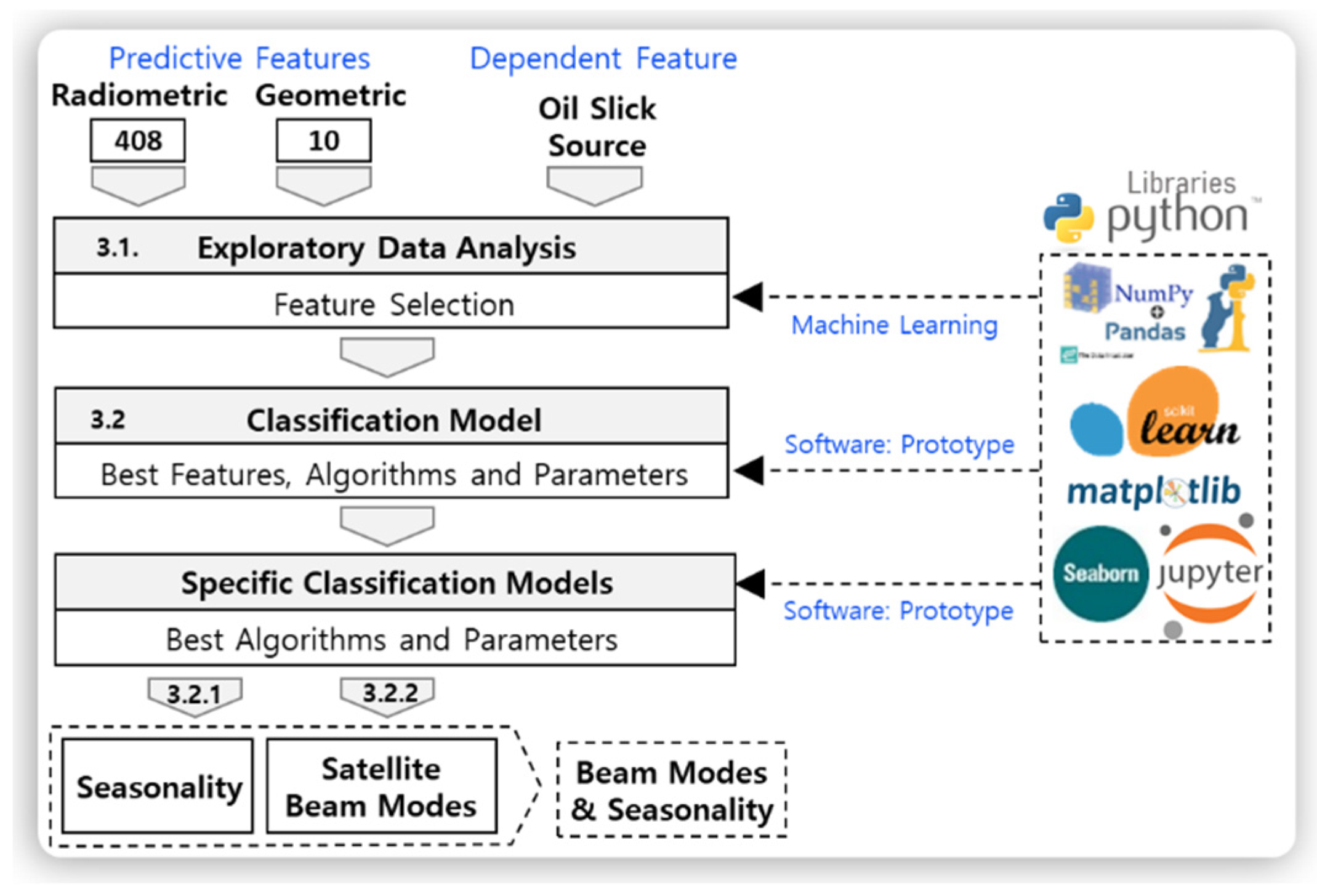
Considering that the quality of input attributes is key for a successful prediction model, a deeper analysis was conducted to discover if geometric and radiometric features perform better when isolated or integrated. In this sense, adopting the features selected by EDA (item 3.1) as the input, the next steps progressed by specifying the best group of features and algorithm fitting parameters.
Since the performances of the algorithms are case-specific, the next analyses used the 12 selected features as the input, keeping the parametric (LDA and LR) and nonparametric (ANN and RF) approaches. The goal was to find the proper inference method to derivate specific classification models (SCMs) from the global model (CM), considering different satellite beam modes and seasons.
3.2.1. Seasonality Effects on the Classification Model Accuracy
As mentioned previously, many factors can affect the detectability of oil slicks at the sea surface, such as the SAR system configuration, meteo-oceanographic conditions, and the physicochemical properties of different oil types. The available database indicates in which season each oil slick was detected, giving indirect clues about the wind behavior. This information allows for evaluating the benefits of building and fitting SCMs considering seasonality effects, as the GoM presents significant variations in terms of wind intensity and direction throughout the year.
