
AVILNet: A New Pliable Network with a Novel Metric for Small-Object Segmentation and Detection in Infrared Images



Abstract
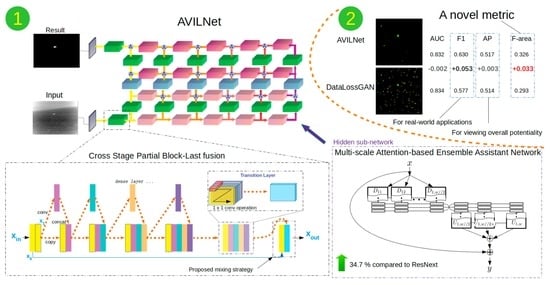
1. Introduction
2. Related Work
2.1. Deeper Network vs. Vanishing Gradient
2.2. Attention and the Receptive Field
2.3. Data-Driven Loss and Ensemble
2.4. Generative Adversarial Network
2.5. Resizing during Pre-Processing
3. The Proposed Method
3.1. Our Approach
3.2. The Amorphous Variable Inter-Located Network
3.2.1. Cross-Stage Partial Dense Block and Dense Dilation Block
3.2.2. Multi-Scale Attention-Based Ensemble Assistant Network and Feature-Highway Connections
3.2.3. Over-Parameterization
3.3. Formulation
3.4. Implementation Details
3.4.1. Generator
3.4.2. Discriminator
4. Experimental Results
4.1. Methods in Comparison
4.2. Hardware/Software Configuration
4.3. Datasets
4.4. Evaluation Metrics
4.5. New Metric: F-Area
5. Results and Discussion
5.1. Comparison with State-of-the-Art Methods
5.2. Ablation Study
5.2.1. Question 1. Thin Pathway Blocks Information Flow
5.2.2. Question 2. In ISOS, Resizing the Input Image Is Adverse to the Performance
5.2.3. Question 3. Slightly Stabilizes Regularization from Over-parameterization
5.2.4. Question 4. Height Is More Important Than Width
5.2.5. Question 5. Only the Proper Ratio of CDB-L to CDDB-L Can Improve the Performance
5.2.6. Question 6. The Cross-Stage Partial Strategy Is Imperative to Overcome the Problem of Gradient Vanishing
5.2.7. Question 7. The Direct-through Shuffle Strategy Is Superior to the Other Strategies
5.2.8. Question 8. Attention-Based Feature Addition Is Better Than Simple Addition
5.2.9. Question 9. The Ratio of Is Dependent on Not only the Datasets but also the Network Configurations
5.2.10. Question 10. Mish Activation Is Better Choice than Leaky ReLU
5.2.11. Question 11. The Learning Rate at 0.0001 Is the Best
5.2.12. Question 12. The Dual-Learning System Enhances the AP and AUC Well, but Increases the Fa Slightly
5.2.13. Applying the Experiment Step by Step
6. Summary and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| General | |
| AVILNet | Amorphous Variable Inter-Located Network |
| ISOS | Infrared Small-Object Segmentation |
| ICCV | International Conference on Computer Vision |
| SOTA | State-of-the-art |
| Artificial Intelligence and Computer Vision | |
| CNN | Convolutional Neural Network |
| CSP | Cross Stage Partial |
| ACM | Asymmetric Contextual Modulation |
| GAN | Generative Adversarial Network |
| AVILNet | |
| CDB-L | Cross-stage Dense Block with Last-fusion |
| CDDB-L | Cross-stage Dense Dilation Block with Last-fusion |
| USB | Up-Sampling Block |
| DSB | Down-Sampling Block |
| MEN | Multi-scale attention-based Ensemble assistant Network |
| Hyper-parameters in Table 7, Table 8 and Table 10 | |
| gw | growth rate |
| nd | number of dense layers |
| w | width |
| h | height |
| RS | Resizing |
| SF | Shuffle |
| lr | Learning rate |
| DL | CDDB-L |
| L | CDB-L |
| cost function | |
| ep | Epoch |
| ori | The original strategy of CSP |
| lafu | The last-fusion strategy of CSP |
| Dense | Dense Block |
| Res | Residual Block |
| ResNext | ResNext Block |
| Metric | |
| MD | Missed Detection |
| FA | False Alarm |
| AP | Average Precision |
| ROC | Receiver Operating Characteristic |
| AUC | Area Under the ROC Curve |
