1. Introduction
Research on autonomous vehicles is being in the ascendant [
1,
2,
3]. Autonomous Vehicles are cars or trucks that operate without human drivers, using a combination of sensors and software for navigation and control [
4]. Autonomous vehicles require not only detecting and locating moving objects but also knowing their motion state relative to the ego-vehicle, i.e., motion estimation [
5,
6,
7]. Motion estimation is a benefit to predict where other traffic participants will be at a certain period of time, and accordingly plan the route of the ego-vehicle. In this work, we propose a novel approach to estimate the motion state for autonomous vehicles by using region-level segmentation and Extended Kalman Filter (EKF).
Motion estimation involves three stages of object detection, tracking, and estimate of motion parameters including position, velocity, and acceleration in three directions. Accurate object detection is crucial for the high quality of motion estimation because the late two stages rely on the points within the object region; that is, only the points exactly within the object region can be used for tracking and parameter estimate. Existing works on motion estimation such as Refs. [
8,
9,
10,
11,
12,
13,
14,
15] normally generate bounding boxes as object proposals for the late two stages. One inherent problem of these methods is that the bounding boxes contain substantial background points as shown in
Figure 1. These points are noise points and will result in unreliable object tracking and incorrect parameter estimate. To address this issue, we adopt two strategies: (1) Instead of bounding boxes, we use segmented object regions as object proposals. We employ the YOLO-v4 detector [
16] to generate object bounding boxes and apply a region-level segmentation on them to accurately locate object contour and determine points within the objects (
Figure 1 shows the results). (2) We compose an edge-point constraint on the feature points and apply the random sample consensus (RANSAC) [
17] algorithm to eliminate outliers of tracking points so that the points used for tracking are ensured within the object body and the parameter estimate are refined by inner points. By the above processing, we can obtain a high-quality point set for tracking and parameter estimate, thereby generating accurate motion estimation.
Other aspects affecting motion estimation are how to establish the motion model for tracking and how to optimize the parameter estimate. In this work, we use optical flow to track the feature points. We propose a relative motion model of the ego-vehicle and moving objects, and accordingly establish an EKF model for point tracking and parameter estimate. The EKF model takes the ego-motion into considerations and integrates optical flow, and disparity to generate optimized object position and velocity.
In summary, we propose a novel framework for motion estimation by using region-level segmentation and Extended Kalman Filter. The main contributions of the work are:
A region-level segmentation is proposed to accurately locate object regions. The proposed method segments object from a pre-generated candidate region, and refines it by combining color, temporal (optical flow), and spatial (depth) information using super-pixels and Conditional Random Field.
We propose a relative motion model of the ego-vehicle and the object, and accordingly establish an EKF model for point tracking and parameter estimate. The EKF model integrates the ego-motion, optical flow, and disparity to generate optimized motion parameters.
We apply edge-point constraint, consistency constraint, and the RANSAC algorithm to eliminate outliers of tracking points, thus ensuring that the feature points used for tracking are within the object body and the parameter estimates are refined by inner points.
The experimental results demonstrate that our region-level segmentation presents excellent segmentation performance and outperforms the state-of-the-art segmentation methods. The motion estimation experiments confirm the superior performance of our proposed method over the state-of-the-art approaches in terms of the root mean squared error.
The remainder of this paper is organized as follows:
Section 2 briefly introduces the relevant works.
Section 3 describes the details of the proposed method including object detection and segmentation, and tracking and parameter estimate. The experiments and results are presented and discussed in
Section 4.
Section 5 concludes the paper.
2. Related Work
Motion estimation involves three stages of object detection, tracking, and estimate of motion parameters. The third stage that is served by the first two stages is the core of the whole pipeline. Thus, we divide the existing works on motion estimation into three categories in terms of the parameter estimates method, i.e., Kalman filter (KF)-based, camera ego-motion-based, and learning-based method.
