
Hyperspectral Image Clustering with Spatially-Regularized Ultrametrics



Abstract
:1. Introduction
- We propose the SRUSC algorithm for HSI clustering. This method enjoys rich theoretical justification and is intuitively simple, with few sensitive parameters to tune. In particular, SRUSC detects the number of clusters in the HSI.
- We prove performance guarantees on the runtime of SRUSC. This ensures fast performance of SRUSC on high-dimensional data that exhibits intrinsically low-dimensional structure, allowing the proposed method to scale.
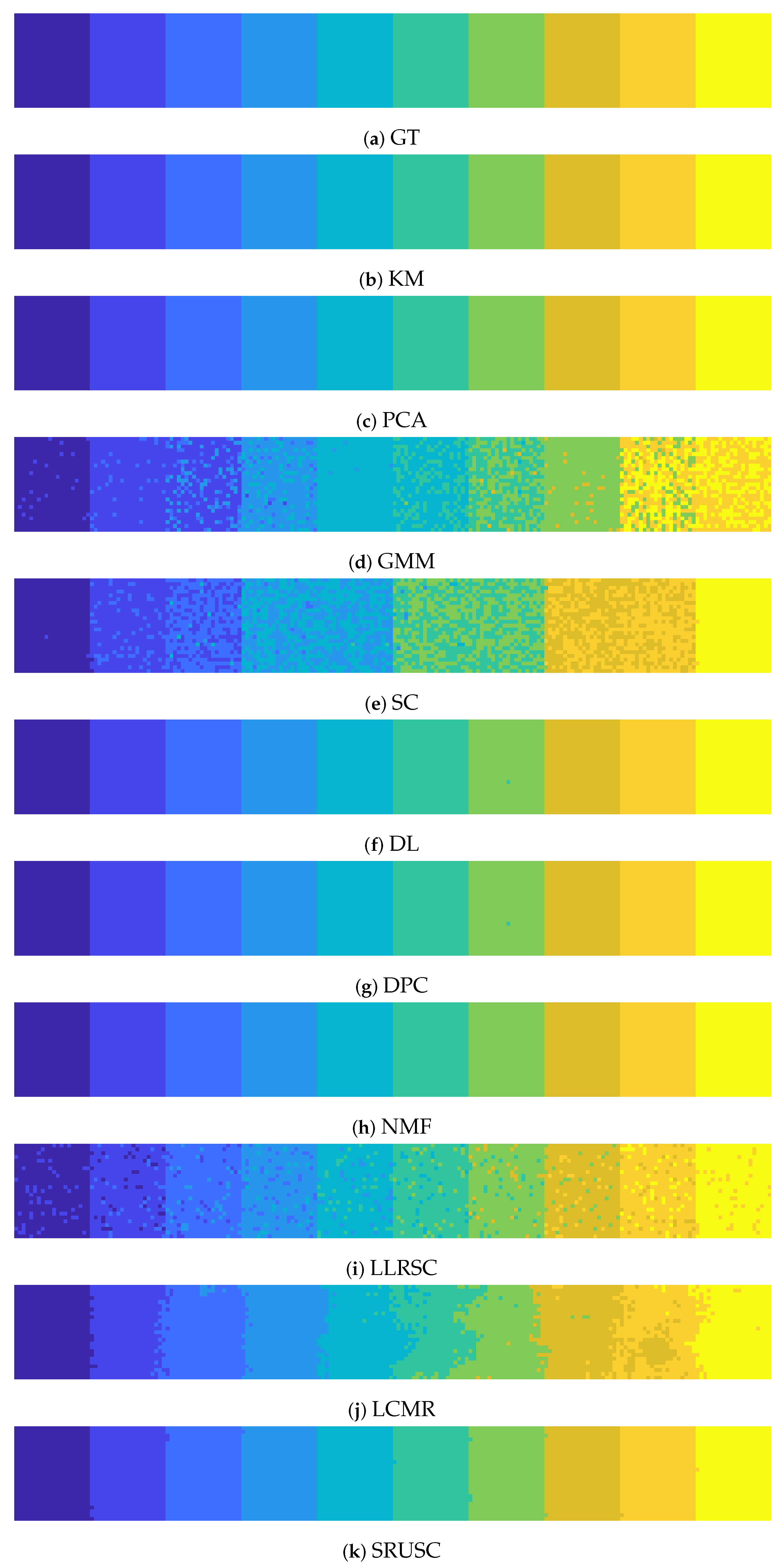
- We demonstrate that SRUSC effectively clusters synthetic and real HSI with higher accuracy than a range of benchmark and state-of-the-art methods. Moreover, we show that SRUSC efficiently estimates the number of clusters in these datasets, thereby addressing a major outstanding problem in the HSI clustering literature.
