
LPIN: A Lightweight Progressive Inpainting Network for Improving the Robustness of Remote Sensing Images Scene Classification



Abstract
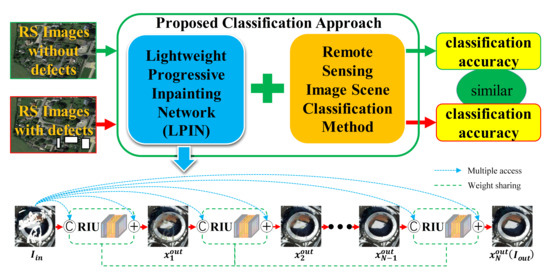
:
1. Introduction
1.1. The Dilemma of Existing RSISC Methods
1.2. The Approach to Overcoming this Dilemma
1.3. Related Works of Image Inpainting
1.4. Contribution
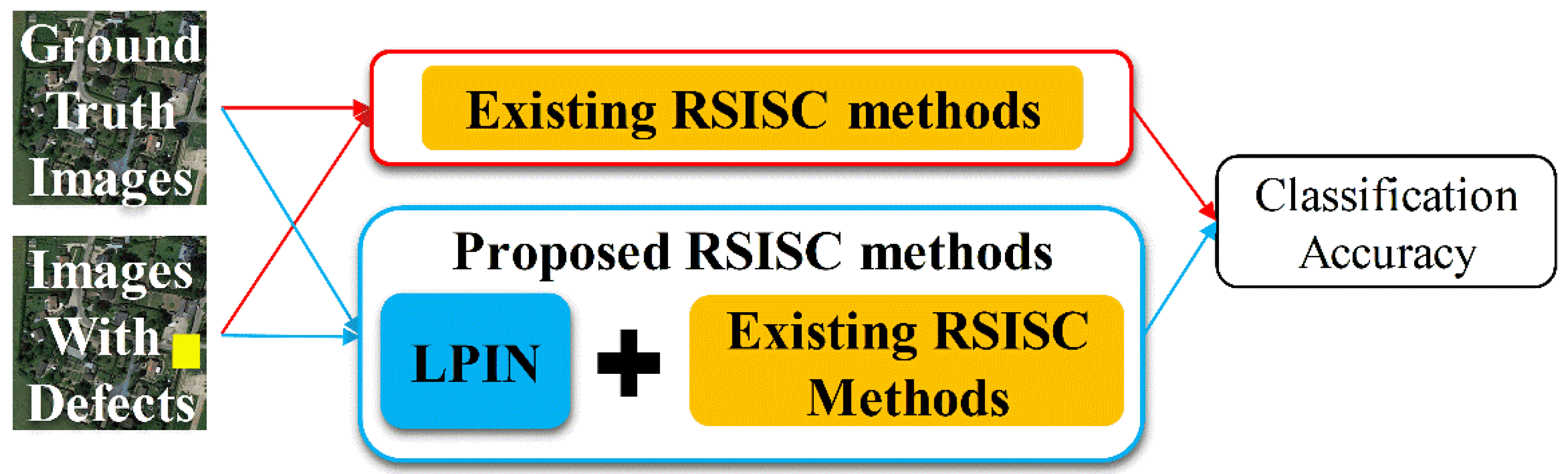
- A novel approach to improving the robustness of RSISC tasks is proposed, which is the combination of an image inpainting network and an existing RSISC method. Unlike the commonly used image preprocessing methods, the approach focuses on the image reconstruction to generate a completely new RS image. To our knowledge, this is the first attempt that image inpainting method has been applied to improve the robustness of RSISC tasks.
- An inpainting network LPIN is proposed on the novel consideration of lightweight design. Compared with the existing inpainting models, the LPIN has a model weight of only 1.2 MB, which is much smaller than other models and is more suitable for practical application of RSISC tasks when implementing it on small portable systems. In spite of the small model weight, the LPIN still remains a state-of-the-art inpainting performance due to the progressive inpainting strategy, residual architecture and the multi-access of input images, which deepen the LPIN and guarantee a high feature and gradient transmission efficiency.
- The proposed approach has a wide applicability and can be adopted to various RSISC methods to improve their classification accuracies on images with defects. The results of extensive experiments show that the proposed approach on RS images with defects generally achieves a classification accuracy of more than 94% (maximum 99.9%) of that on the images without defects. This proves that it can greatly improve the robustness of RSISC tasks.
