1. Introduction
Satellite technology has developed rapidly since the last century, and remote sensing satellite images have gained widespread attention and applications in many fields. They provide an important reference for applications in digital maps, urban planning, disaster prevention and control, emergency rescue, and geological observations [
1,
2,
3,
4].
In most practical applications, remote sensing images with high spatial resolution and high spectral resolution are required. Given the physical structure of satellite sensors, a single sensor is unable to achieve this. Earth-observation satellites, such as Quick-Bird, IKONOS, and World-View, are equipped with sensors for obtaining high-spatial-resolution images for single bands and multispectral sensors for obtaining low-spatial-resolution images for multiple bands, which are acquired as panchromatic (PAN) and multispectral (MS) images, respectively.
In order to fully utilise all of the information available in the two types of images, PAN and MS images are usually fused using a pan-sharpening algorithm to simultaneously generate images having PAN image spatial resolution as well as the corresponding MS image spectral resolution. This results in images with high spatial resolution and high spectral resolution, which practical applications need.
Owing to the need for high-quality remote sensing images in practical applications, many researchers have studied varied directions related to pan-sharpening algorithms: (1) component substitution (CS) [
5,
6,
7,
8], (2) multiresolution analysis (MRA) [
9,
10,
11,
12,
13] (3) model-based algorithms [
14,
15,
16,
17,
18,
19,
20], and (4) algorithms for deep learning. The representative CS algorithms are principal component analysis (PCA) [
5], intensity-hue-saturation (IHS) transform [
6], Gram–Schmidt (GS) sharpening [
7], and partial substitution (PRACS) [
8]. These methods all adopt the core idea of the CS method, namely to first rely on the MS image in another space to separate the spatial-structure component and the spectral-information component, then match the PAN image and spatial-structure component using histograms and complete the replacement or partial replacement. This makes the PAN image have the same mean and variance as the spatial component. Finally, the pan-sharpening task is completed through an inverse transformation operation. These methods can achieve good results when PAN images are highly correlated with MS images, but owing to spectral differences between MS and PAN images, CS methods often encounter spectral-preservation problems and suffer from spectral distortion. Methods based on MRA are more straightforward than CS-based methods; these extract details from the PAN images and then inject them into the upsampled MS images. This approach makes the quality of the output image sensitive to the details of the injection, which makes the image blurred, while excessive detail injection leads to artifacts and spectral distortion. Decimated wavelet transform [
9], atrous wavelet transform [
10], Laplacian Pyramid [
11], curvelet [
12], and non-subsampled contourlets transform [
13] are examples of this approach. The hybrid method combines the advantages of the CS and MRA methods to improve the spectral distortion and fuzzy spatial-detail deficiencies, resulting in better fusion results.
Model-based methods are mainly based on the mapping relationship between MS images, PAN images, and the desired high-resolution multispectral (HRMS) images. If pan-sharpening can be viewed as an inverse problem, the PAN and MS images can be understood as degraded versions of the HRMS images and can be recovered through optimization procedures. As considerable information is lost during the degradation process, this is an unsettled problem. The general practice is to introduce prior constraints and regularization methods into formulas to fuse the images and thus to solve this ill-posed inverse problem. Representative algorithms include sparsity regularization [
14], Bayesian posterior probability [
15], and variational models [
16]. A hierarchical Bayesian model to fuse many multiband images with various spectral and spatial resolutions is proposed [
17]. An online coupled dictionary learning (OCDL) [
18], and two fusion algorithms [
19] that incorporate the contextual constraints into the fusion model via MRF models have been proposed. As these methods are highly dependent on regularization terms, the resulting solutions are sometimes unstable [
20]. These methods have much more temporal complexity than many other algorithms, but they can make immense progress in gradient information extraction.
In recent years, with the rapid development of artificial intelligence, algorithms based on deep learning methods have achieved impressive results in various image-processing domains. In the field of computer vision, CNNs have been successfully applied to a large number of domains, including target detection [
21], medical segmentation [
22], image fusion [
23], and image reconstruction [
24]. Due to the superior feature-representation capabilities of deep convolutional neural networks, many researchers have used the technique for pan-sharpening [
25,
26].
To some extent, image super-resolution reconstruction is a task associated with whole-chromatic sharpening, as super-resolution and euchromatic sharpening are both designed to improve image resolution. However, there are some differences between them, as the former is usually a single-input, single-output process, while the latter is a multiple-input, single-output case. Therefore, in earlier work, the PAN image and the MS image are usually cascaded together in the input grid for training, treating the pan-sharpening task as an image-regression task. Inspired by the super-resolution work based on CNN [
27], Masi et al. [
28] followed the three-layer CNN architecture in SRCNN to implement pan-sharpening and increase input by introducing nonlinear radiation exponents. This is the first application of pan-sharpening in the generalised sharpening field. In light of the significant improvement of the network training effect due to the residual structure, Rao et al. [
29] proposed RCNNP, a residual convolutional neural network for pan-sharpening, which continued to use a three-layer network structure when the idea of jump connections was introduced to help the network with training. Wei et al. [
30] designed a deep residual network (DRPNN) to complete the pan-sharpening task, and they extended the depth of the network to eleven layers, which improved the network performance. Based on these three papers, He et al. [
31] proposed two networks employing detail-injection ideas while clarifying the role of CNN in the pan-sharpening task from a theoretical perspective and clearly explaining the effectiveness of adding residual structure for pan-sharpening network improvement.
