1. Introduction
Hyperspectral images (HSIs) obtained by remote sensing systems usually contain hundreds of continuous narrow bands over a wide range of an electromagnetic spectrum. Each pixel of HSIs forms a continuous spectrum, which is able to provide abundant useful spectral information that is beneficial to distinguish different objects [
1]. By exploiting the different electromagnetic spectra of materials, targets of interest in the hyperspectral scene can be detected and identified through effective processing algorithms.
As one of the most important research areas, target detection (TD) is basically a binary classifier which aims at separating target pixels from the background with known target spectra. Furthermore, just as fields of synthetic aperture radar (SAR) target recognition [
2], electromagnetic sources recognition [
3] and single-image super-resolution [
4], which are very likely to be confronted with the problem of insufficient training samples, TD tasks also face the challenge of a small size of labeled training samples. Because of the small fraction of pixels being labeled as targets, the method of statistical hypothesis testing is usually exploited in classical target detection algorithms. Representative algorithms include the linear spectral matched filter (SMF), matched subspace detector (MSD) and adaptive coherence/cosine estimator (ACE). These algorithms define the target spectral characteristics by either a single target spectrum or a target subspace, while modeling the background statistically by a Gaussian distribution or a subspace representing either the whole or the local background statistics. Through the generalized likelihood ratio test (GLRT), the output for a certain pixel is obtained [
1]. As kernel methods in machine learning are introduced to target detection, the approaches mentioned above are further extended to nonlinear versions, such as kernel SMF and kernel MSD [
5], which can solve nonlinear problems to some extent. However, how to design a suitable kernel remains a problem. Constrained energy minimization (CEM), as a linear filter, is another target detection approach which constrains a desired target signature while being able to minimize the total energy of the output of other known signatures [
6].
Meanwhile, target detection algorithms based on sparse representation are also extensively explored by researchers. Central to sparse representation is the idea that a signal can be expressed as a linear combination of very few atoms of an over-complete dictionary consisting of a set of training samples from all classes. Then, the class information can be revealed by the sparse coefficients under the assumption that signals from different classes lie in different spaces [
7]. Typical approaches include the original sparse representation-based target detector (STD) and its variants: sparse representation-based binary hypothesis detector (SRBBH) [
8] and sparse and dense hybrid representation-based target detector (SDRD) [
9]. On the basis of STD, SRBBH perceives the detection problem as a competition between the background-only subspace and the target-and-background subspace under two different hypotheses. However, different from SRBBH, SDRD emphasizes that the background and the target sub-dictionaries collaboratively compete with each other, which facilitates the learning of sparse and dense hybrid representations for the test pixels.
Although progress has been achieved and many problems in detection tasks have been solved, challenges are still there within the realm of hyperspectral target detection. First, due to sensor noise and other factors, the target spectrum of the same material may vary dramatically, which makes it hard to represent the target spectrum using only a single spectrum or a subspace. Further, since spatial resolutions of HSIs are usually lower than that of multi-spectral and chromatic images, mixing pixels covering several materials still exist, which makes detection tasks much more complicated. Moreover, the problem of target detection is mostly nonlinear, but the approaches mentioned earlier are more likely to make decisions under linear assumptions, which does not do justice to the complex reality of HSI processing. Furthermore, it is noteworthy that many of these approaches just fail to work well when nonlinearity increases.
Recently, the deep neural network (DNN), which has achieved great success in the field of computer vision, has attracted the attention of the HSI processing community. However, due to the small training set with very few target spectra in the task of hyperspectral detection, DNNs designed for large datasets can hardly be utilized directly. In order to utilize the great representation power of a DNN, the training strategy, as well as the network structure and function must be carefully designed.
Furthermore, based on the whole new avenue opened up by DNNs, approaches of [
10,
11,
12,
13,
14] have been proposed accordingly, in which the neural network has been exploited as an unsupervised feature extractor. Specifically, in [
10], a distance-constrained stacked sparse autoencoder is utilized for feature extraction, which is able to maximize the distinction between the target pixels and the other background pixels in the feature space, and the process is followed by background suppression via a simple detector based on a radial basis function kernel. The authors of Ref. [
11] introduce two adversarial losses in the autoencoder to reconstruct enhanced hyperspectral images and utilize the RX detector for anomaly detection. Meanwhile, the autoencoder also proves effective to be exploited to extract spectral features [
12] which are further processed with band selection and spatial post-processing techniques for background suppression. Similar processing techniques can be found in deep latent spectral representation learning proposed in [
13]. Another approach that is comparable is 3-D macro–micro residual autoencoder (3-D-MMRAE) in which a convolutional autoencoder is built to extract the spectral and spatial features from both the macro and the micro branches, and the extracted features are further fed to a hierarchical radial basis function (hRBF) detector for target preservation and background suppression [
14]. The results have demonstrated the effectiveness of these approaches in HSI processing, but the underlying mechanism of the transformation process using an autoencoder remains to be uncovered.
