
Emulation of Sun-Induced Fluorescence from Radiance Data Recorded by the HyPlant Airborne Imaging Spectrometer

 , , ,
, , ,  and
and 
Abstract
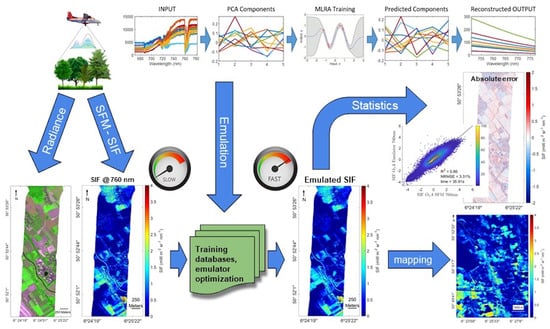
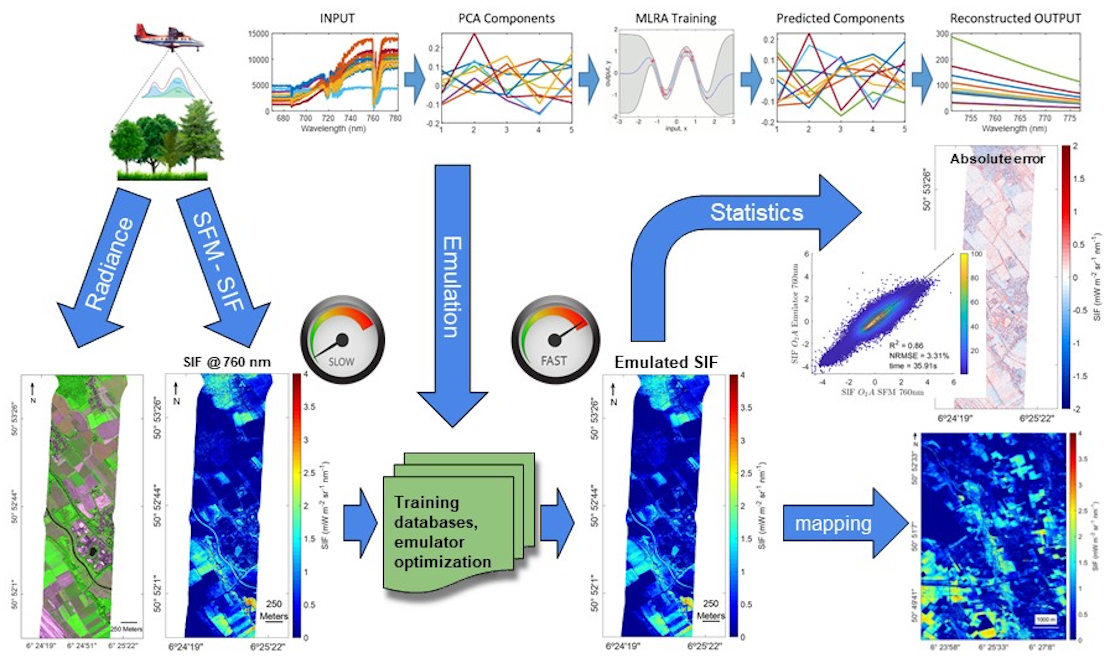
:
1. Introduction
2. Methods and Materials
2.1. Principles of Hyperspectral Data Emulation
2.2. HyPlant Data and SIF Retrieval Using the Spectral Fitting Method
2.3. Machine Learning Algorithms for Emulation
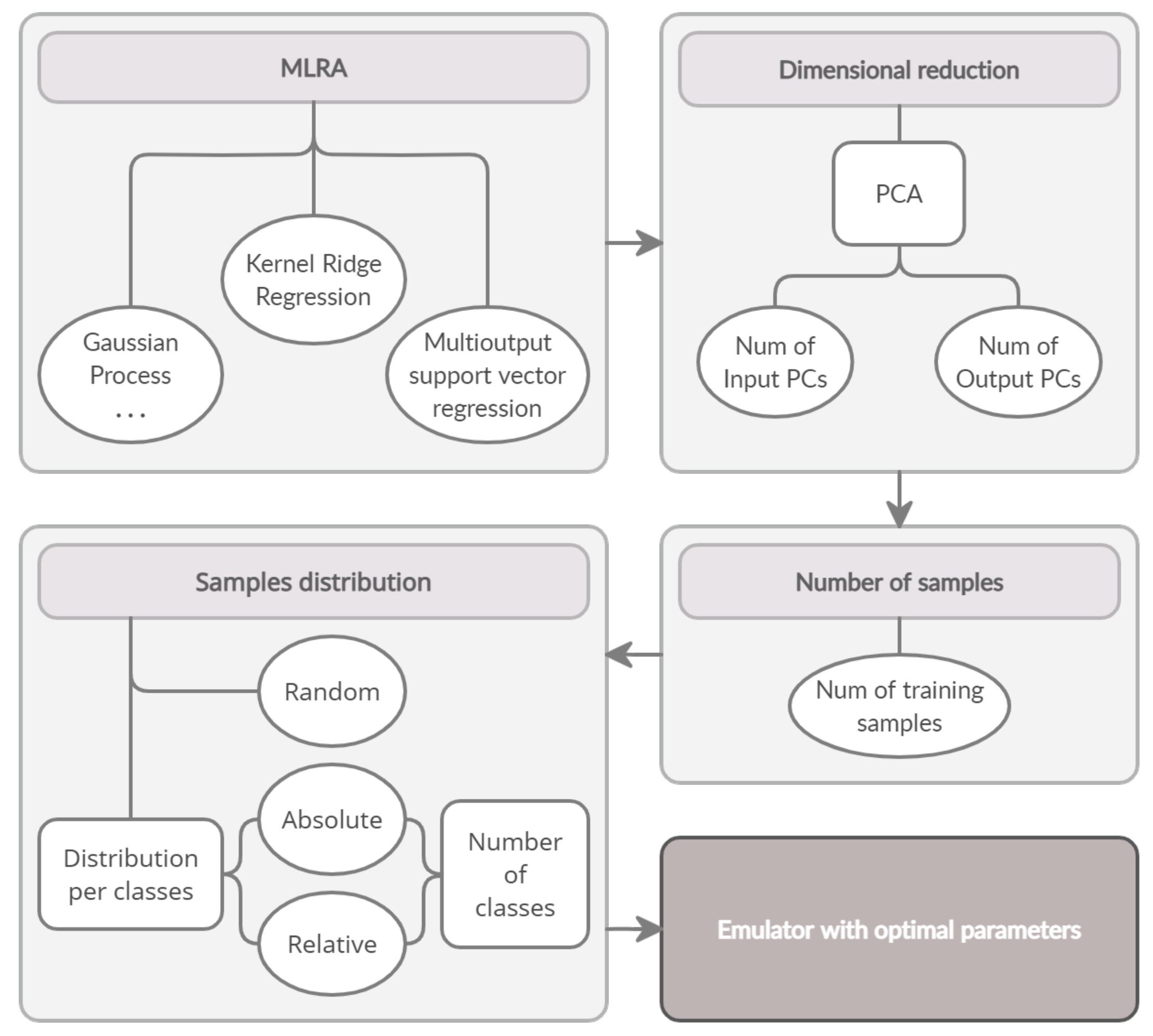
2.4. Experimental Setup
- 1.