Although earlier CNN-based methods achieved better results than previous methods, they did not take into account the importance of spatial and spectral retention in the fusion process, treating it as a black-box learning process. To enhance the network’s ability to retain both spatial and spectral information, Yang et al. [
32] proposed a deep network architecture for pan-sharpening (PanNet), which differs from the other methods. To preserve the spectral information, they propose a method, called spectral mapping, that directly mapps the upsampled multispectral images to the network output for lossless propagation. To enhance the network’s focus on the spatial structure in PAN images, PanNet, unlike the previous work, chose to train the network in high-frequency domains. This idea from an earlier work helped them achieve remarkable results, but it had some limitations. It is generally believed in the pan-sharpening field that PAN and MS images contain different information. PAN images are the carriers of geometric-detail (spatial) information, while MS images provide the spectral information required to fuse the images. Although PanNet trains the network in the high-frequency domain, it still inputs PAN images and MS images after cascading into the network. This operation prevents the network from completely extracting different features contained in PAN and MS images and allows the network to effectively utilise varied spatial information and spectral information. Concurrently, it only uses a simple residual structure that complements the extraction of image features at various scales and lacks the ability to more efficiently recover details from the features. As the network outputs the fusion results directly through a convolutional layer, the network cannot make full use of all the features extracted by various residual blocks, affecting the final fusion effect.
In this study, we are inspired by the ideas of the detail-injection network and image super-resolution reconstruction network. We propose a dense encoder–decoder network with feedback connections for pan-sharpening. As the CNN methods in earlier works either viewed euchromatic sharpening as a super-resolution problem [
29,
30] or used a CNN as a tool to extract spatial details [
31,
32], they generate results with good visual quality, but spectral distortion or artifacts still exist. This is mainly because it is almost impossible to individually extract features representing spatial or spectral information from the input network by stacking the PAN image and the MS information together. To address this issue, we choose to perform image fusion at the feature level rather than at the pixel level, as in earlier works. We use a dual-stream network structure to extract features from the PAN and MS images separately, which allows the network to efficiently extract the desired spatial information and spectral information without interference. To extract richer and efficient multiscale features from images, we input efficient multiscale feature-extraction modules from the two-stream network. Given the powerful multilevel feature-extraction, fusion, and reconstruction capabilities of the encoder–decoder, the extracted multiscale features are encoded and decoded based on the idea of dense connections. The shallow networks are limited by the receptive field size and can only extract coarse features, which we have repeated in subsequent networks, owing to the idea of dense connections, which partly limits the learning power of the network. We, therefore, introduce a feedback-connectivity mechanism that transfers deep features back to the shallow network through long-jump connections to optimise coarse low-level features and improve early reconstruction capability by completing preliminary reconstructed-image correction for some incorrect features in the early network. Concurrently, we follow the idea of detail injection, using the fusion results of the network as the detail branch and low resolution multispectral (LRMS) images as the approximate branch. Both can help the network obtain excellent HRMS images.
In conclusion, the main contributions of this study are as follows:
We propose a multiscale feature-extraction block with an attention mechanism to address the issue of insufficient network extraction ability to extract diverse scales, which can not only effectively extract multiscale features but also utilise feature information between multiple channels. In addition, the spatial and channel-attention mechanisms can effectively enhance the acquisition of important features to the network so as to help the fusion and reconstruction of the later network.
We propose an efficient feature-extraction block with two-way residuals, which stacks three multiscale feature-extraction blocks, enables the network to extract multiscale features at different depths, and maps low-level features to high-level space with two jump connections for the purpose of collecting more information.
We use a network structure with a multilayer encoder and decoder combined with dense connections to complete the task of integrating and reconstructing the extracted multiscale spatial and spectral information. As the task of the deep network is to encode the semantic information and abstract information of images, it is difficult for the network to recover texture, boundary, and colour information directly from advanced features, but shallow networks are excellent at identifying such detailed information. We inject low-level features into high-level features via long-jump connections, making it easier for the network to recover fine real images, while numerous dense connection operations bring the feature graph at the semantic level in the encoder closer to the feature graph in the decoder.
We inject HRMS images from the previous subnetwork into the shallow structure of the latter subnetwork, complete the feedback connectivity operation, and attach the loss function to each subnetwork to ensure that correct deep information can be transmitted backwards in each iteration and the network can obtain better reconstruction capabilities earlier.
The rest of this article is arranged as follows. We present the relevant CNN-based work that inspired us in
Section 2 and analyse networks that have achieved significant results in the current pan-sharpening work based on CNN.
Section 3 introduces the motivation of our proposed dense encoder–decoder network with feedback connections and explains in detail the structure of each part of the network. In
Section 4, we show the experimental results and compare them with other methods. We discuss the validity of the various structures in the network in
Section 5 and summarise the paper in
Section 6.
