1. Introduction
Hyperspectral remote sensing integrates imaging and spectrum technology to acquire rich information in both the spatial and spectral dimensions. In particular, the spectral data are in great abundance, when compared with high-resolution and multispectral images [
1]. The almost continuous spectral curve provides excellent conditions for accurate ground object classification. Thus, hyperspectral images (HSIs) have attracted extensive attention in many fields, such as agricultural crop growth, environmental monitoring [
2,
3], urban planning, military target monitoring, and other fields [
4,
5,
6]. However, some interference factors, including equipment and transmission errors, light conditions, air components, and their jointly presented interferences, cause spectral features to be trapped in a state of high-dimensional non-linearity, increasing the difficulty of carrying out effective objects recognition.
Many shallow machine learning approaches, such as linear discriminant analysis (LDA) [
7], support vector machine [
8], multinomial logistic regression [
9], and dynamic or random subspace [
10,
11], have achieved great success in feature mapping and target recognition, but their use of shallow hidden unit processing restricts their ability to represent data sets with the complicated high-order non-linear distribution.
Deep neural networks, which benefit greatly from layer-wise feature learning (i.e., from shallow to deep), have exhibited excellent performance in the discovery of salient higher-level contextual information buried in data, and have achieved great success in the field of computer vision. The same is true for HSIs [
12]. The stacked sparse autoencoder (SSAE) [
13,
14,
15] and deep belief networks (DBNs) [
16] have been introduced for efficient extraction. With the spatial consistency assumption, the neighboring pixels of each object are often used as auxiliary information for feature learning. The point-wise fully connected architecture, however, performs relatively poorly in terms of local spatial structure learning.
Convolutional neural networks (CNNs) utilize a local sliding filter in the spatial dimension and have shown a superior ability to learn shallow textures and, particularly, deep semantic information. Thus, CNNs have attracted widespread attention in discriminative spectral–spatial feature learning for HSIs. For example, Chen et al. [
17] have used a one-dimensional CNN (1D-CNN), a two-dimensional CNN (2D-CNN), and a three-dimensional CNN (3D-CNN) for spectral, spatial, and spectral–spatial feature learning, respectively. Their experimental results showed that the fusion of spatial and spectral features leads to a better classification performance. Yang et al. [
18] have proposed a deep CNN with a two-branch architecture for spectral and spatial feature learning and fused the respective learned features through fully connected layers. With the networks becoming deeper for high-order, non-linear fitting, ResNet [
19], DenseNet [
20], LSTM [
21], and other enhanced models have been introduced to avoid overfitting and gradient disappearance during parameter training. These features have also been integrated into the spectral–spatial feature learning of HSIs. Hyungtae Lee [
22] has introduced two residual blocks for deep feature learning and used multi-scale filter banks in the initial layer to fully exploit the local contextual information. Mercedes E. Paoletti [
23] has proposed the use of deep pyramidal residual networks for HSI classification, where pyramidal bottleneck residual units are constructed to allow for faster and more accurate feature extraction. Considering the strong complementary and correlated information among different hierarchical layers, multiscale fusion has been confirmed to be much more efficient for discriminative feature learning. Song et al. [
24] have proposed the use of a deep feature fusion network (DFFN), where a fusion mechanism and some residual blocks are utilized to maximize feature interactions among multiple layers. HSIs benefit greatly from hyper-resolution in the spectrum, with which 3D-CNN is more suitable than 2D-CNN for simultaneous spatial and spectral feature learning. Hence, 3D cubes from raw HSI were directly input to a 3D-CNN for feature learning [
25]. Meanwhile, various other modifications have emerged, such as the spectral–spatial residual network (SSRN) [
26] and the deep multilayer fusion dense network (MFDN) [
27]. One major drawback of 3D-CNN is the exponential growth of its training parameters, which leads to a high computational cost, storage burden, and a decline in the model’s generalizability. Thus, 3D filters with kernels of size
were first introduced into the SSRN [
26], in order to reduce the dimensionality of spectral features. Then, filtering is carried out with 3D kernels of size
for spectral–spatial feature learning. The MFDN [
27] adopts a similar spectral processing method, but it extracts spatial features using a 2D-CNN in parallel; thereafter, dense connections are introduced to fuse the multi-layered features. Moreover, lightweight 3D network architecture raised great concern in recent years [
28,
29,
30,
31]. Ghaderizadeh et al. proposed a hybrid 3D-2D convolution network [
28] for spectral–spatial information representation, where PCA and depth-wise 3D-CNN are used to reduce the parameters and computational cost. Cui et al. proposed a LiteDepthwiseNet (LDN) [
31] architecture for HSI classification, which decomposed the standard 3D-CNN into depth-wise and group 3D convolution as well as point-wise convolution. Depth-wise separable 3D-CNN can greatly reduce the parameters and computational cost, but the already heavy communication cost can be doubled. Moreover, double branched feature extraction and fusion made the problem worse.
