Abstract
The noise in position time series of 568 GPS (Global Position System) stations across North America with an observation span of ten years has been investigated using solutions from two processing centers, namely, the Pacific Northwest Geodetic Array (PANGA) and New Mexico Tech (NMT). It is well known that in the frequency domain, the noise exhibits a power-law behavior with a spectral index of around −1. By fitting various noise models to the observations and selecting the most likely one, we demonstrate that the spectral index in some regions flattens to zero at long periods while in other regions it is closer to −2. This has a significant impact on the estimated linear rate since flattening of the power spectral density roughly halves the uncertainty of the estimated tectonic rate while random walk doubles it. Our noise model selection is based on the highest log-likelihood value, and the Akaike and Bayesian Information Criteria to reduce the probability of over selecting noise models with many parameters. Finally, the noise in position time series also depends on the stability of the monument on which the GPS antenna is installed. We corroborate previous results that deep-drilled brace monuments produce smaller uncertainties than concrete piers. However, if at each site the optimal noise model is used, the differences become smaller due to the fact that many concrete piers are located in tectonic/seismic quiet areas. Thus, for the predicted performance of a new GPS network, not only the type of monument but also the noise properties of the region need to be taken into account.
1. Introduction
Space geodetic techniques, and GNSS (Global Navigation Satellite System) in particular, are being used in the study of dynamics of the Earth’s crust [1]. GPS stations have been installed worldwide to measure their changes in position over time with millimeter-level accuracy, which is associated with a number of geophysical phenomena such as plate motion [2,3,4], earthquakes (i.e., pre-, co-, and postseismic offsets and transients) [5,6], glacial isostatic adjustment [7,8,9,10], ocean tide loading [11,12,13,14,15], and atmospheric loading [16,17]. These geophysical phenomena can be described by a trajectory model (also called functional model) [18,19,20] and the remaining difference between the model and observations is noise, which is assumed to be a sum of stochastic processes. It is well known that noise is temporally correlated, for which power spectral density follows a power-law behavior with a spectral index of approximately −1 [21,22]. In addition, Langbein (2012) [23] and Dmitrieva et al. (2015) [24] found that random walk (RW) is present in some of the GPS time series. The effect of RW is almost a doubling of the uncertainty of the estimated linear motion [23]. On the other hand, He et al. (2019) described the analysis of 110 stations from the global IGS core network with more than 12 years of observations for which the power spectral density seems to flatten at low frequencies for 3–5% of horizontal components and around 12% for the vertical component [25]. The result is a reduction of the trend uncertainty by a factor of approximately two. In this research, we investigate the flattening of the power spectral density in some time series of the 568 permanent GPS stations around the USA (United States of America) and Canada, e.g., those blanketing the Pacific Northwest and the central western coast of the USA, from Vancouver Island to southern of California, with a concentration of stations around the Los Angeles area monitoring the San Andreas fault. A small amount of flattening of the power spectral density at low frequencies is also caused by the estimation of the linear trend [26,27]. Therefore, only strong flattening that starts at a period of 1–2 years will be considered. Flattening that starts at a longer period will be assumed to be artificial or undetectable.
2. Materials and Methods: GPS Data Processing, Time Series Analysis, and Simulation Experiment
2.1. GPS Data Processing
We used data from 568 continuously operating GPS receivers distributed over the United States, including Alaska. These data were used to compute time series consisting of position estimates with 1-day sampling by the analysis centers—PANGA/CWU (Pacific Northwest Geodetic Array/Central Washington University) and New Mexico Tech (NMT). Their solutions are given in the global International Terrestrial Reference Frame ITRF2008 reference frame [28]. The analysis center CWU computes the daily positions using the Precise Point Positioning method using the GIPSY software developed by NASA’s Jet Propulsion Laboratory (JPL), which also provides the necessary satellite ephemerides [29], clock corrections, and wide-lane phase bias estimates [30]. Note that the station positions were loosely constrained during the initial estimation and subsequently transformed into the International Terrestrial Reference Frame (ITRF2008) using only the translation and rotation [28]—but not scale—components of the JPL-provided Helmert transformations. On the other hand, NMT processing was performed using the software GAMIT/GLOBK [31,32] utilizing the same stations in North America as those with the PANGA processing, but additional stations in other parts of the world were also included for the stability of the reference frame. The Vienna Mapping Function 1 (VMF1) grid was used in both processing by PANGA and NMT for handling the troposphere delay [33]. All common parameters used in both processing steps are explained in Herring et al. (2016) [34]. No common mode error filtering is used in any processing. It is important to emphasize that GAMIT double differencing does not remove common mode error. The network of GPS stations selected by NMT and PANGA is large (a quarter of the Earth’s surface), which dilutes the strong common mode error that is detectable over smaller regions. The final processing of these time series described by Herring et al. (2016) [34] rotates the loosely constrained solutions provided by PANGA and NMT in the NAM08 reference frame using GLOBK [31,32].
Our study focuses only on the PANGA and the NMT solution (the original time series are cwu.final_nam08.pos and nmt.final_nam08.pos). For both the PANGA and the NMT solutions, the baseline lengths are their uncertainties do not change between the “loose” solutions submitted by PANGA and NMT and the solutions rotated/translated in the NAM08 reference frame. The difference with the processing preformed at NMT is mainly due to how the scale parameter is handled. The strategy in the latter includes the scale in the Helmert transformation, whereas the scale is not estimated directly in the former. Montillet et al.’s (2018) [35] study emphasized that the choice of including a radial scaling degree of freedom during daily reference frame realization primarily impacts the average network radial height and produces apparent height anomalies in excess of 5 mm that persist for months. A comprehensive discussion about the Helmert transformation and the scale parameter can be found in references [34,35].
In our analysis, the 568 stations have time series that began on 1 of January 2008 and ended on 1 January 2018. Our reason for choosing a fixed data time span is to reduce the differences between random models at different time scales. We also choose GPS stations with very few data gaps, less than 8%, which reduced the total number to 568 sites. In Appendix A, Table A1 shows that the percentage of the 568 permanent GPS stations are listed with less than a 3% data gap for each time series. As a result, more than 90% of the stations have more than 9.7 years of data. The average, maximum, and minimum data gaps of the 568 stations are also listed in this table to supply information (see Table A1 in the Appendix A) on the quality of the selected time series used throughout this study.
The GPS stations analyzed in this study have large diversity of monuments on which the GPS antenna has been installed. The metadata file (or log file) associated with each station provides a description of the monument, often referred to as mast, pillar, roof top, tower, or tripod [36,37,38]. In this study, we classified all monument types into four categories: concrete piers (CP), deep-drilled brace monument (DDBm), shallow-drilled brace monument (SDBm), and roof top/chimney (RTC). This classification follows previous studies [39,40]. Concrete pier (CP) is a pillar that can reach several meters attached deeply into the ground (up to 10 m below the surface). DDBm is braced monument where four or five 2.5 cm-diameter pipes are installed and cemented into inclined boreholes with the antenna attached at ~1 m above the surface [40,41]. The pipes are also attached deeply below the surface (up to ~10 m) using heavy motorized equipment. SDB refers to the type of equipment attached to the surface (<1 m-deep) using a hand-driller. The fourth category (RTC) gathers the antennas installed on the top of buildings sometimes using a mast attached to a wall, or with a concrete support. Note that our classification is based on the monument’s description included in each log file available for each station (Table A1 in Appendix C gives more details on the monument type of the analyzed 568 sites).
2.2. GPS Time Series Analysis
First, outliers were removed from the time series. Outliers are observations that are larger than 3 times the interquartile range of the residual time series [42]. Second, the parameters of the trajectory model were estimated with weighted least-squares while the parameters of the model that describe the noise were estimated using maximum likelihood estimation [18,19]. For this estimation process, we used Hector software [43].
The trajectory model is a linear sum of the tectonic rate, seasonal signals, co-seismic offsets, and random stochastic processes (), see Bevis et al. [20]:
where is the initial position at the reference epoch , is the rate, and are the periodic motion parameters ( for annual and semiannual seasonal terms, respectively). The offset term can be caused by earthquakes, equipment (environment) changes, or human intervention, in which it is the magnitude of the change at epochs; is the total number of offsets; H is the Heaviside step function. The time of known offsets are retrieved from the station’s metadata. Finally, the automatic offset detection algorithm developed by Fernandes and Bos (2016) is applied to detect undocumented offsets [44].
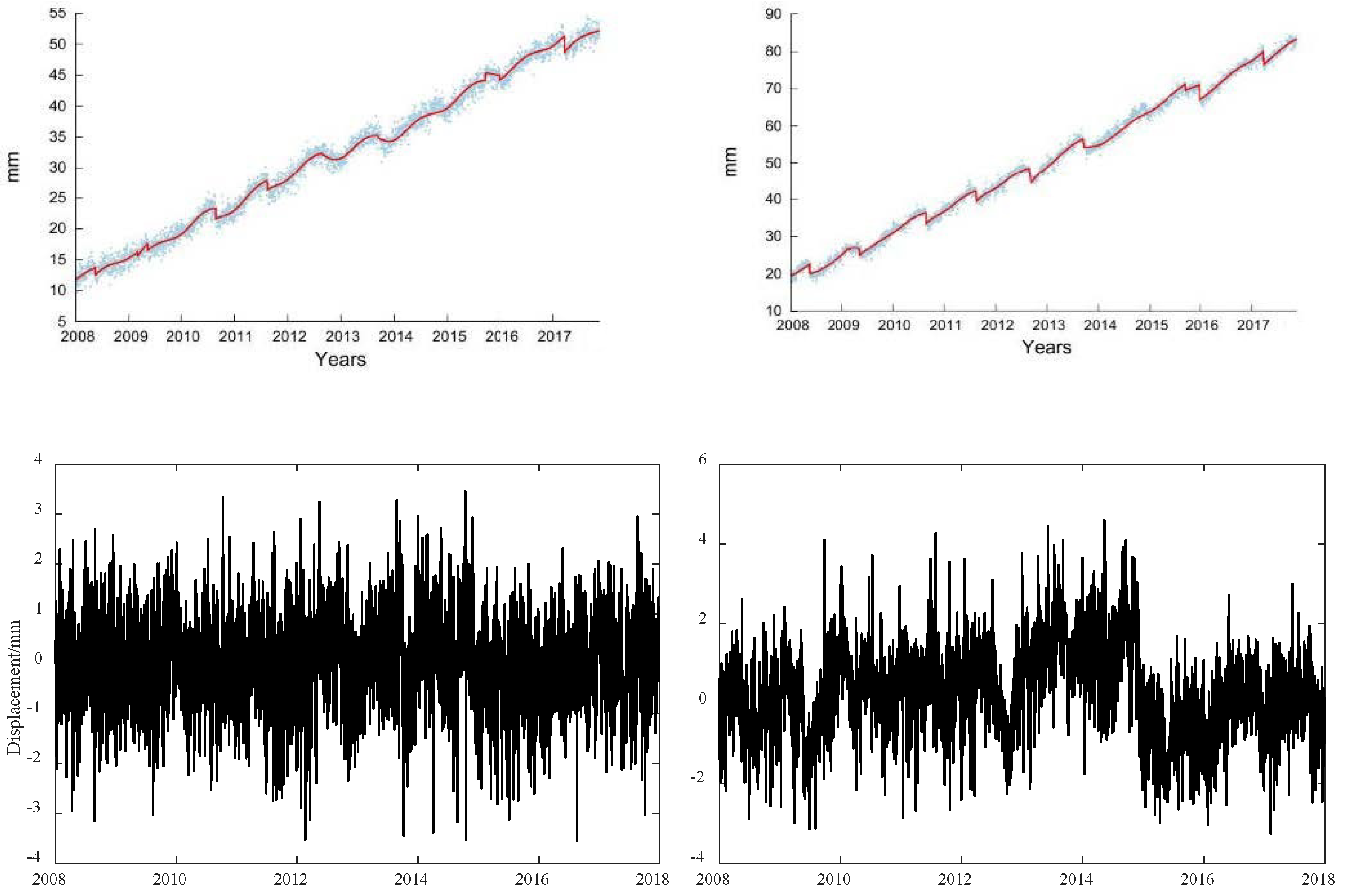
The Cascadia subduction zone is a convergent plate boundary that stretches from northern Vancouver Island in Canada to northern California in the United States. As we model and study time series of stations located in the Pacific Northwest including the Cascadia Mountains, specific events must be modeled, such as the Episodic Tremor and Slip (ETS) [45,46,47,48], for which we used the hyperbolic tangent function [49]. The amplitude of this function is described by . Finally, describes the noise/random stochastic processes. The time of the slow slip event and the delay of the postseismic deformation are required as input parameters for the estimation of the ETS using Hector [49] with a hyperbolic tangent of which the shape is prescribed by the time the ETS event occurred and its width (see in Appendix B). The times of the slow slip events can be requested from the Pacific Northwest Geodetic Array website or by a careful analysis of the time series with some training. The start of a slow slip event is evaluated via the correlation of seismic data together with a careful check of each time series [50]. In the remainder of this work, we use four delays—namely 30, 80, 100, and 130 days—for the postseismic deformation, because it is difficult to precisely estimate the duration of crustal decay. Note that these delays are conservative numbers knowing that the repetition of the ETS events is ~14 months, as evaluated by previous geophysical studies of Cascadia [35,50]. These values represent a tradeoff in not modeling enough the phenomenon, and in contrast, absorbing other geophysical phenomena due to an overestimation of the decay time [50,51,52]. Figure 1 displays an example of the functional model including slow slip events superimposed on the observations at station ALBH. In this example, we use a 100-day decay time scale, and at the bottom are the residuals of the time series.
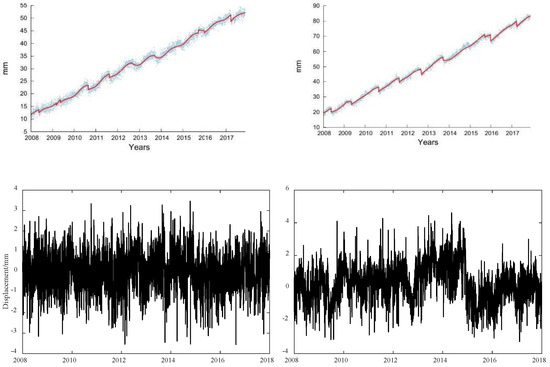
Figure 1.
GPS daily position time series for the North (left) and East (right) components of station ALBH with a functional model on top (red line) including a 100-day postseismic relaxation (the bottom figures are the residuals).
2.3. Stochastic Model Selection Criteria and Simulation Experiment
Power-law noise with a spectral index of −1 is called flicker noise (FN). Random walk (RW) noise has a spectral index of −2. Generalized Gauss Markov (GGM) noise is similar to power-law noise (PL) but flattens below a specified frequency. As noted in the introduction and shown in the following sections, the selection of the correct noise model has a significant influence on the trend uncertainty [21,23,53,54]. The theory of selecting the best model to describe the observation has a long history and many research areas simply use the Akaike or Bayesian Information Criterion [55,56]. However, Langbein (2004) followed a more empirical approach by performing Monte Carlo simulations using synthetic noise, and in this way, determined how much the difference between two log-likelihood values of two competing noise models must be before one can confidently choose one over the other [42]. In the report by Langbein (2004) and Santamaría-Gómez et al. (2011), the default noise model for these simulations, or the null model, was in all cases a random walk plus white noise and it was determined how much the log-likelihood value needed to be higher before one could accept another noise model as being better with 99% confidence [42,57]. The log-likelihood value will be abbreviated as MLE since it is estimated with the maximum likelihood method. Differences between two MLE values are represented as dMLE. The likelihood function represents a probability, although not normalized. Therefore, MLE and dMLE are logarithms of the probabilities and have no units.
We repeated the simulations using 5000 daily time series with a length of 10 years of synthetic random walk + white noise, each with amplitudes of 1 mm/yr0.5 and 0.5 mm, respectively—that is, for 5000 simulations, the dMLE for which there are 50 values greater is identified as the 99% level to reject the null hypothesis. The results are shown in Table 1.