2. Materials and Methods
2.1. Basic Residual Inpainting Unit
2.2. Progressive Networks
2.3. Loss Functions
2.3.1. Reconstruction Loss
2.3.2. Content Loss
2.3.3. Style Loss
2.3.4. Total Variation Loss
3. Results
3.1. Datasets
3.1.1. RS Image Datasets
- NWPU-RESISC45 dataset was released by Northwestern Polytechnical University in 2017 and is the largest and most challenging dataset for RSISC task. It contains 31,500 images extracted from Google Earth with a fixed size of 256 × 256 and has 45 scene categories with 700 images in each category The 45 categories are airplane, airport, baseball diamond, basketball court, beach, bridge, chaparral, church, circular farmland, cloud, commercial area, dense residential, desert, forest, freeway, golf course, ground track field, harbor, industrial area, intersection, island, lake, meadow, medium residential, mobile home park, mountain, overpass, palace, parking lot, railway, railway station, rectangular farmland, river, roundabout, runway, sea ice, ship, snowberg, sparse residential, stadium, storage tank, tennis court, terrace, thermal power station, and wetland. Some examples images from the NWPU-RESISC45 dataset are shown in Figure 4.
- UC Merced Land-Use dataset was released by University of California, Merced in 2010 and is the most widely used dataset for RSISC tasks. It contains 2100 RS images of 256 × 256 pixels extracted from USGS National Map Urban Area Imagery collection and has 21 categories with 100 images per category. The 21 categories are agricultural, airplane, baseball diamond, beach, buildings, chaparral, dense residential, forest, freeway, golf course, harbor, intersection, medium residential, mobile home park, overpass, parking lot, river, runway, sparse residential, storage tanks and tennis court. Some example images from the UC Merced Land-Use dataset are shown in Figure 5.
- AID dataset was released by Wuhan University in 2017 and is one of the most complex datasets for RSISC tasks due to the images being extracted from different sensors and their pixel resolution varying from 8 m to 0.5 m. It contains 10,000 RS images of 600 × 600 pixels extracted from Google Earth imagery and has 30 scene categories with about 220 to 400 images per category. The 30 categories are airport, bareland, baseball field, beach, bridge, center, church, commercial, dense residential, desert, farmland, forest, industrial, meadow, medium residential, mountain, parking, park, playground, pond, port, railway station, resort, river, school, sparse residential, square, stadium, storage tanks and viaduct. Some example images from the AID dataset are shown in Figure 6.
3.1.2. Mask Datasets
3.2. Training Details
3.2.1. Environments
3.2.2. Training Flow
| Algorithm 1. The training process of LPIN. |
| is the input of LPIN, |
| is the output of LPIN, |
| is the i-th RIU, |
| is the input of the i-th RIU, |
| is the residual output of the i-th RIU, |
| is the output of the i-th RIU.7: for number of max epochs do: |
| 12: for number N of phases do: |
| 16: end for |
| 18: calculate loss functions. |
| 19: update parameters using ADAM optimizer. |
