
Assessing the Effect of Training Sampling Design on the Performance of Machine Learning Classifiers for Land Cover Mapping Using Multi-Temporal Remote Sensing Data and Google Earth Engine



Abstract
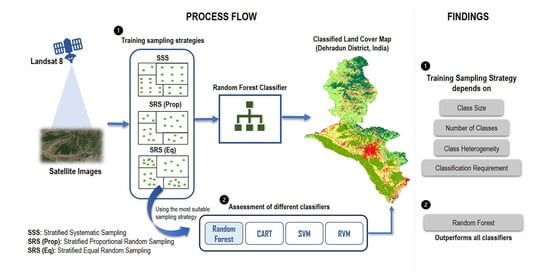
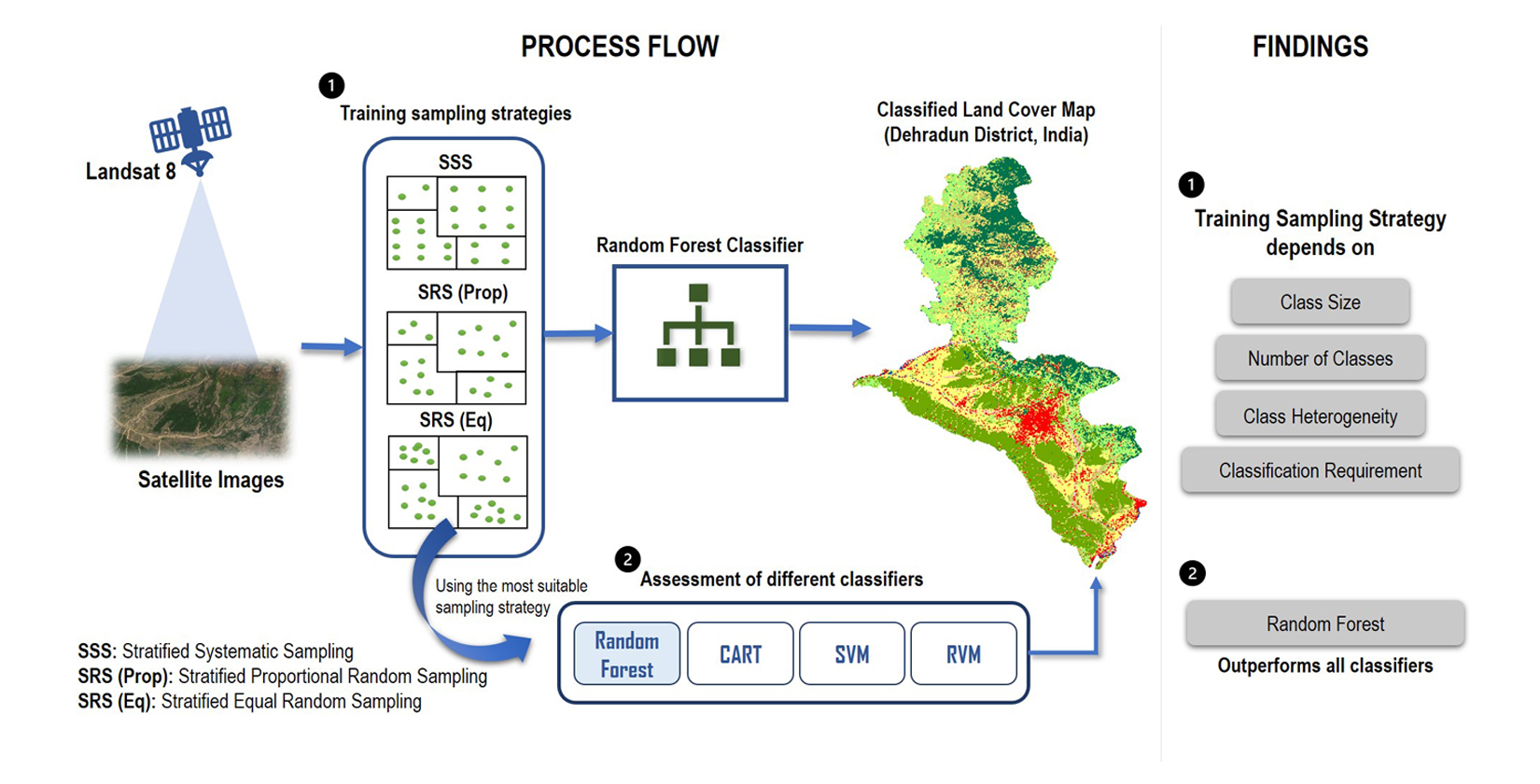
1. Introduction
2. Materials and Methods
2.1. Study Area and Datasets
2.2. Methodology
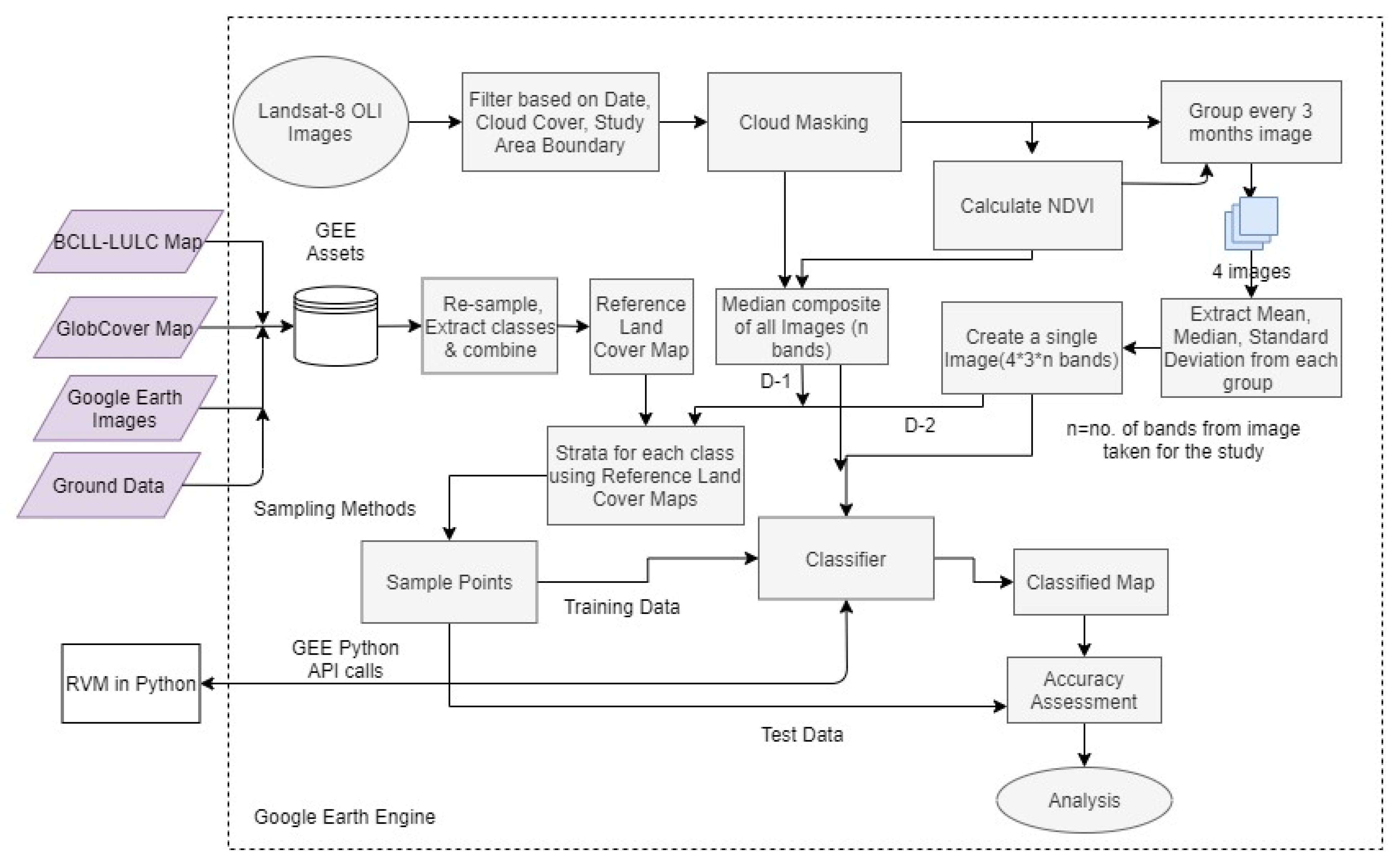
2.2.1. Preparation of Reference Land Cover Maps
2.2.2. Preparation of Multi-Temporal Remote Sensing Data
2.2.3. Training Data Sampling Design
Stratified Random Sampling
Stratified Systematic Sampling
2.2.4. Classification Using In-Built Classifiers in Google Earth Engine
2.2.5. Integrating Relevance Vector Machine Classifier with Google Earth Engine
- (a)
- A polynomial basis kernel function is defined, which is initialized to 1;
- (b)
- A sparsity factor is calculated to determine the extent of overlap of basis vectors;
- (c)
- A quality factor is calculated using the variance of the kernel function with the probabilistic output of the training dataset;
- (d)
- The posterior probability distribution is calculated using Sigmoid and Gaussian convolution to determine α;
- (e)
- If α = ∞, then the corresponding basis vector is retained; and
- (f)
- If α < ∞ and the quality factor is less than the sparsity factor, then the basis vector is removed.
