
A 3D Reconstruction Framework of Buildings Using Single Off-Nadir Satellite Image


Abstract
:
1. Introduction
- A 3D model reconstruction framework was proposed, which can generate water-tight mesh models from the single satellite image;
- By setting the scale factor, Scale-ONet was proposed to reconstruct models from the single image, which has a different view-angle, size of buildings, spatial resolutions;
- Optim-Net was proposed to optimize scale value in different directions and generate optimized building models with accurate scales.
2. Related Work
3. Methodology
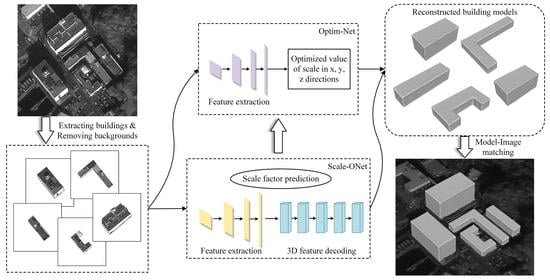
3.1. 3D Model Reconstruction Framework of Buildings
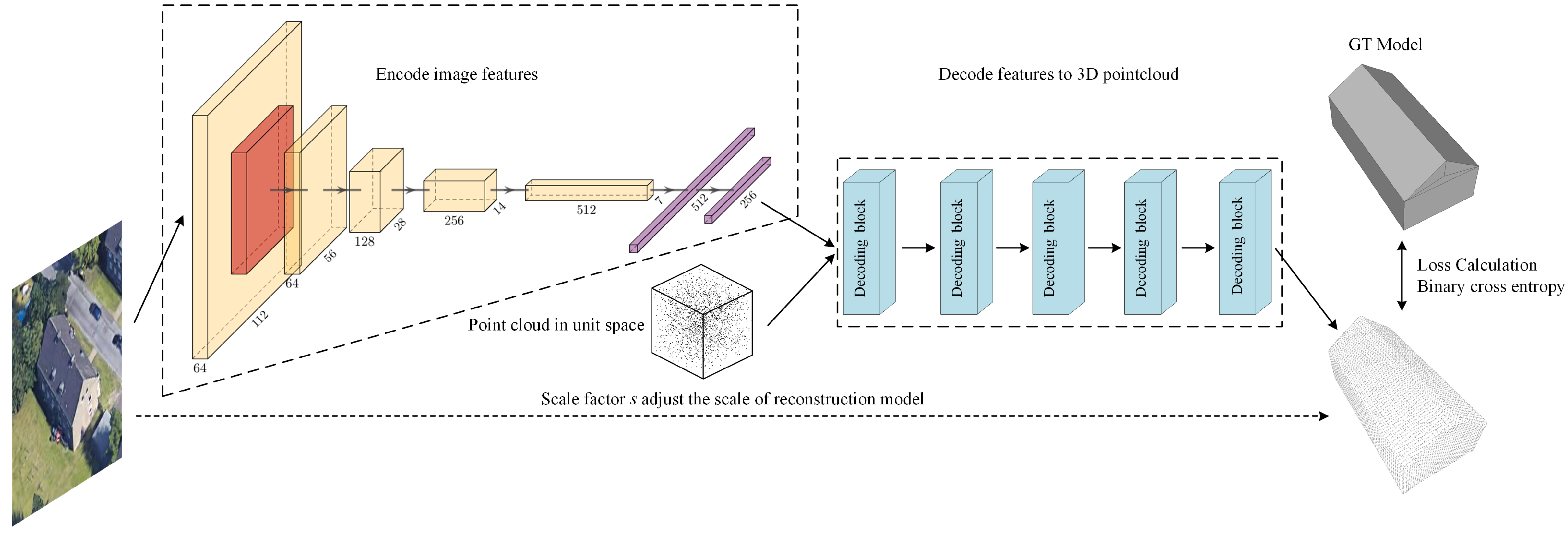
3.2. Scale-ONet
3.2.1. Overall Structure
3.2.2. Solutions to the Problem of Diverse View-Angle
3.2.3. Reconstruct Models of Diverse Size Buildings
3.2.4. Adapt to Diverse Spatial Resolution of Images
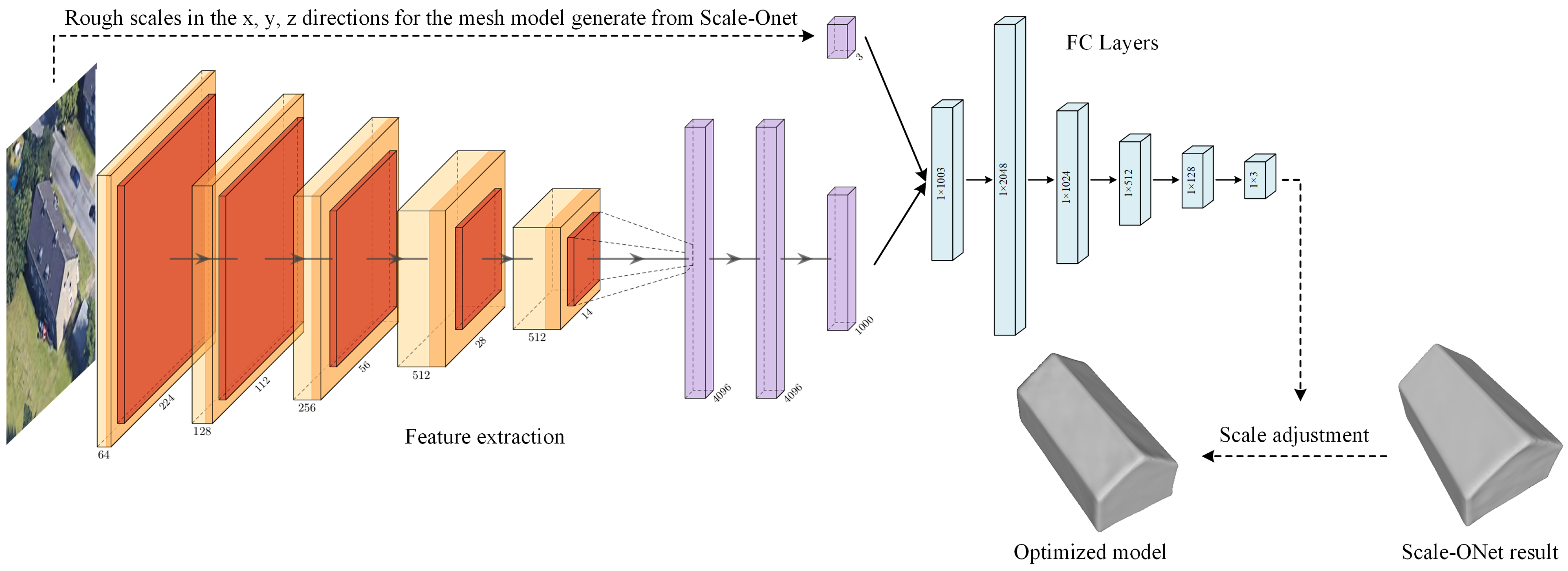
3.3. Model Scale Optimization Network
3.4. Model-Image Matching Algorithm
3.5. Evaluation Metrics
4. Experiments
4.1. Data Preparation and Experimental Environments
- Simulated dataset: 1150 models were drawn for the simulation experiment, with a regular scale and shape. We use the model rendering algorithm to render the drawn 3D models. Different simulation images are generated by setting parameters of the rendered lighting, color, and camera position;
- Satellite images: We selected areas-of-interest from the original satellite image. Each building target in these areas is independently cropped into a square image. The background information in these square images was manually removed;
- 3D mesh models: Most areas on Google Earth contain a “3D Buildings Photorealistic” layer, which has complete building structures. We picked building targets in Google Earth and obtained information on the structure and size of these buildings through measurement tools. We used model software to draw water-tight mesh models of these buildings, which have real and different shapes and scale.