The aforementioned feature learning networks, extracting spectral–spatial features either with a front–end framework or in parallel and then merging them together, although showing a satisfactory level of performance, are limited in multiscale spectral–spatial feature perception and interactions, otherwise suffer certain computation and communication burden. A heavy network framework serves to dramatically delay its promotion and application on mobile terminals. It has recently been demonstrated that parameter reduction is not the only consideration for lightweight model development. Communication costs and floating point operations (FLOPs) are also noteworthy, where the former is related to the average reasoning time of a model [
32] and the latter represents its computational power consumption. In this paper, we propose a novel lightweight multilevel feature fusion network (LMFN) for HSI Classification, which is designed to achieve spectral–spatial feature learning with enhanced multiscale information interaction while reducing the computational burden and parameter storage required. The LMFN contains two main parts, as shown in
Figure 1: A lightweight spectral–spatial 3D-CNN and object-guided multilevel feature fusion. In the first part, a standard 3D-CNN is factorized into successive 3D point-wise (3D-PW) and subsequent sequential 2D depth-wise (2D-DW) convolutions. The former focuses on multiscale band correlation learning by layer-wise perception (from shallow to deep), while the latter concentrates on spatial neighborhood dependence mapping. In order to encourage multilevel feature fusion while reducing the flow of interfering information in the neighborhood within the series-mode frame, a target-guided fusion mechanism (TFM) is constructed between the separate feature extraction modules, where the front multiscale spectral features are added to the high-level spatial module along with object-based neighborhood dependency measurement. Additionally, the TFM can make up for the loss of channel correction and encourage more reasonable spatial resource allocation. Furthermore, in addition to the long-range skip-connection, we introduce a residual connection in the spectral module to allow for smooth information circulation from the shallow to deep layers, as well as a multi-scale filter bank at the end of the spatial module to provide multi-level feature fusion. Our experimental results demonstrate that the LMFN achieves satisfactory classification accuracy, particularly for HSI data sets with more spectral bands but stronger noise interference. Additionally, indicator analyses of Convolutional Input/Output (CIO) [
32], FLOPs, and the number of parameters in the experiment demonstrate that our proposed model has a reasonable execution time.
The rest of this paper is organized as follows: We demonstrate our motivation by introducing the traditional 3D-CNN, then detail the proposed lightweight convolution factorization and target-guided fusion mechanism in
Section 2.
Section 3 reports the network configuration, experimental results, and corresponding discussions.
Section 4 provides some conclusions.
2. Methodology
In this section, we first present the strengths and weaknesses of 3D-CNN in HSI feature learning. Thereafter, the proposed LMFN is detailed in two parts: The lightweight network architecture for multilevel feature learning and multiscale spectral–spatial interaction with the target-guided fusion mechanism.
2.1. Outline of the 3D-CNN for HSI Feature Learning
According to the combination of imaging and spectral technology, hyperspectral data are saved as a 3D digital cube, denoted as a tensor , with spatial size and spectral band number B (which is generally greater than one hundred). Its extremely high resolution prompts the spectrum to be better for mining the physical properties of ground objects, allowing for more accurate recognition. However, high-resolution image acquisition systems tend to corrupt the data with lots of noise, leaving the HSI with high-order non-linearity. Deep neural networks have excellent ability to approximate complex functions, especially CNNs for image data tasks. The 2D-CNN, with outstanding advantages in high-level spatial feature learning, has been widely used for natural image recognition purposes. Spectral information has received less attention, in relation to the 2D-CNN. This is principally attributed to the use of digital color images with only red, green, and blue channels, which provides a limited contribution to object recognition. The high-resolution spectra present in HSIs have led to new proposals, as well as new challenges, in ground object recognition.