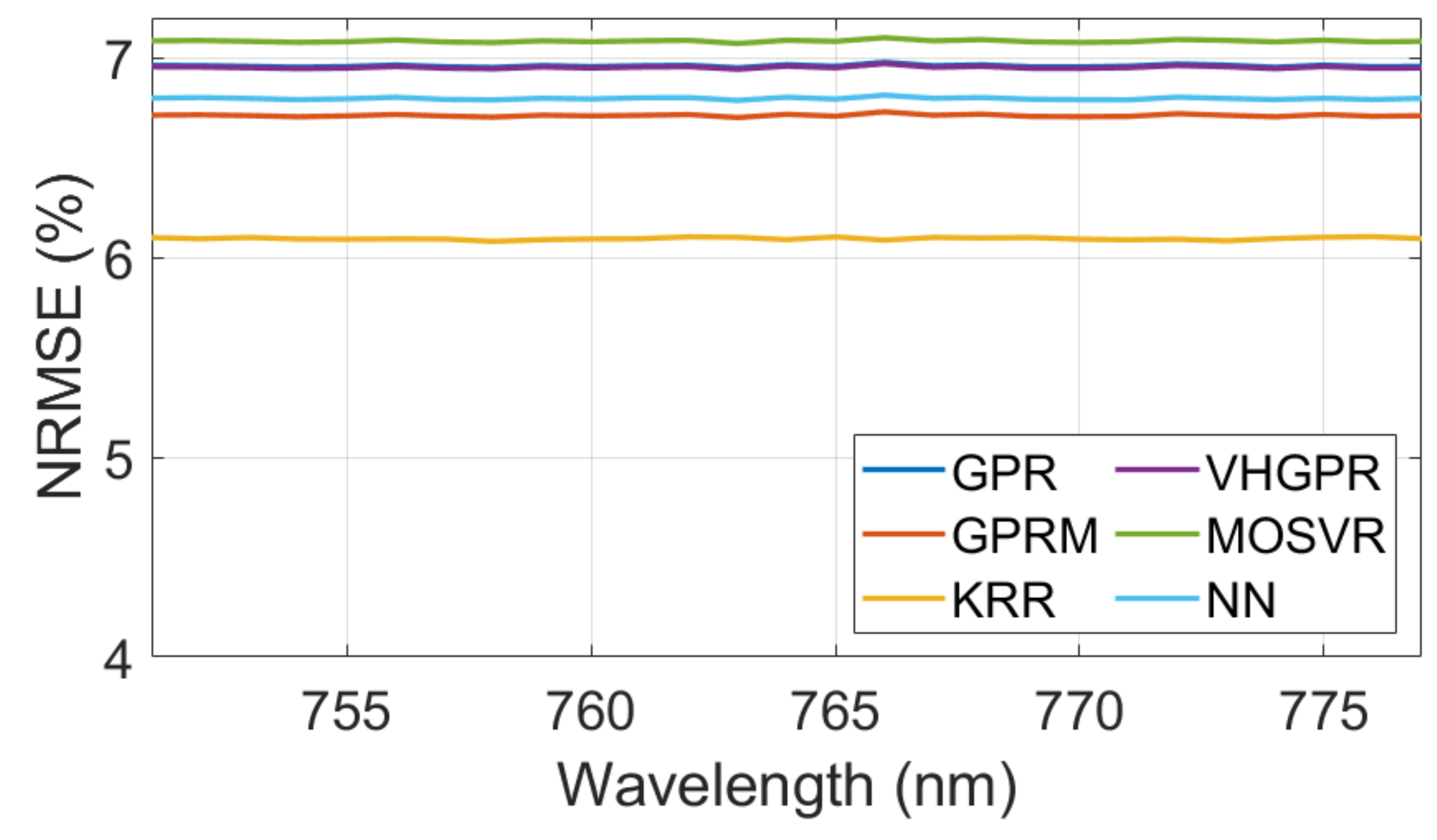
- The selected MLRAs have been evaluated using the training dataset. The default training settings were: 1000 random training samples, 20 PCs for the input, and 5 PCs for the output data.
- 2.
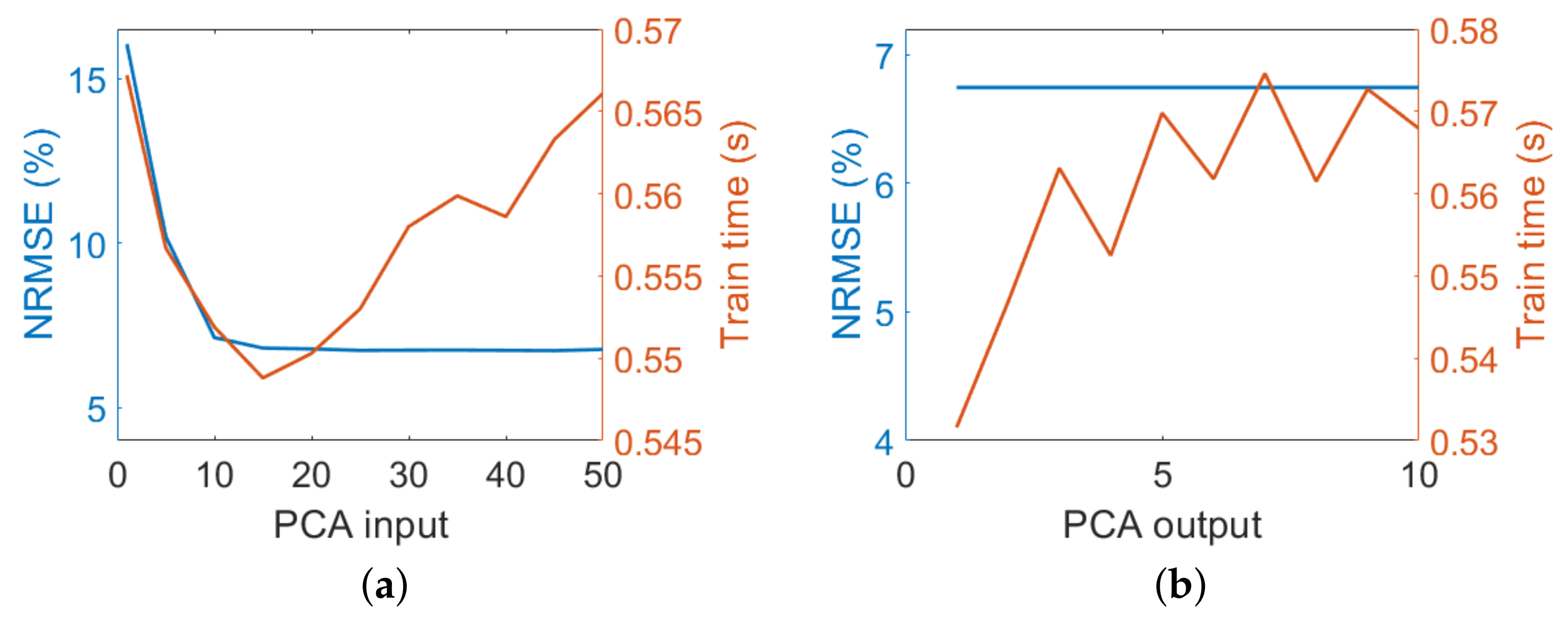
- PCAs were applied to the input and output data to reduce the feature space of both variables. To determine the optimal number of components, we varied the number of PCs in the input (from 1 to 50 PCs in steps of 5 while keeping the number of PCs in the output data constant at 5) and output data (from 1 to 10 PCs in steps of 1 while keeping the number of PCs in the input data constant at 20).
- 3.
