1. Introduction
Hyperspectral images (HSIs) contain rich spatial and spectral information, and have been widely used in many fields of application, such as environmental science, precision agriculture, and land cover mapping [
1,
2,
3,
4]. However, the high-dimensional nature of spectral bands can lead to decreases in storage and computing efficiency [
5]. In addition, the number of available training samples is usually limited in practical application [
6], and it is still a challenging task to achieve a high-precision classification from HSIs [
7,
8].
To solve the above-mentioned problem, feature extraction must be carried out in order to reduce the dimensions of HSIs before inputting them into classifiers. Linear and nonlinear feature-extraction methods are generally applied to HSI classification. Principal component analysis (PCA) [
9], linear discriminant analysis (LDA) [
10], and independent component analysis (ICA) [
11] are the most commonly used linear methods. Nevertheless, linear dimension-reduction methods cannot well solve the nonlinear problems existing in HSIs, and the deep features cannot be extracted. More efficient and robust dimension-reduction methods are required in order to process HSIs. Consequently, some effective methods have been developed. For example, stacked autoencoders (SAEs) [
12] have a good performance in dealing with nonlinear problems; the loss of information can be minimized, and more complex data can be processed. In addition, due to the high-dimensional, nonlinear, and small training samples for HSIs, the classifiers are required to have the ability to extract and process deep features [
13]. Unfortunately, traditional classification methods—such as support vector machine (SVM) [
14], extreme learning machine (ELM) [
15], and random forest (RF) [
16]—are often incapable of giving satisfying classification results without the support of deep features. Zhu et al. [
17] proposed an image-fusion-based algorithm to extract depth information and verify its effectiveness via experiments. Han et al. [
18] developed an edge-preserving filtering-based method that can better remove haze from original images and preserve their spatial details. However, these two methods lack the ability to automatically learn depth features, and rely on prior knowledge.
In recent years, deep learning (DL)-based classification methods have been favored due to the powerful ability of convolutional neural networks (CNNs) to automatically extract deep features [
19,
20]. Some researchers have improved the classification accuracy of HSIs by designing the architectures of CNNs [
21,
22]. Chen et al. [
23,
24] proposed a DL framework combining spatial and spectral features for the first time. The SAE and deep belief network (DBN) were used as feature extractors in order to obtain better classification results, demonstrating the great potential of DL in accurately classifying HSIs. Zhao et al. [
25] proposed a spectral–spatial feature-based classification (SSFC) framework, in which a balanced local discriminant embedding (BLDE) algorithm and two-dimensional CNN (2D-CNN) network were used to extract spectral and spatial information from the dimension-reduced HSIs; it can be observed that this framework does not make use of the three-dimensional (3D) characteristics of HSIs, and needs to be further improved.
Based on spectral–spatial information and 3D characteristics, Li et al. [
26] proposed a three-dimensional convolutional neural network (3D-CNN) framework for precise classification of HSIs. In comparison with 2D-CNNs, the 3D-CNN can more effectively extract deep spatial–spectral fusion features. Roy et al. [
27] designed a hybrid 2D and 3D neural network (HybridSN), finding that the HybridSN reduces the model complexity and has better classification performance than a single 3D neural network. It is clear that shallow networks are generally deficient in terms of classification performance.
Compared with shallow networks, the features extracted from deep network structure are more abstract, and the classification results are better. However, with the deepening development of the network structure, the gradient dispersion or explosion will appear during the backpropagation process, resulting in network degradation [
28,
29]. To solve these problems, network connection methods such as residual networks (ResNets) [
30] and dense networks (DenseNets) [
31] have been adopted, which are beneficial for training deeper networks and alleviating gradient disappearance. Zhong et al. [
32] proposed an end-to-end spatial–spectral residual network (SSRN) based on a 3D-CNN. The spectral and spatial residual modules were designed to learn spatial–spectral discrimination features, alleviating the decline in accuracy and further improving the classification performance. Wang et al. [
33] introduced a DenseNet into their proposed fast-density spatial–spectral convolutional (FDSSC) neural network framework, which achieved better accuracy in less time. Both SSRNs and FDSSC networks first extract spectral features and then extract spatial features. Nevertheless, in the process of extracting spatial features, the extracted spectral features may be destroyed. In addition, Feng et al. [
34] introduced a residual learning module and depth separable convolution based on a HybridSN to build the residual HybridSN (R-HybridSN), which can also obtain satisfactory classification results using depth and an effective network structure depending on less training samples; since the shallow features in the R-HybridSN have not been reused, the network structure can be further optimized.
