
The Development and Application of Machine Learning in Atmospheric Environment Studies


Abstract
:1. Introduction
- Further application in the earth system. As a kind of universal approximation estimation algorithm, ML models have gained wide application in earth-system studies by using remote sensing data, such as atmospheric-pollutant prediction (including gas [41,42,43] and particulate matter pollutants [44,45,46,47]) or atmospheric-parameter retrieval and correction (e.g., Aerosol Optical Depth (AOD) retrieval and error correction [48], planetary boundary layer height estimation [49,50], aerosol chemical composition classification [51,52]), agricultural and forest prediction (e.g., yield prediction for different crops [53,54], forest habitats [55]), other parameter estimation or prediction in the earth system (e.g., land surface temperature (LST) [56,57], precipitation [58], soil moisture [59], evapotranspiration [60], biomass [61,62]), and so on.
- Introduce the development of ML models, especially for prediction;
- Review the application of ML models to atmospheric pollutants, including model classification, ML model performance, and identification of key variables;
- Conduct a case study that applies ML to deposition, in the hope of gaining further insight into the suitability of ML models for deposition estimation;
- Discuss the prospects of ML models for the study of atmospheric pollution.
2. Literature Search
3. Overview of Machine Learning Development
- Traditional convex optimization-based model
- 2.
- Tree models
- 3.
- Linear regression
- 4.
- Modern deep-learning structure models
4. Machine Learning Application to Atmospheric Pollution
- Analysis of the ML application trend by the annual number of publications, and the pollutants of concern;
- Comparison of ML model prediction performance;
- Design of a scoring system to explore key variables in ML models.
4.1. ML Application Trend
4.2. Model Performance
4.3. Key Variable Identification
- Meteorological variables, e.g., temperature, relative humidity, pressure, wind speed, precipitation, and so on.
- Pollutant variables. The most common variables are pollutant data from observation sites. Observation data are usually set as prediction targets. Due to the relationship between different pollutants, observations can also be used as input data for predictive models. Another kind of pollutant variable is satellite data, such as Aerosol Optical Depth (AOD), Top of Atmosphere (TOA) reflectance, and so on.
- Auxiliary variables, including temporal variables (e.g., month of the year, day of the month, and mathematical transformation), spatial variables (e.g., longitude, latitude, and mathematical transformation), elevation, land cover, and social and economic data (e.g., GDP, nightlight brightness, road density).
- Historical data, specifically referring to time-series data before the time point to be predicted, or spatial data near the location to be predicted. In this case, the observation values become both input variables and output targets. Whether they are used as input variables or output targets depends on the predicted time point and the station location. The number of previous time steps depends on your datasets, model types and the characteristics of your tasks. For example, several studies indicated that time series at shorter lags (e.g., one or two lags) are better for ML modeling [103,104,105,106]. However, for some ML structures with powerful capability of temporal information extraction (e.g., LSTM, GRU), suitable longer lags were better for the model performance [107,108].
5. Case Study: ML Application to Nitrate Wet Deposition Estimation
5.1. Study Area and Data
5.1.1. Study Area
5.1.2. Data
5.2. Model Design
5.3. Performance Comparison
5.4. Spatiotemporal Distribution
6. Future Prospects