| 20: end for |
3.3. Hyper-Parameters Tuning
3.3.1. Weight Value of Loss Term
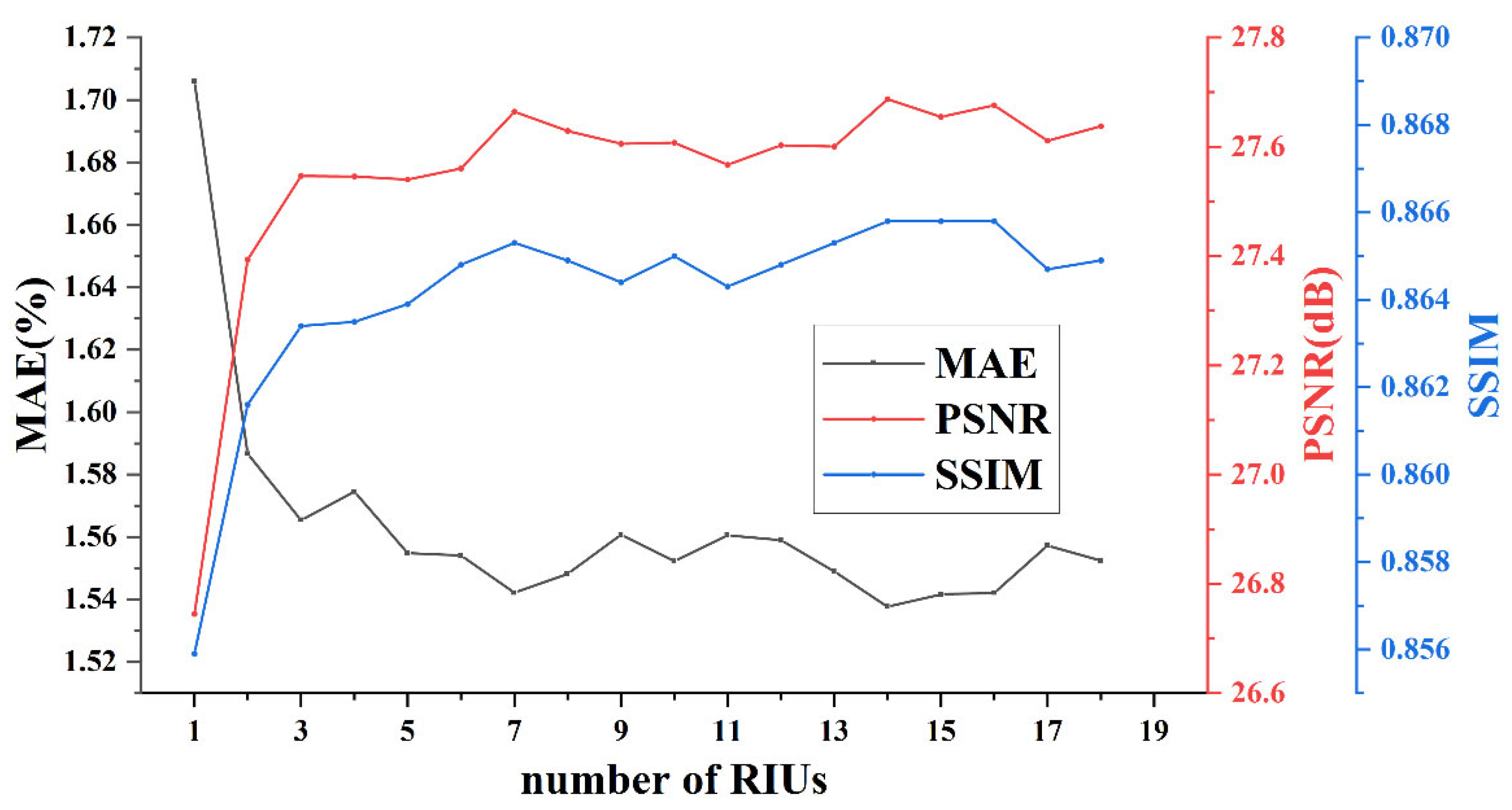
3.3.2. Number of RIUs in LPIN
3.4. Image Inpainting Results
3.4.1. Model Complexity Analysis
3.4.2. Quantitative Results
3.4.3. Qualitative Comparisons
3.5. Scene Classification Results
3.5.1. Classification Accuracy Results
3.5.2. OA Comparison of Different Inpainting Models
4. Discussion
4.1. Generalization Ability Results of Different Datasets
4.2. Image Inpainting Ablation Studies
4.2.1. Network Architecture: With vs. without LSTM
4.2.2. Reconstruction Loss: L1 vs. Negative SSIM
4.2.3. Feature Extractor: ResNet50 vs. VGG16
4.2.4. Feature Extractor Layer: Maxpooling vs. Convolution
4.3. Inpainting Results of Images with Hybrid Defecs
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AID | Aerial Image Dataset |
| BoVW | Bag of Visual Words |
| CapsNet | Capsule Network |
| CE | Context Encoder |
| CNN | Convolutional Neural Network |
| CSA | Coherent Semantic Attention |
| D2GR | Defect-to-GT Ratio |
| DCGAN | Deep Convolutional GAN |
| ETM+ | Enhanced Thematic Mapper Plus |
| FastHyDe | Fast Hyperspectral Denoising |
| FastHyIn | Fast Hyperspectral Inpainting |
| FVs | Fisher vectors |
| GAN | Generative Adversarial Networks |
| GLCIC | Global and Local Consistent Image Completion |
| GT | Ground Truth |
| HCV | Hierarchical Coding Vector |
| LPIN | Lightweight Progressive Inpainting Network |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| MSE | Mean Square Error |
| NSR | Nonlocal Second-order Regularization |
| OA | Overall Accuracy |
| PCONV | Partial Convolution |
| PM-MTGSR | Patch Matching-based Multitemporal Group Sparse Representation |
| PRVS | Progressive Reconstruction of Visual Structure |
| PSNR | Peak Signal-to-Noise Ratio |
| ResBlocks | Residual Blocks |
| RFR | Recurrent Feature Reasoning |
| RIU | Residual Inpainting Unit |
| RS | Remote Sensing |
| RSISC | Remote Sensing Image Scene Classification |
| RSP | Randomized Spatial Partition |
| SLC | Scan-Line Corrector |
| SSIM | Structural Similarity |
| SST | Sea Surface Temperature |
| TV | Total Variation |
| UAV | Unmanned Aerial Vehicles |
| UCTGAN | Unsupervised Cross-Space Translation GAN |
| VGG | Visual Geometry Group |
| WGAN | Wasserstein GAN |
References
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.S. Remote Sensing Image Scene Classification Meets Deep Learning: Challenges, Methods, Benchmarks, and Opportunities. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 270–279. [Google Scholar]
- Jiang, Y.; Yuan, J.; Yu, G. Randomized spatial partition for scene recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 730–743. [Google Scholar]
- Wu, H.; Liu, B.; Su, W.; Zhang, W.; Sun, J. Hierarchical coding vectors for scene level land-use classification. Remote Sens. 2016, 8, 436. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.; Liu, B.; Su, W.; Zhang, W.; Sun, J. Deep filter banks for land-use scene classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1895–1899. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. Att-net: Enhanced emotion recognition system using lightweight self-attention module. Appl. Soft Comput. 2021, 102, 107101. [Google Scholar] [CrossRef]
