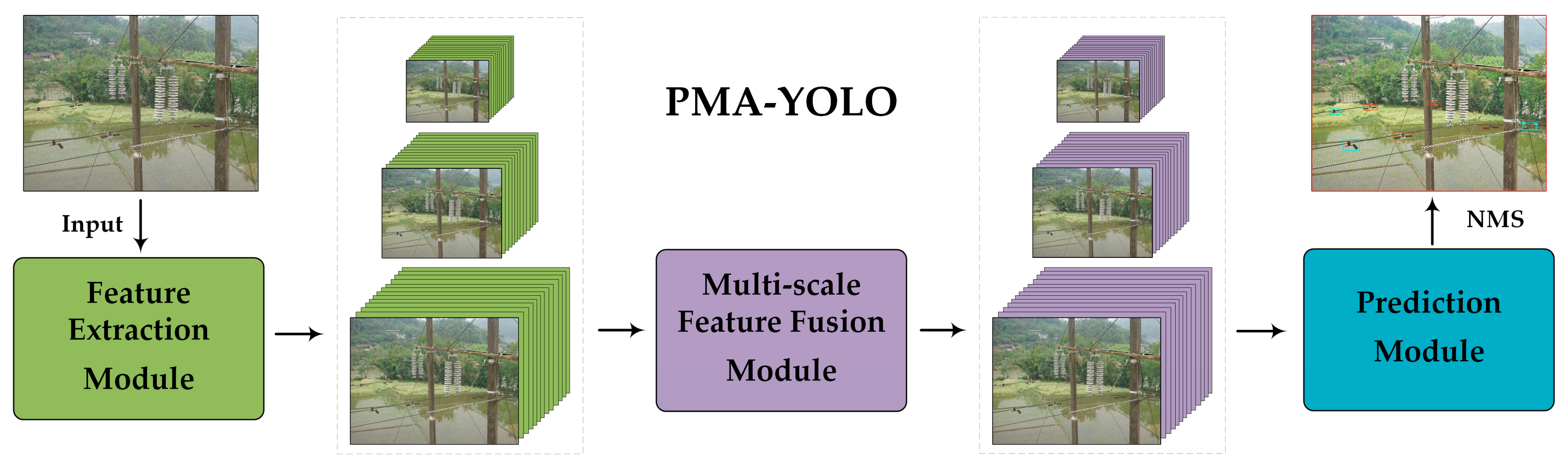
4.2. Architecture of the PMA-YOLO Network
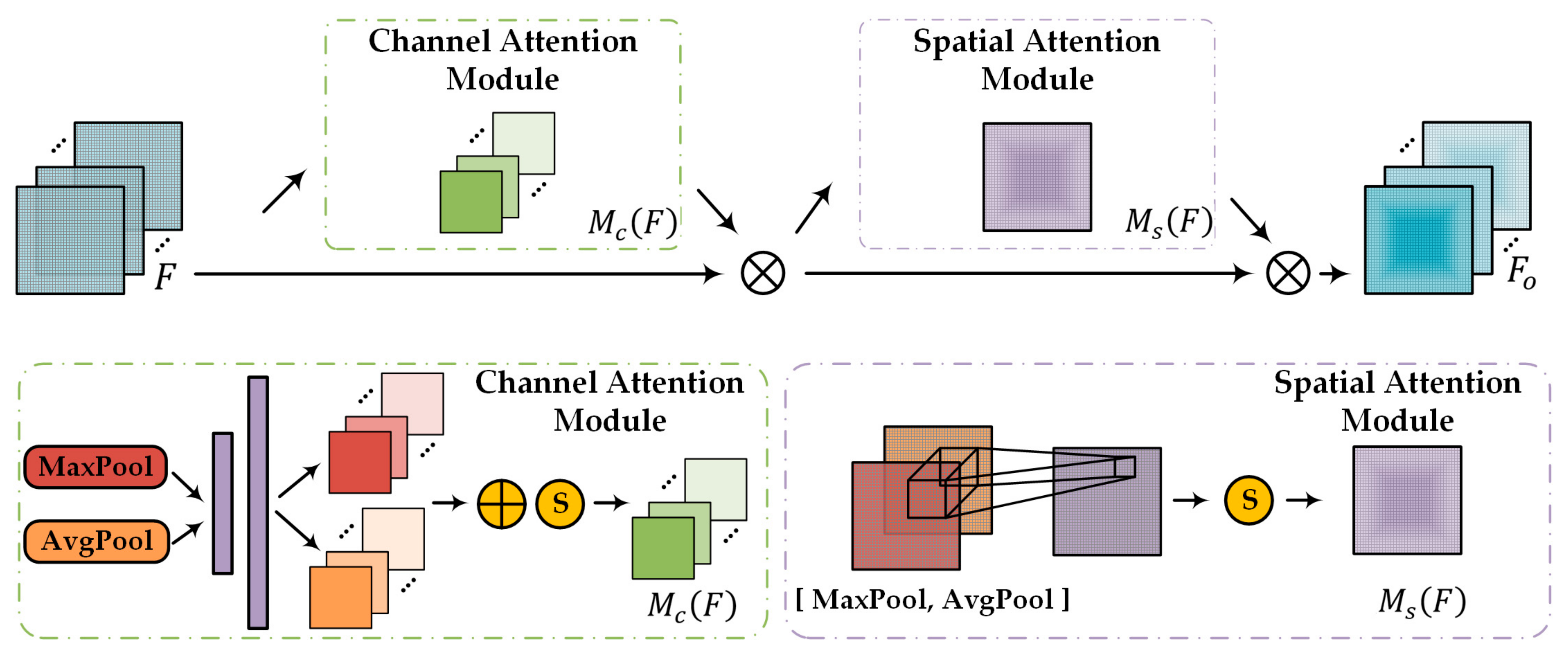
4.2.1. PMA (Parallel Mixed Attention)
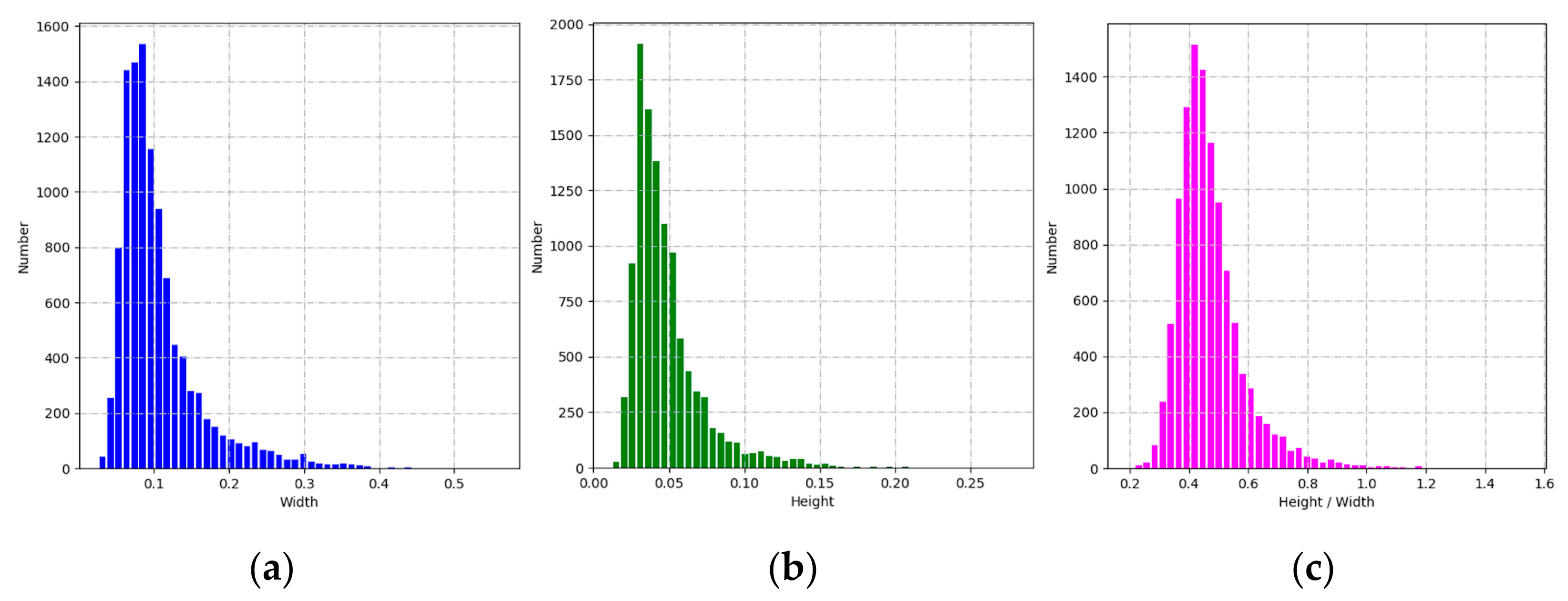
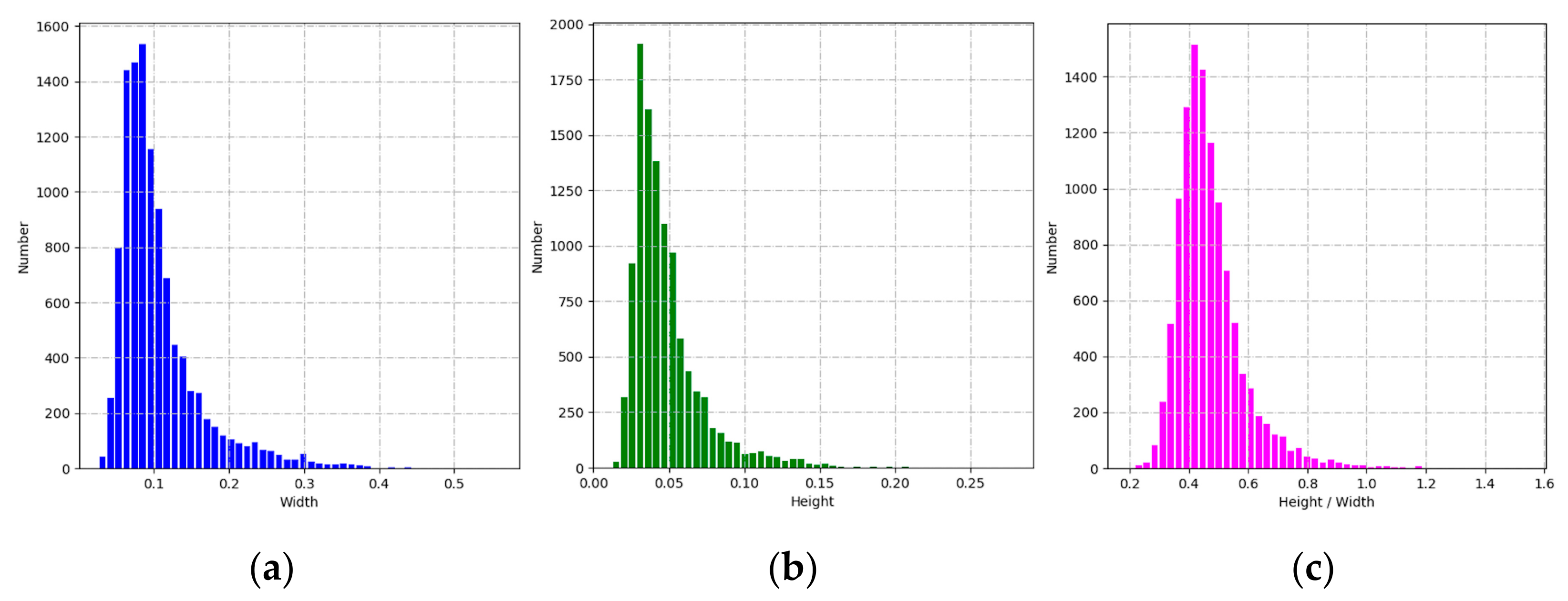
4.2.2. Anchors Design Based on the K-Means Algorithm
4.3. Training Strategy
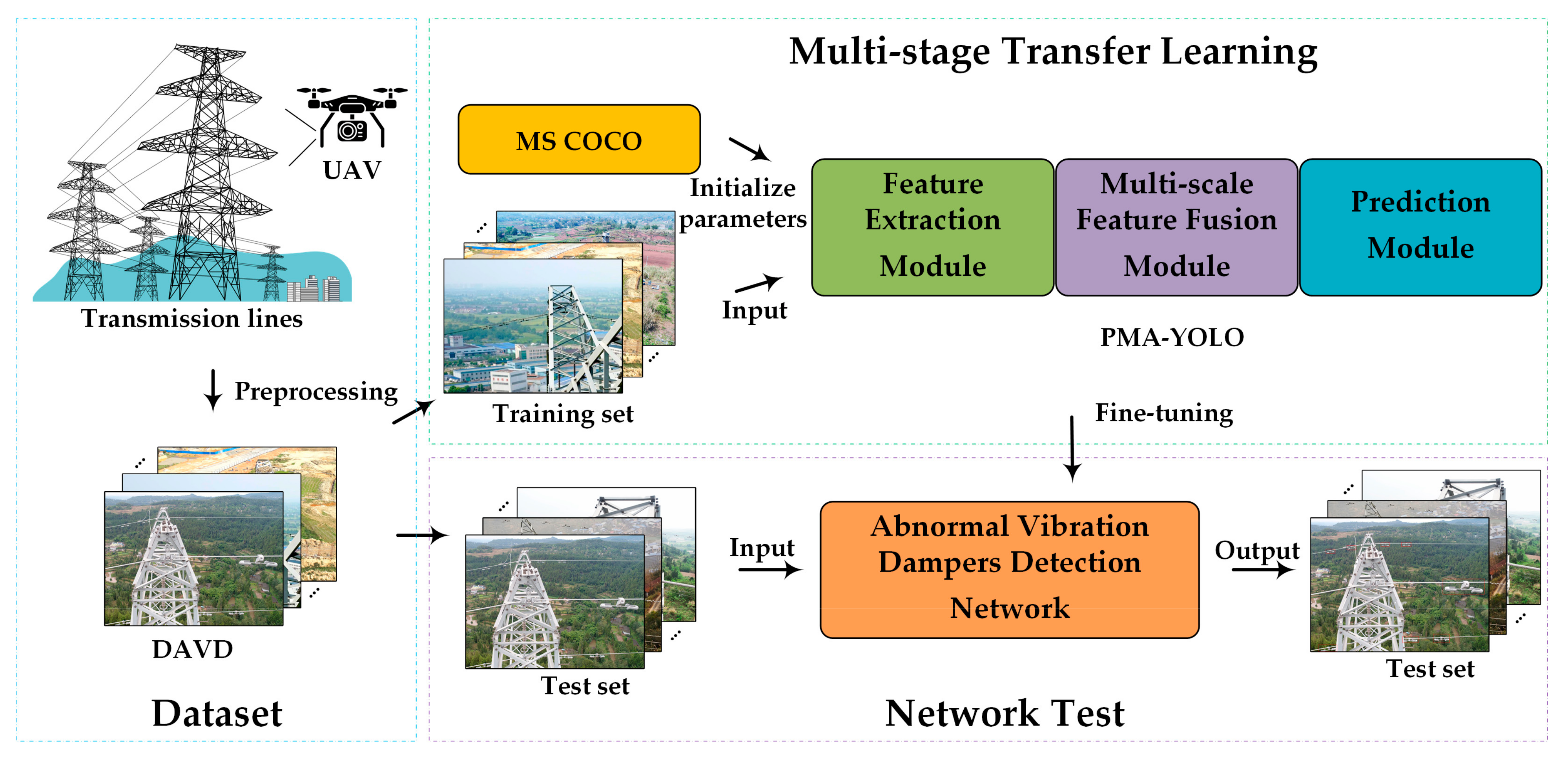