| TPR | True Positive Rate |
| FPR | False Positive Rate |
| TP | True Positive |
| FP | False Positive |
| TN | True Negative |
| FN | False Negative |
| F1 | F1-score |
| Fa | F-area |
References
- Teutsch, M.; Krüger, W. Classification of small boats in infrared images for maritime surveillance. In Proceedings of the 2010 International WaterSide Security Conference, Carrara, Italy, 3–5 November 2010; pp. 1–7. [Google Scholar] [CrossRef]
- Szpak, Z.L.; Tapamo, J.R. Maritime surveillance: Tracking ships inside a dynamic background using a fast level-set. Expert Syst. Appl. 2011, 38, 6669–6680. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.Z.; Zang, F.N. Ship detection for visual maritime surveillance from non-stationary platforms. Ocean. Eng. 2017, 141, 53–63. [Google Scholar] [CrossRef]
- Kim, S.; Lee, J. Scale invariant small target detection by optimizing signal-to-clutter ratio in heterogeneous background for infrared search and track. Pattern Recognit. 2012, 45, 393–406. [Google Scholar] [CrossRef]
- Deng, H.; Sun, X.; Liu, M.; Ye, C.; Zhou, X. Small infrared target detection based on weighted local difference measure. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4204–4214. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared patch-image model for small target detection in a single image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Park, J.; Chen, J.; Cho, Y.K.; Kang, D.Y.; Son, B.J. CNN-based person detection using infrared images for night-time intrusion warning systems. Sensors 2020, 20, 34. [Google Scholar] [CrossRef]
- Yilmaz, A.; Shafique, K.; Shah, M. Target tracking in airborne forward looking infrared imagery. Image Vis. Comput. 2003, 21, 623–635. [Google Scholar] [CrossRef]
- Dong, X.; Huang, X.; Zheng, Y.; Bai, S.; Xu, W. A novel infrared small moving target detection method based on tracking interest points under complicated background. Infrared Phys. Technol. 2014, 65, 36–42. [Google Scholar] [CrossRef]
- Wang, X.; Ning, C.; Xu, L. Spatiotemporal difference-of-Gaussians filters for robust infrared small target tracking in various complex scenes. Appl. Opt. 2015, 54, 1573–1586. [Google Scholar] [CrossRef]
- Xiao, S.; Ma, Y.; Fan, F.; Huang, J.; Wu, M. Tracking small targets in infrared image sequences under complex environmental conditions. Infrared Phys. Technol. 2020, 104, 103102. [Google Scholar] [CrossRef]
- Dong, X.; Huang, X.; Zheng, Y.; Shen, L.; Bai, S. Infrared dim and small target detecting and tracking method inspired by human visual system. Infrared Phys. Technol. 2014, 62, 100–109. [Google Scholar] [CrossRef]
- Liu, T.; Li, X. Infrared small targets detection and tracking based on soft morphology Top-Hat and SPRT-PMHT. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010; Volume 2, pp. 968–972. [Google Scholar] [CrossRef]
- Bittner, L.; Heigl, N.; Petter, C.; Noisternig, M.; Griesser, U.; Bonn, G.; Huck, C. Near-infrared reflection spectroscopy (NIRS) as a successful tool for simultaneous identification and particle size determination of amoxicillin trihydrate. J. Pharm. Biomed. Anal. 2011, 54, 1059–1064. [Google Scholar] [CrossRef] [PubMed]
- Bellisola, G.; Sorio, C. Infrared spectroscopy and microscopy in cancer research and diagnosis. Am. J. Cancer Res. 2012, 2, 1. [Google Scholar] [PubMed]
