1. Introduction
Natural disasters, such as fire, earthquake and mudslides, threaten the nation’s safety and security, rendering post-disaster search and rescue (SAR) operations critical [
1]. The locations and breathing signal of people in disaster areas are significant information for SAR missions in prioritizing operations to save more lives [
2]. However, the environment in disaster areas is always unknown and possibly hostile due to potential poisonous gases, hazardous materials, radiation, extreme temperatures and dust, which increases the challenge for rescue workers in the ground search for trapped survivors.
To address these challenges, ground rescue robots have been used in SAR missions as an assistant technology to reduce both the health and personal risks for rescue workers, and provide an alternative to access disaster areas that may otherwise be inaccessible to workers [
3]. The majority of robots require human operators to remotely guide them in searching for victims, however, this can be a very stressful task, which causes cognitive and physical fatigue to operators during time-critical situations. Semi-autonomous control schemes [
4,
5,
6,
7] for robotic exploration in SAR operations have been proposed to address the limitations of both teleoperation and constant human supervision, but require demanding technical supports, such as path planning, autonomous navigation, task allocation, decision-making and victim identification [
8]. Furthermore, implementing ground rescue robots in hard-to-reach areas is a hard problem due to difficult terrains, such as mountains, rivers and lakes.
Additionally, the Doppler radar sensor is also a powerful tool used in SAR missions [
9]. An important application of the Doppler radar sensor is to search and locate an alive person under the rubble of collapsed building or behind a wall by detecting vital signs, such as heartbeats and breathing [
10,
11,
12]. The fundamental supporting this work is that a moving target relative to the radar sensor can induce a frequency shift of the echo as a result of the well-known Doppler effect; additional movements of smaller parts of the target will result in additional modulation of the main Doppler frequency shift, known as the micro-Doppler effect, i.e., the micro-Doppler signature, which reflects the periodic kinetic characteristics of a moving object and can be used for target or activity recognition and classification [
13,
14,
15]. The radar sensor offers advantages in searching for and locating survivors due to its low cost and capability to work at relatively long distances, as well as strong robustness to illumination and weather conditions, but there may be weaknesses in the process to deploy radar networks immediately and appropriately in disaster zones, especially those which are unknown or hard to reach [
16]. In this respect, drones may be used as a complementary tool to provide additional information for life detection and localization.
Unmanned aerial vehicles (UAVs), also known as drones, have been recognized as one of the revolutionary advances in the recent technological evolution, and are now experiencing new applications also in SAR missions [
15,
17,
18]. This is mainly because: (1) drones can be put into action immediately without any loss of time, and obtain a rapid overview of the disaster situation by transferring surveillance and video data in real time; (2) they are especially suitable for use in the cases of difficult terrains or in hazardous or life-threatening situations; (3) they perform flexible operations to rapidly approach target regions where the potential victims are. Al-Kaff et al. [
19] proposed a detection and tracking algorithm for rescuing victims in disaster environments based on color and depth data obtained from drone videos. This method is efficient for localizing humans who are lying on the ground in many poses, but fails to detect their life signs. In order to detect life signs, such as the breathing signal and heart rate, which help to identify whether the person is alive or not, Al-Naji et al. [
20] proposed a remote physiological measurement system based on the skin color analysis of facial videos. They can detect human physiological parameters if the subject location is known prior, but limit the subject standing in front of the drone camera with a single pose. To release the requirement on a specific pose, in another study, Al-Naji et al. [
21] proposed a new life signs detector system based on analyzing the periodic chest movements of survivors. This method can efficiently distinguish living and non-living subjects at different poses, but requires one to select a region of interest (ROI), i.e., the chest region. A body joint estimation approach [
22] was applied in this method to select ROI, however, it performs well only when there are no occlusions on subjects. In contrast, a motion magnification-based method has recently been proposed by Perera et al. [
2] to estimate the locations and breathing signal of survivors in natural disasters. This method can successfully work well on clearly visible people and even those fully covered with dust, debris or ashes, but relies on a special assumption that only human breathing-related motions exist in the drone video. However, in some natural disasters, breathing movements of survivors are mixed with undesired motions in surroundings, such as swing trees and grass caused by wind. Therefore, the current method often produces ’contaminated’ breathing signal, and results in misleading or even no life signs locations.
