
Revise-Net: Exploiting Reverse Attention Mechanism for Salient Object Detection

 , , , ,
, , , ,  and
and
Abstract
:1. Introduction
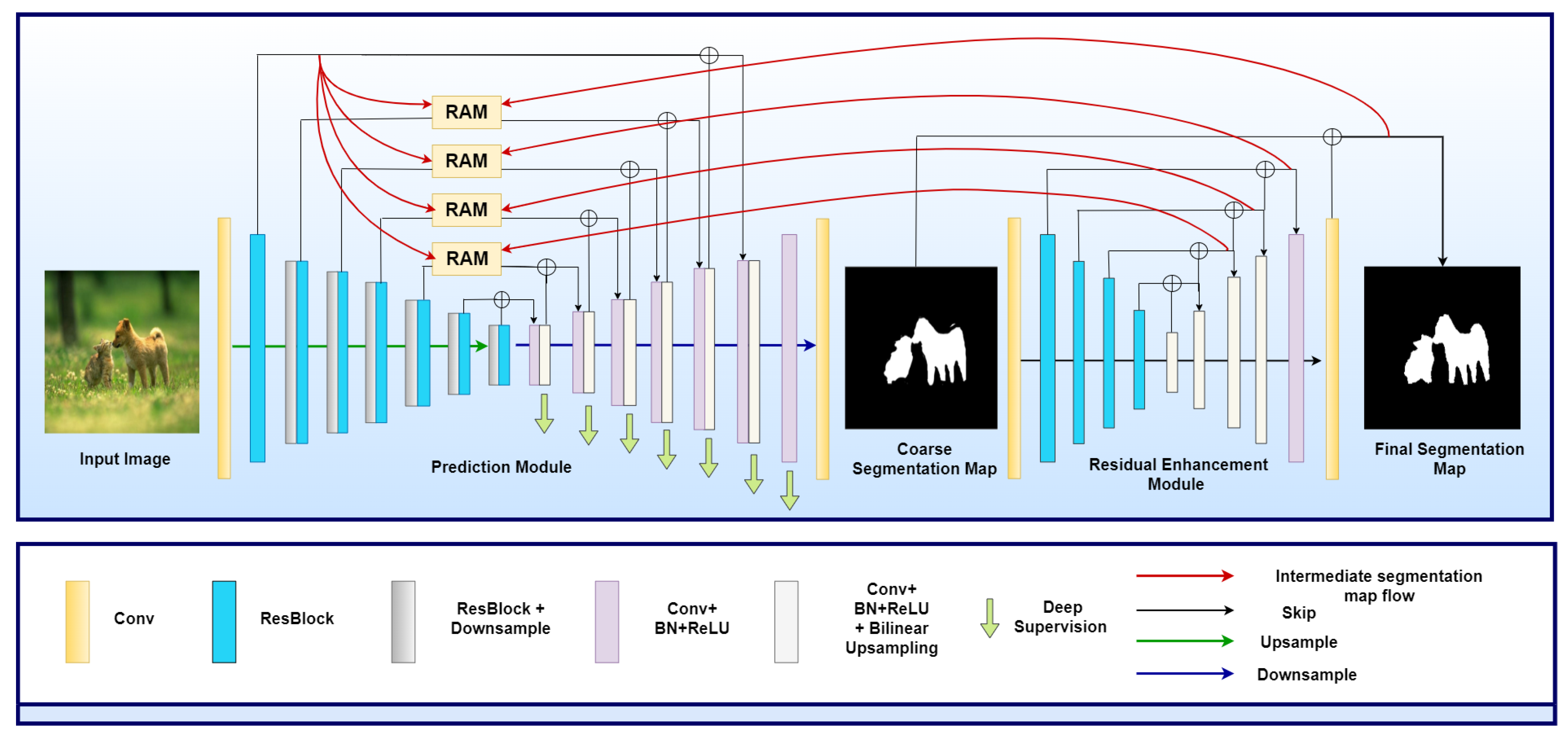
- We propose a novel encoder-decoder based architecture, called Revise-Net, that contains a principal PM for generating the initial coarse segmentation maps. These maps are then passed through the REM for utilisation of the high-level finer features, which increase the overall quality of the final segmentation output.