The Kalman filter is an optimal recursive data processing algorithm that improves the accuracy of state measurement by fusion of prediction and measurement values. The KF-based method [
10,
11,
12,
18,
19,
20] generates optimized motion parameters by iteratively using a motion state equation for prediction and a measurement equation for updating. During the iteration, estimation error covariance is minimized. Lim, et al. [
10] proposed an inverse perspective map-based EKF to estimate the relative velocity via predicting and updating the motion state recursively. The stereovision was used to detect moving objects, and the edge points within the maximum disparity region were extracted as the feature points for tracking and parameter estimate. Liu, et al. [
11] combined Haar-like intensity features of the car-rear shadows with additional Haar-like edge features to detect vehicles, adopted an interacting multiple model algorithm to track the detected vehicles and utilized the KF to update the information of the vehicles including distances and velocities. Vatavu, et al. [
12] proposed a stereo vision-based approach for tracking multiple objects in crowded environments. The method relied on measurement information provided by an intermediate occupancy grid and on free-form object delimiters extracted from this grid. They adopted a particle filter-based mechanism for tracking, in which each particle state is described by the object dynamic parameters and its estimated geometry. The object dynamic properties and the geometric properties are estimated by importance sampling and a Kalman Filter. Garcia, et al. [
18] presented a sensor fusion approach for vehicle detection, tracking, and motion estimation. The approach employed an unscented Kalman filter for tracking and data association (fusion) between the camera and laser scanner. The system relied on the reliability of laser scanners for obstacle detection and computer vision technique for identification. Barth and Franke [
19] proposed a 3-D object model by fusing stereovision and tracked image features. Starting from an initial vehicle hypothesis, tracking and estimate are performed by means of an EKF. The filter combines the knowledge about the movement of the object points with the dynamic model of a vehicle. He, et al. [
20] applied an EKF for motion tracking with an iterative refinement scheme to deal with observation noise and outliers. The rotational velocity of a moving object was computed by solving a depth-independent bilinear constraint, and the translational velocity was estimated by solving a dynamics constraint that reveals the relation between scene depth and translational motion.
The camera ego-motion-based method [
9,
13,
14,
21] derives motion states of moving objects from camera ego-motion and object motion information relative to the camera. It generally consists of two steps: the first step is to obtain the camera’s ego-motion, and the second step is to estimate the object’s motion state by fusing the camera’s ego-motion with other object’s motion cues (such as relative speed, optical flow, depth, etc.). Kuramoto, et al. [
9] obtained the camera ego-motion from the Global Navigation Satellite System/Inertial Measurement Unit. A framework using a 3-D camera model and EKF was designed to estimate the object’s motion. The output of the camera model was interlay utilized to calculate the measurement matrix of the EKF. The matrix was designed to map be-tween the position measurement on the objects in the image domain and the corresponding vector state in the real world. Hayakawa, et al. [
13] predicted 2D flow by PWC-Net and detected the surrounding vehicles’ 3D bounding box using a multi-scale network. The ego-motion was extracted from the 2D flow using projection matrix and ground plane corrected by depth information. A similar approach was used for the estimation of the relative velocity of surrounding vehicles. The absolute velocity was derived from the combination of the ego-motion and the relative velocity. The position and orientation of surrounding vehicles were calculated by projecting the 3D bounding box into the ground plane. Min and Huang [
14] proposed a method of detecting moving objects from the difference between the mixed flow (caused by both camera motion and object motion) and the ego-motion flow (evoked by the moving camera). They established the mathematical relationship between optical flow, depth, and camera ego-motion. Accordingly, a visual odometer was implemented for the estimation of ego-motion parameters by using ground points as feature points. The ego-motion flow was calculated from the estimated ego-motion parameters. The mixed flow was obtained from the correspondence matching between consecutive images. Zhang, et al. [
21] presented a framework to simultaneously track the camera and multiple objects. The 6-DoF motions of the objects, as well as the camera, are optimized jointly with the optical flow in a unified formulation. The object velocity was calculated using the rotation and translation part of the motion of points in the global reference frame. The proposed framework detected moving objects via combining Mask R-CNN object segmentation [
22] and scene flow, and tracked them over frames using optical flow.