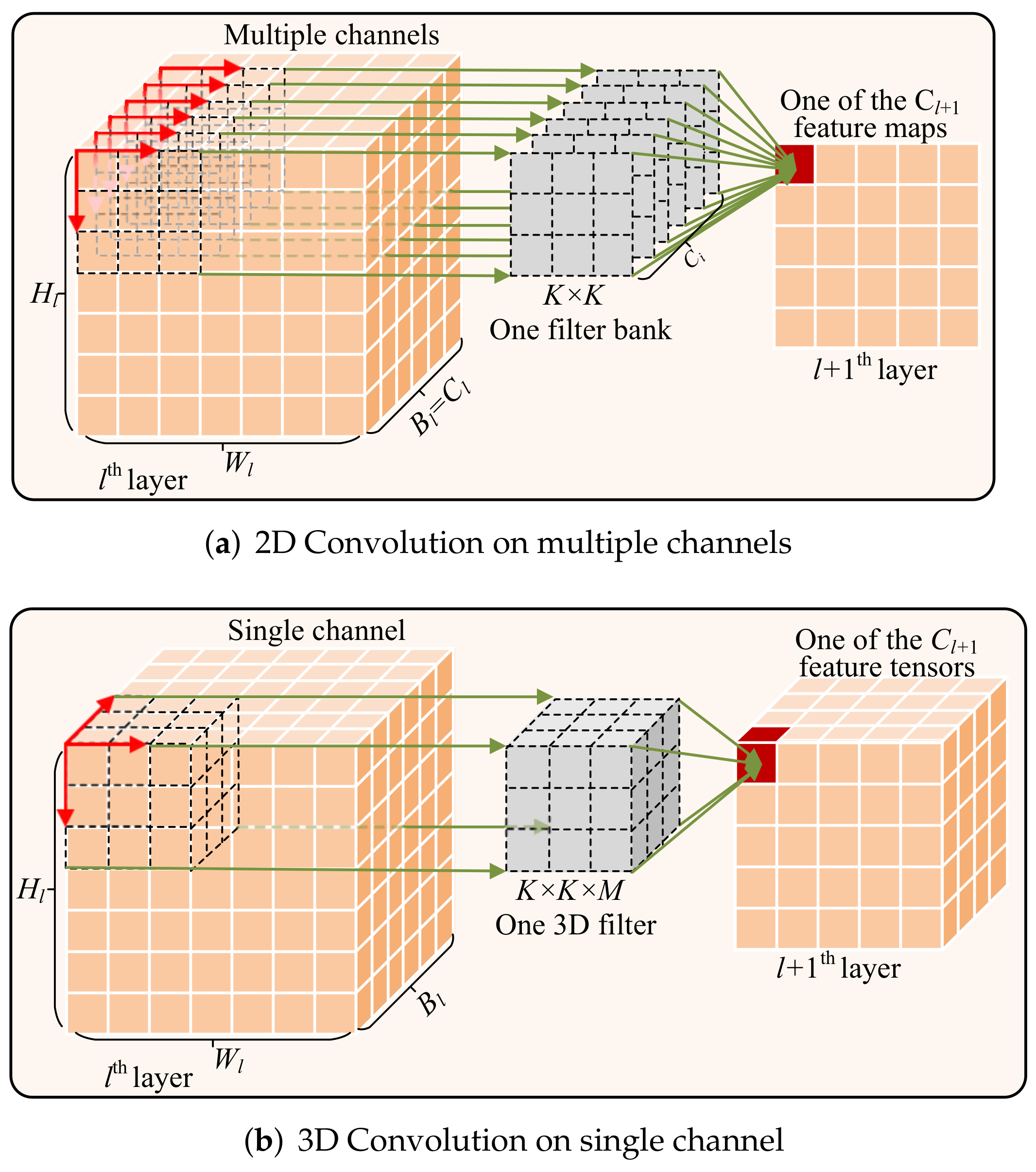
In a standard 2D-CNN, as seen in
Figure 2a,
convolution kernels
with a kernel size of
perform one-on-one Multiply–Add operations on
input channels in
in a sliding-window manner, from top left to bottom right (⊗ indicates this operation), and with a default protocol where
is equal to the input size
. The obtained
output slices are then accumulated to produce one feature map
. The 2D-CNN focuses on spatial local perception and feature recombination, but pays less attention to spectral local perception. This processing can easily result in spectral information loss when compressing all of the convolutional results into one presentation for the subsequent layer, and the global perception on the spectral domain ignores the local dependence, which is relatively stronger than the spatial dependence used in HSIs. In order to focus on spectral–spatial multiscale perception simultaneously and equally, a 3D-CNN is a better choice. Different from the 2D-CNN, the 3D-CNN performs local convolution in three directions (as seen in
Figure 2b) with kernel
, which adds another dimension to
and
. The difference in kernel size brings distinct compositions to the input
and output
, where all channels are 3D tensors, but not 2D matrices.