3. Proposed Network
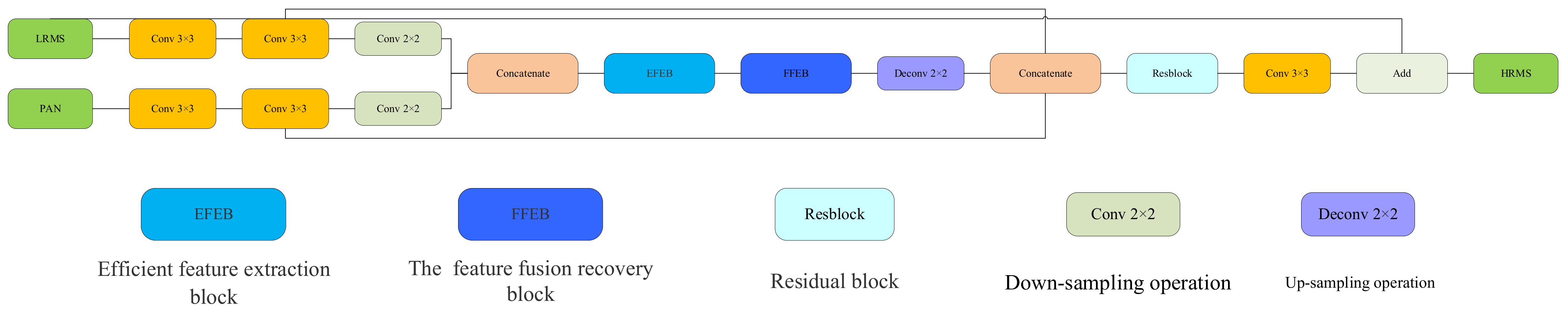
In this section, we detail the specific structure of the DEDwFB model presented in this study. As we use a detail-injection network, our proposed network has clear interpretability. The use of dense and feedback connections in the network gives the network excellent early ability to reconstruct images, while effective feature reuse helps the network alleviate the challenge of gradient disappearance and gradient explosion during gradient transmission, giving the network very good performance against overfitting. We give a detailed description of each part of the proposed network framework. As shown in
Figure 1 and
Figure 2, our model consists of two branches. One includes the LRMS image-approximation branch, which provides most of the spectral information and a small amount of spatial information needed to fuse the images, while the other is the detailed branch used to extract spatial details. This structure has clear physical interpretability, and the presence of approximate branching forces CNN to focus on learning the section information needed to complement LRMS images, which would reduce uncertainty in network training. The detail branch has a structure similar to the encoder–decoder system, consisting of a two-path network, multiscale feature-extraction networks, feature-fusion and recovery networks, feedback connectivity structures, and image-reconstruction networks.
3.1. Two-Path Network
In pan-sharpening, it is widely accepted that the PAN and MS images contain different information. PAN images are the carriers of geometrical detail information, while MS images provide spectral information for the fusion images. The goal of pan-sharpening is to combine spatial details and spectral information to generate new HRMS images.
Although PAN images are considered carriers of spatial information, they may also contain spectral information. Similarly, the spatial information required for the HRMS image is also present in the MS image. To make full use of the information of PAN and MS images, we rely on CNN to fully extract the varied spatial and spectral information in the images and to perform feature-fusion reconstruction and image-recovery work in the feature domain.
We used two identical network results to extract features from the PAN and MS images separately. One network took single-band PAN images (size H × W × 1) as input, while the other network used multiband MS images (size H × W × N) as input. Before entering the network, we upsampled the MS images by transposition convolution to make them the same size as the PAN image. Each subnetwork consists of two separate convolutional layers and a subsampling layer, each followed by a parametric rectified linear unit (PReLU). The downsampling operation improves the robustness of the input image to certain perturbations while obtaining features of translation invariance, rotation invariance, and scale invariance and reduces the risk of overfitting. Most CNN architectures utilise maximum or average pooling for downsampling, but pooling results in an irreparable loss of spatial information, which is unacceptable for pan-sharpening. Therefore, throughout the network, we use a convolutional kernel of step 2 for downsampling rather than simple pooling. The two-path network consists of two branches, each including two
layers and one
layer. We use
to represent convolution layers with size
f ×
f convolution kernels and n channels and use
to represent the PReLU activation function,
, while
represents the extracted MS and PAN image features, respectively, and
represents the concatenation operation:
3.2. Multiscale Feature-Extraction Network
Remote sensing images contain a large number of large-scale objects, such as buildings, roads, vegetation, mountains, and water bodies, as well as vehicles, ships, pedestrians, and municipal facilities. In order to obtain more accurate HRMS images, our network needs to have the ability to fully capture features having different scales from the PAN and MS images. The depth and width of the network have a clear effect on the network’s ability to acquire multiscale features. With a deeper network structure, the network can learn richer feature information and context-related mapping. Owing to the emergence of the ResNet [
35] network structure, optimizing the network training process by adding skip connections effectively solves the issues of gradient explosion, gradient disappearance, and training difficulties as the network structure deepens, ensuring that we can use deeper networks to obtain features at various scales. The inception structure proposed by an earlier study [
34] fully extends the width of the network so that the network can acquire features of various scales at the same depth.
Inspired by the idea of enhancing network feature extraction by extending network depth and width, we propose an efficient feature-extraction block (EFEB) to help the network efficiently acquire features at various scales. As shown in
Figure 3, EFEB consists of three identical multiscale feature-extraction blocks (MFEB) with attention mechanisms and two jump connections. MFEB can help the network acquire local multiscale features by extending network width at a single depth, while EFEB uses multiple MFEB features at various depths. As each MFEB output contains different features and makes full use of these different hierarchical features, we use a simple hierarchical feature-fusion structure that maps low-level features to advanced space through two jump connections, giving EFEB more efficient multiscale feature grasping.