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Turner, M.C.; Krewski, D.; Pope, C.A., III; Chen, Y.; Gapstur, S.M.; Thun, M.J. Long-term ambient fine particulate matter air pollution and lung cancer in a large cohort of never-smokers. Am. J. Respir. Crit. Care Med. 2011, 184, 1374–1381. [Google Scholar] [CrossRef]
- Kampa, M.; Castanas, E. Human health effects of air pollution. Environ. Pollut. 2008, 151, 362–367. [Google Scholar] [CrossRef]
- Liu, W.; Li, X.; Chen, Z.; Zeng, G.; León, T.; Liang, J.; Huang, G.; Gao, Z.; Jiao, S.; He, X. Land use regression models coupled with meteorology to model spatial and temporal variability of NO2 and PM10 in Changsha, China. Atmos. Environ. 2015, 116, 272–280. [Google Scholar] [CrossRef]
- Song, W.; Jia, H.; Huang, J.; Zhang, Y. A satellite-based geographically weighted regression model for regional PM2.5 estimation over the Pearl River Delta region in China. Remote Sens. Environ. 2014, 154, 1–7. [Google Scholar] [CrossRef]
- Wheeler, D.C.; Páez, A. Geographically weighted regression. In Handbook of Applied Spatial Analysis; Springer: Berlin/Heidelberg, Germany, 2010; pp. 461–486. [Google Scholar]
- Lu, X.; Zhang, L.; Chen, Y.; Zhou, M.; Zheng, B.; Li, K.; Liu, Y.; Lin, J.; Fu, T.-M.; Zhang, Q. Exploring 2016–2017 surface ozone pollution over China: Source contributions and meteorological influences. Atmos. Chem. Phys. 2019, 19, 8339–8361. [Google Scholar] [CrossRef] [Green Version]
- Holmes, N.S.; Morawska, L. A review of dispersion modelling and its application to the dispersion of particles: An overview of different dispersion models available. Atmos. Environ. 2006, 40, 5902–5928. [Google Scholar] [CrossRef] [Green Version]
- Hoek, G.; Beelen, R.; De Hoogh, K.; Vienneau, D.; Gulliver, J.; Fischer, P.; Briggs, D. A review of land-use regression models to assess spatial variation of outdoor air pollution. Atmos. Environ. 2008, 42, 7561–7578. [Google Scholar] [CrossRef]
- Liu, Y.; Goudreau, S.; Oiamo, T.; Rainham, D.; Hatzopoulou, M.; Chen, H.; Davies, H.; Tremblay, M.; Johnson, J.; Bockstael, A. Comparison of land use regression and random forests models on estimating noise levels in five Canadian cities. Environ. Pollut. 2020, 256, 113367. [Google Scholar] [CrossRef]
- Zuo, R.; Xiong, Y.; Wang, J.; Carranza, E.J.M. Deep learning and its application in geochemical mapping. Earth-Sci. Rev. 2019, 192, 1–14. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Yegnanarayana, B. Artificial Neural Networks; PHI Learning Pvt. Ltd.: New Delhi, India, 2009. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Pfaffhuber, K.A.; Berg, T.; Hirdman, D.; Stohl, A. Atmospheric mercury observations from Antarctica: Seasonal variation and source and sink region calculations. Atmos. Chem. Phys. 2012, 12, 3241–3251. [Google Scholar] [CrossRef] [Green Version]
- Baker, D.; Bösch, H.; Doney, S.; O’Brien, D.; Schimel, D. Carbon source/sink information provided by column CO2 measurements from the Orbiting Carbon Observatory. Atmos. Chem. Phys. 2010, 10, 4145–4165. [Google Scholar] [CrossRef] [Green Version]
- Bousiotis, D.; Brean, J.; Pope, F.D.; Dall’Osto, M.; Querol, X.; Alastuey, A.; Perez, N.; Petäjä, T.; Massling, A.; Nøjgaard, J.K. The effect of meteorological conditions and atmospheric composition in the occurrence and development of new particle formation (NPF) events in Europe. Atmos. Chem. Phys. 2021, 21, 3345–3370. [Google Scholar] [CrossRef]
- Lee, J.; Kim, K.-Y. Analysis of source regions and meteorological factors for the variability of spring PM10 concentrations in Seoul, Korea. Atmos. Environ. 2018, 175, 199–209. [Google Scholar] [CrossRef]
- Zhao, H.; Li, X.; Zhang, Q.; Jiang, X.; Lin, J.; Peters, G.P.; Li, M.; Geng, G.; Zheng, B.; Huo, H. Effects of atmospheric transport and trade on air pollution mortality in China. Atmos. Chem. Phys. 2017, 17, 10367–10381. [Google Scholar] [CrossRef] [Green Version]