2. Background
2.1. Background on Unsupervised Clustering
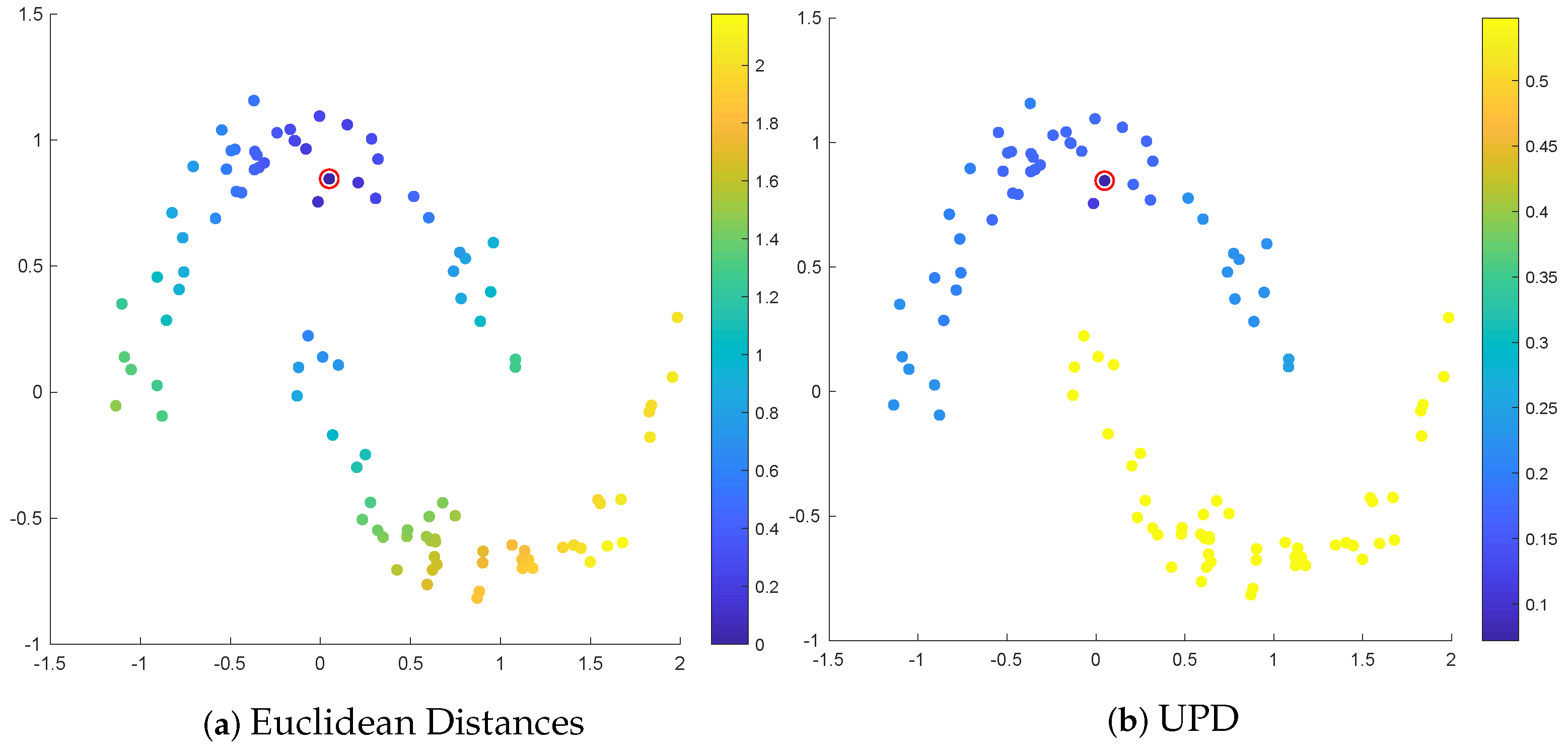
2.2. Background on Ultrametric Path Distances
2.3. Background on Spectral Clustering
| Algorithm 1 Spectral Clustering (SC) |
| Input:W, K; Output:
|
3. Algorithm
| Algorithm 2 Spatially Regularized Ultrametric SC (SRUSC), known |
| Input:); Output:
|
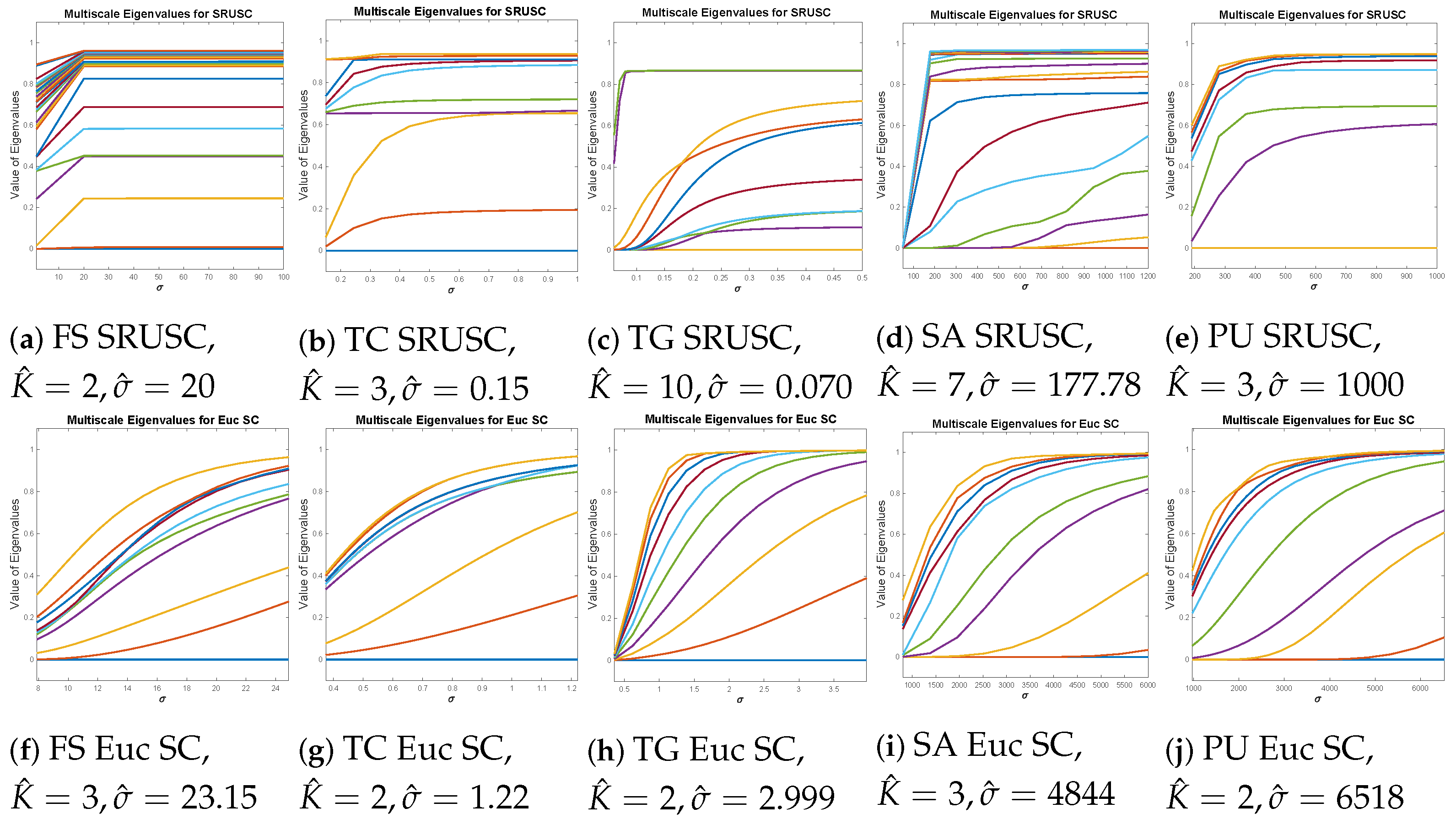
3.1. Discussion of Parameters
Estimation of K
| Algorithm 3 Spatially Regularized Ultrametric SC (SRUSC), unknown |
| Input:; Output:
|
3.2. Computational Complexity
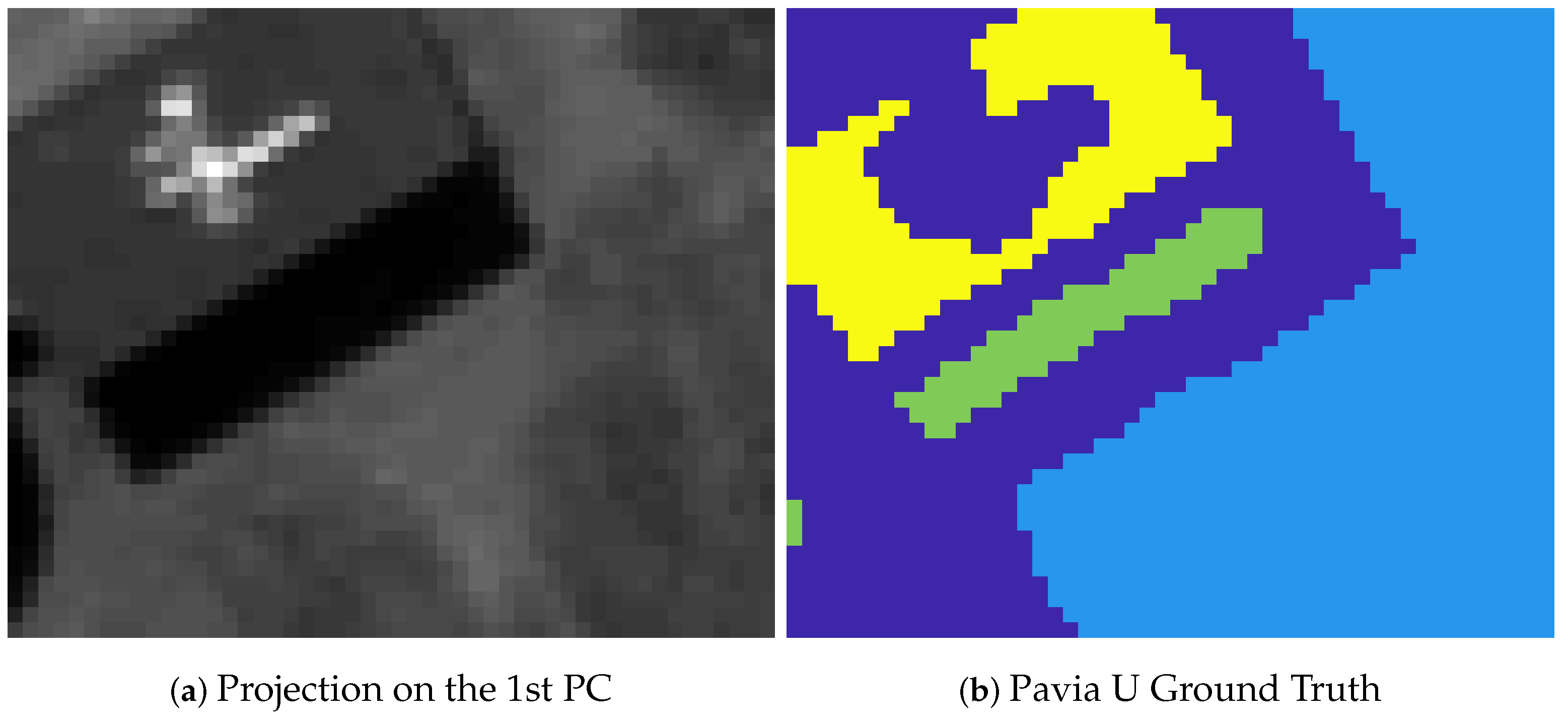
4. Experimental Analysis
4.1. Comparison Methods
- Density Peaks Clustering (DPC) (https://people.sissa.it/~laio/Research/Res_clustering.php, accessed on 1 January 2020) [15];
- Hierarchical Nonnegative Matrix Factorization (NMF) (https://sites.google.com/site/nicolasgillis/code, accessed on 1 January 2017) [22];
- Laplacian-Regularized Low-Rank Subspace Clustering (LLRSC) [20];
- Local Covariance Matrix Representation (LCMR) (https://github.com/henanjun/LCMR, accessed on 1 January 2020) [49]
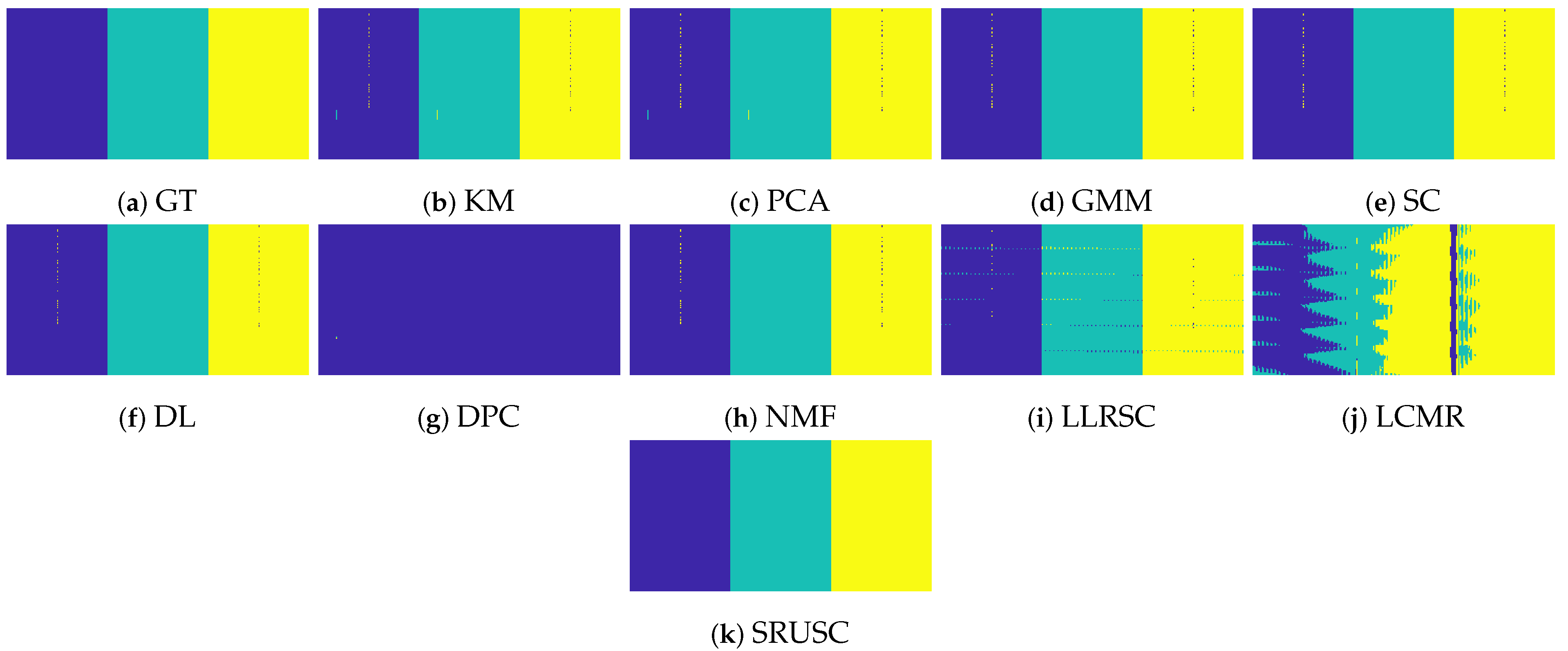
4.2. Clustering Accuracy
4.3. Discussion of Tunable Parameters
4.4. Estimation of Number of Clusters
4.5. Runtime
5. Conclusions and Future Research
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Camps-Valls, G.; Gomez-Chova, L.; Muñoz-Marí, J.; Vila-Francés, J.; Calpe-Maravilla, J. Composite kernels for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2006, 3, 93–97. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Fauvel, M.; Chanussot, J.; Benediktsson, J. SVM-and MRF-based method for accurate classification of hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2010, 7, 736–740. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Select. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Spectral–spatial feature extraction for hyperspectral image classification: A dimension reduction and deep learning approach. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4544–4554. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics; Springer: Berlin, Germany, 2001; Volume 1. [Google Scholar]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Advances in Neural Information Processing Systems; MIT: Cambridge, MA, USA, 2001; Volume 14, pp. 849–856. [Google Scholar]
- Baldi, P. Autoencoders, unsupervised learning, and deep architectures. In Proceedings of ICML Workshop on Unsupervised and Transfer Learning; JMLR Workshop and Conference Proceedings: Edinburgh, Scotland, 2012; pp. 37–49. [Google Scholar]
- Song, C.; Liu, F.; Huang, Y.; Wang, L.; Tan, T. Auto-encoder based data clustering. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin, Germany, 2013; pp. 117–124. [Google Scholar]
- Haeffele, B.; You, C.; Vidal, R. A critique of self-expressive deep subspace clustering. arXiv 2020, arXiv:2010.03697. [Google Scholar]
- Little, A.; Maggioni, M.; Murphy, J. Path-Based Spectral Clustering: Guarantees, Robustness to Outliers, and Fast Algorithms. J. Mach. Learn. Res. 2020, 21, 1–66. [Google Scholar]
- Le Moan, S.; Cariou, C. Minimax Bridgeness-Based Clustering for Hyperspectral Data. Remote Sens. 2020, 12, 1162. [Google Scholar] [CrossRef] [Green Version]
- Ester, M.; Kriegel, H.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Kdd; AAAI: New Orleans, LA, USA, 1996; Volume 96, pp. 226–231. [Google Scholar]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Bachmann, C.; Ainsworth, T.; Fusina, R. Exploiting manifold geometry in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2005, 43, 441–454. [Google Scholar] [CrossRef]
- Lunga, D.; Prasad, S.; Crawford, M.; Ersoy, O. Manifold-learning-based feature extraction for classification of hyperspectral data: A review of advances in manifold learning. IEEE Signal Proc. Mag. 2013, 31, 55–66. [Google Scholar] [CrossRef]
