
Classification of Nemoral Forests with Fusion of Multi-Temporal Sentinel-1 and 2 Data


Abstract
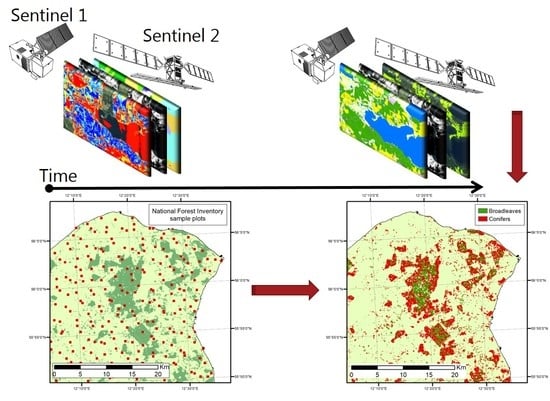
:
1. Introduction
2. Materials and Methods
2.1. Preparation of Optical Data
2.2. Preparation of SAR Data
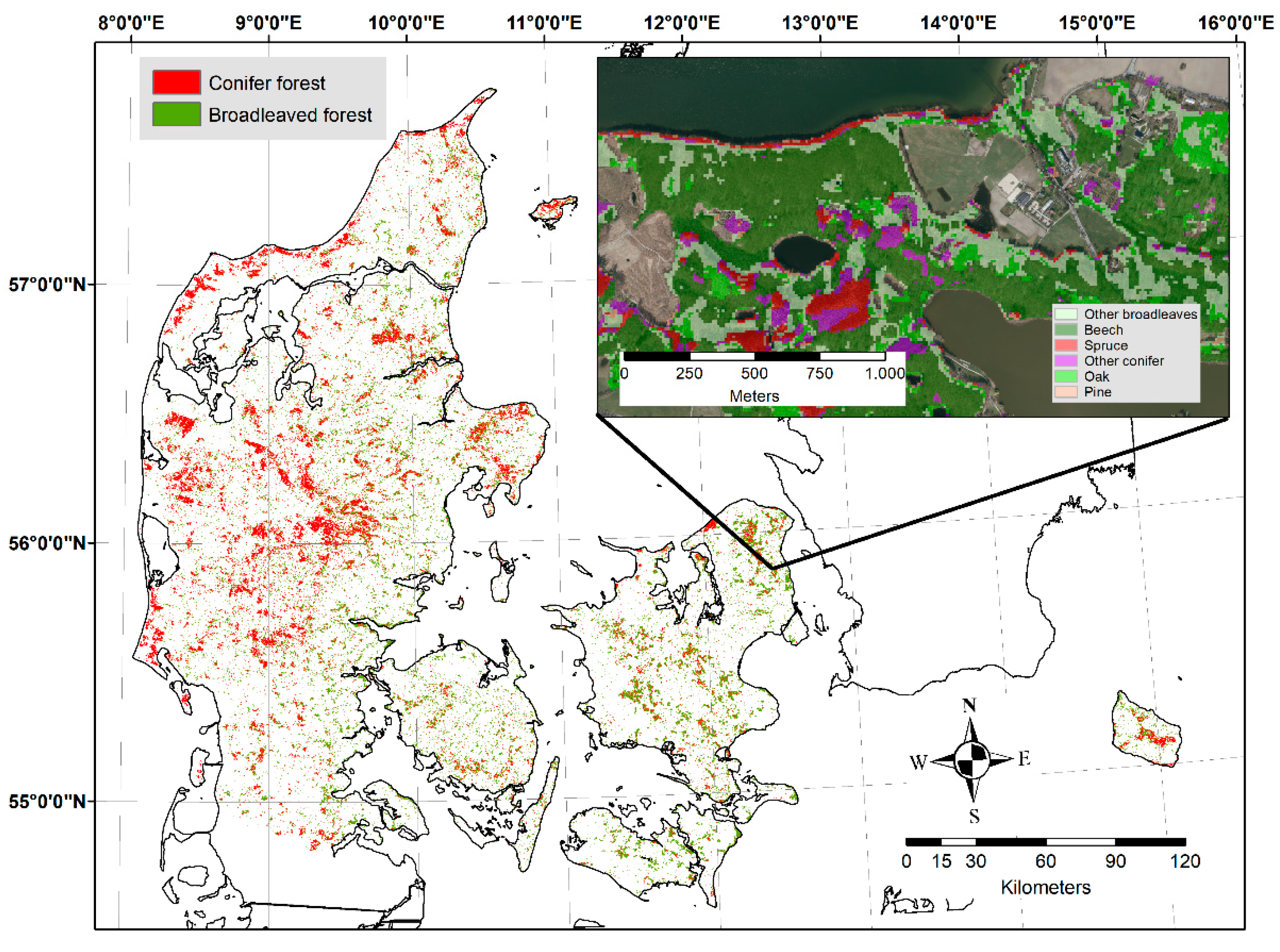
2.3. National Forest Inventory Data
Preparation of NFI Data
2.4. Model Building and Evaluation Framework
2.5. Post Classification Filtering
3. Results
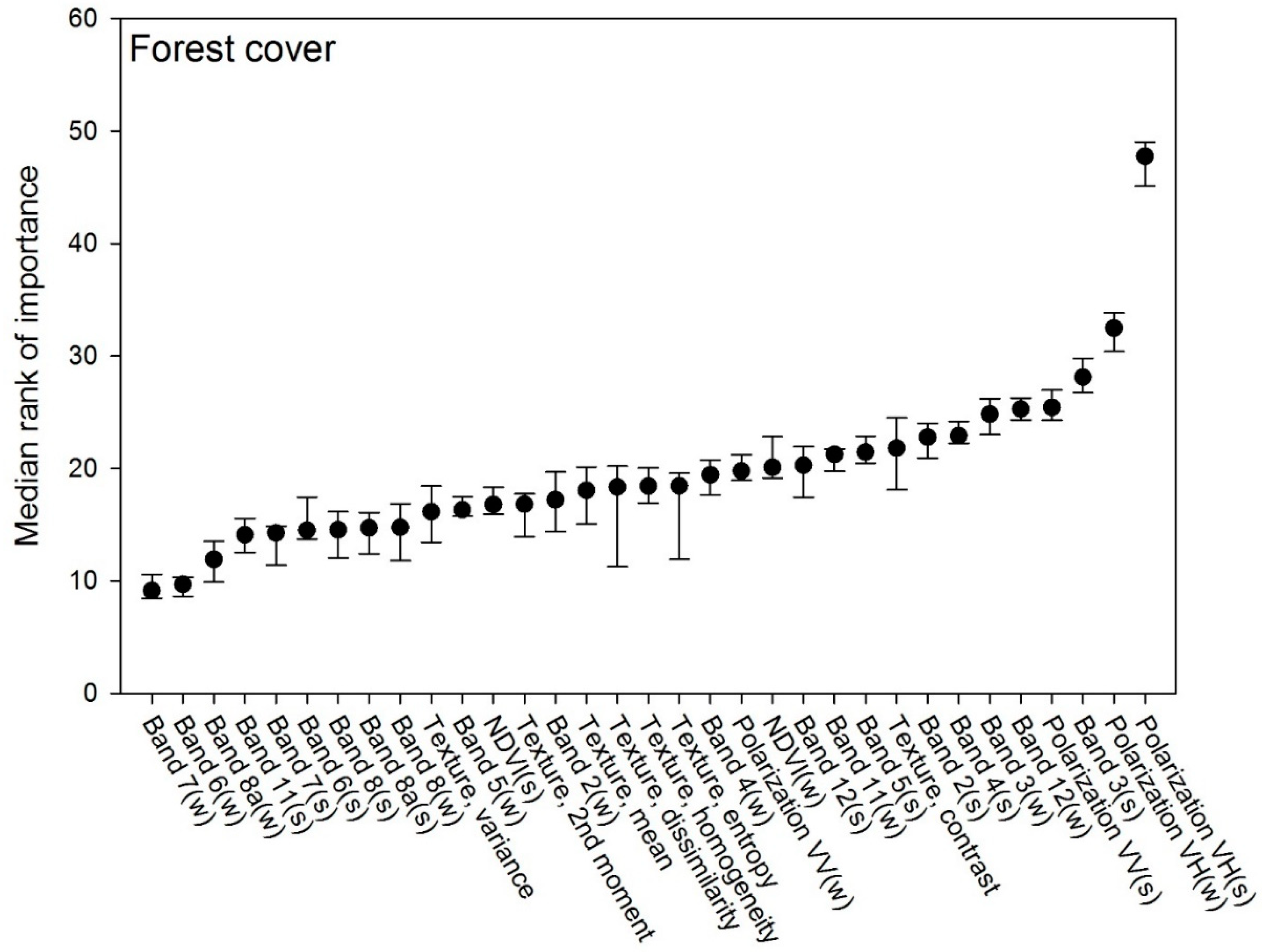
3.1. Forest Cover Model
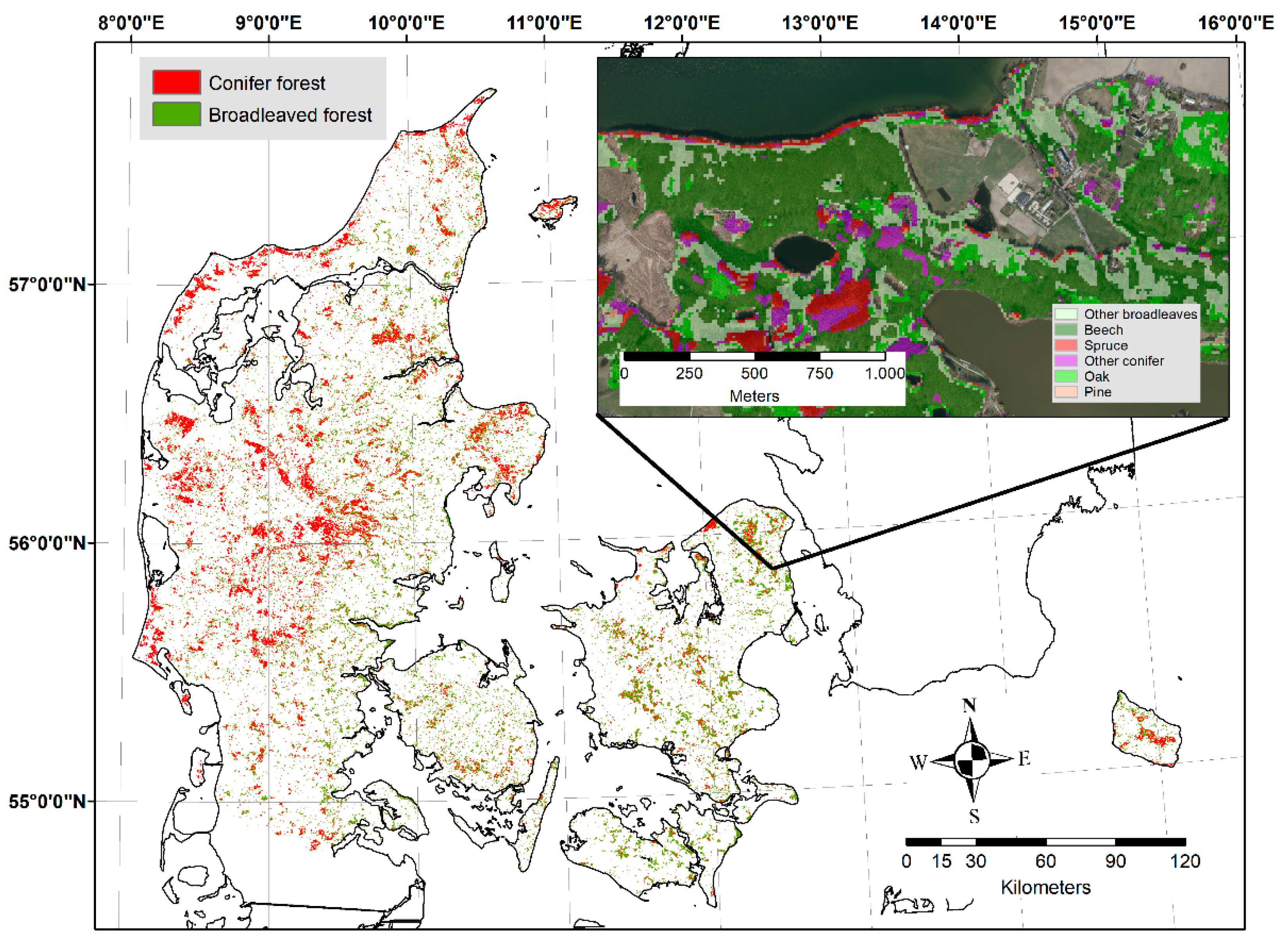
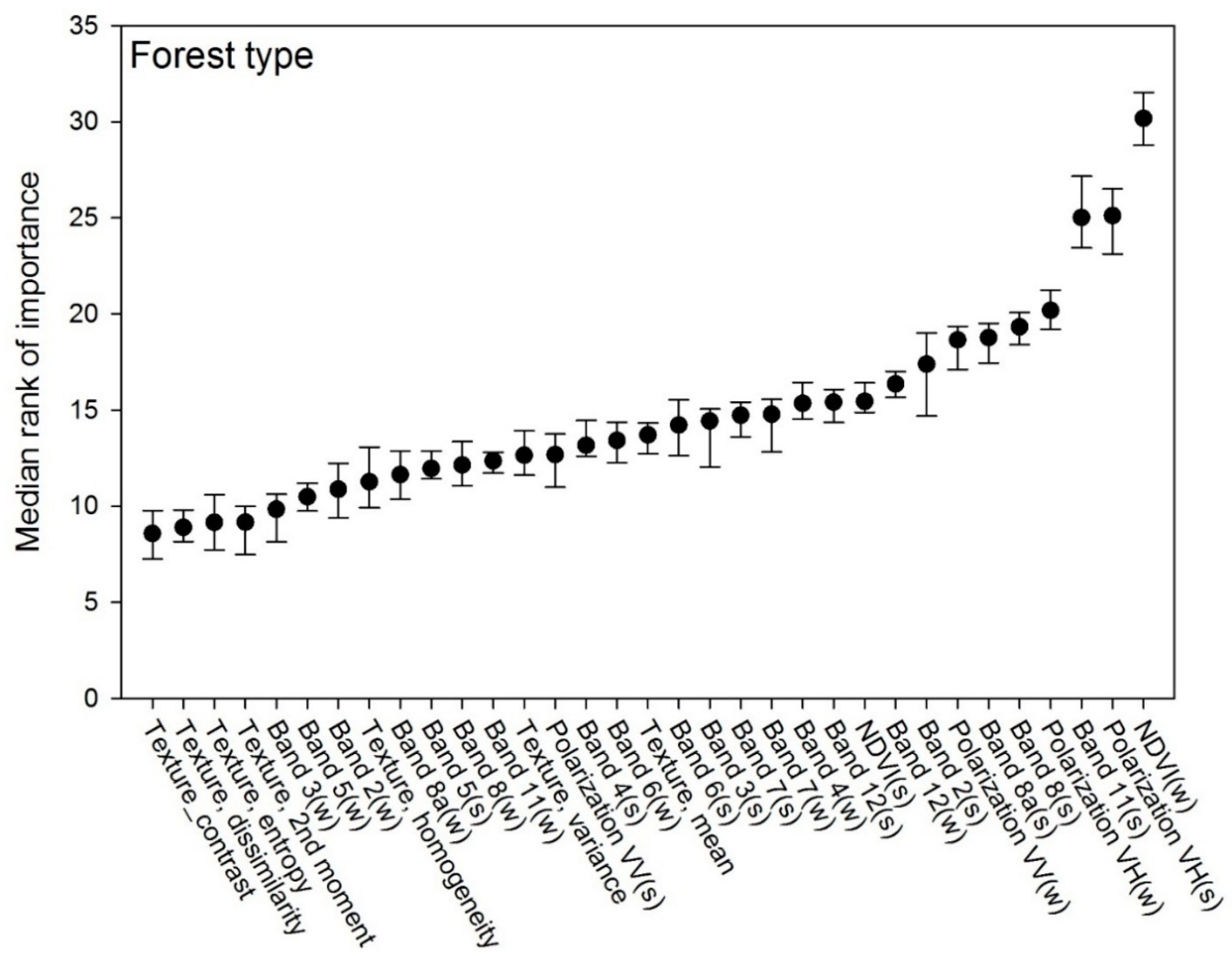
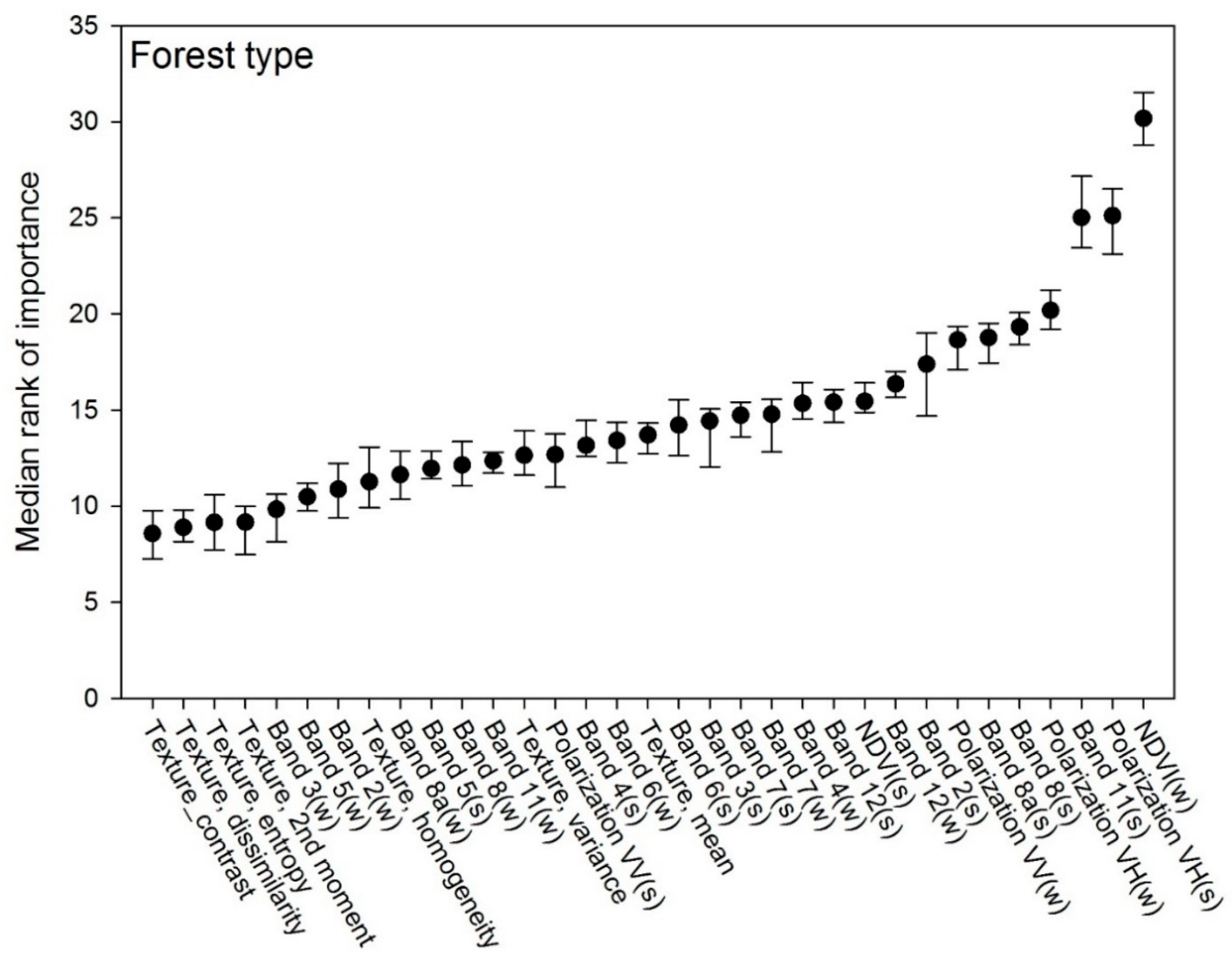
3.2. Forest Type Model
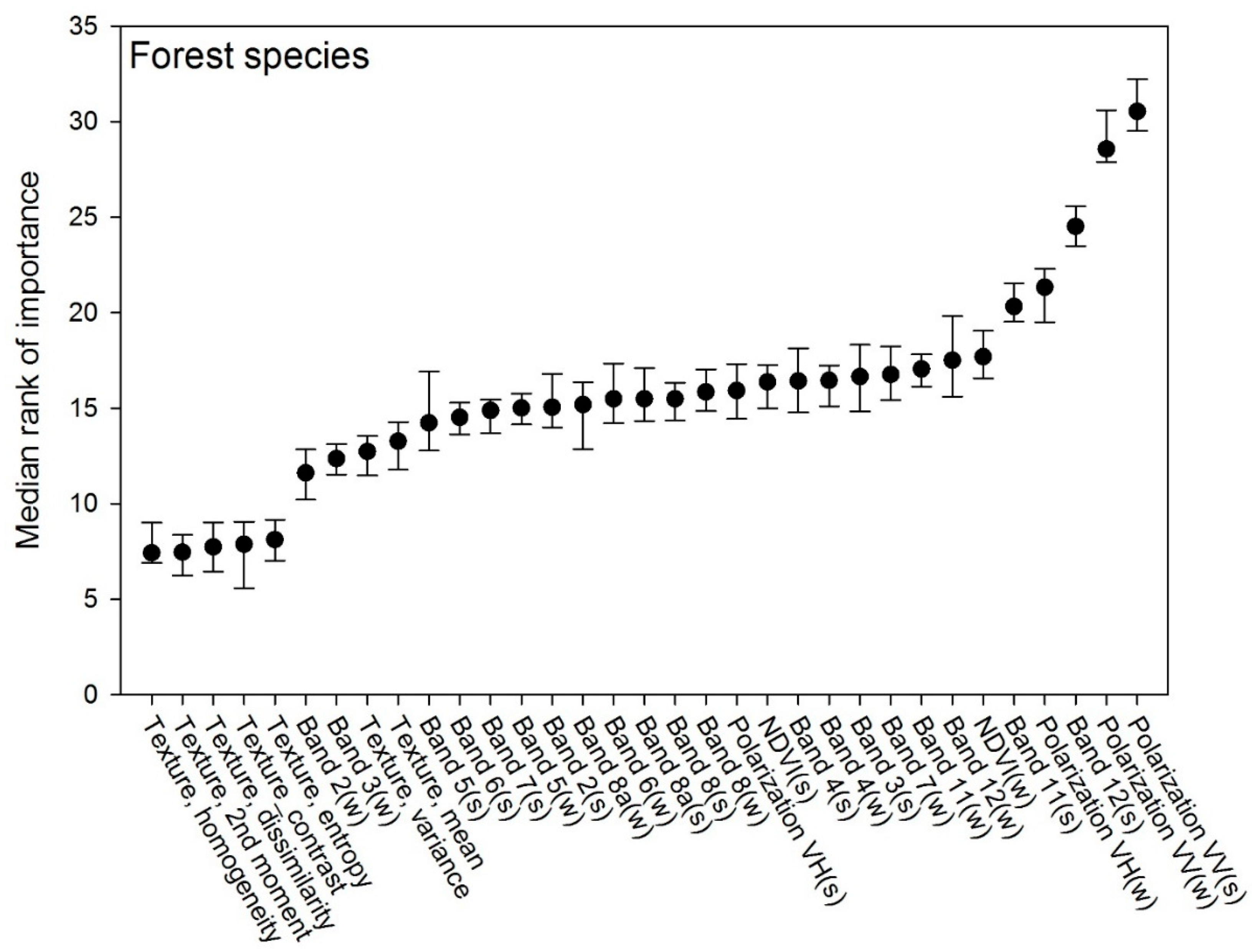
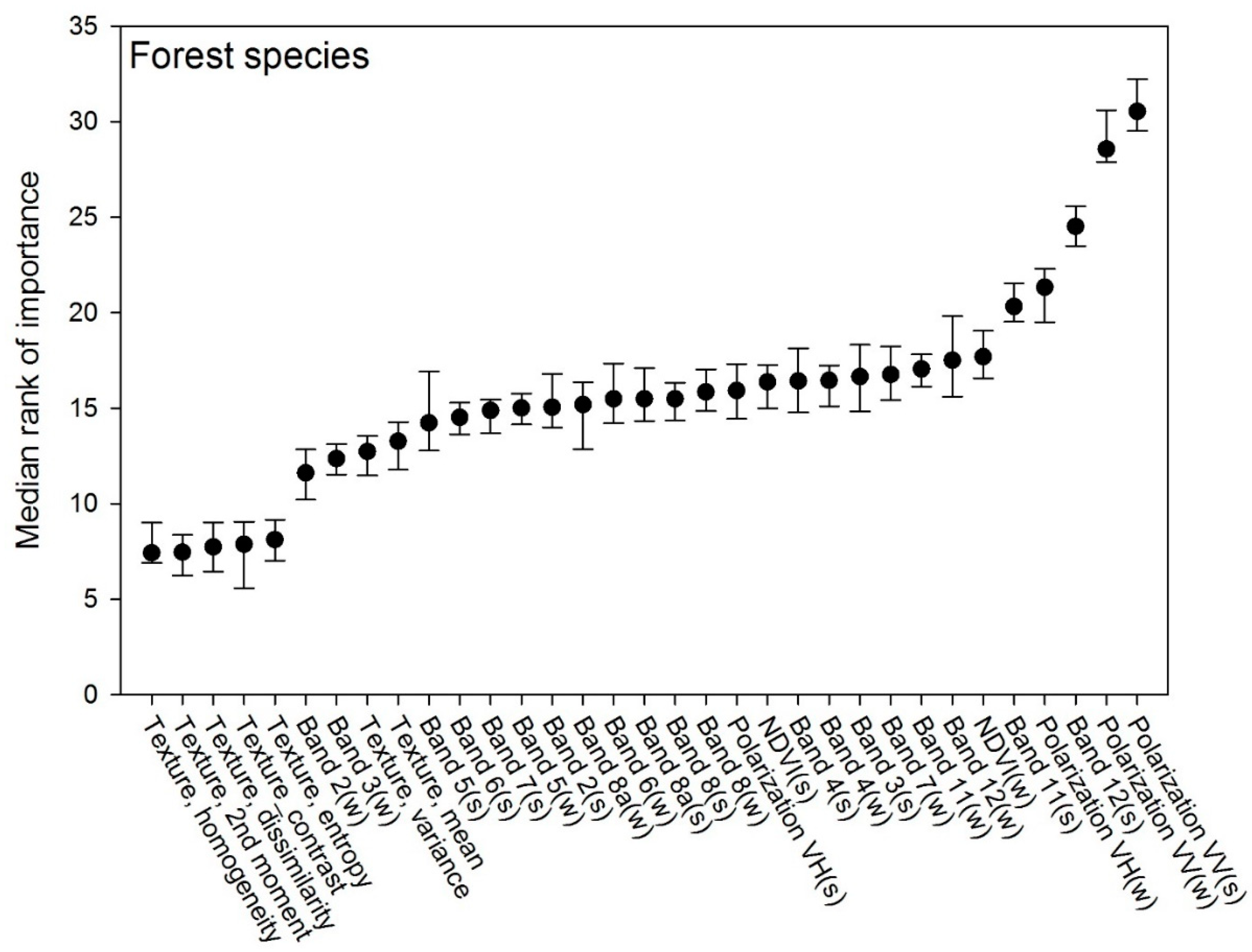
3.3. Tree Species Model
4. Discussion
4.1. Forest Cover Classification
4.2. Forest Type Classification
4.3. Tree Species Classification
4.4. Use of NFI Data in Area-Based Classification
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Summer/Winter) | Abbreviations (Features) | Mean (Summer) | Stdv (Summer) | Mean (Winter) | Stdv (Winter) |
|---|---|---|---|---|---|
| Optical data | |||||
| Raw electromagnetic bands (BOA reflectance value x 10,000) | |||||
| Band 2 | B2s/B2w | 493.49 | 179.88 | 531.34 | 156.43 |
| Band 3 | B3s/B3w | 725.78 | 205.71 | 622.60 | 190.95 |
| Band 4 | B4s/B4w | 590.64 | 266.30 | 543.47 | 220.51 |
| Band 5 | B5s/B5w | 1131.30 | 279.24 | 1008.45 | 278.03 |
| Band 6 | B6s/B6w | 2583.70 | 593.68 | 1958.57 | 802.36 |
| Band 7 | B7s/B7w | 3097.74 | 745.61 | 2214.70 | 923.49 |
| Band 8 | B8s/B8w | 3257.64 | 798.44 | 2398.27 | 994.51 |
| Band 8A | B8As/B8Aw | 3374.79 | 788.27 | 2418.02 | 946.46 |
| Band 11 | B11s/B11w | 1807.18 | 449.32 | 1484.68 | 436.14 |
| Band 12 | B12s/B12w | 1027.51 | 369.10 | 925.03 | 308.94 |
| Vegetation index | |||||
| Normalized Difference Vegetation Index | NDVIs/NDVIw | 0.65 | 0.17 | 0.57 | 0.20 |
| Haralick Texture features (only on NDVIs) | |||||
| Mean | - | 0.86 | 0.09 | - | - |
| Variance | - | 721.16 | 140.91 | - | - |
| Homogeneity | - | 0.76 | 0.17 | - | - |
| Dissimilarity | - | 0.56 | 0.51 | - | - |
| Contrast | - | 1.07 | 1.71 | - | - |
| Entropy | - | 1.08 | 0.60 | - | - |
| Second moment | - | 0.45 | 0.27 | - | - |
| SAR data (Radar image reflectance values) | |||||