- Ma, Q.; Wu, Y.; Zhang, D.; Wang, X.; Xia, Y.; Liu, X.; Tian, P.; Han, Z.; Xia, X.; Wang, Y. Roles of regional transport and heterogeneous reactions in the PM2.5 increase during winter haze episodes in Beijing. Sci. Total Environ. 2017, 599, 246–253. [Google Scholar] [CrossRef]
- An, Z.; Huang, R.-J.; Zhang, R.; Tie, X.; Li, G.; Cao, J.; Zhou, W.; Shi, Z.; Han, Y.; Gu, Z. Severe haze in northern China: A synergy of anthropogenic emissions and atmospheric processes. Proc. Natl. Acad. Sci. USA 2019, 116, 8657–8666. [Google Scholar] [CrossRef] [Green Version]
- Wu, R.; Xie, S. Spatial distribution of ozone formation in China derived from emissions of speciated volatile organic compounds. Environ. Sci. Technol. 2017, 51, 2574–2583. [Google Scholar] [CrossRef]
- Alparone, L.; Wald, L.; Chanussot, J.; Thomas, C.; Gamba, P.; Bruce, L.M. Comparison of pansharpening algorithms: Outcome of the 2006 GRS-S data-fusion contest. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3012–3021. [Google Scholar] [CrossRef] [Green Version]
- Ghamisi, P.; Rasti, B.; Yokoya, N.; Wang, Q.; Hofle, B.; Bruzzone, L.; Bovolo, F.; Chi, M.; Anders, K.; Gloaguen, R. Multisource and multitemporal data fusion in remote sensing. arXiv 2018, arXiv:1812.08287. [Google Scholar]
- Shen, H.; Meng, X.; Zhang, L. An integrated framework for the spatio–temporal–spectral fusion of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7135–7148. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.; Vakalopoulou, M.; Karantzalos, K.; Paragios, N.; Le Saux, B.; Moser, G.; Tuia, D. Multitemporal very high resolution from space: Outcome of the 2016 IEEE GRSS data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3435–3447. [Google Scholar] [CrossRef] [Green Version]
- Gavriil, K.; Muntingh, G.; Barrowclough, O.J. Void filling of digital elevation models with deep generative models. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1645–1649. [Google Scholar] [CrossRef]
- Zeng, C.; Shen, H.; Zhang, L. Recovering missing pixels for Landsat ETM+ SLC-off imagery using multi-temporal regression analysis and a regularization method. Remote Sens. Environ. 2013, 131, 182–194. [Google Scholar] [CrossRef]
- Gu, Z.; Zhan, Z.; Yuan, Q.; Yan, L. Single remote sensing image dehazing using a prior-based dense attentive network. Remote Sens. 2019, 11, 3008. [Google Scholar] [CrossRef] [Green Version]
- Shen, H.; Zhou, C.; Li, J.; Yuan, Q. SAR image despeckling employing a recursive deep CNN prior. IEEE Trans. Geosci. Remote Sens. 2020, 59, 273–286. [Google Scholar] [CrossRef]
- Wang, S.; Quan, D.; Liang, X.; Ning, M.; Guo, Y.; Jiao, L. A deep learning framework for remote sensing image registration. ISPRS J. Photogramm. Remote Sens. 2018, 145, 148–164. [Google Scholar] [CrossRef]
- Hughes, L.H.; Schmitt, M.; Mou, L.; Wang, Y.; Zhu, X.X. Identifying corresponding patches in SAR and optical images with a pseudo-siamese CNN. IEEE Geosci. Remote Sens. Lett. 2018, 15, 784–788. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Talukdar, S.; Singha, P.; Mahato, S.; Pal, S.; Liou, Y.-A.; Rahman, A. Land-use land-cover classification by machine learning classifiers for satellite observations—A review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Li, M.; Zhang, Z.; Xiao, B.; Cao, X. Multimodal ground-based cloud classification using joint fusion convolutional neural network. Remote Sens. 2018, 10, 822. [Google Scholar] [CrossRef] [Green Version]
- He, N.; Fang, L.; Plaza, A. Hybrid first and second order attention Unet for building segmentation in remote sensing images. Sci. China Inf. Sci. 2020, 63, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Jin, X.; Davis, C.H. Vehicle detection from high-resolution satellite imagery using morphological shared-weight neural networks. Image Vis. Comput. 2007, 25, 1422–1431. [Google Scholar] [CrossRef]
- Ji, S.; Yu, D.; Shen, C.; Li, W.; Xu, Q. Landslide detection from an open satellite imagery and digital elevation model dataset using attention boosted convolutional neural networks. Landslides 2020, 17, 1337–1352. [Google Scholar] [CrossRef]