Different from the first two categories of the methods, the learning-based method [
8,
15,
23,
24] does not require a specific mathematical estimation model but relies on ma-chine learning and the ability of neural network regression to estimate the motion parameters. Jain, et al. [
8] used Farneback’s algorithm to calculate optical flow and the DeepSort algorithm to track vehicles detected from the YOLO-v3. The optical flow and the tracking information of the vehicle were then treated as input for two different networks. The features extracted from the two networks were stacked to create a new input for a lightweight Multilayer Perceptron architecture which finally predicts positions and velocities. Cao, et al. [
15] presented a network for learning motion parameters from stereo videos. The network masked object instances and predicted specific 3D scene flow maps, from which the motion direction and speed for each object can be derived. The network took the 3D geometry of the problem into account which allows it to correlate the input images. Kim, et al. [
23] developed a deep neural network that exploits different levels of semantic information to perform the motion estimation. The network used a multi-context pooling layer that integrates both object and global features, and adopt the cyclic ordinal regression scheme using binary classifiers for effective motion classification. In the detection stage, they ran the YOLO-v3 detector to obtain the bounding boxes. Song, et al. [
24] presented an end-to-end deep neural network for estimation of inter-vehicle distance and relative velocity. The network integrated multiple visual clues provided by two time-consecutive frames, which include deep feature clue, scene geometry clue, as well as temporal optical flow clue. It also used a vehicle-centric sampling mechanism to alleviate the effect of perspective distortion in the motion field.
Moving object detection is a prerequisite for motion estimation. Most of the existing methods use bounding boxes as object proposals which affect the accuracy of the motion estimation for the late two stages. In this study, we leverage a region-level segmentation to accurately locate object regions for tracking and parameter estimate. Therefore, we review here relevant segmentation works compared with our segmentation methods. PSPNet [
25] is a pyramid scene parsing network based on the full convolution network [
26], which exploits the capability of global context information by different-region-based context aggregation. PSPNet can provide a pixel-level prediction for the scene parsing task. Mask R-CNN [
22] is a classic network for object instance segmentation. It extends Faster R-CNN by adding a branch in parallel with the existing detection branch for predicting object masks. Bolya, et al. [
27,
28] proposed the YOLACT series, a fully convolutional model for real-time instance segmentation. YOLACT series break instance segmentation into two parallel subtasks, generating a set of prototype masks and predicting per-instance mask coefficients, to achieve compromise of segmentation quality and computation efficiency.
3. Method
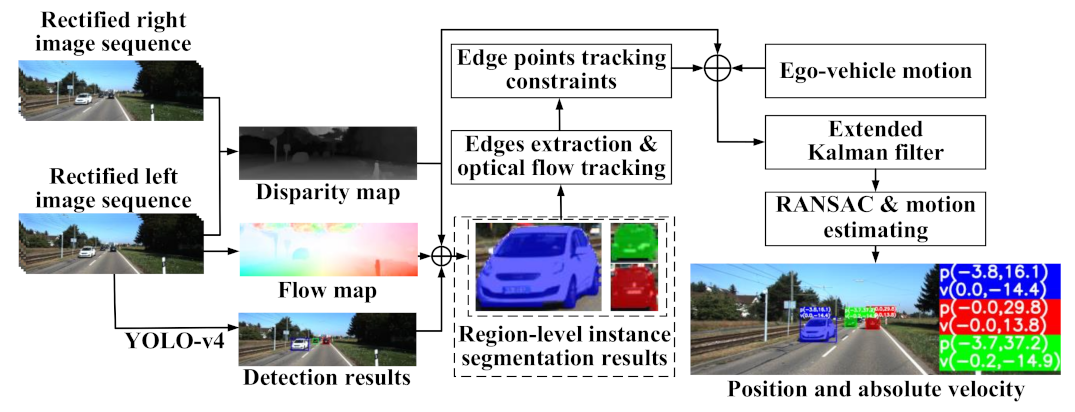
The framework of the proposed method is shown in
Figure 2. The main idea is to accurately determine feature points within the object through instance segmentation and predict the motion state by tracking the feature points through an EKF. The method includes two stages: (1) object segmentation, (2) tracking and motion estimate.
In the first stage, we use the YOLO-v4 detector to locate the object region in a form of a bounding box, and then extract accurate object contour through a region-level segmentation. The output is the feature points exactly within the object body.
In the second stage, we compose an edge-point constraint to further refine the feature points. We use Optical Flow to track the refined feature points. We propose a relative motion model with respect to the ego-vehicle and a moving object, and accordingly establish an EKF model for parameter estimation. We also apply the random sample consensus (RANSAC) algorithm to eliminate outliers of the tracked points. The EKF model integrates the ego-motion, optical flow, and disparity to generate optimized object position and velocity.
3.1. Object Detection and Region-Level Segmentation
Object detection is to locate the object region while segmentation is to determine foreground pixels (the object body) within the region.
Figure 3 shows a process of object detection and segmentation.
We employ a YOLO-v4 detector to locate the object region. The details of YOLO-v4 can be found in Reference [
16]. The detection result is in a form of a bounding box contains background, as shown in
Figure 3a.