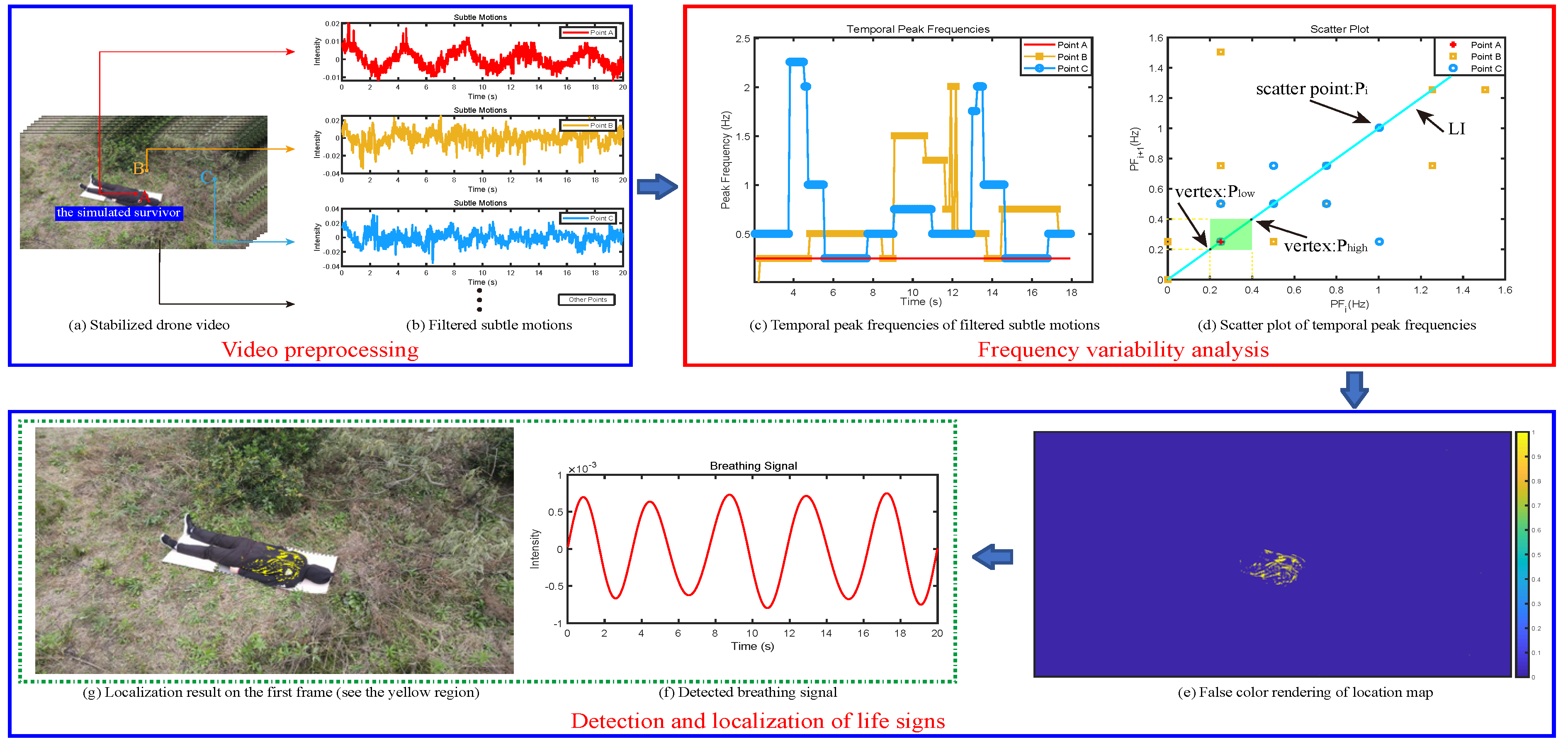
To overcome this limitation, this paper presents a frequency variability feature-based method, which is robust to background motions. It is found that human breathing is a periodic motion with a steady peak frequency that falls within the range of human breathing rate (i.e., (0.2, 0.33) Hz), while for background motions, their peak frequencies seem to be variable over time due to that background motions always involve complex space-time behavior. The peak frequency here means the frequency with largest power in a local spectrum, which is the spectrum corresponding to a signal segement. Therefore, we consider that the temporal variability of peak frequencies of motion signals, which is called frequency variability (FV) feature, enables us to isolate breathing movements from background motions. In developing our method, we focused on analyzing the properties of peak frequencies, and modeled the FV feature using the geometric algebra of a 2D scatter plot. With the estimated FV values, we then designed a binary map that indicates the life signs locations, and with which the breathing signal of survivor was obtained. The proposed method was validated on both drone and camera videos, and experimental results show that our method is more robust and accurate to background motions when compared with the state-of-the-art method [
2].
The contributions of this paper are below. (1) A frequency variability feature-based method is proposed for detecting and locating life signs in natural disasters. (2) The proposed frequency variability feature is successfully applied for discerning breathing movements from background motions. (3) The practical performances that our method provides were demonstrated, and its potential implications and limitations were discussed.
4. Experimental Results
4.1. Experimental Setup
To evaluate the effectiveness of our method, which detects and locates the life signs from drone videos under the presence of background motions, we performed experiments on 20 drone videos. These videos were recorded by a drone, DJI Mavic Air2, at different angles and places in the wild (simulated disaster scenarios) where background motions exist, such as swinging trees and grass caused by wind. During video capture, we set at 60 fps, the resolution 1920 × 1080 pixels, the duration 20 s, and the altitude of drone in hovering state 3–4 m. A total of seven human subjects (five males and two females) aged from 20 to 53 years and one full-body male mannequin (1.72 m tall, fully clothed) participated in these experiments. During the data capture, the human subjects were asked to lie down comfortably and breath naturally. All subjects gave their informed consent for inclusion before they participated in the study. The study was conducted in accordance with the Declaration of Helsinki, and approved by Hefei University of Technology (Project identification code: 18-163-21-TS-001-061-01, date of approval: 27 October 2018).
Referring to the simulated scenarios used in previous work [
2], the drone videos with different simulated scenarios in our experiments included (1) three videos of subject(s) fully covered with a blanket, (2) six videos of a fully visible subject (face up and face down), (3) two videos of a camouflaged subject and clearly visible subject, (4) one video of a camouflaged subject, (5) six videos of a mannequin and clearly visible subject, (6) one video of a mannequin and camouflaged subject and (7) one video of a mannequin and camouflaged subject partly covered with wood plank. Similar to [
2], we drew a red bounding box enclosing the chest area of human subjects in the first frame of videos as the ground truth.
Figure 2 shows the first frames and ground truth regions for 20 drone videos. Note that we presented and discussed the experimental results of the first ten drone videos (i.e., D1 to D10) in the main text, and the experimental results of the last ten drone videos (i.e., AD1 to AD10) are shown in the appendix (see
Table A1 and
Figure A1). Either of the two group results is reliable to indicate the effectiveness of the proposed method. Unless mentioned otherwise, the ten drone videos examined in the main text are the first ten videos, i.e., D1 to D10. Additionally, to evaluate the performance of the proposed method on stable videos, we also did experiments on five camera videos, which were collected in the wild by using a stationary Canon camera (for details, see
Section 4.4.2). All experiments were implemented in MATLAB, and ran on a computer server with an Intel Xeon Silver 4114 CPU at 2.20 GHz and 128 GB of RAM.
4.2. Evaluation Criteria
To evaluate the performance of our method on the detection of life signs from drone videos, we focus on five criteria. They are the detection precision , the location density , the number of false detected points , the computational time and the joint performance .
