
Hyperspectral Image Classification Based on Non-Parallel Support Vector Machine


Abstract
:1. Introduction
2. Materials and Methods
2.1. Software Description
2.2. Data
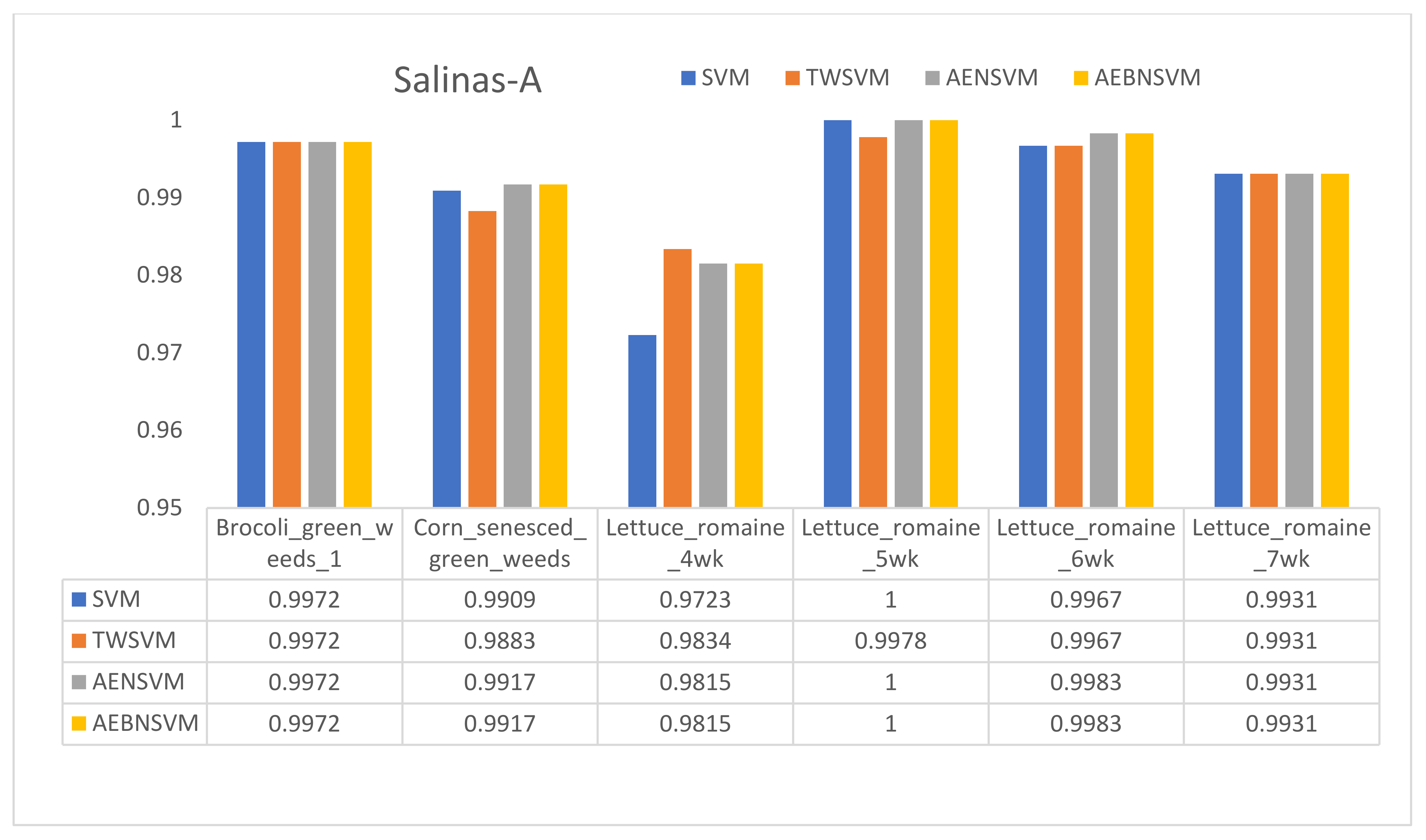
2.2.1. Salinas-A Dataset
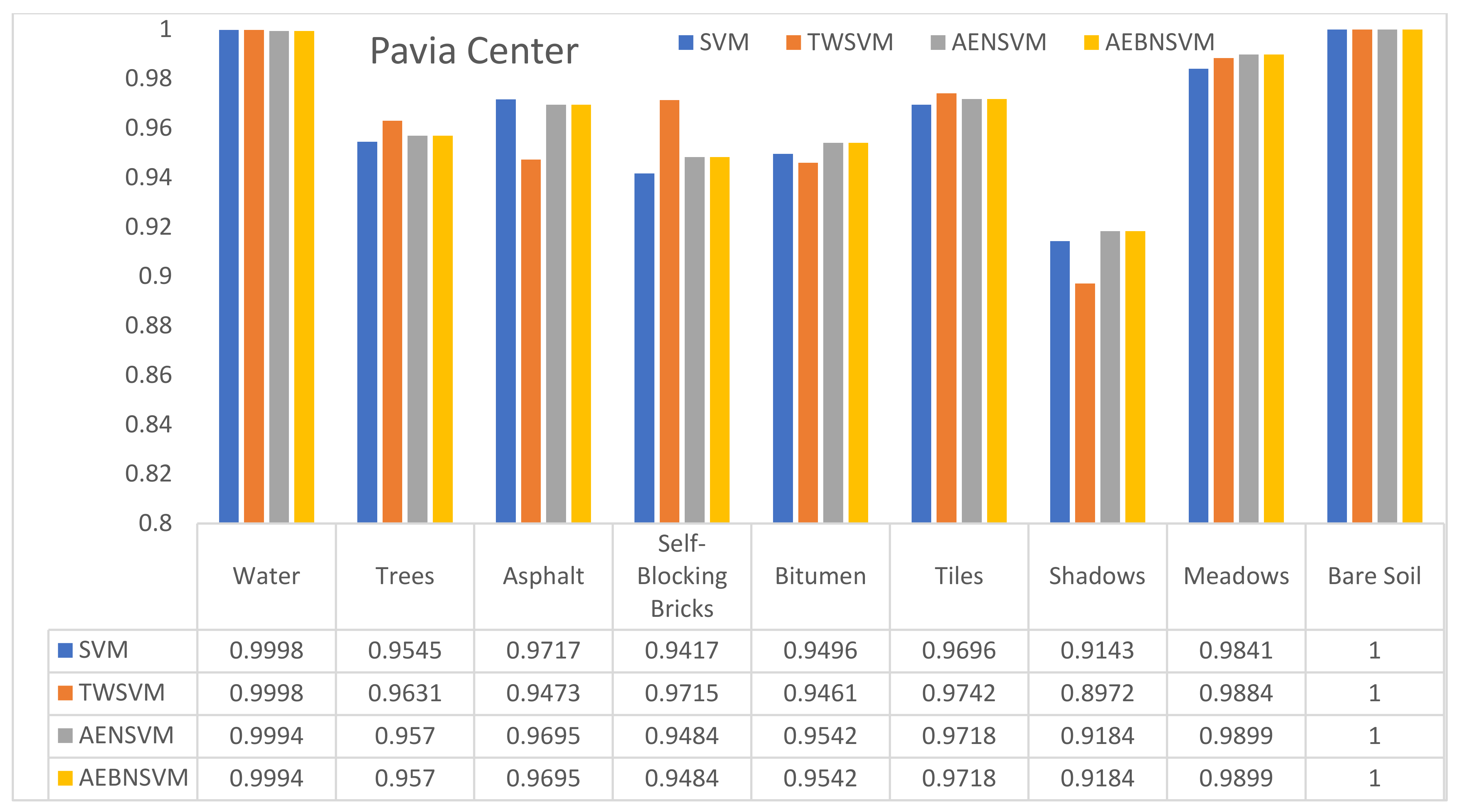
2.2.2. Pavia Center Dataset
2.2.3. Pavia University Dataset
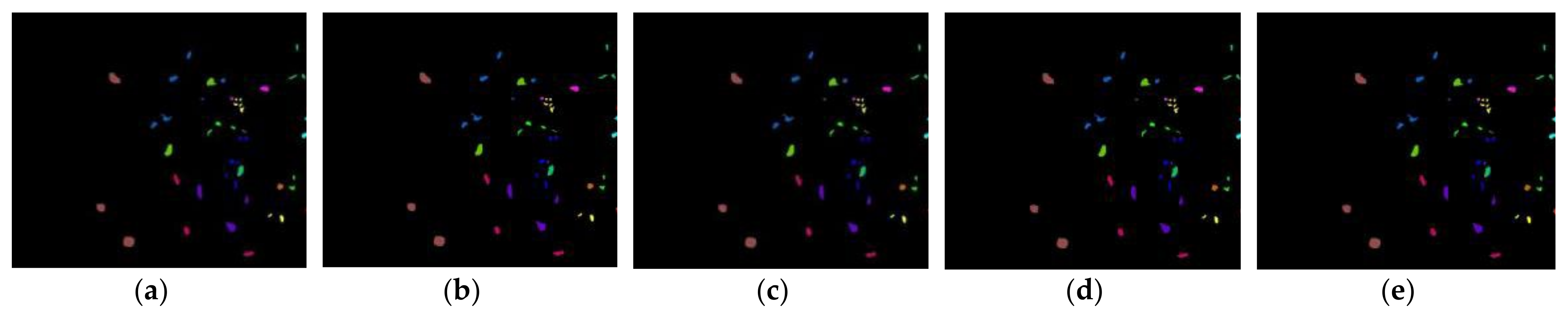
2.2.4. Kennedy Space Center Dataset
2.3. Task
2.4. Support Vector Machine
2.5. Non-Parallel Support Vector Machine
| Algorithm 1. The classification process of the AENSVM algorithm model on the hyperspectral dataset. |
| Step 1: Combining each category of the hyperspectral dataset in pairs is used to obtain binary classification tasks. |
| Step 2: Set the hyperparameters c1, c2, c3, c4 of the AENSVM model. |
| Step 3: Each binary classification task is trained using AENSVM. 1. Use the parameters set in Step 2 to solve the parameters according to Formulas (14) and (18). 2. The offsets of the two decision hyperplanes are obtained by (17) and (20). Finally, classifier models are obtained. |