- Zheng, J.; Fu, H.; Li, W.; Wu, W.; Zhao, Y.; Dong, R.; Yu, L. Cross-regional oil palm tree counting and detection via a multi-level attention domain adaptation network. ISPRS J. Photogramm. Remote Sens. 2020, 167, 154–177. [Google Scholar] [CrossRef]
- Khelifi, L.; Mignotte, M. Deep learning for change detection in remote sensing images: Comprehensive review and meta-analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Chan, K.L.; Khorsandi, E.; Liu, S.; Baier, F.; Valks, P. Estimation of surface NO2 concentrations over Germany from TROPOMI satellite observations using a machine learning method. Remote Sens. 2021, 13, 969. [Google Scholar] [CrossRef]
- Liu, R.; Ma, Z.; Liu, Y.; Shao, Y.; Zhao, W.; Bi, J. Spatiotemporal distributions of surface ozone levels in China from 2005 to 2017: A machine learning approach. Environ. Int. 2020, 142, 105823. [Google Scholar] [CrossRef]
- Requia, W.J.; Di, Q.; Silvern, R.; Kelly, J.T.; Koutrakis, P.; Mickley, L.J.; Sulprizio, M.P.; Amini, H.; Shi, L.; Schwartz, J. An ensemble learning approach for estimating high spatiotemporal resolution of ground-level ozone in the contiguous United States. Environ. Sci. Technol. 2020, 54, 11037–11047. [Google Scholar] [CrossRef]
- Chen, Z.-Y.; Zhang, T.-H.; Zhang, R.; Zhu, Z.-M.; Yang, J.; Chen, P.-Y.; Ou, C.-Q.; Guo, Y. Extreme gradient boosting model to estimate PM2.5 concentrations with missing-filled satellite data in China. Atmos. Environ. 2019, 202, 180–189. [Google Scholar] [CrossRef]
- Chen, G.; Wang, Y.; Li, S.; Cao, W.; Ren, H.; Knibbs, L.D.; Abramson, M.J.; Guo, Y. Spatiotemporal patterns of PM10 concentrations over China during 2005–2016: A satellite-based estimation using the random forests approach. Environ. Pollut. 2018, 242, 605–613. [Google Scholar] [CrossRef] [PubMed]
- Gupta, P.; Christopher, S.A. Particulate matter air quality assessment using integrated surface, satellite, and meteorological products: Multiple regression approach. J. Geophys. Res. Atmos. 2009, 114, D14205. [Google Scholar] [CrossRef] [Green Version]
- Yan, X.; Zang, Z.; Jiang, Y.; Shi, W.; Guo, Y.; Li, D.; Zhao, C.; Husi, L. A Spatial-Temporal Interpretable Deep Learning Model for improving interpretability and predictive accuracy of satellite-based PM2.5. Environ. Pollut. 2021, 273, 116459. [Google Scholar] [CrossRef]
- Lary, D.J.; Remer, L.; MacNeill, D.; Roscoe, B.; Paradise, S. Machine learning and bias correction of MODIS aerosol optical depth. IEEE Geosci. Remote Sens. Lett. 2009, 6, 694–698. [Google Scholar] [CrossRef] [Green Version]
- Rieutord, T.; Aubert, S.; Machado, T. Deriving boundary layer height from aerosol lidar using machine learning: KABL and ADABL algorithms. Atmos. Meas. Tech. 2021, 14, 4335–4353. [Google Scholar] [CrossRef]
- Krishnamurthy, R.; Newsom, R.K.; Berg, L.K.; Xiao, H.; Ma, P.-L.; Turner, D.D. On the estimation of boundary layer heights: A machine learning approach. Atmos. Meas. Tech. 2021, 14, 4403–4424. [Google Scholar] [CrossRef]
- Yorks, J.E.; Selmer, P.A.; Kupchock, A.; Nowottnick, E.P.; Christian, K.E.; Rusinek, D.; Dacic, N.; McGill, M.J. Aerosol and Cloud Detection Using Machine Learning Algorithms and Space-Based Lidar Data. Atmosphere 2021, 12, 606. [Google Scholar] [CrossRef]
- Siomos, N.; Fountoulakis, I.; Natsis, A.; Drosoglou, T.; Bais, A. Automated aerosol classification from spectral UV measurements using machine learning clustering. Remote Sens. 2020, 12, 965. [Google Scholar] [CrossRef] [Green Version]
- Pantazi, X.E.; Moshou, D.; Alexandridis, T.; Whetton, R.L.; Mouazen, A.M. Wheat yield prediction using machine learning and advanced sensing techniques. Comput. Electron. Agric. 2016, 121, 57–65. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Räsänen, A.; Rusanen, A.; Kuitunen, M.; Lensu, A. What makes segmentation good? A case study in boreal forest habitat mapping. Int. J. Remote Sens. 2013, 34, 8603–8627. [Google Scholar] [CrossRef]
