Figure 1.
The study area and the GaoFen-1 D dataset (A, B, C, D, E, and G are used for training and F is used for testing).
Figure 1.
The study area and the GaoFen-1 D dataset (A, B, C, D, E, and G are used for training and F is used for testing).
Figure 2.
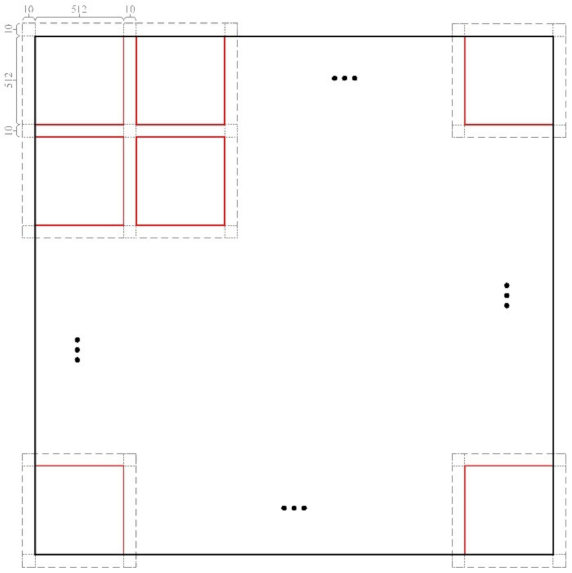
Steps of sample generation.
Figure 2.
Steps of sample generation.
Figure 3.
Flowchart of remote sensing image preprocessing.
Figure 3.
Flowchart of remote sensing image preprocessing.
Figure 4.
The structure of Squeeze and Excitation (SE) blocks. (a–c) are the structures of cSE, sSE, and scSE, respectively.
Figure 4.
The structure of Squeeze and Excitation (SE) blocks. (a–c) are the structures of cSE, sSE, and scSE, respectively.
Figure 5.
(a–c) Convolution kernels with different dilation rates of 0, 1, and 2, respectively.
Figure 5.
(a–c) Convolution kernels with different dilation rates of 0, 1, and 2, respectively.
Figure 6.
The structure of the Lightweight Multi-Scale Land Surface Water Extraction Network (LMSWENet).
Figure 6.
The structure of the Lightweight Multi-Scale Land Surface Water Extraction Network (LMSWENet).
Figure 7.
The accuracy curves of training and validation.
Figure 7.
The accuracy curves of training and validation.
Figure 8.
The loss curves of training and validation.
Figure 8.
The loss curves of training and validation.
Figure 9.
Land surface water information extraction results for different water types. (a(1)) is the raw image of artificial ditches; (a(2–7)) are the water areas extracted from (a(1)) using manually labeling, LMSWENet, DeeplabV3+, FCN, PSPNet, and UNet, respectively; (b(1)–g(7)) are the water areas extracted from various types of water with agricultural water, riverside, lakes, open pools, puddles, and tiny streams, respectively.
Figure 9.
Land surface water information extraction results for different water types. (a(1)) is the raw image of artificial ditches; (a(2–7)) are the water areas extracted from (a(1)) using manually labeling, LMSWENet, DeeplabV3+, FCN, PSPNet, and UNet, respectively; (b(1)–g(7)) are the water areas extracted from various types of water with agricultural water, riverside, lakes, open pools, puddles, and tiny streams, respectively.
Figure 10.
Land surface water information extraction results in a confusing area. (a(1)) is the raw image of highways; (a(2–7)) are the water areas extracted from (a(1)) using manually labeling, LMSWENet, DeeplabV3+,FCN, PSPNet, and UNet, respectively; (b(1)–e(7)) are the water areas extracted from different surface environments with mountain shadows, architecture shadows, agricultural land, and playgrounds, respectively.
Figure 10.
Land surface water information extraction results in a confusing area. (a(1)) is the raw image of highways; (a(2–7)) are the water areas extracted from (a(1)) using manually labeling, LMSWENet, DeeplabV3+,FCN, PSPNet, and UNet, respectively; (b(1)–e(7)) are the water areas extracted from different surface environments with mountain shadows, architecture shadows, agricultural land, and playgrounds, respectively.
Figure 11.
Land surface water information extraction results for LMSWENet, LMSWENet “without scSE Blocks”, and LMSWENet “without Dilated Convolutions”. (a(1)) is the raw image of architecture shadows, and (a(2–5)) are the water areas extracted from (a(1)) using manually labeling, LMSWENet, LMSWENet “without scSE Blocks”, and LMSWENet “without Dilated Convolutions”, respectively; (b(1)–e(7)) are the water areas extracted from geography scenes with highways, ponds, small puddles, and rivers, respectively.