| Vertical-Vertical polarization | VVs/VVw | −10.84 | 2.40 | −10.36 | 2.42 |
| Vertical-Horizontal polarization | VHs/VHw | −17.51 | 2.59 | −18.19 | 2.99 |
References
- Nord-Larsen, T.; Pretzsch, H. Biomass production dynamics for common forest tree species in Denmark—Evaluation of a common garden experiment after 50 years of measurements. For. Ecol. Manag. 2017, 400, 645–654. [Google Scholar] [CrossRef]
- Rothe, A. Tree Species Management and Nitrate Contamination of Groundwater: A Central European Perspective. In Tree Species Effects on Soils: Implications for Global Change; Springer: Dordrecht, The Netherlands, 2005; pp. 71–83. [Google Scholar]
- Salazar, O.; Hansen, S.; Abrahamsen, P.; Hansen, K.; Gundersen, P. Water Balance in Afforestation Chronosequences of Common Oak and Norway Spruce on Former Arable Soils in Denmark as Evaluated Using the DAISY Model. Procedia Environ. Sci. 2013, 19, 217–223. [Google Scholar] [CrossRef] [Green Version]
- Christiansen, J.R.; Vesterdal, L.; Callesen, I.; Elberling, B.; Schmidt, I.K.; Gundersen, P. Role of six European tree species and land-use legacy for nitrogen and water budgets in forests. Glob. Chang. Biol. 2010, 16, 2224–2240. [Google Scholar] [CrossRef]
- Quine, C.P.; Humphrey, J.W. Plantations of exotic tree species in Britain: Irrelevant for biodiversity or novel habitat for native species? Biodivers. Conserv. 2010, 19, 1503–1512. [Google Scholar] [CrossRef]
- Dyderski, M.K.; Paź, S.; Frelich, L.E.; Jagodziński, A.M. How much does climate change threaten European forest tree species distributions? Glob. Chang. Biol. 2018, 24, 1150–1163. [Google Scholar] [CrossRef]
- Loetsch, F.; Haller, K. Forest Inventory; BLV Verlagsgesellschaft: München, Germany, 1964; Volume I. [Google Scholar]
- Roth, W.; Olson, C. Multispectral Sensing of Forest Tree Species. Photogramm. Eng. 1972, 38, 1209–1215. [Google Scholar]
- Boyd, D.; Danson, F. Satellite remote sensing of forest resources: Three decades of research development. Prog. Phys. Geogr. 2005, 29, 1–26. [Google Scholar] [CrossRef]
- Nord-Larsen, T.; Schumacher, J. Estimation of forest resources from a country wide laser scanning survey and national forest inventory data. Remote Sens. Environ. 2012, 119, 148–157. [Google Scholar] [CrossRef]