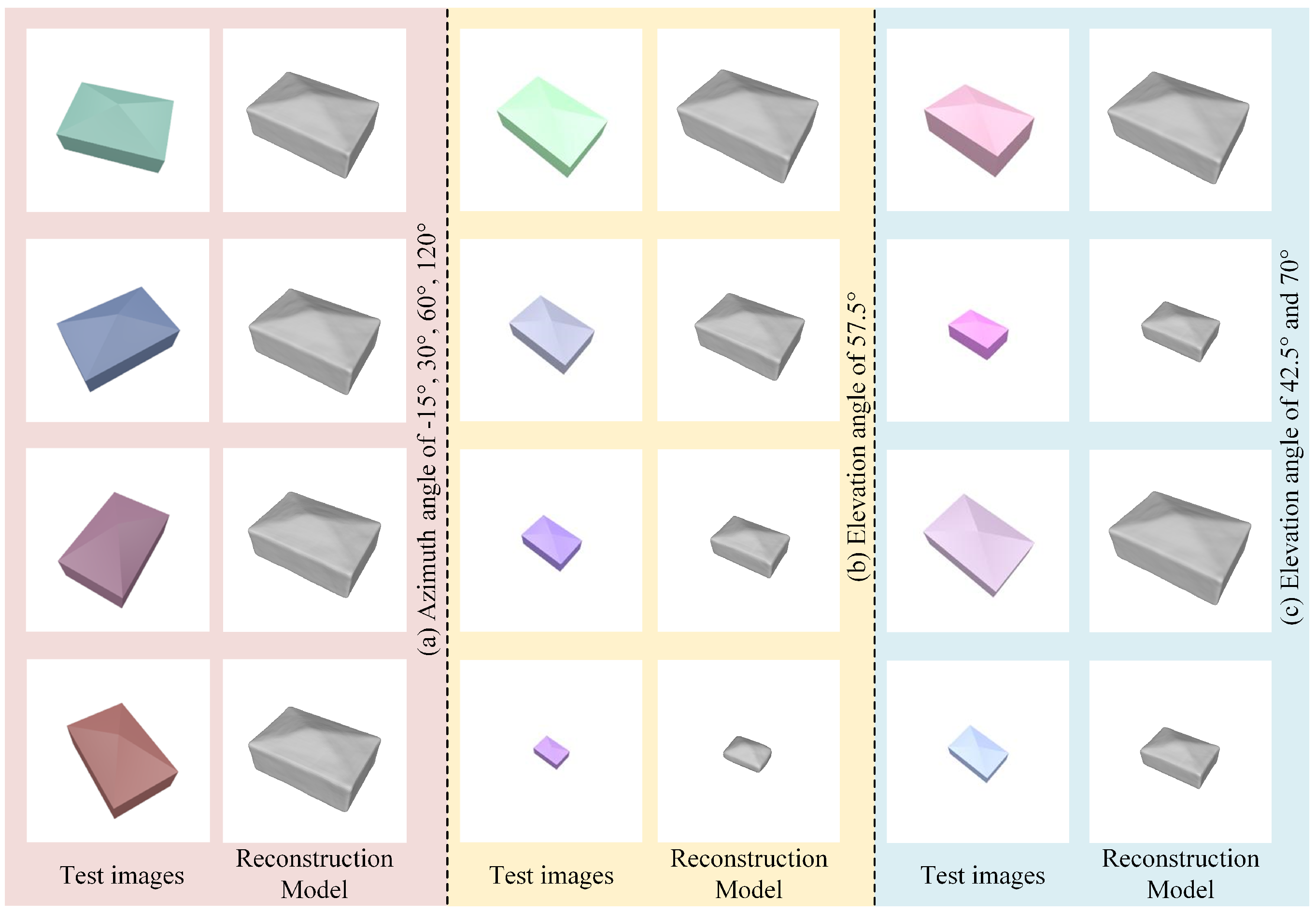
4.2. Simulation Experiment for Scale-ONet
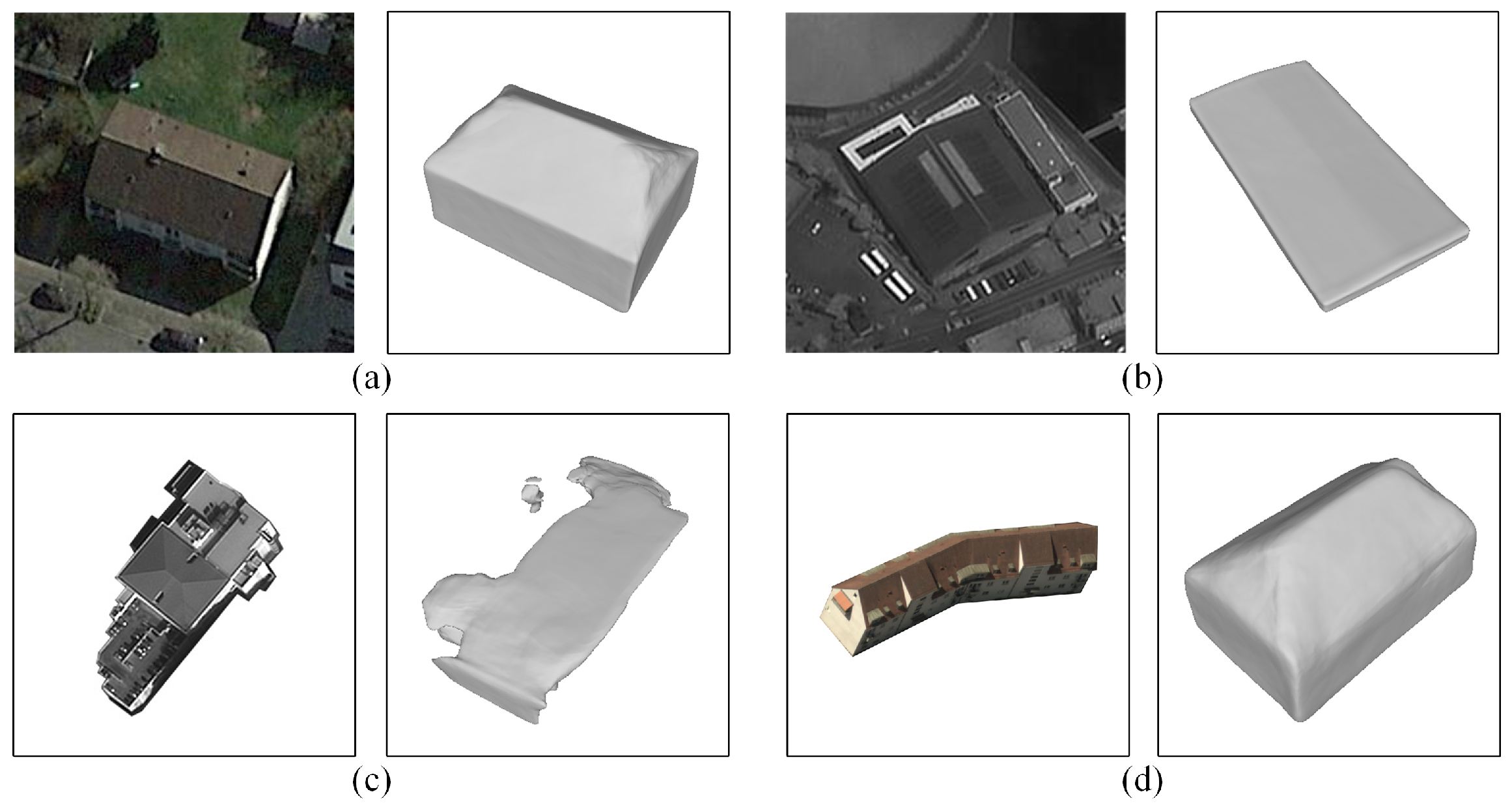
4.3. Real Remote Sensing Image Testing and Evaluation
4.3.1. Satellite Images of the Dortmund
4.3.2. Satellite Images of the Yokosuka
4.3.3. Experiment for Optimizing Scale of Models
4.3.4. Restoration of Reconstruction Scenes
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, R. The development of 3D city model and its applications in urban planning. In Proceedings of the 2011 19th International Conference on Geoinformatics, Shanghai, China, 24–26 June 2011. [Google Scholar]
- Zheng, X.; Wang, F.; Li, Z. A multi-UAV cooperative route planning methodology for 3D fine-resolution building model reconstruction. ISPRS J. Photogramm. Remote Sens. 2018, 146, 483–494. [Google Scholar] [CrossRef]
- Kuang, Q.; Wu, J.; Pan, J.; Zhou, B. Real-Time UAV Path Planning for Autonomous Urban Scene Reconstruction. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation, Paris, France, 31 May–31 August 2020. [Google Scholar]
- Qin, R.; Huang, X.; Liu, W.; Xiao, C. Semantic 3D Reconstruction Using Multi-View High-Resolution Satellite Images Based on U-Net and Image-Guided Depth Fusion. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019. [Google Scholar]
- Yu, D.; Ji, S.; Liu, J.; Wei, S. Automatic 3D building reconstruction from multi-view aerial images with deep learning. ISPRS J. Photogramm. Remote Sens. 2021, 171, 155–170. [Google Scholar] [CrossRef]
- Qin, R. A Critical Analysis of Satellite Stereo Pairs for Digital Surface Model Generation and A Matching Quality Prediction Model. ISPRS J. Photogramm. Remote Sens. 2019, 154, 139–150. [Google Scholar] [CrossRef]
- Partovi, T.; Fraundorfer, F.; Bahmanyar, R.; Huang, H.; Reinartz, P. Automatic 3-D building model reconstruction from very high resolution stereo satellite imagery. Remote Sens. 2019, 11, 1660. [Google Scholar] [CrossRef] [Green Version]
- Jiang, S.; Jiang, C.; Jiang, W. Efficient structure from motion for large-scale UAV images: A review and a comparison of SfM tools. ISPRS J. Photogramm. Remote Sens. 2020, 167, 230–251. [Google Scholar] [CrossRef]
- Kim, T.; Javzandulam, T.; Lee, T. Semiautomatic reconstruction of building height and footprints from single satellite images. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 June 2007. [Google Scholar]
- Liasis, G.; Stavrou, S. Satellite images analysis for shadow detection and building height estimation. ISPRS J. Photogramm. Remote Sens. 2016, 119, 437–450. [Google Scholar] [CrossRef]
