
EFM-Net: Feature Extraction and Filtration with Mask Improvement Network for Object Detection in Remote Sensing Images

Abstract
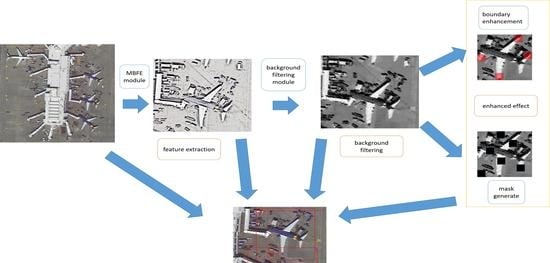
:
1. Introduction
- We propose a new object detection framework for remote sensing image detection called EFM-Net.
- In EFM-Net, we design a multi-branched feature extraction (MBFE) module embedded in an FPN to improve the feature capture ability. At the same time, in order to reduce the complex background information in remote sensing images, we design a background filtering module based on an attention mechanism to reduce the background interference.
- We design an RoI region enhancement method with occlusion and key point enhancement to improve the occlusion detection accuracy.
- This method achieved good results with the DOTA v1.0, NWPU VHR-10, UCAS AOD datasets.
2. Related Works
2.1. Multi-Scale Object Detectors
2.2. Deformable Convolutional Networks
2.3. Attention Mechanism
2.4. Occlusion Improvement
3. Proposed Method
3.1. Overall Architecture
3.2. MBFE Module
3.3. Background Filtering Module
3.4. Mask Improvement Module
3.5. Loss Function
4. Experiments
4.1. Datasets and Evaluation Criteria
4.2. Training Data and Settings
4.3. Ablation Experiment
4.4. Results of DOTA Dataset
4.5. Results of NWPU VHR-10 and UCAS AOD Datasets
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 4th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zürich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams CK, I.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2 cnn: Rotational region cnn for arbitrarily-oriented scene text detection. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 29 November 2018; pp. 3610–3615. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 8232–8241. [Google Scholar]
- Ye, X.; Xiong, F.; Lu, J.; Zhou, J.; Qian, Y. F3-Net: Feature fusion and filtration network for object detection in optical remote sensing images. Remote Sens. 2020, 12, 4027. [Google Scholar] [CrossRef]
- Guo, W.; Li, W.; Gong, W.; Cui, J. Extended feature pyramid network with adaptive scale training strategy and anchors for object detection in aerial images. Remote Sens. 2020, 12, 784. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Ding, J.; Xue, N.; Xia, G.S.; Bai, X.; Yang, W.; Yang, M.Y.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; et al. Object detection in aerial images: A large-scale benchmark and challenges. arXiv 2021, arXiv:2102.12219. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, X.; Pan, C. Augfpn: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 12595–12604. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Wojna, Z.; Shlens, J. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Sergey, I.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 23 February 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9308–9316. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11531–11539. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), online, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Qiu, H.; Ma, Y.; Li, Z.; Liu, S.; Sun, J. Borderdet: Border feature for dense object detection. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2020; pp. 549–564. [Google Scholar]
- Wang, X.; Shrivastava, A.; Gupta, A. A-fast-rcnn: Hard positive generation via adversary for object detection. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2606–2615. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Sun, P.; Zheng, Y.; Zhou, Z.; Xu, W.; Ren, Q. R4 Det: Refined single-stage detector with feature recursion and refinement for rotating object detection in aerial images. Image Vis. Comput. 2020, 103, 104036. [Google Scholar] [CrossRef]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Korner, M.; Reinartz, P. Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery. In Proceedings of the ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 4–6 December 2018; pp. 150–165. [Google Scholar]
- Zhu, Y.; Du, J.; Wu, X. Adaptive period embedding for representing oriented objects in aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7247–7257. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-Merged Single-Shot Detection for Multiscale Objects in Large-Scale Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3377–3390. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone Network | MBFE | Background Filtering | Mask Improvement | Data Augmentation | mAP (%) OBB | mAP (%) HBB | Execution Times (Tasks/s) |
