1. Introduction
Land cover classification (LCC) [
1,
2] is one of the most popular topics in the remote sensing community. With the enhancement of the spatial resolution of remote sensing imagery, fine LCC (FLCC) [
3,
4,
5,
6,
7] of complex landscapes has attracted increasing attention because of the need to improve accuracy. Owing to the complex features of three-dimensional terrain, FLCC of complex surface-mined areas (CSMAs) is challenging and of great importance for mine development.
The solution of FLCC applied to CSMAs involves the use of multimodal data for feature learning and advanced algorithms for classification [
8,
9]. Firstly, feature engineering coupled with machine learning algorithms (MLAs) is effective. Feature engineering mainly includes hand-crafted feature calculation, feature selection (FS), and feature extraction (i.e., feature reduction). FS uses an algorithm to choose a representative feature combination. Feature extraction uses algorithms [
10] to extract a combination of new features. For example, Azeez et al. [
11] used support vector machine (SVM), decision tree (DT), and random forest (RF) algorithms for LCC of a regional agricultural area. Our previous studies have used this scheme. For example, Li et al. [
12] proposed a fine classification framework for three surface-mined land cover classes using multimodal spatial, spectral, and topographic features from ZiYuan-3 (ZY-3) imagery. Additionally, an FS method and RF, SVM, and artificial neural network (ANN) algorithms were used. For FLCC of CSMAs, Chen et al. [
13] assessed the importance of feature sets based on an FS method; Chen et al. [
14] utilized multiple features derived from WorldView-3 imagery and some optimized SVM models. In addition, Chen et al. [
8] conducted a review of FLCC in CSMAs using remote sensing data. The shortcoming of each of the above-mentioned methods was that the feature sets derived by feature engineering were insufficient for representation.
Deep learning (DL) algorithms have been widely used in computer vision and remote sensing fields because they can learn informative high-level features. As a result, some researchers have examined many DL algorithm-based schemes for LCC and FLCC. For example, Lv et al. [
15] used a deep belief network (DBN)-based method for LCC. Li et al. [
16] utilized a stacked autoencoder (SAE) method for LCC, while Tong et al. [
17] proposed a transferable convolutional neural network (CNN) model for LCC. For FLCC of CSMAs, Li et al. [
9] proposed a multimodal and multimodel deep fusion strategy based on ZY-3 imagery, the DBN algorithm, and two MLAs (i.e., RF and SVM). Li et al. [
18] proposed a novel multi-level, output-based DBN. Compared to SAE and DBN, CNN has stronger representation ability due to the consideration of spatial neighborhood information, which has seldom been examined for FLCC.
In addition to directly using DL algorithms, some researchers have explored multistream CNNs based on multiple inputs. For example, Liu et al. [
19] applied a triplet CNN for remote sensing scene classification. Others were based on multimodal data such as hyperspectral image (HSI) and light detection and ranging (LiDAR) data. For example, Li et al. [
20] proposed a three-stream CNN model based on the spectral and spatial features of HSI and the topographic features of LiDAR data. Xu et al. [
21] developed a two-branch CNN based on HSI and LiDAR data. Moreover, a two-tunnel CNN framework was first used to extract deep spectral-spatial features of HSI. Chen et al. [
22] proposed a similar two-stream CNN based on HSI and LiDAR data. Chen et al. [
23] utilized multispectral (MS) image/HSI and LiDAR to form a two-stream CNN. Jahan et al. [
24] proposed a three-stream CNN using HSI and LiDAR data with a feature-reduction technique for LCC. Lastly, Rasti et al. [
25] proposed a three-stream CNN using HSI and LiDAR data for LCC. Moreover, different band combinations that have been used as inputs of the DL algorithms have been considered worthy of investigation [
26,
27]. It has been suggested that the fusion methods for panchromatic (PAN) and MS images might affect the classification results [
28,
29,
30].
Some researchers have focused on extracting multiscale features. For example, Zhang et al. [
31] proposed a multiscale and multifeature-based CNN for LCC. Zhang et al. [
32] proposed a multiscale dense network for LCC. They stated that the models with multi-scale features effectively improved classification accuracy.