- Muhammad, K.; Mustaqeem; Ullah, A.; Imran, A.S.; Sajjad, M.; Kiran, M.S.; Sannino, G.; de Albuquerque, V.H.C. Human action recognition using attention based LSTM network with dilated cnn features. Future Gener. Comput. Syst. 2021, 125, 820–830. [Google Scholar] [CrossRef]
- Lee, H.; Kwon, H. Contextual deep CNN based hyperspectral classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 3322–3325. [Google Scholar]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Du, P.; Li, E.; Xia, J.; Samat, A.; Bai, X. Feature and model level fusion of pretrained CNN for remote sensing scene classification. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2019, 12, 2600–2611. [Google Scholar] [CrossRef]
- Yin, L.; Yang, P.; Mao, K.; Liu, Q. Remote Sensing Image Scene Classification Based on Fusion Method. J. Sens. 2021, 2021, 6659831. [Google Scholar] [CrossRef]
- Li, B.; Su, W.; Wu, H.; Li, R.; Zhang, W.; Qin, W.; Zhang, S. Aggregated deep Fisher feature for VHR remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3508–3523. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1155–1167. [Google Scholar] [CrossRef]
- Li, H.; Wang, W.; Pan, L.; Li, W.; Du, Q.; Tao, R. Robust capsule network based on maximum correntropy criterion for hyperspectral image classification. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2020, 13, 738–751. [Google Scholar] [CrossRef]
- Jiang, X.; Liu, W.; Zhang, Y.; Liu, J.; Li, S.; Lin, J. Spectral–spatial hyperspectral image classification using dual-channel capsule networks. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1094–1098. [Google Scholar] [CrossRef]
- Zhang, X.; An, W.; Sun, J.; Wu, H.; Zhang, W.; Du, Y. Best representation branch model for remote sensing image scene classification. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2021, 14, 9768–9780. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, F. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Su, W.; Wu, H.; Li, R.; Zhang, W.; Qin, W.; Zhang, S.; Wei, J. Further exploring convolutional neural networks’ Potential for Land-Use Scene Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1687–1691. [Google Scholar] [CrossRef]
- Li, B.; Guo, Y.; Yang, J.; Wang, L.; Wang, Y.; An, W. Gated recurrent multiattention network for VHR remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2021, 1–13. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef] [Green Version]
- Naushad, R.; Kaur, T.; Ghaderpour, E. Deep Transfer Learning for Land Use and Land Cover Classification: A Comparative Study. Sensors 2021, 21, 8083. [Google Scholar] [CrossRef]
- Ju, J.; Roy, D.P. The availability of cloud-free Landsat ETM+ data over the conterminous United States and globally. Remote Sens. Environ. 2008, 112, 1196–1211. [Google Scholar] [CrossRef]
- Li, Q.; Shen, L.; Guo, S.; Lai, Z. Wavelet integrated CNNs for noise-robust image classification. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7245–7254. [Google Scholar]