Table 1.
Comparison of Monte Carlo simulation results of Langbein (2004) and our results (He et al.). Each column lists the dMLE value representing the needed difference in MLE value to avoid choosing the wrong noise model instead of RW with 99% confidence.
The Bayesian Information Criterion (BIC) and BIC_tp are defined as follows (He et al., 2019) [25]:
where MLE = ln(L), the log-likelihood value; ν is the number of parameters in the noise model; N is the number of observations. The noise model with the lowest BIC value is selected. For 10 years of daily observations, ln(N) = 8.2. Following Langbein (2004) and Santamaría-Gómez et al. (2011) [42,57], we can rewrite the difference in BIC values as a difference in MLE values:
where and are the number of parameters and and are the MLE values of the null and new models, respectively. If this criterion is larger than zero, then the new noise model (b) is more likely than the null model (n). RWFN and PL have one more parameter than RW while GGM has two more parameters, resulting in correction values of 4.1 and 8.2. For example, the MLE value for the GGM model needs to be 8.2 higher than that of RW before one can be confident that it is a better representation of the noise. These correction values are similar to the values listed in Table 1. For BIC_tp, the weight factor for each extra parameter in the noise model is 3.2 for time series with a length of 10 years instead of 4.1.
As in He et al. (2019) [25], we only consider the detection of GGM to be the most likely noise model significant if ϕ < 0.98; this parameter is also estimated by Hector. If this condition is not met, then the second most likely noise model is chosen. He et al. (2019) explained that this condition implies that we only detect GGM noise with flattening that already starts around a period of 1 year [25]. For the rest of this research, this extra condition of ϕ < 0.98 was always applied in addition to satisfying Equation (4).
The values of the parameters in the noise models used in the Monte Carlo simulations of Langbein (2004) [42] are slightly different from the noise values discussed here. To ensure the most realistic results, we determined the mean values for each estimated noise model for the horizontal and vertical components for our 5000 time series, see Table 2 and Table 3. For each noise model, 5000 synthetic noise time series were generated. Each of them was analyzed using FN + WN (Flicker Noise + White noise), RW + FN + WN (Random Walk + Flicker Noise + White noise), GGM + WN (Generalized Gauss Markov + White Noise), and PL + WN (Power-law + White noise).
Table 2.
Parameters used to create the various synthetic noise time series. These values correspond to those observed in the real TS, horizonal component. Note that for GGM and PL, the unit of the noise is mm/yr−0.25κ.
Table 3.
Same as Table 2 but for the vertical component.
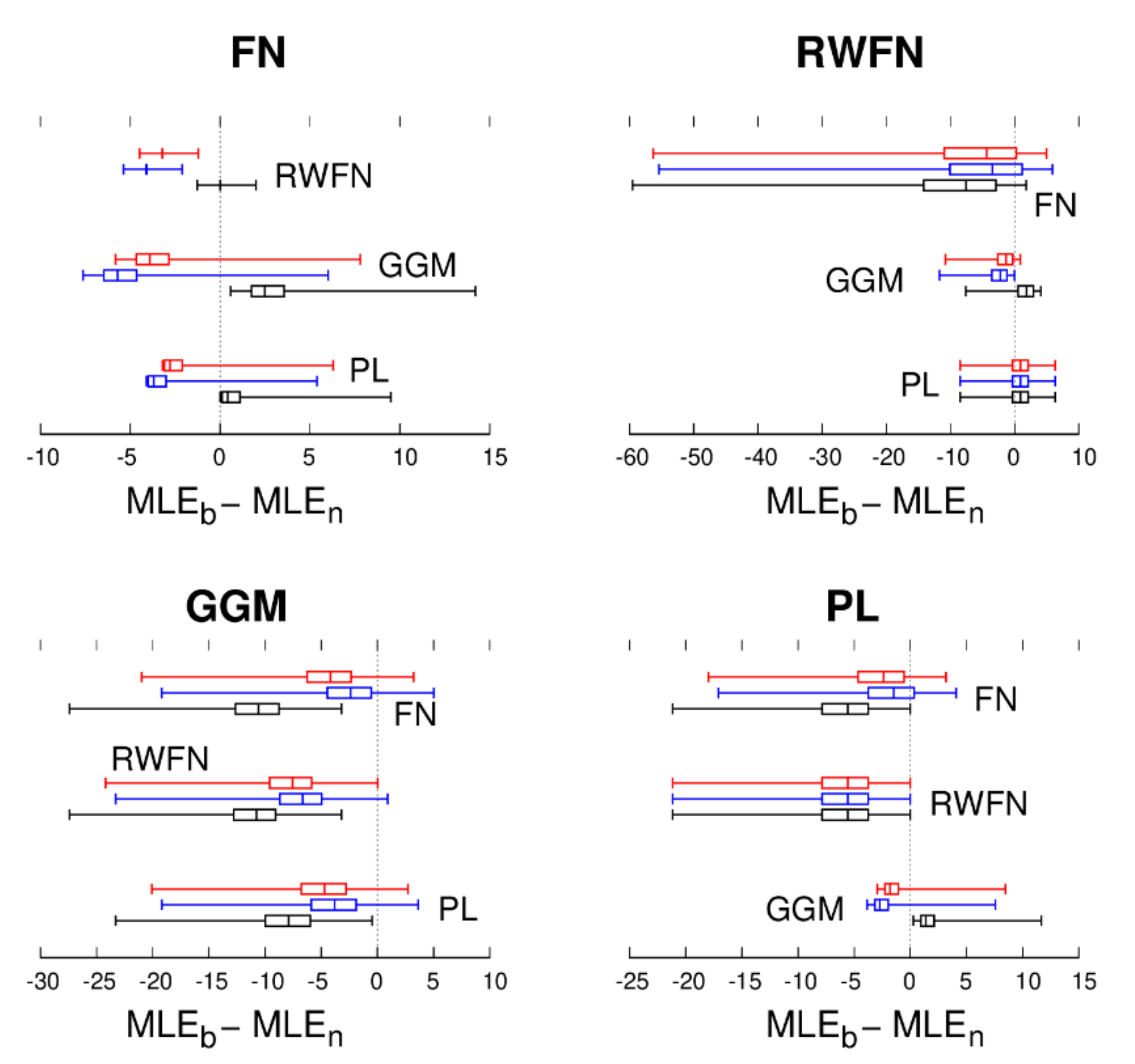
Instead of tabulating the 99% quantile of the difference in , we show all differences as box–whisker plots in Figure 2 and Figure 3. Thus, if all values in the box–whisker plots were negative, one could be 100% sure that using the selected noise model (the noise model we think is correct) with the highest MLE value would indeed reflect the true underlying noise models (better than the alternative noise models). One can see that this is not always the case. Applying the BIC correction (BIC and BIC_tp), resulting in the blue box–whisker plots, reduces the MLE of noise models with more parameters than the test/null model and increases it for models with fewer parameters. Therefore, BIC helps to detect FN noise while reducing the rate of detecting GGM noise. The red box–whisker plots represent the results of using BIC_tp. BIC helps increase the number of true positives (the true noise model was selected) and reduce the number of false positives (the false noise model was selected). Overall, its performance is better than BIC; thus, it will be used for the rest of this research.
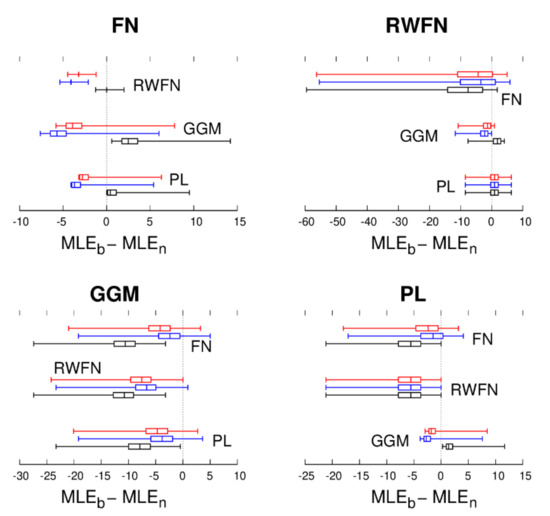
Figure 2.
For each of the noise models, FN, RW + FN, GGM, and PL 5000 synthetic TS were generated. The black box–whisker plots show how much the MLE of another noise model differs from the true one (). The blue and red box–whisker plots are the same after applying the BIC and BIC_tp corrections.
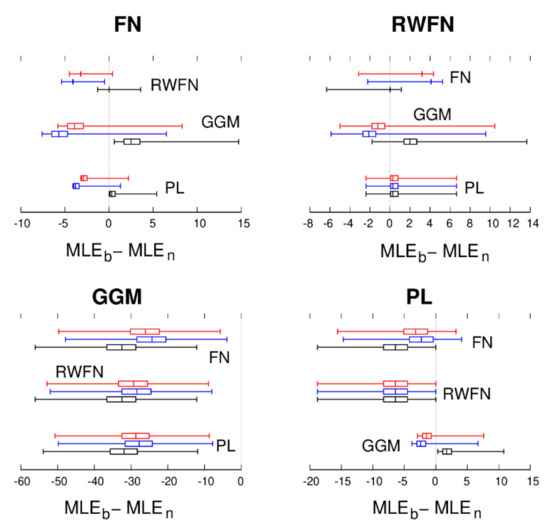
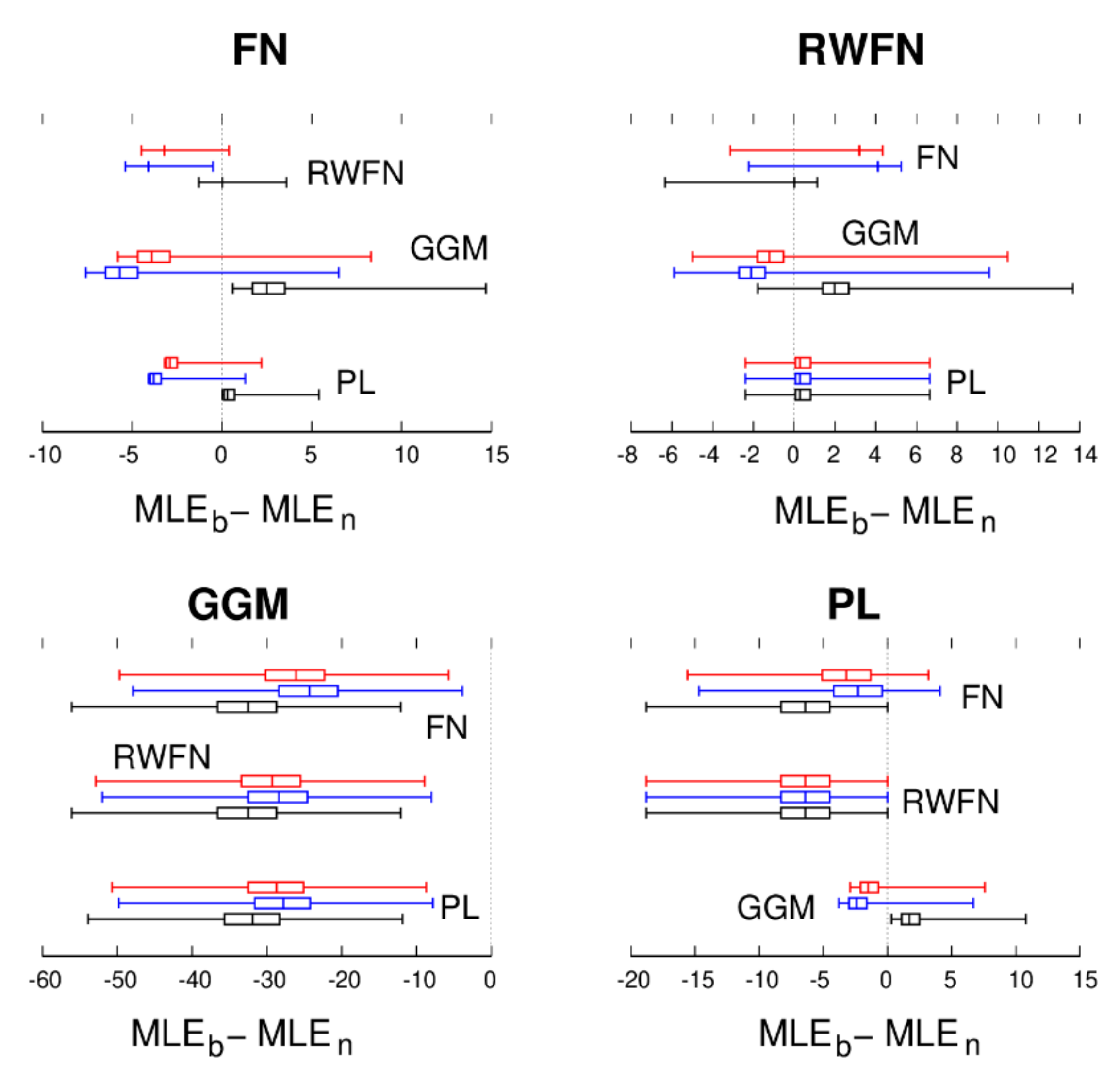
Figure 3.
Same as Figure 2 but for the vertical component.
From Figure 2 and Figure 3, it can be concluded from the RW + FN panels with positive box–whisker plots () that in many cases, PL + WN noise is detected while in fact, the true underlying noise is RW + FN + WN [23]. On the other hand, if RW + FN + WN noise is detected, then we have high confidence that it is correct since false positives are extremely rare—see also He et al. [25]. Important for this research is the fact that for synthetic GGM, the MLE of the other noise models is always lower than that of GGM. In addition, from the other panels of Figure 2 and Figure 3 one can also see that GGM is almost never selected when the underlying noise is not GGM. Thus, we can conclude with great confidence that any detection of GGM using BIC or BIC_tp is correct.
The random walk + flicker + white noise model was used by Langbein and Svarc [40] in the analyses of their time series. However, the analyses of our time series show that some flatten at low frequencies, which can be better described by a GGM noise model. These different conclusions might be caused by the fact that Langbein and Svarc [40] analyzed regionally filtered time series, whereas we are looking at unfiltered time series that are noisier and in which the smaller random walk signal might be hidden.
Note that Santamaría-Gómez et al. (2011) [57] concluded that using neither AIC nor BIC is recommended as a means to discriminate between models. Using similar Monte Carlo simulations, the reader should be convinced that for the time series of a length of 10 years used in this research, the performance of BIC and BIC_tp is actually similar to that of using the approach of Langbein and Svarc (2019) [40], leaving the general debate of using or not using the information criteria in the selection of the stochastic noise model for the future.
