
Machine Learning Classification of Endangered Tree Species in a Tropical Submontane Forest Using WorldView-2 Multispectral Satellite Imagery and Imbalanced Dataset



Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Acquisition and Pre-Processing of WorldView-2 Satellite Data
2.3. Field Data Collection
2.4. Spectral Separability
2.5. Training of Random Forest and Support Vector Machine Classifiers
2.6. Class Imbalance
2.7. Measures of Model Performance
3. Results
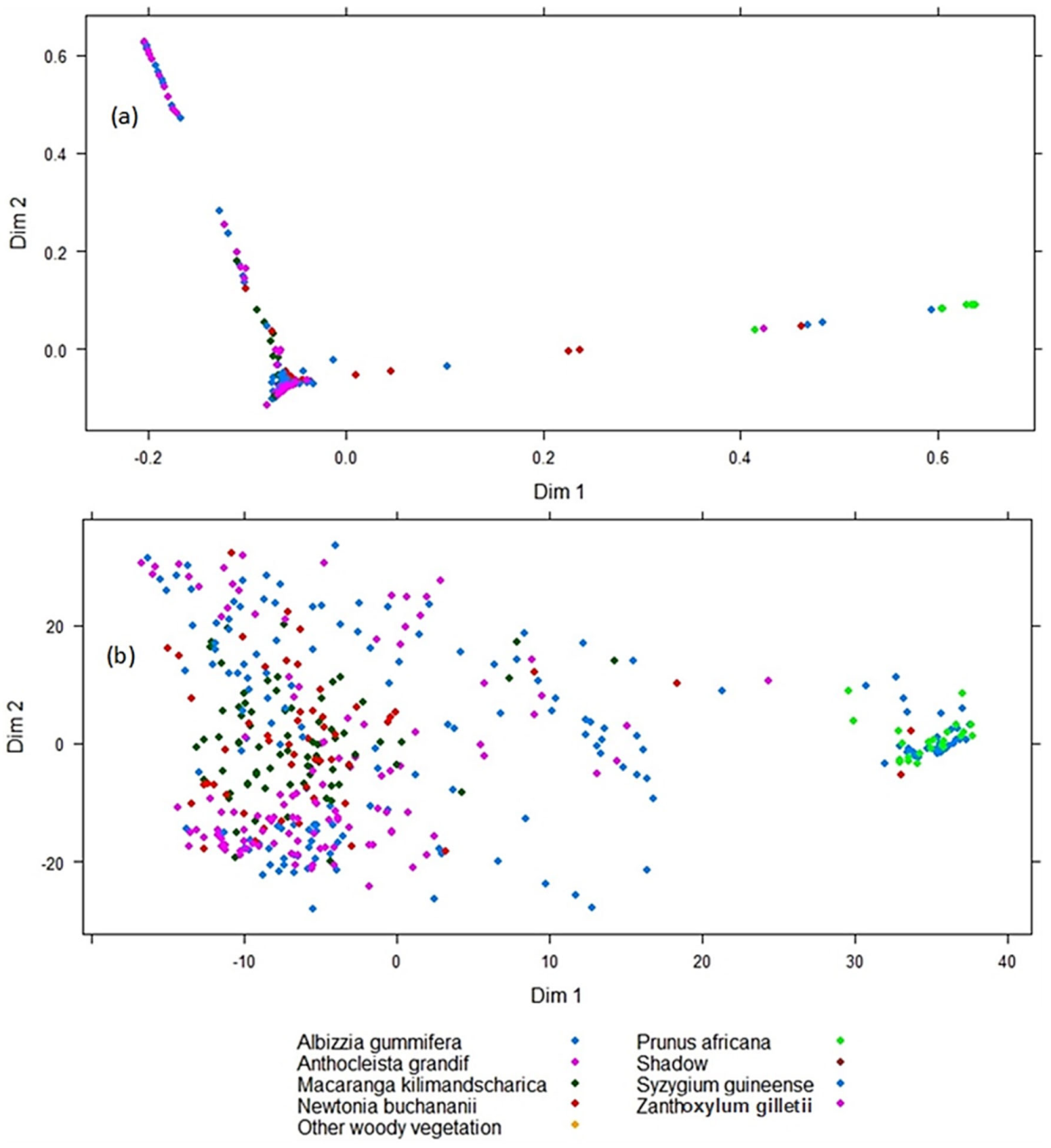
3.1. Spectral Separability between the Tree Species
3.2. Optimization of Random Forest and Support Vector Machine
3.3. Relative Importance of Variables
3.4. Model Performance
3.5. The Spatial Distribution of the Endangered Tree Species
4. Discussion
4.1. Spectral Separability between the Tree Species
4.2. Relative Importance of Variables
4.3. Class Imbalance
4.4. Model Performance
4.5. The Spatial Distribution of Endangered Tree Species
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Solberg, R.; Malnes, E.; Amlien, J.; Danks, F.; Haarpaintner, J.; Høgda, K.-A.; Johansen, B.E.; Karlsen, S.R.; Koren, H. State of the art for tropical forest monitoring by remote sensing. In A Review Carried out for the Ministry for the Environment of Norway and the Norwegian Space Centre; Norwegian Computing Centre: Oslo, Norway, 2008; pp. 1–76. [Google Scholar]
- Slik, J.W.F.; Arroyo-Rodrguez, V.; Aiba, S.-I.; Alvarez-Loayza, P.; Alves, L.F.; Ashton, P.; Balvanera, P.; Bastian, M.L.; Bellingham, P.J.; van den Berg, E.; et al. An estimate of the number of tropical tree species. Proc. Natl. Acad. Sci. USA 2015, 112, 7472–7477. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wagner, F.H.; Ferreira, M.P.; Sanchez, A.; Hirye, M.C.M.; Zortea, M.; Gloor, E.; Phillips, O.L.; Filho, C.R.S.; Shimabukuro, Y.E.; Aragão, L.E.O.C. Individual tree crown delineation in a highly diverse tropical forest using very high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2018, 145 Pt B, 362–377. [Google Scholar] [CrossRef]
- Ferreira, M.P.; Wagner, F.H.; Aragão, L.E.O.C.; Shimabukuro, Y.E.; de Souza Filho, C.R.S. Tree species classification in tropical forests using visible to shortwave infrared WorldView-3 images and texture analysis. ISPRS J. Photogramm. Remote Sens. 2019, 149, 119–131. [Google Scholar] [CrossRef]