Besides unsupervised approaches, supervised approaches have also garnered much attention. Furthermore, among such approaches, the subtraction pixel pair feature (SPPF), which tries to enlarge the training set by using pairs between target spectra and background spectra [
15], eclipses many others as a very effective approach. To be specific, the approach acquires a sufficiently large number of samples using SPPF and ensures the excellent performance of the multi-layer convolutional neural network. Perhaps more effective is the approach of [
16], which combines the representation-based method together with the linear mixing model to generate adequate background and target samples to train the neural network. Whilst being compared to [
15], the subtraction process in [
16] is performed in the final layer rather than the input layer, which improves the detection performance.
Apart from the approaches mentioned above, efforts performed from other angles which prove fruitful are [
17,
18,
19]. The authors of Ref. [
17] utilize a semi-supervised learning method through a two-step training process, which unfolds with the unsupervised pre-training of a generative adversarial network, followed by the fine-tuning of a discriminator through limited labeled samples. The authors of Ref. [
18] realize few shot learning based on domain adaptive approaches. To be specific, a network including both feature fusion and channel attention is built for feature extraction and, then, the learned features from different sensors are correlated through a discriminator whereby the weights learned in the source domain are able to be transferred to the target domain for the following few shot learning. The authors of Ref. [
19] approach the detection problem based on multiple instance learning, in which a sparsity constraint is introduced for the estimated attention factor of the positive training bags and ensures the approach yields superior performance.