- Zhang, H.; Zhai, H.; Zhang, L.; Li, P. Spectral–spatial sparse subspace clustering for hyperspectral remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3672–3684. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Laplacian-regularized low-rank subspace clustering for hyperspectral image band selection. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1723–1740. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, C.; Mu, T.; Yan, T.; Chen, Z.; Wang, Y. An Efficient Representation-Based Subspace Clustering Framework for Polarized Hyperspectral Images. Remote Sens. 2019, 11, 1513. [Google Scholar] [CrossRef] [Green Version]
- Gillis, N.; Kuang, D.; Park, H. Hierarchical clustering of hyperspectral images using rank-two nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2066–2078. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Du, B.; You, J.; Tao, D. Hyperspectral image unsupervised classification by robust manifold matrix factorization. Inf. Sci. 2019, 485, 154–169. [Google Scholar] [CrossRef]
- Cahill, N.; Czaja, W.; Messinger, D. Schroedinger eigenmaps with nondiagonal potentials for spatial-spectral clustering of hyperspectral imagery. In Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XX; International Society for Optics and Photonics: Bellingham, DC, USA, 2014; Volume 9088, p. 908804. [Google Scholar]
- Zhao, Y.; Yuan, Y.; Wang, Q. Fast spectral clustering for unsupervised hyperspectral image classification. Remote Sens. 2019, 11, 399. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Nie, F.; Wang, Z.; He, F.; Li, X. Scalable graph-based clustering with nonnegative relaxation for large hyperspectral image. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7352–7364. [Google Scholar] [CrossRef]
- Murphy, J.; Maggioni, M. Unsupervised Clustering and Active Learning of Hyperspectral Images with Nonlinear Diffusion. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1829–1845. [Google Scholar] [CrossRef] [Green Version]
- Qin, Y.; Bruzzone, L.; Li, B. Learning discriminative embedding for hyperspectral image clustering based on set-to-set and sample-to-sample distances. IEEE Trans. Geosci. Remote Sens. 2019, 58, 473–485. [Google Scholar] [CrossRef]