Figure 2b shows the case of a single channel (i.e.,
). From the different operations, the 3D-CNN has significantly increased parameter counts and computational cost, compared with the 2D-CNN; for example, it has
M times more parameters when set with the same input–output channels and ignoring the offsets. A similar situation occurs for CIO and FLOPs, where 3D-CNN increases the communication cost by
times when setting the padding process for all convolution operations. Its computational cost is
times that of the 2D-CNN.
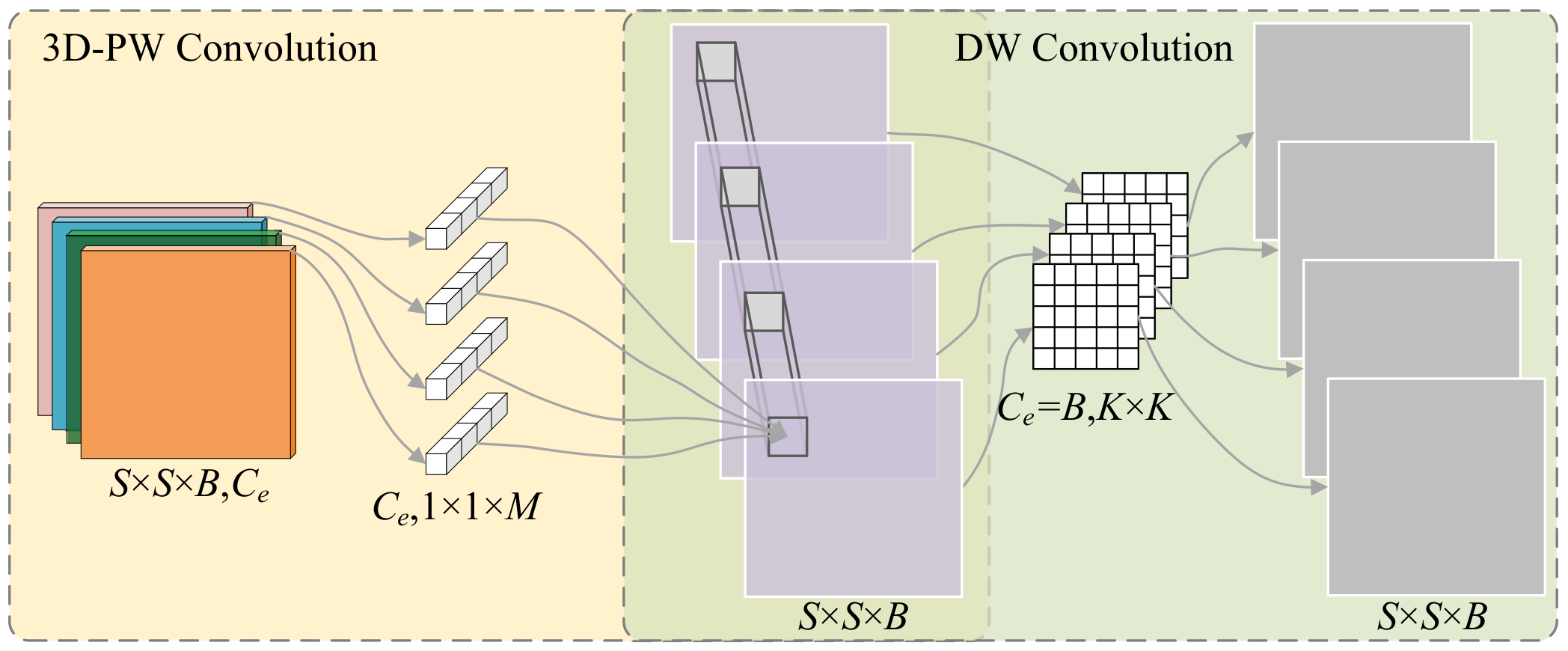
Depth-wise separable convolution factorizes the traditional 2D-CNN into two parts: depth-wise convolution (DW) and point-wise convolution (PW). This factorization drastically reduces the number of parameters and computational burden of 2D-CNNs, while maintaining almost the same feature learning effect [
33]. Decoupling 3D-CNN in the same way although could decrease training parameters and FLOPs, the already large CIO will be doubled. For lightweight 3D spectral–spatial convolution, we separate the 3D-CNN into successive 3D point-wise convolution (PW) and 2D depth-wise convolution (DW), as seen in
Figure 3. We aimed to discover multiscale local correlations among the spatial and spectral spaces in the HSI simultaneously and learn discriminative features, while having fewer possible parameters and less computation.