- Næsset, E.; Gobakken, T.; Holmgren, J.; Hyyppä, H.; Hyyppä, J.; Maltamo, M.; Nilsson, M.; Olsson, H.; Persson, Å.; Söderman, U. Laser scanning of forest resources: The Nordic experience. Scand. J. For. Res. 2004, 19, 482–499. [Google Scholar] [CrossRef]
- Næsset, E. Practical large-scale forest stand inventory using a small-footprint airborne scanning laser. Scand. J. For. Res. 2004, 19, 164–179. [Google Scholar] [CrossRef]
- Næsset, E. Accuracy of forest inventory using airborne laser scanning: Evaluating the first nordic full-scale operational project. Scand. J. For. Res. 2004, 19, 554–557. [Google Scholar] [CrossRef]
- Akujärvi, A.; Lehtonen, A.; Liski, J. Ecosystem services of boreal forests—Carbon budget mapping at high resolution. J. Environ. Manag. 2016, 181, 498–514. [Google Scholar] [CrossRef] [PubMed]
- Mononen, L.; Vihervaara, P.; Repo, T.; Korhonen, K.T.; Ihalainen, A.; Kumpula, T. Comparative study on biophysical ecosystem service mapping methods—A test case of carbon stocks in Finnish Forest Lapland. Ecol. Ind. 2017, 73, 544–553. [Google Scholar] [CrossRef]
- Lehtomäki, J.; Tomppo, E.; Kuokkanen, P.; Hanski, I.; Moilanen, A. Applying spatial conservation prioritization software and high-resolution GIS data to a national-scale study in forest conservation. For. Ecol. Manag. 2009, 258, 2439–2449. [Google Scholar] [CrossRef]
- Räsänen, A.; Lensu, A.; Tomppo, E.; Kuitunen, M. Comparing Conservation Value Maps and Mapping Methods in a Rural Landscape in Southern Finland. Landsc. Online 2015, 44, 1–21. [Google Scholar] [CrossRef]
- Johannsen, V.K.; Rojas, S.K.; Brunbjerg, A.K.; Schumacher, J.; Bladt, J.; Nyed, P.K.; Moeslund, J.E.; Nord-Larsen, T.; Ejrnæs, R. Udvikling af et High. Nature Value—HNV-Skovkort for Danmark; Institut for Geovidenskab og Naturforvaltning, Københavns Universitet: Frederiksberg, Denmark, 2015. [Google Scholar]
- Vatka, E.; Kangas, K.; Orell, M.; Lampila, S.; Nikula, A.; Nivala, V. Nest site selection of a primary hole-nesting passerine reveals means to developing sustainable forestry. J. Avian Biol. 2014, 45. [Google Scholar] [CrossRef]
- McDermid, G.J.; Franklin, S.E.; LeDrew, E.F. Remote sensing for large-area habitat mapping. Prog. Phys. Geogr. 2005, 29, 449–474. [Google Scholar] [CrossRef]