Recently, as the most important part of human perception, the attention mechanism has been introduced into CNNs. This enables the model to selectively identify more critical features and ignore some information that is useless for classification [
35,
36]. Fang et al. [
37], based on a DenseNet and a spectral attention mechanism, proposed an end-to-end 3D dense convolutional network with a single-attention mechanism (MSDN-SA) for HSI classification; the network framework enhanced the discriminability of spectral features, and performed well on three datasets; however, it only considers the spectral branch attention, and not the spatial branch attention. Inspired by the attention mechanism of the human visual system, Mei et al. [
38] established a dual-channel attention spectral–spatial network based on an attention recurrent neural network (ARNN) and an attention CNN (ACNN), which trained the network in the spectral and spatial dimensions, respectively, to extract more advanced joint spectral–spatial features. Zhu et al. [
39] proposed an HSI defogging network based on dual self-attention boost residual octave convolution, which improved the defogging performance. Sun et al. [
40] proposed a spectral–spatial attention network (SSAN), in which a simple spectral–spatial network (SSN) was established and attention modules were introduced to suppress the influence of interfering pixels; the distinctive spectral–spatial features with a large contribution to classification could be extracted; similarly, this method may cause the same problems as the SSRN and FDSSC.
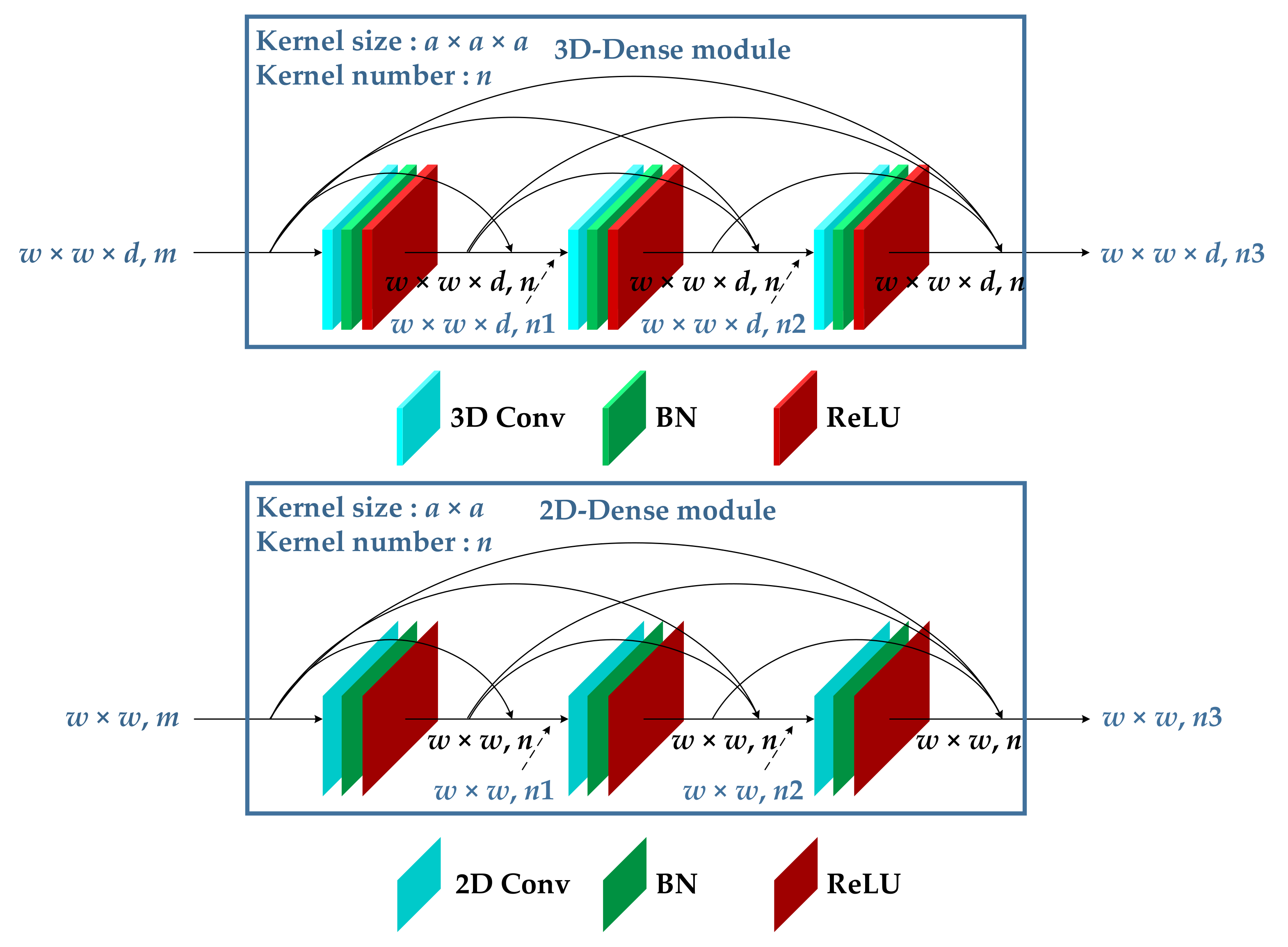
To make use of the attention mechanism and solve the problems of the SSRN and FDSSC, we proposed a hybrid dense network with dual attention (HDDA) for HSI classification. This framework contains two branches of 3D-DenseNet and 2D-DenseNet, which are used to extract spectral–spatial and spatial features, respectively, from dimension-reduced HSIs by the SAE. In addition, the residual channel attention and residual spatial attention are introduced for refining feature maps and avoiding unnecessary information. The enhanced spectral–spatial features are then obtained by connecting the outputs of two branches. Finally, classification results can be obtained using the softmax function. The main contributions of this work are listed as follows:
- (1)
In order to deal with the nonlinear and high-dimensional problems of HSIs, a four-hidden-layer SAE network was built to effectively extract deep features and reduce the feature dimensions;
- (2)
We proposed a hybrid dense network classifier with a dual-attention mechanism. The classification network has two independent feature-extraction paths, which continuously extract spectral–spatial features simultaneously in 3D and 2D spaces, respectively. The problem of feature conflict between the SSRN and FDSSC is avoided;