To accomplish this objective, five scenarios were investigated (
Table 2: 1–5), considering the following: (a) All seasons together (All); (b) Winter; (c) Spring; (d) Summer; (c) Fall.
Table 1 indicates that, even when the oil samples were divided per season, the classes remained relatively balanced, given (a) Winter (1130: 23), (b) Spring (1205: 24), (c) Summer (921: 19), and; (e) Fall (1660: 34). The goal was to discover the best seasons in which to distinguish seeps from spills, seeking the best algorithms and parameters to optimize the accuracy of each searched model. The maximum prediction accuracies obtained using the four ML algorithms are available in
Table 5a, and the median accuracies are available in
Table 5b.
The graph in
Figure 6a compares the maximum and median accuracies achieved by the prediction models considering the seasonality effects.
Figure 6b provides the median accuracies for all tested ML algorithms, plotting the average and maximum trends as a reference.
The highest accuracies were obtained during the winter (Max: 80.51; Median: 75.45) and spring (Max: 77.76; Median: 75.80), reaching the worst predictions during the summer (Max: 73.82; Median: 70.80) and fall (Max: 75.14; Median: 68.79). Result consistency was evidenced by a historical database containing more than 100 years of hurricane and tropical storm records (
Figure 7a: adapted from
https://www.nhc.noaa.gov/climo/ (accessed on 1 May 2020)) in the Atlantic (Atlantic Ocean, Caribbean Sea, and Gulf of Mexico). This database provided by the National Oceanic and Atmospheric Administration (NOAA) [
34] shows that the months with the highest incidence of extreme weather events (August, September, and October) coincide with the worst seasons indicated by the prediction models. The occurrence of high-intensity winds during the summer and fall certainly contributed to the worst performance of these models in distinguishing natural from anthropic oil slicks.
Precisely in the years of the project (2008–2012), the time series evidenced a higher incidence of extreme weather events (
Figure 7b, blue dashed line), notably with major hurricanes above the NOAA’s average, reinforcing the above conclusions.
Extreme events generate high-intensity winds that increase the heights of the waves and the strength of the gravity currents. These extreme conditions tend to damage pipelines, causing oil spills. Additionally, accumulated damage to oil rigs and vessels, as well as to several other critical facilities in petroleum fields, may indirectly produce oil spills during these events or later. Coincidentally, exactly in the years with the highest incidence of extreme weather events (2010, 2011, 2012), the number of spills was significantly higher than the occurrence of seeps (
Table 6). Investigating the relationship between the spills and increasing extreme events is an important topic for future research, considering the environmental and socio-economic impacts that oil pollution may have on local ecosystems.
Regarding ML algorithms (
Figure 6b), RF showed the highest median accuracies, remaining above average for almost all seasons. It is interesting to note that the maximum accuracy achieved using the complete dataset (73.15) was surpassed during the best (Winter: 80.51) and the worst scenarios (Summer: 73.82).
3.2.2. Effect of the RADARSAT-2 Beam Modes on the Classification Model Accuracy
Since oil slick detectability is also limited by satellite configurations, an analysis regarding the effect of RADARSAT-2 beam modes over OSS predictions is recommended.
Aiming to discover the best SAR configuration, the same 12 features and ML algorithms were used to investigate four scenarios (
Table 2, 1, 6–8) as follows: (a) All beam modes together (ALL: W1, W2, SCNA, and SCNB); (b) only the SCN modes (SCN: SCNA and SCNB); (c) SCNA; (d) SCNB. The properties of each beam mode and the respective number of oil slicks detected per beam are available in
Table 2.
The Wide modes were not individually evaluated, since they represent only 7% of the oil slicks registered in the database. This poor sample representation by the Wide modes would provide neither robust nor statistically significant results to be evaluated. To avoid an imbalance of classes, the effect of SCN beam modes was solely considered in the analysis. The maximum prediction accuracies obtained are available in
Table 7a, and the median accuracies are available in
Table 7b.
The graph in
Figure 8a compares the maximum and the median accuracies achieved by CM considering all beam modes, SCN modes, SCNA, and SCNB.
Figure 8b provides the median accuracies for all tested ML algorithms, plotting the average as a reference.
It is interesting to mention that the exclusion of the Wide modes slightly decreased the classification model maximum accuracies, keeping a similar median accuracy (
Figure 8a). This indicates that even though in a smaller proportion within the database, the Wide modes may have been positively contributing to OSS identification, probably because of the higher spatial resolution of these modes (26 m) when compared to SCNA and SCNB (50 m). The higher the spatial resolution, the higher the mode’s ability to detect small dark spots, as well as to better delineate the shape and the border of the larger oil slicks.
Another important conclusion can be seen in the graph available in
Figure 8a, which indicates that for both modes, SCNA and SCNB, the maximum accuracies improved from 73.15, considering all modes together, to 74.59 with only SCNA, achieving a detectability value of 80 using the SCNB mode. The importance of the SCNB mode is enhanced when examining the median accuracies (
Figure 8a, dashed line). This graph demonstrates that the contribution of the SCNB mode to improving CMs is significantly higher (77.11) than that of SCNA (71.65). SCNA showed median accuracies (71.65) similar to those obtained by all modes (71.53) and SCN modes together (71.13).