Inspired by GoogLeNet, MFEB was designed to expand the ability of the network to obtain multiscale features using a structure shown in
Figure 4. To obtain features at different scales in the same level of the network, we used four parallel branches for separate feature extraction. On each clade, we used convolutional nuclei of sizes 3 × 3, 5 × 5, 7 × 7, and 9 × 9, respectively, to obtain receptive fields at different scales. However, this results in high computational costs, which increases the training difficulty of the network. Inspired by the structural improvement work of PanNet in a study [
40], we chose to similarly use the dilated convolution [
41] operation to expand the receptive field of small-scale convolutional kernels without additional parameters. As void convolution is a sparse sampling method, with a mesh effect when multiple void convolutions are superimposed, some pixels are not utilised at all while losing the continuity and correlation of information. This results in a lack of correlation between features obtained from distant convolution, which severely affects the quality of the last-obtained HRMS images. To mitigate this concern, we introduce Res2Net [
49]’s idea to improve the dilated convolution.
We used a dilated convolution block on each branch to gain more contextual information using a 3 × 3 layer and set the expansion rate to 1, 2, 3, and 4, equivalent to our use of convolutional kernels of sizes 3 × 3, 5 × 5, 7 × 7, and 9 × 9 but using a minimal number of parameters. To further expand the receptive field and obtain more sufficient multiscale features, we processed the features using a convolutional layer of 3 × 3 on each clade.
To mitigate the issue of grid effects caused by dilated convolution and the lack of correlation between the extracted features, we connected the output of the former branch to the next branch by jumping, which is repeated several times until the outputs of all branches are processed. This allows for different scale features to be effectively complementary and the loss of detailed features and semantic information to be avoided as large-scale convolutional kernels can be dominated by multiple small-scale convolutional cores. Jump connections between branches allow each branch to have continuous receptive fields of 3, 5, 7, and 9, respectively, while avoiding information loss from continuous use of dilated convolution. Finally, we fused the results from the four pathway cascades through a 1 × 1 convolutional layer. We then used spatial and channel-attention mechanisms through compressed spatial information to measure channel importance and compressed channel information to obtain measures of spatial location importance. Indicators indicate the importance of different feature channels and spatial locations that can help the network enhance features more important to the current task. To better preserve intrinsic information, the output features are fused to the original input in a similar manner, and the jump connections across the module effectively reduce training difficulty and possible degradation. This procedure can be defined as:
We use to represent convolution layers with size f × f convolution kernels and n channels.,, and represent the sigmoid activation functions, PReLU activation function, and global average pooling layer, respectively. and represent the measures of channel importance and the measures of spatial location importance, respectively. Furthermore, x represents multiscale features extracted from four branches with different-scale receptive fields, and represents the concatenation operation.
3.3. Feature Fusion and Recovery Networks
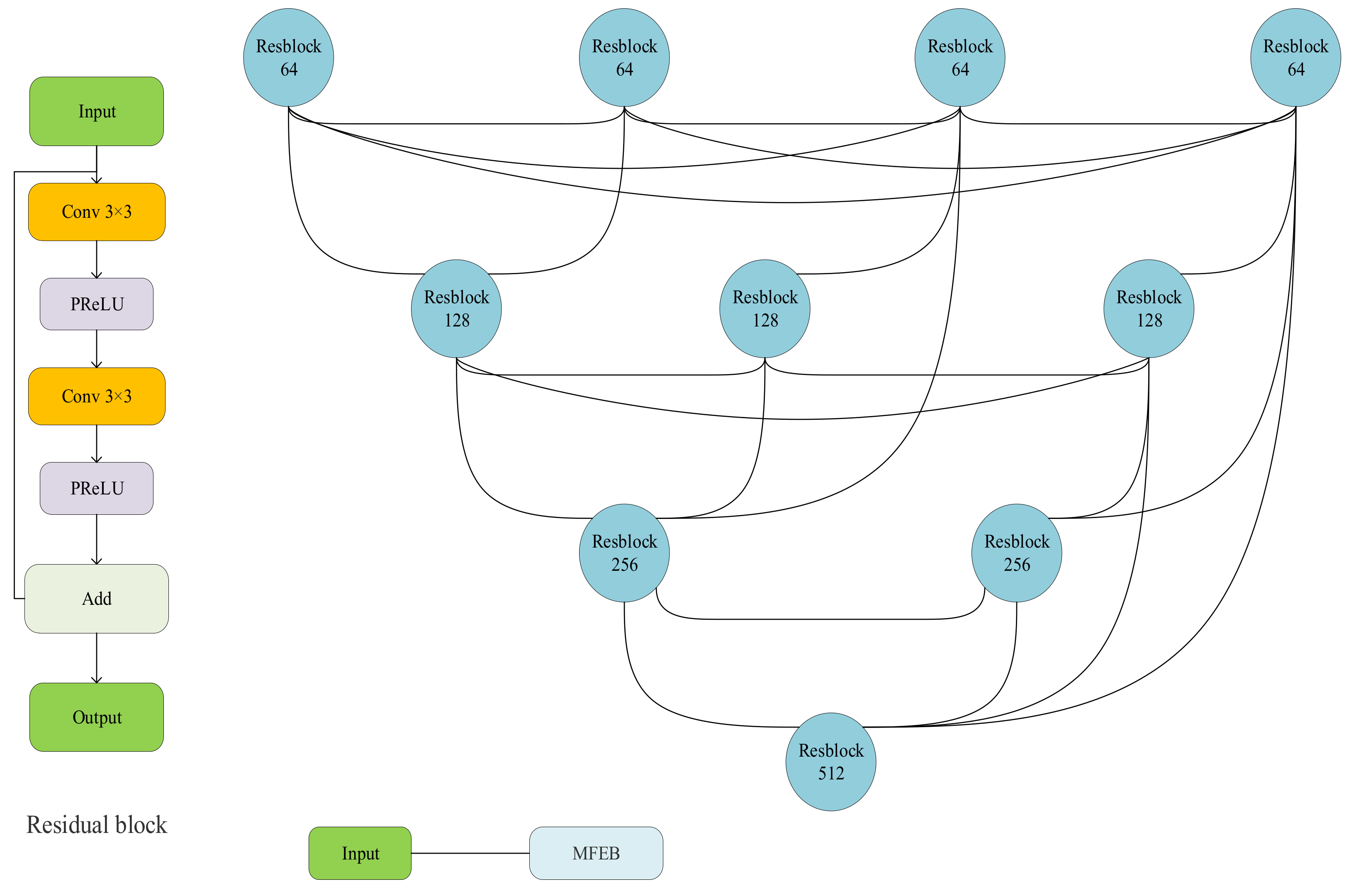
To effectively fuse the various levels of extracted multiple-scale features and recover high-quality HRMS images, we propose a feature-fusion and recovery block (FFRB) composed of densely connected encoders and decoders. The concrete structures of the FFRB and residual block are shown in
Figure 5. CNN-based pan-sharpening approaches, such as TFNet [
42], ResTFNet [
43], PSGAN [
45], and RED-cGAN [
46] adopt a fully symmetric encoder–decoder framework structure and achieve remarkable results. Unlike these works on network design based on the U-Net [
23] infrastructure, we are inspired by U-Net++ [
37] and U-Net3+ [
38] to propose more complex but more efficient encoder–decoder structures.