Four influencing factors were pertinent to land cover classification over the study area: (1) Sample acquisition cost is high, as a result, a small sample classification situation was necessary; (2) There were complex features of the three-dimensional terrain, as a result topographic data was needed. How to effectively mine the multimodal multispectral image and topographic data was, therefore, an issue; (3) The topographic data were of lower spatial resolution than the multispectral images. This raised the question of how to fuse them; (4) The ground objects were at different scales. This raised the question of how to represent them.
Considering these influencing factors, the pipeline design was based on certain prior knowledge, reducing the need for sample data, as follows: (1) True color and false color images have different and complementary feature representation capabilities and can essentially replace multispectral data with four bands. Compared with using multi-spectral data as input, the spectral band combination method can reduce the demand for sample data; (2) The use of multi-branch extraction and post-fusion methods can avoid the interactions of different modal data due to different numerical units, meanings, and magnitudes, and theoretically is more conducive to the extraction of multimodal deep features; (3) Using multisize neighbors as inputs for data with different spatial resolutions can fully express the spatial relationship among different land covers; (4) In view of the multiscale characteristics of the ground objects, a multiscale convolution module was designed to ensure that the algorithms had multiscale feature extraction capabilities.
In this study, a novel multimodal remote data sensing, and multiscale kernel-based multistream CNN (3M-CNN), model was proposed for FLCC of CSMAs. The 3M-CNN model was tested using two ZY-3 imageries. The contributions to development of the approach were as follows:
- (1)
We proposed a multimodal data-based multistream CNN model, which can extract multiple features from true color and false color images, and a digital elevation model (DEM) data that is derived from ZY-3 imagery.
- (2)
We used multisize neighbors as the inputs of the CNN, i.e., using different neighbors for optical images and DEM data.
- (3)
Multiscale convolution flows revised from the inception module were applied to optical images and DEM data, which could match different input neighbors.
5. Discussions
5.1. Effectiveness of Multimodal Data-Based Multistream CNN Structure
Figure 17 shows a diagram of the proposed scheme. When there were some land covers leading to terrain changes, topographic data were helpful for classification. At this time, the proposed model might be positive. We think this model is also suitable for other sensors, as follows: (1) When the other sensors have multi-view cameras (e.g., GaoFen-7 satellite), topographic data can be extracted directly. Then, this model is suitable; (2) When the other sensors can obtain only multispectral images, this model is also suitable because we can use some other topographic data. For example, data with lower resolution, such as advanced spaceborne thermal emission and reflection radiometer global digital elevation models, can be used, if their spatial resolution can describe the terrain changes of the study areas. Other topographic data with higher resolution can also be used, such as light detection and ranging data.
We can also replace DEM data with synthetic aperture radar (SAR), hyperspectral, and unmanned aerial vehicle (UAV) images, etc., in the proposed scheme. Then the fused models with multimodal data (e.g., multispectral and SAR images, multispectral and hyperspectral images, and multispectral and UAV images, etc.) are suitable for classification of other landscapes.
Li et al. [
9] pointed out that directly stacking and normalizing the multimodal features using DBN-based models might undermine the advantages of the topographic information. As a result, this study used a multimodal data-based multistream structure. The results showed that the proposed models outperformed single-stream models, such as the DBN-based models in [
9]. Although performance differences might be attributed partly to the utilization of different models, the results indirectly confirmed the effectiveness of a multistream structure. Other studies have also demonstrated the effectiveness of multimodal data-based multistream structures [
20,
21,
22,
23,
24,
25].
Considering that the true color and false color images had different representative ability, both were used as inputs. Li et al. [
12] found that DEM had the highest importance for LCC. Slope was important, but its significance was much lower than that of DEM. Aspect was not important and was not selected using an FS procedure. As a result, DEM was used as the input for the third CNN branch.
Using the imagery taken on 20 June 2012, an additional experiment was conducted. Based on the multimodal data of two band combinations (true color imagery, hereafter referred to as 321; false color image, hereafter referred to as 432) of MS imagery (blue, green, red, and near-infrared bands, hereafter referred to as 1, 2, 3, and 4 bands) and DEM, this study tested three models with different numbers of branches: (1) CNN
4321 DEM: a CNN model with an input of both four spectral bands and DEM data; (2) CNN
4321 + DEM: a CNN model with two inputs of four spectral bands and DEM data; (3) CNN
321 + 432 + DEM: a CNN model with three inputs of true color image, false color image, and DEM data, respectively. The OA values for these three models are shown in
Table 6; multiple branches improved the classification performances. This experiment demonstrated that using both true color and false color images as inputs was effective. Studies [
26,
27] investigated other band combinations for mapping of ice-wedges. The fusion methods for PAN and MS images might affect the classification results [
28,
29,
30]. These two issues require further consideration.