In this paper, we propose a novel hyperspectral target detection approach with an auxiliary generative adversarial network. It is a neural network which can be trained with very limited target spectra directly without using any other preprocessing approaches. Similar to the general generative adversarial network [
20], the proposed network mainly contains two parts: a generator and a discriminator. The generator generates simulated target spectra and background spectra, which ease the problem of insufficient training samples. Then, the initial detection results can be acquired by a classifier which is highly correlated with the discriminator. Since the neural network only deals with the spectral information of pixels, post-processing techniques are added to make full use of the spatial information. Furthermore, in order to preserve the edges of the targets, several guided filters [
21] are utilized which can further suppress the background and improve the smoothness as well as the robustness of the detection results.
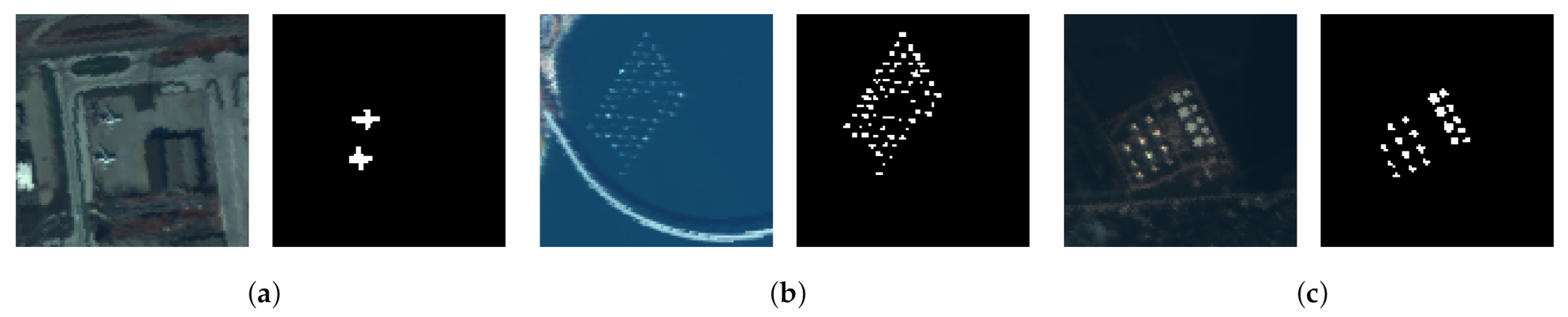
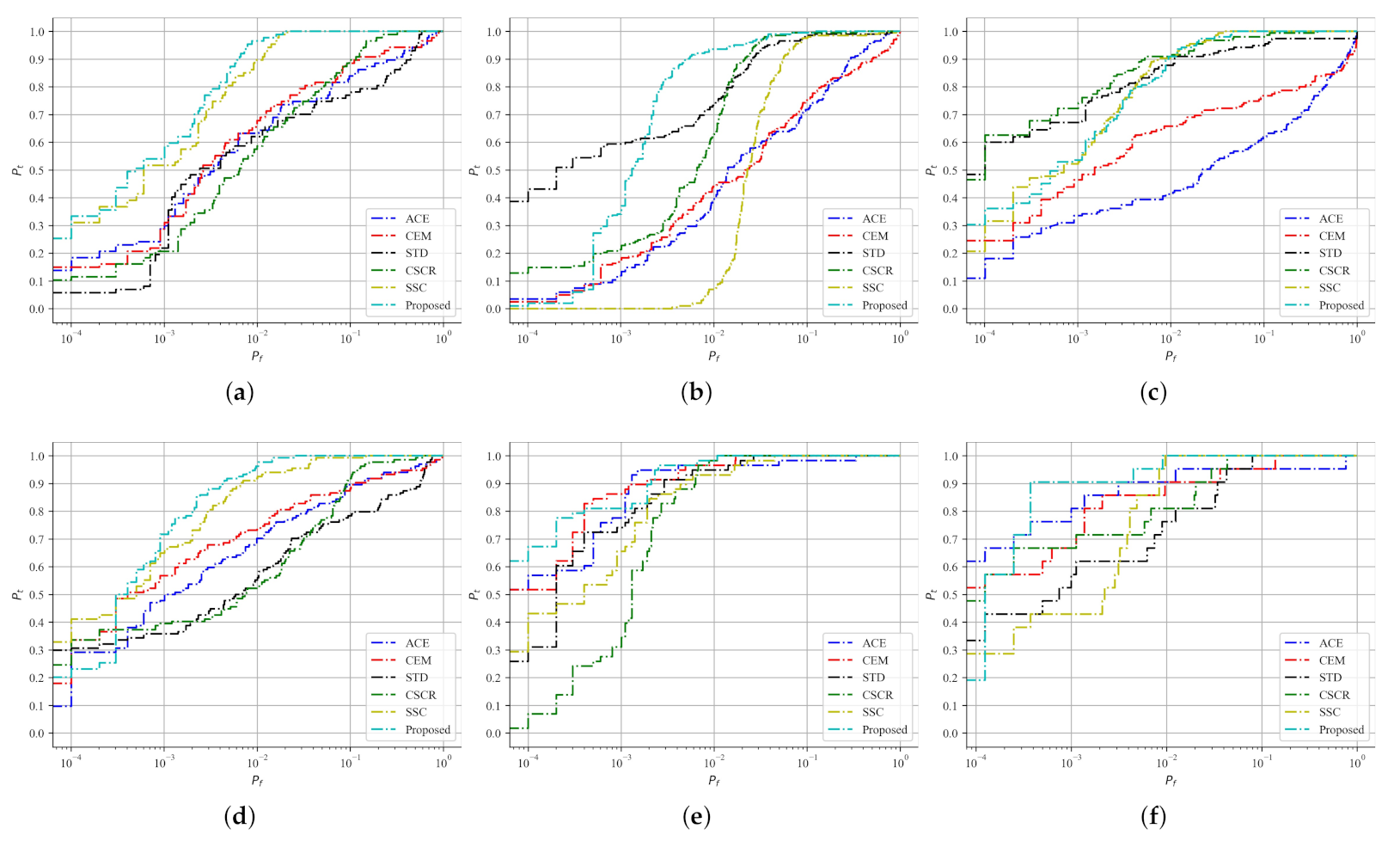
Extensive experiments have been conducted on real HSIs and the results show the proposed approach is more effective compared to the conventional target detection approaches. The contributions of the proposed approach are summarized as follows:
- (1)
A novel hyperspectral target detection framework based on the generative adversarial network is proposed, which can exhibit good performance while being trained with limited target spectra.
- (2)
During the training process, a generator capable of generating simulated target spectra is obtained. Furthermore, the generated targets as well as the background spectra allow us to better understand the real distributions of the target and the background.