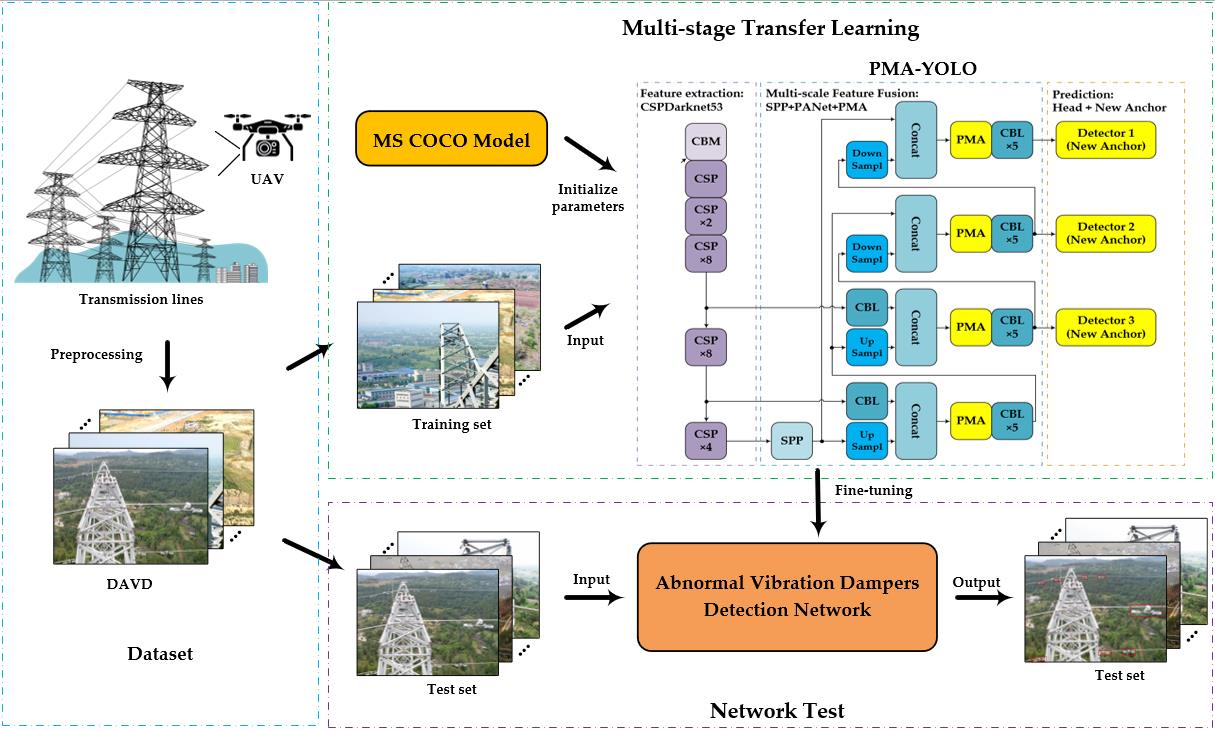
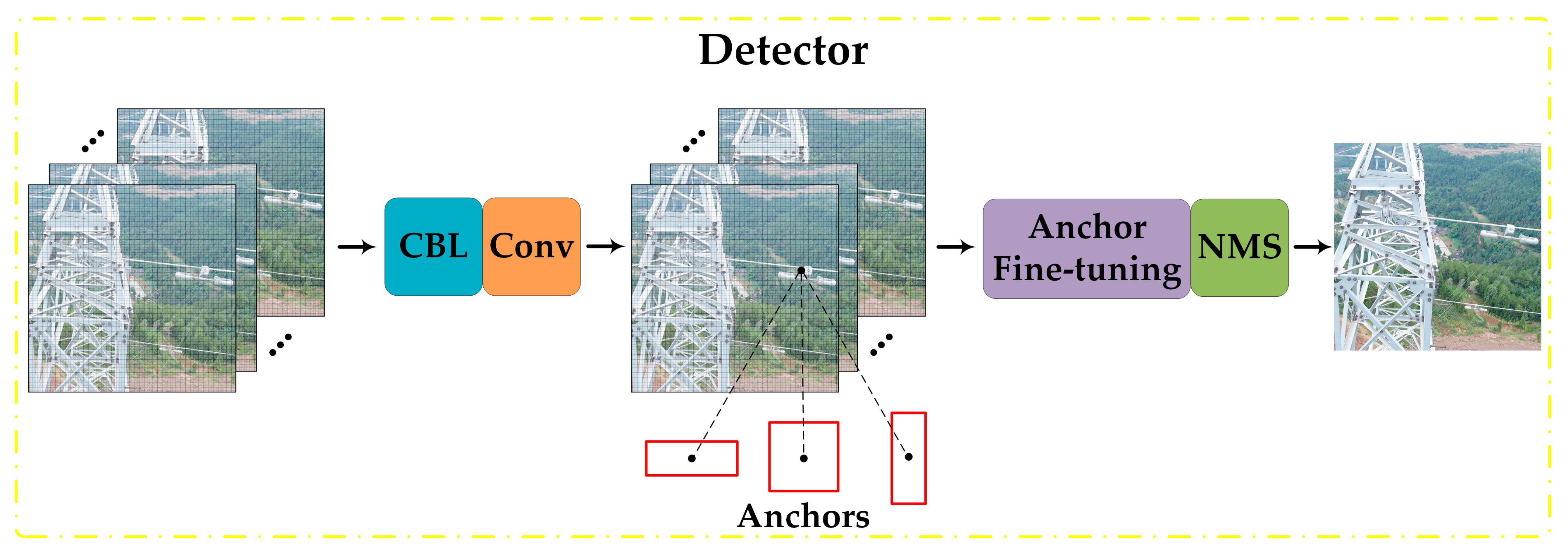
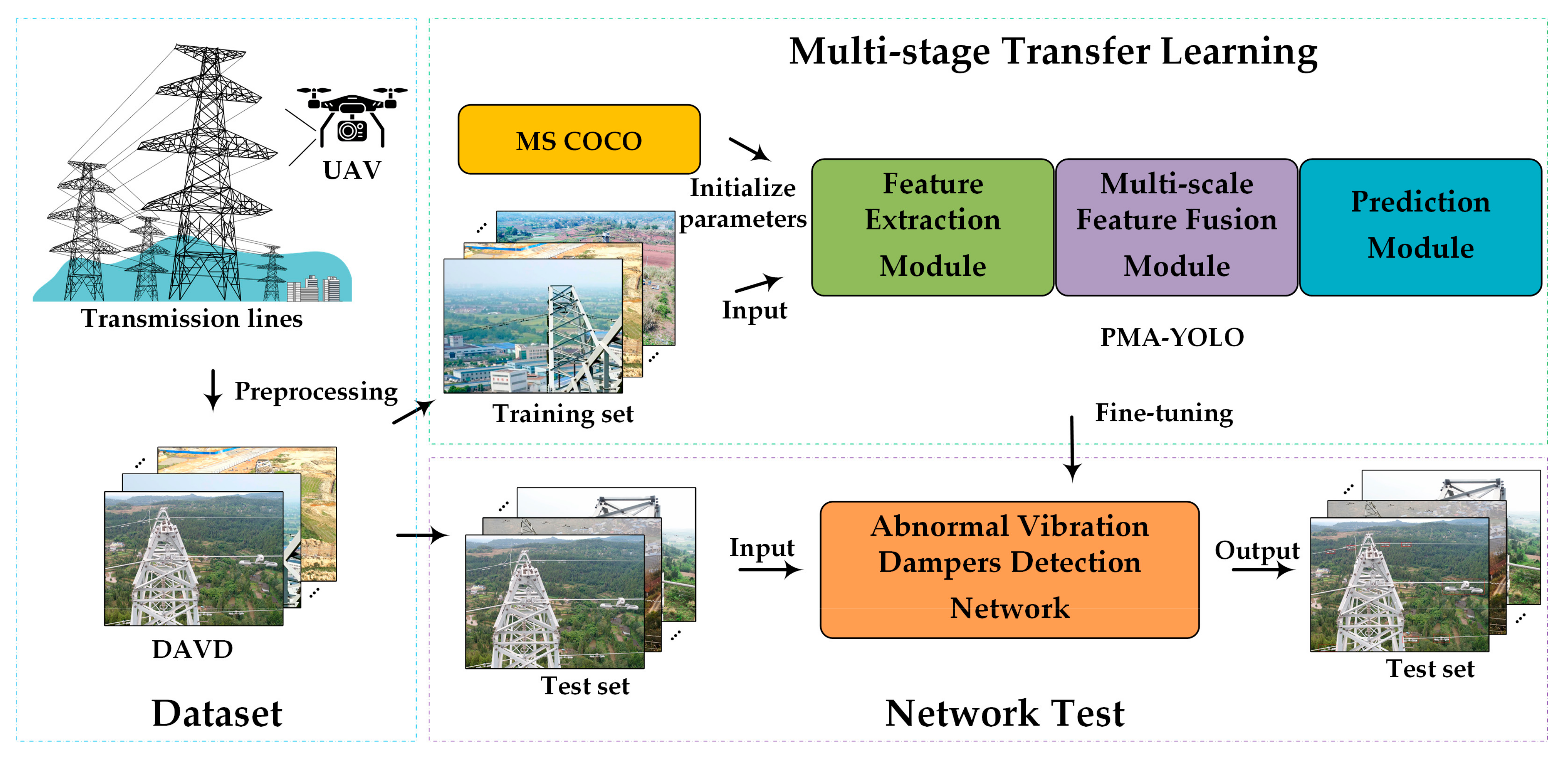
4.4. Methods Framework
- The images of vibration dampers on transmission lines were acquired by UAV;
- Gamma correction and MSR algorithms were used to preprocess the images, and then image augmentation methods, such as horizontal flip and 15° rotation, were implemented;
- All the images were resized to 800 × 600 × 3 and divided into a training set and a test set according to the ratio of 8:2;
- The training images are annotated by LabelImg, and the classes and boxes of vibration dampers were saved into XML files;
- The PMA-YOLO network was pre-trained based on MS COCO to obtain the initial parameters for knowledge transfer;
- The parameters of PMA-YOLO were fine-tuned in our DAVD by freezing;
- The loss value of the training set was observed. The model was saved when the Loss value reached the minimum value;
- The model of the PMA-YOLO network was used to detect the abnormal vibration dampers in the test images.