5.2. Effectiveness of Different Input Sizes for Multimodal Data
As shown in
Figure 12, different sizes of DEM data resulted in different classification accuracies. The model achieved the highest accuracy when the DEM data input size was 51 and the MS data input size was 15. This indicated that matching input sizes for different data was helpful for feature extraction and classification. Terrain fluctuations in the study area were varied. Therefore, too small an input size had too little influence on the classification accuracy due to very small elevation change. However, too large an input size contained excessive interference information. Therefore, the selection of the DEM input size was crucial.
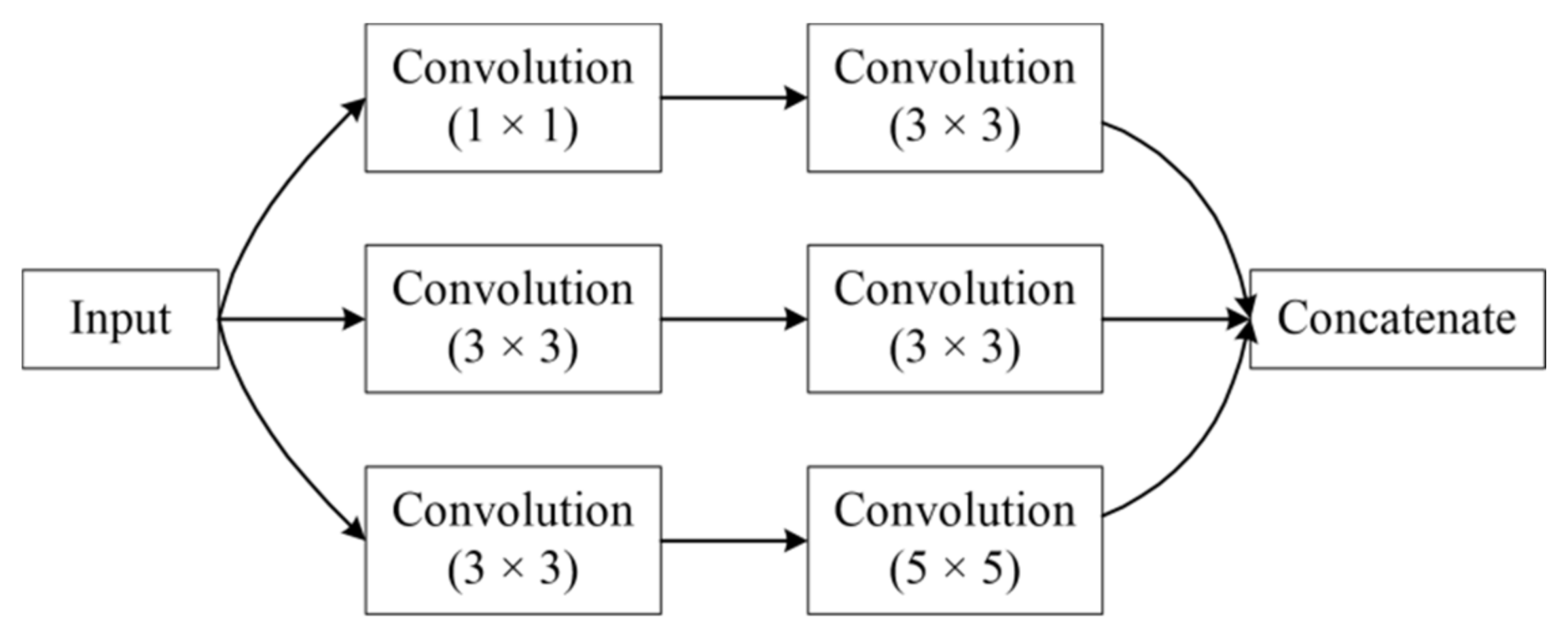
5.3. Effectiveness of Multiscale Kernel Strategy
The convolution kernel size increases directly with input size.
Figure 13 showed that different
k-value-based multiscale convolutional modules yielded different results. Moreover, the 3M-CNN-Magnify model outperformed the others. They both demonstrated that the multiscale convolution kernel contributes to classification performance.