Detection precision is the ability of a classification model to identify only the relevant data points, that is, the fraction of detected items that are correct [
2]. It is defined as
where
is the number of human locations that are correctly detected and
is the number of items that are falsely detected as human locations. In our experiments, if the pixel positions of detected human breathing are in the ground truth box, they are regarded as correct localization items, otherwise not.
Location density is to measure the denseness of life signs locations detected correctly, and is expressed by
where
is the total pixel number in the ground truth region.
Taking
,
,
and
into consideration, we defined a new evaluation criterion
to evaluate the joint performance of a method on detection precision, location density, false detection and computational time. Formally, given
K drone videos, we tested the
video with
Q methods and recorded their
,
,
and
in four vectors respectively as
,
,
and
, where
,
,
and
are the detection precision, location density, the number of false detections and computational time of the
drone video tested by the
method,
, and
. Then, we normalized all elements of each vector between 0 and 1, and obtained the normalized vectors as
,
,
and
. Finally, the joint performance
of the
method can be defined as
The value is high (close to 2) when a method has good performance with high detection precision, high location density, small number of false detections and low computational time, and becomes low (close to −2) when the method has contrasting performance.
4.3. Parameter Analysis
In this subsection, in order to evaluate the effectiveness of the proposed method under various parameter settings, experiments on ten drone videos were conducted. The default parameter settings in the proposed method are: (1) do video stabilization as preprocessing, (2) set the scale factor to 0.5, (3) set the cut-off frequency to 0.1 Hz, and (4) set the frequency resolution to 0.25 Hz. When evaluating the performance of one parameter (e.g., video stabilization) on our method, we keep other parameters (e.g., , and ) unchanged. Experiments contain the following five aspects: (1) video stabilization, (2) image resolution, (3) temporal filtering, (4) frequency resolution and (5) fidelity term and constraint term.
4.3.1. Video Stabilization
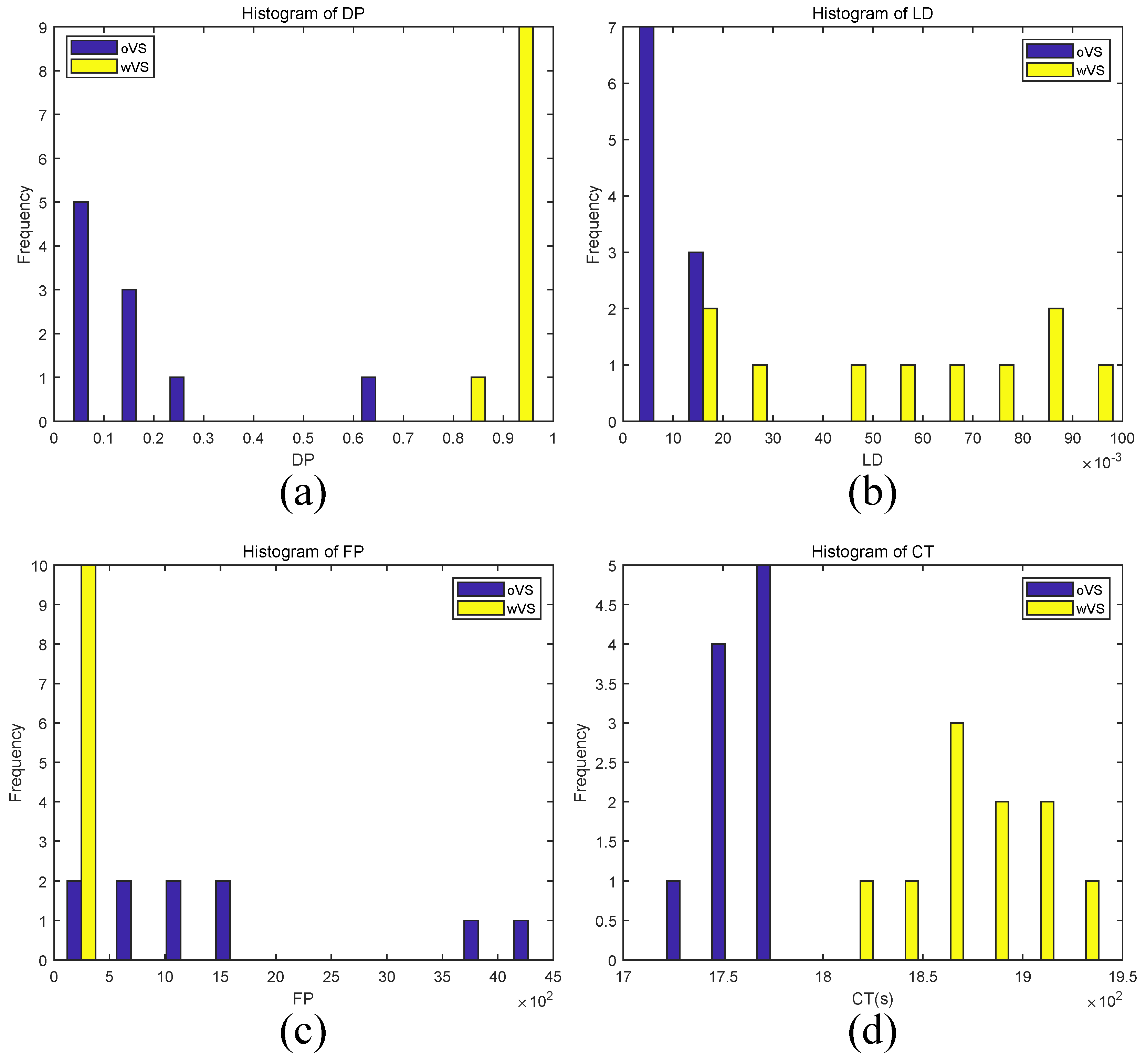
To validate the effectiveness of video stabilization, we tested the stabilized and unstabilized drone videos by our method. For convenient notation within the text, the methods with and without video stabilization are written as wVS and oVS, respectively, when there is no ambiguity. The histogram results of
,
,
and
for ten drone videos are shown in
Figure 3. Each histogram axis is quantized into several bins. The horizontal axis represents the range of
,
,
and
, and the vertical axis corresponds to the number of videos in each bin.