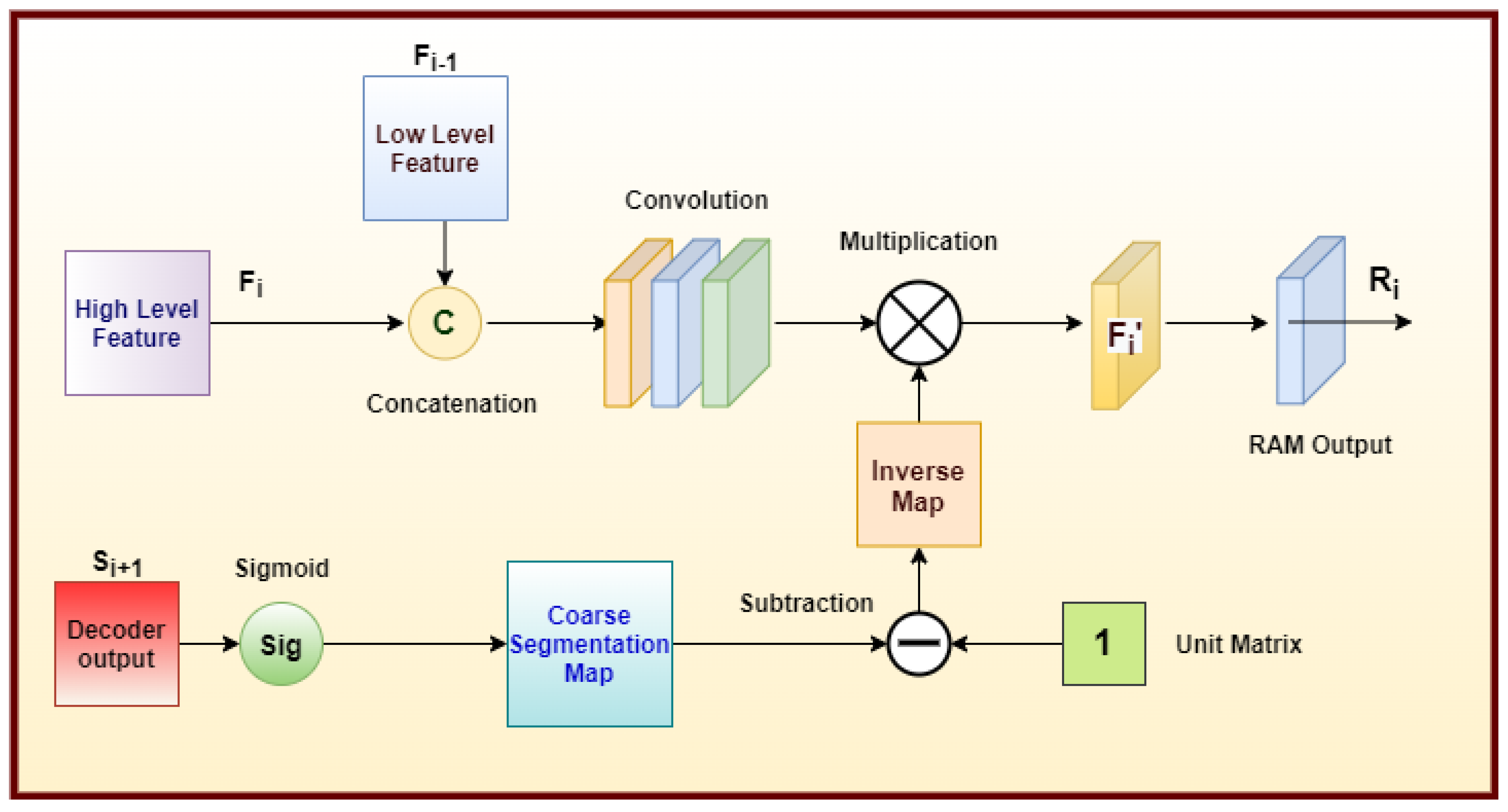
- The intermediate segmented maps generated in each decoding layer of the REM are utilized to attentively guide the PM via RAMs on multiple scales cascaded between the two networks.
- The proposed method further employs a combination of losses by fusing BCE, SSIM, and IoU for the supervision of the training process as well as for accurately predicting the segmentation map at patch, pixel, and map levels.
- The proposed Revise-Net model is thoroughly evaluated on three publicly available natural scene datasets: DUTS (DUTS-TR for train and DUTS-TE for test) [22], HKU-IS [23], and Extended Complex Scene Saliency Dataset (ECSSD) [24] for boundary-aware segmentation. The proposed framework, when compared with 10 state-of-the-art methods, outperforms those methods by a significant margin.
