
A Lightweight Detection Model for SAR Aircraft in a Complex Environment


Abstract
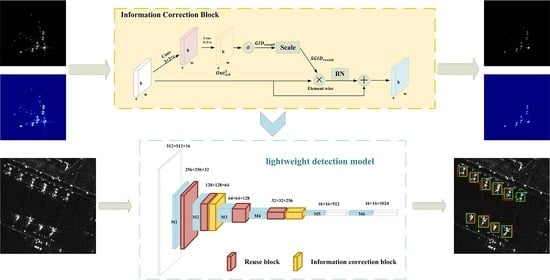
:
1. Introduction
- (1)
- We propose a lightweight detection model to detect SAR aircraft targets in complex environments, and the proposed method achieves superior detection performance far more rapidly than other CNN methods.
- (2)
- We propose an RB module to acquire more aircraft features during feature extraction by aggregating multi-layer information.
- (3)
- We propose an ICB module to enhance effective aircraft features, and suppress redundant information from the RB module and interference from the complex environment by enhancing salient points, especially gray-scale features.
2. Materials and Methods
2.1. Overall Detection Framework
2.2. Reuse Block
2.2.1. Motivation
2.2.2. The Structure of the Reuse Block
2.3. Information Correction Block
2.3.1. Motivation
2.3.2. Salient Point
2.3.3. The Structure of the Information Correction Block
2.4. Detection Section
3. Results
3.1. Experimental Details
3.1.1. Evaluation Metrics
3.1.2. Parameter Settings
3.1.3. Dataset for SAR Aircraft Detection
3.1.4. Dataset for SAR Ship Detection
3.2. Comparison with Other Methods on SAR-ADD
3.3. Additional Evaluation on SSDD
3.4. Ablation Experiment
3.5. RB Module vs. Dense Structure
3.6. ICB Module vs. Attention Methods
3.7. Visualization
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CBAM | Convolutional Block Attention Module |
| CFAR | Constant False Alarm Rate |
| CNN | Convolutional Neural Network |
| GID | Global Information Descriptor |
| GLRT | Generalized Likelihood Ratio Detection |
| GPU | Graphics Processing Unit |
| ICB | Information Correction Block |
| IoU | Insection over Union |
| LDM | Lightweight Detection Model |
| NMS | Non-Maximum Suppression |
| RB | Reuse Block |
| SAR | Synthetic Aperture Radar |
| SAR-ADD | SAR Aircraft Detection Dataset |
| SGID | Salient Global Information Descriptor |
| SSDD | SAR Ship Detection Dataset |
References
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.P. A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef] [Green Version]
- Cui, Z.; Hou, Z.; Yang, H.; Liu, N.; Cao, Z. A CFAR Target-Detection Method Based on Superpixel Statistical Modeling. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1605–1609. [Google Scholar] [CrossRef]
- Abbadi, A.; Bouhedjeur, H.; Bellabas, A.; Menni, T.; Soltani, F. Generalized Closed-Form Expressions for CFAR Detection in Heterogeneous Environment. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1011–1015. [Google Scholar] [CrossRef]
- Zhao, M.; He, J.; Fu, Q. Survey on Fast CFAR Detection Algorithms for SAR Image Targets. Acta Autom. Sin. 2012, 38, 1885–1895. [Google Scholar] [CrossRef]
- Wang, C.; Zhong, X.; Zhou, P.; Zhang, X. Man-made target detection in SAR imagery. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium, IGARSS’05, Seoul, Korea, 29 July 2005; Volume 3, pp. 1721–1724. [Google Scholar] [CrossRef]
- Jao, J.K.; Lee, C.; Ayasli, S. Coherent spatial filtering for SAR detection of stationary targets. IEEE Trans. Aerosp. Electron. Syst. 1999, 35, 614–626. [Google Scholar] [CrossRef]
- Gao, G.; Zhou, D.; Jiang, Y.; Kuang, G. Study on Target Detection in SAR Image: A Survey. Signal Processing. 2008, 24, 971–981. [Google Scholar]