2.2.6. Accuracy Assessment of the Classified Outputs
3. Results
3.1. Reference Land Cover Map
3.2. Effect of Sampling Design on the Classification Results
3.2.1. Stratified Random Sampling
3.2.2. Stratified Systematic Sampling
3.3. Performance of the Evaluated Machine Learning Classifiers
3.4. Application of Relevance Vector Machine (RVM) for Land Cover Classification
4. Discussion
5. Conclusions
- Among the sampling techniques assessed using the RF classifier, the SRS(Prop) method produced the highest OA but obtained less satisfactory results for the underrepresented, i.e., minority, land cover classes. The SRS(Eq) method achieved a slightly lower OA but mapped minority classes with good accuracy. The performance of the SSS method increased significantly after applying the SSA+MMSD on the initial distribution of training sample points. In this method, the producer’s and user’s accuracies for all classes were consistently good for different datasets, but the OA was lower than the SRS(Eq) method. We concluded that the training sampling method should be chosen based on the class size and classification requirement: the SRS(Prop) method is recommended when the difference between the size of target classes is small, whereas the SRS(Eq) method should be applied for obtaining good accuracies at individual class levels, irrespective of their areal extent. The SSS method using SSA+MMSD techniques can be successfully used in case of large intra-class variability. Given the high performance of RF and Artificial Neural Networks for land cover mapping [21] and the importance of understanding training sampling strategies from the current work, future research is recommended to assess the effect of sampling strategies on the performance of deep neural networks. Given the limited number of training samples available for our study area, deep neural network assessments fall beyond the scope of this research.
- The RF and CART classifiers performed relatively well for different sizes of training samples. However, the SVM and RVM classifiers showed a decrease in performance when increasing the training sample size. The RF classifier outperformed other classifiers for all the training sample sizes and datasets. The performance of CART and SVM are found to be similar in this study. The potential of the RVM classifier should be further explored for land cover classification, especially due to its capability to provide information about the classification uncertainties.
- RF and CART classifiers proved to be less sensitive to the quality of training samples as compared to the kernel-based SVM and RVM classifiers. The robustness of the RF classifier to the training sample quality is as an additional advantage besides its overall higher performance.
- The performance of the RF and RVM classifiers proved to improve significantly as compared to the CART and SVM classifiers when the dataset with additional features such as seasonal variations represented by statistical measures, in terms of temporal variability in spectral signatures, was used as input variables.