- Sellami, A.; Abbes, A.; Barra, V.; Farah, I. Fused 3-D spectral-spatial deep neural networks and spectral clustering for hyperspectral image classification. Pattern Recogn. Lett. 2020, 138, 594–600. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, B.; Zhang, L.; Wang, S. A low-rank and sparse matrix decomposition-based Mahalanobis distance method for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1376–1389. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Chanussot, J.; Wei, Z. Joint reconstruction and anomaly detection from compressive hyperspectral images using Mahalanobis distance-regularized tensor RPCA. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2919–2930. [Google Scholar] [CrossRef]
- Heylen, R.; Scheunders, P. A distance geometric framework for nonlinear hyperspectral unmixing. IEEE J. Select. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1879–1888. [Google Scholar] [CrossRef]
- Wang, R.; Nie, F.; Yu, W. Fast spectral clustering with anchor graph for large hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2003–2007. [Google Scholar] [CrossRef]
- Murphy, J.; Maggioni, M. Spectral-spatial diffusion geometry for hyperspectral image clustering. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1243–1247. [Google Scholar] [CrossRef] [Green Version]
- McKenzie, D.; Damelin, S. Power weighted shortest paths for clustering Euclidean data. Found. Data Sci. 2019, 1, 307. [Google Scholar] [CrossRef] [Green Version]
- Arias-Castro, E. Clustering based on pairwise distances when the data is of mixed dimensions. IEEE Trans. Inf. Theory 2011, 57, 1692–1706. [Google Scholar] [CrossRef] [Green Version]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Zelnik-Manor, L.; Perona, P. Self-tuning spectral clustering. In Advances in Neural Information Processing Systems; MIT: Cambridge, MA, USA, 2005; pp. 1601–1608. [Google Scholar]