2. Related Work
3. Proposed Work
3.1. Prediction Module
3.2. Residual Enhancement Module
3.3. Reverse Attention
3.4. Loss Function
4. Experimental Results
- DUTS dataset [22]: This is a collection of 15,572 images intended for saliency detection. The dataset is split into the training set, DUTS-TR having 10,553 images taken from the ImageNet DET training/val sets and the test set, and DUTS-TE having 5019 images taken from the ImageNet DET test set as well as the SUN dataset. The ground-truths have been accurately generated by 50 human subjects. The dataset is the largest of the three datasets used in the study and has very challenging scenarios, which explain why the performance of the proposed model is the lowest when compared to the other datasets used to evaluate the model.
- HKU-IS dataset [23]: The HKU-IS dataset consists of 4447 images for saliency detection. The training dataset consists of 3557 images, while the test set consists of 890 images. This dataset consists of images with low contrast or multiple objects, which makes the saliency detection task on the dataset somewhat challenging.
- ECSSD dataset [24]: The extended complex scene saliency dataset (ECSSD) consists of 1000 images with their respective ground-truths, split into 900 train images and 100 test images. The images of the dataset consist of mostly complex scenes, whose textures and structures resemble those of real-world images. The ground-truth saliency maps of the dataset were prepared by five human experts.
4.1. Evaluation Metrics
- MAE: The MAE estimates the approximation degree between the saliency map and the binary ground-truth , both normalized in the range [0, 1]. As mentioned in [6], other measures do not take into consideration the true negative saliency assignments. However, the evaluation on non-salient regions can be unfair, especially for the methods that successfully detect non-salient regions but do not detect salient regions due to overlap-based evaluation. The MAE score is defined as:
- S-measure: The authors in [58] proposed a novel and easy-to-calculate measure known as structural similarity measure or S to evaluate the non-binary foreground maps. The S-measure combines the region-aware () and object-aware () structural similarity as their final structure metric:where . We have experimentally set = 0.5 in our implementation.
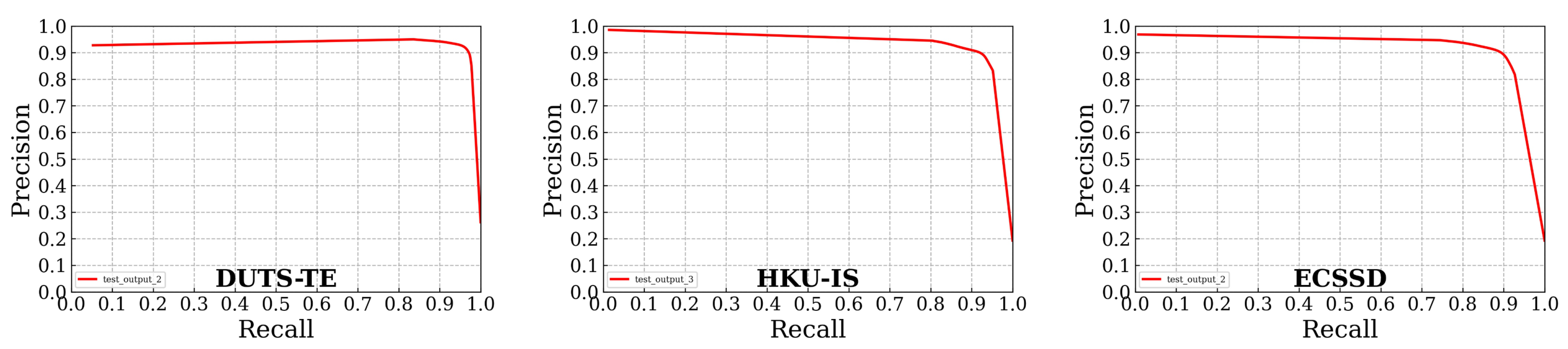
4.2. Quantitative Results
4.3. Comparison with State-of-the-Art
4.3.1. Comparison over DUTS-TE Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | DUTS-TE | HKU-IS | ECSSD | ||||||
|---|---|---|---|---|---|---|---|---|---|
| F | MAE | S | F | MAE | S | F | MAE | S | |
| AFNet [61] | 0.862 | 0.046 | 0.866 | 0.923 | 0.036 | 0.905 | 0.935 | 0.042 | 0.914 |
| CapSal [44] | 0.789 | 0.044 | - | 0.878 | 0.039 | - | - | - | - |
| CPD-R [62] | 0.865 | 0.043 | - | 0.925 | 0.034 | - | 0.939 | 0.037 | - |
| DSS [63] | - | - | - | 0.920 | 0.035 | - | 0.928 | 0.048 | - |
| MLMS [64] | 0.802 | 0.045 | 0.856 | 0.893 | 0.034 | 0.901 | 0.914 | 0.038 | 0.911 |
| MSWS [65] | - | - | - | - | - | - | 0.878 | 0.096 | - |
| PoolNet [66] | 0.892 | 0.036 | - | 0.935 | 0.030 | - | 0.945 | 0.038 | - |
| U2-Net [32] | - | - | - | - | - | - | 0.943 | 0.041 | - |
| EGNet [17] | 0.893 | 0.039 | 0.875 | 0.929 | 0.034 | 0.910 | 0.943 | 0.041 | 0.918 |
| PAGE Net [67] | 0.817 | 0.047 | - | 0.920 | 0.030 | - | 0.926 | 0.035 | - |
| Revise-Net | 0.900 | 0.033 | 0.880 | 0.937 | 0.029 | 0.898 | 0.947 | 0.036 | 0.919 |
4.3.2. Comparison over HKU-IS Dataset
4.3.3. Comparison over ECSSD Dataset
4.4. Empirical Studies
4.4.1. Effectiveness of the REM
4.4.2. Effectiveness of the Reverse Attention Module
4.4.3. Effectiveness of the Combination of Losses
5. Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Treisman, A.M.; Gelade, G. A feature-integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Koch, C.; Ullman, S. Shifts in selective visual attention: Towards the underlying neural circuitry. In Matters of Intelligence; Springer: Berlin/Heidelberg, Germany, 1987; pp. 115–141. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Yuan, Z.; Sun, J.; Wang, J.; Zheng, N.; Tang, X.; Shum, H.Y. Learning to detect a salient object. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 353–367. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Medioni, G.; Nevatia, R. Segment-based stereo matching. Comput. Vision Graph. Image Process. 1985, 31, 2–18. [Google Scholar] [CrossRef]
- Ma, C.; Miao, Z.; Zhang, X.P.; Li, M. A Saliency Prior Context Model for Real-Time Object Tracking. IEEE Trans. Multimed. 2017, 19, 2415–2424. [Google Scholar] [CrossRef]
- Wang, X.; You, S.; Li, X.; Ma, H. Weakly-Supervised Semantic Segmentation by Iteratively Mining Common Object Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Sun, G.; Wang, W.; Dai, J.; Gool, L.V. Mining Cross-Image Semantics for Weakly Supervised Semantic Segmentation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Qin, X.; He, S.; Yang, X.; Dehghan, M.; Qin, Q.; Martin, J. Accurate outline extraction of individual building from very high-resolution optical images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1775–1779. [Google Scholar] [CrossRef]
- Qin, X.; He, S.; Zhang, Z.; Dehghan, M.; Jagersand, M. Bylabel: A boundary based semi-automatic image annotation tool. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1804–1813. [Google Scholar]
- Mechrez, R.; Shechtman, E.; Zelnik-Manor, L. Saliency driven image manipulation. Mach. Vis. Appl. 2019, 30, 189–202. [Google Scholar] [CrossRef] [Green Version]
- Gupta, P.; Gupta, S.; Jayagopal, A.; Pal, S.; Sinha, R. Saliency prediction for mobile user interfaces. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1529–1538. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Yin, B. Learning Uncertain Convolutional Features for Accurate Saliency Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhuge, Y.; Zeng, Y.; Lu, H. Deep Embedding Features for Salient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 27–1 February 2019; Volume 33, pp. 9340–9347. [Google Scholar] [CrossRef]
- Zhao, J.X.; Liu, J.; Fan, D.P.; Cao, Y.; Yang, J.; Cheng, M.M. EGNet:Edge Guidance Network for Salient Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P.A. R3net: Recurrent residual refinement network for saliency detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; AAAI Press: Palo Alto, CA, USA, 2018; pp. 684–690. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Zheng, T.; Li, B.; Zeng, D.; Zhou, Z. Delving into the Impact of Saliency Detector: A GeminiNet for Accurate Saliency Detection. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 347–359. [Google Scholar] [CrossRef]
- Li, X.; Yang, F.; Cheng, H.; Liu, W.; Shen, D. Contour knowledge transfer for salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 355–370. [Google Scholar] [CrossRef]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to Detect Salient Objects with Image-Level Supervision. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3796–3805. [Google Scholar] [CrossRef]
- Li, G.; Yu, Y. Deep contrast learning for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 478–487. [Google Scholar] [CrossRef] [Green Version]
- Tran, R.; Patrick, D.; Geyer, M.; Fernandez, A. SAD: Saliency-based Defenses Against Adversarial Examples. arXiv 2020, arXiv:2003.04820. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency Detection via Graph-Based Manifold Ranking. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar] [CrossRef]
