
Uncovering the Nature of Urban Land Use Composition Using Multi-Source Open Big Data with Ensemble Learning



Abstract
:1. Introduction
2. Methodology
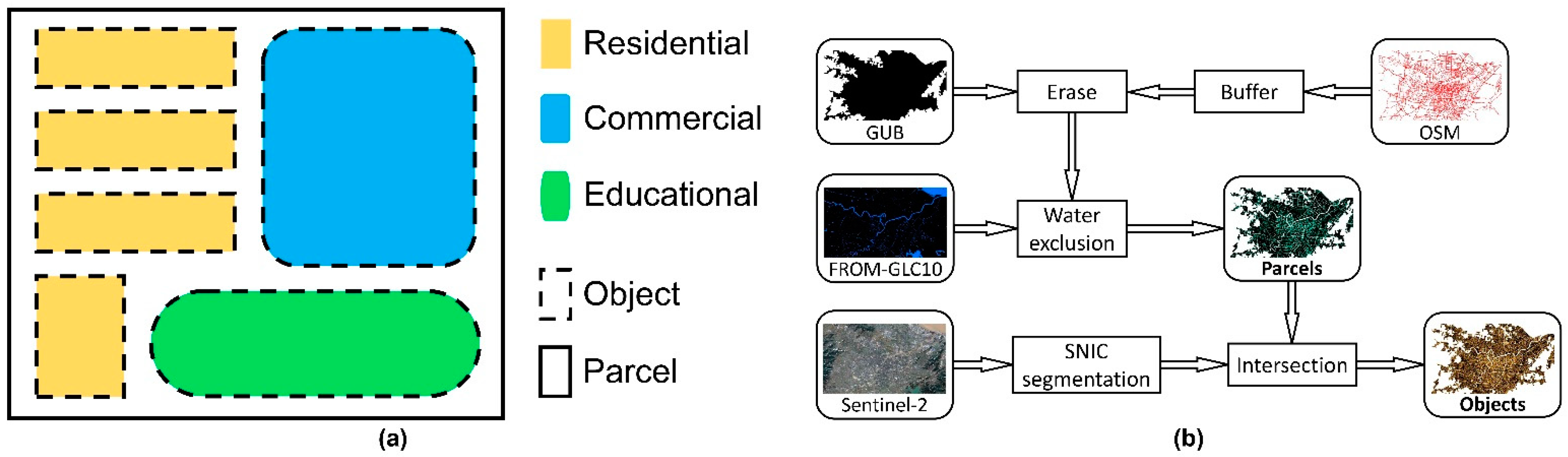
2.1. Basic Assumption: Each Parcel Is Composed of Objects
2.2. Stage-1: Mapping at the Object Scale
2.2.1. Feature Extraction
2.2.2. Sample Collection
2.2.3. Ensemble Learning
2.2.4. Accuracy Assessment and Mapping
2.3. Stage-2: Mapping at the Parcel Scale
2.4. Quantifying Influencing Factors of Land Use Mix
3. Experimental Tests and Results
3.1. Study Area and Data
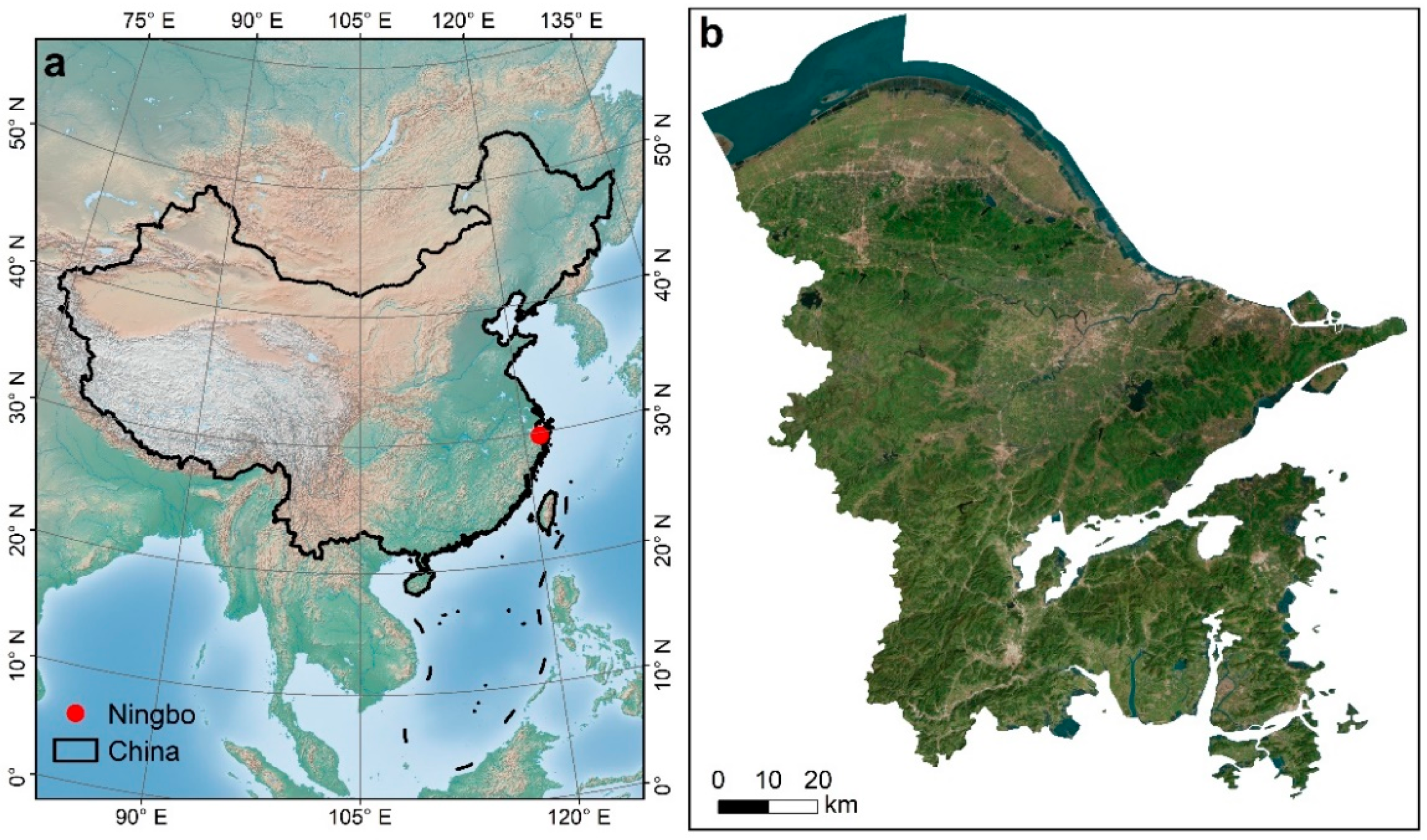
3.1.1. Study Area
3.1.2. Data
3.2. Results
3.2.1. Accuracy Assessment
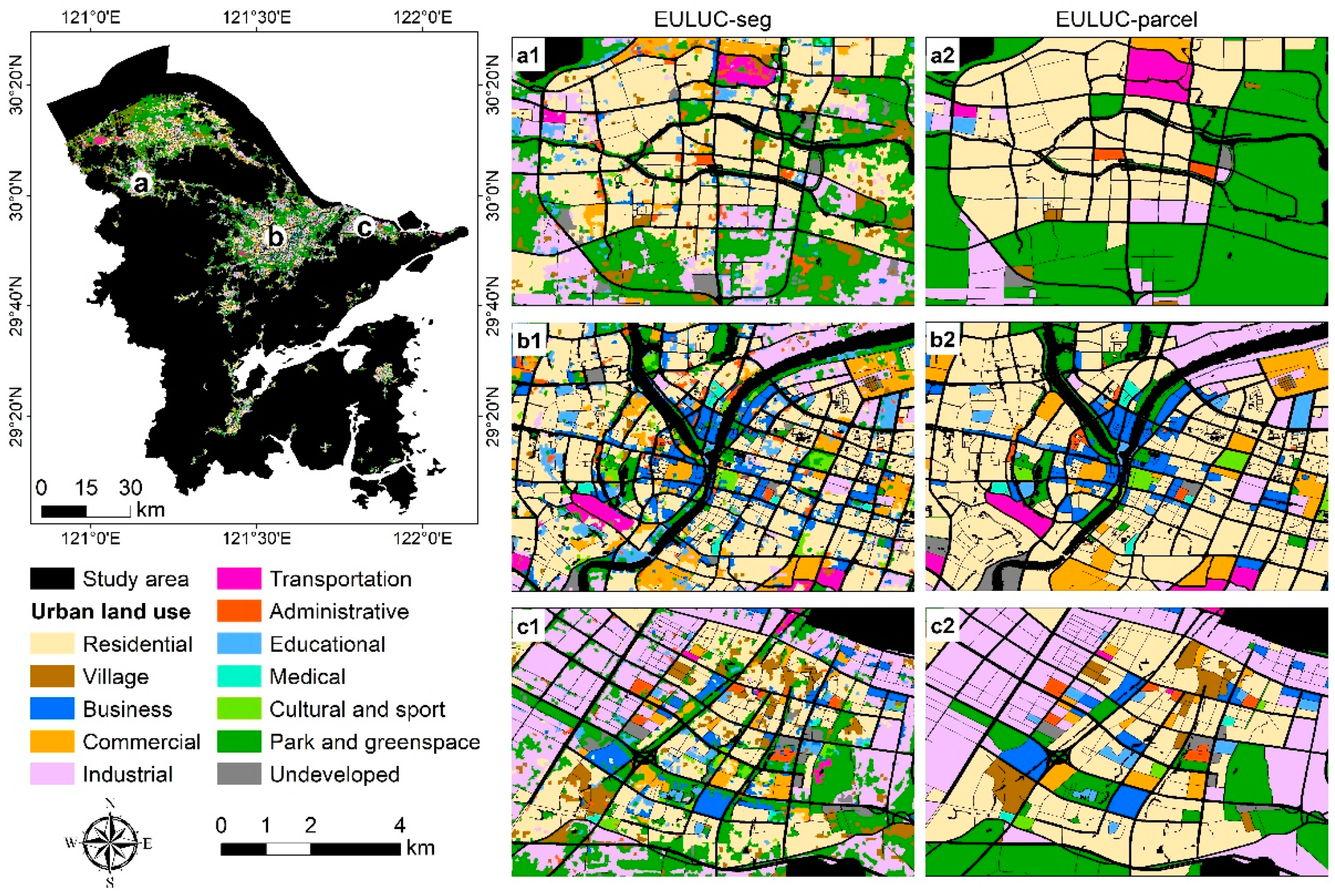
3.2.2. Mapping of Essential Urban Land Use Categories
3.2.3. Influencing Factors of Land Use Mix
4. Discussion
4.1. Advantages of the Proposed Framework
4.2. Limitations and Future Work
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gong, P.; Li, X.; Wang, J.; Bai, Y.; Chen, B.; Hu, T.; Liu, X.; Xu, B.; Yang, J.; Zhang, W.; et al. Annual Maps of Global Artificial Impervious Area (GAIA) between 1985 and 2018. Remote Sens. Environ. 2020, 236, 111510. [Google Scholar] [CrossRef]
- United Nations, Department of Economic and Social Affairs, Population Division. World Population Prospects 2019: Highlights; United Nations: New York, NY, USA, 2019; p. 40. [Google Scholar]
- United Nations. World Urbanization Prospects 2018: Highlights. 2018. Available online: https://population.un.org/wup/Publications/Files/WUP2018-Highlights.pdf (accessed on 20 August 2021).
- Grimm, N.B.; Faeth, S.H.; Golubiewski, N.E.; Redman, C.L.; Wu, J.; Bai, X.; Briggs, J.M. Global Change and the Ecology of Cities. Science 2008, 319, 756–760. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, C.Y.; Gao, B.; Huang, Q.X.; Ma, Q.; Dou, Y.Y. Environmental degradation in the urban areas of China: Evidence from multi-source remote sensing data. Remote Sens. Environ. 2017, 193, 65–75. [Google Scholar] [CrossRef]
- Chen, B.; Nie, Z.; Chen, Z.; Xu, B. Quantitative estimation of 21st-century urban greenspace changes in Chinese populous cities. Sci. Total Environ. 2017, 609, 956–965. [Google Scholar] [CrossRef]
- Song, Y.; Chen, B.; Kwan, M.-P. How does urban expansion impact people’s exposure to green environments? A comparative study of 290 Chinese cities. J. Clean. Prod. 2020, 246, 119018. [Google Scholar] [CrossRef]
- Tu, Y.; Chen, B.; Yu, L.; Xin, Q.; Gong, P.; Xu, B. How does urban expansion interact with cropland loss? A comparison of 14 Chinese cities from 1980 to 2015. Landsc. Ecol. 2021, 36, 243–263. [Google Scholar] [CrossRef]
- Van Vliet, J. Direct and Indirect Loss of Natural Area from Urban Expansion. Nat. Sustain. 2019, 2, 755–763. [Google Scholar] [CrossRef]
- McDonald, R.I.; Kareivab, P.; Forman, R.T. The Implications of Current and Future Urbanization for Global Protected Areas and Biodiversity Conservation. Biol. Conserv. 2008, 141, 1695–1703. [Google Scholar] [CrossRef]