- Tack, F.; Buyuksalih, G.; Goossens, R. 3D building reconstruction based on given ground plan information and surface models extracted from spaceborne imagery. ISPRS J. Photogramm. Remote Sens. 2012, 67, 52–64. [Google Scholar] [CrossRef] [Green Version]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy networks: Learning 3D reconstruction in function space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Kolbe, T.; Gröger, G.; Plümer, L. Citygml: Interoperable access to 3D city models. In Geo-Information for Disaster Management; Springer: Berlin/Heidelberg, Germany, 2005; pp. 883–899. [Google Scholar]
- Hu, H.; Zhu, Q.; Du, Z.; Zhang, Y.; Ding, Y. Reliable spatial relationship constrained feature point matching of oblique aerial images. Photogramm. Eng. Remote Sens. 2015, 81, 49–58. [Google Scholar] [CrossRef]
- Gerke, M.; Nex, F.; Jende, P. Co-registration of terrestrial and UAV-based images—Experimental results. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2016, 40, 11–18. [Google Scholar]
- Gerke, M.; Nex, F.; Remondino, F.; Jacobsen, K.; Kremer, J.; Karel, W.; Huf, H.; Ostrowski, W. Orientation of oblique airborne image sets—Experiences from the ISPRS/Eurosdr benchmark on multi-platform photogrammetry. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2016, 41, 185–191. [Google Scholar]
- Xie, L.; Hu, H.; Wang, J.; Zhu, Q.; Chen, M. An asymmetric re-weighting method for the precision combined bundle adjustment of aerial oblique images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 92–107. [Google Scholar] [CrossRef]
- Galliani, S.; Lasinger, K.; Schindler, K. Massively parallel multiview stereopsis by surface normal diffusion. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Hu, H.; Chen, C.; Wu, B.; Yang, X.; Zhu, Q.; Ding, Y. Texture-aware dense image matching using ternary census transform. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III-3, 59–66. [Google Scholar] [CrossRef] [Green Version]
- Wu, B.; Sun, X.; Wu, Q.; Yan, M.; Wang, H.; Fu, K. Building reconstruction from high-resolution multiview aerial imagery. IEEE Geosci. Remote Sens. Lett. 2015, 12, 855–859. [Google Scholar]
- Frommholz, D.; Linkiewicz, M.; Meissner, H.; Dahlke, D.; Poznanska, A. Extracting semantically annotated 3D building models with textures from oblique aerial imagery. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2015, 40, 53–58. [Google Scholar] [CrossRef] [Green Version]