5. Experimental Results and Analysis
5.1. Experimental Environment and Parameters
5.2. Performance Evaluation Metrics
5.3. Results and Analysis
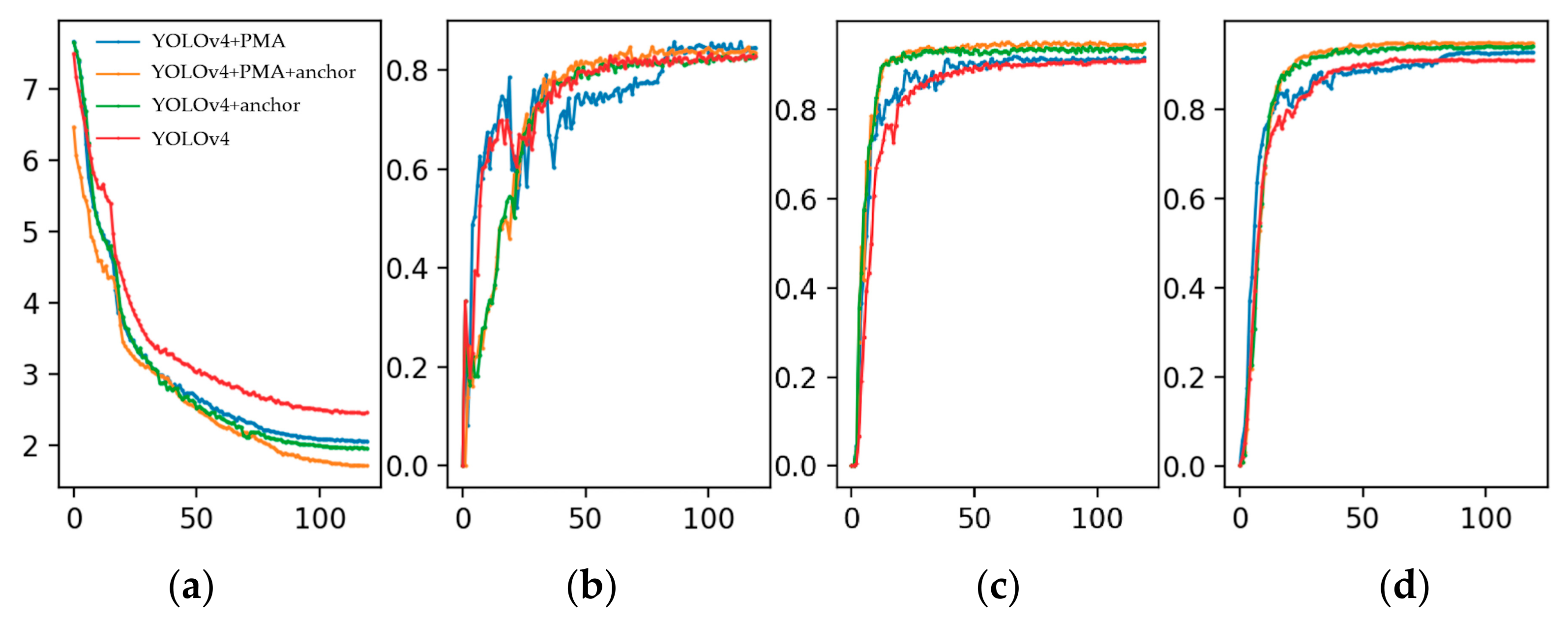
5.3.1. Comparison of Different Attention Modules
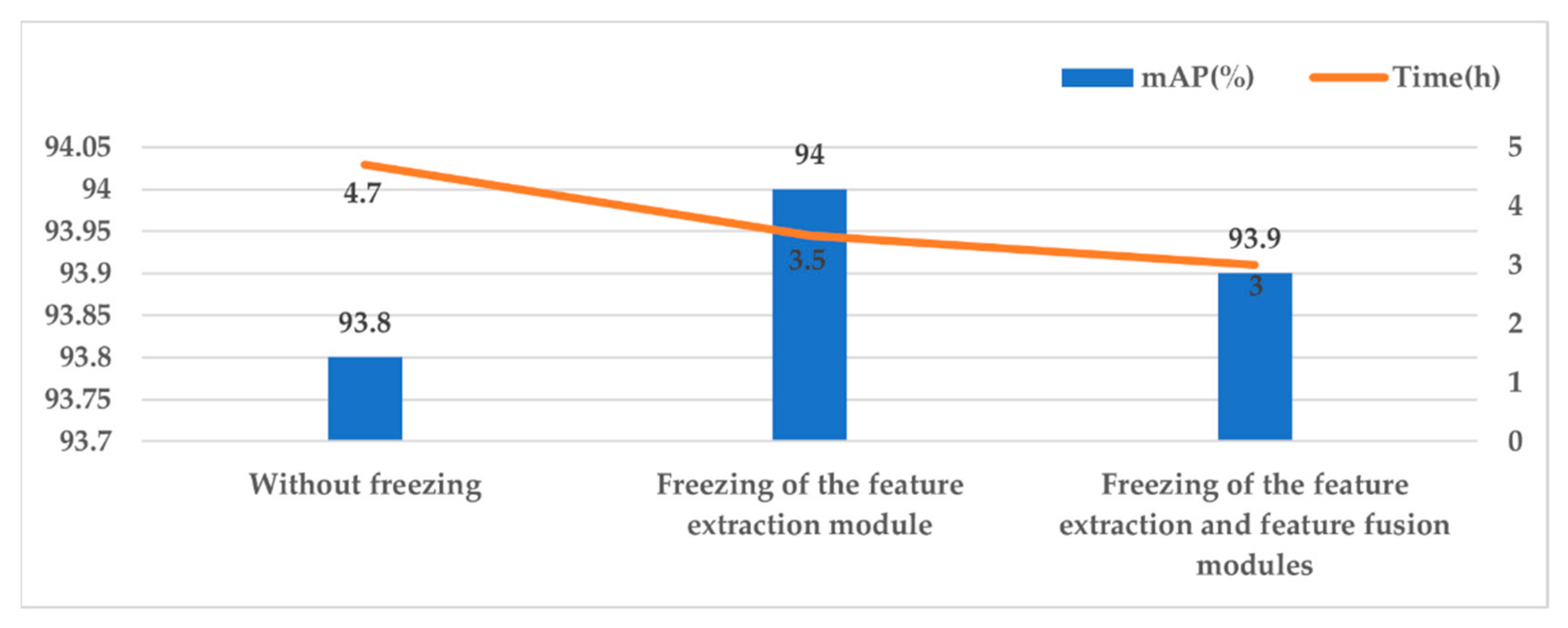
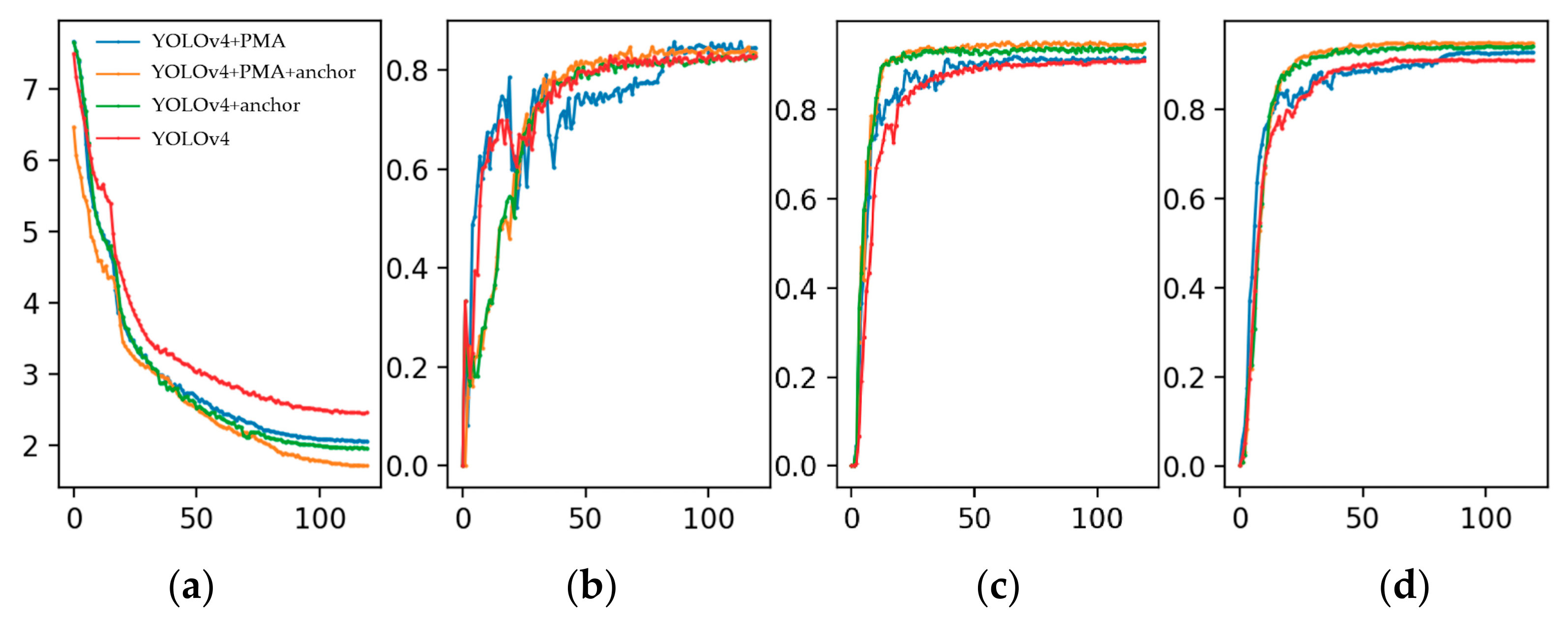
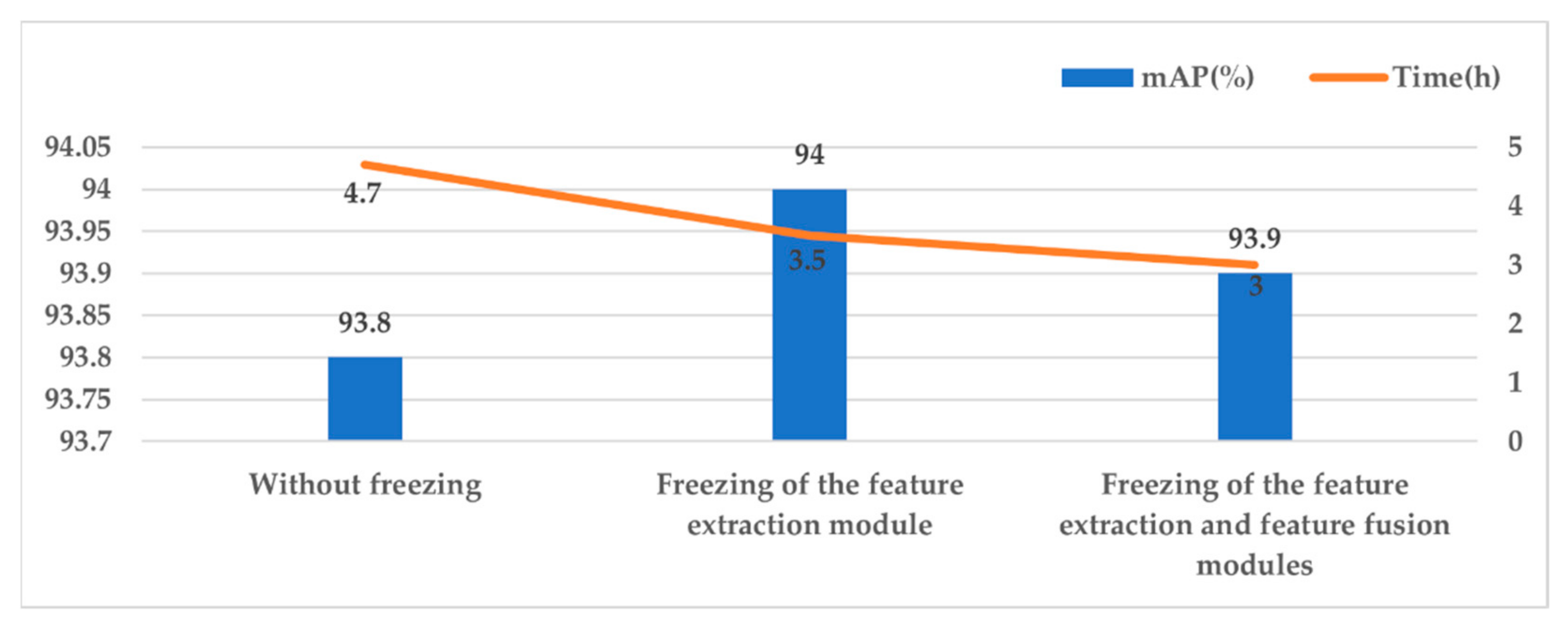
5.3.2. Comparison of Different Training Strategies
5.3.3. Comparison of Different Object Detection Networks
6. Discussion
7. Conclusions
- We screened UAV remote sensing images containing various vibration dampers to construct a data set of abnormal vibration dampers called DAVD. To improve the generalizability of the network and to avoid overfitting, we applied several pre-processing methods.