- McDermid, G.J.; Hall, R.J.; Sanchez-Azofeifa, G.A.; Franklin, S.E.; Stenhouse, G.B.; Kobliuk, T.; LeDrew, E.F. Remote sensing and forest inventory for wildlife habitat assessment. For. Ecol. Manag. 2009, 257, 2262–2269. [Google Scholar] [CrossRef]
- Jusoff, K.; Hassan, H.M. Forest recreation planning in Langkawi Island, Malaysia, using landsat TM. Int. J. Remote Sens. 1996, 17, 3599–3613. [Google Scholar] [CrossRef]
- Wolter, P.P.; Townsend, P.A. Multi-sensor data fusion for estimating forest species composition and abundance in northern Minnesota. Remote Sens. Environ. 2011, 115, 671–691. [Google Scholar] [CrossRef]
- Fortin, J.A.; Cardille, J.A.; Perez, E. Multi-sensor detection of forest-cover change across 45 years in Mato Grosso, Brazil. Remote Sens. Environ. 2020, 238, 111266. [Google Scholar] [CrossRef]
- Lu, M.; Chen, B.; Liao, X.; Yue, T.; Yue, H.; Ren, S.; Li, X.; Nie, Z.; Xu, B. Forest Types Classification Based on Multi-Source Data Fusion. Remote Sens. 2017, 9, 1153. [Google Scholar] [CrossRef] [Green Version]
- Poortinga, A.; Tenneson, K.; Shapiro, A.; Nquyen, Q.; San Aung, K.; Chishtie, F.; Saah, D. Mapping Plantations in Myanmar by Fusing Landsat-8, Sentinel-2 and Sentinel-1 Data along with Systematic Error Quantification. Remote Sens. 2019, 11, 831. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J. Multi-source remote sensing data fusion: Status and trends. Int. J. Image Data Fusion 2010, 1, 5–24. [Google Scholar] [CrossRef] [Green Version]
- Mahyouba, S.; Fadilb, A.; Mansour, E.; Rhinanea, H.; Al-Nahmia, F. Fusing of optical and synthetic aperture radar (SAR) remote sensing data: A systematic literature review (SLR). Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Joshi, N.; Baumann, M.; Ehammer, A.; Fensholt, R.; Grogan, K.; Hostert, P.; Jepsen, M.R.; Kuemmerle, T.; Meyfroidt, P.; Mitchard, E.T.A.; et al. A Review of the Application of Optical and Radar Remote Sensing Data Fusion to Land Use Mapping and Monitoring. Remote Sens. 2016, 8, 70. [Google Scholar] [CrossRef] [Green Version]
- Asner, G.P.; Martin, R.E.; Anderson, C.B.; Knapp, D.E. Quantifying forest canopy traits: Imaging spectroscopy versus field survey. Remote Sens. Environ. 2015, 158, 15–27. [Google Scholar] [CrossRef]