- McKinney, M.L. Urbanization, Biodiversity, and ConservationThe Impacts of Urbanization on Native Species are Poorly Studied, but Educating a Highly Urbanized Human Population about These Impacts can Greatly Improve Species Conservation in all Ecosystems. Bioscience 2002, 52, 883–890. [Google Scholar] [CrossRef]
- Chen, B.; Tu, Y.; Song, Y.; Theobald, D.M.; Zhang, T.; Ren, Z.; Li, X.; Yang, J.; Wang, J.; Wang, X.; et al. Mapping Essential Urban Land use Categories with Open Big Data: Results for Five Metropolitan Areas in the United States of America. ISPRS J. Photogramm. Remote Sens. 2021, 178, 203–218. [Google Scholar] [CrossRef]
- Chen, B.; Xu, B.; Gong, P. Mapping Essential Urban Land Use Categories (Euluc) Using Geospatial Big Data: Progress, Challenges, and Opportunities. Big Earth Data 2021, 5, 410–441. [Google Scholar] [CrossRef]
- Gong, P.; Howarth, P.J. Land-Use Classification of SPOT HRV Data Using a Cover-Frequency Method. Int. J. Remote Sens. 1992, 13, 1459–1471. [Google Scholar] [CrossRef]
- Gong, P.; Marceau, D.J.; Howarth, P.J. A Comparison of Spatial Feature Extraction Algorithms for Land-Use Classification with SPOT HRV Data. Remote Sens. Environ. 1992, 40, 137–151. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. Use of Impervious Surface in Urban Land-Use Classification. Remote Sens. Environ. 2006, 102, 146–160. [Google Scholar] [CrossRef]
- Myint, S.W.; Wentz, E.A.; Purkis, S.J. Employing Spatial Metrics in Urban Land-Use/Land-Cover Mapping. Photogramm. Eng. Remote Sens. 2007, 73, 1403–1415. [Google Scholar] [CrossRef]
- Pacifici, F.; Chini, M.; Emery, W. A Neural Network Approach Using Multi-Scale Textural Metrics from Very High-Resolution Panchromatic Imagery for Urban land-Use Classification. Remote Sens. Environ. 2009, 113, 1276–1292. [Google Scholar] [CrossRef]
- Theobald, D.M. Development and Applications of a Comprehensive Land Use Classification and Map for the US. PLoS ONE 2014, 9, e94628. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Herold, M.; Liu, X.; Clarke, K. Spatial Metrics and Image Texture for Mapping Urban Land Use. Photogramm. Eng. Remote Sens. 2003, 69, 991–1001. [Google Scholar] [CrossRef] [Green Version]
- Petropoulos, G.P.; Kalaitzidis, C.; Vadrevu, K. Support Vector Machines and Object-Based Classification for Obtaining Land-Use/Cover Cartography from Hyperion Hyperspectral Imagery. Comput. Geosci. 2012, 41, 99–107. [Google Scholar] [CrossRef]
- Hernandez, I.E.R.; Shi, W. A Random Forests Classification Method for Urban Land-Use Mapping Integrating Spatial Metrics and Texture Analysis. Int. J. Remote Sens. 2017, 39, 1175–1198. [Google Scholar] [CrossRef]
- Tu, Y.; Chen, B.; Zhang, T.; Xu, B. Regional Mapping of Essential Urban Land Use Categories in China: A Segmentation-Based Approach. Remote Sens. 2020, 12, 1058. [Google Scholar] [CrossRef] [Green Version]