- Immitzer, M.; Atzberger, C.; Koukal, T. Tree species classification with random forest using very high spatial resolution 8-band WorldView-2 satellite data. Remote Sens. 2012, 4, 2661–2693. [Google Scholar] [CrossRef] [Green Version]
- Nagendra, H.; Rocchini, D. High resolution satellite imagery for tropical biodiversity studies: The devil is in the detail. Biodiv. Conserv. 2008, 17, 3431–3442. [Google Scholar] [CrossRef]
- Clark, M.L.; Roberts, D.A.; Clark, D.B. Hyperspectral discrimination of tropical rain forest tree species at leaf to crown scales. Remote Sens. Environ. 2005, 96, 375–398. [Google Scholar] [CrossRef]
- Zhang, J.; Rivard, B.; Sánchez-Azofeifa, A.; Castro-Esau, K. Intra- and inter-class spectral variability of tropical tree species at La Selva, Costa Rica: Implications for species identification using HYDICE imagery. Remote Sens. Environ. 2006, 105, 129–141. [Google Scholar] [CrossRef]
- Trichon, V.; Julien, M.-P. Tree species identification on large-scale aerial photographs in a tropical rain forest, French Guiana-application for management and conservation. For. Ecol. Manag. 2006, 225, 51–61. [Google Scholar] [CrossRef] [Green Version]
- Somers, B.; Asner, G.P. Hyperspectral time series analysis of native and invasive species in Hawaiian rainforests. Remote Sens. 2012, 4, 2510–2529. [Google Scholar] [CrossRef] [Green Version]
- Féret, J.-B.; Asner, G.P. Semi-supervised methods to identify individual crowns of lowland tropical canopy species using imaging spectroscopy and LiDAR. Remote Sens. 2012, 4, 2457–2476. [Google Scholar] [CrossRef] [Green Version]
- Clark, M.L.; Roberts, D.A.; Clark, D.B. Species-Level Differences in Hyperspectral Metrics among Tropical Rainforest Trees as Determined by a Tree-Based Classifier. Remote Sens. 2012, 4, 1820–1855. [Google Scholar] [CrossRef] [Green Version]
- Papeş, M.; Tupayachi, R.; Martínez, P.; Peterson, A.T.; Asner, G.P.; Powell, G.V.N. Seasonal variation in spectral signatures of five genera of rainforest trees. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013; 6, 339–350. [Google Scholar] [CrossRef]
- Feret, J.B.; Asner, G.P. Tree species discrimination in tropical forests using airborne imaging spectroscopy. IEEE Trans. Geosci. Remote Sens. 2013, 51, 73–84. [Google Scholar] [CrossRef]