3. Results and Discussion with Real GPS Time Series
3.1. Multitaper Analysis
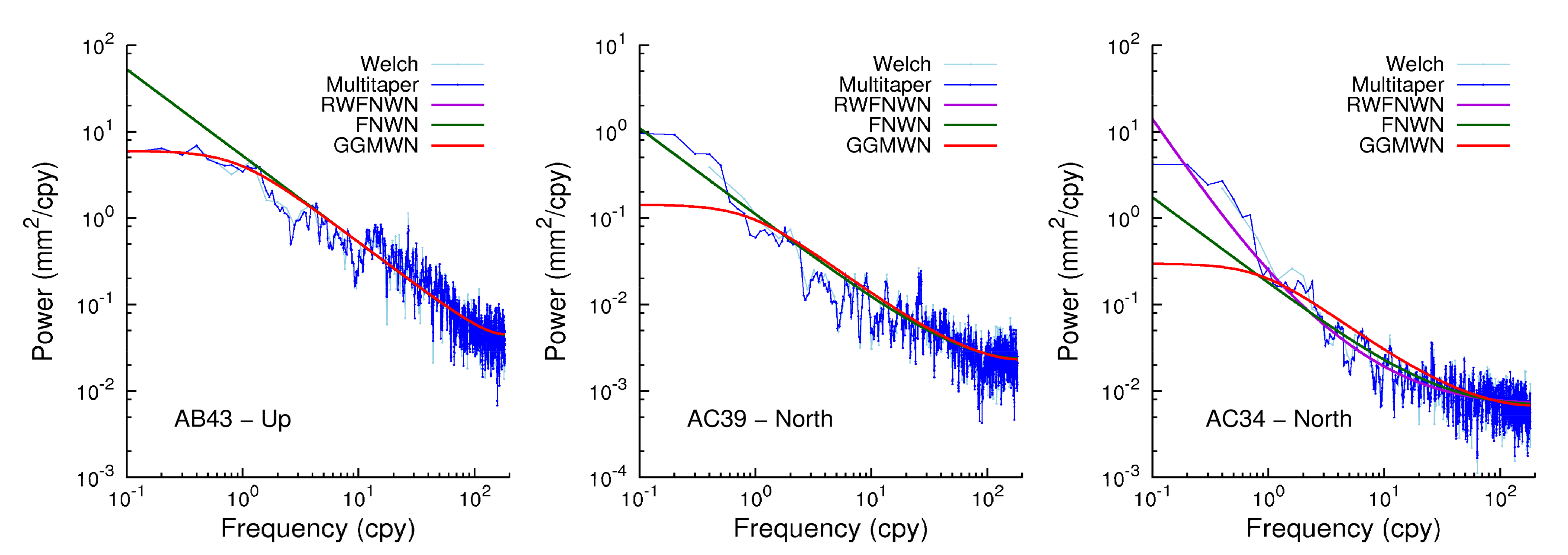
We have previously discussed the selection of noise models based on log-likelihood values. However, we can also illustrate the difference in stochastic properties of the noise by power spectral density (PSD) plots. Here, we used the Welch method to compute the PSD. We further used the multitaper method of Thomson [58], using the software of Prieto [59], which produces increasingly accurate estimates of the power at low frequencies [60]. Figure 4 shows three examples that illustrate the different behavior at low frequencies. For some stations, a flattening of the power spectrum can be observed, while for other stations, the slope of the power spectra increases at low frequencies and is better described by a random walk noise model. For the left and center panels in Figure 4, the RW part of the RW + FN + WN model was very small and resulted in very similar power spectra as FN + WN.
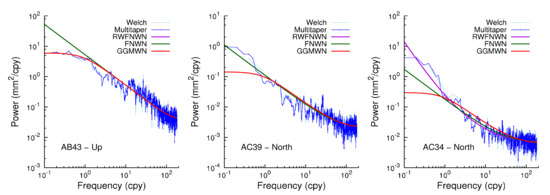
Figure 4.
Power spectral density plots computed using the multitaper method for three stations. Each of them shows a different behavior at low frequencies.
3.2. Episodic Tremors and Slip
In this research, the focus is on the noise within GPS time series. However, the trajectory model should be accurate in order to ensure that the separation between geophysical processes and other noise sources is realistic. This is especially important for stations that experience episodic tremors and slip (ETS) events. ETS events are restricted to 20 stations located specifically in the Cascadia area. Table 4 displays the results of modeling or not the ETS events using 100 days of postseismic decay time scale for the two processing centers, PANGA and NMT. Table A2 and Table A3 in Appendix A provide more details on the stochastic noise models’ behavior of each East North Up (ENU) component. Note that the results using 30, 80, and 130 days of postseismic relaxation are included in the appendices (see Table A4), but do not vary significantly compared with the results shown in Table A4. It is worth emphasizing that there is a slightly higher frequency rate of selecting the RW + FN + WN model, for both PANGA and NMT processing, when including a small postseismic relaxation delay (i.e., 30 or 80 days) in the functional model, which indicates that the remaining relaxation phenomenon is modeled as RW noise.
Table 4.
Comparison of modeling the ETS events (NoETS). The statistics are realized using 20 stations in the Cascadia subduction zone, including the North, East, and Up components. The postseismic relaxation is equal to 100 days in our model. The results are shown using either the AIC or BIC_tp criterion.
From Table 4, we can see that there is a much higher chance of selecting an RW component (i.e., the RW + FN + WN model) in the stochastic model for both processing strategies without modeling the ETS. Looking at the results using the BIC_tp, the percentages are 10.00% and 5.00% for PANGA and NMT, respectively, whereas with the ETS model, the percentages decrease to 1.67% and 0.00% for PANGA and NMT, respectively. The results are similar using the AIC. In addition, we can see that the AIC selects slightly more often the RW component in the case of PANGA processing when there is no modeling of the ETS events. This result echoes the conclusions in He et al. (2019) [25]. where it was found that the AIC criteria were slightly more sensitive to the detection of the RW component. Furthermore, with ETS modeling, the proportion of GGM + WN increases, from approximately 37% to 58% and approximately 41% to 51% for the PANGA and NMT solutions, respectively. In addition, modeling the ETS has a significant effect on the selection of the stochastic noise model of the GPS time series, as shown in Table A5 (Appendix A). As an example, the model changes when including or not including the ETS events, which is approximately 35% and 40.0% for PANGA and NMT, respectively, using the AIC, and approximately 21.7% for both PANGA and NMT with the BIC_tp criteria. In particular, for the variation in the stochastic noise models, the GGM + WN model more likely fits the time series of the Up component than the other models for the 20 sites considered here. Table A2 and Table A3 show that the changes in stochastic noise models mainly occurred in the East and North components.
3.3. Spatial Variations Analysis
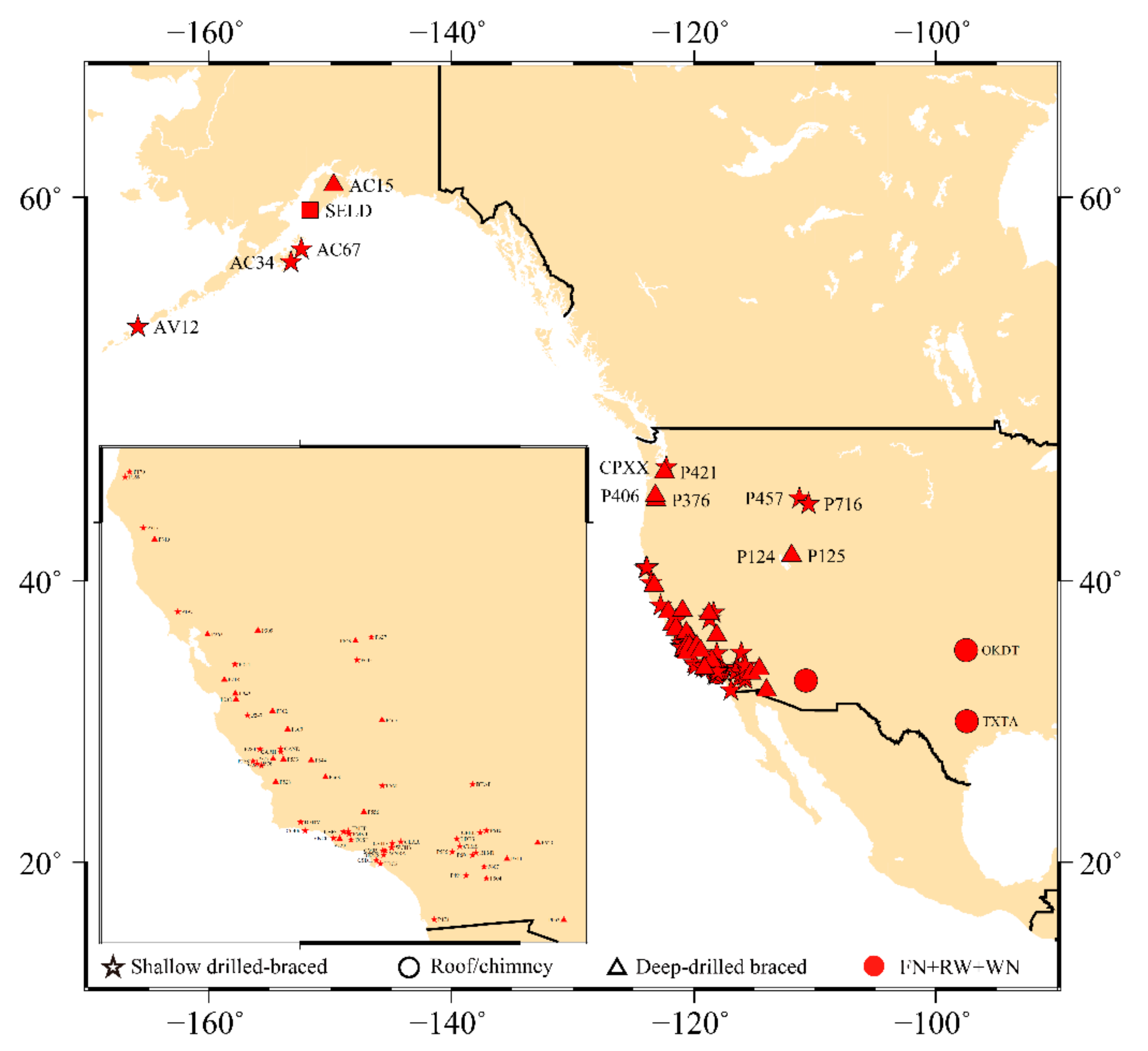
In this section, we use the 568 stations located in North America and displayed in Figure 5. To process the time series and select the optimal stochastic noise model using the AIC and BIC_tp criteria, we follow the same approach described in the previous sections. Note that for the stations experiencing ETS events in the Cascadia region, the postseismic relaxation was set up to 100 days to be consistent with our results established in the previous section. In addition, we implement automatic offset detection on the GPS residual time series discussed in Fernandes and Bos (2016) [44].
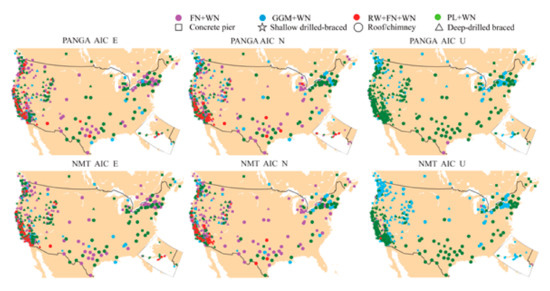
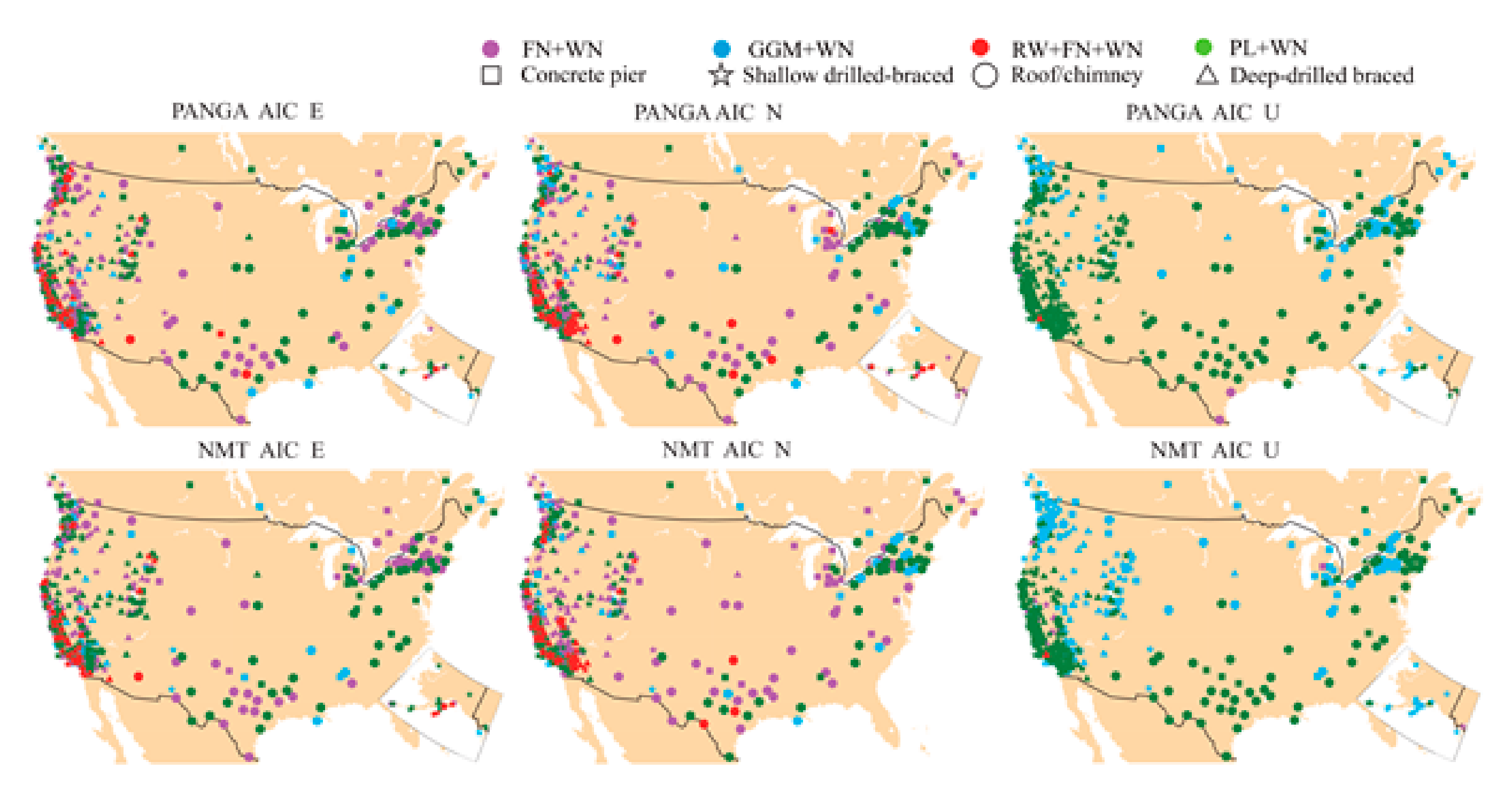
Figure 5.
Spatial distribution of the selected noise models using AIC (there is slight difference with BIC_tp, the main difference is that AIC is slight sensitive to the RW noise, as shown in Table 5).
The selected stochastic noise models using AIC and BIC_tp over 568 stations show high consistency (approximately 98.7% and 98.6% for the PANGA and NMT solutions, respectively). The significant differences in the selection of the stochastic noise model between AIC and BIC_tp applied to the PANGA and NMT solutions are displayed in Table 5. We can see that AIC is generally more sensitive to RW noise in the selection of the RW + FN + WN and GGM + WN models, which supports the previous conclusions mentioned in He et al. (2019) [25]. Table 6 shows the percentage of stochastic noise models selected over the 568 stations for the PANGA and NMT solutions with only the AIC (for ENU and the average of the 3 components). The difference in terms of percentage is much higher in the Up component, where, for the NMT solutions, the GGM + WN model is more likely selected, and the PL + WN for the PANGA time series.
Table 5.
Summary of cases for which AIC and BIC_tp gave different results. Listed here are the selected noise models for each IC and how many times this occurred for the PANGA and NMT solutions.
Table 6.
Statistics on the optimal stochastic noise model selection (AIC) with 568 stations in North America (PANGA and NMT).
The results in Table 6 also emphasize that the RW + FN + WN is approximately 8–14% for the horizontal components and only approximately 0.2% for the Up component; this is also demonstrated in Figure 5. Spatial distribution of the selected noise models using AIC (there is slight difference with BIC_tp—the main difference is that AIC is a little more sensitive to the RW noise, as shown in Table 5). The RW + FN + WN noise is much less in the Up component. In fact, we can see that all four models are selected in the horizontal components, whereas the vertical components have mostly PL + WN and GGM + WN noise models. This result holds in the analysis of the time series of both processing centers. This difference can be attributed to the fact that the vertical component is generally much noisier (~3 times greater) than the East and North components [22]. He et al. (2019) [25] concluded that GGM + WN fits slightly better than the other noise models for the vertical component, which is also supported by our results.