The
of wVS ranged from 0.87 to 0.98, while that of oVs ranged from 0.02 to 0.62 (see
Figure 3a). The
of wVS distributed in the interval larger than 14.36‰, while that of oVs distributed less than 19.94‰(see
Figure 3b). Additionally, the
of wVS mainly located at regions with false detection less than 194, while that of oVs distributed widely from 36 to 4495 (see
Figure 3c). The
of wVs were in the range (1827.84, 1942.95) s, and that of oVs were in (1716.96, 1784.67) s (see
Figure 3d).
The
histogram (
Figure 3d) shows that the method wVs costs more time (the average
is 1877.56 s) than oVS (the average
is 1758.88 s). This is because wVs needs to take time to do the process of video stabilization, while oVS not. However, method wVs has a better performance on
,
and
than oVS. For example, the average
and
values of wVS are 0.94 and 57.38‰, which are much higher than that of oVS, i.e., 0.17 and 8.69‰; furthermore, the average
of wVS is 57, which is much lower than that of oVS, 1517. This is because the video stabilization in wVS can remove most of camera motions in the drone video that helps the resulting stabilized video to meet the first-order Taylor series expansion [
24], therefore, the subtle motions can be extracted effectively at fixed positions by using Equation (
2) that helps to detect the target human breathing; however, for oVS, the raw drone video without stabilization does not meet this expansion, resulting in distorted motions caused by camera motions that lead to false detection. The joint performance values of wVS and oVS are 1 and −1, respectively, indicating that video stabilization is a useful preprocessing to improve method’s performance.
4.3.2. Image Resolution
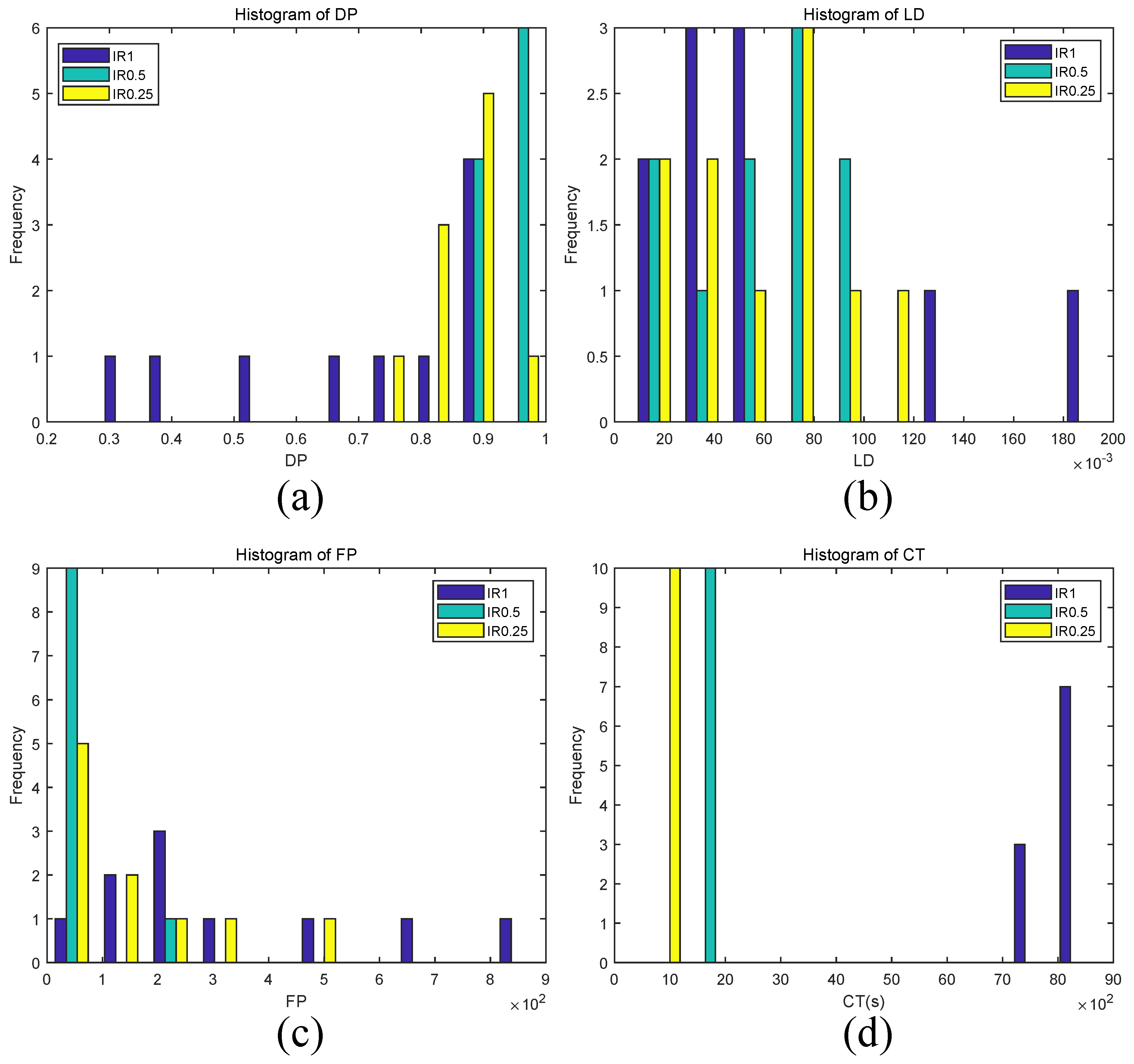
Next, we examined the impact of image resolution on reducing the time cost. We set the scale factor
to 1, 0.5 and 0.25, and write methods under these three factors as IR1, IR0.5 and IR0.25, respectively. Under the different scale factors, the histogram results of
,
,
and
of the proposed method for ten drone videos are shown in
Figure 4.