Owing to the different size of the receptive field, the shallow structure of the network focuses on capturing some simple features, such as boundary, colour, and texture information, whereas deep structures are good at capturing semantic information and abstract features. The downsampling operation improves the robustness of the input image to certain perturbations while obtaining features of translation invariance, rotation invariance, and scale invariance and reducing the risk of overfitting. Continuous downsampling can increase the receptive-field size and help the network fully capture multiscale features. The downsampling operation helps the encoder fuse and encode features at different levels, the edge and detail information of the image are recovered through the upsampling operation and decoder, and the reconstruction of the fusion image was initially completed. However, multiple downsampling and upsampling operations can cause edge information and small-scale object loss. The complex-encoded semantic and abstract information also poses substantial difficulties for the decoder.
As shown in
Figure 5, we used four residual blocks and three downsampling operations to compose the encoder network. Unlike other fully symmetrical encoder–decoder structures in the work, we used six residual blocks to constitute the decoder network and add an upsampling layer before each decoder. In the network, we doubled the number of channels of the feature graph by each subsampled layer and halve the number of feature-graph channels at each upsampled layer. As we changed the number of channels after each downsampling and upsampling, given that the jump connection of the residual block requires input and output with the same number of channels, we changed the number of channels via a 1 × 1 convolutional layer.
To effectively compensate for the information lost in multiple downsampling and upsampling operations and to reduce the difficulty for the decoder to recover features from highly complex and abstract information, we introduced the idea of dense connectivity in the encoder-decoder structure, adding dense connectivity between encoders and decoders with the same size of the feature graph, which not only places the encoder and decoder at a similar semantic level but also improves the ability of the network to resist overfitting. Different levels of features focus on different information but are consistent with the importance of completing pan-sharpening, and in order to obtain higher precision images while enhancing the ability of the network to explore full-scale information and make full use of all levels of features, we also added dense connections between decoders acting on the same encoder. The input to each decoder is composed of feature maps in encoders and decoders with the same scale and large scale that capture fine-grained and coarse-grained semantics at the full scale.
3.4. Feedback Connection Structure
Li et al. [
50] carefully designed a feedback block to extract powerful high-level representations for low-level computer-vision tasks and transmit high-level representations to perfect low-level functions. Fu et al. [
44] added this feedback connection mechanism for super-resolution tasks to the network for pan-sharpening. They enable the feature-extraction block to generate more powerful features by iterating the information in each subnetwork to the same module of the next subnetwork, iteratively up and downsampling the input features to achieve the feedback connectivity mechanism.
Our proposed network has a similar structure to that of TPNwFB, which consists of four identical subnetworks, each with a specific structure, as shown in
Figure 2. Compared to feedforward connections, each network layer can only accept information from the previous layer, and the shallow network cannot access useful information from the deep network, so it can only extract the underlying features, lacking sufficient context information and abstract fields. Feedback connections can input features that have already completed the initial reconstruction as depth information into the next subnetwork. The high-level information transmitted can complement the semantic and abstract information lacking in low-level features, correct the misinformation carried in low-level features, correct some previous states, and provide the network with significant early reconstruction capability.
3.5. Image Reconstruction Network
We reconstructed the images from the recovered features using a residual block and a convolution layer of 3 × 3. We upsampled the recovered features to the same scale as the PAN image and injected them into the residual block after they were stacked with the features extracted by the two-path network, which helps compensate for the information lost by the network during convolution while effectively reducing the training difficulty of the network. Finally, the detailed features needed to complement the LRMS images were recovered by a convolutional layer and interacted with the LRMS in the approximate branch to generate high-quality HRMS images. This procedure can be defined as:
We use to represent cascading operations. and represent convolutional and deconvolutional layers, respectively, and f and n represent the size and number of channels of convolutional kernels. and represent the residual blocks and the feature-fusion reconstruction blocks, respectively.