- (3)
A combination of guided filters is adopted to further suppress the background, which ensures the smoothness and robustness of the results and makes the processing of various sizes of targets possible.
The remainder of this article is organized as follows:
Section 2 introduces the relevant theories and the proposed approach based on the generative adversarial network in detail.
Section 3 shows the analysis process and the experimental results.
Section 4 puts forward a brief discussion on similar approaches and sheds light upon the future work.
Section 5 draws the conclusion.
2. Materials and Methods
Before introducing the proposed approach, we first explicate the theories related to generative adversarial network and guided filter, which were used for spectral target detection and spatial smoothing in the proposed approach, respectively. In the following section of this paper, we examined the circumstantial process.
2.1. Generative Adversarial Network
Generative adversarial network (GAN) was first proposed and used for estimating generative models in [
20]. To achieve good performance, GAN utilizes two models: a generator and a discriminator, both of which can be realized by neural networks.
The basic idea of GAN is that the generator tries to generate fake samples and fool the discriminator, while the discriminator tries to distinguish between real samples coming from the data and fake samples coming from the generator. This adversarial competition drives both the generator and the discriminator to improve their performance until the generated or fake samples cannot be distinguished from the real ones. This process can be formulated in a more mathematical manner.
Suppose
,
denote data distribution and a random noise distribution, respectively. The generator builds a mapping
, where
denotes the distribution of generated samples. As for the discriminator, let
denote the probability of
x coming from
rather than
. Then, the objective function of the generator and the discriminator, denoted as
and
, can be formulated as Equations (
1) and (
2), respectively.
Thus, during alternate iteration of the training process, the final value function
can be formulated as Equation (
3).
The value function in Equation (
3) can be further interpreted as a distance metric, i.e., Jensen–Shannon divergence. In practice, however, vanilla GAN proposed in [
20] is usually hard to train in deep networks. Researchers holding different viewpoints have been working hard to propose various variants which can be optimized more easily, including the activation function, objective function and network architectures, etc.
For example, in [
22], several strategies for training stable deep convolutional GANs are suggested, including adopting batchnorm, using ReLU activation in the generator other than the output layer and using LeakyReLU activation in the discriminator. On the other hand, through the variational divergence estimation network, the training objective of GAN is generalized to arbitrary f-divergences in [
23]. Moreover, in order to accommodate different application scenarios, modified network architectures are introduced, such as information maximizing GAN (InfoGAN) [
24] and auxiliary classifier GAN (ACGAN) [
25].
Generally speaking, generative adversarial network is mainly utilized either to model the distribution of samples or to generate samples. Although there exist several criteria for evaluating the quality of generated samples, open issues still remain in the particular fields.
In the proposed approach, we exploit the core idea of GAN and try to detect targets through discrimination. To be more concrete, a detection network is built with an auxiliary GAN which provides supplementary samples and shares several layers with the detector. Furthermore, to fix the problem of the detection network in being only able to deal with spectral information, a spatial post-processing technique was employed in the training process.
2.2. Guided Filter
Guided image filtering is one kind of self-adaptive image filters. It computes the filtering process according to the content of a guided image which can be the input image itself or another image. To put it more specifically, the guided filter is assumed to be a local linear model between the guided image
I and the filtering output
q. Suppose
q is a linear transformation of
I in a local area
centered at the pixel
k [
21]:
where
and
denote linear coefficients which are assumed to be constant in
. On the other hand, the output
q is modeled as the input
p which eliminates a few other parts
n, defined as:
When Equations (
4) and (
5) are combined together, the previous tough issue is transformed into a minimization problem with a quadric formula:
where
is a regularization parameter which penalizes large
.
As an edge-preserving smooth operator, guided filter is faster and works better near edges when compared to the popular bilateral filters. Therefore, we adopted guided filter as a post-processing technique in the detection algorithm to further suppress the background information and the tiny isolated points in the previous detection maps.
2.3. Proposed Approach
In this section, we explain the proposed detection approach in detail. Firstly, a general introduction about the detection framework with circumstantial explanations was given. After that, the architectures of the network along with the training objective were introduced. Finally, a bank of guided filters used for spatial smoothing was illustrated briefly.