- Singh, M.; Evans, D.; Tan, B.S.; Nin, C.S. Mapping and Characterizing Selected Canopy Tree Species at the Angkor World Heritage Site in Cambodia Using Aerial Data. PLoS ONE 2015, 10, e0121558. [Google Scholar] [CrossRef]
- Baldeck, C.A.; Asner, G.P.; Martin, R.E.; Anderson, C.B.; Knapp, D.E.; Kellner, J.R.; Wright, S.J. Operational tree species mapping in a diverse tropical forest with airborne imaging spectroscopy. PLoS ONE 2015, 10, e0118403. [Google Scholar] [CrossRef]
- Ferreira, M.P.; Zortea, M.; Zanotta, D.C.; Shimabukuro, Y.E.; de Souza Filho, C.R. Mapping tree species in tropical seasonal semi-deciduous forests with hyperspectral and multispectral data. Remote Sens. Environ. 2016, 179, 66–78. [Google Scholar] [CrossRef]
- Graves, S.J.; Asner, G.P.; Martin, R.E.; Anderson, C.B.; Colgan, M.S.; Kalantari, L.; Bohlman, S.A. Tree species abundance predictions in a tropical agricultural landscape with a supervised classification model and imbalanced data. Remote Sens. 2016, 8, 161. [Google Scholar] [CrossRef] [Green Version]
- Mutanga, O.; Adam, E.; Cho, M.A. High density biomass estimation for wetland vegetation using WorldView-2 imagery and random forest regression algorithm. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 399–406. [Google Scholar] [CrossRef]
- NEMA (National Environment Management Authority). Kenya State of the Environment and Outlook 2010; Supporting the Delivery of Vision 2030. Available online: http://www.enviropulse.org/documents/Kenya_SOE.pdf (accessed on 3 January 2019).
- KWS (Kenya Wildlife Service). Mt Kenya Ecosystem Management Plan 2010–2020. Available online: http://www.kws.go.ke/file/1470/download?token=1lO6G3zI (accessed on 16 February 2019).
- Wass, P. Kenya’s Indigenous Forests: Status, Management and Conservation; IUCN: Gland, Switzerland; Cambridge, UK, 1995; 205p. [Google Scholar]
- Bussmann, R.W. Destruction and management of Mount Kenya’s forests. Ambio 1996, 25, 314–317. [Google Scholar]
- Ng’eno, J.K. Kenya. Proceedings of Country report to the FAO International Technical Conference on Plant Genetic Resources, Leipzig, Germany, 17–23 June 1996. [Google Scholar]
- KFS (Kenya Forest Service). Mt. Kenya Forest Reserve Management Plan 2010–2019. Available online: http://www.kenyaforestservice.org/documents/MtKenya.pdf (accessed on 3 January 2019).