- Rothermel, M.; Gong, K.; Fritsch, D.; Schindler, K.; Haala, N. Photometric multi-view mesh refinement for high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 52–62. [Google Scholar] [CrossRef]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. MVSNet: Depth inference for unstructured multi-view stereo. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wei, X.; Zhang, Y.; Li, Z.; Fu, Y.; Xue, X. DeepSFM: Structure from Motion via Deep Bundle Adjustment. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Shen, T.; Fang, T.; Quan, L. Recurrent MVSnet for high-resolution multi-view stereo depth inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Xiang, X.; Wang, Z.; Lao, S.; Zhang, B. Pruning multi-view stereo net for efficient 3D reconstruction. ISPRS J. Photogramm. Remote Sens. 2020, 168, 17–27. [Google Scholar] [CrossRef]
- Aguilar, M.; Del Mar Saldana, M.; Aguilar, F. Generation and quality assessment of stereo-extracted DSM from geoeye-1 and worldview-2 imagery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 1259–1271. [Google Scholar] [CrossRef]
- Gu, Y.; Cao, Z.; Zhang, Y. Three-dimensional reconstruction of multiplatform stereo data with variance component estimation. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4211–4226. [Google Scholar]
- Kim, S.; Rhee, S.; Kim, T. Digital surface model interpolation based on 3D mesh models. Remote Sens. 2019, 11, 24. [Google Scholar] [CrossRef] [Green Version]
- Izadi, M.; Saeedi, P. Three-dimensional polygonal building model estimation from single satellite images. IEEE Trans. Geosci. Remote Sens. 2012, 50, 2254–2272. [Google Scholar] [CrossRef]
- Haala, N.; Kada, M. An update on automatic 3D building reconstruction. ISPRS J. Photogramm. Remote Sens. 2010, 65, 570–580. [Google Scholar] [CrossRef]
- Alidoost, F.; Arefi, H.; Tombari, F. 2D image-to-3D model: Knowledge-based 3D building reconstruction (3DBR) using single aerial images and convolutional neural networks (CNNs). Remote Sens. 2019, 11, 2219. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Xu, B.; Shan, J. Geometric object based building reconstruction from satellite imagery derived point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2019, 42, 73–78. [Google Scholar] [CrossRef] [Green Version]
- Partovi, T.; Krauß, T.; Arefi, H.; Omidalizarandi, M.; Reinartz, P. Model-driven 3D building reconstruction based on integeration of DSM and spectral information of satellite images. In Proceedings of the 2014 IEEE International Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014. [Google Scholar]