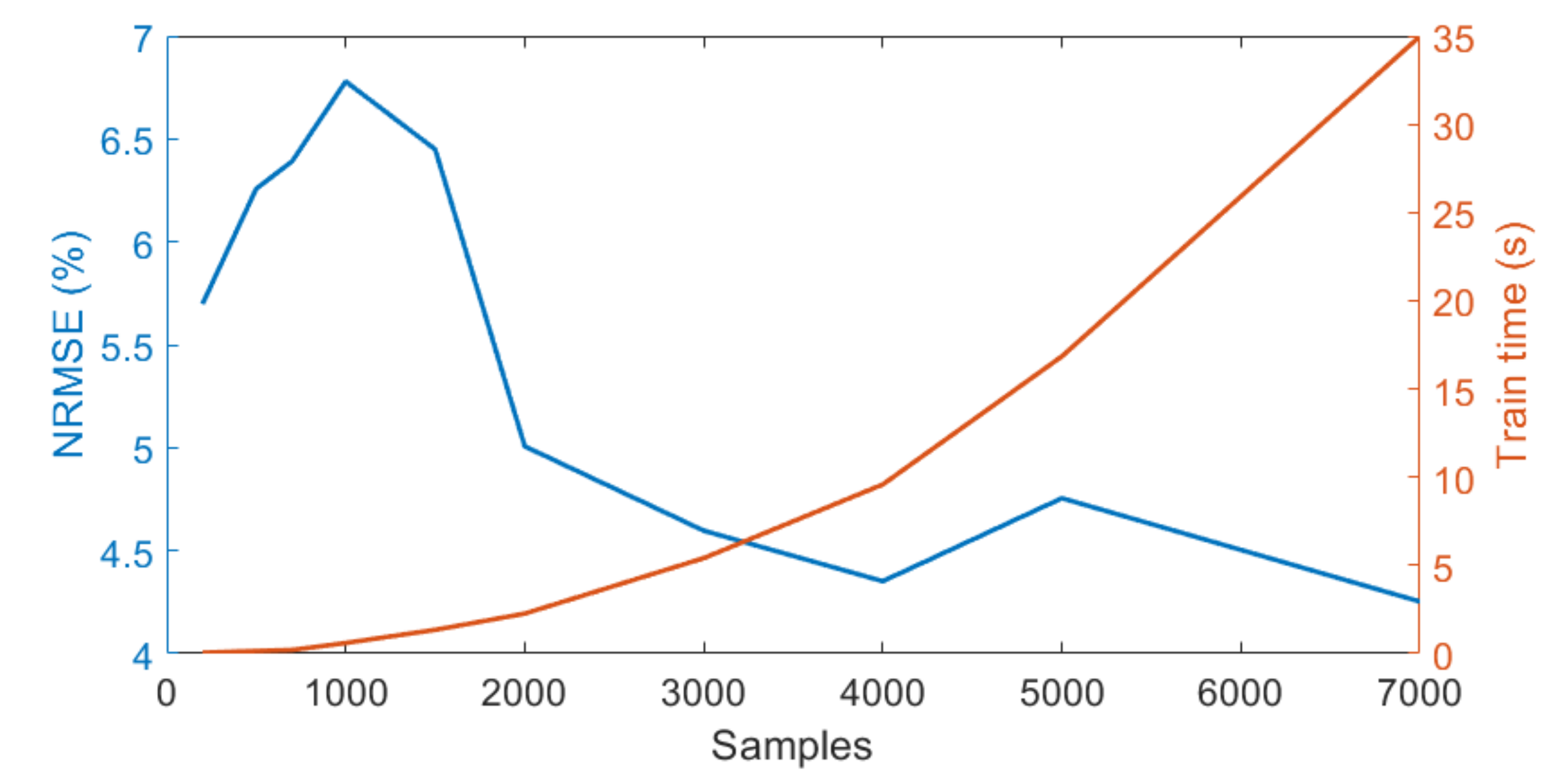
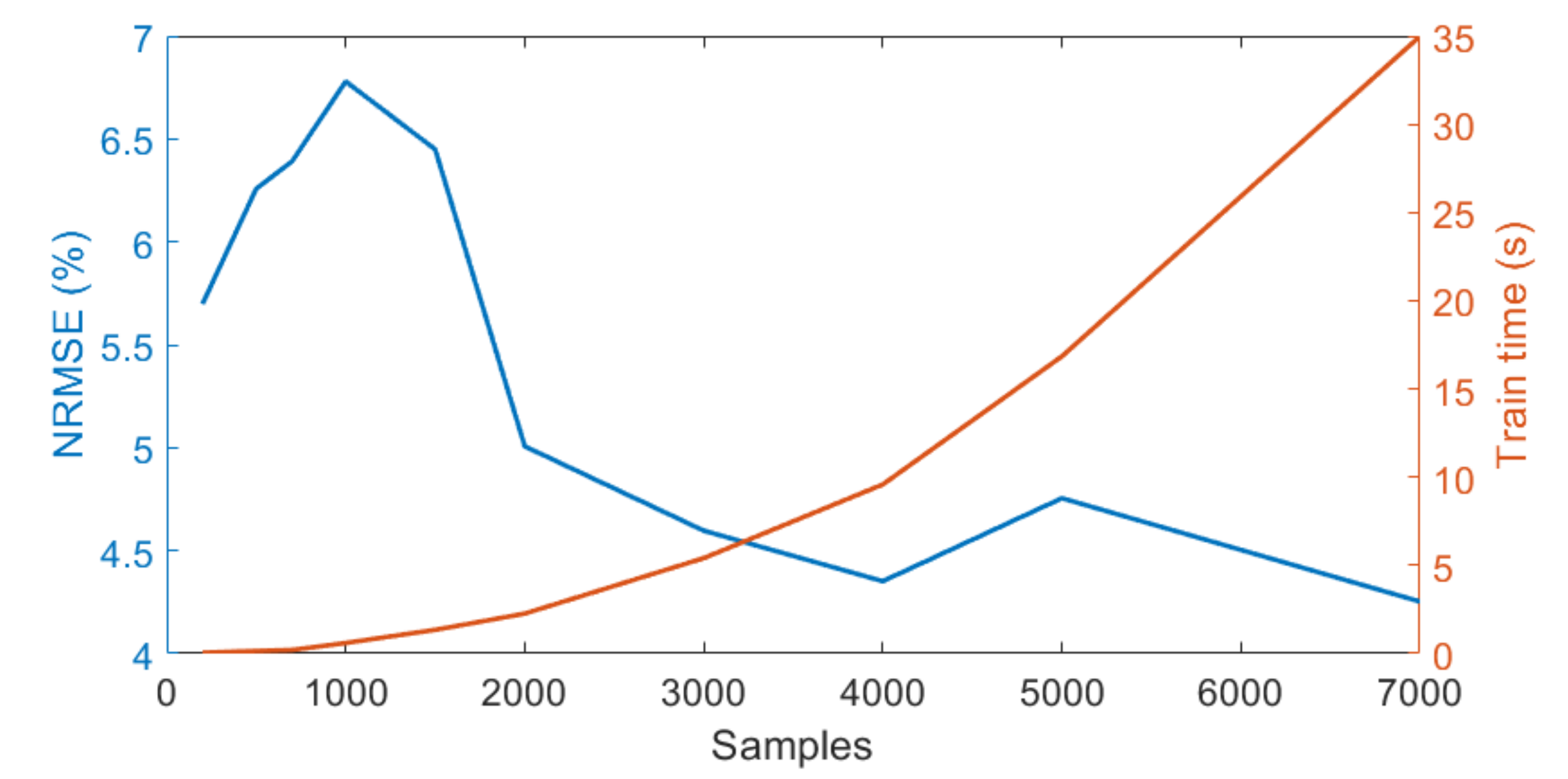
- To investigate the effect of the number of samples on emulator performance we varied the number of samples from 200 to 7000 (200, 500, 700, 1000, 1500, 2000, 3000, 4000, 5000, 7000) while we fixed the number of PCs in the input and output data to 20 and 5, respectively.
- 4.
- The effect of the three different sampling strategies on emulator performance has been analyzed: (1) random sampling without classification, and segmented sampling according to (2) absolute number of pixels per class, and (3) relative number of pixels per class. Additionally, the impact of the number of classes used in unsupervised classification has also been tested by varying it from 1 to 50 classes (1, 2, 5, 10, 15, 20, 30, 40, 50).