To further analyze the potential correlation of sites showing RW noise with geophysical phenomena, we highlight the sites for both NMT and PANGA solutions in Figure 5 (i.e., red dot for the RW + FN + WN). Most are located near the coasts (distance <10 km from the shoreline—see Figure A1 in Appendix A, which shows the spatial distribution of the RW sites for both PANGA/NMT) and in known tectonically active areas: the Cascadia subduction zone and San Andreas strike-slip fault. This result is in agreement with our results shown in the previous section, where we demonstrated that when the functional model does not completely capture all geophysical signals (due to earthquakes and/or postseismic deformation and possibly generates short-duration transient signals), the algorithm estimates higher amplitude RW noise than in much less tectonically active areas. The results also show that the detected RW amplitudes are larger than . (see Figure A1 and Table A6 in Appendix A).
3.4. Relation between Type of Noise and Type of Monument
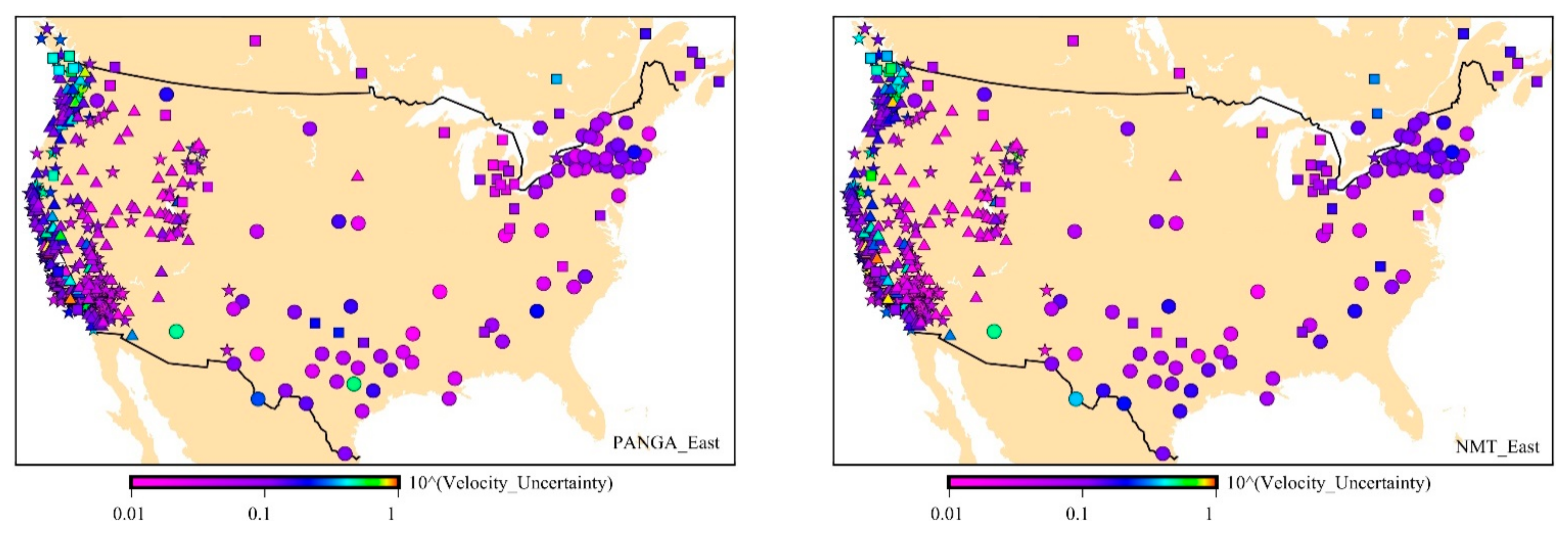
First, we analyze the velocity uncertainty of the 568 GPS stations related to type of monument. Figure 6 shows the spatial distribution of the velocity uncertainty with the optimal stochastic noise model, using AIC, for PANGA and NMT. From Figure 6, we can see that the Nevada/Idaho and Utah regions are quieter (i.e., lower uncertainty value) than the other areas, especially for the NMT solutions. In contrast, the Washington/Oregon region is noisier (i.e., higher uncertainty value). It can also be observed that there is no obvious pattern between types of monuments and velocity uncertainty. DDB monuments have the largest percentage of random walk component according to Figure 6. These monuments are mostly located along the San Andreas fault in central and southern California. Therefore, they display larger noise amplitudes due to high tectonic activities [61,62,63]. CP monuments are mostly located near Washington/Oregon states and near the Great Lakes. To recall the previous discussion, the Pacific Northwest is also a tectonic active area with the Cascadia subduction zone [64]. The Great Lakes region is not a strong tectonic active area but is known for strong postglacial rebound [65] and complex geodynamics [66]. Besides, there are other geodynamic mechanisms related to the lakes such as the lake-level variability impacted by climate change [67]. For this type of monument, GGM + WN is often the optimal model.
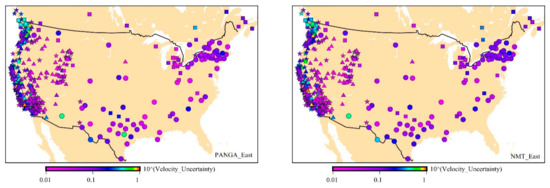
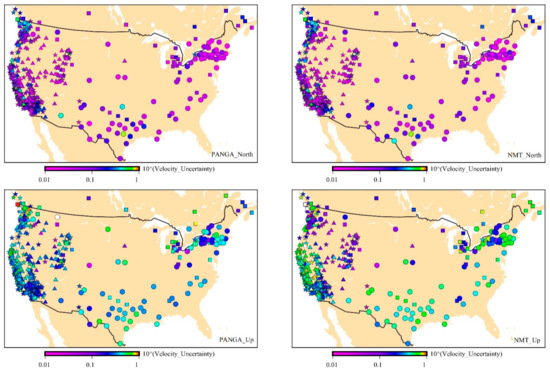
Figure 6.
Spatial distribution of the velocity uncertainty (in mm unit) for PANGA and NMT with the optimal noise model (AIC) (☐—CP, ☆—SDB, ◯—RTC, ∆—DDB).
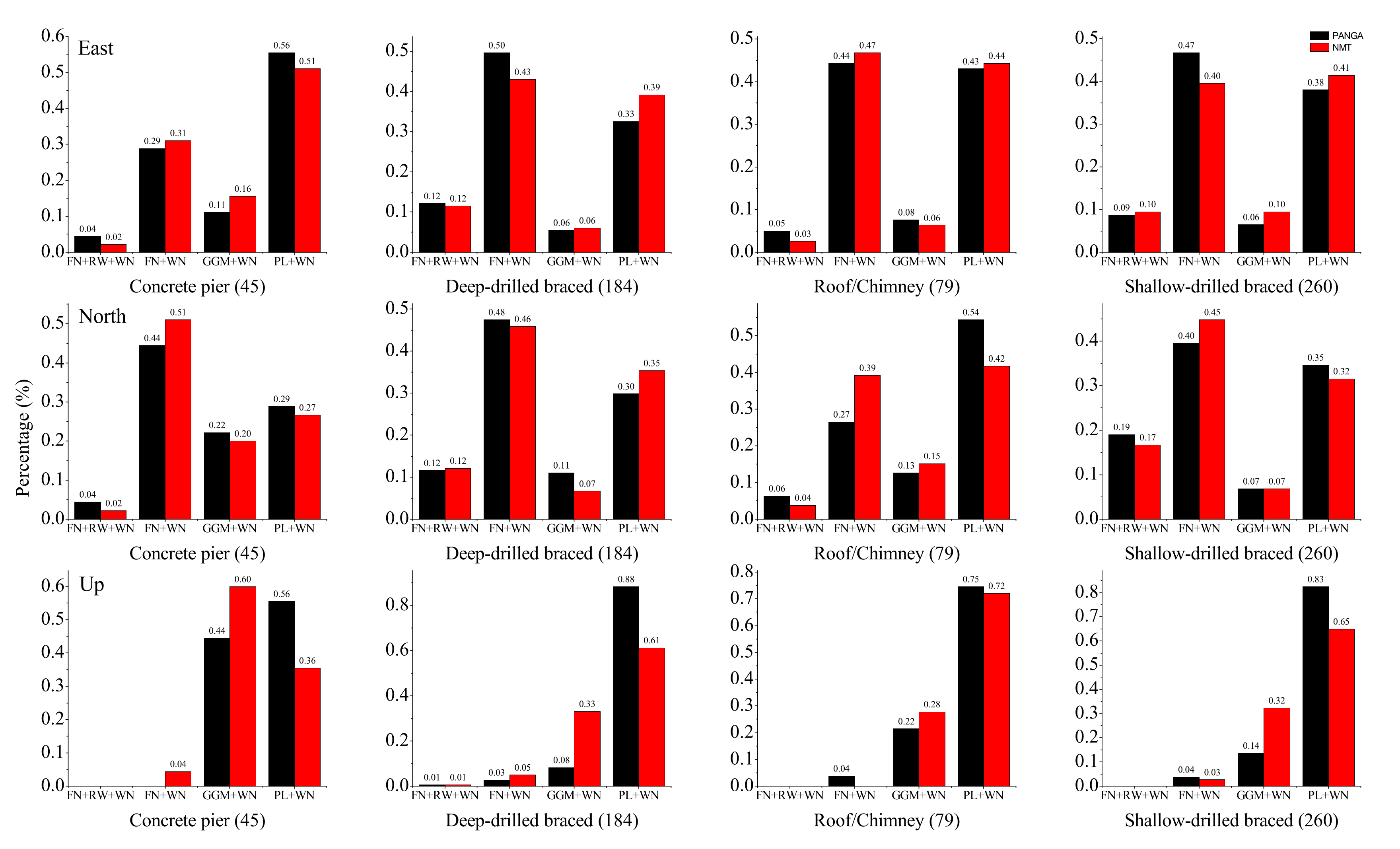
Furthermore, the statistical analysis of Table A7 and Table A8 together with Figure 7 show that there is diversity in the results depending on the types of monuments and components. Previous results established that the FN + WN model is the stochastic noise model mostly selected for East and North components. Our results support that the FN + WN and PL + WN are still the most common noise models, but in the up component, GGM + WN is more present as well for both PANGA and NMT solutions.
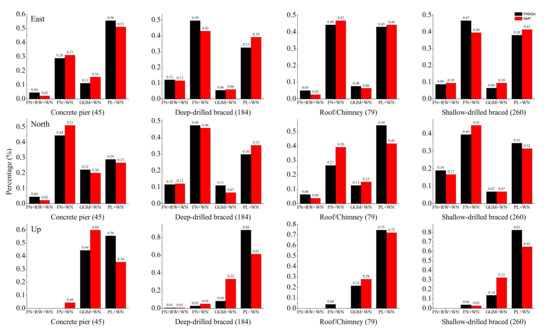
Figure 7.
Histogram view of relationship between types of monuments and stochastic noise models (selected using AIC) of PANGA (black)/NMT (red) with the number of stations falling in each category (in brackets) (Percentage expressed as a decimal.).
Note that the largest ratio of GGM + WN model mainly appears for the CP monuments (44.4% Up (PANGA) and 60% Up (NMT)). Thus, we cannot conclude on the discrimination between type of monuments and stochastic noise model. The noise properties are spatially varying so we cannot define a general ‘preferred’ noise model for a type of monument since it depends on the geographical distribution of the monument. The largest ratio of RW mainly appears in DDB and SDB monuments. Moreover, the largest percentage of RW component is prominent in the SDB and DDB types of monuments.
From Table A7 and Table A8, we can see some slight variations when comparing the results between the East and North components for each type of monument. The percentage of the selected RW + FN + WN model is the largest for the DDB monuments on the East component (~12.15% PANGA; 11.6% NMT), but not on the North component (~11.60% PANGA; 12.15% NMT). Instead, the probability of selecting this noise model is the largest for the SDB monuments on the North component (~19.10% PANGA; 16.73% NMT).
This sensitivity to RW noise is not experienced for the CP and RTC monuments. However, one needs to take into account that in our study, most of the CP monuments are installed in tectonically active areas where higher noise amplitude can mask the RW component. The RW component models the small-amplitude, short-duration, transient signals originating from regional (or local) deformations, which seem to be more present in the time series of the SDB and DDB monuments.
In addition, the stochastic noise properties of the vertical component are mostly modeled with PL + WN. However, the GGM + WN model challenges this result in the case of CPs where the percentage is higher, approximately 44.44% and 60.00% for PANGA and NMT solutions, respectively. Thus, these time series of the vertical component experience flattening at a low frequency, as discovered and analyzed by He et al. (2019) [25].