- The availability of multi-dimensional remote sensing data, processing capability, and flexibility to integrate with external programs makes GEE a vital platform for land cover mapping and monitoring the change. The inclusion of geostatistical tools would further strengthen its functionality.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Luan, X.-L.; Buyantuev, A.; Baur, A.H.; Kleinschmit, B.; Wang, H.; Wei, S.; Liu, M.; Xu, C. Linking greenhouse gas emissions to urban landscape structure: The relevance of spatial and thematic resolutions of land use/cover data. Landsc. Ecol. 2018, 33, 1211–1224. [Google Scholar] [CrossRef]
- Roy, P.S.; Roy, A.; Joshi, P.K.; Kale, M.P.; Srivastava, V.K.; Srivastava, S.K.; Dwevidi, R.S.; Joshi, C.; Behera, M.D.; Meiyappan, P.; et al. Development of Decadal (1985–1995–2005) Land Use and Land Cover Database for India. Remote Sens. 2015, 7, 2401–2430. [Google Scholar] [CrossRef]
- Jalkanen, J.; Toivonen, T.; Moilanen, A. Identification of ecological networks for land-use planning with spatial conservation prioritization. Landsc. Ecol. 2019, 35, 353–371. [Google Scholar] [CrossRef]
- Shalaby, A.; Tateishi, R. Remote sensing and GIS for mapping and monitoring land cover and land-use changes in the Northwestern coastal zone of Egypt. Appl. Geogr. 2007, 27, 28–41. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef]
- Yu, L.; Liang, L.; Wang, J.; Zhao, Y.; Cheng, Q.; Hu, L.; Liu, S.; Yu, L.; Wang, X.; Zhu, P.; et al. Meta-discoveries from a synthesis of satellite-based land-cover mapping research. Int. J. Remote Sens. 2014, 35, 4573–4588. [Google Scholar] [CrossRef]
- Ghimire, B.; Rogan, J.; Galiano, V.R.; Panday, P.; Neeti, N. An Evaluation of Bagging, Boosting, and Random Forests for Land-Cover Classification in Cape Cod, Massachusetts, USA. GIScience Remote Sens. 2012, 49, 623–643. [Google Scholar] [CrossRef]
- Foody, G.; Mathur, A. A relative evaluation of multiclass image classification by support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1335–1343. [Google Scholar] [CrossRef]
- Nery, T.; Sadler, R.; Solis-Aulestia, M.; White, B.; Polyakov, M.; Chalak, M. Comparing supervised algorithms in Land Use and Land Cover classification of a Landsat time-series. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 5165–5168. [Google Scholar]
- Tso, B.; Mather, P.M. Classification Methods for Remotely Sensed Data, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Friedl, M.A.; McIver, D.K.; Baccini, A.; Gao, F.; Schaaf, C.; Hodges, J.C.F.; Zhang, X.Y.; Muchoney, D.; Strahler, A.H.; Woodcock, C.E.; et al. Global land cover mapping from MODIS: Algorithms and early results. Remote Sens. Environ. 2002, 83, 287–302. [Google Scholar] [CrossRef]
- Lawrence, R.L.; Wrlght, A. Rule-Based Classification Systems Using Classification and Regression Tree (CART) Analysis. Photogramm. Eng. Remote Sens. 2001, 67, 1137–1142. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random Forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A.; Sanchez-Hernandez, C.; Boyd, D.S. Training set size requirements for the classification of a specific class. Remote Sens. Environ. 2006, 104, 1–14. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse Bayesian Learning and the Relevance Vector Machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Pal, M.; Foody, G.M. Evaluation of SVM, RVM and SMLR for Accurate Image Classification with Limited Ground Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1344–1355. [Google Scholar] [CrossRef]
- Foody, G.M. RVM-Based Multi-Class Classification of Remotely Sensed Data. Int. J. Remote Sens. 2008, 29, 1817–1823. [Google Scholar] [CrossRef]
- Talukdar, S.; Singha, P.; Mahato, S.; Pal, S.; Liou, Y.-A.; Rahman, A. Land-Use Land-Cover Classification by Machine Learning Classifiers for Satellite Observations—A Review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef]
- Rostami, M.; Kolouri, S.; Eaton, E.; Kim, K. Deep Transfer Learning for Few-Shot SAR Image Classification. Remote Sens. 2019, 11, 1374. [Google Scholar] [CrossRef]
- Bejiga, M.B.; Melgani, F.; Beraldini, P. Domain Adversarial Neural Networks for Large-Scale Land Cover Classification. Remote Sens. 2019, 11, 1153. [Google Scholar] [CrossRef]