- Martin, R.E.; Chadwick, K.D.; Brodrick, P.G.; Carranza-Jimenez, L.; Vaughn, N.R.; Asner, G.P. An Approach for Foliar Trait Retrieval from Airborne Imaging Spectroscopy of Tropical Forests. Remote Sens. 2018, 10, 199. [Google Scholar] [CrossRef]
- Dutta, D.; Wang, K.; Lee, E.; Goodwell, A.; Woo, D.K.; Wagner, D.; Kumar, P. Characterizing Vegetation Canopy Structure Using Airborne Remote Sensing Data. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1160–1178. [Google Scholar] [CrossRef]
- Treuhaft, R.N.; Law, B.E.; Asner, G.P. Forest attributes from radar interferometric structure and its fusion with optical remote sensing. BioScience 2004, 54, 561–571. [Google Scholar] [CrossRef] [Green Version]
- Brovelli, M.A.; Sun, Y.; Yordanov, V. Monitoring Forest Change in the Amazon Using Multi-Temporal Remote Sensing Data and Machine Learning Classification on Google Earth Engine. ISPRS Int. J. Geo-Inf. 2020, 9, 580. [Google Scholar] [CrossRef]
- Ahern, F.J.; Leckie, D.J.; Drieman, J.A. Seasonal changes in relative C-band backscatter of northern forest cover types. IEEE Trans. Geosci. Remote Sens. 1993, 31, 668–680. [Google Scholar] [CrossRef]
- Pulliainen, J.T.; Kurvonen, L.; Hallikainen, M.T. Multitemporal behavior of L- and C-band SAR observations of boreal forests. IEEE Trans. Geosci. Remote Sens. 1999, 37, 927–937. [Google Scholar] [CrossRef]
- Sharma, R.; Leckie, D.; Hill, D.; Crooks, B.; Bhogal, A.S.; Arbour, P.; D’eon, S. Hyper-temporal radarsat SAR data of a forested terrain. In Proceedings of the International Workshop on the Analysis of Multi-Temporal Remote Sensing Images, Biloxi, MS, USA, 16–18 May 2005; pp. 71–75. [Google Scholar]
- Santoro, M.; Fransson, J.E.S.; Eriksson, L.E.B.; Magnusson, M.; Ulander, L.M.H.; Olsson, H. Signatures of ALOS PALSAR L-Band Backscatter in Swedish Forest. IEEE Trans. Geosci. Remote Sens. 2009, 47, 4001–4019. [Google Scholar] [CrossRef] [Green Version]
- Guyot, G.; Guyon, D.; Riom, J. Factors affecting the spectral response of forest canopies: A review. Geocarto Int. 1989, 4, 3–18. [Google Scholar] [CrossRef]
- Dostálová, A.; Wagner, W.; Milenković, M.; Hollaus, M. Annual seasonality in Sentinel-1 signal for forest mapping and forest type classification. Int. J. Remote Sens. 2018, 39, 7738–7760. [Google Scholar] [CrossRef]