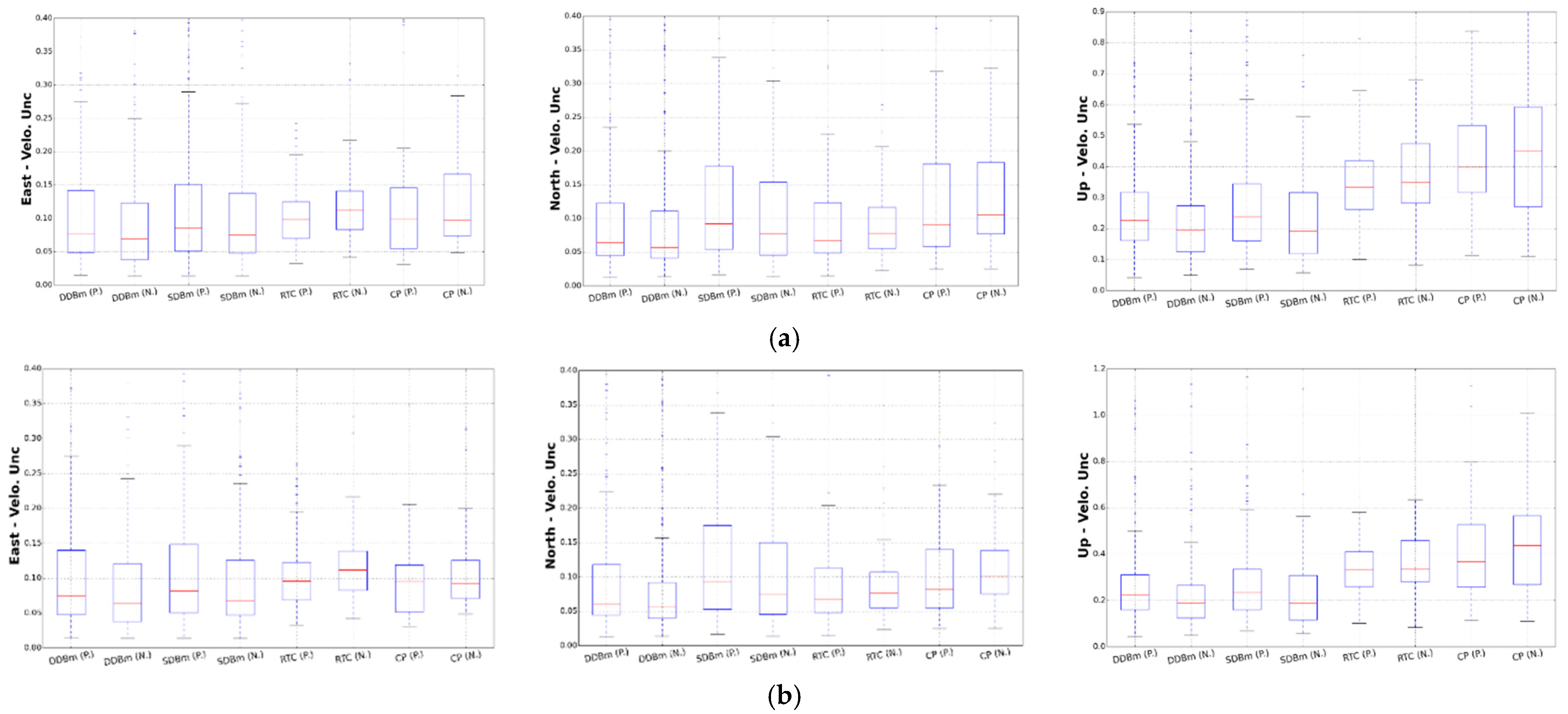
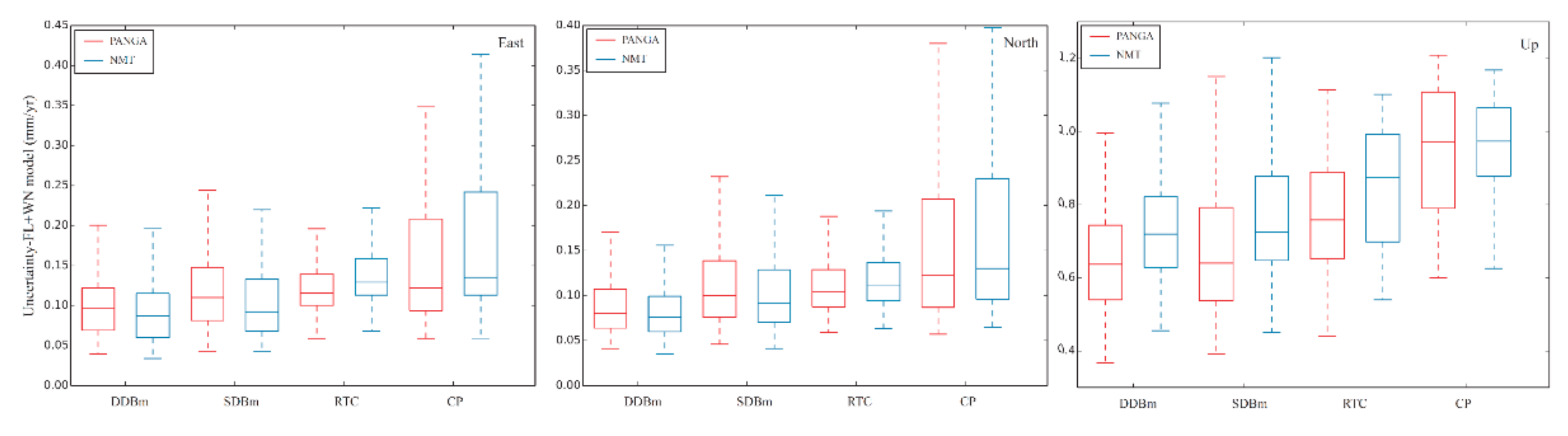
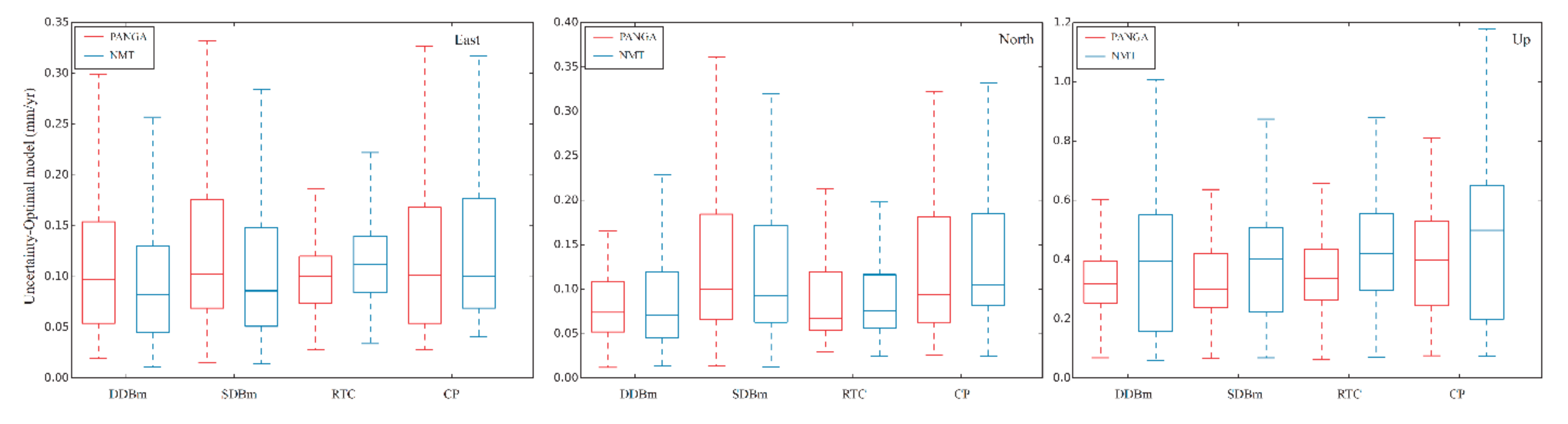
To further support this result, we draw a boxplot of the velocity uncertainties with the selected FL + WN and optimal noise model, as shown in Figure 8 and Figure 9, respectively. In Figure 8, a clear trend is seen from stable monuments such as the DDBm. However, Figure 9 does not show the differences between the types of monuments. We think that a large number of receivers on CP experience GGM noise, which halves the trend uncertainty. The total effect is a reduction in the correlation between the type of monument and velocity uncertainties.
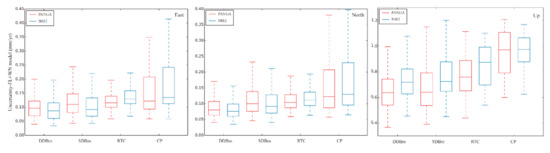
Figure 8.
Trend uncertainty computed with FL + WN.
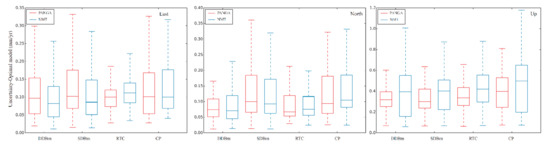
Figure 9.
Trend uncertainty computed by using the optimal noise model.
From Figure 8 and Figure 9, we can also see that the RTC monument performs as well as the DDBm. To understand this result, we should look again at Table A7 and Table A8 in the Appendix A; they display the amplitude of the white noise for the PANGA processing using the AIC criteria. We notice that the amplitude of the white noise is largest for the RTC monuments. Therefore, the RTC setup may partially mask small, transient, geophysical signals by increasing the amplitude of the white noise, rendering this setup disadvantageous for geophysical studies at the regional scale when looking at small amplitude short-duration signals. From Table A7 and Table A8, we can also see that the estimated white noise amplitude is very different between the NMT and PANGA solutions. As discussed in Section 1, PANGA uses GIPSY–OASIS (GIPSYX) without any scale parameter in the Helmert transform, whereas the NMT solution results from the processing with GAMIT/GLOBK including a scale parameter. It results in different stochastic noise properties of the time series, with a smaller scatter than the PANGA ones (~30%), and hence, a smaller noise amplitude.
In light of this discussion, we can conclude that the higher white noise amplitude associated with the RTC monuments can mask the presence of a RW component (see Table A9 and Table A10 in Appendix A, which show the relation between the monument type and estimated noise model) in the stochastic noise model than in other monuments (SDBm and DDBm). This can explain why the velocity uncertainties in Figure 8 and Figure 9 are smaller.
From the above results and analysis, we can conclude that there is reduced discrimination as to which monument performs the best over the three coordinates. The spatial distribution of the monuments supersedes the type of monuments in the selection of the noise model for the global, not regionally filtered, GNSS time series. Previous studies, such as Herring et al. (2016) [34], have warned about the spatial distribution across North America. Williams et al. (2004) restricted their study to a small area to determine the influence of the various types of monuments [22]. Beavan (2005) [68] concluded that monument noise is not the dominant factor in the stochastic noise properties of the GPS time series; hence, we corroborate his results. Finally, we supplement CME reduction and the elimination of some stations in active areas in the Appendix A, to explore the effect of regional filtering and large postseismic relaxation events on monument performance. We can see that regional filtering does not change the overall results. The DDBm is still the best monument type, which supports what we have already previously discussed in this paper.
4. Conclusions
This work has investigated the noise properties of 568 GPS daily position time series with a length of 10 years in North America, computed by NMT and PANGA, together with their spatial distribution. These time series are given with respect to a global reference frame (ITRF2008) and no regional filter has been applied.
To model the noise in the GPS time series, the following models were used: FN + WN, RW + FN + WN, GGM + WN, and PL + WN. The selection of the optimal noise model was based on the log-likelihood value and the information criteria (i.e., AIC, BIC, BIC_tp) to avoid overselecting noise models with many parameters. This approach was criticized by authors of various studies who do not recommend the use of AIC or BIC. However, when we apply these information criteria to Monte Carlo simulations of synthetic time series, we can demonstrate that for noise RW + FN + WN, we have a very low percentage of false positives. Thus, if we detect RW + FN + WN noise, then we have high confidence this is correct. On the other hand, we still have a high number of false negatives, which means that PL + WN is still detected, while in reality, the underlying noise model is RW + FN + WN, in agreement with previous studies [23,25]. The simulations also demonstrate that we are able to reliably detect the GGM noise model. Statistically, we found that for around 10% of the stations, the power spectral density shows flattening at low frequencies, which can be better described with a Generalized Gauss Markov (GGM) noise model, further extending the conclusions of He et al. (2019).
For the Cascadia subduction region, which is tectonically active, it is necessary to include episodic tremor and slip in the trajectory model. Otherwise, the misfit between observations and model is absorbed as a large random walk component, which affects the value of the estimated linear motion and increases its uncertainty. In addition, our results show that the selection of the RW component in the RW + FN + WN model accounts for a non-negligible percentage when not modeling the ETS events, whereas when properly modeled, the GGM + WN and PL + WN models are more often selected. Note that AIC is generally more sensitive to the RW noise in the selection of the RW + FN + WN and GGM + WN model.
Furthermore, the spatial distribution of selected noise models shows a pattern in our case study. Stations including the RW component are generally located near the coasts (distance <10 km from the shoreline) or in active tectonic areas (Cascadia subduction zone, San Andreas fault). In terms of differences between the two processing strategies, the time series from the NMT solutions are more often modeled with the GGM + WN than the PANGA solution, therefore exhibiting a flattening of the power-spectrum. In addition, the largest percentage of RW + FN + WN model is selected in SDB and DDB monuments mainly for the horizontal components. The PL + WN and FN + WN models are generally the dominant stochastic noise models for the monuments, but the GGM + WN is also often selected for the CP monuments, especially on the Up component, which means that the very long time series generated from monitoring the CP monuments are experiencing this flattening at low frequency. The difference in results between AIC and BIC_tp is relatively small for each monument in selecting the various stochastic noise models. However, we show that the amplitude of the white noise is largest for the RTC. Therefore, the RTC setup may partially mask small transient geophysical signals by mismodeling the amplitude of the noise. Moreover, when investigating the relationship between the various types of monuments and the estimation of the geophysical signals, the results emphasized that the smallest uncertainties associated with the tectonic rate are recorded by the DDBm monuments for the East and North components, especially selecting the FL + WN model. On the vertical component, the results difference between the DDBm and SDBm is not significant. Additional results obtained by removing CME and monuments located in tectonically active areas (such as the Cascadia subduction zone) show that the uncertainties decrease, especially with CP and DDBm monuments on the East and North components. CP and DDBm monuments are mostly located in tectonically active areas or close to the coastline. Overall, we recommend the use of DDBm in noisy or tectonically active areas. However, their stochastic noise properties are different to those in more stable areas. Therefore, we conclude that the location of the station supersedes these types of monuments in the estimation of the tectonic rate uncertainty, supporting previous studies [34,68].
Author Contributions
X.H., M.S.B. and J.-P.M. writing-original draft preparation and methodology; R.F. and T.M. reviewed and edited the manuscript. T.M. provided some of the resources displayed in this study; W.J. and W.L. made the common mode error filtering analysis. All authors have read and agreed to the published version of the manuscript.
Funding
Xiaoxing He was sponsored by National Natural Science Foundation of China (42104023, 42061077) and Jiangxi University of Science and Technology High-level Talent Research Startup Project (205200100564). Machiel Bos and Rui Fernandes were sponsored by national Portuguese funds through FCT in the scope of the project UIDB/50019/2021—Instituto Dom Luiz. Computational resources were provided by C4G-Collaboratory for Geosciences (PINFRA/22151/2016).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The processed time series are available at ftp://data-out.unavco.org/pub/products/position/.
Acknowledgments
We thank Thomas Herring and Mike Floyd of MIT for their helpful discussion on PANGA and NMT solution.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Table A1.
Statistics of data gap over the 568 sites used in this study.
Table A1.
Statistics of data gap over the 568 sites used in this study.
| Data Gap | PANGA | PANGA | PANGA | NMT | NMT | NMT |
|---|---|---|---|---|---|---|
| E | N | U | E | N | U | |
| <3% | 93.7% | 93.5% | 97.0% | 91.7% | 92.6% | 97.9% |
| Mean | 1.17% | 1.09% | 0.84% | 1.24% | 1.18% | 0.81% |
| Max | 7.91% | 6.41% | 7.61% | 6.79% | 7.07% | 7.20% |
| Min | 0.05% | 0.05% | 0.05% | 0.05% | 0.05% | 0.05% |
Table A2.
Stochastic noise model behavior of ENU component for the 20 GPS stations selected in the Cascadia area (PANGA).
Table A2.
Stochastic noise model behavior of ENU component for the 20 GPS stations selected in the Cascadia area (PANGA).
| ENU | Model | No-ETS | ETS | ||
|---|---|---|---|---|---|
| AIC | BICtp | AIC | BICtp | ||
| E | RW + FN + WN | 20.00% | 15.00% | 10.00% | 5.00% |
| FN + WN | 30.00% | 60.00% | 30.00% | 45.00% | |
| GGM + WN | 0.00% | 0.00% | 20.00% | 20.00% | |
| PL + WN | 50.00% | 25.00% | 40.00% | 30.00% | |
| N | RW + FN + WN | 15.00% | 15.00% | 0.00% | 0.00% |
| FN + WN | 20.00% | 40.00% | 15.00% | 25.00% | |
| GGM + WN | 30.00% | 25.00% | 65.00% | 65.00% | |
| PL + WN | 35.00% | 20.00% | 20.00% | 10.00% | |
| U | RW + FN + WN | 0.00% | 0.00% | 0.00% | 0.00% |
| FN + WN | 0.00% | 5.00% | 0.00% | 0.00% | |
| GGM + WN | 85.00% | 85.00% | 90.00% | 90.00% | |
| PL + WN | 15.00% | 10.00% | 10.00% | 10.00% | |
Table A3.
Stochastic noise model behavior of ENU component for the 20 GPS stations selected in the Cascadia area (NMT).
Table A3.
Stochastic noise model behavior of ENU component for the 20 GPS stations selected in the Cascadia area (NMT).
| ENU | Model | No-ETS | ETS | ||
|---|---|---|---|---|---|
| AIC | BICtp | AIC | BICtp | ||
| E | RW + FN + WN | 20.00% | 15.00% | 0.00% | 0.00% |
| FN + WN | 45.00% | 65.00% | 40.00% | 50.00% | |
| GGM + WN | 5.00% | 5.00% | 40.00% | 30.00% | |
| PL + WN | 30.00% | 15.00% | 20.00% | 20.00% | |
| N | RW + FN + WN | 0.00% | 0.00% | 0.00% | 0.00% |
| FN + WN | 40.00% | 60.00% | 30.00% | 45.00% | |
| GGM + WN | 25.00% | 20.00% | 30.00% | 15.00% | |
| PL + WN | 35.00% | 20.00% | 40.00% | 40.00% | |
| U | RW + FN + WN | 0.00% | 0.00% | 0.00% | 0.00% |
| FN + WN | 0.00% | 0.00% | 0.00% | 0.00% | |
| GGM + WN | 95.00% | 95.00% | 95.00% | 95.00% | |
| PL + WN | 5.00% | 5.00% | 5.00% | 5.00% | |
Table A4.
Selected stochastic noise model with the AIC with varying postseismic relaxation time.
Table A4.