Thus, SCMs designed for SCNB improved OSS prediction, providing an increment of about 8%, in terms of median accuracies. The higher performances were obtained using the RF algorithm, presenting above average median accuracies for all tested cases (
Figure 8b). Particularly for the SCNB mode, all tested ML algorithms showed similar or higher performances, reinforcing the conclusion that SCNB presented better potential to distinguish seeps from spills.
The obtained results are consistent with the concepts regarding the detectability of the sea surface scattering mechanisms using SAR instruments. As mentioned previously, it is well known that SAR viewing geometry and instrument noise floor (NESZ) can affect target detection [
12,
36,
37,
38,
39].
In this case study, both RADARSAT-2 beam modes, SCNA and SCNB, covered the range of incidence angles recommended by oil slick detection (20° ≤ ϴi ≤ 45°), with the same swath width. However, SCNB comprises higher incidence angles (31° ≤ ϴi ≤ 47°) with a higher inclined geometry, starting the scene acquisition 11o above SCNA (20° ≤ ϴi ≤ 39°). These characteristics may have enhanced the contrast between the dark spots and the surrounding ocean in the near range.
Moreover, conceptual beam modes like SCNA and SCNB are a multiplexing of different physical beams [
38]; consequently, their NESZ is an integration of the noise floor provided by each single mode (
Table 8). SCNA merges the geometric and the noise properties of two physical beams, Wide 1 (W1) and Wide 2 (W2), while SCNB merges three different beams, Wide 2 (W2), Standard 5 (S5), and Standard 6 (S6) [
38].
Table 8 synthesizes the NESZ in dB, indicating that the maximum and the minimum noise levels are lower for SCNB, remaining 2.5 dB below SCNA.
Therefore, differences in terms of viewing geometry in the near range added to lower noise floor levels, very likely contributed to a better detectability provided by the SCNB mode, probably improving the contrast between the dark spots and the surrounding ocean.
Moreover, since the information about the beam modes can also be depicted per seasonality, a deeper analysis was done considering the synergy effect among them in 12 scenarios (
Table 2, 9–20). SCN was not affected after being divided by seasons (
Table 2, Scenarios 9–12), thus keeping the previously observed tendency.
The synergy effect between the beam modes and seasonality is perceptible in terms of accuracies for SCNA and SCNB. After dividing SCNA by season (
Table 2, Scenarios 13–16), the maximum median accuracy increases from 71.65 to 82.25 during the winter. The same effect occurs for the SCNB mode. Without considering the seasons, the maximum median accuracy is 77.10; after splitting by seasons (
Table 2, Scenarios 17–20), it reaches 83.05 during the winter.
Assessing the performances of the algorithms for SCNA, RF kept the best accuracies always above the average, before and after the division by seasons. For SCNB, the behavior of the algorithms was different after splitting, showing that LDA and LR responded better than RF. These results are important to demonstrate the potential of specific models to improve classification results.
Figure 9a synthesizes the landmarks achieved by classification models in terms of performance. It shows the best maximum accuracies (red line), median accuracies (blue line), and the total increments in terms of median performances, considering (i) the global model (GCM); (ii) the better season (SCM: Winter); (iii) the better beam mode (SCM: SCNB); (iv) the synergy between the best beam mode and season (SCM: SCNB/Winter).
The landmarks evolution shows the potential of optimized models (SCM) to significantly improve the prediction accuracies, which in previous studies, did not surpass a median accuracy of 70 [
5,
26,
27,
28]. The seasonality effect provoked an increment of 5% in terms of median accuracy over the best season (winter). SCNB provided a median increment of 8%. Finally, the best scenario showed a median increment of around 16%, accomplishing a maximum accuracy of 87.83 and distinguishing natural from anthropic oils (SCNB/Winter).
Analyzing the best median performances obtained by the tested ML algorithms, the non-parametric RF was the most robust in distinguishing seeps from spills in the GoM. RF delivered the best predictions in 81% of the scenarios (13), offering the best potential for distinguishing natural from anthropic oil slicks (
Figure 9b). Regarding satellite configurations, the best predictions were obtained employing RF in all combinations of beam modes (
Figure 9b). RF offered the best performances for spring, summer, and fall, while ANN had the best only for winter. RF robustness for oil slick detection has also been evidenced by different authors [
47,
52,
63,
64,
65]. However, the parametric algorithms LDA and LR offered better performances mainly after the synergy between the beam modes and seasons. Five out of 20 scenarios responded well using LDA and two responded well using LR (
Figure 9b). It is likely that the lower number of training samples available for these scenarios justifies the results, as parametric methods require a smaller number of samples for training [
41,
42,
43,
44].


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}