- Zeng, C.; Long, D.; Shen, H.; Wu, P.; Cui, Y.; Hong, Y. A two-step framework for reconstructing remotely sensed land surface temperatures contaminated by cloud. ISPRS J. Photogramm. Remote Sens. 2018, 141, 30–45. [Google Scholar] [CrossRef]
- Mao, K.; Zuo, Z.; Shen, X.; Xu, T.; Gao, C.; Liu, G. Retrieval of land-surface temperature from AMSR2 data using a deep dynamic learning neural network. Chin. Geogr. Sci. 2018, 28, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Moraux, A.; Dewitte, S.; Cornelis, B.; Munteanu, A. A Deep Learning Multimodal Method for Precipitation Estimation. Remote Sens. 2021, 13, 3278. [Google Scholar] [CrossRef]
- Ali, I.; Greifeneder, F.; Stamenkovic, J.; Neumann, M.; Notarnicola, C. Review of machine learning approaches for biomass and soil moisture retrievals from remote sensing data. Remote Sens. 2015, 7, 16398–16421. [Google Scholar] [CrossRef] [Green Version]
- Elbeltagi, A.; Deng, J.; Wang, K.; Malik, A.; Maroufpoor, S. Modeling long-term dynamics of crop evapotranspiration using deep learning in a semi-arid environment. Agric. Water Manag. 2020, 241, 106334. [Google Scholar] [CrossRef]
- Zhang, L.; Shao, Z.; Liu, J.; Cheng, Q. Deep learning based retrieval of forest aboveground biomass from combined LiDAR and landsat 8 data. Remote Sens. 2019, 11, 1459. [Google Scholar] [CrossRef] [Green Version]
- Castro, W.; Marcato Junior, J.; Polidoro, C.; Osco, L.P.; Gonçalves, W.; Rodrigues, L.; Santos, M.; Jank, L.; Barrios, S.; Valle, C. Deep learning applied to phenotyping of biomass in forages with UAV-based RGB imagery. Sensors 2020, 20, 4802. [Google Scholar] [CrossRef]
- Jia, Y.; Yu, G.; He, N.; Zhan, X.; Fang, H.; Sheng, W.; Zuo, Y.; Zhang, D.; Wang, Q. Spatial and decadal variations in inorganic nitrogen wet deposition in China induced by human activity. Sci. Rep. 2014, 4, 3763. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sehmel, G.A. Particle and gas dry deposition: A review. Atmos. Environ. 1980, 14, 983–1011. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A review on generative adversarial networks: Algorithms, theory, and applications. arXiv 2020, arXiv:2001.06937. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Soman, K.; Loganathan, R.; Ajay, V. Machine Learning with SVM and Other Kernel Methods; PHI Learning Pvt. Ltd.: New Delhi, India, 2009. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [Green Version]
- Broomhead, D.S.; Lowe, D. Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks; Royal Signals and Radar Establishment: Worcestershire, UK, 1988. [Google Scholar]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Specht, D.F. A general regression neural network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Horne, B.G.; Tino, P.; Giles, C.L. Learning long-term dependencies in NARX recurrent neural networks. IEEE Trans. Neural Netw. 1996, 7, 1329–1338. [Google Scholar]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No. 04CH37541), Budapest, Hungary, 25–29 July 2004; pp. 985–990. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. Improved use of continuous attributes in C4. 5. J. Artif. Intell. Res. 1996, 4, 77–90. [Google Scholar] [CrossRef] [Green Version]
- Grajski, K.A.; Breiman, L.; Di Prisco, G.V.; Freeman, W.J. Classification of EEG spatial patterns with a tree-structured methodology: CART. IEEE Trans. Biomed. Eng. 1986, 1076–1086. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the ICML, Long Beach, CA, USA, 9–15 June 2019; pp. 148–156. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. arXiv 2017, arXiv:1706.09516. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso: A retrospective. J. R. Stat. Soc. Ser. B 2011, 73, 273–282. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R. Generalized additive models: Some applications. J. Am. Stat. Assoc. 1987, 82, 371–386. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Krogh, A.; Hertz, J.A. A simple weight decay can improve generalization. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 30 November–3 December 1992; pp. 950–957. [Google Scholar]