- Rüetschi, M.; Schaepman, M.E.; Small, D. Using Multitemporal Sentinel-1 C-band Backscatter to Monitor Phenology and Classify Deciduous and Coniferous Forests in Northern Switzerland. Remote Sens. 2018, 10, 55. [Google Scholar] [CrossRef] [Green Version]
- Mercier, A.; Betbeder, J.; Rumiano, F.; Baudry, J.; Gond, V.; Blanc, L.; Bourgoin, C.; Cornu, G.; Ciudad, C.; Marchamalo, M.; et al. Evaluation of Sentinel-1 and 2 Time Series for Land Cover Classification of Forest-Agriculture Mosaics in Temperate and Tropical Landscapes. Remote Sens. 2019, 11, 979. [Google Scholar] [CrossRef] [Green Version]
- Heckel, K.; Urban, M.; Schratz, P.; Mahecha, M.; Schmullius, C. Predicting Forest Cover in Distinct Ecosystems: The Potential of Multi-Source Sentinel-1 and -2 Data Fusion. Remote Sens. 2020, 12, 302. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Gong, W.; Hu, X.; Gong, J. Forest Type Identification with Random Forest Using Sentinel-1A, Sentinel-2A, Multi-Temporal Landsat-8 and DEM Data. Remote Sens. 2018, 10, 946. [Google Scholar] [CrossRef] [Green Version]
- Mutanga, O.; Kumar, L. Google Earth Engine Applications. Remote Sens. 2019, 11, 591. [Google Scholar] [CrossRef] [Green Version]
- Müller-Wilm, U. Sentinel-2 MSI—Level-2A Prototype Processor Installation and User Manual; Version 2.2; Telespazio VEGA Deutschland GmbH: Darmstadt, Germany, 2016. [Google Scholar]
- Main-Knorn, M.; Pflug, B.; Louis, J.; Debaecker, V.; Ferran Gascon, U.M.-W. Sen2Cor for Sentinel-2. In Proceedings SPIE 10427, Image and Signal Processing for Remote Sensing XXIII; SPIE: Warsaw, Poland, 2017. [Google Scholar]
- Gascon, F.; Bouzinac, C.; Thépaut, O.; Jung, M.; Francesconi, B.; Louis, J.; Lonjou, V.; Lafrance, B.; Massera, S.; Gaudel-Vacaresse, A.; et al. Copernicus Sentinel-2A Calibration and Products Validation Status. Remote Sens. 2017, 9, 584. [Google Scholar] [CrossRef] [Green Version]
- Hird, J.N.; DeLancey, E.R.; McDermid, G.J.; Kariyeva, J. Google Earth Engine, Open-Access Satellite Data, and Machine Learning in Support of Large-Area Probabilistic Wetland Mapping. Remote Sens. 2017, 9, 1315. [Google Scholar] [CrossRef] [Green Version]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- ESA. The Sentinel-1 Toolbox. Available online: https://sentinel.esa.int/web/sentinel/toolboxes/sentinel-1 (accessed on 9 February 2021).