2.5. Emulation Validation
2.6. Mapping Emulated SIF
2.7. Developed Software for Emulation Applications
3. Results
3.1. Analysis of SIF Emulation Strategies
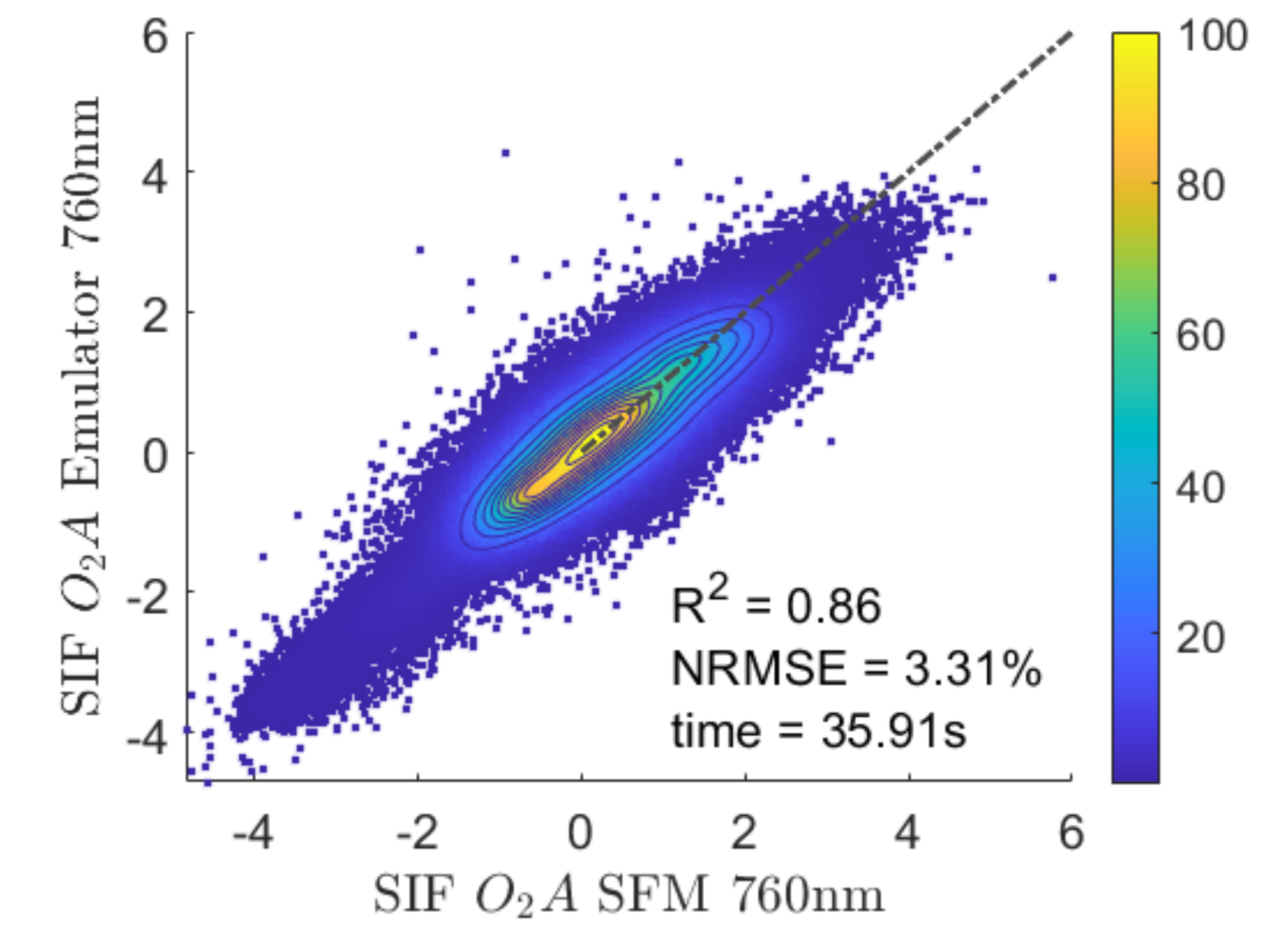
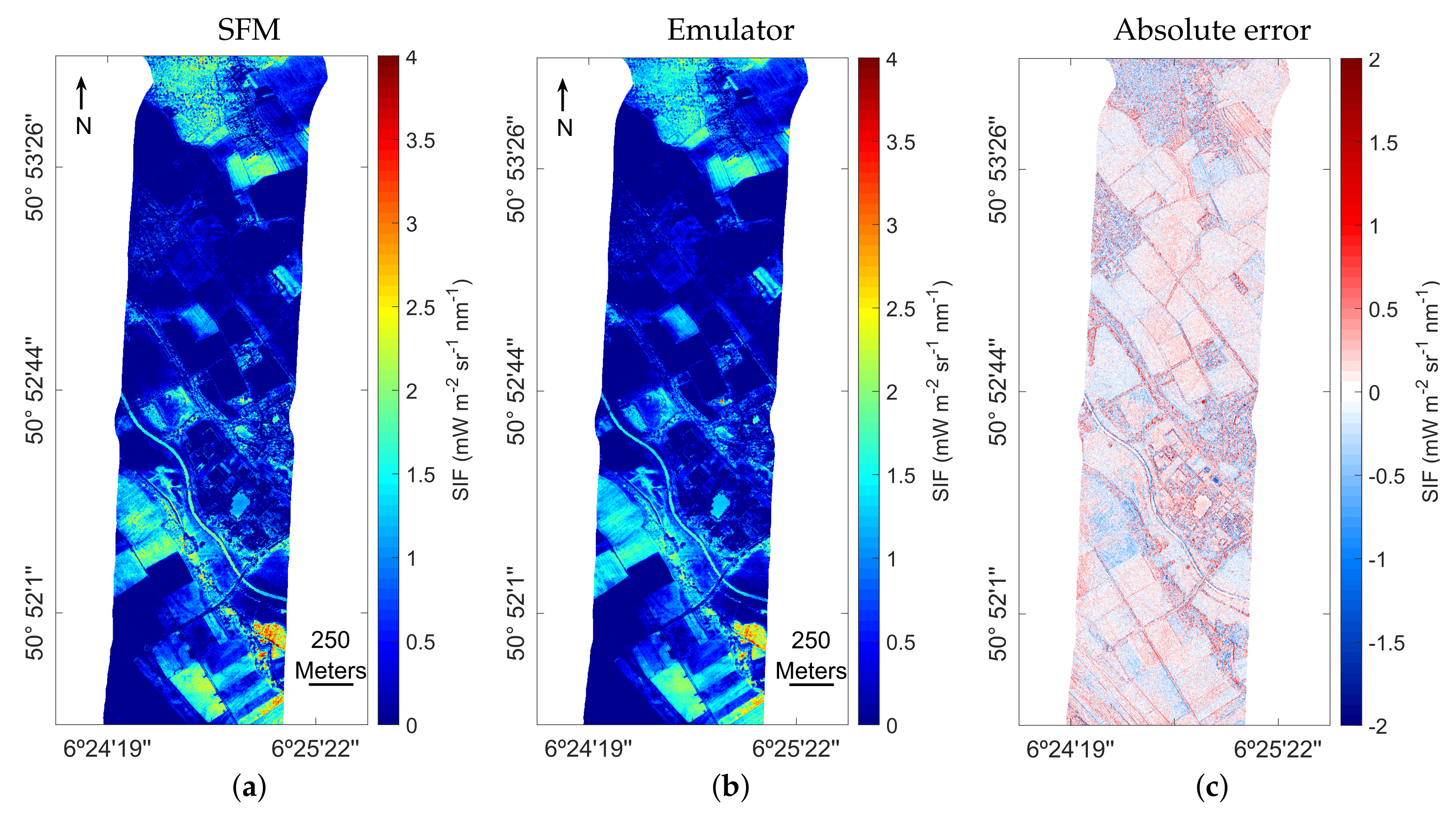
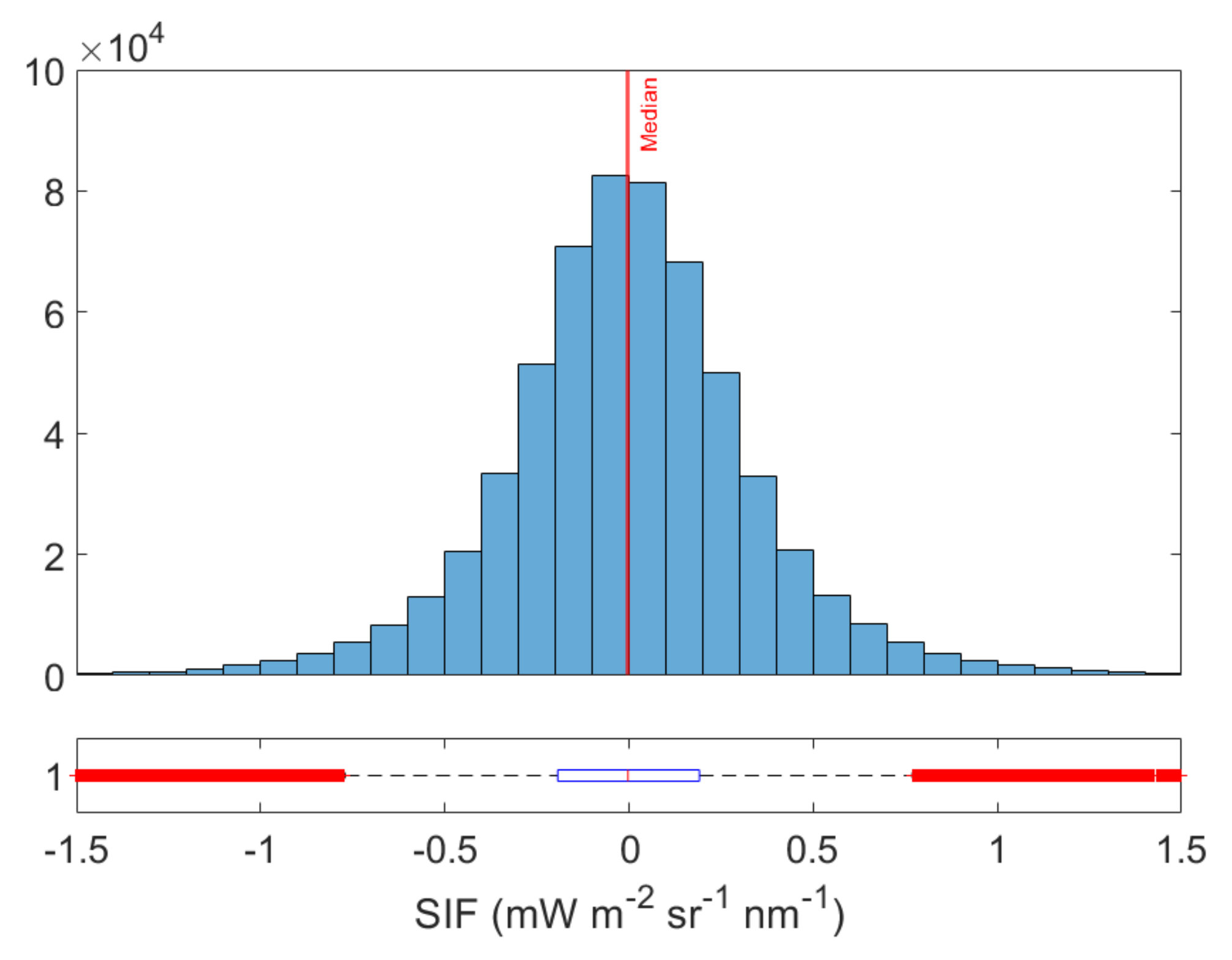
3.2. Application of the Emulator to a Subset of a Flight Line
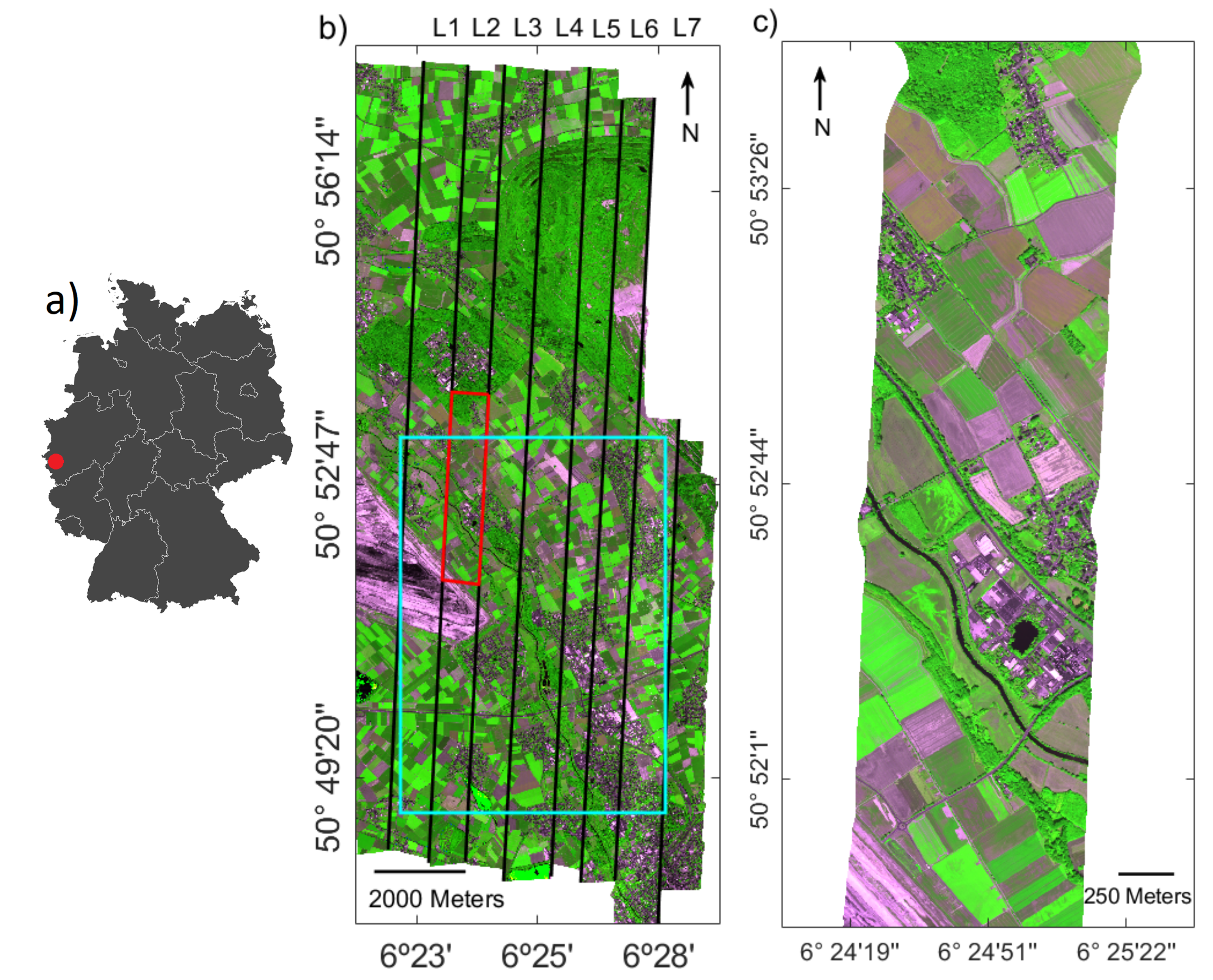
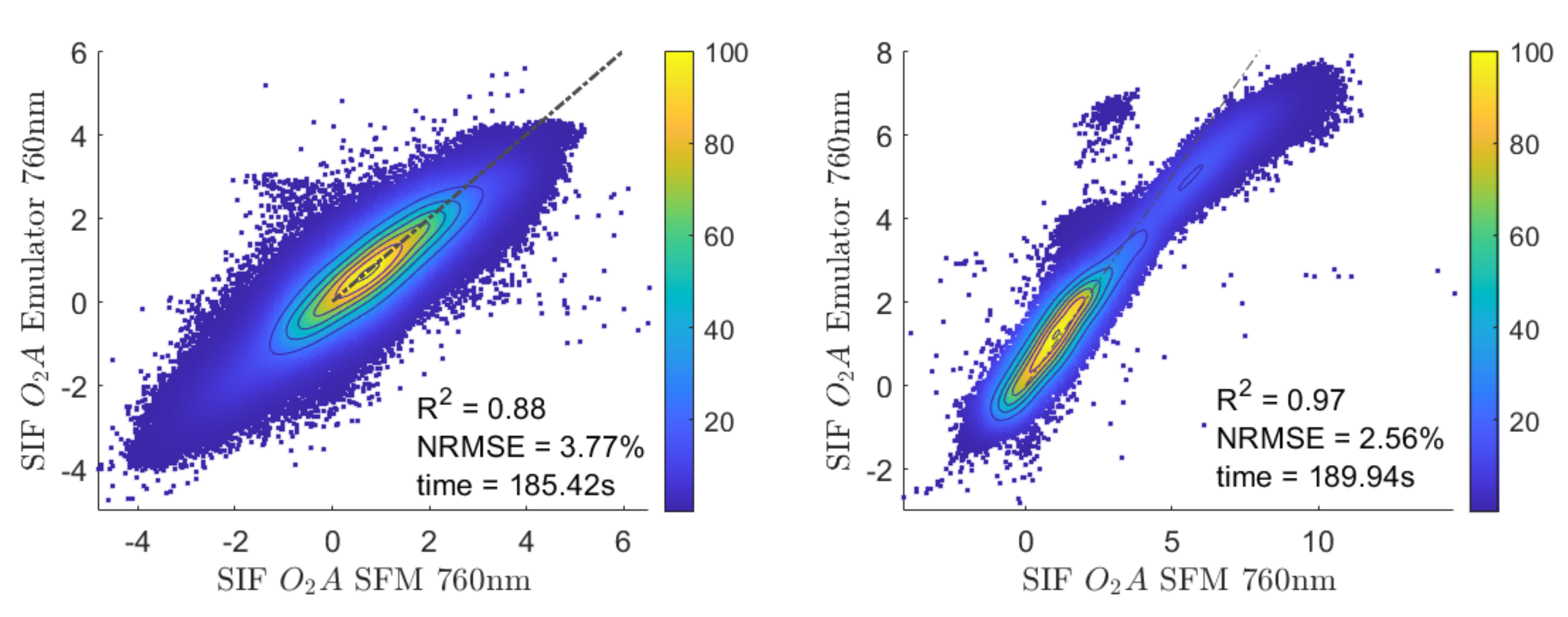
3.3. Application of the SIF Emulator to an Entire Flight Line and Adjacent Flight Lines
3.4. Application of the SIF Emulator to All Flight Lines
4. Discussion
4.1. Interpreting SIF Emulator Results
4.2. Opportunities for Emulation of Spectral Products
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mohammed, G.; Colombo, R.; Middleton, E.; Rascher, U.; van der Tol, C.; Nedbal, L.; Goulas, Y.; Pérez-Priego, O.; Damm, A.; Meroni, M.; et al. Remote sensing of solar-induced chlorophyll fluorescence (SIF) in vegetation: 50 years of progress. Remote Sens. Environ. 2019, 231, 111177. [Google Scholar] [CrossRef] [PubMed]
- Cendrero-Mateo, M.P.; Wieneke, S.; Damm, A.; Alonso, L.; Pinto, F.; Moreno, J.; Guanter, L.; Celesti, M.; Rossini, M.; Sabater, N.; et al. Sun-induced chlorophyll fluorescence III: Benchmarking retrieval methods and sensor characteristics for proximal sensing. Remote Sens. 2019, 11, 962. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.Y.; Guanter, L.; Frankenberg, C.; Köhler, P.; Gu, L.; Magney, T.S.; Grossmann, K.; Sun, Y. Systematic Assessment of Retrieval Methods for Canopy Far-Red Solar-Induced Chlorophyll Fluorescence Using High-Frequency Automated Field Spectroscopy. J. Geophys. Res. Biogeosci. 2020, 125, e2019JG005533. [Google Scholar] [CrossRef]
- Cogliati, S.; Verhoef, W.; Kraft, S.; Sabater, N.; Alonso, L.; Vicent, J.; Moreno, J.; Drusch, M.; Colombo, R. Retrieval of sun-induced fluorescence using advanced spectral fitting methods. Remote Sens. Environ. 2015, 169, 344–357. [Google Scholar] [CrossRef]
- Liu, X.; Liu, L.; Zhang, S.; Zhou, X. New Spectral Fitting Method for Full-Spectrum Solar-Induced Chlorophyll Fluorescence Retrieval Based on Principal Components Analysis. Remote Sens. 2015, 7, 10626. [Google Scholar] [CrossRef] [Green Version]