Region-level segmentation consists of three stages including Grabcut, Super-pixels, and Super-pixels fixed by Conditional Random Field. Starting from the bounding box (
Figure 3a) detected by YOLO-v4, we apply the GrabCut algorithm to segment foreground from background. GrabCut algorithm proposed in Ref. [
29] is an interactive method that segments images according to texture and boundary information. When using GrabCut, we initially define the inner of the bounding box as foreground and the external as background, and accordingly build a pixel-level Gaussian Mixture Model to estimate the texture distribution of foreground/background. By an iterative process until convergence, we can obtain the confidence maps of the foreground and background. The results are shown in
Figure 3b,c.
Accordingly, GrabCut assigns a label
to pixel
as follows:
The result is shown in
Figure 3d in which the background is marked as black and the foreground is marked as red. This is a pre-segmentation process with some significant errors, for example, the license plate in
Figure 3d is excluded from the car body.
We refine the pre-segmentation in virtue of Super-pixels idea proposed in Reference [
30]. Super-pixels are an over-segmentation formed by grouping pixels based on low-level image properties including color, brightness, etc. Super-pixels provide a perceptually meaningful tessellation of image content, and naturally preserve the boundary of objects, thereby reducing the number of image primitives for subsequent segmentation. We adopt Simple Linear Iterative Clustering (SLIC) [
31] to generate
M super-pixels. SLIC is a simple-minded and easy-to-implement algorithm. It transforms the color image to
CIELAB color space, constructs the distance metric based on coordinates and
L/A/B color components, and adopts the k-means clustering approach to efficiently generate super-pixels. The label
of a super-pixel
is marked by Equation (2):
where
is the total number of pixels within super-pixel
. The generated super-pixels are shown in
Figure 3e where the white lines partition the super-pixels. Super-pixels can greatly reduce computation load in the late stages.
Conditional Random Field (CRF) [
32] is a discriminative probability model and is often used in pixel labeling. Supposing the output random variable constitutes a Markov random field, CRF is the extension of the maximum entropy Markov model. Since the labels of super-pixels can be regarded as such a random variable, we can use CRF to model the labeling problem. We define the CRF as an undirected graph with super-pixels as nodes. It can be solved through an approximate graph inference algorithm by minimizing an energy function. The energy function generally contains a unary potential and a pairwise potential. The unary potential is only related to the node itself and determines the likelihood of the node to be labeled as a class. The pairwise potential describes the interactions between neighboring nodes, and is defined as similarity between them. In this work, we employ CRF to fix the labels of super-pixels generated in
Figure 3e. Two super-pixels are considered as neighbors if they share an edge in image space. Let
and
(
) be neighboring super-pixels, the CRF energy function is defined as
where
denotes the set of all neighboring super-pixels.
is the initial super-pixel label assigned in Equation (2).
represents the 1/0 labeling of super-pixels. The energy function is minimized by using graph cuts algorithm. We refer readers to [
33] for a detailed derivation of the minimization algorithm.
The unary potential
in Equation (3) measures the cost of labeling
with
:
where
denotes the probability that
belongs to the foreground, computed by averaging the foreground confidence scores (
Figure 2b) over all pixels in
.
is the probability that
belongs to the background.
The pairwise potential
in Equation (3) describes the interaction relationship between two neighboring super-pixels.
incorporates the pairwise constraint by combining color similarity, the mean optical flow direction similarity and the depth similarity between
and
.
is defined as
where
is the weight used to adjust the pairwise potential function in
.
is an indicator function: if the input condition is true, the output is 1; otherwise, the output is 0.
denotes the
L 2-norm.
defines the color similarity between
and
.
is computed as the average
LAB color of
in
CIELAB color space.
is the mean optical flow of
and
represents the direction similarity between the mean flows of
and
.
is the depth similarity between
and
, measured using the Bhattacharyya distance.
is the normalized depth histogram of
. It can been seen that the pairwise potential integrates color, temporal (optical flow) and spatial (depth) information as criteria for segmentation purpose. The final segmentation result is shown in
Figure 3f.
3.2. Tracking and Parameter Estimate
We use Optical Flow to track the feature points. We establish a relative motion model between ego-vehicle and object by taking camera ego-motion into considerations, accordingly build an EKF model for point tracking and parameter estimate. The EKF model integrates the ego-motion, optical flow, and disparity to generate optimized object position and velocity. During the tracking process, we compose an edge-point constraint to refine the feature points. During the parameter estimate, we apply the RANSAC algorithm to eliminate outliers of tracked points.