- Sirmacek, B.; Taubenböck, H.; Reinartz, P.; Ehlers, M. Performance evaluation for 3-D city model generation of six different DSMs from air- and spaceborne sensors. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 59–70. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Gilani, S.; Siddiqui, F. An effective data-driven method for 3-D building roof reconstruction and robust change detection. Remote Sens. 2018, 10, 1512. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Krylov, V.; Kane, P.; Kavanagh, G.; Dahyot, R. IM2ELEVATION: Building height estimation from single-view aerial imagery. Remote Sens. 2020, 12, 2719. [Google Scholar] [CrossRef]
- Amirkolaee, H.; Arefi, H. Height estimation from single aerial images using a deep convolutional encoder-decoder network. ISPRS J. Photogramm. Remote Sens. 2019, 149, 50–66. [Google Scholar] [CrossRef]
- Smith, E.; Meger, D. Improved adversarial systems for 3d object generation and reconstruction. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017. [Google Scholar]
- Choy, C.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction. In Proceedings of the 14th European Conference on Computer Vision, Scottsdale, AZ, USA, 3–7 November 2014. [Google Scholar]
- Smith, E.; Fujimoto, S.; Meger, D. Multi-view silhouette and depth decomposition for high resolution 3D object representation. In Proceedings of the 32nd Conference on Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, W.; Tenenbaum, J. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. In Proceedings of the 30th Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L. A point set generation network for 3D object reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wei, Y.; Liu, S.; Zhao, W.; Lu, J. Conditional single-view shape generation for multi-view stereo reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Deprelle, T.; Groueix, T.; Fisher, M.; Kim, V.; Russell, B.; Aubry, M. Learning elementary structures for 3D shape generation and matching. In Proceedings of the 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y. Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Groueix, T.; Fisher, M.; Kim, V.; Russell, B.; Aubry, M. A Papier-Mache Approach to Learning 3D Surface Generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Rubner, Y.; Tomasi, C.; Guibas, L. The earth mover’s distance as a metric for image retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulated | Dortmund | Yokosuka | |
|---|---|---|---|
| Images | 13,800 | 860 | 1056 |
| Models | 1150 | 215 | 264 |
| Range of size | 10–100 m | 7–20 m | 40–80 m |
| Spatial resolution | 0.5 m | 0.09 m | 0.49 m |
| Cropped image size | 224 × 224 | 224 × 224 | 350 × 350 |
| Model Type | Elevation Angle of 57.5° | Elevation Angle of 42.5° | Elevation Angle of 70° | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Length (m) | Real model | 90.00 | 70.00 | 50.00 | 30.00 | 90.00 | 50.00 | 90.00 | 50.00 |