- Blaschke, T. Object Based Image Analysis for Remote Sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Liu, D.; Xia, F. Assessing Object-Based Classification: Advantages and Limitations. Remote Sens. Lett. 2010, 1, 187–194. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep Learning in Remote Sensing Applications: A Meta-Analysis and Review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban Land-Use Mapping Using a Deep Convolutional Neural Network with High Spatial Resolution Multispectral Remote Sensing Imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P. An Object-Based Convolutional Neural Network (OCNN) for Urban Land Use Classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Qi, Z.; Li, X.; Yeh, A.G.-O. Integration of Convolutional Neural Networks and Object-Based Post-Classification Refinement for Land Use and Land Cover Mapping with Optical and SAR Data. Remote Sens. 2019, 11, 690. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, S.; Vargas-Muñoz, J.E.; Tuia, D. Understanding Urban Landuse from the Above and Ground Perspectives: A Deep Learning, Multimodal Solution. Remote Sens. Environ. 2019, 228, 129–143. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Sargent, I.M.J.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for Land Cover and Land Use Classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef] [Green Version]
- Bao, H.; Ming, D.; Guo, Y.; Zhang, K.; Zhou, K.; Du, S. DFCNN-Based Semantic Recognition of Urban Functional Zones by Integrating Remote Sensing Data and POI Data. Remote Sens. 2020, 12, 1088. [Google Scholar] [CrossRef] [Green Version]
- Atwell, W.; Rojdev, K.; Aghara, S.; Sriprisan, S. Mitigating the Effects of the Space Radiation Environment: A Novel Approach of Using Graded-Z Materials. In AIAA SPACE 2013 Conference & Exposition; American Institute of Aeronautics and Astronautics: Reston, VI, USA, 2013. [Google Scholar] [CrossRef]
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-Pixel Vs. Object-Based Classification of Urban Land Cover Extraction Using High Spatial Resolution Imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Zhong, Y.; Su, Y.; Wu, S.; Zheng, Z.; Zhao, J.; Ma, A.; Zhu, Q.; Ye, R.; Li, X.; Pellikka, P.; et al. Open-Source Data-Driven Urban Land-Use Mapping Integrating Point-Line-Polygon Semantic Objects: A Case Study of Chinese Cities. Remote Sens. Environ. 2020, 247, 111838. [Google Scholar] [CrossRef]
- Erol, H.; Akdeniz, F. A Per-Field Classification Method Based on Mixture Distribution Models and an Application to Landsat Thematic Mapper Data. Int. J. Remote Sens. 2005, 26, 1229–1244. [Google Scholar] [CrossRef]
- Liu, X.; Long, Y. Automated Identification and Characterization of Parcels with OpenStreetMap and Points of Interest. Environ. Plan. B Plan. Des. 2015, 43, 341–360. [Google Scholar] [CrossRef]
- Hu, T.; Yang, J.; Li, X.; Gong, P. Mapping Urban Land Use by Using Landsat Images and Open Social Data. Remote Sens. 2016, 8, 151. [Google Scholar] [CrossRef]