- Elhamifar, E.; Vidal, R. Sparse manifold clustering and embedding. In Advances in Neural Information Processing Systems; MIT: Cambridge, MA, USA, 2011; pp. 55–63. [Google Scholar]
- Arias-Castro, E.; Lerman, G.; Zhang, T. Spectral clustering based on local PCA. The J. Mach. Learn. Res. 2017, 18, 253–309. [Google Scholar]
- Schiebinger, G.; Wainwright, M.; Yu, B. The geometry of kernelized spectral clustering. Ann. Stat. 2015, 43, 819–846. [Google Scholar] [CrossRef] [Green Version]
- Little, A.; Byrd, A. A multiscale spectral method for learning number of clusters. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), IEEE, Miami, FL, USA, 9–11 December 2015; pp. 457–460. [Google Scholar]
- González-Barrios, J.; Quiroz, A. A clustering procedure based on the comparison between the k nearest neighbors graph and the minimal spanning tree. Stat. Probab. Lett. 2003, 62, 23–34. [Google Scholar] [CrossRef]
- Trefethen, L.; Bau, D. Numerical Linear Algebra; Siam: Philadelphia, PA, USA, 1997; Volume 50. [Google Scholar]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, W.; Chayes, V.; Tiard, A.; Sanchez, S.; Dahlberg, D.; Bertozzi, A.; Osher, S.; Zosso, D.; Kuang, D. Unsupervised classification in hyperspectral imagery with nonlocal total variation and primal-dual hybrid gradient algorithm. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2786–2798. [Google Scholar] [CrossRef]
- Bishop, C. Pattern Recognition and Machine Learning; Springer: Berlin, Germany, 2006. [Google Scholar]
- Maggioni, M.; Murphy, J. Learning by Unsupervised Nonlinear Diffusion. J. Mach. Learn. Res. 2019, 20, 1–56. [Google Scholar]
- Fang, L.; He, N.; Li, S.; Plaza, A.; Plaza, J. A new spatial–spectral feature extraction method for hyperspectral images using local covariance matrix representation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3534–3546. [Google Scholar] [CrossRef]