| Reconstruction model | 88.73 | 69.14 | 50.78 | 33.62 | 91.19 | 51.24 | 90.48 | 51.23 | |
| Height (m) | Real model | 42.00 | 32.60 | 23.30 | 14.00 | 42.00 | 23.30 | 42.00 | 23.30 |
| Reconstruction model | 43.29 | 33.09 | 24.21 | 14.94 | 41.45 | 22.81 | 41.87 | 23.44 | |
| Image Date | 2 August 2015 | 20 July 2016 | 18 August 2016 | 27 May 2017 | 6 April 2018 | 2 June 2019 |
|---|---|---|---|---|---|---|
| EMD | 0.7549 | 0.6443 | 0.7997 | 0.6964 | 0.8621 | 0.6820 |
| RMSE (m) | 2.1802 | 2.0850 | 2.1756 | 2.1696 | 2.1902 | 2.3242 |
| a | b | c | d | e | f | Average of a–f | Average of Total 110 Models | |
|---|---|---|---|---|---|---|---|---|
| ( = 0.95) | 0.6172 | 0.6557 | 0.9839 | 0.6176 | 0.5989 | 1.0654 | 0.7565 | 0.7681 |
| ( = 0.5) | 0.6239 | 0.6608 | 0.8613 | 0.6181 | 0.7394 | 1.1170 | 0.7701 | 0.7852 |
| ( = 0.2) | 0.6615 | 0.7491 | 1.0133 | 0.6599 | 0.6932 | 1.5013 | 0.8797 | 0.9028 |
| (m) | 2.6207 | 2.0972 | 2.0401 | 1.7957 | 1.9885 | 2.1867 | 2.1215 | 2.0562 |
| a | b | c | d | e | f | Average of a–f | Average of Total 41 Models | |
|---|---|---|---|---|---|---|---|---|
| ( = 0.95) | 0.5455 | 0.2938 | 0.3618 | 0.4973 | 0.2652 | 0.2704 | 0.3723 | 0.4593 |
| ( = 0.5) | 0.5101 | 0.3082 | 0.3799 | 0.5017 | 0.2638 | 0.2761 | 0.3733 | 0.4687 |
| ( = 0.2) | 0.5647 | 0.3155 | 0.4003 | 0.5252 | 0.2892 | 0.2931 | 0.3980 | 0.4820 |
| (m) | 2.0835 | 1.6636 | 2.7004 | 2.5677 | 1.9658 | 1.6228 | 2.1006 | 2.6523 |
| Resolutions | ||||
| Time (s) | 0.0789 | 0.1774 | 1.0573 | 8.2847 |
| a | b | c | d | e | f | Average of Total Dataset | ||
|---|---|---|---|---|---|---|---|---|
| In Dortmund | Original (m) | 2.6207 | 2.0972 | 2.0401 | 1.7957 | 1.9885 | 2.1867 | 2.0562 |
| Optimized (m) | 1.6811 | 1.1386 | 0.5531 | 0.9082 | 0.8619 | 1.2354 | 1.0017 | |
| In Yokosuka | Original (m) | 2.0835 | 1.6636 | 2.7004 | 2.5677 | 1.9658 | 1.6228 | 2.6523 |
| Optimized (m) | 0.9143 | 0.7474 | 1.9345 | 1.3951 | 1.1802 | 0.6104 | 1.5061 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, C.; Zhang, C.; Yan, Y.; Su, N. A 3D Reconstruction Framework of Buildings Using Single Off-Nadir Satellite Image. Remote Sens. 2021, 13, 4434. https://doi.org/10.3390/rs13214434
Zhao C, Zhang C, Yan Y, Su N. A 3D Reconstruction Framework of Buildings Using Single Off-Nadir Satellite Image. Remote Sensing. 2021; 13(21):4434. https://doi.org/10.3390/rs13214434
Chicago/Turabian StyleZhao, Chunhui, Chi Zhang, Yiming Yan, and Nan Su. 2021. "A 3D Reconstruction Framework of Buildings Using Single Off-Nadir Satellite Image" Remote Sensing 13, no. 21: 4434. https://doi.org/10.3390/rs13214434