- Gong, P.; Chen, B.; Li, X.; Liu, H.; Wang, J.; Bai, Y.; Chen, J.; Chen, X.; Fang, L.; Feng, S.; et al. Mapping Essential Urban Land Use Categories in China (EULUC-China): Preliminary Results for 2018. Sci. Bull. 2020, 65, 182–187. [Google Scholar] [CrossRef] [Green Version]
- Polikar, R. Ensemble Learning. In Ensemble Machine Learning; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–34. [Google Scholar]
- Sagi, O.; Rokach, L. Ensemble Learning: A Survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, 1249. [Google Scholar] [CrossRef]
- Liu, H.; Gong, P.; Wang, J.; Wang, X.; Ning, G.; Xu, B. Production of Global Daily Seamless Data Cubes and Quantification of Global Land Cover Change from 1985 to 2020—Imap World 1.0. Remote Sens. Environ. 2021, 258, 112364. [Google Scholar] [CrossRef]
- Fan, R.; Feng, R.; Wang, L.; Yan, J.; Zhang, X. Semi-MCNN: A Semisupervised Multi-CNN Ensemble Learning Method for Urban Land Cover Classification Using Submeter HRRS Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4973–4987. [Google Scholar] [CrossRef]
- Cai, Y.; Li, X.; Zhang, M.; Lin, H. Mapping Wetland Using the Object-Based Stacked Generalization Method Based on Multi-temporal Optical and SAR Data. Int. J. Appl. Earth Obs. Geoinf. 2020, 92, 102164. [Google Scholar] [CrossRef]
- Wen, L.; Hughes, M. Coastal Wetland Mapping Using Ensemble Learning Algorithms: A Comparative Study of Bagging, Boosting and Stacking Techniques. Remote Sens. 2020, 12, 1683. [Google Scholar] [CrossRef]
- Wang, X.; Liu, S.; Du, P.; Liang, H.; Xia, J.; Li, Y. Object-Based Change Detection in Urban Areas from High Spatial Resolution Images Based on Multiple Features and Ensemble Learning. Remote Sens. 2018, 10, 276. [Google Scholar] [CrossRef] [Green Version]
- Cui, B.; Zhang, Y.; Yan, L.; Wei, J.; Wu, H. An Unsupervised SAR Change Detection Method Based on Stochastic Subspace Ensemble Learning. Remote Sens. 2019, 11, 1314. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Merlin, L.; Rodriguez, D. Comparing Measures of Urban Land Use Mix. Comput. Environ. Urban Syst. 2013, 42, 1–13. [Google Scholar] [CrossRef]
- Tian, L.; Liang, Y.; Zhang, B. Measuring Residential and Industrial Land Use Mix in the Peri-Urban Areas of China. Land Use Policy 2017, 69, 427–438. [Google Scholar] [CrossRef]
- Abdullahi, S.; Pradhan, B.; Mansor, S.; Shariff, A.R.M. GIS-Based Modeling for the Spatial Measurement and Evaluation of Mixed Land Use Development for a Compact City. GIScience Remote Sens. 2015, 52, 18–39. [Google Scholar] [CrossRef]
- He, J.; Li, X.; Liu, P.; Wu, X.; Zhang, J.; Zhang, D.; Liu, X.; Yao, Y. Accurate Estimation of the Proportion of Mixed Land Use at the Street-Block Level by Integrating High Spatial Resolution Images and Geospatial Big Data. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6357–6370. [Google Scholar] [CrossRef]
- Zhuo, Y.; Zheng, H.; Wu, C.; Xu, Z.; Li, G.; Yu, Z. Compatibility Mix Degree Index: A Novel Measure to Characterize Urban Land Use Mix Pattern. Comput. Environ. Urban Syst. 2019, 75, 49–60. [Google Scholar] [CrossRef]
