
Feature-Level Fusion of Polarized SAR and Optical Images Based on Random Forest and Conditional Random Fields




Abstract
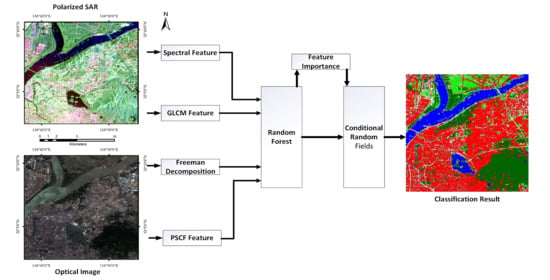
:
1. Introduction
2. Materials
2.1. Study Site
2.2. Sampling Point Selection
3. Characteristic Data Acquisition
3.1. Polarization Feature Extraction
3.1.1. Freeman-Durden Decomposition
3.1.2. Polarization Signature Correlation Feature (PSCF)
3.2. Optical Image Feature Extraction
3.2.1. Spectral Information Extraction
3.2.2. Grey-Level Co-Occurrence Matrix (GLCM)
4. Random Forest-Importance_Conditional Random Forest (RF-Im_CRF) Model
4.1. Random Forest
4.2. Conditional Random Fields
4.3. RF-Im_CRF Model
4.3.1. Establishment of Potential Functions
4.3.2. Feature Importance
5. Experiment and Analysis
5.1. Multi-Source Data Comparative Classification Experiment
5.2. Comparison of RF-Im_CRF Model Experiment Results
5.2.1. Analysis of Classified Image Results
5.2.2. Classification Data Analysis
5.2.3. Analysis of Feature Importance
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Aswatha, S.M.; Mukherjee, J.; Biswas, P.K.; Aikat, S. Unsupervised classification of land cover using multi-modal data from mul-ti-spectral and hybrid-polarimetric SAR imageries. Int. J. Remote Sens. 2020, 41, 5277–5304. [Google Scholar] [CrossRef]
- Hall, D.K.; Riggs, G.A.; Salomonson, V.V. Development of methods for mapping global snow cover using moderate resolution imaging spectroradiometer data. Remote Sens. Environ. 1995, 54, 127–140. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, Q.; Li, A.; Liang, C.Z. Historical landscape dynamics of Inner Mongolia: Patterns, drivers, and impacts. Landsc. Ecol. 2015, 30, 1579–1598. [Google Scholar] [CrossRef]
- Useya, J.; Chen, S. Exploring the Potential of Mapping Cropping Patterns on Smallholder Scale Croplands Using Sentinel-1 SAR Data. Chin. Geogr. Sci. 2019, 29, 626–639. [Google Scholar] [CrossRef] [Green Version]
- Neetu; Ray, S.S. Evaluation of different approaches to the fusion of Sentinel -1 SAR data and Resourcesat 2 LISS III optical data for use in crop classification. Remote Sens. Lett. 2020, 11, 1157–1166. [Google Scholar] [CrossRef]
- Malthus, T.J.; Madeira, A.C. High resolution spectroradiometry: Spectral reflectance of field bean leaves infected by Botrytis fabae. Remote Sens. Environ. 1993, 45, 107–116. [Google Scholar] [CrossRef]
- Sun, J.; Mao, S. River detection algorithm in SAR images based on edge extraction and ridge tracing techniques. Int. J. Remote Sens. 2011, 32, 3485–3494. [Google Scholar] [CrossRef]
- Pohl, C.; Genderen, J.L. Review Article Multisensor Image Fusion in Remote Sensing: Concepts, Methods and Applications. Int. J. Remote Sens. 1998, 19, 823–854. [Google Scholar] [CrossRef] [Green Version]
- Su, R.; Tang, Y. Feature Fusion and Classification of Optical-PolSAR Images. Geomat. Spat. Inf. Technol. 2019, 42, 51–55. [Google Scholar]
- Zhang, L.; Zou, B.; Zhang, J.; Zhang, Y. Classification of Polarimetric SAR Image Based on Support Vector Machine Using Multiple-Component Scattering Model and Texture Features. EURASIP J. Adv. Signal Process. 2010, 2010, 960831. [Google Scholar] [CrossRef] [Green Version]
- Ojala, T.; Pietiainen, M.; Harwood, D. A Comparative Study of Texture Measures with Classification Based on Feature Distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. In IEEE Transactions on Systems, Man, and Cybernetics; IEEE: New York, NY, USA, 1973; Volume SMC-3, pp. 610–621. [Google Scholar] [CrossRef] [Green Version]
- Dong, J. Statistical Analysis of Polarization SAR Image Features and Research on Classification Algorithm; Wuhan University: Wuhan, China, 2018. [Google Scholar]
- Freeman, A.; Durden, S.L. A three-component scattering model for polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef] [Green Version]
- Sato, A.; Yamaguchi, Y.; Singh, G.; Park, S.E. Four-Component Scattering Power Decomposition with Extended Volume Scattering Model. IEEE Geosci. Remote Sens. Lett. 2012, 9, 166–170. [Google Scholar] [CrossRef]
- Attarchi, S. Extracting impervious surfaces from full polarimetric SAR images in different urban areas. Int. J. Remote Sens. 2020, 41, 4644–4663. [Google Scholar] [CrossRef]
- Phartiyal, G.S.; Kumar, K.; Singh, D. An improved land cover classification using polarization signatures for PALSAR 2 data. Adv. Space Res. 2020, 65, 2622–2635. [Google Scholar] [CrossRef]