- Kosaka, N.; Mitsunaga, M.; Longmire, M.R.; Choyke, P.L.; Kobayashi, H. Near infrared fluorescence-guided real-time endoscopic detection of peritoneal ovarian cancer nodules using intravenously injected indocyanine green. Int. J. Cancer 2011, 129, 1671–1677. [Google Scholar] [CrossRef]
- Zhang, R.; Huang, L.; Xia, W.; Zhang, B.; Qiu, B.; Gao, X. Multiple supervised residual network for osteosarcoma segmentation in CT images. Comput. Med. Imaging Graph. 2018, 63, 1–8. [Google Scholar] [CrossRef]
- Yu, Q.; Xie, L.; Wang, Y.; Zhou, Y.; Fishman, E.K.; Yuille, A.L. Recurrent saliency transformation network: Incorporating multi-stage visual cues for small organ segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8280–8289. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Li, H.; Wei, Y.; Xia, T.; Tang, Y.Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Trans. Geosci. Remote Sens. 2014, 52, 574–581. [Google Scholar] [CrossRef]
- Tom, V.T.; Peli, T.; Leung, M.; Bondaryk, J.E. Morphology-based algorithm for point target detection in infrared backgrounds. In Signal and Data Processing of Small Targets 1993; International Society for Optics and Photonics: Orlando, FL, USA, 1993; Volume 1954, pp. 2–11. [Google Scholar] [CrossRef]
- Deshpande, S.D.; Er, M.H.; Venkateswarlu, R.; Chan, P. Max-mean and max-median filters for detection of small targets. In Signal and Data Processing of Small Targets 1999; International Society for Optics and Photonics: Denver, CO, USA, 1999; Volume 3809, pp. 74–83. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, L.; Wang, L. Miss Detection vs. False Alarm: Adversarial Learning for Small Object Segmentation in Infrared Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 27 October–3 November 2019; pp. 8508–8517. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Fourure, D.; Emonet, R.; Fromont, E.; Muselet, D.; Tremeau, A.; Wolf, C. Residual Conv-Deconv Grid Network for Semantic Segmentation. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017; Kim, T.-K., Stefanos Zafeiriou, G.B., Mikolajczyk, K., Eds.; BMVA Press: Norwich, UK, 2017; pp. 181.1–181.13. [Google Scholar] [CrossRef]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 16–18 June 2020; pp. 390–391. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Ryu, J.; Kim, S. Small infrared target detection by data-driven proposal and deep learning-based classification. In Infrared Technology and Applications XLIV; International Society for Optics and Photonics: Orlando, FL, USA, 2018; Volume 10624, p. 106241J. [Google Scholar] [CrossRef]
- Zhao, D.; Zhou, H.; Rang, S.; Jia, X. An Adaptation of Cnn for Small Target Detection in the Infrared. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 23–27 July 2018; pp. 669–672. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric Contextual Modulation for Infrared Small Target Detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision—WACV 2021, Waikoloa, HI, USA, 5–9 January 2021. [Google Scholar]
- Wei, Y.; You, X.; li, H. Multiscale Patch-based Contrast Measure for Small Infrared Target Detection. Pattern Recognit. 2016, 58. [Google Scholar] [CrossRef]
- Qin, Y.; Bruzzone, L.; Gao, C.; Li, B. Infrared Small Target Detection Based on Facet Kernel and Random Walker. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7104–7118. [Google Scholar] [CrossRef]