- Li, K.; Jacob, D.J.; Shen, L.; Lu, X.; De Smedt, I.; Liao, H. Increases in surface ozone pollution in China from 2013 to 2019: Anthropogenic and meteorological influences. Atmos. Chem. Phys. 2020, 20, 11423–11433. [Google Scholar] [CrossRef]
- Liang, P.; Zhu, T.; Fang, Y.; Li, Y.; Han, Y.; Wu, Y.; Hu, M.; Wang, J. The role of meteorological conditions and pollution control strategies in reducing air pollution in Beijing during APEC 2014 and Victory Parade 2015. Atmos. Chem. Phys. 2017, 17, 13921–13940. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Ma, Q.; Zhao, B.; Liu, X.; Wang, Y.; Jia, B.; Zhang, X. Winter haze over North China Plain from 2009 to 2016: Influence of emission and meteorology. Environ. Pollut. 2018, 242, 1308–1318. [Google Scholar] [CrossRef]
- Rahman, S.M.; Khondaker, A.; Abdel-Aal, R. Self organizing ozone model for Empty Quarter of Saudi Arabia: Group method data handling based modeling approach. Atmos. Environ. 2012, 59, 398–407. [Google Scholar] [CrossRef]
- Lu, W.-Z. Comparison of three prediction strategies within PM2.5 and PM10 monitoring networks. Atmos. Pollut. Res. 2020, 11, 590–597. [Google Scholar]
- Sfetsos, A.; Vlachogiannis, D. A new methodology development for the regulatory forecasting of PM10. Application in the Greater Athens Area, Greece. Atmos. Environ. 2010, 44, 3159–3172. [Google Scholar] [CrossRef]
- Sun, W.; Li, Z. Hourly PM2.5 concentration forecasting based on mode decomposition-recombination technique and ensemble learning approach in severe haze episodes of China. J. Clean. Prod. 2020, 263, 121442. [Google Scholar] [CrossRef]
- Abirami, S.; Chitra, P. Regional air quality forecasting using spatiotemporal deep learning. J. Clean. Prod. 2021, 283, 125341. [Google Scholar] [CrossRef]
- Zhang, B.; Zou, G.; Qin, D.; Lu, Y.; Jin, Y.; Wang, H. A novel Encoder-Decoder model based on read-first LSTM for air pollutant prediction. Sci. Total Environ. 2021, 765, 144507. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, S.; Tomsett, R.; Raghavendra, R.; Harborne, D.; Alzantot, M.; Cerutti, F.; Srivastava, M.; Preece, A.; Julier, S.; Rao, R.M. Interpretability of deep learning models: A survey of results. In Proceedings of the 2017 IEEE Smartworld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (smartworld/SCALCOM/UIC/ATC/CBDcom/IOP/SCI), San Francisco, CA, USA, 4–8 August 2017; pp. 1–6. [Google Scholar]
- Bessho, K.; Date, K.; Hayashi, M.; Ikeda, A.; Imai, T.; Inoue, H.; Kumagai, Y.; Miyakawa, T.; Murata, H.; Ohno, T. An introduction to Himawari-8/9—Japan’s new-generation geostationary meteorological satellites. J. Meteorol. Soc. Japan. Ser. II 2016, 94, 151–183. [Google Scholar] [CrossRef] [Green Version]
- Ialongo, I.; Virta, H.; Eskes, H.; Hovila, J.; Douros, J. Comparison of TROPOMI/Sentinel-5 Precursor NO2 observations with ground-based measurements in Helsinki. Atmos. Meas. Tech. 2020, 13, 205–218. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Stoffelen, A.; Zou, J.; Lin, W.; Verhoef, A.; Zhang, Y.; He, Y.; Lin, M. Validation of new sea surface wind products from Scatterometers Onboard the HY-2B and MetOp-C satellites. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4387–4394. [Google Scholar] [CrossRef]
- Ackerman, D.; Millet, D.B.; Chen, X. Global estimates of inorganic nitrogen deposition across four decades. Glob. Biogeochem. Cycles 2019, 33, 100–107. [Google Scholar] [CrossRef] [Green Version]
- Ge, Y.; Heal, M.R.; Stevenson, D.S.; Wind, P.; Vieno, M. Evaluation of global EMEP MSC-W (rv4.34)-WRF (v3.9.1.1) model surface concentrations and wet deposition of reactive N and S with measurements. Geosci. Model Dev. Discuss. 2021, 14, 7021–7046. [Google Scholar] [CrossRef]