The
values of IR0.25, IR0.5 and IR1 ranged from 0.72 to 1.0, from 0.87 to 0.98 and from 0.28 to 0.91, respectively (see
Figure 4a). For methods IR0.25 and IR0.5, they had a similar
distribution in the range (6.35‰, 106.83‰); while IR1 had a wide range of
, from 15.36‰to 197.58‰(see
Figure 4b). In addition, the
of IR0.5 was mainly located in the range (22, 194), while that of IR0.25 and IR1 ranged from 0 to 456 and 85 to 892, respectively (see
Figure 4c). The
values of IR0.25 and IR0.5 were in the range (495.31, 536.12) s and (1827.84, 1942.95) s, while that of IR1 was in (7492.91, 8727.41) s (see
Figure 4d).
The
histogram (
Figure 4d) shows that the computational time is significantly reduced with the decrease of image resolution. For instance, the average
values of IR1, IR0.5, and IR0.25 are 8272.06 s, 1877.56 s and 507.28 s respectively. This is because the number of key points in downsampled image is smaller than that in the raw image, and therefore improving the computation speed of video stabilization process. However, when downsampled the raw video further from
to a smaller scale factor
, the performance on
,
and
became a little worse. For instance, the average
and
values decreased from 0.94 to 0.87 and from 57.39‰to 56.01‰, respectively, and the average
increased from 57 to 142. There are likely two reasons for this outcome. On the one hand, videos at small image resolution may have smaller number of target signals than that of videos at larger ones, therefore resulting in low
and
. On the other hand, the target signals may be distorted when downsampling the raw video from fine resolutions to coarse ones, thus resulting in high
. Additionally, results also show that IR1 has poor performance, not only on
, but also on
and
. For example, IR1 has a lower average
(i.e., 0.70) than that of IR0.5 and IR0.25 (i.e., 0.94 and 0.87), and has a higher average
(i.e., 347) than that of IR0.5 and IR0.25 (i.e., 57 and 142). This may due to the fact that in the raw video, some background motions satisfying
are falsely detected as target breathing motions, therefore resulting in low
and high
. These background motions may be removed in the downsampling process, therefore IR0.5 and IR0.25 have better performance on
and
than IR1. Taking all criteria results into consideration, the joint performance criterion JP of method IR0.5 with
is the highest (i.e., 1.29), especially compared to that of IR1 and IR0.25 (i.e., −1.27 and 0.74). Therefore, the scale factor was set to 0.5 in all experiments for obtaining a better performance on detection precision, location density, false detection and time cost at the same time.
4.3.3. Temporal Filtering
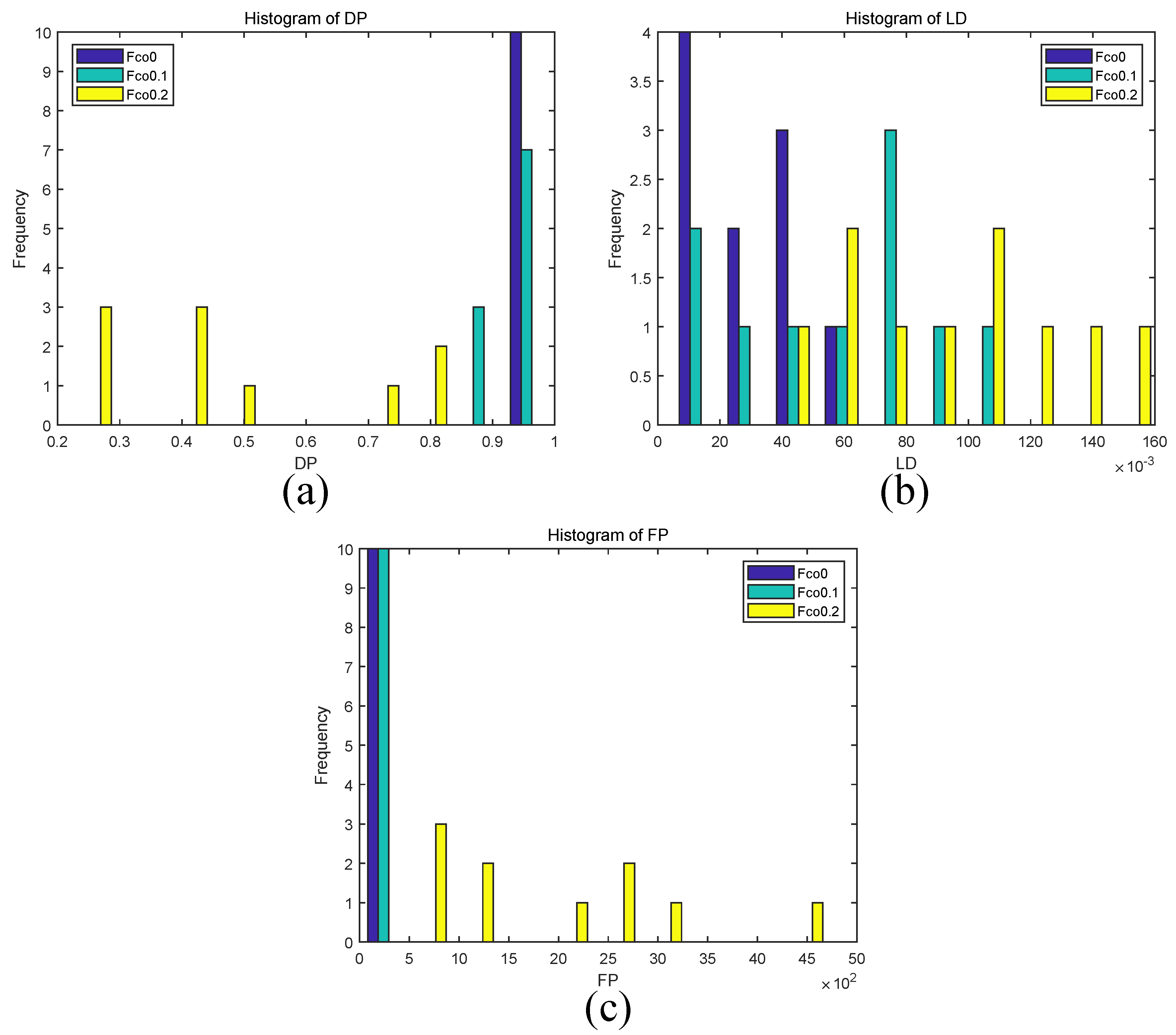
In this part, we analyzed the performance of the proposed method with three different cut off frequencies
, i.e., 0, 0.1 and 0.2 Hz (which are not larger than the lower bound of breathing rate
). The corresponding methods are labeled as Fco0, Fco0.1 and Fco0.2 for convenient notation. Since the total computational time does not change much when adjusting the
value in temporal filtering, only detection precision
, location density
and false detection
are evaluated, except for
. Under different cut off frequencies, the histogram results of
,
and
of the proposed method for ten drone videos are shown in
Figure 5.