- Nord-Larsen, T.; Johannsen, V.K. Danish National Forest Inventory: Design and Calculations; Department of Geosciences and Natural Resource Management, University of Copenhagen: Frederiksberg, Denmark, 2016. [Google Scholar]
- Kortforsyningen. GeoDanmark Ortofoto. Available online: https://download.kortforsyningen.dk/content/geodanmark-ortofoto-blokinddelt (accessed on 11 February 2021).
- FAO. Global Forest Resources Assessment 2020: Main Report; FAO: Rome, Italy, 2020. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key issues in rigorous accuracy assessment of land cover products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Alexander, C.; Bøcher, P.K.; Arge, L.; Svenning, J.-C. Regional-scale mapping of tree cover, height and main phenological tree types using airborne laser scanning data. Remote Sens. Environ. 2014, 147, 156–172. [Google Scholar] [CrossRef]
- Grabska, E.; Hostert, P.; Pflugmacher, D.; Ostapowicz, K. Forest Stand Species Mapping Using the Sentinel-2 Time Series. Remote Sens. 2019, 11, 1197. [Google Scholar] [CrossRef] [Green Version]
- Magdon, P.; Fischer, C.; Fuchs, H.; Kleinn, C. Translating criteria of international forest definitions into remote sensing image analysis. Remote Sens. Environ. 2014, 149, 252–262. [Google Scholar] [CrossRef]
- Ørka, H.O.; Gobakken, T.; Næsset, E.; Ene, L.; Lien, V. Simultaneously acquired airborne laser scanning and multispectral imagery for individual tree species identification. Can. J. Remote Sens. 2012, 38, 125–138. [Google Scholar] [CrossRef]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Stehman, S.V.; Woodcock, C.E. Making better use of accuracy data in land change studies: Estimating accuracy and area and quantifying uncertainty using stratified estimation. Remote Sens. Environ. 2013, 129, 122–131. [Google Scholar] [CrossRef]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 13. [Google Scholar] [CrossRef] [Green Version]
- GeoDanmark. GeoDanmark—Det Fælles Datagrundlag. Specifikation 6.0.1. Available online: http://geodanmark.nu/Spec6/HTML5/DK/StartHer.htm (accessed on 11 February 2021).
- Lapini, A.; Pettinato, S.; Santi, E.; Paloscia, S.; Fontanelli, G.; Garzelli, A. Comparison of Machine Learning Methods Applied to SAR Images for Forest Classification in Mediterranean Areas. Remote Sens. 2020, 12, 369. [Google Scholar] [CrossRef] [Green Version]
- Kasischke, E.S.; Melack, J.M.; Craig Dobson, M. The use of imaging radars for ecological applications—A review. Remote Sens. Environ. 1997, 59, 141–156. [Google Scholar] [CrossRef]
- Nord-Larsen, T.; Johannsen, V.K.; Riis-Nielsen, T.; Thomsen, I.M.; Jørgensen, B.B. Skovstatistik 2018: Forest Statistics 2018. (2 udg.); Institut for Geovidenskab og Naturforvaltning, Københavns Universitet: Frederiksberg, Denmark, 2020. [Google Scholar]
- Nielsen, O.-K.; Pejdrup, M.S.; Winther, M.; Nielsen, M.; Gyldenkærne, S.; Mikkelsen, M.H.; Albrektsen, R.; Thomsen, M.; Hjelgaard, K.; Fauser, P.; et al. Denmark’s National Inventory Report 2020. Emission Inventories 1990–2018—Submitted under the United Nations Framework Convention on Climate Change and the Kyoto Protocol; Scientific Report from DCE; Danish Centre for Environment and Energy: Århus, Denmark, 2020; p. 900. [Google Scholar]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Schumacher, J.; Nord-Larsen, T. Wall-to-wall tree type classification using airborne lidar data and CIR images. Int. J. Remote Sens. 2014, 35, 3057–3073. [Google Scholar] [CrossRef]
- Yu, X.; Lu, D.; Jiang, X.; Li, G.; Chen, Y.; Li, D.; Chen, E. Examining the Roles of Spectral, Spatial, and Topographic Features in Improving Land-Cover and Forest Classifications in a Subtropical Region. Remote Sens. 2020, 12, 2907. [Google Scholar] [CrossRef]
- Strahler, A.; Logan, T.; Bryant, N. Improving forest cover classification accuracy from Landsat by incorporating topographic information. In Proceedings of the 12th International Symposium on Remote Sensing of Environment, Manilla, Philippines, 20–26 April 1978. [Google Scholar]
- Persson, M.; Lindberg, E.; Reese, H. Tree Species Classification with Multi-Temporal Sentinel-2 Data. Remote Sens. 2018, 10, 1794. [Google Scholar] [CrossRef] [Green Version]
- Kou, W.; Liang, C.; Wei, L.; Hernandez, A.J.; Yang, X. Phenology-Based Method for Mapping Tropical Evergreen Forests by Integrating of MODIS and Landsat Imagery. Forests 2017, 8, 34. [Google Scholar] [CrossRef]
- Azzari, G.; Lobell, D.B. Landsat-based classification in the cloud: An opportunity for a paradigm shift in land cover monitoring. Remote Sens. Environ. 2017, 202, 64–74. [Google Scholar] [CrossRef]
- Fan, H.; Fu, X.; Zhang, Z.; Wu, Q. Phenology-Based Vegetation Index Differencing for Mapping of Rubber Plantations Using Landsat OLI Data. Remote Sens. 2015, 7, 6041–6058. [Google Scholar] [CrossRef] [Green Version]
- Maschler, J.; Atzberger, C.; Immitzer, M. Individual Tree Crown Segmentation and Classification of 13 Tree Species Using Airborne Hyperspectral Data. Remote Sens. 2018, 10, 1218. [Google Scholar] [CrossRef] [Green Version]