2.3.1. General Framework
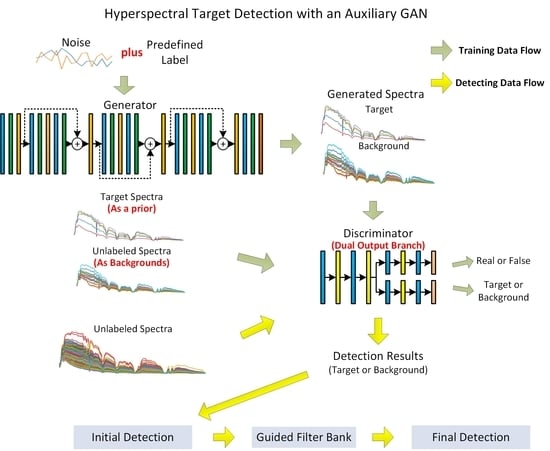
Given the fact that labeled target spectra are quite limited, unlabeled spectra including targets and backgrounds should, therefore, be utilized much more efficiently. To this end, our approach utilized the generative adversarial network to model the distributions of both the target spectra and the background spectra. Furthermore, to our delight, we found when the generative adversarial network converged, the generator would well generate both the simulated target spectra and the background spectra, and the discriminator was also able to extract useful information to be used for target detection. Hence, a target detector could be merged with the discriminator of a GAN. The general framework of the proposed approach is shown in
Figure 1.
As demonstrated in
Figure 1, the whole process of the proposed approach was divided into two phases: network training and detecting. In the training process, the target spectra together with the unlabeled spectra to be detected were regarded as the targets and the backgrounds, respectively, and were fed into the general adversarial network for training. Although it seemed venturesome to deem all of the unlabeled spectra as backgrounds, the generative adversarial network proved to be able to counteract the wrong apportionment very effectively with simulated samples. When the training process converged, the discriminator of GAN was selected as the detector in the detecting phase. In this process, we obtained an initial detection map through the discriminator based on the spectral information. Furthermore, to further suppress the background and the tiny outliers, guided filters were utilized to improve the smoothness and robustness of the detection results.
2.3.2. Network Architecture and Objective Function
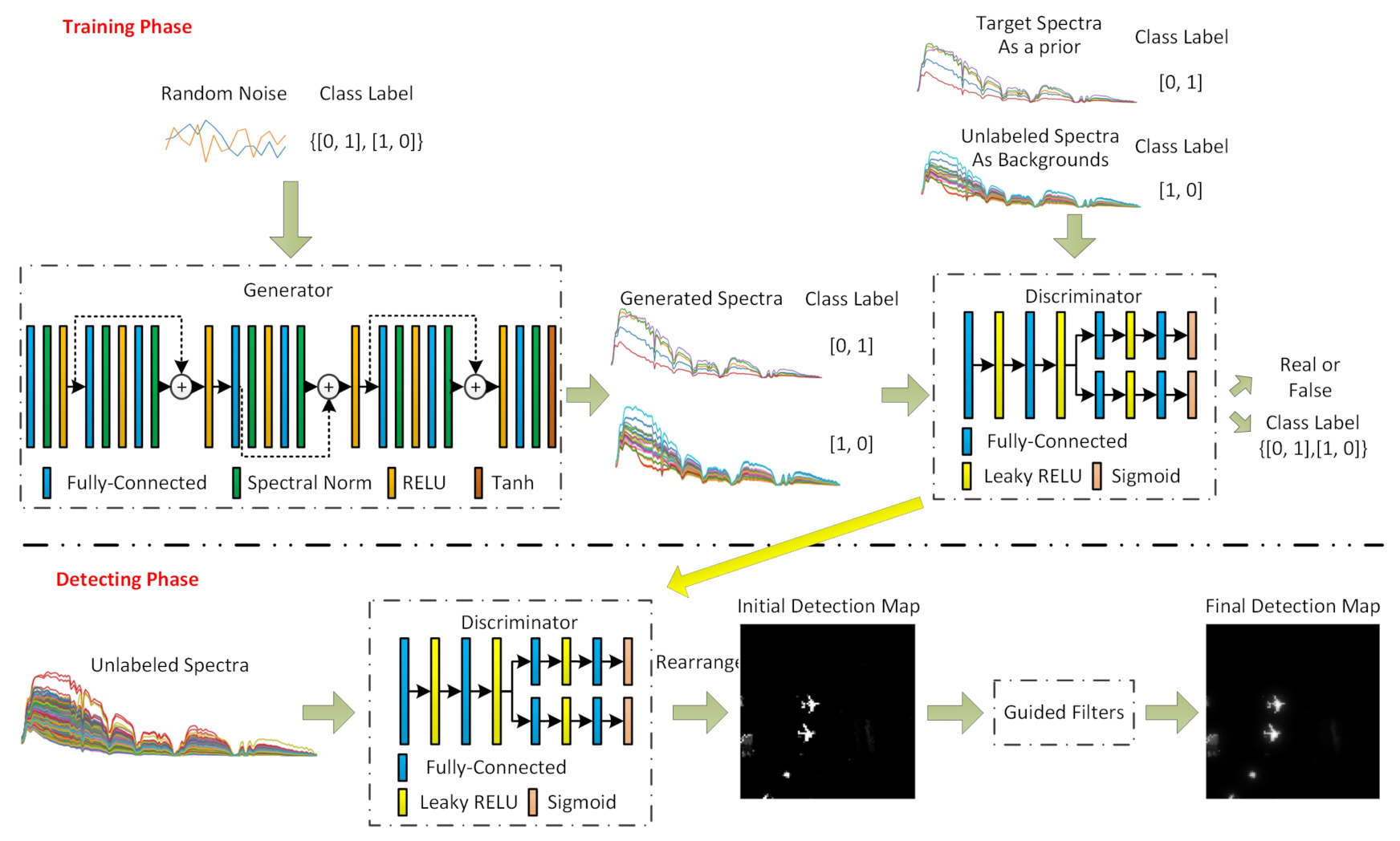
With respect to the specific network architectures, it should be noted that the neural network during training was divided into a generator network and a discriminator network. Furthermore, we followed different criteria while building these two networks for target detection.
As shown in
Figure 1, a residual structure was adopted in the generator, which was very expressive and could be used to well model the complicated distributions of the target and the background spectra. Meanwhile, in order to stabilize the training process, spectral normalization (SN) layers which were proposed in [
26] were added between every two fully connected layers. As for the discriminator, we designed a dual branch structure. One branch output the truth value indicating whether the sample was real or false, and the other output the class label indicating whether the sample was target or background. The dual branches shared as many layers as possible, linking the generative adversarial network with a detector. Parameters of our network are listed in
Table 1.
As the discriminator in the proposed network was able to provide two kinds of probabilities through the dual branches, viz. one for the truth value and the other for the class label, the loss of the discriminator denoted as