3.2.1. The Relative Motion Model of the Ego-Vehicle and the Object
Figure 4 shows the relative motion model between the ego-vehicle and a moving object.
The ego-vehicle and the object move on
X-
Z plane. Assuming that the ego-vehicle moves from position
C1 to
C2 within a time interval
with a translational velocity
and a rotational velocity around
Y-axis
, the trajectory can be regarded as the arc
C1C2 with a rotation angle
. The displacement
in the camera coordinates at position
C2 will be:
The object
P is located at
C3 at time t, and the absolute velocities in the camera coordinates at position
C1 is
. Assuming that the object moves from
C3 to
C4 with
within
, the absolute velocities
of
P at time
is related to the change of the camera coordinates. Taking ego-vehicle motion into considerations, the displacement
and
of
P in the camera coordinates at
C2 are computed from:
where
is the rotation matrix given by the Rodrigues rotation formula:
Thus, given the coordinates of
P in the camera coordinates at
C1 at time
t , the coordinates of
P in the camera coordinates at
C2 at time
is calculated by:
3.2.2. Design of Kalman Filter
(1) Motion Model
The state vector for
P is defined as
where
represents the coordinates of
P in the moving camera coordinates.
is the absolute velocities of
P moving along the
X-axis,
Y-axis and
Z-axis.
Combing Equations (6) – (8) and (10), The time-discrete motion equation for the state vector
is given by:
where
k is the time index, the process noise
is considered as Gaussian white noise with a mean value of zero.
(2) Measurement Model
The measurement vector for P is where is the projection, and d is the disparity. The optical flow is used to track at time k to at time k+1, and the corresponding disparities and can be measured from the stereovision.
According to the ideal pinhole camera model, the nonlinear measurement equation can be written as:
where
is the Gaussian measurement noise.
,
are the camera focal lengths;
,
are the camera centre offsets and
b is the camera baseline length. The Jacobian matrix of measurement equation can be expressed as
(3) Estimation and Update
The location and absolute velocities of
P can be obtained by iterating the following estimation and update process. The time update equations are:
where
is the priori estimate of the state vector
at time
k,
is the posteriori estimate (optimal value) of the state vector
at time
k-1,
is the priori estimate of the variance of the estimation error,
is the covariance of
.
The measurement update equations are
where
is the Kalman gain,
is the covariance of
,
I is the identity matrix,
is the posteriori estimate (optimal value) of the state vector
at time
k, and
is the posteriori estimate of the variance of the estimation error.
3.2.3. Feature-Point Filtering
The tracking discussed in the above EKF is for a single object point. As described in
Section 3.1, each segmented object consists of a cluster of points, i.e., a set of foreground pixels. For sake of tracking reliability and computation efficiency, it is essential to select reliable feature points for tracking and estimation. The motion state of an object is taken as the average of these points. Feature-point filtering is crucial for tracking and estimation.
Since the edge points have a strong textural feature and facilitate optical flow calculations, we employ the Canny operator [
34] to extract the edge points as feature points. During the tracking, we compose an edge-point constraint on the tracking results. That is, the tracked points must still be edge points, otherwise, they are excluded.
Furthermore, we enhance estimation accuracy by applying the RANSAC algorithm [
17] to eliminate outliers of tracking points. The RANSAC is a statistics-based hypothesis-verification method that iteratively finds the inner data from noisy data. In each iteration, a minimum number of samples is randomly selected to construct a consistency hypothesis, and other samples are verified whether they conform to the hypothesis. The samples that conform are taken as inner samples. Repeat the above steps to form a sample set with the largest number of inner samples, i.e., the maximum consensus set, for calculation of the motion parameters.
We compose a consistency constrain on the estimate results, that is, the estimate results for feature points in the same object should be consistent. In this work, the longitudinal distance and velocity, the lateral distance and velocity are used as target parameters to iteratively select the inner data set. The implementation flow for the RANSAC filtering is illustrated in Algorithm 1.
| Algorithm 1. Implementation flow for RANSAC filtering (example of longitudinal distance). |
Input: A set of feature points: FR The maximum iterations:
Consistency threshold th, i.e., the threshold of the deviation that is the difference between longitudinal distance and its average.