3.6. Loss Function
The L2 loss function may cause local minimization problems and result in artifacts in the image-smoothing region. Simultaneously, the L1 loss function yields a good minimum, and the L1 loss function retains the spectral information, such as colour and brightness, better than the L2 loss function. Therefore, we chose the L1 loss function to optimise the parameters of the proposed network. We attached the loss function to each subnet, ensuring that the information passed to the latter subnetwork in the feedback connection is valid:
where
,
and
represent a set of training samples;
and
refer to the PAN image and low-resolution MS image, respectively;
represents high-resolution MS images;
represents the entire network; and
is the parameter in the network.
4. Experiments and Analysis
In this section, we demonstrate the effectiveness and superiority of the proposed method through experiments on the QuickBird, WorldView-2, WorldView-3, and IKONOS datasets. In early experiments, the best model is selected for experiments by comparing and evaluating the training and test results of various network parameter models. Finally, the visual and objective metrics of our best model are compared with several existing traditional algorithms and CNN methods to demonstrate the superior performance of the proposed method.
4.1. Datasets
For QuickBird data, the spatial resolution of the MS image is 2.44 m, the spatial resolution of the PAN image is 0.61 m, and the MS image has four bands, i.e., blue, green, red, and near-infrared (NIR) bands, with a spectral resolution of 450–900 nm. For WorldView-2 and WorldView-3 data, the spatial resolutions of the MS images are 1.84 m and 1.24 m, respectively, the spatial resolutions of the PAN images are 0.46 m and 0.31 m, respectively, the MS image has eight bands, i.e., coastal, blue, green, yellow, red, edge, NIR and NIR 2 bands, and the spectral resolutions of the images are 400–1040 nm. For IKONOS data, the spatial resolution of the MS image is 4 m, the spatial resolution of the PAN image is 1 m, and the MS image has four bands, i.e., blue, green, red, and near-NIR bands, with a spectral resolution of 450–900 nm.
The network architecture in this study was implemented using the PyTorch deep learning framework and trained on an NVIDIA RTX 2080Ti GPU. The training time for the entire program was approximately eight hours. We used the Adam optimisation algorithm to minimise the loss function and optimise the model. We set the learning rate to 0.001 and the exponential decay factor to 0.8. The LRMS and PAN images were both downsampled by Wald’s protocol in order to use the original LRMS images as the ground truth images. The image patch size was set to 64 × 64 and the batch size to 64. To facilitate visual observation, the red, green, and blue bands of the multispectral images were used as imaging bands of RGB images to form colour images. The results are presented using ENVI. In the calculation of image-evaluation indexes, all the bands of the images were used simultaneously.
Considering that different satellites have different properties, the models were trained and tested on all four datasets. Each dataset is divided into two subsets, namely the training and test sets, between which the samples do not overlap. The training set was used to train the network, and the test set was used to evaluate the performance. The sizes of the training and test sets for the four datasets are listed in
Table 1. We used a separate set of images as a validation set to assess differences in objective metrics and to judge the quality of methods from a subjective visual perspective, each consisting of original 256 × 256 MS images and original 1024 × 1024 PAN images.
4.2. Evaluation Indexes
We contrast the performance of different algorithms through two different types of experiments, i.e., simulation experiments with HRMS images as a reference and real experiments without HRMS images as a reference, because in the actual application scenarios of remote sensing images, there is often a lack of HRMS images. In order to more objectively evaluate and analyse the performance of different algorithms in different aspects of different datasets, we selected ten objective evaluation indicators according to the characteristics of simulation experiments and real experiments. Depending on whether or not reference images are used, they can be divided into reference indicators and non-reference indicators.
The universal image quality index [
51], averaged over the bands (Q_avg) and its four-band extension, Q4 [
52] represents the quality of each band and the quality of all the bands, respectively. The relative global dimensional synthesis error (ERGAS) [
32], also known as the relative overall two-dimensional comprehensive error, is generally used as the overall quality index. The relative average spectral error (RASE) [
42] estimates the overall spectral quality of the pan-sharpened image. Structural similarity (SSIM) [
53] is a measure of similarity between two images. The correlation coefficient (CC) [
43] is a widely used index for measuring the spectral quality of pan-sharpened images. It calculates the correlation coefficient between the generated image and the corresponding reference image. The spectral angle mapper (SAM) [
54] measures the spectral distortion of the pan-sharpened image compared with the reference image. It is defined as the angle between the spectral vectors of the pan-sharpened image and the reference image in the same pixel. The closer Q_avg, Q4, SSIM, and SCC are to 1, the better the fusion results, while the lower SAM, RASE, and ERGAS are, the better the fusion quality.
To evaluate these methods in the full-resolution case, we used the reference-free mass index (QNR) [
55] and its spatial index (DS), as well as the spectral index (Dλ) for quantitative evaluation. QNR primarily reflects the fusion performance with no real reference values and is composed of Ds and Dλ. The Ds index being close to 0 indicates good structural performance; the Dλ index being close to 0 shows good fusion in the spectrum; and a QNR value close to 1 indicates the original full-colour pan-sharpening performance. As these metrics rely heavily on raw MS and PAN images, often, quantifying the similarity of certain components in the fusion images to low-resolution observations would bias these indicator estimates, and for this reason, some methods can generate images with high QNR values but poor quality.