- Moradi, S.; Moallem, P.; Sabahi, M.F. A false-alarm aware methodology to develop robust and efficient multi-scale infrared small target detection algorithm. Infrared Phys. Technol. 2018, 89, 387–397. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Song, Y.; Guo, J. Non-negative infrared patch-image model: Robust target-background separation via partial sum minimization of singular values. Infrared Phys. Technol. 2017, 81, 182–194. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y. Reweighted infrared patch-tensor model with both nonlocal and local priors for single-frame small target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3752–3767. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, Z. Infrared small target detection based on partial sum of the tensor nuclear norm. Remote Sens. 2019, 11, 382. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, L.; Zhang, T.; Cao, S.; Peng, Z. Infrared small target detection via non-convex rank approximation minimization joint l2, 1 norm. Remote Sens. 2018, 10, 1821. [Google Scholar] [CrossRef]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training Very Deep Networks. In Proceedings of the Advances in Neural Information Processing Systems 2015 (NIPS 2015), Palais des Congrès de Montréal, Montréal, QC, Canada, 7–12 December 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 2377–2385. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar] [CrossRef]
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K.Q. Deep networks with stochastic depth. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 646–661. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, South Korea, 27 October–3 November 2019; pp. 7314–7323. [Google Scholar] [CrossRef]
- Araujo, A.; Norris, W.; Sim, J. Computing receptive fields of convolutional neural networks. Distill 2019, 4, e21. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 5–9 October 2015; pp. 801–818. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2014; pp. 2672–2680. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar] [CrossRef]
- Karimpouli, S.; Tahmasebi, P. Segmentation of digital rock images using deep convolutional autoencoder networks. Comput. Geosci. 2019, 126, 142–150. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar] [CrossRef]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. Solo: Segmenting objects by locations. arXiv 2019, arXiv:1912.04488. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1405.0312. [Google Scholar]
- Allen-Zhu, Z.; Li, Y.; Song, Z. A Convergence Theory for Deep Learning via Over-Parameterization. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; Volume 97, pp. 242–252. [Google Scholar]
- Allen-Zhu, Z.; Li, Y.; Liang, Y. Learning and Generalization in Overparameterized Neural Networks, Going Beyond Two Layers. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 6158–6169. [Google Scholar]
- Kim, J.; Kim, M.; Kang, H.; Lee, K.H. U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral Normalization for Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gao, C.; Wang, L.; Xiao, Y.; Zhao, Q.; Meng, D. Infrared small-dim target detection based on Markov random field guided noise modeling. Pattern Recognit. 2018, 76, 463–475. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv 2015, arXiv:1502.01852. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical Evaluation of Rectified Activations in Convolutional Network. arXiv 2015, arXiv:1505.00853. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | gw | nd | w | h | RS | lr | DL | L | SF | ep | F1 | AP | AUC | Fa | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| D1 | 16 | 4 | 3 | 6 | 1 | ✓ | ✓ | ✓ | 100, 10 | 123 | 0.564 | 0.486 | 0.799 | 0.274 | ||