Output: The maximum consensus set: The object longitudinal distance: |
,
while do
1 Hypothesis generation
Randomly select m feature points form FR as minimal consensus set
Calculate the average longitudinal distance in the minimal consensus set
2 Verification
Calculate the difference between the longitudinal distance of each point in FR and , i.e., deviations
Determine a set whose deviations are less than th
Count the total number of as N
If then
,
end if
i = i + 1
end while
Calculate the average longitudinal distance in as |
4. Experiments
Experiments have been conducted on image sequences (Road and City) of the KITTI public datasets [
35]. The binocular camera settings are: baseline length 0.54 m, mounting height 1.65 m, tilt angle to the ground 0°, and rectified image resolution 375 × 1242. KITTI provides the ground truth of ego-vehicle motion, motion state of moving objects. The experiments were implemented in the workstation with an Intel Xeon Silver 4110 4 core processor, 16GB RAM, a Nvidia GeForce gtx1080ti graphic processor, and 11 GB video memory.
We use HD
3-flow [
36] for predicting optical flow and employ PSMNet [
37] to generate the disparity maps. We retrained HD
3-flow and PSMNet based on the original weights using the KITTI dataset.
4.1. Segmentation Results
We compare our segmentation method with two state-of-the-art methods, PSPNet [
25] and YOLACT++ [
28]. The results of three methods compared with the ground truth are shown in
Figure 5. The fourth row shows the results obtained by our method only using color information without using optical flow, and disparity, called “Our method
1”.
In the road scene, it can be seen that our method can accurately segment the Obj. 1, 2, and 3. Our method1 fails in recognizing the license plates and lights of Obj. 2 and 3 as part of the car bodies. PSPNet wrongly mixtures Obj. 2 and 3 together while YOLACT++ wrongly mixtures distant building with Obj. 2 into one object.
In the city scene, our method also achieves the best result either in frame 4 (no-occlusion case) or frame 9 (occlusion case). Especially, our method is able to accurately distinguish Obj. 4 from the traffic light poles in frame 9. PSPNet presents significant errors either on frame 4 or frame 9 while YOLACT++ fails to segment Obj. 4 from the traffic poles. Our method1 does not correctly segment the front windshield of Obj.4 in frame 9, while the wheels are excluded from the car body in frame 4 and 9.
We use four metrics to quantitatively evaluate the segmentation performance.
Mean Intersection over Union (MIoU) [
38]: It computes a ratio between the intersection and the union of the ground truth and predicted segmentation.
where
is the class number, in this case
(foreground/background).
is the number of pixels of class
inferred to belong to class
and by parity of reasoning. When calculating
MIoU,
and
are regarded as foreground (1) or background (0) respectively to count the positive and negative pixels. Thus,
and
refers to be 1 or 0.
The False Positive Rate (
FPR) and the False Negative Rate (
FNR) are computed by
where True Positive (
TP) and False Positive (
FP) indicate the correctly and incorrectly segmented positive (foreground) pixels, while the True Negative (
TN) and False Negative (
FN) indicate the correctly and incorrectly segmented negative (background) pixels.
Overall error (Ov. err.) is the percentage of wrongly labelled pixels.
Since the KITTI doesn’t provide the ground truth of the instance segmentation, we manually labeled 411 images from the Road and City sequences. We conducted experiments on those images, and the average values of the metrics are listed in
Table 1. It can be seen that our method achieves the best
MIoU score and the lowest
FPR,
FNR, and
Ov.err., and outperforms other methods.
The reasons for the superior performance of our method are: (1) our method segments object from candidate region (bounding box) pre-generated by YOLO-v4 detector rather than from the whole image, which eliminates trivial information and makes segmentation easy; (2) our method combines color, temporal (optical flow), and spatial (depth) information as the basis for segmentation; and (3) super-pixels naturally preserve the boundary of objects and are computationally efficient for processing.
4.2. Results of Feature-Point Filtering
As described in
Section 3.2.3, the edge points within the object point cluster are used as feature points for tracking. The edge point constraint and consistency constraint are applied to filter the feature points. Taking a segmented object as an example, the filtering processing is shown in
Figure 6.