Selected stochastic noise model with the AIC with varying postseismic relaxation time.
| Postseismic Relaxation Time in Days (×10) | PANGA-AIC | NMT-AIC | ||||||
|---|---|---|---|---|---|---|---|---|
| 3 | 8 | 10 | 13 | 3 | 8 | 10 | 13 | |
| RW + FN + WN | 4 | 2 | 2 | 2 | 0 | 0 | 0 | 0 |
| FN + WN | 10 | 10 | 9 | 9 | 15 | 14 | 14 | 13 |
| GGM + WN | 32 | 33 | 35 | 35 | 30 | 31 | 31 | 32 |
| PL + WN | 14 | 15 | 14 | 14 | 15 | 15 | 15 | 15 |
Table A5.
ETS effect on the selection of the stochastic noise.
Table A5.
ETS effect on the selection of the stochastic noise.
| Stochastic Noise Vartion | ||
|---|---|---|
| AIC | BICtp | |
| PANGA | 35.00% | 40.00% |
| NMT | 21.67% | 21.67% |
Table A6.
The amplitudes (mm) of the RW component of the sites in Figure A1.
Table A6.
The amplitudes (mm) of the RW component of the sites in Figure A1.
| Site | ENU | PANGA | NMT | Site | ENU | PANGA | NMT | Site | ENU | PANGA | NMT |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AC15 | N | 1.3 | 1.2 | P170 | E | 1.2 | 2.0 | P527 | E | 1.8 | 1.3 |
| AC34 | E | 1.3 | 1.5 | P197 | N | 1.6 | 1.2 | P530 | N | 1.2 | 1.2 |
| AC67 | N | 2.0 | 1.3 | P197 | E | 1.4 | 1.5 | P530 | E | 0.8 | 0.7 |
| AC67 | E | 0.9 | 1.1 | P218 | N | 1.8 | 2.4 | P533 | N | 0.7 | 0.5 |
| AV12 | N | 1.8 | 1.7 | P238 | N | 1.7 | 1.6 | P544 | E | 1.0 | 0.8 |
| AZGB | E | 1.3 | 1.3 | P238 | E | 2.8 | 2.6 | P556 | E | 0.7 | 0.8 |
| BBDM | N | 1.7 | 1.5 | P242 | N | 2.1 | 2.3 | P563 | N | 1.2 | 1.1 |
| BBDM | E | 1.9 | 2.2 | P247 | N | 1.1 | 1.2 | P563 | E | 1.2 | 1.1 |
| BEMT | N | 0.6 | 0.6 | P254 | N | 1.2 | 1.3 | P568 | E | 0.6 | 0.5 |
| BKAP | N | 0.6 | 0.6 | P254 | E | 0.9 | 0.6 | P576 | N | 2.1 | 2.2 |
| BKMS | N | 1.8 | 1.8 | P278 | N | 1.2 | 1.5 | P576 | E | 3.2 | 2.4 |
| BKMS | E | 0.7 | 1.6 | P278 | E | 1.6 | 1.6 | P585 | N | 0.8 | 0.8 |
| CARH | N | 1.2 | 1.0 | P284 | N | 1.2 | 1.3 | P601 | N | 0.7 | 0.6 |
| CARH | E | 1.5 | 1.5 | P284 | E | 1.6 | 1.9 | P607 | N | 0.8 | 0.7 |
| CLAR | N | 1.0 | 1.3 | P300 | N | 2.1 | 1.7 | P610 | N | 0.7 | 0.5 |
| CLAR | E | 0.9 | 0.5 | P300 | E | 3.1 | 3.1 | P623 | N | 0.7 | 0.6 |
| COPR | N | 0.8 | 0.8 | P302 | N | 1.1 | 1.2 | P627 | N | 0.7 | 0.9 |
| CPXX | E | 1.5 | 1.7 | P302 | E | 2.7 | 2.7 | P643 | N | 1.5 | 1.5 |
| CSDH | E | 1.4 | 0.9 | P309 | E | 1.7 | 1.4 | P649 | N | 0.7 | 0.8 |
| CTMS | N | 0.7 | 0.6 | P317 | N | 0.6 | 0.5 | P649 | E | 0.7 | 0.7 |
| CVHS | E | 2.1 | 1.7 | P317 | E | 1.5 | 1.1 | P716 | N | 1.8 | 1.3 |
| FMTP | N | 1.2 | 1.4 | P319 | N | 0.9 | 0.7 | P716 | E | 2.5 | 2.1 |
| FMVT | N | 1.0 | 0.9 | P376 | N | 0.9 | 1.4 | P729 | N | 1.6 | 1.7 |
| GVRS | E | 1.0 | 0.7 | P376 | E | 1.1 | 0.7 | P729 | E | 2.6 | 2.3 |
| KBRC | E | 1.8 | 1.6 | P406 | N | 2.5 | 2.3 | SELD | N | 2.0 | 1.4 |
| LBC2 | N | 2.1 | 1.8 | P421 | E | 2.1 | 2.4 | SELD | E | 0.9 | 0.8 |
| LBC2 | E | 1.5 | 1.7 | P457 | E | 0.8 | 1.0 | TOST | N | 1.1 | 1.2 |
| LDES | N | 0.6 | 0.6 | P465 | E | 1.4 | 1.3 | TXTA | N | 2.3 | 2.3 |
| OKDT | N | 1.1 | 1.0 | P473 | E | 1.1 | 0.9 | VNCO | N | 1.4 | 1.2 |
| OPBL | N | 0.5 | 0.6 | P491 | N | 0.8 | 0.7 | VNCO | E | 0.9 | 0.8 |
| P003 | E | 0.9 | 0.9 | P504 | N | 0.7 | 0.6 | WCHS | N | 0.9 | 1.2 |
| P124 | N | 1.2 | 0.9 | P511 | N | 0.8 | 0.6 | WCHS | E | 1.6 | 1.2 |
| P125 | E | 0.8 | 0.9 | P526 | N | 0.8 | 0.7 | WHC1 | E | 0.6 | 0.8 |
| P169 | E | 0.5 | 0.5 | P526 | E | 1.4 | 1.0 | WNRA | N | 1.3 | 1.1 |
| P170 | N | 1.5 | 1.4 | P527 | N | 1.4 | 1.3 | WNRA | E | 0.8 | 0.8 |
Table A7.
Amplitude (mm) of white noise vs. type of monument (PANGA).
Table A7.
Amplitude (mm) of white noise vs. type of monument (PANGA).
| PANGA | E | N | U | |||
|---|---|---|---|---|---|---|
| μ | σ | μ | σ | μ | σ | |
| RTC | 0.66 | 0.35 | 0.75 | 0.32 | 0.6 | 1.46 |
| CP | 0.47 | 0.35 | 0.74 | 0.32 | 0.25 | 0.82 |
| DDB | 0.66 | 0.22 | 0.72 | 0.32 | 0.55 | 1.19 |
| SDB | 0.67 | 0.27 | 0.75 | 0.34 | 0.71 | 1.27 |
Table A8.
Amplitude (mm) of white noise vs. type of monument (NMT).
Table A8.
Amplitude (mm) of white noise vs. type of monument (NMT).
| NMT | E | N | U | |||
|---|---|---|---|---|---|---|
| μ | σ | μ | σ | μ | σ | |
| RTC | 0.62 | 0.31 | 0.53 | 0.27 | 0.29 | 0.76 |
| concrete | 0.55 | 0.40 | 0.56 | 0.26 | 0.27 | 0.76 |
| DDB | 0.58 | 0.18 | 0.53 | 0.19 | 0.16 | 0.55 |
| SDB | 0.59 | 0.20 | 0.55 | 0.25 | 0.15 | 0.51 |
Table A9.
Monument type vs. noise model PANGA (AIC).
Table A9.
Monument type vs. noise model PANGA (AIC).
| ENU | Monument Type | RW + FN + WN | FN + WN | GGM + WN | PL + WN |
|---|---|---|---|---|---|
| E | Concrete pier | 4.44% | 28.89% | 11.11% | 55.56% |
| Deep-drilled braced | 12.15% | 49.72% | 5.52% | 32.60% | |
| Roof/chimney | 5.06% | 44.30% | 7.59% | 43.04% | |
| Shallow-drilled braced | 8.75% | 46.77% | 6.46% | 38.02% | |
| N | Concrete pier | 4.44% | 44.44% | 22.22% | 28.89% |
| Deep-drilled braced | 11.60% | 47.51% | 11.05% | 29.83% | |
| Roof/chimney | 6.33% | 26.58% | 12.66% | 54.43% | |
| Shallow-drilled braced | 19.01% | 39.54% | 6.84% | 34.60% | |
| U | Concrete pier | 0.00% | 0.00% | 44.44% | 55.56% |
| Deep-drilled braced | 0.55% | 2.76% | 8.29% | 88.40% | |
| Roof/chimney | 0.00% | 3.80% | 21.52% | 74.68% | |
| Shallow-drilled braced | 0.00% | 3.80% | 13.69% | 82.51% |
Table A10.
Monument type vs. noise model NMT.
Table A10.
Monument type vs. noise model NMT.
| ENU | Monument Type | RW + FN + WN | FN + WN | GGM + WN | PL + WN |
|---|---|---|---|---|---|
| E | Concrete pier | 2.22% | 31.11% | 15.56% | 51.11% |
| Deep-drilled braced | 11.60% | 43.09% | 6.08% | 39.23% | |
| Roof/chimney | 2.53% | 46.84% | 6.33% | 44.30% | |
| Shallow-drilled braced | 9.51% | 39.54% | 9.51% | 41.44% | |
| N | Concrete pier | 2.22% | 51.11% | 20.00% | 26.67% |
| Deep-drilled braced | 12.15% | 45.86% | 6.63% | 35.36% | |
| Roof/chimney | 3.80% | 39.24% | 15.19% | 41.77% | |
| Shallow-drilled braced | 16.73% | 44.87% | 6.84% | 31.56% | |
| U | Concrete pier | 0.00% | 4.44% | 60.00% | 35.56% |
| Deep-drilled braced | 0.55% | 4.97% | 33.15% | 61.33% | |
| Roof/chimney | 0.00% | 0.00% | 27.85% | 72.15% | |
| Shallow-drilled braced | 0.00% | 2.66% | 32.32% | 65.02% |
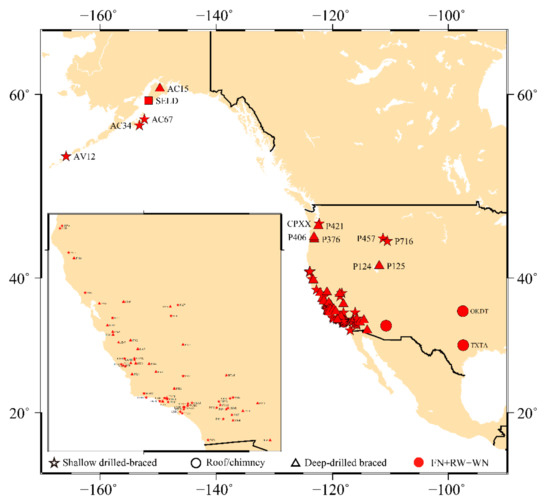
Figure A1.
Spatial distribution of the RW sites for PANGA/NMT (the rectangular area in the lower left corner of the figure is a zoom view of all the stations under P406 without station name mark).
Figure A1.
Spatial distribution of the RW sites for PANGA/NMT (the rectangular area in the lower left corner of the figure is a zoom view of all the stations under P406 without station name mark).
As mentioned in the previous section on ‘GPS processing’, the PANGA and NMT solutions did not implement any regional filtering. We extract the regional common mode error (CME) on the GPS network for both PANGA and NMT solution. For filtering on the CME, we implement the VBPCA method to extract CME (Li et al., 2020). The VBPCA method imposed a priori distributions on the model parameters and estimated the hyperparameters by maximizing the evidence of observed signals. This method can naturally handle missing data in the Bayesian framework and utilizes the variational expectation–maximization iterative algorithm to search the CME for the incomplete GNSS position time series. Moreover, it can automatically select the optimal number of principal components for data reconstruction and be more reliable against the overfitting problem than other statistical signal decomposition methods. The boxplots with CME filter of the velocity uncertainties with the selected FL + WN and optimal noise model are shown in Figure A2aa. From Figure A2aa together with Figure 8 and Figure 9, we can see that regional filtering does not change the overall results. The DDBm is still the best monument type. The CME removal is only interesting looking at the CP monuments. However, we only have 45 CP in this study. In addition, some of the 568 analyzed sites were located in a region that was known to contain tectonic or volcanic transient events, which will affect the stochastic noise properties and, therefore, the monument performance. Thus, we removed these sites (reducing the total number to 538 sites). The boxplot figures after filtering the CME and with optimal model selection are shown in Figure A2bb. Overall, the filter improves only the results with CP monuments. These monuments are located in the Pacific Northwest, with postseismic relaxation, and this result supports what we have already said in this study.
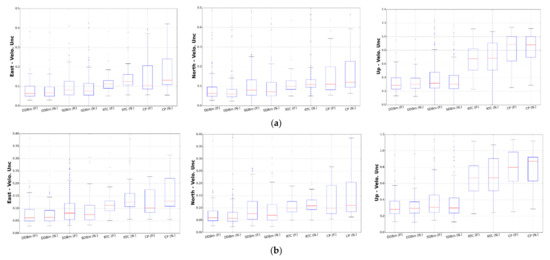
Figure A2.
Boxplot with CME filter with FN + WN model for PANGA (P.) and NMT (N.) solution. (a) Boxplot with CME filter with FN + WN model for PANGA (P.) and NMT (N.). (b) Boxplot with CME filter with FN + WN model for PANGA and NMT (large postseismic relaxation sites removed).
Figure A2.
Boxplot with CME filter with FN + WN model for PANGA (P.) and NMT (N.) solution. (a) Boxplot with CME filter with FN + WN model for PANGA (P.) and NMT (N.). (b) Boxplot with CME filter with FN + WN model for PANGA and NMT (large postseismic relaxation sites removed).