| D2 | 8 | 7 | 3 | 6 | 1 | ✓ | ✓ | 100, 10 | 23 | 0.561 | 0.495 | 0.783 | 0.278 | |||
| D3 | 8 | 7 | 3 | 6 | 3 | ✓ | ✓ | 100, 10 | 76 | 0.601 | 0.503 | 0.793 | 0.302 | |||
| D4 | 8 | 7 | 3 | 6 | 3 | ✓ | ✓ | ✓ | 100, 10 | 4 | 0.564 | 0.485 | 0.785 | 0.236 | ||
| D5 | 8 | 7 | 6 | 3 | 3 | ✓ | ✓ | 100, 10 | 51 | 0.570 | 0.494 | 0.799 | 0.282 | |||
| D6 | 8 | 7 | 6 | 3 | 3 | ✓ | 100, 10 | 4 | 0.594 | 0.441 | 0.726 | 0.251 | ||||
| D7 | 8 | 7 | 6 | 3 | 3 | ✓ | ✓ | 100, 10 | 24 | 0.554 | 0.437 | 0.729 | 0.242 | |||
| D8 | 24 | 7 | 4 | 6 | 3 | ✓ | ✓ | ✓ | 100, 10 | 2 | 0.630 | 0.517 | 0.832 | 0.326 | ||
| D9 | 24 | 7 | 4 | 6 | 3 | ✓ | ✓ | ✓ | (b) | 100, 10 | 17 | 0.576 | 0.496 | 0.789 | 0.286 | |
| D10 | 24 | 7 | 4 | 6 | 3 | ✓ | ✓ | ✓ | (c) | 100, 10 | 31 | 0.575 | 0.477 | 0.790 | 0.279 | |
| D11 | 24 | 7 | 4 | 3 | 3 | ✓ | ✓ | ✓ | 100, 10 | 5 | 0.574 | 0.440 | 0.740 | 0.252 | ||
| D12 | 24 | 7 | 4 | 6 | 3 | ✓ | 100, 10 | 26 | 0.552 | 0.448 | 0.753 | 0.247 | ||||
| D13 | 24 | 7 | 4 | 6 | 3 | ✓ | ✓ | ✓ | 100, 10 | 3 | 0.546 | 0.449 | 0.779 | 0.245 | ||
| D14 | 24 | 7 | 4 | 6 | 3 | ✓ | ✓ | ✓ | 100, 10 | 3 | 0.560 | 0.475 | 0.798 | 0.266 | ||
| D15 | 24 | 7 | 4 | 6 | 3 | ✓ | ✓ | ✓ | 100, 3 | 3 | 0.563 | 0.486 | 0.782 | 0.273 | ||
| D16 | 24 | 7 | 4 | 6 | 3 | ✓ | ✓ | ✓ | 100, 3 | 19 | 0.564 | 0.470 | 0.771 | 0.265 | ||
| D17 | 24 | 7 | 4 | 6 | 3 | ✓ | ✓ | ✓ | 100, 10 | 2 | 0.581 | 0.485 | 0.790 | 0.282 | ||
| D18 | 24 | 7 | 4 | 6 | 3 | ✓ | ✓ | ✓ | 100, 10 | 10 | 0.593 | 0.507 | 0.849 | 0.301 | ||
| D19 | 24 | 7 | 4 | 6 | 2 | ✓ | ✓ | ✓ | 100, 10 | 5 | 0.575 | 0.522 | 0.817 | 0.300 | ||
| D20 | 24 | 7 | 4 | 6 | 1 | ✓ | ✓ | ✓ | 100, 10 | 5 | 0.566 | 0.495 | 0.801 | 0.280 | ||
| D21 | 24 | 7 | 4 | 6 | 3 | ✓ | ✓ | 100, 10 | 2 | 0.581 | 0.455 | 0.782 | 0.264 |
| Index | Data Loss | Discriminator | Mish | gw + nd | ori | lafu | DL | Dense | Res | ResNext | ep | F1 | AP | AUC | Fa |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q1 | ✓ | ✓ | 11 | 0.515 | 0.390 | 0.731 | 0.201 | ||||||||
| Q2 | ✓ | ✓ | ✓ | 7 | 0.526 | 0.413 | 0.792 | 0.217 | |||||||
| Q3 | ✓ | ✓ | ✓ | ✓ | 8 | 0.534 | 0.426 | 0.786 | 0.227 | ||||||
| Q4 | ✓ | ✓ | ✓ | ✓ | ✓ | 4 | 0.509 | 0.399 | 0.724 | 0.203 | |||||
| Q5 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 14 | 0.591 | 0.519 | 0.792 | 0.307 | ||||
| AVILNet (Single) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 2 | 0.630 | 0.517 | 0.832 | 0.326 | |||
| AVILNet (Dual) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 1 | 0.610 | 0.536 | 0.928 | 0.327 | |||
| Q6 | ✓ | ✓ | ✓ | ✓ | ✓ | 22 | 0.586 | 0.464 | 0.801 | 0.272 | |||||
| Q7 | ✓ | ✓ | ✓ | ✓ | ✓ | 15 | 0.576 | 0.460 | 0.774 | 0.265 |
| Sub-Network | Setting | ep | F1 | AP | AUC | Fa |
|---|---|---|---|---|---|---|
| MEN (Proposed) | D8 | 1 | 0.630 | 0.517 | 0.832 | 0.326 |
| ResNext | D8 | 1 | 0.560 | 0.433 | 0.721 | 0.243 |
| Method | FLOPs | Parameters | ep | F1 | AP | AUC | Fa | Framework |
|---|---|---|---|---|---|---|---|---|