- Duan, P.; Kang, X.; Li, S.; Ghamisi, P. Noise-robust hyperspectral image classification via multi-scale total variation. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2019, 12, 1948–1962. [Google Scholar] [CrossRef]
- Chen, Y.; Das, M. An automated technique for image noise identification using a simple pattern classification approach. In Proceedings of the 50th Midwest Symposium on Circuits and Systems (MWSCAS), Montreal, QC, Canada, 5–8 August 2007; pp. 819–822. [Google Scholar]
- Chen, C.; Li, W.; Tramel, E.W.; Cui, M.; Prasad, S.; Fowler, J.E. Spectral–spatial preprocessing using multihypothesis prediction for noise-robust hyperspectral image classification. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2014, 7, 1047–1059. [Google Scholar] [CrossRef]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Akbari, Y. Image inpainting: A review. Neural Process. Lett. 2020, 51, 2007–2028. [Google Scholar] [CrossRef] [Green Version]
- Ruzic, T.; Pizurica, A. Context-aware patch-based image inpainting using markov random field modeling. IEEE Trans. Image Process. 2015, 24, 444–456. [Google Scholar] [CrossRef]
- Jin, K.H.; Ye, J.C. Annihilating filter-based low-rank hankel matrix approach for image inpainting. IEEE Trans. Image Process. 2015, 24, 3498–3511. [Google Scholar]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. Patchmatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph. 2009, 28, 24. [Google Scholar] [CrossRef]
- Kawai, N.; Sato, T.; Yokoya, N. Dminished reality based on image inpainting considering background geometry. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1236–1247. [Google Scholar] [CrossRef] [Green Version]
- Zheng, J.; Jiang, J.; Xu, H.; Liu, Z.; Gao, F. Manifold-based nonlocal second-order regularization for hyperspectral image inpainting. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2020, 14, 224–236. [Google Scholar] [CrossRef]
- Zhuang, L.; Bioucas-Dias, J.M. Fast hyperspectral image denoising and inpainting based on low-rank and sparse representations. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2018, 11, 730–742. [Google Scholar] [CrossRef]
- Li, X.; Shen, H.; Li, H.; Zhang, L. Patch matching-based multitemporal group sparse representation for the missing information reconstruction of remote-sensing images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2016, 9, 3629–3641. [Google Scholar] [CrossRef]
- Lin, C.; Lai, K.; Chen, Z.; Chen, J. Patch-based information reconstruction of cloud-contaminated multitemporal images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 163–174. [Google Scholar] [CrossRef]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature learning by inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; pp. 2536–2544. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. 2017, 36, 107. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein GANs. In Proceedings of the advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.C.; Tao, A.; Catanzaro, B. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 89–105. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T. Free-Form Image Inpainting with Gated Convolution. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 4470–4479. [Google Scholar]