- Heydari, S.S.; Mountrakis, G. Effect of classifier selection, reference sample size, reference class distribution and scene heterogeneity in per-pixel classification accuracy using 26 Landsat sites. Remote Sens. Environ. 2018, 204, 648–658. [Google Scholar] [CrossRef]
- Jin, H.; Stehman, S.V.; Mountrakis, G. Assessing the impact of training sample selection on accuracy of an urban classification: A case study in Denver, Colorado. Int. J. Remote Sens. 2014, 35, 2067–2081. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B.; Walvoort, D.J. The variance quadtree algorithm: Use for spatial sampling design. Comput. Geosci. 2007, 33, 383–392. [Google Scholar] [CrossRef]
- Beuchle, R.; Grecchi, R.C.; Shimabukuro, Y.E.; Seliger, R.; Eva, H.D.; Sano, E.; Achard, F. Land cover changes in the Brazilian Cerrado and Caatinga biomes from 1990 to 2010 based on a systematic remote sensing sampling approach. Appl. Geogr. 2015, 58, 116–127. [Google Scholar] [CrossRef]
- Montanari, R.; Souza, G.S.A.; Pereira, G.T.; Marques, J.; Siqueira, D.S.; Siqueira, G.M. The use of scaled semivariograms to plan soil sampling in sugarcane fields. Precis. Agric. 2012, 13, 542–552. [Google Scholar] [CrossRef]
- Van Groenigen, J.W.; Stein, A. Constrained Optimization of Spatial Sampling using Continuous Simulated Annealing. J. Environ. Qual. 1998, 27, 1078–1086. [Google Scholar] [CrossRef]
- Chen, B.; Pan, Y.; Wang, J.; Fu, Z.; Zeng, Z.; Zhou, Y.; Zhang, Y. Even sampling designs generation by efficient spatial simulated annealing. Math. Comput. Model. 2013, 58, 670–676. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Midekisa, A.; Holl, F.; Savory, D.J.; Andrade-Pacheco, R.; Gething, P.W.; Bennett, A.; Sturrock, H.J.W. Mapping land cover change over continental Africa using Landsat and Google Earth Engine cloud computing. PLoS ONE 2017, 12, e0184926. [Google Scholar] [CrossRef] [PubMed]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-resolution global maps of 21st-century forest cover change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef]
- Goldblatt, R.; You, W.; Hanson, G.; Khandelwal, A.K. Detecting the Boundaries of Urban Areas in India: A Dataset for Pixel-Based Image Classification in Google Earth Engine. Remote Sens. 2016, 8, 634. [Google Scholar] [CrossRef]
- Patel, N.N.; Angiuli, E.; Gamba, P.; Gaughan, A.; Lisini, G.; Stevens, F.R.; Tatem, A.J.; Trianni, G. Multitemporal settlement and population mapping from Landsat using Google Earth Engine. Int. J. Appl. Earth Obs. Geoinf. 2015, 35, 199–208. [Google Scholar] [CrossRef]
- Trianni, G.; Angiuli, E.; Lisini, G.; Gamba, P. Human settlements from Landsat data using Google Earth Engine. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 1473–1476. [Google Scholar]
- Aguilar, R.; Zurita-Milla, R.; Izquierdo-Verdiguier, E.; De By, R.A. A Cloud-Based Multi-Temporal Ensemble Classifier to Map Smallholder Farming Systems. Remote Sens. 2018, 10, 729. [Google Scholar] [CrossRef]
- Dong, J.; Xiao, X.; Menarguez, M.A.; Zhang, G.; Qin, Y.; Thau, D.; Biradar, C.; Moore, B. Mapping paddy rice planting area in northeastern Asia with Landsat 8 images, phenology-based algorithm and Google Earth Engine. Remote Sens. Environ. 2016, 185, 142–154. [Google Scholar] [CrossRef] [PubMed]
- Shelestov, A.; Lavreniuk, M.; Kussul, N.; Novikov, A.; Skakun, S. Exploring Google Earth Engine Platform for Big Data Processing: Classification of Multi-Temporal Satellite Imagery for Crop Mapping. Front. Earth Sci. 2017, 5, 17. [Google Scholar] [CrossRef]
- Becker, W.R.; Ló, T.B.; Johann, J.A.; Mercante, E. Statistical features for land use and land cover classification in Google Earth Engine. Remote Sens. Appl. Soc. Environ. 2021, 21, 100459. [Google Scholar] [CrossRef]
- Padarian, J.; Minasny, B.; McBratney, A. Using Google’s cloud-based platform for digital soil mapping. Comput. Geosci. 2015, 83, 80–88. [Google Scholar] [CrossRef]
- ESA. Land Cover CCI Product User Guide Version 2. Tech. Rep. Available online: http://maps.elie.ucl.ac.be/CCI/viewer/download/ESACCI-LC-Ph2-PUGv2_2.0.pdf (accessed on 7 June 2020).
- Roy, P.S.; Kushwaha, S.; Murthy, M.; Roy, A. Biodiversity Characterisation at Landscape Level: National Assessment; Indian Institute of Remote Sensing, ISRO: Dehradun, India, 2012; ISBN 81-901418-8-0.