- Cogliati, S.; Celesti, M.; Cesana, I.; Miglietta, F.; Genesio, L.; Julitta, T.; Schuettemeyer, D.; Drusch, M.; Rascher, U.; Jurado, P.; et al. A spectral fitting algorithm to retrieve the fluorescence spectrum from canopy radiance. Remote Sens. 2019, 11, 1840. [Google Scholar] [CrossRef] [Green Version]
- Siegmann, B.; Alonso, L.; Celesti, M.; Cogliati, S.; Colombo, R.; Damm, A.; Douglas, S.; Guanter, L.; Hanus, J.; Kataja, K.; et al. The High-Performance Airborne Imaging Spectrometer HyPlant—From Raw Images to Top-of-Canopy Reflectance and Fluorescence Products: Introduction of an Automatized Processing Chain. Remote Sens. 2019, 11, 2760. [Google Scholar] [CrossRef] [Green Version]
- Rivera, J.P.; Verrelst, J.; Gómez-Dans, J.; Muñoz Marí, J.; Moreno, J.; Camps-Valls, G. An Emulator Toolbox to Approximate Radiative Transfer Models with Statistical Learning. Remote Sens. 2015, 7, 9347. [Google Scholar] [CrossRef] [Green Version]
- O’Hagan, A. Bayesian analysis of computer code outputs: A tutorial. Reliab. Eng. Syst. Saf. 2006, 91, 1290–1300. [Google Scholar] [CrossRef]
- Gómez-Dans, J.L.; Lewis, P.E.; Disney, M. Efficient Emulation of Radiative Transfer Codes Using Gaussian Processes and Application to Land Surface Parameter Inferences. Remote Sens. 2016, 8, 119. [Google Scholar] [CrossRef] [Green Version]
- Verrelst, J.; Sabater, N.; Rivera, J.P.; Muñoz Marí, J.; Vicent, J.; Camps-Valls, G.; Moreno, J. Emulation of Leaf, Canopy and Atmosphere Radiative Transfer Models for Fast Global Sensitivity Analysis. Remote Sens. 2016, 8, 673. [Google Scholar] [CrossRef] [Green Version]
- Vicent, J.; Verrelst, J.; Rivera Caicedo, J.; Sabater Medina, N.; Muñoz, J.; Camps-Valls, G.; Moreno, J. Emulation as an Accurate Alternative to Interpolation in Sampling Radiative Transfer Codes. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2018, 11, 1–14. [Google Scholar] [CrossRef]
- Verrelst, J.; Rivera Caicedo, J.P.; Vicent, J.; Morcillo Pallarés, P.; Moreno, J. Approximating Empirical Surface Reflectance Data through Emulation: Opportunities for Synthetic Scene Generation. Remote Sens. 2019, 11, 157. [Google Scholar] [CrossRef] [Green Version]
- Bue, B.D.; Thompson, D.R.; Deshpande, S.; Eastwood, M.; Green, R.O.; Natraj, V.; Mullen, T.; Parente, M. Neural network radiative transfer for imaging spectroscopy. Atmos. Meas. Tech. 2019, 12, 2567–2578. [Google Scholar] [CrossRef] [Green Version]