- Li, J.; He, F.; Zhang, L.; Du, B.; Tao, D. Progressive reconstruction of visual structure for image inpainting. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6721–6729. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.; Ebrahimi, M. EdgeConnect: Structure guided image inpainting using edge prediction. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3265–3274. [Google Scholar]
- Liu, H.; Jiang, B.; Xiao, Y.; Yang, C. Coherent semantic attention for image inpainting. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Korea, 15–20 June 2019; pp. 4169–4178. [Google Scholar]
- Li, J.; Wang, N.; Zhang, L.; Du, B.; Tao, D. Recurrent feature reasoning for image inpainting. In Proceedings of the 202 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7757–7765. [Google Scholar]
- Zhao, L.; Mo, Q.; Lin, S.; Wang, Z.; Lu, D. UCTGAN: Diverse Image Inpainting Based on Unsupervised Cross-Space Translation. In Proceedings of the 2020 IEEE International Conference on Computer Vision (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5740–5749. [Google Scholar]
- Dong, J.; Yin, R.; Sun, X.; Li, Q.; Yang, Y.; Qin, X. Inpainting of remote sensing SST images with deep convolutional generative adversarial network. IEEE Geosci. Remote Sens. Lett. 2019, 16, 173–177. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Zhang, Q.; Yuan, Q.; Zeng, C.; Li, X.; Wei, Y. Missing data reconstruction in remote sensing image with a unified spatial–temporal–spectral deep convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4274–4288. [Google Scholar] [CrossRef] [Green Version]
- Wong, R.; Zhang, Z.; Wang, Y.; Chen, F.; Zeng, D. HSI-IPNet: Hyperspectral imagery inpainting by deep learning with adaptive spectral extraction. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2020, 13, 4369–4380. [Google Scholar] [CrossRef]
- Zhang, H.; Hu, Z.; Luo, C.; Zuo, W.; Wang, M. Semantic image inpainting with progressive generative networks. In Proceedings of the 26th ACM International Conference on Multimedia (ACM MM), Seoul, Korea, 22–26 October 2018; pp. 1939–1947. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; pp. 2414–2423. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; pp. 2818–2826. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inpainting Method | GLCIC [40] | DeepFill [41] | PCONV [43] | DeepFill v2 [45] | PRVS [46] | Edge-Connect [47] | RFR [49] | PGN [55] | Proposed LPIN |
|---|---|---|---|---|---|---|---|---|---|
| Pretrained Model Weight (MB) | 23.2 | 130.8 | 412.5 | 176.4 | 666.7 | 38.1 | 374.8 | 3132.8 | 1.2 |
| Method | PGN [55] | PCONV [43] | PRVS [46] | RFR [49] | LPIN (Ours) |
|---|---|---|---|---|---|
| FLOPs (G) | 77.64 | 18.95 | 19.71 | 206.11 | 6.23 |
| Bytes (M) | 249.39 | 51.55 | 22.38 | 30.59 | 0.095 |
| Model Weight (MB) | 3132.8 | 412.5 | 666.7 | 374.8 | 1.2 |
| Inpainting Speed (fps) | 24.89 | 66.75 | 22.47 | 15.75 | 67.29 |