- Kun, Y.; Jie, H. China Meteorological Forcing Dataset (1979–2018); National Tibetan Plateau Data Center: Beijing, China, 2019. [Google Scholar] [CrossRef]
- Liu, M.; Lin, J.; Boersma, K.F.; Pinardi, G.; Wang, Y.; Chimot, J.; Wagner, T.; Xie, P.; Eskes, H.; Roozendael, M.V. Improved aerosol correction for OMI tropospheric NO2 retrieval over East Asia: Constraint from CALIOP aerosol vertical profile. Atmos. Meas. Tech. 2019, 12, 1–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, M.; Liu, H.; Geng, G.; Hong, C.; Liu, F.; Song, Y.; Tong, D.; Zheng, B.; Cui, H.; Man, H. Anthropogenic emission inventories in China: A review. Natl. Sci. Rev. 2017, 4, 834–866. [Google Scholar] [CrossRef]
- Zheng, B.; Tong, D.; Li, M.; Liu, F.; Hong, C.; Geng, G.; Li, H.; Li, X.; Peng, L.; Qi, J. Trends in China’s anthropogenic emissions since 2010 as the consequence of clean air actions. Atmos. Chem. Phys. 2018, 18, 14095–14111. [Google Scholar] [CrossRef] [Green Version]
- Dhillon, A.; Verma, G.K. Convolutional neural network: A review of models, methodologies and applications to object detection. Prog. Artif. Intell. 2020, 9, 85–112. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Huang, Z.; Wang, S.; Zheng, J.; Yuan, Z.; Ye, S.; Kang, D. Modeling inorganic nitrogen deposition in Guangdong province, China. Atmos. Environ. 2015, 109, 147–160. [Google Scholar] [CrossRef]
- Hoshyaripour, G.; Brasseur, G.; Andrade, M.; Gavidia-Calderón, M.; Bouarar, I.; Ynoue, R.Y. Prediction of ground-level ozone concentration in São Paulo, Brazil: Deterministic versus statistic models. Atmos. Environ. 2016, 145, 365–375. [Google Scholar] [CrossRef]
- Zhan, Y.; Luo, Y.; Deng, X.; Zhang, K.; Zhang, M.; Grieneisen, M.L.; Di, B. Satellite-based estimates of daily NO2 exposure in China using hybrid random forest and spatiotemporal kriging model. Environ. Sci. Technol. 2018, 52, 4180–4189. [Google Scholar] [CrossRef] [PubMed]
- Fernando, H.J.; Mammarella, M.; Grandoni, G.; Fedele, P.; Di Marco, R.; Dimitrova, R.; Hyde, P. Forecasting PM10 in metropolitan areas: Efficacy of neural networks. Environ. Pollut. 2012, 163, 62–67. [Google Scholar] [CrossRef]
- Bai, Y.; Li, Y.; Zeng, B.; Li, C.; Zhang, J. Hourly PM2.5 concentration forecast using stacked autoencoder model with emphasis on seasonality. J. Clean. Prod. 2019, 224, 739–750. [Google Scholar] [CrossRef]
- Wang, B.; Jiang, Q.; Jiang, P. A combined forecasting structure based on the L1 norm: Application to the air quality. J. Environ. Manag. 2019, 246, 299–313. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Ausati, S.; Amanollahi, J. Assessing the accuracy of ANFIS, EEMD-GRNN, PCR, and MLR models in predicting PM2.5. Atmos. Environ. 2016, 142, 465–474. [Google Scholar] [CrossRef]
- Niu, M.; Gan, K.; Sun, S.; Li, F. Application of decomposition-ensemble learning paradigm with phase space reconstruction for day-ahead PM2.5 concentration forecasting. J. Environ. Manag. 2017, 196, 110–118. [Google Scholar] [CrossRef] [PubMed]
- Luo, H.; Wang, D.; Yue, C.; Liu, Y.; Guo, H. Research and application of a novel hybrid decomposition-ensemble learning paradigm with error correction for daily PM10 forecasting. Atmos. Res. 2018, 201, 34–45. [Google Scholar] [CrossRef]
- Wu, Q.; Lin, H. A novel optimal-hybrid model for daily air quality index prediction considering air pollutant factors. Sci. Total Environ. 2019, 683, 808–821. [Google Scholar] [CrossRef]
- Zhan, Y.; Luo, Y.; Deng, X.; Chen, H.; Grieneisen, M.L.; Shen, X.; Zhu, L.; Zhang, M. Spatiotemporal prediction of continuous daily PM2.5 concentrations across China using a spatially explicit machine learning algorithm. Atmos. Environ. 2017, 155, 129–139. [Google Scholar] [CrossRef]
- Li, T.; Shen, H.; Yuan, Q.; Zhang, X.; Zhang, L. Estimating ground-level PM2.5 by fusing satellite and station observations: A geo-intelligent deep learning approach. Geophys. Res. Lett. 2017, 44, 11985–11993. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Chen, C. Spatial air quality index prediction model based on decomposition, adaptive boosting, and three-stage feature selection: A case study in China. J. Clean. Prod. 2020, 265, 121777. [Google Scholar] [CrossRef]