- Duffy, K.; Vandal, T.; Wang, W.; Nemani, R.; Ganguly, A.R. Deep Learning Emulation of Multi-Angle Implementation of Atmospheric Correction (MAIAC). arXiv 2019, arXiv:1910.13408. [Google Scholar]
- Verrelst, J.; Rivera-Caicedo, J.; Muñoz Marí, J.; Camps-Valls, G.; Moreno, J. SCOPE-Based Emulators for Fast Generation of Synthetic Canopy Reflectance and Sun-Induced Fluorescence Spectra. Remote Sens. 2017, 9, 927. [Google Scholar] [CrossRef] [Green Version]
- Verrelst, J.; Malenovský, Z.; Tol, C.; Camps-Valls, G.; Gastellu-Etchegorry, J.P.; Lewis, P.; North, P.; Moreno, J. Quantifying Vegetation Biophysical Variables from Imaging Spectroscopy Data: A Review on Retrieval Methods. Surv. Geophys. 2019, 40, 589–629. [Google Scholar] [CrossRef] [Green Version]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef] [Green Version]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Liu, X.; Smith, W.L.; Zhou, D.K.; Larar, A. Principal component-based radiative transfer model for hyperspectral sensors: Theoretical concept. Appl. Opt. 2006, 45, 201–209. [Google Scholar] [CrossRef] [PubMed]
- Matricardi, M. A principal component based version of the RTTOV fast radiative transfer model. Q. J. R. Meteorol. Soc. 2010, 136, 1823–1835. [Google Scholar] [CrossRef]
- del Águila, A.; Efremenko, D.; Molina García, V.; Xu, J. Analysis of Two Dimensionality Reduction Techniques for Fast Simulation of the Spectral Radiances in the Hartley-Huggins Band. Atmosphere 2019, 10, 142. [Google Scholar] [CrossRef] [Green Version]
- Bounceur, N.; Crucifix, M.; Wilkinson, R. Global sensitivity analysis of the climate–vegetation system to astronomical forcing: An emulator-based approach. Earth Syst. Dyn. Discuss. 2014, 5, 901–943. [Google Scholar]
- Rascher, U.; Alonso, L.; Burkart, A.; Cilia, C.; Cogliati, S.; Colombo, R.; Damm, A.; Drusch, M.; Guanter, L.; Hanus, J.; et al. Sun-induced fluorescence–a new probe of photosynthesis: First maps from the imaging spectrometer HyPlant. Glob. Chang. Biol. 2015, 21, 4673–4684. [Google Scholar] [CrossRef] [Green Version]
- Plascyk, J.A. The MK II Fraunhofer Line Discriminator (FLD-II) for Airborne and Orbital Remote Sensing of Solar-Stimulated Luminescence. Opt. Eng. 1975, 14, 144339. [Google Scholar] [CrossRef]