- Jacobs, J. The Death and Life of Great American Cities; Vintage: New York, NY, USA, 2016. [Google Scholar]
- Kitamura, R.; Mokhtarian, P.L.; Daidet, L. A Micro-Analysis of Land Use and Travel in Five Neighborhoods in the San Francisco Bay Area. Transportation 1997, 24, 125–158. [Google Scholar] [CrossRef]
- Duncan, M.J.; Winkler, E.; Sugiyama, T.; Cerin, E.; Dutoit, L.; Leslie, E.; Owen, N. Relationships of Land Use Mix with Walking for Transport: Do Land Uses and Geographical Scale Matter? J. Hered. 2010, 87, 782–795. [Google Scholar] [CrossRef] [Green Version]
- Jia, P.; Pan, X.; Liu, F.; He, P.; Zhang, W.; Liu, L.; Zou, Y.; Chen, L. Land Use Mix in the Neighbourhood and Childhood Obesity. Obes. Rev. 2021, 22, 13098. [Google Scholar] [CrossRef]
- Frank, L.D.; Schmid, T.L.; Sallis, J.F.; Chapman, J.; Saelens, B.E. Linking Objectively Measured Physical Activity with Objectively Measured Urban form: Findings from SMARTRAQ. Am. J. Prev. Med. 2005, 28, 117–125. [Google Scholar] [CrossRef] [PubMed]
- Kong, H.; Sui, D.Z.; Tong, X.; Wang, X. Paths to Mixed-Use Development: A Case Study of Southern Changping in Beijing, China. Cities 2015, 44, 94–103. [Google Scholar] [CrossRef]
- Comer, D.; Greene, J.S. The Development and Application of a Land Use Diversity Index for Oklahoma City, OK. Appl. Geogr. 2015, 60, 46–57. [Google Scholar] [CrossRef]
- Li, X.; Gong, P.; Zhou, Y.; Wang, J.; Bai, Y.; Chen, B.; Hu, T.; Xiao, Y.; Xu, B.; Yang, J.; et al. Mapping Global Urban Boundaries from the Global Artificial Impervious Area (GAIA) Data. Environ. Res. Lett. 2020, 15, 094044. [Google Scholar] [CrossRef]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable Classification with Limited Sample: Transferring a 30-m Resolution Sample Set Collected in 2015 to Mapping 10-m Resolution Global Land Cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef] [Green Version]
- Achanta, R.; Susstrunk, S. Superpixels and Polygons Using Simple Non-Iterative Clustering. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4895–4904, ISBN 1063-6919. [Google Scholar]
- Bhabatosh, C. Digital Image Processing and Analysis; PHI Learning Pvt. Ltd.: New Delhi, India, 1977. [Google Scholar]
- Xu, B.; Gong, P.; Seto, E.; Spear, R. Comparison of Gray-Level Reduction and Different Texture Spectrum Encoding Methods for Land-Use Classification Using a Panchromatic Ikonos Image. Photogramm. Eng. Remote Sens. 2003, 69, 529–536. [Google Scholar] [CrossRef]
- Wu, S.-S.; Qiu, X.; Usery, E.L.; Wang, L. Using Geometrical, Textural, and Contextual Information of Land Parcels for Classification of Detailed Urban Land Use. Ann. Assoc. Am. Geogr. 2009, 99, 76–98. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Kupidura, P. The Comparison of Different Methods of Texture Analysis for Their Efficacy for Land Use Classification in Satellite Imagery. Remote Sens. 2019, 11, 1233. [Google Scholar] [CrossRef] [Green Version]