- Munkres, J. Algorithms for the assignment and transportation problems. J. Soc. Ind. Appl. Math. 1957, 5, 32–38. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, M.; Capozzoli, M.; McSweeney, L.; Sinha, D. Beyond kappa: A review of interrater agreement measures. Can. J. Stat. 1999, 27, 3–23. [Google Scholar] [CrossRef]
- Bijral, A.; Ratliff, N.; Srebro, N. Semi-supervised Learning with density based distances. In Proceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence, Barcelona, Spain, 14–17 July 2011; pp. 43–50. [Google Scholar]
- Maggioni, M.; Murphy, J. Learning by Active Nonlinear Diffusion. Found. Data Sci. 2019, 1, 271–291. [Google Scholar] [CrossRef] [Green Version]
- Murphy, J. Spatially regularized active diffusion learning for high-dimensional images. Pattern Recogn. Lett. 2020, 135, 213–220. [Google Scholar] [CrossRef]
- Najafipour, S.; Hosseini, S.; Hua, W.; Kangavari, M.; Zhou, X. SoulMate: Short-text author linking through Multi-aspect temporal-textual embedding. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef] [Green Version]
- Rousseeuw, P. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Davies, D.; Bouldin, D. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 2, 224–227. [Google Scholar] [CrossRef]
- Murphy, J.; Polk, S. A Multiscale Environment for Learning by Diffusion. arXiv 2021, arXiv:2102.00500. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | FS AA | TC AA | TG AA | SA AA | PU AA | FS OA | TC OA | TG OA | SA OA | PU OA | FS | TC | TG | SA | PU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| KM | 1.00 | 1.00 | 1.00 | 0.66 | 0.58 | 1.00 | 1.00 | 1.00 | 0.63 | 0.60 | 1.00 | 1.00 | 1.00 | 0.53 | 0.09 |
| PCA | 1.00 | 1.00 | 1.00 | 0.85 | 0.67 | 1.00 | 1.00 | 1.00 | 0.80 | 0.79 | 1.00 | 1.00 | 1.00 | 0.76 | 0.39 |
| GMM | 0.51 | 1.00 | 0.62 | 0.58 | 0.80 | 0.56 | 1.00 | 0.62 | 0.59 | 0.57 | 0.51 | 1.00 | 0.58 | 0.48 | 0.36 |
| SC | 1.00 | 1.00 | 0.58 | 0.72 | 1.00 | 1.00 | 1.00 | 0.58 | 0.76 | 1.00 | 1.00 | 1.00 | 0.53 | 0.69 | 1.00 |