- Srivatsa, R.S.; Babu, R.V. Salient Object Detection via Objectness Measure. In Proceedings of the 2015 IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar]
- Zhu, W.; Liang, S.; Wei, Y.; Sun, J. Saliency Optimization from Robust Background Detection. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2814–2821. [Google Scholar] [CrossRef] [Green Version]
- Hu, X.; Zhu, L.; Qin, J.; Fu, C.W.; Heng, P.A. Recurrently Aggregating Deep Features for Salient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; AAAI: Palo Alto, CA, USA, 2018. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.H. PiCANet: Learning Pixel-Wise Contextual Attention for Saliency Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3089–3098. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Wang, L.; Lu, H.; Zhang, P.; Ruan, X. Salient Object Detection with Recurrent Fully Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1734–1746. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Han, L.; Li, X.; Dong, Y. Convolutional edge constraint-based U-net for salient object detection. IEEE Access 2019, 7, 48890–48900. [Google Scholar] [CrossRef]
- Yu, S.; Zhang, B.; Xiao, J.; Lim, E.G. Structure-consistent weakly supervised salient object detection with local saliency coherence. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Online, 2–9 February 2021; AAAI: Palo Alto, CA, USA, 2021. [Google Scholar]
- Zhang, J.; Xie, J.; Barnes, N. Learning noise-aware encoder-decoder from noisy labels by alternating back-propagation for saliency detection. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 349–366. [Google Scholar]
- Fu, K.; Zhao, Q.; Gu, I.Y.H.; Yang, J. Deepside: A general deep framework for salient object detection. Neurocomputing 2019, 356, 69–82. [Google Scholar] [CrossRef]
- Wang, N.; Gong, X. Adaptive fusion for RGB-D salient object detection. IEEE Access 2019, 7, 55277–55284. [Google Scholar] [CrossRef]
- Liu, Z.; Shi, S.; Duan, Q.; Zhang, W.; Zhao, P. Salient object detection for RGB-D image by single stream recurrent convolution neural network. Neurocomputing 2019, 363, 46–57. [Google Scholar] [CrossRef]
- Chen, Z.; Xu, Q.; Cong, R.; Huang, Q. Global context-aware progressive aggregation network for salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI: Palo Alto, CA, USA, 2020; Volume 34, pp. 10599–10606. [Google Scholar]
- Wei, J.; Wang, S.; Huang, Q. F3Net: Fusion, Feedback and Focus for Salient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI: Palo Alto, CA, USA, 2020; Volume 34, pp. 12321–12328. [Google Scholar]
- Kousik, N.; Natarajan, Y.; Arshath Raja, R.; Kallam, S.; Patan, R.; Gandomi, A.H. Improved salient object detection using hybrid Convolution Recurrent Neural Network. Expert Syst. Appl. 2021, 166, 114064. [Google Scholar] [CrossRef]
- Liu, Y.; Cheng, M.M.; Zhang, X.Y.; Nie, G.Y.; Wang, M. DNA: Deeply Supervised Nonlinear Aggregation for Salient Object Detection. IEEE Trans. Cybern. 2021, 1–12. [Google Scholar] [CrossRef]
- Mohammadi, S.; Noori, M.; Bahri, A.; Majelan, S.G.; Havaei, M. CAGNet: Content-aware guidance for salient object detection. Pattern Recognit. 2020, 103, 107303. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, J.; Lin, Z.; Lu, H.; He, Y. CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Kong, Y.; Feng, M.; Li, X.; Lu, H.; Liu, X.; Yin, B. Spatial context-aware network for salient object detection. Pattern Recognit. 2021, 114, 107867. [Google Scholar] [CrossRef]
- Zhao, X.; Pang, Y.; Zhang, L.; Lu, H.; Zhang, L. Suppress and Balance: A Simple Gated Network for Salient Object Detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Islam, M.A.; Kalash, M.; Rochan, M.; Bruce, N.D.; Wang, Y. Salient Object Detection using a Context-Aware Refinement Network. In Proceedings of the British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahman, M.A.; Wang, Y. Optimizing intersection-over-union in deep neural networks for image segmentation. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 12–14 December 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 234–244. [Google Scholar]