- Wei, J.; Huang, W.; Li, Z.; Xue, W.; Peng, Y.; Sun, L.; Cribb, M. Estimating 1-km-resolution PM2.5 concentrations across China using the space-time random forest approach. Remote Sens. Environ. 2019, 231, 111221. [Google Scholar] [CrossRef]
- Díaz-Robles, L.A.; Ortega, J.C.; Fu, J.S.; Reed, G.D.; Chow, J.C.; Watson, J.G.; Moncada-Herrera, J.A. A hybrid ARIMA and artificial neural networks model to forecast particulate matter in urban areas: The case of Temuco, Chile. Atmos. Environ. 2008, 42, 8331–8340. [Google Scholar] [CrossRef] [Green Version]
- Zhu, S.; Yang, L.; Wang, W.; Liu, X.; Lu, M.; Shen, X. Optimal-combined model for air quality index forecasting: 5 cities in North China. Environ. Pollut. 2018, 243, 842–850. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Kukkonen, J.; Olsson, T.; Schultz, D.M.; Baklanov, A.; Klein, T.; Miranda, A.; Monteiro, A.; Hirtl, M.; Tarvainen, V.; Boy, M. A review of operational, regional-scale, chemical weather forecasting models in Europe. Atmos. Chem. Phys. 2012, 12, 1–87. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Cao, X.; Liu, B.; Gao, M. Solving partial differential equations using deep learning and physical constraints. Appl. Sci. 2020, 10, 5917. [Google Scholar] [CrossRef]
- Conibear, L.; Reddington, C.L.; Silver, B.J.; Chen, Y.; Knote, C.; Arnold, S.R.; Spracklen, D.V. Statistical emulation of winter ambient fine particulate matter concentrations from emission changes in China. GeoHealth 2021, 5, e2021GH000391. [Google Scholar] [CrossRef]
- Zheng, Z.; Curtis, J.H.; Yao, Y.; Gasparik, J.T.; Anantharaj, V.G.; Zhao, L.; West, M.; Riemer, N. Estimating submicron aerosol mixing state at the global scale with machine learning and Earth system modeling. Earth Space Sci. 2021, 8, e2020EA001500. [Google Scholar] [CrossRef]
- Li, R.; Cui, L.; Zhao, Y.; Meng, Y.; Kong, W.; Fu, H. Estimating monthly wet sulfur (S) deposition flux over China using an ensemble model of improved machine learning and geostatistical approach. Atmos. Environ. 2019, 214, 116884. [Google Scholar] [CrossRef]
- Huang, K.; Xiao, Q.; Meng, X.; Geng, G.; Wang, Y.; Lyapustin, A.; Gu, D.; Liu, Y. Predicting monthly high-resolution PM2.5 concentrations with random forest model in the North China Plain. Environ. Pollut. 2018, 242, 675–683. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Zhang, X. Predicting ground-level PM2.5 concentrations in the Beijing-Tianjin-Hebei region: A hybrid remote sensing and machine learning approach. Environ. Pollut. 2019, 249, 735–749. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
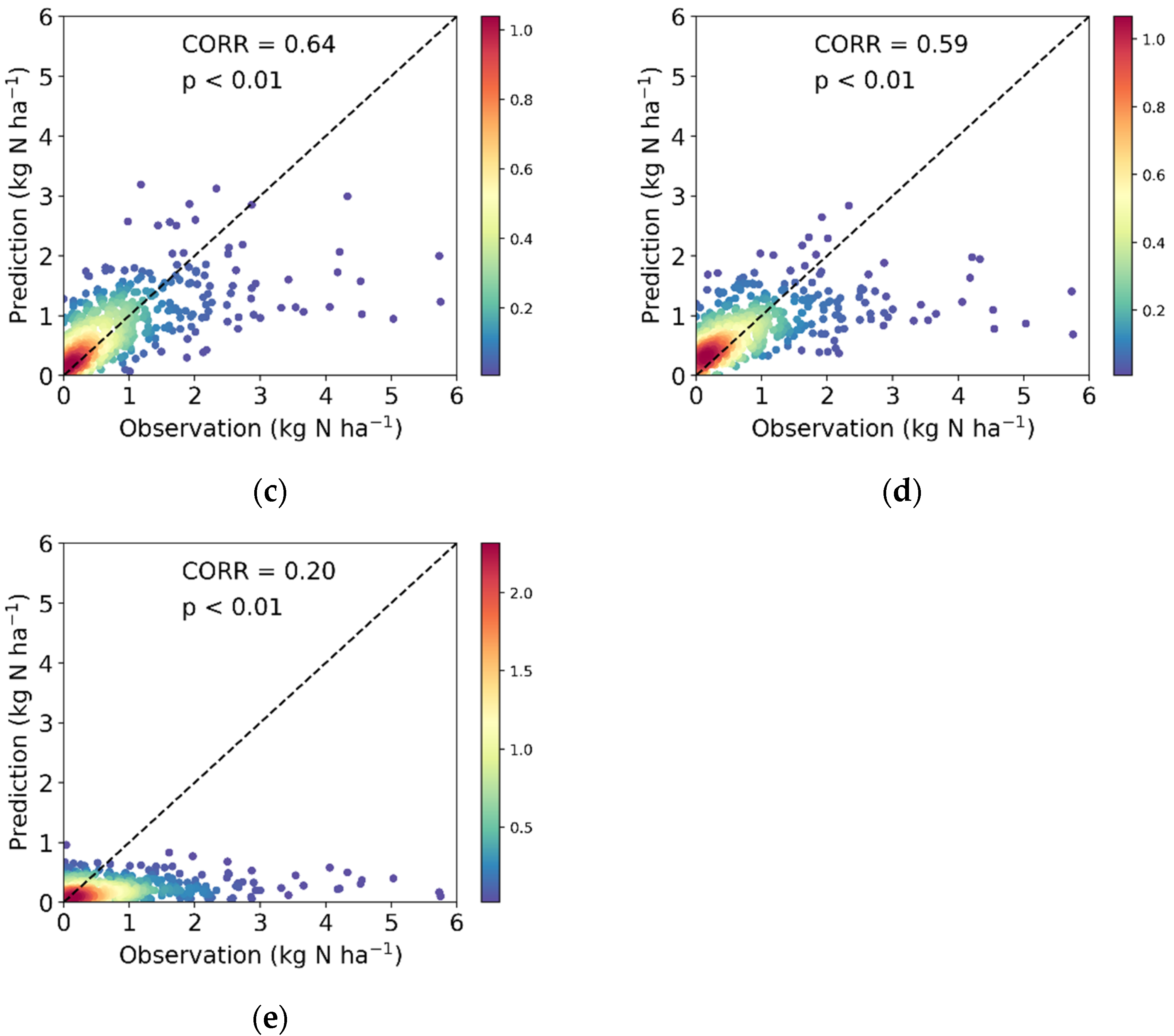
| Model | CORR | RMSE | MSE | MAE |
|---|---|---|---|---|
| CNN | 0.68 | 0.61 | 0.38 | 0.37 |
| RF | 0.65 | 0.64 | 0.41 | 0.38 |
| MLP | 0.64 | 0.64 | 0.41 | 0.39 |
| MLR | 0.59 | 0.68 | 0.46 | 0.41 |
| WRF-EMEP | 0.20 | 0.93 | 0.87 | 0.55 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, L.; Lin, R.; Wang, X.; Chen, W. The Development and Application of Machine Learning in Atmospheric Environment Studies. Remote Sens. 2021, 13, 4839. https://doi.org/10.3390/rs13234839
Zheng L, Lin R, Wang X, Chen W. The Development and Application of Machine Learning in Atmospheric Environment Studies. Remote Sensing. 2021; 13(23):4839. https://doi.org/10.3390/rs13234839
Chicago/Turabian StyleZheng, Lianming, Rui Lin, Xuemei Wang, and Weihua Chen. 2021. "The Development and Application of Machine Learning in Atmospheric Environment Studies" Remote Sensing 13, no. 23: 4839. https://doi.org/10.3390/rs13234839
APA StyleZheng, L., Lin, R., Wang, X., & Chen, W. (2021). The Development and Application of Machine Learning in Atmospheric Environment Studies. Remote Sensing, 13(23), 4839. https://doi.org/10.3390/rs13234839