The
values of Fco0, Fco0.1 and Fco0.2 ranged from 0.96 to 0.99, from 0.87 to 0.98 and from 0.22 to 0.84, respectively (see
Figure 5a). The
of Fco0 was mainly distributed in the low range (4.29‰, 54.50‰), that of Fco0.1 distributed in the low-middle range (14.36‰, 100.14‰), and that of Fco0.2 was in the middle-high range (49.36‰, 161.23‰) (see
Figure 5b). In addition, the
values of Fco0 and Fco0.1 mainly located in the interval (2, 194), while that of Fco0.2 was in (561, 4737) (see
Figure 5c).
Although Fco0 has the highest
values with an average 0.98, its average
is the lowest (28.61‰). This may be due to the fact that there are residual low-frequency camera movements in the stabilized video that have high amplitude and dominate the peak frequency of
; therefore, only few target signals falling inside the range of human breathing are correctly detected. On the other hand, method Fco0.2 obtains the highest
values but has the lowest
and highest
, due to many motions, including breathing signals and background motions, which do not satisfy
initially, could in turn become satisfied after removing frequency components lower than 0.2 Hz. By setting
in Equation (
11) to zero, the
values corresponding to Fco0, Fco0.1 and Fco0.2 were 1.00, 1.36 and −0.009 respectively; it seems to obtain a good compromise between
,
and
when setting
to 0.1 Hz.
4.3.4. Frequency Resolution
Then, the impact of various frequency resolutions
on the performance of the proposed method was evaluated. The frequency resolution has four potential values: 0.1, 0.2, 0.25 and 0.3 Hz. Similar to the above notations, the corresponding methods are written as Fres0.1, Fres0.2, Fres0.25 and Fres0.3 if there is no ambiguity. Under four different frequency resolutions, 0.1, 0.2, 0.25, and 0.3 Hz, the JP and average results of
,
,
and
of the proposed method for ten drone videos are presented in
Table 2.
As presented in
Table 2, by increasing the value of
, the average
rises initially, peaks, and then falls, while the average
,
and
always fall. Additionally, though Fres0.1 has the highest
value 231.71‰, its average
is the lowest (i.e., 0.27), and its average
is the largest (i.e., 12,224). This is because of the fact that 0.1 Hz is a fine frequency resolution, so that some background motions with steady peak frequencies falling within the breathing frequency band (0.2, 0.33) Hz are falsely detected as life signals. One may improve the detection precision by increasing
values. However, when increasing frequency resolution to be coarser (e.g., 0.3 Hz), which is close to or larger than the upper bound of breathing rate 0.33 Hz, the
value falls again. For instance, we found that there are no life signs been detected when increasing
higher than 0.5 Hz. This may be due to the fact that the real breathing rate cannot be detected correctly under coarser frequency resolutions. Taking
,
,
and
into consideration, our method has a better joint performance (i.e.,
= 1.16) when setting
to 0.25 Hz. This suggests that a frequency resolution not larger than
may be a candidate for users.
4.3.5. Fidelity Term and Constraint Term
Finally, we estimated the importance of the combination of fidelity term and constraint term in the model of the frequency variability feature (defined in Equation (
6)). For comparison, we also evaluated the individual impact of fidelity term and constraint term on the performance of the proposed method. For convenient notation within the text, the methods when only fidelity term or constraint term works are written as MFt and MCt, respectively.
Note that a strict constraint, i.e.,
, is used in our method for life detection and localization (for details, see
Section 3.2 and
Section 3.3, and Equation (
7)); while, in this part, in order to assess and compare the robustness of MFt, MCt and our method for isolating breathing movements from background motions, we relaxed this strict constraint with a threshold
allowing one to detect those motions whose FV value is not larger than
. Here, we rewrite Equation (
7) with a threshold
as
The threshold
is set to four different values manually in this experiment, i.e., 0, 0.1, 1 and 1.5. Here,
means that Equation (
12)) has the same ability with Equation (
7)) to detect only motions that have constant peak frequencies and absolutely satisfy the breathing frequency band; while, for
(e.g., 0.1, 1 or 1.5), it means that Equation (
12)) also detects those background motions that have approximate peak frequencies and approximately satisfy the breathing frequency band. It means that when
is 0, the probability of false detection is the lowest and the greater the
is, the higher probability the false detection will be. The average results of
,
and
for ten drone videos are reported in
Table 3. Meanwhile, the
values were not evaluated, since the total computational time does not change much under different FV thresholds.
Table 3 reports that these three methods have similar results when threshold
is set to 0 or 0.1. This indicates that each of them performs well under a strict threshold constraint. When adjusting threshold from
to higher value
, the average
of MFt significantly falls from 0.94 to 0.76, and average
and
values rise from 57.39‰to 103.51‰and from 57 to 539, respectively. This is due to that lots of motion signals (including both breathing and background motions) with slight changes in peak frequencies are detected as target motions. On the other hand, MCt shows a slight decrease in average
and a small increase in average
and
values. This is because that MCt obtained some motions that have variable frequencies close to the breathing frequency band. In contrast, our method shows almost steady performance for all of the cases. For instance, the mean and standard deviation values of
,
and
of our method under different thresholds are (0.94, 0), (58.03‰, 0.79‰) and (57.75, 0.96). This is because under the same threshold
, our method using the combination of fidelity term and constraint term obtains less false detections than MFt and MCt. These results indicate that the combination of fidelity term and constraint term is important to remain the performance of frequency variability feature for isolating breathing movements from background motions. Additionally, note that when performing the proposed method in the practice, we do not use Equation (
12) (which contains parameter
), but still Equation (
7) (i.e., under the strict constraint
) for obtaining the highest
and lowest
.