4.3. Simulated Experiments and Real Experiments
To verify the effectiveness and reliability of the proposed network, we performed simulated and real experiments on different datasets. Some representative traditional and deep learning-based algorithms were selected from four datasets, and performance was compared between different methods by subjective visual and objective metrics. The selected traditional algorithms include the CS-based methods, such as IHS [
5], PRACG [
8], HPF [
56], and GS [
7]. Among the MRA-based methods, DWT [
9] and GLP [
57] were considered. One model-based method, PPXS [
58], was considered. We selected five deep learning-based methods as contrast objects, including PNN [
28], DRPNN [
30], PanNet [
40], ResTFNet [
43], and TPNwFB [
44].
4.3.1. Experiment with QuickBird Dataset
The fusion results using the QuickBird dataset with four bands are shown in
Figure 6.
Figure 6a–c shows the HRMS, LRMS, and PAN (with a resolution of 256 × 256 pixels),
Figure 6d–j shows the fusion results of the traditional algorithms, and
Figure 6k–p shows the fusion results of the deep learning methods.
Based on the analysis of all the fused and contrast images, it can be intuitively observed that the fused images of the seven non-deep learning methods have obvious colour differences. These images have distinct spectral distortions, with some ambiguity in the edges of the image. Significant artifacts appear around moving objects. Among these methods, the spectral distortion of the DWT image is the most severe. The IHS fusion image has an obvious detail loss in the obvious part of the changing spectral information. The spatial distortion of the PPXS is the most severe, and the fusion image presents a very vague effect. GLP and GS present significant edge blur in the spectral distortion region, and the PRACS method presents artifacts in the image edges, while HPF images show slight blur and edge-texture blur on the image. The deep learning methods show good fidelity to spectral and spatial information on the QuickBird dataset, and it is difficult to determine the texture details of image generation through subjective vision. Therefore, we further compared the following metrics and objectively analysed the advantages and disadvantages of each fusion method.
Table 2 lists the results of objective analysis of each method according to the index values.
Objective evaluation metrics show that deep learning-based methods show significantly better performance than conventional methods in terms of evaluating spectral information as well as the metrics for measuring spatial quality. Among traditional methods, the HPF method achieves the best results on the overall metrics, but there is still a huge gap compared to those using deep learning. The HPF and GLP methods differ only slightly in other metrics, but the HPF method outperforms the GLP method in maintaining spectral information, while GLP’s spatial details are better. With extremely severe spectral distortion and ambiguous spatial detail, the DWT band exhibits extremely poor performance across all metrics. The PPXS RASE index evaluation outperforms only the serious DWT, shows spatial distortion, and the fusion image is fuzzy. However, it has a good retention of spectral information. In CNN-based methods, affected by the network structure, the more complex networks can achieve better results in general. As only the three-layer network structure was used, even when the nonlinear radiation metrics were introduced with added input, PNN showed the worst performance in the deep learning-based approach. Networks using dual-stream structures achieve significantly superior performance over PNN, DRPNN, and PanNet, bringing the texture details and spectral information of the fused images closer to the original image. Although our proposed network and TPNwFB use feedback connectivity, we use a more efficient feature-extraction structure. Therefore, whether one indicator evaluates spatial or spectral information, the proposed neural network outperforms all compared fusion methods, without obvious artifacts or spectral distortion in the fusion results. These results demonstrate the effectiveness of our proposed method.
4.3.2. Experiment with WorldView-2 Dataset
The fusion results using the WorldView-2 dataset with four bands are shown in
Figure 7.
Figure 7a–c shows the HRMS, LRMS, and PAN (with a resolution of 256 × 256 pixels),
Figure 7d–j shows the fusion results of the traditional algorithms, and
Figure 7k–p shows the fusion results of the deep learning methods.
It is intuitively seen from the graph that the fusion images of non-deep learning methods have distinct colour differences compared to the reference images, and the results of traditional methods are affected by more serious spatial blurring than deep learning-based methods. PRACS and GLP partially recover better spatial details and spectral information, obtaining better subjective visual effects than other conventional methods. However, it is still affected by spectral distortion and artifacts. Through visual observation, it is intuitive that deep learning-based methods do better in the preservation of spectral information than conventional methods.
Table 3 presents the results of objective analysis of each method according to the index values. On the WorldView-2 dataset, images produced using conventional algorithms and fusion images produced based on deep learning algorithms do not show significant gaps in various metrics, but the latter still performs better from all perspectives.
Unlike other methods, PanNet chose to train networks in the high-frequency domain, still inevitably causing a loss of information, even with spectral mapping. Owing to the differences between datasets, it is harder to train deep learning-based methods on WorldView-2 datasets than on other datasets. This results in PanNet failing to achieve satisfactory results on the objective evaluation indicators. Notably, the networks using the feedback connectivity mechanism yielded significantly better results than other methods, with better objective evaluation of metrics, indicating that the fusion images are more similar to ground truth. On each objective evaluation metric, our proposed method exhibits good quality in terms of spatial detail and spectral fidelity.
4.3.3. Experiment with WorldView-3 Dataset
The fusion results using the WorldView-3 dataset with four bands are shown in
Figure 8.
Figure 8a–c shows the HRMS, LRMS, and PAN (with a resolution of 256 × 256 pixels),
Figure 8d–j shows the fusion results of the traditional algorithms, and
Figure 8k–p shows the fusion results of the deep learning methods.
Table 4 presents the results of objective analysis of each method according to the index values.