- Erickson, N.; Mueller, J.; Shirkov, A.; Zhang, H.; Larroy, P.; Li, M.; Smola, A. Autogluon-Tabular: Robust and Accurate Automl for Structured Data. arXiv 2020, arXiv:2003.06505. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient Boosting with Categorical Features Support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. 2017. Available online: https://proceedings.neurips.cc/paper/2017/file/6449f44a102fde848669bdd9eb6b76fa-Paper.pdf (accessed on 20 August 2021).
- Yegnanarayana, B. Artificial Neural Networks; PHI Learning Pvt. Ltd.: New Delhi, India, 2009. [Google Scholar]
- Congalton, R.G. A Review of Assessing the Accuracy of Classifications of Remotely Sensed Data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Jiao, J.; Rollo, J.; Fu, B. The Hidden Characteristics of Land-Use Mix Indices: An Overview and Validity Analysis Based on the Land Use in Melbourne, Australia. Sustainability 2021, 13, 1898. [Google Scholar] [CrossRef]
- Xing, H.; Meng, Y.; Shi, Y. A Dynamic Human Activity-Driven Model for Mixed Land Use Evaluation Using Social Media Data. Trans. GIS 2018, 22, 1130–1151. [Google Scholar] [CrossRef]
- Lang, W.; Long, Y.; Chen, T. Rediscovering Chinese Cities through the Lens of Land-Use Patterns. Land Use Policy 2018, 79, 362–374. [Google Scholar] [CrossRef]
- Yue, Y.; Zhuang, Y.; Yeh, A.G.-O.; Xie, J.-Y.; Ma, C.-L.; Li, Q.-Q. Measurements of POI-Based Mixed Use and Their Relationships with Neighbourhood Vibrancy. Int. J. Geogr. Inf. Sci. 2017, 31, 658–675. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.-T.; Chan, F.K.S.; Griffiths, J.A. City profile: Ningbo. Cities 2015, 42, 97–108. [Google Scholar] [CrossRef]
- Liang, H.; Guo, Z.; Wu, J.; Chen, Z. GDP Spatialization in Ningbo City based on NPP/VIIRS Night-Time Light and Auxiliary Data Using Random Forest Regression. Adv. Space Res. 2020, 65, 481–493. [Google Scholar] [CrossRef]
- Liu, Y.; Feng, Y.; Zhao, Z.; Zhang, Q.; Su, S. Socioeconomic Drivers of Forest Loss and Fragmentation: A Comparison between Different Land Use Planning Schemes and Policy Implications. Land Use Policy 2016, 54, 58–68. [Google Scholar] [CrossRef]
- Han, Y.; Yu, C.; Feng, Z.; Du, H.; Huang, C.; Wu, K. Construction and Optimization of Ecological Security Pattern Based on Spatial Syntax Classification—Taking Ningbo, China, as an Example. Land 2021, 10, 380. [Google Scholar] [CrossRef]
- Zhang, C.; Zhong, S.; Wang, X.; Shen, L.; Liu, L.; Liu, Y. Land Use Change in Coastal Cities during the Rapid Urbanization Period from 1990 to 2016: A Case Study in Ningbo City, China. Sustainability 2019, 11, 2122. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Huang, B.; Xu, B. Multi-Source Remotely Sensed Data Fusion for Improving Land Cover Classification. ISPRS J. Photogramm. Remote Sens. 2017, 124, 27–39. [Google Scholar] [CrossRef]
- Chen, B.; Huang, B.; Xu, B. Fine Land Cover Classification Using Daily Synthetic Landsat-Like Images at 15-m Resolution. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2359–2363. [Google Scholar] [CrossRef]