From the above parameter analysis, we can conclude as follows. (1) Video stabilization is a necessary preprocessing to remove the camera motions in drone videos, and helps to improve method’s performance. (2) A small resolution (e.g., 480 × 270 pixels) is recommended if users want to obtain method results in a short time (about 8.45 min); in addition, the resolution can be adjusted as users’ requirements change. (3) The temporal filtering enables us to remove the frequencies of residual low-frequency camera motions in a stabilized video; additionally, the cut off frequency can be set with a low value (e.g., 0.1 Hz) but not lager than . (4) Frequency resolution seems to be an important factor; as finer value led to long computational time and large number of false detections, while coarser decreased the detection precision and location density, a frequency resolution not larger than may be a candidate for users. (5) For reliably isolating human breathing from background motions, both fidelity and constraint terms are recommended to be applied in the proposed model of the frequency variability feature.
4.4. Comparison Experiments
In this section, our method was compared with a motion magnification-based method recently proposed by Perera et al. [
2]. Additionally, at the frequency variability feature we are after, one might ask: is it also valid when using only the main frequency of
rather than temporal peak frequencies to identify the life signs locations? Here, the main frequency means the frequency with largest power in the Fourier spectrum of
. To answer this question, we conducted another method, called MFFT. MFFT marks positions
as the life signs locations if the main frequency of
falls within the range of human breathing rate. Ten drone videos and five camera videos were tested in this section.
4.4.1. Drone Videos
Based on the parameters analyzed in
Section 4.3, experiments on drone videos use the default parameter settings as follows:
,
Hz,
Hz. Results of detection precision
, location density
, number of false detected points
and computational time
for ten drone videos are summarized in
Table 4.
For the motion magnification-based method [
2], the
,
and
values ranged from 0 to 0.78, from 0 to 0.05‰, and from 0 to 4301, respectively. The potential reason that accounts for this performance seems to be an overly strong assumption to the drone video, in which only breathing related motions exist. However, in the wild, background motions, such as swing trees and grass caused by wind, severely distort this assumption, resulting in misleading or even no life signs locations. The false color location maps of the motion magnification-based method [
2] for ten drone videos are shown in the second column of
Figure 6. As shown in this figure, due to the negative effect of background motions, only four of ten location maps indicate the human positions.
For method MFFT, the
ranged from 0.03 to 0.21, while the LD and FP ranged from 310.99‰to 716.07‰and from 90,832 to 184,969, respectively. These results show that MFFT has low detection precision and high false detection, although it has the highest location density (the average LD is 510.94‰). Since MFFT identifies life signs locations only by judging whether the main frequency of
falls within the breathing frequency band or not, it cannot remove those background motions whose main frequencies are also in the range of human breathing rate. Therefore, MFFT presented many false detected locations in the background, as shown in the third column of
Figure 6.
As reported in
Table 4, the average
value of our method is 0.94, which is higher than that of Perera et al. [
2] and MFFT (i.e., 0.23 and 0.08), and the average FP is 57, which is less than that of compared methods (i.e., 870 and 117,408). These results indicate that the proposed method obtained more accurate estimate of life signs locations and less false detections than compared methods. Such good performance on
and
mainly owes to the proposed FV feature, which is capable of discerning the human breathing movements from background motions. The reason why
values did not reach 1 is that a small number (i.e., the FP value) of background motions satisfying
is falsely detected as breathing signals. However, these outlier points were always distributed sparsely, and therefore can be removed by using morphological operator of erosion. The false color location maps and localization results of our method for ten drone videos are presented in the last two columns of
Figure 6. Compared with the results of Perera et al.’s work [
2] and MFFT shown in the second and third columns of
Figure 6, the proposed frequency variability feature-based method can detect and locate only the human breathing signals around the chest area, and ignores the background motions.
Additionally, the computational times displayed in
Table 4 indicate that the proposed method produces results about six times faster than [
2], whose average
value is 11,210.96 s. This is because the proposed method did not need the expensive processes of video stabilization and motion magnification for tile videos as done in [
2]. Meanwhile, our method has a processing speed lower than that of MFFT. This is due to the fact that the STFT in the analysis of frequency variability is more expensive than the Fourier transform in MFFT. However, the
values of the motion magnification-based method [
2], MFFT and ours are −0.79, 0.03 and 0.96, respectively, demonstrating that when detecting life signs from drone videos, our method has a better joint performance than compared methods.
4.4.2. Camera Videos
To evaluate the performance of the proposed method on stable videos, we also did experiments on camera videos, which were collected in the wild by using a stationary Canon camera. During video capture, we set
at 50 fps, the resolution 1280 × 720 pixels, the duration 20 s, and the distance between camera and subject to about 10 m. The parameter settings in this part are as follows:
= 0.75 (the new resolution is 960 × 540 pixels),
= 0.1 Hz,
= 0.25 Hz. Our method was compared with method MFFT and the motion magnification-based method proposed by Perera et al. [
2]. Scenarios and results of detection precision
, location density
, number of false detected points
and computational time
for five camera videos are presented in
Table 5.