- Loveland, T.; Belward, A. The International Geosphere Biosphere Programme Data and Information System global land cover data set (DISCover). Acta Astronaut. 1997, 41, 681–689. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- J., J.E. Sampling Techniques. Technometrics 1978, 20, 104. [Google Scholar] [CrossRef]
- McBratney, A.; Webster, R.; Burgess, T. The design of optimal sampling schemes for local estimation and mapping of of regionalized variables—I. Comput. Geosci. 1981, 7, 331–334. [Google Scholar] [CrossRef]
- Samuel-Rosa, A.; Heuvelink, G.; Vasques, G.; Anjos, L. Spsann–Optimization of Sample Patterns Using Spatial Simulated Annealing. EGU Gen. Assem. 2015, 7780, 17. [Google Scholar]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. Int. Jt. Conf. Artif. Intell. 1995, 14, 1137–1145. [Google Scholar]
- Yang, C.; Odvody, G.N.; Fernandez, C.J.; Landivar, J.A.; Minzenmayer, R.R.; Nichols, R.L. Evaluating unsupervised and supervised image classification methods for mapping cotton root rot. Precis. Agric. 2015, 16, 201–215. [Google Scholar] [CrossRef]
- Tipping, M.E.; Faul, A.C. Fast Marginal Likelihood Maximisation for Sparse Bayesian Models. In Proceedings of the Ninth International Workshop on Artificial Intelligence and Statistics, Key West, FL, USA, 3–6 January 2003. [Google Scholar]
- Shetty, S.; Gupta, P.K.; Belgiu, M.; Srivastav, S.K. Analysis of Machine Learning Classifiers for LULC Classification on Google Earth Engine; University of Twente (ITC): Enschede, The Netherlands, 2019. [Google Scholar]
- Shaumyan, A. Python Package for Bayesian Machine Learning with Scikit-Learn API. Available online: https://github.com/AmazaspShumik/sklearn-bayes (accessed on 16 January 2018).
- Panyam, J.; Lof, J.; O’Leary, E.; Labhasetwar, V. Efficiency of Dispatch ® and Infiltrator ® Cardiac Infusion Catheters in Arterial Localization of Nanoparticles in a Porcine Coronary Model of Restenosis. J. Drug Target. 2002, 10, 515–523. [Google Scholar] [CrossRef]
- Heung, B.; Ho, H.C.; Zhang, J.; Knudby, A.; Bulmer, C.E.; Schmidt, M.G. An overview and comparison of machine-learning techniques for classification purposes in digital soil mapping. Geoderma 2016, 265, 62–77. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. Support vector machines for classification in remote sensing. Int. J. Remote Sens. 2005, 26, 1007–1011. [Google Scholar] [CrossRef]
- Xiong, K.; Adhikari, B.R.; Stamatopoulos, C.A.; Zhan, Y.; Wu, S.; Dong, Z.; Di, B. Comparison of Different Machine Learning Methods for Debris Flow Susceptibility Mapping: A Case Study in the Sichuan Province, China. Remote Sens. 2020, 12, 295. [Google Scholar] [CrossRef]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- Foody, G.M.; Pal, M.; Rocchini, D.; Garzon-Lopez, C.X.; Bastin, L. The Sensitivity of Mapping Methods to Reference Data Quality: Training Supervised Image Classifications with Imperfect Reference Data. ISPRS Int. J. Geo-Inf. 2016, 5, 199. [Google Scholar] [CrossRef]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring issues of training data imbalance and mislabelling on random forest performance for large area land cover classification using the ensemble margin. ISPRS J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Tuteja, U. Baseline Data on Horticultural Crops in Uttarakhand; Agricultural Economics Research Centre, University of Delhi: Delhi, India, 2013. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset D-1 | Median band values of B, G, R, NIR, NDVI bands |