- (3)
We constructed the residual dual-attention module. By integrating channel attention and spatial attention, the feature refinement was realized in the channel and spatial dimensions respectively. The results showed that spectral and spatial features had a better impact on the classification results, suppressing less useful features.
The rest of this study is arranged as follows: Three HSI datasets and evaluation factors for assessing the proposed network are described in
Section 2. The background information is briefly introduced in
Section 3. The proposed overall classification framework is presented in detail in
Section 4. In
Section 5, the experimental results are compared and discussed with reference to the ablation experiments. Finally, a summary and future directions are provided in
Section 6.
2. Hyperspectral Datasets and Evaluation Factors
Three publicly available HSI datasets—namely, Indian Pines (IP), Pavia University (PU), and Salinas (SA)—were selected to verify the classification performance of the proposed HDDA method (
Table 1). The false-color composite images and ground-truth classes are shown in
Figure 1,
Figure 2 and
Figure 3 and
Table 2,
Table 3 and
Table 4. For a general deep network, the more training samples, the better the classification performance. Unfortunately, it is usually time-consuming and laborious to collect enough label information from HSI data. It can be difficult or even impossible to provide sufficient training samples for most networks. Moreover, with the increase in the number of samples, the computational complexity and time consumption also increase correspondingly. Consequently, it is better to perform the classification using a small number of training samples. In our study, only 5%, 1%, and 1% of the samples from IP, UP, and SA, respectively, were selected as the training set, while the remaining samples were used to validate the classification performance.
The primary configuration of the computer included an Intel Corei5-7300HQ CPU (2.50 GHz), a GTX1050Ti GPU, and 8 GB RAM, with the Windows 10 64-bit operating system. The compiler was Spyder and the DL framework was PyTorch. To comparatively analyze the classification performance, the overall accuracy (OA), average accuracy (AA), and kappa coefficient (
k) based on the confusion matrix were used as the evaluation factors [
41]. OA is the ratio between the correctly classified samples and total samples. AA is the ratio between the sum of the classification accuracy for each category and the number of categories.
k is generally used for checking consistency, and can be also used to measure the classification accuracy. The higher the three factors are, the better the classification performance.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