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Bussmann, R.W. Stand structure and regeneration of the subalpine Hagenia abyssinica forest of Mt. Kenya. Bot. Act. 1997, 110, 473–480. [Google Scholar] [CrossRef]
- Baker, B.H. Geology of the Mount Kenya Area. Geol. Surv. Kenya Rep. 1967, 79, 464–465. [Google Scholar]
- Nyongesa, K.W.; Vacik, H. Evaluating management strategies for Mount Kenya Forest Reserve and National Park to reduce fire danger and address interests of various stakeholders. Forests 2019, 10, 426. [Google Scholar] [CrossRef] [Green Version]
- Ogondo, J.A. Geomorphological formation of Mount Kenya. Proceedings of Kenya National Commission for UNESCO, Stakeholders sensitization Workshop on the extension of Mt. Kenya World Heritage Site, at Sportsman’s Arm Hotel, Nanyuki, Kenya, 27–28 August 2009. [Google Scholar] [CrossRef]
- DigitalGlobe. The Benefits of the 8 Spectral Bands of WorldView-2. Available online: https://dg-cms-uploads-production.s3.amazonaws.com/uploads/document/file/35/DG-8SPECTRAL-WP_0.pdf (accessed on 2 February 2019).
- Jensen, J.R. Introductory Digital Image Processing: A Remote Sensing Perspective, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2005; pp. 210–215. [Google Scholar]
- GoK (Government of Kenya). Fifth National Report to the Conference of Parties to the Convention on Biological Diversity. Available online: https://www.cbd.int/doc/world/ke/ke-nr-05-en.pdf (accessed on 16 June 2019).
- GoK (Government of Kenya). The Wildlife Conservation and Management Act, 2013; No. 47 of 2013; GoK: Nairobi, Kenya, 2013. [Google Scholar]
- Richards, J.A.; Jia, X. Remote Sensing Digital Image Analysis: An Introduction, 3rd ed.; Springer-Verlag: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Kailath, T. The divergence and bhattacharyya distance measures in signal selection. IEEE Trans. Commun. Technol. 1967, 15, 52–60. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Machin. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V. The Nature of Statistical Learning Theory, 2nd ed.; Springer-Verlag: New York, NY, USA, 2000. [Google Scholar]
- Kuter, S. Completing the machine learning saga in fractional snow cover estimation from MODIS Terra reflectance data: Random forests versus support vector regression. Remote Sens. Environ. 2021, 255, 112294. [Google Scholar] [CrossRef]
- Chawla, N.V.; Japkowicz, N.; Kolcz, A. Editorial: Special issue on learning from imbalanced data sets. ACM SIGKDD Explor. Newsl. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Borg, I.; Groenen, P.J.F. Modern Multidimensional Scaling: Theory and Applications, 2nd ed.; Springer Science + Business Media: Berlin, Germany, 2005. [Google Scholar]
- NCSS. Chapter 435. Multidimensional Scaling. Available online: https://ncss-wpengine.netdna-ssl.com/wp-content/themes/ncss/pdf/Procedures/NCSS/Multidimensional_Scaling.pdf (accessed on 18 November 2021).
- Buja, A.; Swayne, D.F.; Littman, M.L.; Dean, N.; Hofmann, H.; Chen, L. Data Visualization with Multidimensional Scaling. J. Comput. Graph. Stat. 2007, 17, 444–472. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A. Toward intelligent training of supervised image classifications: Directing training data acquisition for SVM classification. Remote Sens. Environ. 2004, 93, 107–117. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.-L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef] [Green Version]