Figure 6a shows the point cluster obtained from our region-level segmentation, and
Figure 6b shows the edge points extracted by the Canny operator, which are taken as feature points. The yellow points in
Figure 6c are the feature points in
Figure 6b (previous frame) that are tracked to the current frame while the white points are the edge points in the current frame. Some of the yellow points do not overlap the white points and should be eliminated. The blue points in
Figure 6d are the result of excluding the non-overlapping points, i.e., satisfying the edge point constraint. The results of applying the consistency constraint on
Figure 6d are shown in
Figure 6e. The red points are the feature points with consistent distances and velocities that have been selected by the RANSAC, i.e., the maximum consensus set. The arrows in
Figure 6f represent the optical flows of the valid feature points. It can be seen that the optical flows are identical, indicating a valid feature point selection.
4.3. Motion Estimate Results and Analysis
4.3.1. Motion Estimate Results
Table 2 lists the estimates and errors of position and absolute velocity of the objects in
Figure 5. It can be seen that our method presents small errors. In the Road scene, objects have little variation in their lateral positions and mainly move longitudinally. The maximum absolute errors of the objects’ longitudinal position and velocity estimations are 0.4 m (Obj. 3, corresponding to the ground truth 37.5 m) and 0.6 m/s (Obj. 3, corresponding to −13.0 m/s), respectively. In the City scene, the objects are mainly moving laterally from left to right. The maximum absolute errors of the objects’ lateral position and velocity estimation are −0.2 m (Obj. 4 in frame 4, corresponding to −9.9 m) and −0.3 m/s (Obj. 5 in frame 4, corresponding to 10.8 m/s), respectively.
Figure 7 shows the results of object segmentation and motion estimation in three frames of the Road scene sequence.
indicates the lateral and longitudinal distances of objects in the camera coordinates, while
denotes the lateral and longitudinal absolute velocities. Starting from frame 210 to frame 291, the red car that moves in the same direction as the ego-vehicle is tracked. At frame 210, it is 29.8 m away from the ego-vehicle with a longitudinal velocity of 13.8 m/s. At frame 210, it is getting far with a distance of 33.9 m and a velocity of 15.2 m/s. At frame 291, it is getting closer with a distance of 32.3 m and a velocity of 13.7 m/s. At the same time, other vehicles on the road (as shown in the blue, green, brown, and purple masks) are also segmented, tracked and predicated with their motion states.
4.3.2. Evaluation and Comparison
We tested our method against the ground truth over a sequence of images. We evaluated our method in terms of: (1) the method with feature-point filtering (
w Ft.Pts.F.); (2) the method without feature-point filtering (
w/o Ft.Pts.F.).
Figure 8 shows the variations of lateral distance and velocity of Obj. 4 from frame 4 to 23 in the City scene. It moves almost uniformly from left to right, the lateral distance becomes progressively larger and the lateral absolute velocity is approximately constant.
Figure 9 shows the variations of longitudinal distance and velocity of Obj. 2 from frame 4 to 294 in the Road scene. It moves in the same direction as the ego-vehicle. It can also be seen that the variations of the
w Ft.Pts.F. method are closer to the ground truth and smoother than the
w/o Ft.Pts.F. method. This indicates that the performance of our method is improved by using feature-point filtering.
There is no uniform evaluation metric for object motion estimation. One of the commonly used metrics is the root mean squared error (
RMSE) over a sequence of images. The
RMSE is defined as
where
NF refers to the number of frames that at least one object is being tracked in a sequence,
the estimate and
the ground truth.
represents the parameters used for evaluation including the lateral distance
X, the lateral velocity
, the longitudinal distance
Z and the longitudinal velocity
. For example,
is the root mean square error of the lateral distance
X. Therefore, we compared our method with other three start-of-the-art works [
13,
21,
24] that also used the
RMSE as evaluation metric.
Table 3 lists the comparison results.
As can be seen in
Table 3, our proposed method with feature-point filter brings significant improvement compared with the other methods, particularly in the
RMSE of distance. It can also be seen the performance of our method is improved by using the feature-point filtering.
To evaluate the effect of each component in the proposed method on motion estimation, we have conducted an ablation study on different versions of the method. The results are summarized in
Table 4.
Comparing other rows with the first row which is the standard version, it can be seen how each component contributes to improving the RMSE values. Comparing the second row (using bounding box rather than region-level segmentation) with the first row demonstrates the proposed region-level segmentation method can significantly improve the results. Comparing the third row with the first row demonstrates the effect of the feature-point filtering. Comparing the fourth row with the first row demonstrates that the EKF model is effective.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}