As reported in
Table 5, the average DP, LD, FP and CT values of Perera et al.’s work [
2], MFFT and ours are (0.11, 263.83‰, 67,413, 94.84 s), (0.04, 339.47‰, 123,428, 83.83 s) and (0.92, 85.6‰, 116, 1243.37 s), respectively. Our method got the lowest location density (average: 85.6‰) than compared methods. This may due to the fact that some factors, such as image noise introduced during the photographic process, affect the peak frequencies of breathing movements, leading to larger FV values than zero. These breathing movements do not satisfy
anymore, and therefore cannot be detected by Equation (
7). In addition, the proposed method costs much time than compared methods. This is because that the STFT in the analysis of frequency variability feature for obtaining the time-frequency information is time consuming; in contrast, since there are less or no camera shaking in ground recorded videos, compared methods did not need the expensive operation of video stabilization, and therefore ran faster than ours. However, our method obtained the highest DP (average: 0.92) and lowest FP (average: 116), which indicate that the proposed method still keeps a high detection precision and a small number of false detections when evaluating on camera videos. The false color location maps and localization results of three methods for five camera videos are shown in
Figure 7. Perera et al.’s work [
2] did not work well due to the background motions (resulting in misleading life signs locations). MFFT can present the human locations but produces much false detections in background. In contrast, our proposed method shows clear locations of life signs without the negative effects of background motions.
5. Discussion
This study was proposed to detect and locate life signs of survivors who are lying on the ground in disaster areas and covered with dust, debris or ashes. As the current method [
2] assumes only human breathing related motions existing in the video, it did not work well in challenging conditions when background motions, like swing trees and grass, exist. In contrast, our method is robust to background motions with the help of frequency variability (FV) feature, and can be used as an emergency tool for detecting survivors in SAR missions.
Besides being used in SAR missions for detecting life signs, the proposed FV feature may be applied in signal analysis for describing the frequency property of a signal. For instance, as shown in the results in
Figure 6 and
Figure 7, the FV is indeed an effective feature for isolating the periodic breathing motions from non-meaningful ones. There may be several potential applications by using the FV feature. For example, the FV feature may be used in the cardiac pulse measurement [
41] for extracting pure heart pulse, without the effects of face motions, such as eye blink and mouth motion. This is because heart pulse is also a periodic signal accompanying blood circulation, while face motions are not. In contrast, users could also analyze non-periodic signals by focusing on the different range of FV values, since the peak frequency-to-peak frequency variations may be benefit to describing the potential properties of signals. For example, the FV feature may have potential implications in mechanical engineering for extracting the time-varying vibration mode shapes [
42], and in micro-expression recognition for detecting the tiny, sudden and short-lived subtle emotions [
43].
There are some factors that may affect the method’s performance. The proposed FV feature enables us to discern breathing motions from background motions, but it relies on the assumption that the extracted breathing motions are periodic signals and fall in the range of human breathing rate. However, some factors may contaminate these breathing motions and distort this assumption, resulting in misleading or sparse results. (1) Camera movements. The subtle motions are extracted based on the EVM [
24] method, which requires that the video frames should be approximated by a first-order Taylor series expansion. However, videos with large camera motions do not hold this requirement. Video stabilization is a necessary preprocess step to remove most of these camera motions; in addition, we consider that a method for directly extracting periodic motions mixed with camera motions can be developed as a subject for future work. (2) Image noise. The collected videos may be mixed with image noise caused by low light levels, atmospheric turbulence, high sensor gain, short exposure time, and so on. Therefore, breathing signals would be contaminated by image noise, and cannot be detected correctly. Denoising methods, such as principal component analysis, wavelet analysis and fractional anisotropy [
44], may be useful to overcome this problem. (3) Camera distance. The breathing movements around the chest are the key clue for detecting life signs in this study. However, as the camera distance increased (e.g., longer than 30 m), the size of the survivor in a image decreased. Therefore, it is difficult to detect ideal breathing signals from a small chest region. To overcome this problem, users can flexibly operate the drone to approach the target zones where the potential victims are at a close distance (e.g., 5 m). Another limitation of this approach is computational complexity. It takes about 30 min to process a drone video with resolution 1920 × 1080 pixels, although it is about six times faster than the motion magnification-based method [
2]; it seems too slow for a real time implementation. This is because the STFT in the analysis of the frequency variability feature for obtaining the time-frequency information is time consuming. A simple and principled approach should be developed as a substitute for using STFT in future work. In addition, weather conditions, such as heavy wind, rain, dense fog and snow, could affect our approach on both data collection and video processing. On the one hand, the drone may not work well in adverse weather conditions; this could alter how the drone perceives its environment and reacts to it. On the other hand, the motion artifacts and poor image quality introduced during the photographic process would bring challenge to video processing. In this respect, the integration of other type of sensors (e.g., radars, thermal and IR cameras) could also be investigated to provide an additional information for life detection and localization complementary to drone-based methods.
6. Conclusions
A frequency variability feature-based method is proposed in this paper for detecting and locating life signs in disaster areas where background motions exist. Motion magnification-based method [
2] has recently been proposed for detecting both clearly visible survivors and those who are fully occluded by dust, debris or ashes, without the additional information that previous methods required [
19,
20,
21]. However, this method can only work well in controlled environment without background motions, such as swing trees and grass caused by wind.
To overcome this limitation, on the basis of our observation that human breathing is a stable periodic motion with constant peak frequency, while that of background motions are not, we analyzed the temporal variability of peak frequency of subtle motions to model a frequency variability (FV) feature. It is found that the FV feature can be used to describe a signal’s frequency properties, and enables us to isolate human breathing from background motions. Using the estimated FV values, we designed a binary map that indicates the human locations, and with which the breathing signal of survivor was obtained. The proposed method was validated on both drone and camera videos, and the average precision measures of our method for drone and camera videos were 0.94 and 0.92, which are higher than that of Perera et al. [
2] (i.e., 0.28 and 0.11) and MFFT (i.e., 0.08 and 0.04), demonstrating that the proposed method obtained more accurate results than those obtained with compared methods. Besides being used in SAR missions for detecting life signs, our method has potential implications in signal analysis and practical applications, such as cardiac pulse measurement, mechanical engineering and micro-expression recognition. Possible future directions of this study are target motion extraction from drone videos without video stabilization and algorithm optimization to reduce computational complexity.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