| Dataset D-2 | Mean, Median, Standard Deviation of B, G, R, NIR, NDVI bands within 3-month groups of 2017 |
| Classifier | Parameter | Values | Supporting Reference |
|---|---|---|---|
| CART | Cross-Validation Factor for Pruning | 5 and 10 | [50] |
| RF | Number of Trees Number of Variables per Split | 50, 100, 150, 200 Square root of input variables (√60, √5) | [46] |
| SVM | Kernel Type Cost Parameter SVM Type | Linear 210, 211, 3510, 212, 213, 214, 215 C_SVC | [51] |
| Land Cover Map | BU | CL | EF | DF | SL | GL | WB | RB * | FL # |
|---|---|---|---|---|---|---|---|---|---|
| Producer’s Accuracy (%) | |||||||||
| Globcover | 89.77 ± 2.32 | 78.63 ± 4.33 | 90.88 ± 2.35 | 55.96 ± 1.92 | 46.83 ± 10.11 | 34.18 ± 19.41 | 98.11 ± 1.19 | - | - |
| BCLL-LULC | 84.28 ± 2.74 | 76.43 ± 2.60 | 91.08 ± 2.43 | 73.14 ± 3.25 | 56.66 ± 3.55 | 70.64 ± 8.69 | 96.73 ± 3.15 | 55.02 ± 2.26 | - |
| New Reference | 85.97 ± 2.69 | 77.24 ± 3.47 | 98.67 ± 0.94 | 90.51 ± 2.37 | 73.29 ± 2.63 | 58.34 ± 2.50 | 69.42 ± 8.65 | 100 ± 0.00 | 98.55 ± 1.07 |
| User’s Accuracy (%) | |||||||||
| Globcover | 100 ± 0.00 | 66.92 ± 3.90 | 85.41 ± 3.22 | 95.73 ± 2.66 | 13.55 ± 4.46 | 2.32 ± 1.43 | 100 ± 0.00 | - | - |
| BCLL-LULC | 94.32 ± 2.22 | 84.94 ± 3.03 | 97.60 ± 1.46 | 99.58 ± 0.66 | 67.81 ± 4.04 | 13.42 ± 3.27 | 41.99 ± 4.49 | 76.59 ± 4.50 | - |
| New Reference | 93.65 ± 2.28 | 94.45 ± 2.49 | 100 ± 0.00 | 97.87 ± 1.52 | 99.13 ± 0.83 | 69.16 ± 4.38 | 14.68 ± 3.57 | 100 ± 0.00 | 82.52 ± 3.13 |
| Sample Size | Overall Accuracy (%) with Standard Deviation (%) | |||
|---|---|---|---|---|
| SRS(Eq) | SRS(Prop) | |||
| D-1 | D-2 | D-1 | D-2 | |
| 3222 | 63.62 ± 0.4 | 77.38 ± 0.4 | 76.07 ± 1 | 82.33 ± 0.9 |
| 9000 | 64.7 ± 0.3 | 78.91 ± 0.2 | 74.69 ± 5 | 81.24 ± 0.73 |
| 18,000 | 65.12 ± 0.27 | 79.28 ± 0.13 | 75.57 ± 0.5 | 83.96 ± 0.65 |
| Class | Initial Range Using Semi-Variogram (m) | Minimum Distance Using SSA+MMSD (m) | Final Training Sample Size |
|---|---|---|---|
| BU | 320 | 280 | 1006 |
| CL | 504 | 363 | 2719 |
| FL | 216 | 186 * | 450 |
| EF | 3637/1500 | 259 * | 1092 |
| DF | 2440/1500 | 1057 * | 377 |
| SL | 2220/1500 | 242 | 2415 |
| GL | 333 | 250 | 207 |
| WB | 1200 | 314 | 63 |
| RB | 1110 | 279 * | 131 |
| Reference Map | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BU | CL | FL | EF | DF | SL | GL | WB | RB | UA (%) | ||
| Classified Map | BU | 74 | 6 | 3 | 0 | 0 | 1 | 5 | 7 | 5 | 73.27 |
| CL | 15 | 65 | 36 | 5 | 3 | 11 | 52 | 7 | 12 | 31.55 | |
| FL | 1 | 8 | 60 | 1 | 4 | 1 | 0 | 1 | 0 | 78.95 | |
| EF | 0 | 6 | 0 | 79 | 10 | 9 | 0 | 0 | 0 | 75.96 | |
| DF | 0 | 0 | 0 | 3 | 59 | 0 | 2 | 0 | 0 | 92.19 | |
| SL | 2 | 14 | 1 | 12 | 21 | 77 | 19 | 7 | 0 | 50.33 | |
| GL | 0 | 1 | 0 | 0 | 3 | 1 | 22 | 0 | 0 | 81.48 | |