- Our PMA module was integrated into the YOLOv4 network. This combined a channel attention module and a spatial attention module with the convolution results of the input feature map in parallel, meaning that the network was able to pay more attention to critical features.
- Based on the characteristics of the numerous, small, abnormal vibration dampers in DAVD, we used the K-means algorithm to re-cluster a new set of anchors that were more suitable for the abnormal vibration dampers, thus reducing the probability of missed detection.
- Finally, we introduced a multi-stage transfer learning strategy to train the PMA-YOLO network and used different freezing positions to carry out comparison experiments, to improve the training efficiency of the network and avoid overfitting.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sadykova, D.; Pernebayeva, D.; Bagheri, M.; James, A. IN-YOLO: Real-time detection of outdoor high voltage insulators using UAV imaging. IEEE Trans. Power Deliv. 2019, 35, 1599–1601. [Google Scholar] [CrossRef]
- Liang, H.; Zuo, C.; Wei, W. Detection and evaluation method of transmission line defects based on deep learning. IEEE Access 2020, 8, 38448–38458. [Google Scholar] [CrossRef]
- Siddiqui, Z.A.; Park, U. A drone based transmission line components inspection system with deep learning technique. Energies 2020, 13, 3348. [Google Scholar] [CrossRef]
- Jiang, S.; Jiang, W.; Huang, W.; Yang, L. UAV-based oblique photogrammetry for outdoor data acquisition and offsite visual inspection of transmission line. Remote Sens. 2017, 9, 278. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Lin, Y.; Jiang, H.; Miao, X.; Chen, J. Slippage fault diagnosis of dampers for transmission lines based on faster R-CNN and distance constraint. Electr. Power Syst. Res. 2021, 199, 107449. [Google Scholar] [CrossRef]
- Yang, H.; Guo, T.; Shen, P.; Chen, F.; Wang, W.; Liu, X. Anti-vibration hammer detection in UAV image. In Proceedings of the 2017 2nd International Conference on Power and Renewable Energy (ICPRE), Chengdu, China, 20–23 September 2017; pp. 204–207. [Google Scholar] [CrossRef]
- Du, C.; van der Sar, T.; Zhou, T.X.; Upadhyaya, P.; Casola, F.; Zhang, H.; Onbasli, M.C.; Ross, C.A.; Walsworth, R.L.; Tserkovnyak, Y.; et al. Control and local measurement of the spin chemical potential in a magnetic insulator. Science 2017, 357, 195–198. [Google Scholar] [CrossRef] [Green Version]
- Jenssen, R.; Roverso, D. Automatic autonomous vision-based power line inspection: A review of current status and the potential role of deep learning. Int. J. Electr. Power Energy Syst. 2018, 99, 107–120. [Google Scholar] [CrossRef] [Green Version]
- Kraft, M.; Piechocki, M.; Ptak, B.; Walas, K. Autonomous, onboard vision-based trash and litter detection in low altitude aerial images collected by an unmanned aerial vehicle. Remote Sens. 2021, 13, 965. [Google Scholar] [CrossRef]
- Lee, S.; Song, Y.; Kil, S.-H. Feasibility analyses of real-time detection of wildlife using UAV-derived thermal and rgb images. Remote Sens. 2021, 13, 2169. [Google Scholar] [CrossRef]
- Zhang, R.; Yang, B.; Xiao, W.; Liang, F.; Liu, Y.; Wang, Z. Automatic extraction of high-voltage power transmission objects from UAV lidar point clouds. Remote Sens. 2019, 11, 2600. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Yuan, X.; Li, W.; Chen, S. Automatic power line inspection using UAV images. Remote Sens. 2017, 9, 824. [Google Scholar] [CrossRef] [Green Version]
- Mirallès, F.; Pouliot, N.; Montambault, S. State-of-the-art review of computer vision for the management of power transmission lines. In Proceedings of the 2014 3rd International Conference on Applied Robotics for the Power Industry (CARPI), Foz do Iguacu, Brazil, 14–16 October 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-J.M. YOLOv4 optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, W.; Ye, G.; Feng, H.; Wang, S.; Chang, W. Recognition of insulator based on developed MPEG-7 texture feature. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing (CISP), Yantai, China, 16–18 October 2010; pp. 265–268. [Google Scholar] [CrossRef]
- Wu, H.; Xi, Y.; Fang, W.; Sun, X.; Jiang, L. Damper detection in helicopter inspection of power transmission line. In Proceedings of the 2014 4th International Conference on Instrumentation and Measurement, Computer, Communication and Control (IMCCC), Harbin, China, 18–20 September 2014; pp. 628–632. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, X.; Zhang, Y.; Zhao, L. A method of identifying rust status of dampers based on image processing. IEEE Trans. Instrum. Meas. 2020, 69, 5407–5417. [Google Scholar] [CrossRef]
- Sravanthi, R.; Sarma, A.S.V. Efficient image-based object detection for floating weed collection with low cost unmanned floating vehicles. Soft Comput. 2021, 25, 13093–13101. [Google Scholar] [CrossRef]
- Hou, J.; Li, B. Swimming target detection and tracking technology in video image processing. Microprocess. Microsyst. 2021, 80, 103535. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Liu, Y.; Li, E.; Peng, J.; Liang, Z. A review on state-of-the-art power line inspection techniques. IEEE Trans. Instrum. Meas. 2020, 69, 9350–9365. [Google Scholar] [CrossRef]