| DL | 0.77 | 1.00 | 1.00 | 0.88 | 0.38 | 0.66 | 1.00 | 1.00 | 0.83 | 0.60 | 0.77 | 1.00 | 1.00 | 0.79 | 0.07 |
| DPC | 0.77 | 0.33 | 1.00 | 0.61 | 0.34 | 0.66 | 0.33 | 1.00 | 0.63 | 0.65 | 0.77 | 0.33 | 1.00 | 0.54 | 0.03 |
| NMF | 0.94 | 1.00 | 1.00 | 0.67 | 0.59 | 0.90 | 1.00 | 1.00 | 0.64 | 0.76 | 0.94 | 1.00 | 1.00 | 0.54 | 0.52 |
| LLRSC | 0.75 | 1.00 | 0.86 | 0.75 | 0.67 | 0.62 | 1.00 | 0.86 | 0.77 | 0.79 | 0.75 | 1.00 | 0.85 | 0.75 | 0.67 |
| LCMR | 0.94 | 0.62 | 0.89 | 0.79 | 0.99 | 0.94 | 0.62 | 0.89 | 0.76 | 0.99 | 0.95 | 0.62 | 0.88 | 0.71 | 0.98 |
| SRUSC | 1.00 | 1.00 | 1.00 | 0.89 | 1.00 | 1.00 | 1.00 | 1.00 | 0.85 | 1.00 | 1.00 | 1.00 | 1.00 | 0.81 | 1.00 |
| Data Set | FS | TC | TG | SA | PU |
|---|---|---|---|---|---|
| KM | 0.7718 | 0.4352 | 0.1532 | 0.3206 | 0.1590 |
| PCA | 0.0472 | 0.0411 | 0.0372 | 0.0788 | 0.0479 |
| GMM | 3.4639 | 2.1814 | 0.6806 | 1.3530 | 0.1662 |
| SC | 563.8514 | 1832.7 | 9.3997 | 56.2373 | 2.0211 |
| DL | 870.0409 | 1036.8 | 23.7778 | 13.3009 | 1.2118 |
| DPC | 748.5418 | 1062.2 | 21.8215 | 9.6928 | 0.4860 |
| NMF | 0.4553 | 0.7978 | 0.6298 | 0.6593 | 0.3272 |
| LLRSC | 1.6171 | 1.0303 | 0.4702 | 1.15 | 0.4793 |
| LCMR | 240.5580 | 131.4040 | 4.55611 | 35.2812 | 3.5041 |
| SRUSC | 1402.1 | 2971.6 | 25.3597 | 97.4420 | 6.0195 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Murphy, J.M. Hyperspectral Image Clustering with Spatially-Regularized Ultrametrics. Remote Sens. 2021, 13, 955. https://doi.org/10.3390/rs13050955
Zhang S, Murphy JM. Hyperspectral Image Clustering with Spatially-Regularized Ultrametrics. Remote Sensing. 2021; 13(5):955. https://doi.org/10.3390/rs13050955
Chicago/Turabian StyleZhang, Shukun, and James M. Murphy. 2021. "Hyperspectral Image Clustering with Spatially-Regularized Ultrametrics" Remote Sensing 13, no. 5: 955. https://doi.org/10.3390/rs13050955
APA StyleZhang, S., & Murphy, J. M. (2021). Hyperspectral Image Clustering with Spatially-Regularized Ultrametrics. Remote Sensing, 13(5), 955. https://doi.org/10.3390/rs13050955