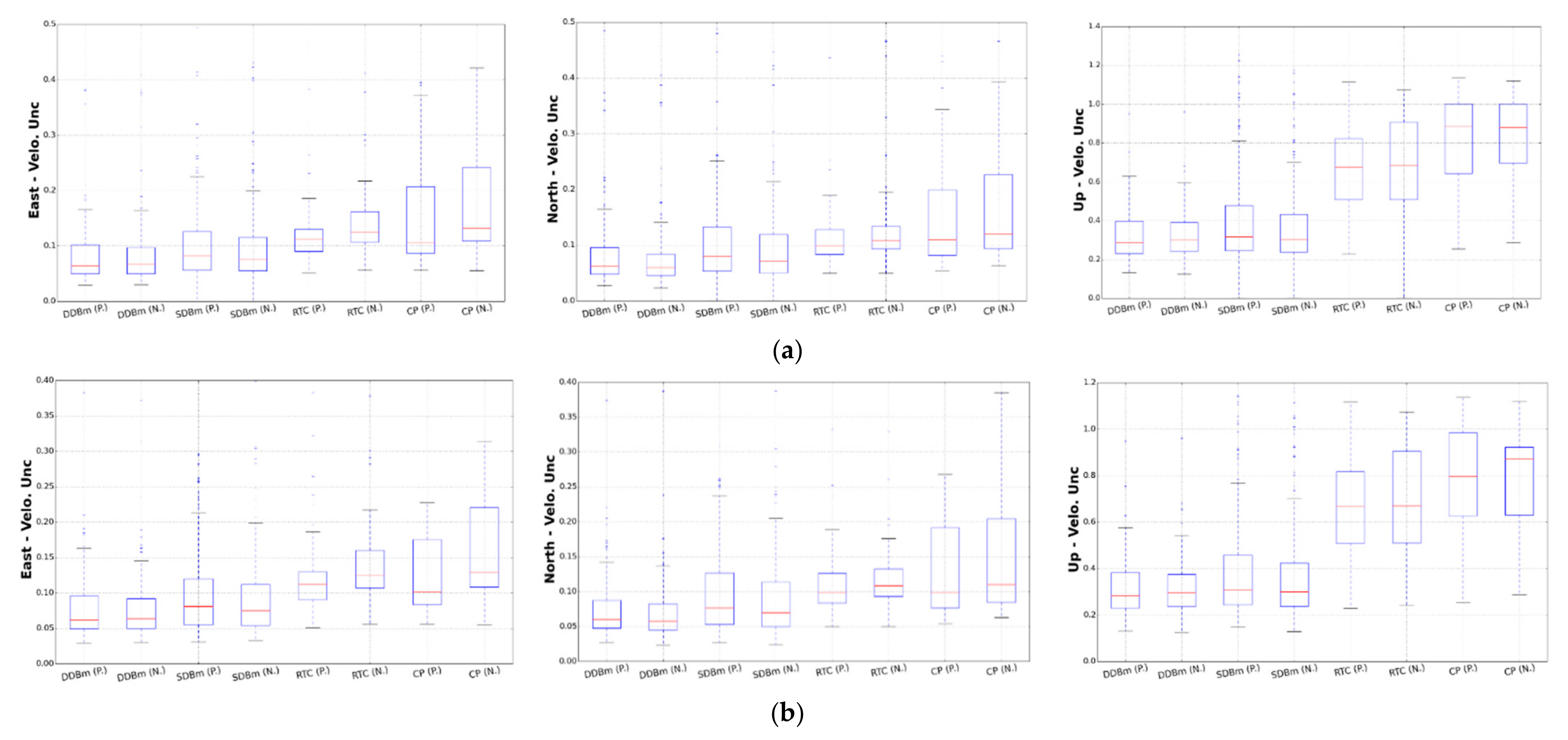
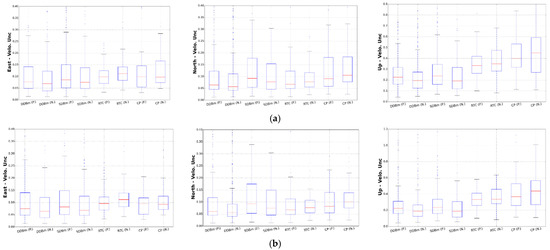
Figure A3.
Boxplot with CME filter with optimal model for PANGA and NMT solution. (a) Boxplot with CME filter with optimal model for PANGA and NMT. (b) Boxplot with CME filter with optimal model for PANGA and NMT (remove large postseismic relaxation sites).
Figure A3.
Boxplot with CME filter with optimal model for PANGA and NMT solution. (a) Boxplot with CME filter with optimal model for PANGA and NMT. (b) Boxplot with CME filter with optimal model for PANGA and NMT (remove large postseismic relaxation sites).
Appendix B
For the postseismic relaxation or Episodic Tremor and Slip events, we assume that the observations are the sum of a deterministic model and stochastic noise. This deterministic model is as follows:
where are the coefficients of a degree polynomial. By default, means a linear trend. is the Heaviside step function and used to model offsets with amplitudes . An annual and semiannual signal are commonly included in the model and therefore have their own keywords, ’seasonal’ and ’halfseasonal’, in Hector [43]. In the equation, their angular velocities are represented by . Other periodic signals need to be entered using the keyword ’PeriodicSignals’, followed by a list of their periods in days. The time of the slow slip event and the delay of the postseismic deformation are required as input parameters for the estimation of the ETS using Hector with a hyperbolic tangent by providing two parameters, and .
Appendix C
Table A11.
Monument types of the analyzed 568 sites: concrete pier (CP), Deep-drilled brace (DDB), Shallow-drilled brace (SDB), and Roof top/Chimney (RTC).
Table A11.
Monument types of the analyzed 568 sites: concrete pier (CP), Deep-drilled brace (DDB), Shallow-drilled brace (SDB), and Roof top/Chimney (RTC).
| Site | Type | Site | Type | Site | Type | Site | Type | Site | Type | Site | Type | Site | Type | Site | Type |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1NSU | RTC | CORV | SDB | MAT2 | SDB | P114 | DDB | P256 | DDB | P420 | DDB | P557 | DDB | ROCK | SDB |
| AB07 | SDB | COVG | RTC | MHCB | RTC | P115 | DDB | P257 | SDB | P421 | DDB | P558 | DDB | SASK | CP |
| AB22 | SDB | CPXX | SDB | MICW | CP | P116 | DDB | P258 | SDB | P422 | DDB | P563 | DDB | SCIA | SDB |
| AB43 | SDB | CRBT | SDB | MIDA | DDB | P117 | DDB | P259 | DDB | P423 | DDB | P566 | SDB | SDHL | SDB |
| AB44 | SDB | CRU1 | SDB | MIDS | CP | P118 | SDB | P262 | DDB | P427 | DDB | P568 | SDB | SEAT | RTC |
| AC15 | DDB | CSCI | SDB | MIG1 | SDB | P119 | SDB | P267 | DDB | P429 | DDB | P569 | SDB | SEDR | DDB |
| AC20 | SDB | CSDH | SDB | MIHO | CP | P121 | DDB | P268 | DDB | P432 | DDB | P570 | SDB | SELD | CP |
| AC27 | SDB | CSST | SDB | MIIR | CP | P124 | DDB | P272 | DDB | P436 | DDB | P572 | DDB | SHE2 | CP |
| AC31 | SDB | CTBR | RTC | MLFP | SDB | P125 | DDB | P273 | SDB | P437 | DDB | P576 | SDB | SHIN | DDB |
| AC34 | SDB | CTDM | SDB | MNMC | SDB | P128 | DDB | P274 | SDB | P439 | DDB | P579 | DDB | SHLD | DDB |
| AC39 | SDB | CTGU | RTC | MOIL | DDB | P132 | DDB | P275 | DDB | P442 | DDB | P580 | SDB | SHOS | DDB |
| AC41 | SDB | CTMS | SDB | MPLE | CP | P134 | SDB | P276 | DDB | P445 | SDB | P581 | DDB | SHRV | RTC |
| AC59 | SDB | CTPU | RTC | MPWD | SDB | P138 | DDB | P278 | SDB | P448 | SDB | P583 | SDB | SIBY | CP |
| AC63 | SDB | CVHS | SDB | MSOL | CP | P139 | SDB | P280 | DDB | P449 | SDB | P585 | SDB | SMEL | DDB |
| AC67 | SDB | DDSN | SDB | MTFV | RTC | P141 | SDB | P283 | DDB | P451 | DDB | P592 | DDB | SNFD | RTC |
| ADRI | CP | DOBS | CP | NANO | CP | P148 | SDB | P284 | SDB | P457 | SDB | P593 | SDB | SPIC | DDB |
| AGMT | SDB | DRAO | CP | NCPO | RTC | P154 | SDB | P285 | DDB | P460 | DDB | P595 | SDB | SPK1 | RTC |
| AHID | SDB | DSSC | SDB | NCSW | RTC | P156 | DDB | P287 | SDB | P461 | DDB | P599 | SDB | SPMS | SDB |
| AL30 | RTC | DUBO | CP | NEAH | CP | P157 | SDB | P288 | SDB | P462 | SDB | P601 | SDB | STJO | CP |
| AL50 | CP | DVPB | SDB | NEDR | RTC | P160 | DDB | P289 | SDB | P463 | SDB | P606 | SDB | SVIN | SDB |
| AL60 | RTC | ECFS | SDB | NEGI | RTC | P163 | DDB | P290 | SDB | P465 | DDB | P607 | SDB | TABL | SDB |
| ALBH | CP | ECSD | DDB | NHRG | SDB | P164 | SDB | P293 | SDB | P466 | DDB | P610 | SDB | TBLP | SDB |
| ALGO | CP | ELIZ | SDB | NHUN | RTC | P165 | DDB | P294 | DDB | P467 | SDB | P611 | SDB | THCP | SDB |
| ALPP | SDB | ESCU | CP | NJTW | RTC | P166 | SDB | P295 | SDB | P468 | DDB | P615 | SDB | THU3 | CP |
| ARCM | RTC | EWPP | SDB | NMRO | RTC | P167 | SDB | P296 | SDB | P469 | SDB | P616 | DDB | TOIY | DDB |
| ARPG | RTC | FERN | DDB | NMSF | RTC | P168 | SDB | P297 | SDB | P471 | DDB | P617 | SDB | TONO | DDB |
| AV01 | SDB | FGST | SDB | NOR3 | CP | P169 | SDB | P300 | DDB | P472 | DDB | P618 | SDB | TORP | SDB |
| AV02 | SDB | FMTP | SDB | NYBH | RTC | P170 | SDB | P301 | DDB | P473 | SDB | P621 | SDB | TOST | SDB |
| AV06 | SDB | FMVT | SDB | NYBT | RTC | P171 | SDB | P302 | DDB | P474 | DDB | P622 | SDB | TPW2 | SDB |
| AV07 | SDB | FOOT | DDB | NYCL | RTC | P174 | SDB | P305 | DDB | P476 | SDB | P623 | DDB | TWHL | SDB |
| AV08 | SDB | FORE | SDB | NYCP | RTC | P175 | DDB | P306 | DDB | P478 | SDB | P626 | SDB | TXAB | RTC |
| AV09 | SDB | FRDN | CP | NYDV | RTC | P178 | SDB | P309 | DDB | P480 | DDB | P627 | SDB | TXAM | RTC |
| AV10 | SDB | FRED | DDB | NYFD | RTC | P180 | SDB | P312 | DDB | P482 | DDB | P636 | DDB | TXCH | CP |
| AV11 | SDB | GAAT | RTC | NYFS | RTC | P182 | DDB | P313 | DDB | P483 | DDB | P643 | SDB | TXCO | CP |
| AV12 | SDB | GARF | RTC | NYFV | RTC | P183 | SDB | P314 | SDB | P484 | SDB | P649 | DDB | TXDR | RTC |
| AV16 | SDB | GARL | DDB | NYHC | RTC | P185 | SDB | P315 | DDB | P485 | SDB | P651 | DDB | TXEL | RTC |
| AV18 | SDB | GOBS | SDB | NYHS | RTC | P186 | DDB | P316 | DDB | P486 | DDB | P653 | SDB | TXHE | RTC |
| AZGB | RTC | GODE | CP | NYLV | RTC | P187 | SDB | P317 | SDB | P490 | SDB | P674 | DDB | TXLF | RTC |
| BAIE | CP | GOSH | DDB | NYMD | RTC | P188 | SDB | P318 | DDB | P491 | SDB | P675 | SDB | TXLL | RTC |
| BAMF | SDB | GVRS | SDB | NYML | RTC | P189 | SDB | P319 | DDB | P504 | SDB | P677 | DDB | TXPE | RTC |
| BAR1 | SDB | HAMP | RTC | NYON | RTC | P192 | DDB | P324 | SDB | P511 | DDB | P678 | DDB | TXPR | RTC |
| BAYR | CP | HCMN | SDB | NYPD | RTC | P196 | DDB | P326 | SDB | P513 | SDB | P683 | DDB | TXSA | RTC |
| BBDM | SDB | HLFX | CP | NYPF | RTC | P197 | SDB | P332 | SDB | P514 | DDB | P684 | SDB | TXSN | RTC |
| BBID | SDB | HOGS | CP | NYST | RTC | P206 | DDB | P341 | SDB | P515 | DDB | P698 | SDB | TXST | RTC |
| BBRY | SDB | HUNT | SDB | NYWL | RTC | P208 | SDB | P344 | DDB | P516 | DDB | P700 | SDB | TXTA | RTC |
| BCOV | SDB | HVYS | SDB | NYWT | RTC | P210 | DDB | P354 | SDB | P519 | DDB | P706 | DDB | TXTY | RTC |
| BEMT | SDB | HWUT | CP | OHAS | RTC | P211 | DDB | P356 | SDB | P523 | DDB | P710 | SDB | TXVA | RTC |
| BEPK | SDB | IDDR | CP | OKDT | RTC | P212 | DDB | P367 | DDB | P525 | SDB | P716 | SDB | TXWA | RTC |
| BILL | DDB | KBRC | SDB | OPBL | SDB | P213 | DDB | P370 | SDB | P526 | SDB | P720 | SDB | TXWF | CP |
| BKAP | SDB | KNGS | RTC | OPCL | SDB | P215 | DDB | P371 | SDB | P527 | DDB | P726 | DDB | UCLU | CP |
| BKMS | SDB | KNTN | CP | ORMT | SDB | P216 | DDB | P372 | DDB | P528 | DDB | P727 | SDB | UNIV | CP |
| BLW2 | CP | KOKB | RTC | OVLS | SDB | P218 | DDB | P374 | DDB | P529 | DDB | P729 | DDB | USLO | SDB |
| BLYT | SDB | KTBW | SDB | OXYC | SDB | P227 | SDB | P376 | DDB | P530 | DDB | P741 | RTC | VALD | CP |
| BMHL | SDB | KYBO | RTC | P002 | DDB | P228 | SDB | P377 | DDB | P531 | DDB | P742 | RTC | VCAP | RTC |
| BREW | CP | KYVW | SDB | P003 | DDB | P230 | SDB | P387 | DDB | P532 | DDB | PARY | RTC | VDCY | SDB |
| BRPK | SDB | LACR | DDB | P091 | SDB | P231 | SDB | P388 | DDB | P533 | DDB | PCOL | RTC | VIMT | SDB |
| BSMK | RTC | LAND | DDB | P092 | SDB | P232 | DDB | P394 | DDB | P535 | DDB | PGC5 | CP | VNCO | SDB |
| BSRY | SDB | LANS | CP | P093 | SDB | P233 | DDB | P395 | DDB | P536 | DDB | PSDM | SDB | VNCX | SDB |
| BTDM | SDB | LBC2 | SDB | P094 | SDB | P234 | DDB | P397 | SDB | P537 | DDB | PTAL | SDB | VNPS | SDB |
| BURN | SDB | LDES | SDB | P095 | DDB | P237 | SDB | P398 | DDB | P538 | DDB | PVE3 | CP | VTIS | SDB |
| CABL | SDB | LDSW | SDB | P099 | SDB | P238 | DDB | P401 | DDB | P540 | DDB | PVRS | SDB | WCHS | SDB |
| CAND | DDB | LEBA | CP | P100 | DDB | P241 | SDB | P402 | DDB | P543 | DDB | PWEL | SDB | WHC1 | RTC |
| CARH | SDB | LEWI | DDB | P102 | SDB | P242 | DDB | P404 | DDB | P544 | DDB | QCY2 | DDB | WIDC | SDB |
| CAST | DDB | LFRS | SDB | P104 | DDB | P243 | SDB | P406 | DDB | P546 | DDB | QUAD | SDB | WMAP | SDB |
| CDMT | SDB | LINH | RTC | P106 | DDB | P244 | SDB | P408 | DDB | P547 | DDB | RAMT | SDB | WNRA | SDB |
| CEDA | DDB | LKCP | SDB | P108 | SDB | P247 | SDB | P409 | DDB | P549 | DDB | RCA2 | SDB | WOMT | SDB |
| CHWK | SDB | LL01 | SDB | P109 | DDB | P250 | SDB | P411 | DDB | P550 | DDB | REDM | SDB | WRHS | SDB |
| CIRX | SDB | LMCN | RTC | P110 | SDB | P252 | DDB | P412 | DDB | P551 | DDB | RG07 | SDB | WVRA | RTC |
| CJMS | SDB | LORS | SDB | P111 | SDB | P253 | SDB | P414 | DDB | P553 | DDB | RG09 | SDB | YBHB | CP |
| CLAR | SDB | LOWS | SDB | P112 | SDB | P254 | SDB | P417 | DDB | P554 | DDB | RHCL | SDB | ZAB1 | RTC |
| COPR | SDB | MASW | SDB | P113 | DDB | P255 | DDB | P418 | DDB | P556 | DDB | RNCH | SDB | ZDV1 | RTC |
References
- Segall, P.; Davis, J.L. GPS applications for geodynamics and earthquake studies. Annu. Rev. Earth Planet. Sci. 1997, 25, 301–336. [Google Scholar] [CrossRef] [Green Version]
- Fernandes, R.M.S.; Ambrosius, B.A.C.; Noomen, R.; Bastos, L.; Combrinck, L.; Miranda, J.M.; Spakman, W. Angular velocities of Nubia and Somalia from continuous GPS data: Implications on present-day relative kinematics. Earth Planet. Sci. Lett. 2004, 222, 197–208. [Google Scholar] [CrossRef]
- Fernandes, R.M.S.; Bastos, L.; Miranda, J.M.; Lourenço, N.; Ambrosius, B.A.C.; Noomen, R.; Simons, W. Defining the plate boundaries in the Azores region. J. Volcanol. Geotherm. Res. 2006, 156, 1–9. [Google Scholar] [CrossRef]
- Bock, Y.; Melgar, D. Physical applications of GPS geodesy: A review. Rep. Prog. Phys. 2016, 79, 106801. [Google Scholar] [CrossRef] [PubMed]
- Montillet, J.P.; Williams, S.D.P.; Koulali, A.; McClusky, S.C. Estimation of offsets in GPS time-series and application to the detection of earthquake deformation in the far-field. Geophys. J. Int. 2015, 200, 1207–1221. [Google Scholar] [CrossRef] [Green Version]
- Amiri-Simkooei, A.R.; Hosseini-Asl, M.; Asgari, J.; Zangeneh-Nejad, F. Offset detection in GPS position time series using multivariate analysis. GPS Solut. 2019, 23, 13. [Google Scholar] [CrossRef]
- Sauber, J.; Plafker, G.; Molnia, B.F.; Bryant, M.A. Crustal deformation associated with glacial fluctuations in the eastern Chugach Mountains, Alaska. J. Geophys. Res. Solid Earth 2000, 105, 8055–8077. [Google Scholar] [CrossRef] [Green Version]
- Tregoning, P.; Watson, C.; Ramillien, G.; McQueen, H.; Zhang, J. Detecting hydrologic deformation using GRACE and GPS. Geophys. Res. Lett. 2009, 36. [Google Scholar] [CrossRef] [Green Version]
- Husson, L.; Bodin, T.; Spada, G.; Choblet, G.; Kreemer, C. Bayesian surface reconstruction of geodetic uplift rates: Mapping the global fingerprint of Glacial Isostatic Adjustment. J. Geodyn. 2018, 122, 25–40. [Google Scholar] [CrossRef]