- Jabid, T.; Uddin, M.Z. Rotation invariant power line insulator detection using local directional pattern and support vector machine. In Proceedings of the 2016 International Conference on Innovations in Science, Engineering and Technology (ICISET), Dhaka, Bangladesh, 28–29 October 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Dan, Z.; Hong, H.; Qian, R. An insulator defect detection algorithm based on computer vision. In Proceedings of the 2017 IEEE International Conference on Information and Automation (ICIA), Macao, China, 18–20 July 2017; pp. 361–365. [Google Scholar] [CrossRef]
- Krummenacher, G.; Ong, C.S.; Koller, S.; Kobayashi, S.; Buhmann, J.M. Wheel defect detection with machine learning. IEEE Trans. Intell. Transp. Syst. 2017, 19, 1176–1187. [Google Scholar] [CrossRef]
- Wen, Q.; Luo, Z.; Chen, R.; Yang, Y.; Li, G. Deep learning approaches on defect detection in high resolution aerial images of insulators. Sensors 2021, 21, 1033. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Nguyen, V.N.; Jenssen, R.; Roverso, D. Intelligent monitoring and inspection of power line components powered by UAVs and deep learning. IEEE Power Energy Technol. Syst. J. 2019, 6, 11–21. [Google Scholar] [CrossRef]
- Ji, Z.; Liao, Y.; Zheng, L.; Wu, L.; Yu, M.; Feng, Y. An assembled detector based on geometrical constraint for power component recognition. Sensors 2019, 19, 3517. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; He, Z.; Shi, B.; Zhong, T. Research on recognition method of electrical components based on YOLO V3. IEEE Access 2019, 7, 157818–157829. [Google Scholar] [CrossRef]
- Liu, B.; Wang, X.; Jin, W.; Chen, Y.; Liu, C. Infrared image detail enhancement based on local adaptive gamma correction. Chin. Opt. Lett. 2012, 10, 25–29. [Google Scholar]
- Rahman, Z.; Jobson, D.; Woodell, G. Multi-scale retinex for color image enhancement. In Proceedings of the 3rd IEEE International Conference on Image Processing (ICIP), Lausanne, Switzerland, 19 September 1996; pp. 1003–1006. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal Visual Object Classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Wang, P.; Liu, W.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and better learning for bounding box regression. arXiv 2019, arXiv:1911.08287. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the 28th Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 3320–3328. [Google Scholar]
- Hu, J.; Sun, G.; Albanie, S.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef] [Green Version]
- Ultralytics. Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 22 September 2021).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes | Training Set | Test Set | ||
|---|---|---|---|---|
| Images | Objects | Images | Objects | |
| Rusty | 641 | 3872 | 160 | 957 |
| Defective | 208 | 1122 | 50 | 276 |
| Normal | 686 | 3766 | 175 | 964 |
| Total | 1448 | 8760 | 362 | 2197 |
| Prediction Branch | Feature Map | Anchors |
|---|---|---|
| 1 (large) | ||
| 2 (medium) | ||
| 3 (small) |
| Platform | Configuration |
|---|---|
| Operating system | Ubuntu18.04 LTS 64-bits |
| CPU | Intel(R) Core (TM) i7-9700 |
| GPU | NVIDIA GeForce RTX 2080Ti |
| GPU accelerator | CUDA 10.1 and cuDNN 7.6.5 |
| Deep learning frame | PyTorch1.5 |
| Compilers | PyCharm and Anaconda |
| Scripting language | Python 3.7 |
| Parameters | Configuration |
|---|---|
| Input size | |
| Optimization algorithm | SGD |
| Batch size | 8 |
| Training epochs | 120 |
| Learning rate | 0.01 |
| Momentum | 0.937 |
| Weight decay | 0.0005 |
| Network | P (%) | R (%) | mAP@0.5 (%) |
|---|---|---|---|
| YOLOv4 | 79.1 | 90.0 | 90.3 |
| YOLOv4 + SE | 80.3 | 89.4 | 90.3 |
| YOLOv4 + CBAM | 80.9 | 90.5 | 91.4 |
| YOLOv4 + PMA | 81.0 | 90.8 | 91.9 |
| Network | Rusty (AP) | Defective (AP) | Normal (AP) | mAP@0.5 (%) |
|---|---|---|---|---|
| SSD512 | 86.9 | 74.7 | 84.9 | 82.1 |
| Faster R-CNN + FPN | 89.7 | 77.2 | 88.7 | 85.2 |
| RetinaNet | 87.1 | 84.3 | 87.0 | 86.2 |
| Cascade R-CNN+ 1 | 91.6 | 90.9 | 91.1 | 91.2 |
| YOLOv3 | 88.6 | 78.9 | 86.7 | 84.7 |
| YOLOv4 | 93.4 | 87.6 | 90.0 | 90.3 |
| YOLOv5x | 94.8 | 90.5 | 94.2 | 93.2 |
| Ours | 96.4 | 92.3 | 93.2 | 94.0 |
| Baseline | PMA | Anchors | P (%) | R (%) | mAP@0.5 (%) |
|---|---|---|---|---|---|
| YOLOv4 | × | × | 79.1 | 90.0 | 90.3 |
| √ | × | 81.0 | 90.8 | 91.9 | |
| × | √ | 78.4 | 93.3 | 93.6 | |
| √ | √ | 81.8 | 93.8 | 93.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bao, W.; Ren, Y.; Wang, N.; Hu, G.; Yang, X. Detection of Abnormal Vibration Dampers on Transmission Lines in UAV Remote Sensing Images with PMA-YOLO. Remote Sens. 2021, 13, 4134. https://doi.org/10.3390/rs13204134
Bao W, Ren Y, Wang N, Hu G, Yang X. Detection of Abnormal Vibration Dampers on Transmission Lines in UAV Remote Sensing Images with PMA-YOLO. Remote Sensing. 2021; 13(20):4134. https://doi.org/10.3390/rs13204134
Chicago/Turabian StyleBao, Wenxia, Yangxun Ren, Nian Wang, Gensheng Hu, and Xianjun Yang. 2021. "Detection of Abnormal Vibration Dampers on Transmission Lines in UAV Remote Sensing Images with PMA-YOLO" Remote Sensing 13, no. 20: 4134. https://doi.org/10.3390/rs13204134
APA StyleBao, W., Ren, Y., Wang, N., Hu, G., & Yang, X. (2021). Detection of Abnormal Vibration Dampers on Transmission Lines in UAV Remote Sensing Images with PMA-YOLO. Remote Sensing, 13(20), 4134. https://doi.org/10.3390/rs13204134