- Tu, Y.; Lang, W.; Yu, L.; Li, Y.; Jiang, J.; Qin, Y.; Wu, J.; Chen, T.; Xu, B. Improved Mapping Results of 10 m Resolution Land Cover Classification in Guangdong, China Using Multisource Remote Sensing Data With Google Earth Engine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5384–5397. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level I | Level II | Number of Samples |
|---|---|---|
| 01 Residential | 0101 Residential | 83 |
| 0102 Village | 50 | |
| 02 Commercial | 0201 Business | 51 |
| 0202 Commercial | 33 | |
| 03 Industrial | 0301 Industrial | 48 |
| 04 Transportation | 0401 Transportation | 20 |
| 05 Public | 0501 Administrative | 28 |
| 0502 Educational | 43 | |
| 0503 Medical | 15 | |
| 0504 Sport and cultural | 21 | |
| 0505 Park and greenspace | 73 | |
| 0506 Undeveloped | 20 | |
| Total | 485 |
| Aspect | Description | Variable | Data Source | Spatial Resolution (m) |
|---|---|---|---|---|
| Geography | Mean of elevation | elevation | SRTM DEM 2 | 30 |
| Mean of NDVI 1 | ndvi | Sentinel-2 | 10 | |
| Fraction of clay | fra_clay | Soil texture data | 1000 | |
| Fraction of sand | fra_sand | Soil texture data | 1000 | |
| Fraction of silt | fra_silt | Soil texture data | 1000 | |
| Socioeconomy | Number of business points | business | Baidu POI 3 | / |
| Number of commercial points | commercial | Baidu POI 3 | / | |
| Mean of population | pop | WorldPop | 100 | |
| Mean of nighttime light | ntl | Luojia-1 | 130 | |
| Mean of house price | house_price | Lianjia | / | |
| Accessibility | Distance to bus station | dis_bus | Baidu POI 3 | / |
| Distance to subway station | dis_subway | Baidu POI 3 | / | |
| Distance to railway | dis_ railway | OSM 4 | ±20 | |
| Distance to major road | dis_major_road | OSM 4 | ±20 | |
| Distance to minor road | dis_minor_road | OSM 4 | ±20 | |
| Distance to track road | dis_track_road | OSM 4 | ±20 | |
| Landscape | Area of parcel | area | / | / |
| Shape index of parcel | shape | / | / | |
| Richness index of parcel | richness | / | / |
| Category | Data Source | Resolution (m) | Year |
|---|---|---|---|
| Synthetic Aperture Radar | Sentinel-1 | 10 | 2018 |
| Multispectral | Sentinel-2 | 10–60 | 2018 |
| Nighttime light | Luojia-1 | 130 | 2018 |
| Population | WorldPop | 100 | 2018 |
| Points of Interest | Baidu POI | / | 2018 |
| Model | Training Accuracy (%) | Training Time (s) | Stack Level |
|---|---|---|---|
| Random Forest | 80.29 | 85.57 | 1 |
| Extremely Randomized Trees | 80.88 | 68.46 | 1 |
| CatBoost | 82.65 | 232.77 | 1 |
| LightGBM | 83.82 | 168.00 | 1 |
| Neural Networks | 86.47 | 4271.07 | 1 |
| Ensemble | 86.47 | 4271.52 | 2 |
| Model | Training Accuracy (%) | Training Time (s) | Stack Level |
|---|---|---|---|
| Random Forest | 69.41 | 75.01 | 1 |
| Extremely Randomized Trees | 72.35 | 58.75 | 1 |
| CatBoost | 72.06 | 423.39 | 1 |
| LightGBM | 74.41 | 170.89 | 1 |
| Neural Networks | 75.29 | 4356.12 | 1 |
| Ensemble | 77.94 | 5279.67 | 2 |
| Level I | Indices | |||||||
|---|---|---|---|---|---|---|---|---|