could, accordingly, be represented by two parts, i.e.,
for the truth loss and
for the class loss, which were similar to that of ACGAN as proposed in [
25] and could be defined as Equation (
7):
where
and
denote the truth values for real and generated samples separately and
c and
denote the real and the predicted class labels for all the samples, respectively. As shown in Equation (
7), the first two terms represented the hinge version of the adversarial loss as proposed in [
26,
27], while the third term represented the cross-entropy between the real and the predicted class labels. Through integrated loss, as the network converged, the discriminator could not only distinguish between real and generated samples, but also provide a class label for each sample.
As for the objective of the generator (denoted as
), the case became quite simple. As demonstrated in Equation (
8):
where
denotes a certain value on position
p of the generated spectrum
, the first term denotes the ordinary generative loss and is denoted as
, and the second term, represented as
, refers to the second-order difference and denotes a relatively weak but useful penalty which could help to smoothen the generated spectra and stabilize the training process. Worth noting,
is a penalty constant which was empirically set as 1.
As for the training process of the proposed network, it was very similar to that of conventional GAN. Specifically, the technique of back-propagation was utilized in the training process to minimize and alternately. When the network converged, it came to the detection phase. In this phase, the generator was removed and the discriminator was utilized as a detector to deal with the real spectra. Since we could utilize the discriminator at different times and with different weights, several initial detection maps could be acquired. To further suppress the background and the tiny outliers, necessary spatial processing techniques were adopted.
2.3.3. Bank of Guided Filters
Furthermore, since spatial correlation was useful in detecting certain objects in HSIs, a bank of guided filters could be utilized to smoothen the initial detection results. The framework of spatial filtering with guided filters is illustrated in
Figure 2.
As shown in
Figure 2, the initial detection maps obtained at different times were firstly filtered by the bank of filters individually. In this case, all the filters would adopt the initial input image as the guided image and they differed from each other only in radius
r and the regularization coefficient
. Then, different degrees and scales of smoothening procedures were conducted on the initial detection maps. After that, max pooling was performed on the filtered images to gather the most valuable information. At last, an overall average value regarding the images acquired at different times was calculated so as to obtain a relatively stable detection result.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}