Figure 11.
Land surface water information extraction results for LMSWENet, LMSWENet “without scSE Blocks”, and LMSWENet “without Dilated Convolutions”. (a(1)) is the raw image of architecture shadows, and (a(2–5)) are the water areas extracted from (a(1)) using manually labeling, LMSWENet, LMSWENet “without scSE Blocks”, and LMSWENet “without Dilated Convolutions”, respectively; (b(1)–e(7)) are the water areas extracted from geography scenes with highways, ponds, small puddles, and rivers, respectively.
Figure 12.
The principle of the “sliding window” prediction method.
Figure 12.
The principle of the “sliding window” prediction method.
Figure 13.
Land surface water map of Wuhan for 2020 (LSWMWH-2020).
Figure 13.
Land surface water map of Wuhan for 2020 (LSWMWH-2020).
Figure 14.
The distribution of validation points in Wuhan. (a,b) are the distributions of random validation points and equidistant validation points, respectively.
Figure 14.
The distribution of validation points in Wuhan. (a,b) are the distributions of random validation points and equidistant validation points, respectively.
Figure 15.
Border area of water and non-water and the water extraction results. (a(1),b(1)) and are the raw image of ponds mixed with vegetation and sediment; (a(2),b(2)) are the water areas extracted from (a(1),b(1)) using LMSWENet; (c(1),c(2)) are the raw image of wetland and the water extraction result.
Figure 15.
Border area of water and non-water and the water extraction results. (a(1),b(1)) and are the raw image of ponds mixed with vegetation and sediment; (a(2),b(2)) are the water areas extracted from (a(1),b(1)) using LMSWENet; (c(1),c(2)) are the raw image of wetland and the water extraction result.
Table 1.
Recent methods for land surface water extraction.
Table 1.
Recent methods for land surface water extraction.
| Category | Extraction Method of Land Surface Water |
|---|
| Threshold algorithm | Threshold value of single wave band [8] |
| Law of the spectrum relevance [9,10] |
| Index of water body [15,16,17] |
| Machine learning | Support vector machine [22] |
| Maximum likelihood classification [19] |
| Decision tree [20] |
| Random forest [23] |
| Deep learning | Convolutional neural network [13,14] |
Table 2.
Notation and symbols used in this paper.
Table 2.
Notation and symbols used in this paper.
| Symbol | Description |
|---|
| The input image. |
| The feature map of the channel of an input image. |
| = Hight of a feature map, and = Width of a feature map. |
| A descriptor encoding the global spatial information. |
| The channel dimensions of feature maps |
| The spatial location of a point in the feature map. |
| The vectors obtained through two cascaded fully connected layers |
| Weights of two fully-connected layers. |
| The function |
| The Sigmoid function. |
| The mapping between and . |
| The tensor after spatial-dimension recalibration. |
| A vector in spatial position (i, j) along all channels |
| A projection tensor representing the linearly combined representation. |
| The weight of a convolutional layer. |
| The mapping between and . |
| The tensor after spatial-dimension recalibration. |
| The concatenation of and . |
Table 3.
Detailed information of the study data.
Table 3.
Detailed information of the study data.
| Images | Central Longitude (°E) | Central Latitude (°N) | Imaging Time
(M-D-Y) | Image Size (pixel×pixel) | Image Usage |
|---|
| A | 114.1 | 31.3 | 11-09-2020 | 41,329 × 40,988 | Training |
| B | 114.0 | 30.8 | 11-09-2020 | 41,335 × 40,983 | Training |
| C | 113.8 | 30.2 | 11-09-2020 | 40,004 × 39,643 | Training |
| D | 114.7 | 31.3 | 11-13-2020 | 41,188 × 40,839 | Training |
| E | 115.1 | 30.8 | 10-11-2020 | 41,070 × 40,715 | Training |
| G | 114.4 | 30.2 | 11-13-2020 | 41,224 × 40,854 | Training |
| F | 114.5 | 30.8 | 11-13-2020 | 41,211 × 40,876 | Testing |
Table 4.
Training parameters of CNNs.
Table 4.