- Turner, R.J.; Reading, A.M.; King, M.A. Separation of tectonic and local components of horizontal GPS station velocities: A case study for glacial isostatic adjustment in East Antarctica. Geophys. J. Int. 2020, 222, 1555–1569. [Google Scholar] [CrossRef]
- King, M.A.; Penna, N.T.; Clarke, P.J.; King, E.C. Validation of ocean tide models around Antarctica using onshore GPS and gravity data. J. Geophys. Res. 2005, 110, B08401. [Google Scholar] [CrossRef] [Green Version]
- Thomas, I.D.; King, M.A.; Clarke, P.J. A comparison of GPS, VLBI and model estimates of ocean tide loading displacements. J. Geodesy 2007, 81, 359–368. [Google Scholar] [CrossRef] [Green Version]
- Penna, N.T.; Bos, M.S.; Baker, T.F.; Scherneck, H.G. Assessing the accuracy of predicted ocean tide loading displacement values. J. Geodesy 2008, 82, 893–907. [Google Scholar] [CrossRef] [Green Version]
- Penna, N.T.; Clarke, P.J.; Bos, M.S.; Baker, T.F. Ocean tide loading displacements in western Europe: 1. Validation of kinematic GPS estimates. J. Geophys. Res. Solid Earth 2015, 120, 6523–6539. [Google Scholar] [CrossRef]
- Abbaszadeh, M.; Clarke, P.J.; Penna, N.T. Benefits of combining GPS and GLONASS for measuring ocean tide loading displacement. J. Geodesy 2020, 94, 63. [Google Scholar] [CrossRef]
- Van Dam, T.; Collilieux, X.; Wuite, J.; Altamimi, Z.; Ray, J. Nontidal ocean loading: Amplitudes and potential effects in GPS height time series. J. Geodesy 2012, 86, 1043–1057. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Montillet, J.P.; Hua, X.; Yu, K.; Jiang, W.; Zhou, F. Noise analysis for environmental loading effect on GPS position time series. Acta Geodyn. Geomater. 2017, 14, 131–143. [Google Scholar]
- Bevis, M.; Brown, A. Trajectory models and reference frames for crustal motion geodesy. J. Geodesy 2014, 88, 283–311. [Google Scholar] [CrossRef] [Green Version]
- Sobrero, F.S.; Bevis, M.; Gómez, D.D.; Wang, F. Logarithmic and exponential transients in GNSS trajectory models as indicators of dominant processes in postseismic deformation. J. Geodesy 2020, 94, 84. [Google Scholar] [CrossRef]
- Bevis, M.; Jonathan, B.; Dana, J.C., II. The Art and Science of Trajectory Modelling. In Geodetic Time Series Analysis in Earth Sciences; Springer: Cham, Switzerland, 2020; ISSN 2364-9119. [Google Scholar]
- Mao, A.; Harrison, C.G.A.; Dixon, T.H. Noise in GPS coordinate time series. J. Geophys. Res. 1999, 104, 2797–2816. [Google Scholar] [CrossRef] [Green Version]
- Williams, S.D.; Bock, Y.; Fang, P.; Jamason, P.; Nikolaidis, R.M.; Prawirodirdjo, L.; Miller, M.; Johnson, D.J. Error analysis of continuous GPS position time series. J. Geophys. Res. Solid Earth 2004, 109. [Google Scholar] [CrossRef] [Green Version]
- Langbein, J. Estimating rate uncertainty with maximum likelihood: Diferences between power-law and licker–random-walk models. J. Geodesy 2012, 86, 775–783. [Google Scholar] [CrossRef] [Green Version]
- Dmitrieva, K.; Segall, P.; DeMets, C. Network-based estimation of time-dependent noise in gps position time series. J. Geodesy 2015, 89, 591–606. [Google Scholar] [CrossRef]
- He, X.; Bos, M.S.; Montillet, J.P.; Fernandes, R.M.S. Investigation of the noise properties at low frequencies in long GNSS time series. J. Geodesy 2019, 93, 1271–1282. [Google Scholar] [CrossRef]
- Dmitrieva, K.; Segall, P.; Bradley, A.M. Effects of linear trends on estimation of noise in GNSS position time series. Geophys. J. Int. 2016, 208, 281–288. [Google Scholar] [CrossRef]
- Santamaría-Gómez, A.; Ray, J. Chameleonic noise in GPS position time series. J. Geophys. Res. Solid Earth 2021, 126, e2020JB019541. [Google Scholar] [CrossRef]
- Altamimi, Z.; Collilieux, X.; Métivier, L. ITRF2008: An improved solution of the international terrestrial reference frame. J. Geodesy 2011, 85, 457–472. [Google Scholar] [CrossRef] [Green Version]
- Zumberge, J.F.; Heflin, M.B.; Jefferson, D.C.; Watkins, M.M.; Webb, F.H. Precise point positioning for the efficient and robust analysis of GPS data from large networks. J. Geophys. Res. 1997, 102, 5005–5017. [Google Scholar] [CrossRef] [Green Version]
- Bertiger, W.; Desai, S.D.; Haines, B.; Harvey, N.; Moore, A.W.; Owen, S.; Weiss, J.P. Single receiver phase ambiguity resolution with GPS data. J. Geodesy 2010, 84, 327–337. [Google Scholar] [CrossRef]
- Herring, T.A.; King, R.W.; McClusky, S.C. GAMIT Reference Manual: GPS Analysis at MIT, Release 10.4; Massachusetts Institute of Technology: Cambridge, MA, USA, 2010. [Google Scholar]
- Herring, T.A.; King, R.W.; McClusky, S.C. GLOBK Reference Manual: Global Kalman Filter VLBI and GPS Analysis Program, Release 10.4; Massachusetts Institute of Technology: Cambridge, MA, USA, 2010; pp. 1–95. [Google Scholar]
- Kouba, J. Implementation and testing of the gridded Vienna Mapping Function 1 (VMF1). J. Geodesy 2008, 82, 193–205. [Google Scholar] [CrossRef]
- Herring, T.A.; Melbourne, T.I.; Murray, M.H.; Floyd, M.A.; Szeliga, W.M.; King, R.W.; Phillips, D.A.; Puskas, C.M.; Santillan, M.; Wang, L. Plate Boundary Observatory and Related Networks: GPS Data Analysis Methods and Geodetic Products. Rev. Geophys. 2016, 54, 54. [Google Scholar] [CrossRef]
- Montillet, J.P.; Melbourne, T.I.; Szeliga, W.M. GPS Vertical Land Motion Corrections to Sea-Level Rise Estimates in the Pacific Northwest. J. Geophys. Res. Ocean. 2018, 123, 1196–1212. [Google Scholar] [CrossRef]
- Hofmann-Wellenhof, B.; Lichtenegger, H.; Collins, J. Global Positioning System: Theory and Practice, 5th ed.; Springer: Wien, Austria; New York, NY, USA, 2001. [Google Scholar]
- King, M.A.; Bevis, M.; Wilson, T.; Johns, B.; Blume, F. Monument-antenna effects on GPS coordinate time series with application to vertical rates in Antarctica. J. Geodesy 2011, 86, 53–63. [Google Scholar] [CrossRef]
- Klos, A.; Bogusz, J.; Figurski, M.; Kosek, W. Noise analysis of continuous GPS time series of selected EPN stations to investigate variations in stability of monument types. In VIII Hotine-Marussi Symposium on Mathematical Geodesy; Springer: Cham, Switzerland, 2015; pp. 19–26. [Google Scholar]
- Haas, R.; Bergstrand, S.; Lehner, W. Evaluation of GNSS monument stability. In Reference Frames for Applications in Geosciences; Springer: Berlin/Heidelberg, Germany, 2013; pp. 45–50. [Google Scholar]
- Langbein, J.; Svarc, J.L. Evaluation of Temporally Correlated Noise in Global Navigation Satellite System Time Series: Geodetic Monument Performance. J. Geophys. Res. Solid Earth 2019, 124, 925–942. [Google Scholar] [CrossRef] [Green Version]
- Langbein, J.; Wyatt, F.; Johnson, H.; Hamann, D.; Zimmer, P. Improved stability of a deeply anchored geodetic monument for deformation monitoring. Geophys. Res. Lett. 1995, 22, 3533–3536. [Google Scholar] [CrossRef]
- Langbein, J.; Bock, Y. Noise in two-color electronic distance meter measurements revisited. J. Geophys. Res. 2004, 109. [Google Scholar] [CrossRef]
- Bos, M.S.; Fernandes, R.M.S.; Williams, S.D.P.; Bastos, L. Fast error analysis of continuous GNSS observations with missing data. J. Geodesy 2013, 87, 351–360. [Google Scholar] [CrossRef] [Green Version]
- Fernandes, R.M.S.; Bos, M.S. Applied automatic offset detection using HECTOR within EPOS-IP. In AGU Fall Meeting Abstracts; Time-series; San Francisco, CA, USA, 2016; p. G51A-1084. [Google Scholar]
- Dragert, H.; Wang, K.; James, T.S. A silent slip event on the deeper Cascadia subduction interface. Science 2001, 292, 1525–1528. [Google Scholar] [CrossRef] [Green Version]
- Rogers, G.; Dragert, H. Episodic tremor and slip on the Cascadia subduction zone: The chatter of silent slip. Science 2003, 300, 1942–1943. [Google Scholar] [CrossRef]
- Melbourne, T.I.; Webb, F.H. Slow but not quite silent. Science 2003, 300, 1886–1887. [Google Scholar] [CrossRef]
- Viesca, R.C.; Dublanchet, P. The slow slip of viscous faults. J. Geophys. Res. Solid Earth 2019, 124, 4959–4983. [Google Scholar] [CrossRef] [Green Version]
- Bos, M.; Fernandes, R. Hector User Manual Version 1.7. 2; Space and Earth Geodetic Analysis Laboratory: Covilhã, Portugal, 2019. [Google Scholar]
- Szeliga, W.; Melbourne, T.; Santillan, M.; Miller, M. GPS constraints on 34 slow slip events within the Cascadia subduction zone, 1997–2005. J. Geophys. Res. Solid Earth 2008, 113. [Google Scholar] [CrossRef] [Green Version]
- Miller, M.M.; Melbourne, T.; Johnson, D.J.; Sumner, W.Q. Periodic slow earthquakes from the Cascadia subduction zone. Science 2002, 295, 2423. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Montillet, J.P.; Fernandes, R.; Bos, M.; Yu, K.; Hua, X.; Jiang, W. Review of current GPS methodologies for producing accurate time series and their error sources. J. Geodyn. 2017, 106, 12–29. [Google Scholar] [CrossRef]
- Langbein, J. Noise in GPS displacement measurements from Southern California and Southern Nevada. J. Geophys. Res. 2008, 113. [Google Scholar] [CrossRef]
- Williams, S.D.P. The effect of coloured noise on the uncertainties of rates from geodetic time series. J. Geod. 2003, 76, 483–494. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Santamaría-Gómez, A.; Bouin, M.N.; Collilieux, X.; Wöppelmann, G. Correlated errors in GPS position time series: Implications for velocity estimates. J. Geophys. Res. Solid Earth 2011, 116. [Google Scholar] [CrossRef]
- Thomson, D.J. Spectrum estimation and harmonic analysis. Proc. IEEE 1982, 70, 1055–1096. [Google Scholar] [CrossRef] [Green Version]
- Prieto, G.A.; Parker, R.L.; Vernon, F.L., III. A Fortran 90 library for multitaper spectrum analysis. Comput. Geosci. 2009, 35, 1701–1710. [Google Scholar] [CrossRef]
- Bronez, T.P. On the performance advantage of multitaper spectral analysis. IEEE Trans. Signal Process. 1992, 40, 2941–2946. [Google Scholar] [CrossRef]
- Zhu, L. Crustal structure across the San Andreas Fault, southern California from teleseismic converted waves. Earth Planet. Sci. Lett. 2000, 179, 183–190. [Google Scholar] [CrossRef]
- Shelly, D.R.; Hardebeck, J.L. Precise tremor source locations and amplitude variations along the lower-crustal central San Andreas Fault. Geophys. Res. Lett. 2010, 37. [Google Scholar] [CrossRef] [Green Version]
- Rousset, B.; Bürgmann, R.; Campillo, M. Slow slip events in the roots of the San Andreas fault. Sci. Adv. 2019, 5, eaav3274. [Google Scholar] [CrossRef] [Green Version]
- Miller, M.M. A Pacific Northwest Geodetic Array (PANGA), Providing Constraints on North America, Juan de Fuca, Pacific Plate Interactions for Geophysical and Geologic Modeling and Earthquake Hazards Assessment; Central Washington University: Ellensburg, WA, USA, 1998. [Google Scholar]
- Clark, J.A.; Hendriks, M.; Timmermans, T.J.; Struck, C.; Hilverda, K.J. Glacial isostatic deformation of the Great Lakes region. Geol. Soc. Am. Bull. 1994, 106, 19–31. [Google Scholar] [CrossRef]
- Sims, P.K.; Day, W.C. Great Lakes Tectonic Zone—Revisited; US Government Printing Office: Washington, DC, USA, 1993. [Google Scholar]
- Croley, T.E., II; Lewis, C.M. Warmer and drier climates that make terminal great lakes. J. Great Lakes Res. 2006, 32, 852–869. [Google Scholar] [CrossRef]
- Beavan, J. Noise properties of continuous GPS data from concrete pillar geodetic monuments in New Zealand and comparison with data from US deep drilled braced monuments. J. Geophys. Res. Solid Earth 2005, 110. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).