- Máttyus, G.; Luo, W.; Urtasun, R. Deeproadmapper: Extracting road topology from aerial images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3438–3446. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. Sun database: Large-scale scene recognition from abbey to zoo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar]
- Yan, Q.; Xu, L.; Shi, J.; Jia, J. Hierarchical Saliency Detection. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1155–1162. [Google Scholar] [CrossRef] [Green Version]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A New Way to Evaluate Foreground Maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, G.; Yu, Y. Visual Saliency Based on Multiscale Deep Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Shi, J.; Yan, Q.; Xu, L.; Jia, J. Hierarchical Saliency Detection on Extended CSSD. arXiv 2015, arXiv:1408.5418. [Google Scholar] [CrossRef] [PubMed]
- Feng, M.; Lu, H.; Ding, E. Attentive Feedback Network for Boundary-aware Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Wu, Z.; Su, L.; Huang, Q. Cascaded Partial Decoder for Fast and Accurate Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H.S. Deeply Supervised Salient Object Detection with Short Connections. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 815–828. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, R.; Feng, M.; Guan, W.; Wang, D.; Lu, H.; Ding, E. A Mutual Learning Method for Salient Object Detection With Intertwined Multi-Supervision. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8142–8151. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhuge, Y.; Lu, H.; Zhang, L.; Qian, M.; Yu, Y. Multi-source weak supervision for saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A Simple Pooling-Based Design for Real-Time Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Zhao, S.; Shen, J.; Hoi, S.C.; Borji, A. Salient object detection with pyramid attention and salient edges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1448–1457. [Google Scholar] [CrossRef]





| Ablation | Arrangement | F-Measure | MAE |
|---|---|---|---|
| Architecture (Using BCE Loss) | U-Net | 0.896 | 0.066 |
| En-De | 0.929 | 0.047 | |
| En-De + Sup | 0.934 | 0.040 | |
| En-RA-De + Sup | 0.938 | 0.039 | |
| En-De + Sup + REM | 0.937 | 0.042 | |
| En-RA-De + Sup + REM (Proposed) | 0.940 | 0.041 | |
| Objective function | SSIM Loss | 0.924 | 0.042 |
| IOU Loss | 0.933 | 0.039 | |
| BCE + SSIM Loss | 0.940 | 0.040 | |
| BCE + IOU Loss | 0.940 | 0.038 | |
| BCE + SSIM + IOU Loss (Proposed) | 0.947 | 0.036 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hussain, R.; Karbhari, Y.; Ijaz, M.F.; Woźniak, M.; Singh, P.K.; Sarkar, R. Revise-Net: Exploiting Reverse Attention Mechanism for Salient Object Detection. Remote Sens. 2021, 13, 4941. https://doi.org/10.3390/rs13234941
Hussain R, Karbhari Y, Ijaz MF, Woźniak M, Singh PK, Sarkar R. Revise-Net: Exploiting Reverse Attention Mechanism for Salient Object Detection. Remote Sensing. 2021; 13(23):4941. https://doi.org/10.3390/rs13234941
Chicago/Turabian StyleHussain, Rukhshanda, Yash Karbhari, Muhammad Fazal Ijaz, Marcin Woźniak, Pawan Kumar Singh, and Ram Sarkar. 2021. "Revise-Net: Exploiting Reverse Attention Mechanism for Salient Object Detection" Remote Sensing 13, no. 23: 4941. https://doi.org/10.3390/rs13234941
APA StyleHussain, R., Karbhari, Y., Ijaz, M. F., Woźniak, M., Singh, P. K., & Sarkar, R. (2021). Revise-Net: Exploiting Reverse Attention Mechanism for Salient Object Detection. Remote Sensing, 13(23), 4941. https://doi.org/10.3390/rs13234941