Training parameters of CNNs.
| Parameter | Value |
|---|
| Loss function | Mean cross-entropy |
| Optimizer | Adam |
| Learning rate | 0.001, reduce to 1/2 of the previous every ten epochs |
| Batch size | 4 |
| Train epoch | 200 |
Table 5.
Eight evaluation criteria for the accuracy assessment.
Table 5.
Eight evaluation criteria for the accuracy assessment.
| Accuracy Evaluation Criteria | Definition | Formula |
|---|
| PA | The ratio of the correctly predicted pixel numbers to the total pixel numbers | |
| ER | The ratio of erroneously predicted pixel numbers to the total pixel numbers | |
| WP | The ratio of the number of correctly predicted water pixels to the number of the labelled water pixels | |
| MP | The mean Precision for all classes (water and background) | |
| WIoU | The ratio of the intersection to the union of the ground truth water and the predicted water area | |
| MIoU | The mean IoU for all classes (water and background) | |
| Recall | The proportion of the number of correctly predicted water pixels and the number of the actual target feature pixels | |
| F1-Score | The harmonic means for water precision and recall | |
Table 6.
The efficiency comparison of the CNNs.
Table 6.
The efficiency comparison of the CNNs.
| CNN | Number of Trainable
Parameters (Million) | FLOPs(G) | Training Time
(s/epoch) |
|---|
| LMSWENet | 11.35 | 49.24 | 65.63 |
| DeeplabV3+ | 26.71 | 54.80 | 82.53 |
| FCN | 18.64 | 80.56 | 75.64 |
| PSPNet | 17.46 | 117.28 | 78.86 |
| UNet | 17.27 | 160.60 | 72.53 |
Table 7.
Land surface water information extraction accuracy of the CNNs.
Table 7.
Land surface water information extraction accuracy of the CNNs.
| CNN | PA | ER | WPI | MPI | WIoU | MIoU | Recall | F1-Score |
|---|
| LMSWENet | 98.23% | 1.77% | 98.17% | 98.16% | 92.33% | 94.99% | 93.94% | 96.01% |
| DeeplabV3+ | 97.85% | 2.15% | 97.55% | 97.63% | 91.10% | 94.12% | 93.27% | 95.34% |
| FCN | 97.96% | 2.04% | 98.52% | 98.08% | 91.43% | 94.36% | 92.71% | 95.52% |
| PSPNet | 97.29% | 2.71% | 95.57% | 96.63% | 88.99% | 92.70% | 92.81% | 94.17% |
| UNet | 98.07% | 1.93% | 98.29% | 98.09% | 91.76% | 94.60% | 93.25% | 95.70% |
Table 8.
Land surface water information extraction accuracy of LMSWENet, LMSWENet “without scSE Blocks” and LMSWENet “without Dilated Convolutions”.
Table 8.
Land surface water information extraction accuracy of LMSWENet, LMSWENet “without scSE Blocks” and LMSWENet “without Dilated Convolutions”.
| CNN | PA | ER | WPI | MPI | WIoU | MioU | Recall | F1-Score |
|---|
| LMSWENet | 98.23% | 1.77% | 98.17% | 98.16% | 92.33% | 94.99% | 93.94% | 96.01% |
| LMSWENet “without scSE Blocks” | 97.95% | 2.05% | 98.74% | 98.15% | 92.29% | 94.74% | 93.39% | 95.99% |
| LMSWENet “without Dilated Convolutions” | 97.35% | 2.65% | 98.70% | 97.76% | 88.90% | 92.70% | 89.95% | 91.98% |
Table 9.
Confusion matrix for mapping.
Table 9.
Confusion matrix for mapping.
| Type of Validation Point | | Classification Data |
|---|
| Water | Not Water | Total |
|---|
| Random validation points | Reference data | Water | 91 | 19 | 110 |
| Not water | 5 | 235 | 240 |
| Total | 96 | 254 | 350 |
| Equidistant validation points | Water | 64 | 10 | 74 |
| Not water | 4 | 266 | 270 |
| Total | 68 | 276 | 344 |
Table 10.
Accuracy assessment for mapping.
Table 10.
Accuracy assessment for mapping.
Type of
Validation Point | PA | ER | WPI | MPI | WIoU | MIoU | Recall | F1-Score |
|---|
| Random validation points | 93.14% | 6.86% | 82.73% | 90.32% | 79.13% | 84.93% | 94.79% | 88.35% |
| Random validation points | 95.93% | 4.07% | 86.45% | 92.50% | 82.05% | 88.53% | 94.12% | 90.14% |

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}