2.2. Lightweight 3D Convolution for Spectral–Spatial Feature Learning
Due to the extremely limited number of HSIs for training deep segmentation models, object recognition in HSIs is usually seen as a pixel-wise classification task. Thus, a 3D patch
with a spatial size of
and
N neighboring pixels is split out as an input, in order to help in identifying the center pixel on the basis of the neighborhood consistency assumption and auxiliary spatial information. For lightweight multiscale perception from the spectral and spatial domains, we separate spectral–spatial feature extraction into two modules—spectral correlation learning (top line in
Figure 1) and spatial feature mapping (bottom line)—in an end-to-end manner.
In the spectral feature extraction module, 3D filters
are introduced to perform the convolution operation, where the depth
M is less than the band number
B. This is called 3D-PW. Deep CNNs abstract and conceptualize object representation by combining features from shallow textures to deep semantic information, where an important concept is the receptive field. To extract higher-order semantic information from the spectrum, we use five 3D-PW layers for neighborhood relationship mining with a gradual increase in the receptive field. All convolutions are set with the same kernel size and slide with stride 1; except for the first layer, which has stride 2 for dimension reduction.
Figure 1 shows the receptive field size of each layer as
and
, where
is the size of the spectral dimension and
is the spatial receptive field. In the spectral module, the value of
remains unchanged from 1, as none of the spatial neighborhood perception is presented here. In consideration of the relatively simple local directional information in the spectrum, and to achieve a more lightweight network, only one 3D kernel is used in each 3D-PW layer, which means
, and the output
has the same size (
) when the paddings are set for all convolutions. Experiments showed that including more 3D filters in each layer does not contribute to a greater classification accuracy. To alleviate the “Distortion” in the original spectral information during feature composition, and to prevent model degradation as the network deepens, we added shortcut connections between layers to aggregate low-level features from the feed-forward network to high-level layers, ensuring the deep layer has more (or, at least, no less) image information than the shallow one. Additionally, batch normalization (BN) follows each 3D-PW convolution, in order to enhance the generalizability and convergence behavior of the model. For further details about the settings, please see
Figure 1.
In the spatial correlation learning module with lightweight architecture, we exclusively focused on each feature map but left channel correlations to the preceding spectral module. Thus, DW convolution was introduced to extract spatial features. Unlike the 2D-CNN, which produces a new representation by grouping features from the previous layer, DW applies a single convolutional kernel
specifically to each input channel
(as seen in
Figure 3), and produces one corresponding feature representation in the
th layer. To ensure that the spatial module possesses a large spectral receptive field for multiscale fusion, the spatial module is followed by the foregoing spectral module. With the originally limited spatial neighborhood in the input patch, there are only three DW layers for layer-wise perception and padding is set for all convolutions. In the spatial module, the value of
remains unchanged as the last 3D-PW layer, as none of the channel neighborhood perception is presented here, but the spatial receptive field is enlarged along with the layer-wise DW convolution.