| Method | Stripe Defects | Noise Defects | Cloud Defects | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PCGN [55] | 1.737 | 29.082 | 0.921 | 2.548 | 27.066 | 0.812 | 1.873 | 28.320 | 0.875 |
| PCONV [43] | 1.483 | 27.621 | 0.874 | 2.709 | 23.555 | 0.665 | 1.484 | 28.092 | 0.873 |
| PRVS [46] | 1.404 | 28.306 | 0.883 | 1.375 | 28.302 | 0.882 | 1.380 | 28.267 | 0.882 |
| RFR [49] | 1.461 | 28.897 | 0.851 | 1.588 | 26.794 | 0.877 | 1.386 | 28.421 | 0.883 |
| LPIN (ours) | 0.722 | 33.849 | 0.967 | 0.646 | 33.282 | 0.951 | 1.384 | 28.432 | 0.884 |
| Method | GT OA | Stripe Defects | Noise Defects | Cloud Defects | |||
|---|---|---|---|---|---|---|---|
| OA | D2GR | OA | D2GR | OA | D2GR | ||
| HCV + FV [4] | 82.36 ± 0.17 | 32.48 ± 0.43 | 39.44 | 39.15 ± 0.27 | 47.54 | 50.12 ± 0.44 | 60.85 |
| HCV + FV + LPIN | 82.15 ± 0.23 | 99.77 | 80.94 ± 0.14 | 98.30 | 79.42 ± 0.34 | 96.45 | |
| ADFF [12] | 88.82 ± 0.22 | 43.17 ± 0.57 | 48.60 | 53.80 ± 0.38 | 60.57 | 49.74 ± 0.39 | 56.00 |
| ADFF + LPIN | 88.23 ± 0.25 | 99.37 | 87.35 ± 0.28 | 98.37 | 83.63 ± 0.34 | 94.19 | |
| VGG16 [56] | 87.66 ± 0.37 | 28.01 ± 0.53 | 31.95 | 28.53 ± 0.41 | 32.55 | 39.50 ± 0.55 | 45.06 |
| VGG16 + LPIN | 87.21 ± 0.39 | 99.61 | 86.05 ± 0.36 | 98.29 | 82.82 ± 0.41 | 94.60 | |
| ResNet50 [61] | 90.12 ± 0.14 | 36.80 ± 0.51 | 40.83 | 48.17 ± 0.53 | 53.45 | 50.45 ± 0.61 | 55.98 |
| ResNet50+LPIN | 89.98±0.44 | 99.85 | 89.66 ± 0.49 | 99.50 | 87.75 ± 0.51 | 97.38 | |
| Inception V3 [62] | 93.42 ± 0.39 | 42.17 ± 0.69 | 45.14 | 56.61 ± 0.87 | 60.60 | 52.99 ± 0.75 | 56.72 |
| Inception V3 + LPIN | 93.30 ± 0.51 | 99.90 | 92.99 ± 0.62 | 99.57 | 88.45 ± 0.62 | 94.71 | |
| F2BRBM [16] | 94.72 ± 0.38 | 44.16 ± 0.45 | 46.62 | 43.36 ± 0.32 | 45.78 | 60.80 ± 0.41 | 64.19 |
| F2BRBM + LPIN | 93.77 ± 0.37 | 99.00 | 94.43 ± 0.38 | 99.69 | 89.92 ± 0.38 | 94.93 | |
| Method | Stripes Defects | Noises Defects | Clouds Defects |
|---|---|---|---|
| F2BRBM + PGN [55] | 93.06 ± 0.22 | 85.43 ± 0.20 | 86.49 ± 0.19 |
| F2BRBM + PCONV [43] | 79.84 ± 0.89 | 60.60 ± 1.25 | 89.01 ± 0.15 |
| F2BRBM + PRVS [46] | 92.93 ± 0.18 | 92.81 ± 0.43 | 89.99 ± 0.34 |
| F2BRBM + RFR [49] | 66.43 ± 1.05 | 74.23 ± 0.92 | 90.19 ± 0.27 |
| F2BRBM + LPIN (ours) | 93.77 ± 0.23 | 94.43 ± 0.15 | 89.92 ± 0.25 |
| Dataset | Stripes Defects | Noises Defects | Clouds Defects | ||||||
|---|---|---|---|---|---|---|---|---|---|
(%) | |||||||||
| UC Merced Land-Use | 0.776 | 33.589 | 0.964 | 0.880 | 30.958 | 0.911 | 1.616 | 27.049 | 0.885 |
| AID | 0.711 | 34.062 | 0.965 | 0.666 | 33.122 | 0.942 | 1.395 | 28.419 | 0.889 |
| Dataset | Method | GT OA | Stripe Defects | Noise Defects | Cloud Defects | |||
|---|---|---|---|---|---|---|---|---|
| OA | D2GR | OA | D2GR | OA | D2GR | |||
| UC Merced Land-Use | F2BRBM | 97.23 ± 0.03 | 48.76 ± 0.26 | 50.15 | 70.71 ± 0.32 | 72.72 | 72.63 ± 0.28 | 74.70 |
| F2BRBM + LPIN | 96.56 ± 0.14 | 99.31 | 94.39 ± 0.12 | 97.08 | 93.24 ± 0.09 | 95.90 | ||
| AID | F2BRBM | 96.05 ± 0.02 | 44.34 ± 0.12 | 46.16 | 35.08 ± 0.27 | 36.52 | 60.88 ± 0.30 | 60.38 |
| F2BRBM + LPIN | 94.05 ± 0.22 | 97.92 | 91.76 ± 0.19 | 95.53 | 89.23 ± 0.42 | 93.00 | ||
| Network Architecture | With LSTM | Without LSTM | |