|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [1,16] | ResNet-50 | - | - | - | - | 70.06 | 71.09 | 7.7 |
| our | ResNet-50 | √ | - | - | - | 71.77 | 72.37 | 6.8 |
| our | ResNet-50 | - | √ | - | - | 71.92 | 72.63 | 7.7 |
| our | ResNet-50 | - | - | √ | - | 71.89 | 72.64 | 6.4 |
| our | ResNet-50 | √ | √ | √ | - | 74.32 | 74.43 | 5.1 |
| our | ResNet-101 | √ | √ | √ | - | 75.48 | 76.27 | 4.8 |
| our | ResNet-101 | √ | √ | √ | √ | 76.22 | 77.30 | 4.8 |
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| One-stage methods | ||||||||||||||||
| SSD [6] | 39.83 | 9.09 | 0.64 | 13.18 | 0.26 | 0.39 | 1.11 | 16.24 | 27.57 | 9.23 | 27.16 | 9.09 | 3.03 | 1.05 | 1.01 | 10.59 |
| Yolov2 [20] | 39.57 | 20.29 | 36.58 | 23.42 | 8.85 | 2.09 | 4.82 | 44.34 | 38.25 | 34.65 | 16.02 | 37.62 | 47.23 | 25.19 | 7.45 | 21.39 |
| R4Det [43] | 89.49 | 81.17 | 50.53 | 66.10 | 70.92 | 78.66 | 78.21 | 90.81 | 85.26 | 84.23 | 61.81 | 63.77 | 68.16 | 69.83 | 67.17 | 73.74 |
| Two-stage methods | ||||||||||||||||
| FR-O [1,16] | 84.76 | 77.46 | 47.17 | 63.49 | 75.29 | 74.69 | 85.71 | 90.52 | 81.04 | 79.83 | 48.03 | 61.68 | 62.76 | 63.79 | 54.70 | 70.06 |
| ICN [44] | 81.36 | 74.30 | 47.70 | 70.32 | 64.89 | 67.82 | 69.98 | 90.76 | 79.06 | 78.20 | 53.64 | 62.90 | 67.02 | 64.17 | 50.23 | 68.16 |
| SCRDet [11] | 89.98 | 80.65 | 52.09 | 68.36 | 68.36 | 60.32 | 72.41 | 90.85 | 87.94 | 86.86 | 65.02 | 66.68 | 66.25 | 68.24 | 65.21 | 72.61 |
| APE [45] | 89.96 | 83.62 | 53.42 | 76.03 | 74.01 | 77.16 | 79.45 | 90.83 | 87.15 | 84.51 | 67.72 | 60.33 | 74.61 | 71.84 | 65.55 | 75.75 |
| F3-Net [12] | 88.89 | 78.48 | 54.62 | 74.43 | 72.80 | 77.52 | 87.54 | 90.78 | 87.64 | 85.63 | 63.80 | 64.53 | 78.06 | 72.36 | 63.19 | 76.02 |
| EFM-Net(our) | 89.53 | 85.64 | 51.82 | 75.11 | 75.26 | 75.46 | 86.36 | 90.88 | 87.97 | 82.62 | 64.89 | 67.39 | 75.47 | 68.73 | 66.25 | 76.22 |
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| One-stage methods | ||||||||||||||||
| SSD [6] | 57.85 | 32.79 | 16.14 | 18.67 | 0.05 | 36.93 | 24.74 | 81.16 | 25.10 | 47.47 | 11.22 | 31.53 | 14.12 | 9.09 | 14.12 | 29.86 |
| Yolov2 [20] | 76.90 | 33.87 | 22.73 | 34.88 | 38.73 | 32.02 | 52.37 | 61.65 | 48.54 | 33.91 | 29.27 | 36.83 | 36.44 | 38.26 | 11.61 | 39.20 |
| Two-stage methods | ||||||||||||||||
| FR-H [1,16] | 88.95 | 82.52 | 51.06 | 62.01 | 78.57 | 71.37 | 85.14 | 88.99 | 82.99 | 84.72 | 41.19 | 62.39 | 72.69 | 70.30 | 43.43 | 71.09 |
| ICN [44] | 89.97 | 77.71 | 53.38 | 73.26 | 73.46 | 65.02 | 78.22 | 90.79 | 79.05 | 84.81 | 57.20 | 62.11 | 73.45 | 70.22 | 58.08 | 72.45 |
| SCRDet [11] | 90.18 | 81.88 | 55.30 | 73.29 | 72.09 | 77.65 | 78.06 | 90.91 | 82.44 | 86.39 | 64.53 | 63.45 | 75.77 | 78.21 | 60.11 | 75.35 |
| F3-Net [12] | 88.91 | 78.50 | 56.20 | 74.43 | 73.00 | 77.53 | 87.72 | 90.78 | 87.64 | 85.71 | 64.27 | 63.93 | 78.70 | 74.00 | 65.85 | 76.48 |
| EFM-Net (our) | 89.97 | 86.34 | 57.71 | 73.52 | 80.78 | 71.70 | 86.40 | 90.88 | 87.94 | 87.38 | 65.00 | 69.34 | 77.77 | 72.87 | 61.86 | 77.30 |
| Method | PL | SH | ST | BD | TC | BC | GTF | HB | BR | VE | mAP (%) |
| FMSSD [46] | 99.70 | 90.80 | 90.60 | 92.90 | 90.30 | 80.10 | 90.80 | 80.30 | 68.50 | 87.10 | 87.10 |
| F3-Net [12] | 99.31 | 92.62 | 92.89 | 97.14 | 91.38 | 86.16 | 98.00 | 90.30 | 82.18 | 88.90 | 91.89 |
| EFM-Net(our) | 99.70 | 86.70 | 92.50 | 97.40 | 99.70 | 96.30 | 99.60 | 76.10 | 82.40 | 90.20 | 92.10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Jia, Y.; Gu, L. EFM-Net: Feature Extraction and Filtration with Mask Improvement Network for Object Detection in Remote Sensing Images. Remote Sens. 2021, 13, 4151. https://doi.org/10.3390/rs13204151
Wang Y, Jia Y, Gu L. EFM-Net: Feature Extraction and Filtration with Mask Improvement Network for Object Detection in Remote Sensing Images. Remote Sensing. 2021; 13(20):4151. https://doi.org/10.3390/rs13204151
Chicago/Turabian StyleWang, Yu, Yannan Jia, and Lize Gu. 2021. "EFM-Net: Feature Extraction and Filtration with Mask Improvement Network for Object Detection in Remote Sensing Images" Remote Sensing 13, no. 20: 4151. https://doi.org/10.3390/rs13204151