With this decomposition, our network backbone is much more lightweight. For comparison with the 3D-CNN on an equal basis, we carried out once-through spectral–spatial convolution with one 3D-PW spectral module and one DW spatial module (as illustrated in
Figure 3), with the same filter size as detailed in
Section 2.1. This combined block produced the following number of parameters:
where
M represents the 3D-PW convolution and
represents the DW convolution. The computational cost was
FLOPs, in total. Both indicators had lower values than the original depth-wise separable convolution, which can mainly be attributed to the use of only one 3D filter in the 3D-PW for local spectral recombination. Our decoupled spectral–spatial convolution achieved a much better effect than the standard 3D-CNN, even when we set the 3D-PW part with the same filter bank. More specifically, our proposed model produced about the parameters and the computational cost of the 3D-CNN. Factorization of 3D-CNN into 3D-PW and DW caused our method to require twice the communication cost for the CIO, compared with the standard 2D-CNN, but this increase is acceptable, compared with the traditional 3D-CNN ( times that of 2D-CNN).
2.3. Target-Guided Fusion Mechanism
The separation of the spectral and spatial modules can easily lead to information loss as the network deepens, especially when spatial filtering follows the spectral module. Meanwhile, the large size of the spectral-spatial receptive field at the end of the network framework causes the feature to be insensitive to local finer perception. Moreover, DW convolution filters each input feature map independently, giving fast response and performance, but it tends to break the correlations between channels. Direct addition of the foregoing multiscale spectral features which with the smallest spatial receptive field, to the depth-wise spatial module, can compensate for the problem mentioned above. However, the intact spatial adjacent relationship may cause irrelevant information and especially the noise flow into the deep layers. A target-guided fusion mechanism (TFM), therefore, is proposed to enhance adjacent spectral correction and focus on pixels which actively boost the target classification accuracy, while performing multiscale feature fusion. The primary line is formulated as
where
denotes the calculated target-based response from one feature bank
in the spectral module, and
is a feature tensor from the spatial convolution module. The spectral module contains features with incremental receptive fields in the spectral domain but with unaltered neighborhood perception in the spatial domain, while the spatial module has the reverse situation. Thus, we added
sequentially to the spatial module to achieve spectral–spatial fusion.
is the obtained multiscale feature from one set of spectral–spatial features.
As mentioned earlier, a block of neighborhood members around the center pixel
are split out to assist with target classification. These neighbors inevitably contain some pixels unrelated to the center target, particularly for ground surface objects with limited contributions to high-level outlines. This means that not all the neighborhood information has a positive effect on network performance improvement. Hence, before feature fusion, pairwise-dependent relationships are built between
and its neighborhood
in
from the spectral layer, and the tensor
is produced to guide spatial convolution, paying close attention to areas that should be of concern. This is formulated as:
where
is the set of
N neighbors (
) around
, and
is the output of TFM, with the same size as
, to be fused. The function
measures the correlation between
and
: the larger the value, the higher the correlation and, thus, the greater the influence of the weight on the center point. We chose the Cosine distance to measure the similarity. The target-guided fusion mechanism can be seen as a 2D convolution on
(as seen in
Figure 4), and the kernel
is generated by the feature at the input center; that is,
. Then, TFM can be formulated as:
where ⊗ and ⊙ indicate 2D convolution and scalar multiplication, respectively. The sigmoid function
is designed here with two main considerations: (1) It can compress the obtained similarity value into
, in order to produce a controllable weighting coefficient; (2) it will heighten the areas of attention by stretching the two extreme values (positive or negative) to the saturated zone, thus preventing further noise passing through when information flows from the previous layers.
We can conclude that one TFM block increases CIO and FLOPs from the dependence measurement and point-wise multiplication, and has about the communication cost and the computational cost of the 3D-CNN, on the basis of the previous analysis.
The 3D-PW and DW convolution operations can be regarded as feature mapping in spectral and spatial spaces independently, while the TFM is responsible for interaction and circulation of the information, with clear division of the two. As little burden is produced, in terms of parameters storage and computational cost, we present three TFMs on the end of each identity residual block for long range skip-connection and multiscale spectral–spatial fusion, as shown in
Figure 1. After the 3D interactive feature learning, a multi-scale filter bank (with kernel size of
,
,
) and GELU activation are introduced for local multi-level convolution of the input feature, using
filters to address channel correlations. Finally, a global average pooling (GAP) and fully connected (FC) layer are introduced for probability prediction of object classification.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}