- Li, J.; Zelnio, E. Target detection with synthetic aperture radar. IEEE Trans. Aerosp. Electron. Syst. 1996, 32, 613–627. [Google Scholar] [CrossRef]
- Novak, L.; Owirka, G.; Weaver, A. Automatic target recognition using enhanced resolution SAR data. IEEE Trans. Aerosp. Electron. Syst. 1999, 35, 157–175. [Google Scholar] [CrossRef]
- Ghaderpour, E.; Pagiatakis, S.D.; Hassan, Q.K. A Survey on Change Detection and Time Series Analysis with Applications. Appl. Sci. 2021, 11, 6141. [Google Scholar] [CrossRef]
- Huang, S.; Zhao, W.; Luo, P. Target Detection of SAR Image Based on Wavelet and Empirical Mode Decomposition. In Proceedings of the 2019 6th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Xiamen, China, 26–29 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Wei, D.; Du, Y.; Du, L.; Li, L. Target Detection Network for SAR Images Based on Semi-Supervised Learning and Attention Mechanism. Remote Sens. 2021, 13, 2686. [Google Scholar] [CrossRef]
- Gong, M.; Yang, H.; Zhang, P. Feature learning and change feature classification based on deep learning for ternary change detection in SAR images. ISPRS J. Photogramm. Remote Sens. 2017, 129, 212–225. [Google Scholar] [CrossRef]
- He, X.; Tong, N.; Hu, X. Automatic recognition of ISAR images based on deep learning. In Proceedings of the 2016 CIE International Conference on Radar (RADAR), Guangzhou, China, 10–13 October 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Wang, S.; Gao, X.; Sun, H.; Zheng, X.; Sun, X. An Aircraft Detection Method Based on Convolutional Neural Networks in High-Resolution SAR Images. J. Radars 2017, 6, 195–203. [Google Scholar] [CrossRef]
- He, C.; Tu, M.; Xiong, D.; Tu, F.; Liao, M. A Component-Based Multi-Layer Parallel Network for Airplane Detection in SAR Imagery. Remote Sens. 2018, 10, 1016. [Google Scholar] [CrossRef] [Green Version]
- An, Q.; Pan, Z.; Liu, L.; You, H. DRBox-v2: An Improved Detector With Rotatable Boxes for Target Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8333–8349. [Google Scholar] [CrossRef]
- Luo, R.; Chen, L.; Xing, J.; Yuan, Z.; Tan, S.; Cai, X.; Wang, J. A Fast Aircraft Detection Method for SAR Images Based on Efficient Bidirectional Path Aggregated Attention Network. Remote Sens. 2021, 13, 2940. [Google Scholar] [CrossRef]
- Zhang, L.; Li, C.; Zhao, L.; Xiong, B.; Quan, S.; Kuang, G. A cascaded three-look network for aircraft detection in SAR images. Remote Sens. Lett. 2020, 11, 57–65. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Kuang, G. Fast detection of aircrafts in complex large-scene SAR images. Chin. J. Radio Sci. 2020, 35, 594–602. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, H.; Xu, F. Scattering Enhanced Attention Pyramid Network for Aircraft Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7570–7587. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Zhao, Y.; Zhao, L.; Li, C.; Kuang, G. Pyramid Attention Dilated Network for Aircraft Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 662–666. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, J.; Xiao, H.; Chen, L.; Xing, J.; Pan, Z.; Luo, R.; Cai, X. Integrating Weighted Feature Fusion and the Spatial Attention Module with Convolutional Neural Networks for Automatic Aircraft Detection from SAR Images. Remote Sens. 2021, 13, 910. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Chen, J.; Zhang, B.; Wang, C. Backscattering Feature Analysis and Recognition of Civilian Aircraft in TerraSAR-X Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 796–800. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Zhang, Q. System Design and Key Technologies of the GF-3 Satellite. Acta Geod. Cartogr. Sin. 2017, 46, 269–277. [Google Scholar] [CrossRef]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Theagarajan, R.; Bhanu, B.; Erpek, T.; Hue, Y.K.; Schwieterman, R.; Davaslioglu, K.; Shi, Y.; Sagduyu, Y.E. Integrating deep learning-based data driven and model-based approaches for inverse synthetic aperture radar target recognition. Opt. Eng. 2020, 59, 051407. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| k-Fold | 1 | 2 | 3 | 4 | 5 | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | t/ms | AP | t/ms | AP | t/ms | AP | t/ms | AP | t/ms | AP | t/ms | |
| Faster R-CNN [16] | 0.592 | 34.7 | 0.59 | 34.7 | 0.659 | 34.1 | 0.679 | 35.6 | 0.801 | 33.4 | 0.6642 | 34.5 |
| Cascade R-CNN [17] | 0.561 | 45.7 | 0.602 | 45.6 | 0.655 | 43.1 | 0.635 | 45.1 | 0.736 | 42.6 | 0.6378 | 44.42 |
| SSD [15] | 0.637 | 40.3 | 0.711 | 40.2 | 0.688 | 38.8 | 0.706 | 37.9 | 0.775 | 38.3 | 0.7034 | 39.1 |
| RetinaNet [39] | 0.596 | 33.1 | 0.665 | 33.2 | 0.644 | 33.2 | 0.671 | 35.6 | 0.752 | 32.4 | 0.6656 | 33.5 |
| Yolov3 [14] | 0.592 | 13.8 | 0.637 | 13.9 | 0.719 | 13.7 | 0.641 | 13.2 | 0.713 | 14.1 | 0.6604 | 13.74 |
| LDM | 0.618 | 6.4 | 0.669 | 6.6 | 0.718 | 6.4 | 0.675 | 6.2 | 0.797 | 6.3 | 0.6954 | 6.38 |
| Methods | P | R | AP | F1 | t/ms |
|---|---|---|---|---|---|
| Faster R-CNN [16] | 0.78 | 0.957 | 0.944 | 0.859 | 51.1 |
| Cascade R-CNN [17] | 0.856 | 0.947 | 0.938 | 0.899 | 59 |
| SSD [15] | 0.875 | 0.944 | 0.914 | 0.908 | 28.5 |
| RetinaNet [39] | 0.558 | 0.946 | 0.922 | 0.701 | 48.2 |
| Yolov3 [14] | 0.752 | 0.899 | 0.858 | 0.819 | 11.5 |
| LDM | 0.822 | 0.925 | 0.904 | 0.87 | 5.2 |
| Methods | P | R | AP | F1 | t/ms |
|---|---|---|---|---|---|
| baseline | 0.711 | 0.798 | 0.732 | 0.752 | 3.3 |
| +RB | 0.734 | 0.825 | 0.762 | 0.777 | 5.8 |
| +ICB | 0.723 | 0.825 | 0.773 | 0.77 | 4 |
| LDM | 0.819 | 0.833 | 0.797 | 0.826 | 6.3 |
| Methods | P | R | AP | F1 | t/ms |
|---|---|---|---|---|---|
| tiny | 0.711 | 0.798 | 0.732 | 0.752 | 3.3 |
| +Dens [32] | 0.796 | 0.789 | 0.738 | 0.793 | 6.4 |
| +RB | 0.734 | 0.825 | 0.762 | 0.777 | 5.8 |
| LDM(+Dens) | 0.823 | 0.816 | 0.782 | 0.819 | 7.1 |
| LDM | 0.819 | 0.833 | 0.797 | 0.826 | 6.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Wen, G.; Huang, X.; Li, K.; Lin, S. A Lightweight Detection Model for SAR Aircraft in a Complex Environment. Remote Sens. 2021, 13, 5020. https://doi.org/10.3390/rs13245020
Li M, Wen G, Huang X, Li K, Lin S. A Lightweight Detection Model for SAR Aircraft in a Complex Environment. Remote Sensing. 2021; 13(24):5020. https://doi.org/10.3390/rs13245020
Chicago/Turabian StyleLi, Mingwu, Gongjian Wen, Xiaohong Huang, Kunhong Li, and Sizhe Lin. 2021. "A Lightweight Detection Model for SAR Aircraft in a Complex Environment" Remote Sensing 13, no. 24: 5020. https://doi.org/10.3390/rs13245020
APA StyleLi, M., Wen, G., Huang, X., Li, K., & Lin, S. (2021). A Lightweight Detection Model for SAR Aircraft in a Complex Environment. Remote Sensing, 13(24), 5020. https://doi.org/10.3390/rs13245020