| WB | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 77 | 2 | 95.06 | |
| RB | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 81 | 92.05 | |
| PA (%) | 74 | 65 | 60 | 79 | 59 | 77 | 22 | 77 | 81 | ||
| Overall Accuracy: 66% | |||||||||||
| RF vs. CART | RF vs. SVM | RF vs. RVM | CART vs. RVM | CART vs. SVM | SVM vs. RVM |
|---|---|---|---|---|---|
| 99.998 | 99.997 | 99.998 | 99.855 | 67.822 | 98.942 |
| Reference Map | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BU | CL | FL | EF | DF | SL | GL | WB | RB | UA (%) | ||
| Classified Map | BU | 46 | 4 | 1 | 0 | 0 | 1 | 0 | 1 | 4 | 75 |
| CL | 4 | 33 | 1 | 1 | 2 | 3 | 7 | 0 | 1 | 48 | |
| FL | 0 | 5 | 68 | 2 | 0 | 11 | 13 | 0 | 2 | 62.9 | |
| EF | 1 | 6 | 0 | 52 | 3 | 19 | 16 | 2 | 0 | 45.6 | |
| DF | 2 | 9 | 3 | 11 | 59 | 10 | 18 | 1 | 0 | 43.3 | |
| SL | 0 | 9 | 0 | 5 | 4 | 30 | 13 | 0 | 0 | 40 | |
| GL | 3 | 5 | 0 | 2 | 8 | 3 | 7 | 3 | 0 | 13.3 | |
| WB | 5 | 1 | 0 | 1 | 0 | 1 | 1 | 65 | 3 | 90.5 | |
| RB | 15 | 4 | 1 | 1 | 0 | 1 | 0 | 3 | 66 | 82.5 | |
| PA (%) | 47.4 | 32.4 | 82.2 | 62.7 | 60.5 | 30.4 | 5.3 | 90.5 | 93.6 | ||
| Overall Accuracy: 62.46% | |||||||||||
| Quartile | Posterior Probability | Misclassified Test Samples (%) in Allocated Class | Total Mis-classification (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (Min–Max) | BU | CL | FL | EF | DF | SL | GL | WB | RB | ||
| Q1 | 0.17–0.29 | 4.3 | 5.9 | 2.4 | 4.0 | 15.8 | 3.2 | 4.3 | 1.2 | 1.2 | 42.3 |
| Q2 | 0.30–0.42 | 0.0 | 1.6 | 3.6 | 10.7 | 5.5 | 8.3 | 5.1 | 1.6 | 4.0 | 40.3 |
| Q3 | 0.43–0.54 | 0.0 | 0.0 | 5.1 | 4.0 | 0.0 | 0.8 | 0.0 | 0.8 | 2.4 | 13.0 |
| Q4 | 0.55–0.67 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2.4 | 4.3 |
| Total Misclassification (%) | 3.9 | 4.3 | 7.5 | 13.0 | 18.6 | 21.3 | 12.3 | 9.5 | 3.6 | 9.9 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shetty, S.; Gupta, P.K.; Belgiu, M.; Srivastav, S.K. Assessing the Effect of Training Sampling Design on the Performance of Machine Learning Classifiers for Land Cover Mapping Using Multi-Temporal Remote Sensing Data and Google Earth Engine. Remote Sens. 2021, 13, 1433. https://doi.org/10.3390/rs13081433
Shetty S, Gupta PK, Belgiu M, Srivastav SK. Assessing the Effect of Training Sampling Design on the Performance of Machine Learning Classifiers for Land Cover Mapping Using Multi-Temporal Remote Sensing Data and Google Earth Engine. Remote Sensing. 2021; 13(8):1433. https://doi.org/10.3390/rs13081433
Chicago/Turabian StyleShetty, Shobitha, Prasun Kumar Gupta, Mariana Belgiu, and S. K. Srivastav. 2021. "Assessing the Effect of Training Sampling Design on the Performance of Machine Learning Classifiers for Land Cover Mapping Using Multi-Temporal Remote Sensing Data and Google Earth Engine" Remote Sensing 13, no. 8: 1433. https://doi.org/10.3390/rs13081433
APA StyleShetty, S., Gupta, P. K., Belgiu, M., & Srivastav, S. K. (2021). Assessing the Effect of Training Sampling Design on the Performance of Machine Learning Classifiers for Land Cover Mapping Using Multi-Temporal Remote Sensing Data and Google Earth Engine. Remote Sensing, 13(8), 1433. https://doi.org/10.3390/rs13081433