- Meroni, M.; Rossini, M.; Guanter, L.; Alonso, L.; Rascher, U.; Colombo, R.; Moreno, J. Remote sensing of solar-induced chlorophyll fluorescence: Review of methods and applications. Remote Sens. Environ. 2009, 113, 2037–2051. [Google Scholar] [CrossRef]
- Alonso, L.; Gómez-Chova, L.; Vila-Francés, J.; Amorós, J.; Guanter, L.; Calpe, J.; Moreno, J. Sensitivity analysis of the Fraunhofer Line Discrimination method for the measurement of chlorophyll fluorescence using a field spectroradiometer. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007; pp. 3756–3759. [Google Scholar] [CrossRef]
- Alonso, L.; Gómez-Chova, L.; Vila-Francés, J.; Amorós, J.; Guanter, L.; Calpe, J.; Moreno, J. Improved Fraunhofer Line Discrimination Method for Vegetation Fluorescence Quantification. IEEE Geosci. Remote Sens. Lett. 2008, 5, 620–624. [Google Scholar] [CrossRef]
- Sabater, N.; Vicent, J.; Alonso, L.; Verrelst, J.; Middleton, E.M.; Porcar-Castell, A.; Moreno, J. Compensation of Oxygen Transmittance Effects for Proximal Sensing Retrieval of Canopy–Leaving Sun–Induced Chlorophyll Fluorescence. Remote Sens. 2018, 10, 1551. [Google Scholar] [CrossRef] [Green Version]
- Berk, A.; Anderson, G.; Acharya, P.; Bernstein, L.; Muratov, L.; Lee, J.; Fox, M.; Adler-Golden, S.; Chetwynd, J.; Hoke, M.; et al. MODTRAN (TM) 5, a reformulated atmospheric band model with auxiliary species and practical multiple scattering options: Update. Proc. SPIE 2005, 5806, 662–667. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks–A Comprehensive Foundation, 2nd ed.; Prentice Hall: Hoboken, NJ, USA, 1999. [Google Scholar]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Camps-Valls, G.; Bruzzone, L. Kernel Methods for Remote Sensing Data Analysis; Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Tuia, D.; Verrelst, J.; Alonso, L.; Pérez-Cruz, F.; Camps-Valls, G. Multioutput Support Vector Regression for Remote Sensing Biophysical Parameter Estimation. IEEE Geosci. Remote Sens. Lett. 2011, 8, 804–808. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; The MIT Press: New York, NY, USA, 2006. [Google Scholar]
- Camps-Valls, G.; Gómez-Chova, L.; Muñoz-Marí, J.; Lázaro-Gredilla, M.; Verrelst, J. simpleR: A Simple Educational Matlab Toolbox for Statistical Regression. 2013. Available online: https://www.uv.es/gcamps/software.html (accessed on 10 December 2018).