On the WorldView-3 dataset, non-deep learning methods are still affected by spectral distortion, which is particularly evident with buildings. The DWT fusion images exhibit the most severe spectral distortion and a loss of spatial detail. The IHS fusion images show partial details of some spectral distortion regions and fuzzy artifacts of the road-vehicle regions. The HPF, GS, GLP, and PRACS methods show good performance in the overall spatial structure, but they show distortion and ambiguity in spectrum and detail. The HPF and GS methods can show colours closer to the reference image, but the edges and details of the house are accompanied by artifacts visible to the naked eye. Spectral distortion in non-deep learning methods leads to local detail loss, with distortion and blurring of vehicle and building edges. Deep learning-based methods all reflect a better retention of spectral and spatial information as a whole.
To further compare the performance of the various methods, we analysed them using objective evaluation measures for different networks. Although PPXS achieved good evaluation on SAM, it has an obvious gap in terms of other metrics and other methods. The HPF and GLP methods show performance similar to that of deep learning methods on SAM metrics, achieving good results in preserving spatial information and yielding better spectral information in the fused results over other non-deep learning methods. However, they still have a large gap on RASE and ERGAS and the methods using CNN, indicating that there are more detailed blurs and artifacts in the fused images.
Among the CNN methods, PanNet showed the best performance, with superior results using high-frequency domains on the WorldView-3 dataset. ResTFnet and TPNwFB achieved similar performance, in addition to TPNwFB, still showing better performance in SSIM indicators, which shows that feedback connection operations in the network still play an important role. Compared with all the contrast methods, our proposed network more effectively retains the spectral and spatial information in the image, yielding good fusion results. Based on all the evaluation measures, the proposed method significantly outperforms the existing fusion methods, demonstrating the effectiveness of the proposed method.
4.3.4. Experiment with the IKONOS Dataset
The fusion results using the IKONOS dataset with four bands are shown in
Figure 9.
Figure 9a–c shows the HRMS, LRMS, and PAN (with a resolution of 256 × 256 pixels),
Figure 9d–j shows the fusion results of the traditional algorithms, and
Figure 9k–p shows the fusion results of the deep learning methods.
Table 5 presents the results of objective analysis of each method according to the index values.
All conventional methods produce images with apparent spectral distortion and blur or loss of edge detail. It is clear from the figure that the images obtained using the PNN and DRPNN methods have significant spectral distortion. At the same time, given that the spatial structure is too smooth and a lot of edge information is lost, the index value objectively shows the advantages and disadvantages of various methods, and the overall effect of deep learning is significantly better than that of traditional methods. These data suggest that networks with an encoder–decoder structure have better performance than other structures. ResTFNet obtained significantly superior results using this dataset. Through our proposal that the network-generated images closest approach the original image, the evaluation metrics clearly show the effectiveness of the method.
4.3.5. Experiment with WorldView-3 Real Dataset
For the full-resolution experiment, we used the model trained by the reduced-resolution experiment and the real data as the input to generate fused images. In this experiment, we directly input MS and PAN images into models without any resolution reduction, which guarantees the ideal full-resolution experimental results and follows a similar approach to those used by the other models.
The fusion results using the WorldView-3 Real dataset with four bands are shown in
Figure 10.
Figure 10a,b shows the LRMS and PAN (with a resolution of 256 × 256 pixels),
Figure 10c–i shows the fusion results of the traditional algorithms, and
Figure 10j–o shows the fusion results of the deep learning methods.
Table 6 presents the results of objective analysis of each method according to the index values.
By observing the fusion images, it is found that DWT and IHS show obvious spectral distortion. Although in the GS and GLP methods, the overall spatial structure information is well preserved, local information is lost. The merged images in the PRACS method were too smooth, resulting in severe loss of edge detail.
TPNwFB and our proposed method have the best overall performance and can demonstrate practical utility in using feedback connection operations in the network. An analysis of objective data shows that the index values of PPXS are significantly better than other methods in Dλ but decreased slightly in QNP and Ds. Deep learning-based methods show a certain performance gap in non-deep learning methods. However, given the extremely simple network structure of PNN and DRPNN, satisfactory results are not achieved. Considering three indicators, our proposed network achieves better results in full-resolution experiments, conclusively demonstrating that the proposed innovation plays a positive role in generalised sharpening.
4.3.6. Experiment with QuickBird Real Dataset
The fusion results using the QuickBird Real dataset with four bands are shown in
Figure 11.
Figure 11a,b shows the LRMS and PAN (with a resolution of 256 × 256 pixels),
Figure 11c–i shows the fusion results of the traditional algorithms, and
Figure 11j–o shows the fusion results of the deep learning methods.
Table 7 presents the results of objective analysis of each method according to the index values.
PRACS and PPXS obtain better visual effects in non-deep learning methods with sufficient retention of spectral information but still lack effective retention of detail compared to deep learning methods. Among the deep learning methods, ResTFNet and our proposed method achieved the best results on the whole, with full and effective retention of spatial details and spectral colour and comprehensive analysis of three objective evaluation indicators. The use of encoder–decoder structure in the network structure can effectively improve the performance of the network in real experiments.
4.3.7. Processing Time and Model Size
As shown in
Table 8, for different deep learning methods, our proposed method had the longest processing time in the test mode. Our method also has a far greater number of parameters than the other methods. The data clearly show that the more complex the model, the more time it takes to generate a single fusion image; however, a more complex structure can achieve better performance results. Our method is mainly designed to optimize the structure from the perspective of improving the effect of the fusion result. The issue of optimizing the network runtime was not considered.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}