| Complexity index | ||||||||
| Count | Mean | STD | 0% | 25% | 50% | 75% | 100% | |
| 01 | 1767 | 0.37 | 0.36 | 0.00 | 0.00 | 0.33 | 0.70 | 1.00 |
| 02 | 570 | 0.46 | 0.38 | 0.00 | 0.00 | 0.53 | 0.80 | 1.00 |
| 03 | 722 | 0.56 | 0.29 | 0.00 | 0.40 | 0.61 | 0.76 | 1.00 |
| 04 | 110 | 0.49 | 0.35 | 0.00 | 0.00 | 0.60 | 0.80 | 0.99 |
| 05 | 2493 | 0.31 | 0.37 | 0.00 | 0.00 | 0.00 | 0.66 | 1.00 |
| Total | 5662 | 0.38 | 0.37 | 0.00 | 0.00 | 0.36 | 0.71 | 1.00 |
| Dominant rate | ||||||||
| Count | Mean | STD | 0% | 25% | 50% | 75% | 100% | |
| 01 | 1767 | 0.85 | 0.17 | 0.32 | 0.72 | 0.93 | 1.00 | 1.00 |
| 02 | 570 | 0.82 | 0.18 | 0.36 | 0.68 | 0.86 | 1.00 | 1.00 |
| 03 | 722 | 0.76 | 0.17 | 0.27 | 0.63 | 0.79 | 0.90 | 1.00 |
| 04 | 110 | 0.73 | 0.23 | 0.31 | 0.51 | 0.73 | 1.00 | 1.00 |
| 05 | 2493 | 0.87 | 0.18 | 0.31 | 0.74 | 1.00 | 1.00 | 1.00 |
| Total | 5662 | 0.84 | 0.18 | 0.27 | 0.70 | 0.92 | 1.00 | 1.00 |
| Component | Percentage of Explained Variances (%) | Important Variables | Physical Meanings |
|---|---|---|---|
| PC1 | 39.17 | dis_subway | accessibility |
| PC2 | 16.59 | dis_subway | accessibility |
| PC3 | 11.41 | dis_track_road, dis_rail | accessibility |
| PC4 | 7.01 | ndvi | geography |
| PC5 | 4.09 | richness, shape | landscape |
| PC6 | 3.99 | fra_silt | geography |
| PC7 | 3.74 | dis_major_road | accessibility |
| PC8 | 3.37 | house_price, shape | socioeconomy and landscape |
| PC9 | 2.43 | dis_major_road, house_price | accessibility and socioeconomy |
| PC10 | 1.89 | dis_rail | accessibility |
| Total | 93.68 |
| Coefficient | STD | p Value | CI95 | ||
|---|---|---|---|---|---|
| LL | UL | ||||
| Intercept | 41.40 *** | 0.55 | 0.000 | 40.33 | 42.48 |
| PC1 | 5.17 *** | 1.43 | 0.000 | 2.37 | 7.97 |
| PC2 | 6.21 ** | 2.19 | 0.005 | 1.91 | 10.52 |
| PC3 | −6.51 * | 2.65 | 0.014 | −11.7 | −1.32 |
| PC4 | 8.70 * | 3.38 | 0.010 | 2.07 | 15.34 |
| PC5 | −7.23 | 4.42 | 0.102 | −15.88 | 1.43 |
| PC6 | 10.80 * | 4.48 | 0.016 | 2.02 | 19.58 |
| PC7 | −8.69 | 4.62 | 0.060 | −17.76 | 0.37 |
| PC8 | −20.52 *** | 4.87 | 0.000 | −30.06 | −10.98 |
| PC9 | −8.91 | 5.73 | 0.120 | −20.15 | 2.33 |
| PC10 | 8.68 | 6.51 | 0.183 | −4.09 | 21.45 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tu, Y.; Chen, B.; Lang, W.; Chen, T.; Li, M.; Zhang, T.; Xu, B. Uncovering the Nature of Urban Land Use Composition Using Multi-Source Open Big Data with Ensemble Learning. Remote Sens. 2021, 13, 4241. https://doi.org/10.3390/rs13214241
Tu Y, Chen B, Lang W, Chen T, Li M, Zhang T, Xu B. Uncovering the Nature of Urban Land Use Composition Using Multi-Source Open Big Data with Ensemble Learning. Remote Sensing. 2021; 13(21):4241. https://doi.org/10.3390/rs13214241
Chicago/Turabian StyleTu, Ying, Bin Chen, Wei Lang, Tingting Chen, Miao Li, Tao Zhang, and Bing Xu. 2021. "Uncovering the Nature of Urban Land Use Composition Using Multi-Source Open Big Data with Ensemble Learning" Remote Sensing 13, no. 21: 4241. https://doi.org/10.3390/rs13214241