While the 3M-CNN model was slightly inferior to the single-scale CNN model, this was due to a small multiscale kernel k-value of 1, which was unsuitable for a large input size of 51.
5.4. Comparison with Different Methods
To assess the effectiveness of the 3M-CNN-Magnify model, a series of comparison experiments were conducted. Traditional MLAs-based models, such as RF, SVM, and FS-RF, etc., and DBN-based models, were selected. As shown in
Table 4, the 3M-CNN-Magnify model achieved the highest average OA value, which was significantly higher than that of the MLAs-based OAs, and slightly higher than that of the DBN-based OAs.
The results showed that the strategy of multiscale kernels, coupled with various input sizes for different data, could contribute significantly to the extraction of the representative classification features.
Table 4 indicates that the training time of the 3M-CNN models was slightly longer than that of the MLAs- and DBN-based models. However, the time for parameter selection of some MLAs-based models was greater. For example, there were 80 groups of parameter combinations for SVM-based models. The time of parameter selection for DBN-SVM was also greater, which contained the selection of DBN’s and SVM’s parameters. Using less time, DBN-SVM yielded comparative OA with that of the 3M-CNN models. On the one hand, the coding layers based on feature vectors were much quicker than the convolution layers obtained by feature maps. On the other hand, the test accuracies were based on only a small set of samples, i.e., with 500 for each class. Therefore, the comparative test accuracies cannot reflect the true performances of the DBN-SVM and 3M-CNN models. The assessments of the predicted maps demonstrated that the 3M-CNN models were significantly better than the DBN-SVM model.
Three larger test sets were then used to further compare the model performances.
Table 7 shows the accuracy values. From
Figure 7, the following conclusions can be drawn: (1) With greater test sets, CNN-based models obtained greater accuracy values (about 3% improvement). This might be attributed to the overlap of 15 pixels × 15 pixels neighbors. However, the accuracies for those three test sets were stable, showing that the accuracy values for CNN-based models were reliable; (2) With greater test sets, DBN-based models’ accuracy values were slightly reduced; (3) With greater test sets, CNN-based models yielded about 4.7% improvement compared to DBN-based models. In the future, spatially independent test sets [
9] will be constructed for model comparison.
5.5. Parameter Selection and Effects of the Dataset
The selection of input size of DEM data and corresponding kernel size was strictly conducted. However, the tuning of the baseline was very simple. For example, the input size of spectral images was determined based on subjective experience and the size of different land covers in the study area. In the single-scale CNN models, the numbers of convolution flows and fully connected layers were determined by a trial-and-error method.
The datasets in this study were not very large, containing only 2000, 500, and 500 samples for each class in the training, validation, and test sets, respectively. Therefore, the baseline of the single-scale CNN model was not complex, which helps avoid underfitting. The small performance gains among 3M-CNN-Magnify, single-scale CNN, and DBN-SVM models, might be partly caused by the small size of the datasets and their spatial auto-correlation [
9] (see the subset area of 6 in
Figure 6), which reached precision saturation. However, the map accuracies of the whole study area were far from optimal and showed obvious differences. As a result, larger spatial independent datasets should be investigated in the future.
5.6. Investigations on Different Datasets
A lot of time is needed to label the polygons for extracting training, validation, and test sets; consequently, our former studies [
9,
12,
13,
18] relied on only one dataset, i.e., the ZY-3 imagery on 20 June 2012.
The following features contributed to the reliability of the accuracy assessment results: (1) The training, validation, and test sets containing 2000, 500, and 500 samples for each class, respectively, were spatially independent (only 12.88% pixels in the data polygons were used on average (
Table 2) [
9]; (2) There were five groups of training, validation, and test sets, and each was run 5 times; (3) The study area was very large, i.e., 104.9 km
2; (4) The classification maps were visually accurate.
However, it was considered of benefit to also investigate using other datasets (e.g., different imageries for different study areas), or ZY-3 datasets of this study at other times. As a result, the ZY-3 imagery on 11 November 2020 was further tested in this study. By directly using the model structures and hyper-parameters derived from the imagery on 20 June 2012, the imagery on 11 November 2020 yielded very high test accuracy values and accurate visual maps of LCC and FLCC. In future, imageries from different sources, geographical locations, and with varying spatial resolutions, should be further investigated to test the generalization capability of the proposed models.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}