|---|---|---|---|
| Stripe defects | (%) | 2.786 | 1.015 |
| (dB) | 22.048 | 31.193 | |
| 0.785 | 0.935 | ||
| Noise defects | (%) | 2.774 | 2.330 |
| (dB) | 23.131 | 24.690 | |
| 0.664 | 0.715 | ||
| Cloud defects | (%) | 2.908 | 1.630 |
| (dB) | 21.751 | 26.885 | |
| 0.825 | 0.875 | ||
| Reconstruction Loss | L1 Loss | Negative SSIM Loss | |
|---|---|---|---|
| Stripe defects | (%) | 1.400 | 1.015 |
| (dB) | 28.989 | 31.193 | |
| 0.887 | 0.935 | ||
| Noise defects | (%) | 2.780 | 2.330 |
| (dB) | 23.329 | 24.690 | |
| 0.656 | 0.715 | ||
| Cloud defects | (%) | 1.664 | 1.630 |
| (dB) | 27.053 | 26.885 | |
| 0.867 | 0.875 | ||
| Feature Extractor | ResNet50 | VGG16 | |
|---|---|---|---|
| Stripe defects | (%) | 1.356 | 1.357 |
| (dB) | 30.978 | 30.912 | |
| 0.903 | 0.910 | ||
| Noise defects | (%) | 2.403 | 2.418 |
| (dB) | 24.715 | 24.841 | |
| 0.767 | 0.761 | ||
| Cloud defects | (%) | 1.710 | 1.671 |
| (dB) | 26.554 | 26.715 | |
| 0.852 | 0.849 | ||
| Feature Extractor Layer | Maxpooling | Convolution | |
|---|---|---|---|
| Stripe defects | (%) | 1.063 | 1.015 |
| (dB) | 30.834 | 31.193 | |
| 0.930 | 0.935 | ||
| Noise defects | (%) | 2.987 | 2.330 |
| (dB) | 22.748 | 24.690 | |
| 0.636 | 0.715 | ||
| Cloud defects | (%) | 1.654 | 1.630 |
| (dB) | 26.453 | 26.885 | |
| 0.875 | 0.875 | ||
| Defect Type | |||
|---|---|---|---|
| Stripes + noises | 1.255 | 30.824 | 0.928 |
| Stripes + clouds | 2.014 | 26.883 | 0.855 |
| Noises + clouds | 1.927 | 26.847 | 0.846 |
| Stripes + noises + clouds | 2.456 | 26.075 | 0.822 |
| Defect Type | Methods | GT OA | OA | D2GR |
|---|---|---|---|---|
| Stripes + Noises | F2BRBM | 94.72 ± 0.38 | 30.17 ± 0.44 | 31.85 |
| F2BRBM + LPIN | 93.97 ± 0.28 | 99.21 | ||
| Stripes + clouds | F2BRBM | 19.18 ± 0.82 | 20.25 | |
| F2BRBM + LPIN | 87.66 ± 0.52 | 92.55 | ||
| Noises + clouds | F2BRBM | 19.75 ± 0.76 | 20.85 | |
| F2BRBM + LPIN | 87.16 ± 0.35 | 92.02 | ||
| Stripes + noises + clouds | F2BRBM | 9.67 ± 0.68 | 10.21 | |
| F2BRBM + LPIN | 84.99 ± 0.48 | 89.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, W.; Zhang, X.; Wu, H.; Zhang, W.; Du, Y.; Sun, J. LPIN: A Lightweight Progressive Inpainting Network for Improving the Robustness of Remote Sensing Images Scene Classification. Remote Sens. 2022, 14, 53. https://doi.org/10.3390/rs14010053
An W, Zhang X, Wu H, Zhang W, Du Y, Sun J. LPIN: A Lightweight Progressive Inpainting Network for Improving the Robustness of Remote Sensing Images Scene Classification. Remote Sensing. 2022; 14(1):53. https://doi.org/10.3390/rs14010053
Chicago/Turabian StyleAn, Weining, Xinqi Zhang, Hang Wu, Wenchang Zhang, Yaohua Du, and Jinggong Sun. 2022. "LPIN: A Lightweight Progressive Inpainting Network for Improving the Robustness of Remote Sensing Images Scene Classification" Remote Sensing 14, no. 1: 53. https://doi.org/10.3390/rs14010053
APA StyleAn, W., Zhang, X., Wu, H., Zhang, W., Du, Y., & Sun, J. (2022). LPIN: A Lightweight Progressive Inpainting Network for Improving the Robustness of Remote Sensing Images Scene Classification. Remote Sensing, 14(1), 53. https://doi.org/10.3390/rs14010053