- Lázaro-Gredilla, M.; Titsias, M. Variational Heteroscedastic Gaussian Process Regression. In Proceedings of the ICML, Bellevue, WA, USA, 28 June–2 July 2011; pp. 841–848. [Google Scholar]
- Macqueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the 5-th Berkeley Symposium on Mathematical Statistics and Probability; Statistical Laboratory of the University of California: Berkeley, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Verrelst, J.; Romijn, E.; Kooistra, L. Mapping vegetation density in a heterogeneous river floodplain ecosystem using pointable CHRIS/PROBA data. Remote Sens. 2012, 4, 2866–2889. [Google Scholar] [CrossRef] [Green Version]
- Efremenko, D.; Doicu, A.; Loyola, D.; Trautmann, T. Optical property dimensionality reduction techniques for accelerated radiative transfer performance: Application to remote sensing total ozone retrievals. J. Quant. Spectrosc. Radiat. Transf. 2014, 133, 128–135. [Google Scholar] [CrossRef]
- Gu, X.; Shu, M.; Yang, G.; Xu, X.; Song, X. Spectral Response of Soil Organic Matter by Principal Component Analysis. In Proceedings of the 2018 7th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Hangzhou, China, 6–9 August 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Servera, J.V.; Rivera-Caicedo, J.P.; Verrelst, J.; Muñoz-Marí, J.; Sabater, N.; Berthelot, B.; Camps-Valls, G.; Moreno, J. Systematic Assessment of MODTRAN Emulators for Atmospheric Correction. IEEE Trans. Geosci. Remote Sens. 2021, 1–17. [Google Scholar] [CrossRef]
- McKay, M.; Beckman, R.; Conover, W. Comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics 1979, 21, 239–245. [Google Scholar]
- Gan, Y.; Duan, Q.; Gong, W.; Tong, C.; Sun, Y.; Chu, W.; Ye, A.; Miao, C.; Di, Z. A comprehensive evaluation of various sensitivity analysis methods: A case study with a hydrological model. Environ. Model. Softw. 2014, 51, 269–285. [Google Scholar] [CrossRef] [Green Version]
- Razavi, S.; Sheikholeslami, R.; Gupta, H.V.; Haghnegahdar, A. VARS-TOOL: A toolbox for comprehensive, efficient, and robust sensitivity and uncertainty analysis. Environ. Model. Softw. 2019, 112, 95–107. [Google Scholar] [CrossRef]
- Bratley, P.; Fox, B.L. Algorithm 659: Implementing Sobol’s Quasirandom Sequence Generator. ACM Trans. Math. Softw. 1988, 14, 88–100. [Google Scholar] [CrossRef]
- Svendsen, D.H.; Martino, L.; Camps-Valls, G. Active emulation of computer codes with Gaussian processes – Application to remote sensing. Pattern Recognit. 2020, 100, 107103. [Google Scholar] [CrossRef] [Green Version]
- Verrelst, J.; Rivera, J.P.; Gitelson, A.; Delegido, J.; Moreno, J.; Camps-Valls, G. Spectral band selection for vegetation properties retrieval using Gaussian processes regression. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 554–567. [Google Scholar] [CrossRef]
- Coppo, P.; Taiti, A.; Pettinato, L.; Francois, M.; Taccola, M.; Drusch, M. Fluorescence Imaging Spectrometer (FLORIS) for ESA FLEX Mission. Remote Sens. 2017, 9, 649. [Google Scholar] [CrossRef] [Green Version]
- Verrelst, J.; Rivera, J.; Moreno, J.; Camps-Valls, G. Gaussian processes uncertainty estimates in experimental Sentinel-2 LAI and leaf chlorophyll content retrieval. ISPRS J. Photogramm. Remote Sens. 2013, 86, 157–167. [Google Scholar] [CrossRef]
- Fell, F.; Fischer, J. Numerical simulation of the light field in the atmosphere-ocean system using the matrix-operator method. J. Quant. Spectrosc. Radiat. Transf. 2001, 69, 351–388. [Google Scholar] [CrossRef]
- Berk, A.; Conforti, P.; Kennett, R.; Perkins, T.; Hawes, F.; Van Den Bosch, J. MODTRAN6: A major upgrade of the MODTRAN radiative transfer code. Proc. Spie-Int. Soc. Opt. Eng. 2014, 9088. [Google Scholar] [CrossRef]
- Emde, C.; Buras-Schnell, R.; Kylling, A.; Mayer, B.; Gasteiger, J.; Hamann, U.; Kylling, J.; Richter, B.; Pause, C.; Dowling, T.; et al. The libRadtran software package for radiative transfer calculations (version 2.0.1). Geosci. Model Dev. 2016, 9, 1647–1672. [Google Scholar] [CrossRef] [Green Version]
- Saunders, R.; Hocking, J.; Turner, E.; Rayer, P.; Rundle, D.; Brunel, P.; Vidot, J.; Roquet, P.; Matricardi, M.; Geer, A.; et al. An update on the RTTOV fast radiative transfer model (currently at version 12). Geosci. Model Dev. 2018, 11, 2717–2737. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Brief Description | References |
|---|---|---|
| Neural Networks (NN) | NN are an interconnected group of nodes. Each node represents an artificial neuron with a connection from the output of one neuron to the input of another. Using the training dataset, weights are established for each neuron and the model is able to capture the non-linear relationships of the model. NN is multi-output. | [31] |
| Kernel ridge regression (KRR) | KRR minimizes the squared residuals in a higher dimensional feature space and can be considered as the kernel version of the regularized linear regression. KRR is multi-output. | [32,33] |
| Multioutput Support Vector Regression (MOSVR) | MOSVR extends the single-output SVR by taking into account the nonlinear relations between features but also among the output variables, which are typically inter-dependent. MOSVR is multi-output. | [34] |
| Gaussian process regression (GPR) | GPR is a nonparametric, Bayesian approach to regression. GPR has the ability to provide uncertainty measurements on the predictions. GPR is single-output. | [35,36] |
| Matlab Gaussian process regression (GPRM) | GPRM is similar to GPR but with the option to change multiple kernels https://es.mathworks.com/help/stats/kernel-covariance-function-options.html?lang=en, accessed on 29 October 2021. These kernels were initially tested, and the evaluated best trade-off between accuracy and speed was for “Squared Exponential”. GPRM is single-output. | [35] |
| Variational Heteroscedastic Gaussian Process Regression (VHGPR) | VHGPR is an anisotropic RBF kernel that has a scale, lengthscale per input feature, and a input-dependent noise power parameter as hyperparameters. VHGPR is single-output. | [37] |
| MLRA | RMSE | NRMSE (%) | Time Train (s) |
|---|---|---|---|
| Kernel ridge Regression | 0.30 | 6.09 | 0.57 |
| Gaussian Processes Regression-Matlab | 0.30 | 6.71 | 10.55 |
| Neural Network | 0.31 | 6.80 | 7.61 |
| VH. Gaussian Processes Regression | 0.31 | 6.95 | 80.14 |
| Gaussian Processes Regression | 0.31 | 6.96 | 23.80 |
| Multioutput Support Vector Regression | 0.32 | 7.08 | 12.33 |
| Sampling | Flight Line | RMSE | NRMSE (%) | R2 |
|---|---|---|---|---|
| Random | L3 | 1.14 | 8.16 | 0.81 |
| L6 | 0.98 | 5.72 | 0.87 | |
| Relative | L3 | 1.22 | 8.76 | 0.78 |
| L6 | 1.19 | 6.92 | 0.79 | |
| Absolute | L3 | 1.09 | 7.83 | 0.80 |
| L6 | 0.90 | 5.28 | 0.87 |
| Acquisition Time (LT) | Direction | Num Pixels (Milions) | Processing Time (s) | RMSE (mW m sr nm | NRMSE (%) | R2 | |
|---|---|---|---|---|---|---|---|
| L1 | 13:54 | N | 2.3 | 185.50 | 0.62 | 5.19 | 0.85 |
| L2 | 13:46 | S | 2.3 | 182.93 | 0.73 | 6.42 | 0.82 |
| L3 | 13:38 | N | 2.3 | 187.17 | 0.69 | 5.13 | 0.81 |
| L4 | 13:30 | S | 2.3 | 185.87 | 0.81 | 5.19 | 0.95 |
| L5 | 13:22 | N | 2.3 | 188.52 | 0.80 | 5.06 | 0.91 |
| L6 | 13:14 | S | 2.3 | 186.25 | 0.68 | 4.13 | 0.88 |
| L7 | 13:06 | N | 1.3 | 68.00 | 0.58 | 5.57 | 0.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morata, M.; Siegmann, B.; Morcillo-Pallarés, P.; Rivera-Caicedo, J.P.; Verrelst, J. Emulation of Sun-Induced Fluorescence from Radiance Data Recorded by the HyPlant Airborne Imaging Spectrometer. Remote Sens. 2021, 13, 4368. https://doi.org/10.3390/rs13214368
Morata M, Siegmann B, Morcillo-Pallarés P, Rivera-Caicedo JP, Verrelst J. Emulation of Sun-Induced Fluorescence from Radiance Data Recorded by the HyPlant Airborne Imaging Spectrometer. Remote Sensing. 2021; 13(21):4368. https://doi.org/10.3390/rs13214368
Chicago/Turabian StyleMorata, Miguel, Bastian Siegmann, Pablo Morcillo-Pallarés, Juan Pablo Rivera-Caicedo, and Jochem Verrelst. 2021. "Emulation of Sun-Induced Fluorescence from Radiance Data Recorded by the HyPlant Airborne Imaging Spectrometer" Remote Sensing 13, no. 21: 4368. https://doi.org/10.3390/rs13214368
APA StyleMorata, M., Siegmann, B., Morcillo-Pallarés, P., Rivera-Caicedo, J. P., & Verrelst, J. (2021). Emulation of Sun-Induced Fluorescence from Radiance Data Recorded by the HyPlant Airborne Imaging Spectrometer. Remote Sensing, 13(21), 4368. https://doi.org/10.3390/rs13214368