- Sheeren, D.; Fauvel, M.; Josipović, V.; Lopes, M.; Planque, C.; Willm, J.; Dejoux, J.-F. Tree Species Classification in Temperate Forests Using Formosat-2 Satellite Image Time Series. Remote Sens. 2016, 8, 734. [Google Scholar] [CrossRef] [Green Version]
- Plakman, V.; Janssen, T.; Brouwer, N.; Veraverbeke, S. Mapping Species at an Individual-Tree Scale in a Temperate Forest, Using Sentinel-2 Images, Airborne Laser Scanning Data, and Random Forest Classification. Remote Sens. 2020, 12, 3710. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Latifi, H.; Stereńczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- Clark, M.L.; Roberts, D.A. Species-Level Differences in Hyperspectral Metrics among Tropical Rainforest Trees as Determined by a Tree-Based Classifier. Remote Sens. 2012, 4, 1820–1855. [Google Scholar] [CrossRef] [Green Version]
- Korpela, I.; Heikkinen, V.; Honkavaara, E.; Rohrbach, F.; Tokola, T. Variation and directional anisotropy of reflectance at the crown scale—Implications for tree species classification in digital aerial images. Remote Sens. Environ. 2011, 115, 2062–2074. [Google Scholar] [CrossRef]
- DeFries, R.S.; Hansen, M.; Townshend, J.R.G.; Sohlberg, R. Global land cover classifications at 8 km spatial resolution: The use of training data derived from Landsat imagery in decision tree classifiers. Int. J. Remote Sens. 1998, 19, 3141–3168. [Google Scholar] [CrossRef]
- Tomppo, E.; Gschwantner, T.; Lawrence, M.; McRoberts, R.E. National Forest Inventories—Pathways for Common Reporting; Springer: Heidelberg, Germany, 2010; p. 614. [Google Scholar] [CrossRef]

| Class | Criteria | Training (2018) | Evaluation (2017, 2019) |
|---|---|---|---|
| Forest cover | |||
| Non-forest | Forest fraction = 0% and crown cover = 0% | 6548 | 13,365 |
| Forest | Forest fraction > 75% and Crown cover > 10% | 981 | 1827 |
| Ambiguous | Not meeting above criteria | 965 | 1828 |
| Total | 8586 | 17,020 | |
| Forest type | Conifer/broadleaf species > 75% of basal area | ||
| Conifer | 319 | 532 | |
| Broadleaf | 357 | 650 | |
| Total | 676 | 1182 | |
| Tree species | Species group > 75% of basal area | ||
| Fagus | 75 | 165 | |
| Quercus | 57 | 93 | |
| Other broadleaves | 113 | 180 | |
| Picea | 99 | 203 | |
| Pinus | 74 | 125 | |
| Other conifers | 88 | 146 | |
| Total | 506 | 912 |
| Forest Cover | Reference | Reference (Post Filtered) | ||||
|---|---|---|---|---|---|---|
| Prediction | Non-Forest | Forest | Total | Non-Forest | Forest | Total |
| Non-forest | 13,236 (87.1%) | 174 (1.1%) | 13,410 | 13,325 (87.7%) | 191 (1.3%) | 13,516 |
| Forest | 129 (0.8%) | 1653 (10.9%) | 1782 | 40 (0.3%) | 1636 (10.8%) | 1676 |
| Total | 13,365 | 1827 | 15,192 | 13,365 | 1827 | 15,192 |
| PA | 0.99 | 0.90 | 1.00 | 0.90 | ||
| UA | 0.99 | 0.93 | 0.99 | 0.98 | ||
| OA | 0.98 | 0.98 | ||||
| Forest area (ha) | 637,290 | 597,980 | ||||
| CI 95% (ha) | ±10,402 | ±8573 | ||||
| Forest Type | Reference | ||
|---|---|---|---|
| Prediction | Conifer | Broadleaf | Total Pred. |
| Conifer | 503 (42.6%) | 27 (2.3%) | 530 |
| Broadleaf | 29 (2.5%) | 623 (52.7%) | 652 |
| Total ref. | 532 | 650 | 1182 |
| PA | 0.95 | 0.96 | |
| UA | 0.95 | 0.96 | |
| OA | 0.95 | ||
| Area (ha) | 268,824 | 329,156 | |
| CI 95% (ha) | ±7247 | ±7247 | |
| Reference | |||||||
|---|---|---|---|---|---|---|---|
| Prediction | Fagus | Quercus | Other Broadleaves | Picea | Pinus | Other Conifers | Total Pred. |
| Fagus | 104 | 17 | 35 | 2 | 0 | 6 | 164 |
| Quercus | 10 | 32 | 27 | 0 | 0 | 3 | 72 |
| Other broadleaves | 46 | 41 | 107 | 7 | 5 | 9 | 215 |
| Picea | 1 | 2 | 3 | 149 | 15 | 29 | 199 |
| Pinus | 1 | 0 | 4 | 11 | 92 | 4 | 112 |
| Other conifers | 3 | 1 | 4 | 34 | 13 | 95 | 150 |
| Total ref. | 165 | 93 | 180 | 203 | 125 | 146 | 912 |
| PA | 0.63 | 0.34 | 0.59 | 0.73 | 0.73 | 0.65 | |
| UA | 0.63 | 0.44 | 0.50 | 0.75 | 0.82 | 0.63 | |
| OA | 0.63 | ||||||
| Area (ha) | 112,759 | 66,089 | 133,160 | 119,273 | 70,271 | 96,428 | |
| CI 95% (ha) | ±13,423 | ±12,099 | ±15,209 | ±11,371 | ±8468 | ±11,761 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bjerreskov, K.S.; Nord-Larsen, T.; Fensholt, R. Classification of Nemoral Forests with Fusion of Multi-Temporal Sentinel-1 and 2 Data. Remote Sens. 2021, 13, 950. https://doi.org/10.3390/rs13050950
Bjerreskov KS, Nord-Larsen T, Fensholt R. Classification of Nemoral Forests with Fusion of Multi-Temporal Sentinel-1 and 2 Data. Remote Sensing. 2021; 13(5):950. https://doi.org/10.3390/rs13050950
Chicago/Turabian StyleBjerreskov, Kristian Skau, Thomas Nord-Larsen, and Rasmus Fensholt. 2021. "Classification of Nemoral Forests with Fusion of Multi-Temporal Sentinel-1 and 2 Data" Remote Sensing 13, no. 5: 950. https://doi.org/10.3390/rs13050950
APA StyleBjerreskov, K. S., Nord-Larsen, T., & Fensholt, R. (2021). Classification of Nemoral Forests with Fusion of Multi-Temporal Sentinel-1 and 2 Data. Remote Sensing, 13(5), 950. https://doi.org/10.3390/rs13050950