- Hur, J.-H.; Ihm, S.-Y.; Park, Y.-H. A variable impacts measurement in random forest for mobile cloud computing. Wirel. Commun. Mob. Comput. 2017, 2017, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Gerlach, B.; Casasent, D. Pruning support vectors for imbalanced data classification. Proceedings of International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; pp. 1883–1888. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Garcia, E.A. Learning Form Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Adam, E.; Mutanga, O.; Odindi, J.; Abdel-Rahman, E.M. Land-use/cover classification in a heterogeneous coastal landscape using RapidEye imagery: Evaluating the performance of random forest and support vector machines classifiers. Int. J. Remote Sens. 2014, 35, 3440–3458. [Google Scholar] [CrossRef]
- Janssen, L.L.F.; van der Wel, F.J.M. Accuracy assessment of satellite-derived land-cover data—A review. Photogramm. Eng. Remote Sens. 1994, 60, 419–426. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Botanical Name | Code | Family | Leaf Phenology | DBH (m) | Train Data | Test Data | Total |
|---|---|---|---|---|---|---|---|
| Macaranga k. | MK | Euphorbiaceae | Semi-deciduous | 0.30–0.57 | 56 | 24 | 80 |
| Zanthoxylum g. | ZG | Rutaceae | Semi-deciduous | 0.97–3.00 | 56 | 24 | 80 |
| Syzygium g. | SG | Myrtaceae | Evergreen | 1.00–2.50 | 56 | 24 | 80 |
| Newtonia b. | NB | Fabaceae | Deciduous | 1.50–4.50 | 56 | 24 | 80 |
| Anthocleista g. | AnG | Gentianaceae | Evergreen | 1.01–2.50 | 36 | 15 | 51 |
| Prunus a. | PA | Rosaceae | Evergreen | 1.24–3.50 | 22 | 10 | 32 |
| Albizzia g. | AlG | Fabaceae | Deciduous | 1.37–4.00 | 20 | 8 | 28 |
| Other woody vegetation | OWV | --- | --- | --- | 56 | 24 | 80 |
| Shadow | SD | --- | --- | --- | 56 | 24 | 80 |
| SG | ZG | AnG | AlG | PA | NB | MK | |
|---|---|---|---|---|---|---|---|
| SG | 1.37 | 1.21 | 1.23 | 1.27 | 1.25 | 1.16 | |
| ZG | 1.01 | 0.75 | 1.05 | 0.89 | 1.22 | ||
| AnG | 0.51 | 0.59 | 0.43 | 0.66 | |||
| AlG | 0.65 | 0.42 | 0.87 | ||||
| PA | 0.58 | 0.90 | |||||
| NB | 0.74 | ||||||
| MK |
| Model | Train Data per Species | RF | SVM | ||||
|---|---|---|---|---|---|---|---|
| mtry | ntree | OOB Error | Gamma | Cost | CV Error | ||
| Original dataset | Refer to Table 1 | 3 | 1500 | 0.377 | 0.01 | 1000 | 0.387 |
| Oversampling technique | 56 | 4 | 4500 | 0.279 | 0.01 | 1000 | 0.327 |
| Undersampling technique | 20 | 2 | 3500 | 0.476 | 0.01 | 10 | 0.422 |
| Combined technique | varied | 2 | 3500 | 0.271 | 1 | 100 | 0.326 |
| (a) Random Forest | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| AlG | AnG | MK | NB | OWV | PA | SD | SG | ZG | Total | UA (%) | |
| AlG | 4 | 1 | 1 | 3 | 0 | 0 | 1 | 0 | 0 | 10 | 40.0 |
| AnG | 0 | 9 | 4 | 1 | 2 | 2 | 0 | 0 | 0 | 18 | 50.0 |
| MK | 0 | 0 | 16 | 2 | 0 | 2 | 0 | 0 | 0 | 20 | 80.0 |
| NB | 3 | 4 | 2 | 9 | 1 | 0 | 0 | 0 | 1 | 20 | 45.0 |
| OWV | 0 | 0 | 0 | 2 | 17 | 0 | 0 | 0 | 1 | 20 | 85.0 |