| AVILNet (Single) | 10.98B | 90.98M | 2 | 0.630 | 0.517 | 0.832 | 0.326 | Pytorch |
| AVILNet (Dual) | 21.96B | 161.96M | 1 | 0.610 | 0.536 | 0.928 | 0.327 | Pytorch |
| DataLossGAN | 30.89B | 3.14M | 29 | 0.577 | 0.514 | 0.834 | 0.293 | Pytorch |
| ACM-FPN | 0.565B | 0.387M | 91 | 0.616 | 0.475 | 0.803 | 0.293 | Pytorch |
| ACM-UNet | 0.9B | 0.520M | 38 | 0.568 | 0.422 | 0.821 | 0.240 | Pytorch |
| YoloV4 | 31.05B | 20.6M | 21 | 0.503 | 0.356 | 0.851 | 0.184 | Pytorch |
| DeepLabV3 | 44.425B | 59.34M | 11 | 0.105 | 0.026 | 0.124 | 0.003 | Pytorch |
| IPI | ’ | ’ | ’ | 0.449 | 0.313 | 0.397 | 0.141 | Matlab |
| MPCM | ’ | ’ | ’ | 0.358 | 0.278 | 0.744 | 0.099 | Matlab |
| PSTNN | ’ | ’ | ’ | 0.465 | 0.200 | 0.321 | 0.093 | Matlab |
| MoG | ’ | ’ | ’ | 0.276 | 0.282 | 0.697 | 0.078 | Matlab |
| RIPT | ’ | ’ | ’ | 0.295 | 0.189 | 0.403 | 0.056 | Matlab |
| FKRW | ’ | ’ | ’ | 0.311 | 0.153 | 0.265 | 0.048 | Matlab |
| NRAM | ’ | ’ | ’ | 0.379 | 0.119 | 0.203 | 0.045 | Matlab |
| AAGD | ’ | ’ | ’ | 0.210 | 0.061 | 0.199 | 0.013 | Matlab |
| Top-hat | ’ | ’ | ’ | 0.171 | 0.066 | 0.182 | 0.011 | Python |
| NIPPS | ’ | ’ | ’ | 0.144 | 0.047 | 0.293 | 0.007 | Matlab |
| LSM | ’ | ’ | ’ | 0.103 | 0.059 | 0.915 | 0.006 | Matlab |
| Max-median | ’ | ’ | ’ | 0.153 | 0.001 | 0.012 | 0.000 | Python |
| Block | Layer/Operation | Kernel/Dilation/Stride/Padding |
|---|---|---|
| CDB-L | conv-batch normalization-mish activation-concat conv-batch normalization-mish activation-concat conv-batch normalization-mish activation-concat conv-batch normalization-mish activation-concat conv-batch normalization-mish activation-concat conv-batch normalization-mish activation-concat conv-batch normalization-mish activation-concat conv-concat | |
| CDDB-L | conv-batch normalization-mish activation-concat conv-batch normalization-mish activation-concat conv-batch normalization-mish activation-concat conv-batch normalization-mish activation-concat conv-batch normalization-mish activation-concat conv-batch normalization-mish activation-concat conv-batch normalization-mish activation-concat conv-concat | |
| USB | transposed conv-batch normalization-mish activation conv-batch normalization-mish activation | |
| DSB | conv-batch normalization-mish activation conv-batch normalization-mish activation |
| Block | Height | Input Dimension | Output Dimension |
|---|---|---|---|
| CDB-L, CDDB-L | 1 2 3 4 5 6 | 128, 128, 34 64, 64, 68 32, 32, 136 16, 16, 272 8, 8, 544 4, 4, 1088 | 128, 128, 34 64, 64, 68 32, 32, 136 16, 16, 272 8, 8, 544 4, 4, 1088 |
| USB | 2 3 4 5 6 | 64, 64, 68 32, 32, 136 16, 16, 272 8, 8, 544 4, 4, 1088 | 128, 128, 34 64, 64, 68 32, 32, 136 16, 16, 272 8, 8, 544 |
| DSB | 2 3 4 5 6 | 128, 128, 34 64, 64, 68 32, 32, 136 16, 16, 272 8, 8, 544 | 64, 64, 68 32, 32, 136 16, 16, 272 8, 8, 544 4, 4, 1088 |
| Input Dimension | Output Dimension | Layer/Operation | Kernel/Dilation/Stride/Padding |
|---|---|---|---|
| 128, 128, 2 64, 64, 24 32, 32, 48 16, 16, 192 | 64, 64, 24 32, 32, 48 16, 16, 192 8, 8, 768 | conv-batch normalization-lrelu activation conv-batch normalization-lrelu activation conv-batch normalization-lrelu activation conv-batch normalization-lrelu activation | 4, 1, 2, 1 4, 1, 2, 1 4, 1, 2, 1 4, 1, 2, 1 |
| 8, 8, 768 | 1, 1, 2 | avgpooling-fully connected layer-spectral normalization | |