- Breiman, L. Manual on Setting Up, Using, and Understanding Random Forests V3.1 [EB/OL]; Statistics Department University of California Berkley: Berkley, CA, USA, 2002. [Google Scholar]
- Du, P.; Samat, A.; Waske, B.; Liu, S.; Li, Z. Random Forest and Rotation Forest for fully polarized SAR image classification using po-larimetric and spatial features. ISPRS J. Photogramm. Remote Sens. 2015, 105, 38–53. [Google Scholar] [CrossRef]
- Sutton, C.; Mccallum, A. An Introduction to Conditional Random fields. Found. Trends Mach. Learn. 2010, 4, 267–373. [Google Scholar] [CrossRef]
- Zhong, Y.; Jia, T.; Ji, Z.; Wang, X.; Jin, S. Spatial-Spectral-Emissivity Land-Cover Classification Fusing Visible and Thermal Infrared Hyperspectral Imagery. Remote Sens. 2017, 9, 910. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Zhou, X.; Zhu, X.; Dong, Z.; Guo, W. Estimation of biomass in wheat using random forest regression algorithm and remote sensing data. Crop J. 2016, 4, 212–219. [Google Scholar] [CrossRef] [Green Version]
- Harold, M. The Kennaugh matrix. In Remote Sensing with Polarimetric Radar, 1st ed.; John Wiley & Sons: Hoboken, NJ, USA, 2007; pp. 295–298. [Google Scholar]
- Lee, J.S.; Grunes, M.R.; Boerner, W.M. Polarimetric property preservation in SAR speckle filtering. In Proceedings of SPIE 3120, Wideband Interferometric Sensing and Imaging Polarimetry; Mott, H., Ed.; SPIE: San Diego, CA, USA, 1997; pp. 1–7. [Google Scholar]
- Lee, J.S.; Pottier, E. Electromagnetic vector scattering operators. In Polarimetric Radar Imaging: From Basics to Applications, 1st ed.; Thompson, B.J., Ed.; CRC Press: New York, NY, USA, 2009; pp. 92–98. [Google Scholar]
- Menze, B.; Kelm, B.; Masuch, R.; Himmelreich, U.; Bachert, P.; Petrich, W.; Hamprecht, F. A comparison of random forest and its Gini importance with standard chemometric methods for the feature selection and classification of spectral data. BMC Bioinform. 2009, 10, 213. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics (Oxf. Engl.) 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [PubMed]
- Strobl, C.; Boulesteix, A.L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label Category | Train Number | Test Number |
|---|---|---|
| Water | 100 | 150 |
| High vegetation | 100 | 150 |
| Building | 100 | 150 |
| Low vegetation | 100 | 150 |
| Road | 100 | 150 |
| Total | 500 | 750 |
| SVM | RF | RF-CRF | RF-Im_CRF | |
|---|---|---|---|---|
| OA | 79% | 88.0% | 91.6% | 94.0% |
| 95% confidence interval | [85.88%,90.4%] | [90.22%,93.02%] | [93.52%,94.54%] | |
| Kappa | 0.74 | 0.85 | 0.89 | 0.91 |
| 95% confidence interval | [0.834,0.866] | [0.879,0.905] | [0.902,0.918] |
| Model | Water | High | Building | Low | Road | |
|---|---|---|---|---|---|---|
| Precision (%) | 87 | 85 | 72 | 79 | 74 | |
| Recall (%) | 77 | 88 | 84 | 84 | 63 | |
| F1-score (%) | 82 | 86 | 78 | 81 | 70 | |
| RF | Precision (%) | 98 | 92 | 79 | 85 | 78 |
| Recall (%) | 95 | 93 | 91 | 81 | 72 | |
| F1-score (%) | 96 | 92 | 85 | 83 | 75 | |
| RF-CRF | Precision (%) | 99 | 96 | 80 | 90 | 82 |
| Recall (%) | 95 | 95 | 93 | 88 | 75 | |
| F1-score (%) | 97 | 95 | 86 | 89 | 78 | |
| RF-Im_CRF | Precision (%) | 100 | 97 | 84 | 93 | 88 |
| Recall (%) | 95 | 96 | 97 | 89 | 84 | |
| F1-score (%) | 97 | 96 | 90 | 91 | 86 |
| Feature | Freeman | Spectral | GLCM | PSCF |
|---|---|---|---|---|
| (%) | 33.78 | 30.03 | 13.44 | 22.72 |
| Class | Pd | Ps | Pv | R | G | B | G1 | G2 | G3 | P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
(%) | 7.35 | 5.91 | 20.53 | 8.94 | 9.15 | 11.96 | 3.11 | 2.84 | 7.49 | 3.93 | 2.93 | 2.14 | 2.01 | 3.95 | 2.30 | 2.74 | 2.74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, Y.; Yan, B.; Liu, Y.; Leung, H.; Peng, X. Feature-Level Fusion of Polarized SAR and Optical Images Based on Random Forest and Conditional Random Fields. Remote Sens. 2021, 13, 1323. https://doi.org/10.3390/rs13071323
Kong Y, Yan B, Liu Y, Leung H, Peng X. Feature-Level Fusion of Polarized SAR and Optical Images Based on Random Forest and Conditional Random Fields. Remote Sensing. 2021; 13(7):1323. https://doi.org/10.3390/rs13071323
Chicago/Turabian StyleKong, Yingying, Biyuan Yan, Yanjuan Liu, Henry Leung, and Xiangyang Peng. 2021. "Feature-Level Fusion of Polarized SAR and Optical Images Based on Random Forest and Conditional Random Fields" Remote Sensing 13, no. 7: 1323. https://doi.org/10.3390/rs13071323