| PA | 0 | 0 | 1 | 5 | 1 | 6 | 0 | 0 | 0 | 13 | 46.2 |
| SD | 0 | 0 | 0 | 0 | 0 | 0 | 23 | 0 | 0 | 23 | 100.0 |
| SG | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 23 | 0 | 23 | 100.0 |
| ZG | 1 | 1 | 0 | 2 | 3 | 0 | 0 | 1 | 22 | 30 | 73.3 |
| Total | 8 | 15 | 24 | 24 | 24 | 10 | 24 | 24 | 24 | 177 | |
| PA (%) | 50.0 | 60.0 | 66.7 | 37.5 | 70.8 | 60.0 | 90.0 | 90.0 | 80.0 | ||
| Overall accuracy = 72.9% F1-score = 68.0% | |||||||||||
| (b) Support Vector Machine algorithm | |||||||||||
| AlG | AnG | MK | NB | OWV | PA | SD | SG | ZG | Total | UA (%) | |
| AlG | 3 | 1 | 1 | 2 | 1 | 0 | 0 | 0 | 0 | 8 | 37.5 |
| AnG | 1 | 8 | 3 | 2 | 2 | 2 | 1 | 0 | 1 | 20 | 40.0 |
| MK | 0 | 0 | 15 | 3 | 0 | 2 | 1 | 0 | 0 | 21 | 71.4 |
| NB | 3 | 4 | 2 | 7 | 1 | 0 | 0 | 0 | 1 | 18 | 38.9 |
| OWV | 0 | 0 | 0 | 2 | 17 | 0 | 0 | 0 | 0 | 19 | 89.5 |
| PA | 1 | 1 | 2 | 6 | 2 | 6 | 0 | 0 | 0 | 18 | 33.3 |
| SD | 0 | 0 | 0 | 0 | 0 | 0 | 22 | 0 | 0 | 22 | 100.0 |
| SG | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 24 | 0 | 24 | 100.0 |
| ZG | 0 | 1 | 1 | 2 | 1 | 0 | 0 | 0 | 22 | 27 | 81.5 |
| Total | 8 | 15 | 24 | 24 | 24 | 10 | 24 | 24 | 24 | 177 | |
| PA (%) | 37.5 | 53.3 | 62.5 | 29.2 | 70.8 | 60.0 | 80.0 | 100.0 | 70.8 | ||
| Overall accuracy = 70.1% F1-score = 64.2% | |||||||||||
| Classifier | RF | |||
|---|---|---|---|---|
| SVM | CC | IC | Total | |
| CC | 98 | 11 | 111 | |
| IC | 16 | 52 | 66 | |
| Total | 114 | 63 | 177 | |
| Classes | RF Classified Area (ha) | Percentage (%) | SVM Classified Area (ha) | Percentage (%) |
| Macaranga kilimandscharica | 45.2 | 34.8 | 44.1 | 33.9 |
| Zanthoxylum gilletii | 7.1 | 5.5 | 7.2 | 5.6 |
| Syzygium guineense | 9.6 | 7.4 | 10.6 | 8.2 |
| Newtonia buchananii | 23.6 | 18.1 | 23.2 | 17.8 |
| Anthocleista grandiflora | 13.4 | 10.3 | 15.2 | 11.7 |
| Prunus africana | 0.0 | 0.0 | 0.0 | 0.0 |
| Albizzia gummifera | 0.0 | 0.0 | 0.0 | 0.0 |
| Other woody vegetation | 20.5 | 15.8 | 18.6 | 14.3 |
| Shadow | 10.6 | 8.1 | 11.1 | 8.5 |
| Total | 130 | 100 | 130 | 100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jackson, C.M.; Adam, E. Machine Learning Classification of Endangered Tree Species in a Tropical Submontane Forest Using WorldView-2 Multispectral Satellite Imagery and Imbalanced Dataset. Remote Sens. 2021, 13, 4970. https://doi.org/10.3390/rs13244970
Jackson CM, Adam E. Machine Learning Classification of Endangered Tree Species in a Tropical Submontane Forest Using WorldView-2 Multispectral Satellite Imagery and Imbalanced Dataset. Remote Sensing. 2021; 13(24):4970. https://doi.org/10.3390/rs13244970
Chicago/Turabian StyleJackson, Colbert M., and Elhadi Adam. 2021. "Machine Learning Classification of Endangered Tree Species in a Tropical Submontane Forest Using WorldView-2 Multispectral Satellite Imagery and Imbalanced Dataset" Remote Sensing 13, no. 24: 4970. https://doi.org/10.3390/rs13244970
APA StyleJackson, C. M., & Adam, E. (2021). Machine Learning Classification of Endangered Tree Species in a Tropical Submontane Forest Using WorldView-2 Multispectral Satellite Imagery and Imbalanced Dataset. Remote Sensing, 13(24), 4970. https://doi.org/10.3390/rs13244970