| 8, 8, 768 | 1, 1, 2 | maxpooling-fully connected layer-spectral normalization | |
| 1, 1, 4 | 2 | addition-softmax | - |
| Methods | Parameter Settings |
|---|---|
| AVILNet | , Adam optimizer |
| DataLossGAN | , Adom optimizer |
| ACM | , Adagrad optimizer |
| YoloV4 | , Adam optimizer |
| DeepLabV3 | , SGD optimizer |
| IPI | Patch size = , sliding step = 10, , |
| MPCM | L = 3, N = 3, 5, 7, 9 |
| PSTNN | Patch size = , sliding step = 40, , |
| MoG | Temporal sliding length = 3, Patch size = , sliding step = 5, patch length = 3, , |
| RIPT | Patch size = , sliding step = 8, , , , |
| FKRW | Patch size = , , , |
| NRAM | Patch size = , sliding step = 10, , , , , , |
| AAGD | K = 4, , |
| Top-hat | Patch size = |
| NIPPS | Patch size = , sliding step = 10, , |
| LSM | L = 3, N = 3, 5, 7, 9 |
| Max-median |
| No. | Name | Size | Frames/Images |
|---|---|---|---|
| 1 | Canonball | 30 | |
| 2 | Car | 116 | |
| 3 | Plane | 298 | |
| 4 | Bird | 232 | |
| 5 | Cat | 292 | |
| 6 | Rockets | 242 | |
| 7 | Drone | 396 | |
| 8 | Target1 | 361 | |
| 9 | Target2 | 30 | |
| 10 | Target3 | 50 | |
| 11 | Target4 | 51 | |
| 12 | Single-frame image set | Min: , Max: | 100 |
| Index | gw | nd | w | h | RS | # | lr | DL | L | ep | F1 | AP | AUC | Fa | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T1 | 4 | 3 | 3 | 1 | 3 | 64 | ✓ | 100, 10 | 5 | 0.577 | 0.491 | 0.847 | 0.283 | |||
| 8 | 7 | 6 | 3 | 3 | 36 | ✓ | 100, 10 | |||||||||
| T2 | 4 | 3 | 3 | 1 | 1 | 64 | ✓ | 100, 1 | 4 | 0.532 | 0.384 | 0.741 | 0.204 | |||
| 8 | 7 | 4 | 6 | 1 | 36 | ✓ | 1, 10 | |||||||||
| T3 | 4 | 3 | 3 | 1 | 3 | 64 | ✓ | ✓ | 100, 10 | 3 | 0.575 | 0.474 | 0.821 | 0.273 | ||
| 8 | 7 | 6 | 3 | 3 | 36 | ✓ | ✓ | 100, 10 | ||||||||
| T4 | 16 | 4 | 2 | 4 | 3 | 16 | ✓ | ✓ | 100, 10 | 21 | 0.513 | 0.477 | 0.813 | 0.230 | ||
| 16 | 4 | 3 | 6 | 3 | 16 | ✓ | ✓ | 100, 10 | ||||||||
| T5 | 4 | 3 | 2 | 3 | 3 | 64 | ✓ | ✓ | ✓ | 100, 10 | 5 | 0.530 | 0.447 | 0.805 | 0.237 | |
| 8 | 7 | 4 | 6 | 3 | 36 | ✓ | ✓ | ✓ | 100, 10 | |||||||
| T6 | 4 | 3 | 2 | 3 | 3 | 64 | ✓ | ✓ | 100, 10 | 6 | 0.567 | 0.452 | 0.790 | 0.256 | ||
| 8 | 7 | 4 | 6 | 3 | 36 | ✓ | ✓ | 100, 10 | ||||||||
| T7 | 24 | 7 | 4 | 6 | 3 | 34 | ✓ | ✓ | 100, 1 | 1 | 0.582 | 0.502 | 0.942 | 0.292 | ||
| 24 | 7 | 4 | 6 | 3 | 34 | ✓ | ✓ | 100, 10 | ||||||||
| T8 | 24 | 7 | 4 | 6 | 3 | 34 | ✓ | ✓ | ✓ | 100, 1 | 1 | 0.610 | 0.536 | 0.928 | 0.327 | |
| 24 | 7 | 4 | 6 | 3 | 34 | ✓ | ✓ | ✓ | 100, 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, I.; Kim, S. AVILNet: A New Pliable Network with a Novel Metric for Small-Object Segmentation and Detection in Infrared Images. Remote Sens. 2021, 13, 555. https://doi.org/10.3390/rs13040555
Song I, Kim S. AVILNet: A New Pliable Network with a Novel Metric for Small-Object Segmentation and Detection in Infrared Images. Remote Sensing. 2021; 13(4):555. https://doi.org/10.3390/rs13040555
Chicago/Turabian StyleSong, Ikhwan, and Sungho Kim. 2021. "AVILNet: A New Pliable Network with a Novel Metric for Small-Object Segmentation and Detection in Infrared Images" Remote Sensing 13, no. 4: 555. https://doi.org/10.3390/rs13040555
APA StyleSong, I., & Kim, S. (2021). AVILNet: A New Pliable Network with a Novel Metric for Small-Object Segmentation and Detection in Infrared Images. Remote Sensing, 13(4), 555. https://doi.org/10.3390/rs13040555