| Step 4: For the classifier models trained in Step 3, the category of the new sample is predicted by Formula (30), all predicted categories are recorded, and the sample is classified into the category with the most votes by voting. |
2.6. Accuracy Assessment
3. Results
3.1. Salinas-A Dataset
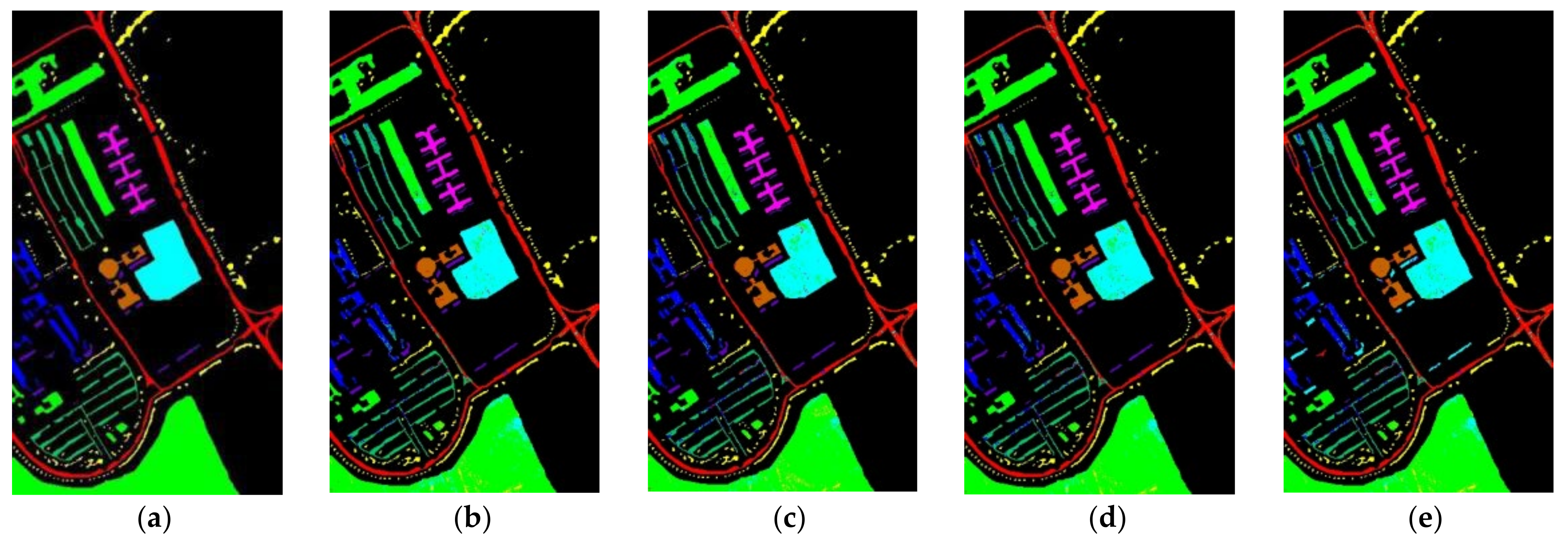
3.2. Pavia Center Dataset
3.3. Pavia University Dataset
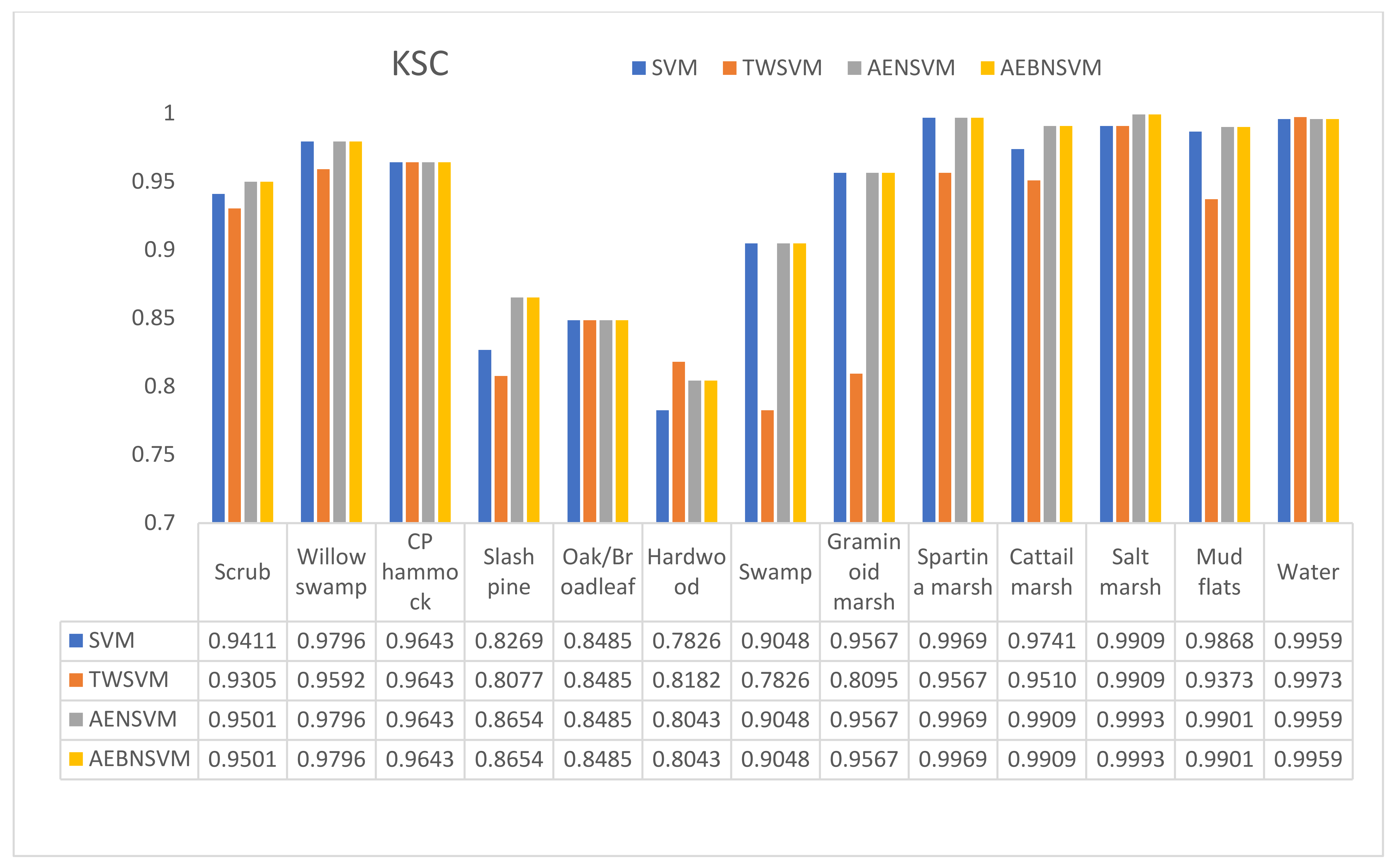
3.4. Kennedy Space Center Dataset
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. AERM-NPSVM
Appendix A.2. BC-AERM-NPSVM
Appendix A.2.1. Linear Case
Appendix A.2.2. Nonlinear Case
References
- Zhong, Y.; Wang, X.; Wang, S.; Zhang, L. Advances in spaceborne hyperspectral remote sensing in China. Geo-Spat. Inf. Sci. 2021, 24, 95–120. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent advances of hyperspectral imaging technology and applications in agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Stein, D.W.; Beaven, S.G.; Hoff, L.E.; Winter, E.M.; Schaum, A.P.; Stocker, A.D. Anomaly detection from hyperspectral imagery. IEEE Signal Processing Mag. 2002, 19, 58–69. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Pei, Y.; Zhao, S.; Xiao, R.; Sang, X.; Zhang, C. A review of remote sensing for environmental monitoring in China. Remote Sens. 2020, 12, 1130. [Google Scholar] [CrossRef] [Green Version]
- Tan, K.; Du, P. Hyperspectral Remote Sensing Image Classification Based on Support Vector Machine. J. Infrared Millim. Waves 2008, 27, 123–128. [Google Scholar] [CrossRef]
- Wang, Y. Remote Sensing Image Automatic Classification with Support Vector Machine. Comput. Simul. 2013, 30, 378–385. [Google Scholar]
- Lv, W.; Wang, X. Overview of Hyperspectral Image Classification. J. Sens. 2020, 2020, 13. [Google Scholar] [CrossRef]
- Song, W.; Li, S.; Kang, X.; Huang, K. Hyperspectral image classification based on KNN sparse representation. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 2411–2414. [Google Scholar] [CrossRef]
- Goel, P.K.; Prasher, S.O.; Patel, R.M.; Landry, J.A.; Bonnell, R.B.; Viau, A.A. Classification of hyperspectral data by decision trees and artificial neural networks to identify weed stress and nitrogen status of corn. Comput. Electron. Agric. 2003, 39, 67–93. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Sain, S.R. The Nature of Statistical Learning Theory; Taylor & Francis: Abingdon, UK, 1996; p. 409. [Google Scholar]
- Zhang, D.; Zhou, Z.H.; Chen, S. Semi-supervised dimensionality reduction. In Proceedings of the 2007 SIAM International Conference on Data Mining. Society for Industrial and Applied Mathematics, Minneapolis, MN, USA, 26–28 April 2007; pp. 629–634. [Google Scholar]
- Harikiran, J.J. Hyperspectral image classification using support vector machines. IAES Int. J. Artif. Intell. 2020, 9, 684. [Google Scholar] [CrossRef]
- Mangasarian, O.L.; Wild, E.W. Multisurface proximal support vector machine classification via generalized eigenvalues. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 28, 69–74. [Google Scholar] [CrossRef] [PubMed]
- Khemchandani, R.; Chandra, S. Twin support vector machines for pattern classification. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 905–910. [Google Scholar]
- Schölkopf, B.; Smola, A.J.; Bach, F. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Zhang, C.; Tian, Y.; Deng, N. The new interpretation of support vector machines on statistical learning theory. Sci. China Ser. A Math. 2010, 53, 151–164. [Google Scholar] [CrossRef]
- Kaya, G.T.; Torun, Y.; Küçük, C. Recursive feature selection based on non-parallel SVMs and its application to hyperspectral image classification. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 3558–3561. [Google Scholar]
- Liu, Z.; Zhu, L. A novel remote sensing image classification algorithm based on multi-feature optimization and TWSVM. In Proceedings of the Ninth International Conference on Digital Image Processing (ICDIP 2017). International Society for Optics and Photonics, Hong Kong, China, 19–22 May 2017. [Google Scholar]
- Wang, L.; Lu, T.; Yang, Y. Least Squares Twin Support Vector Machines Based on Sample Reduction for Hyperspectral Image Classification. In Proceedings of the International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2015), Zhengzhou, China, 11–12 April 2015. [Google Scholar]
- Wang, L.; Du, X. Semi-supervised classification of hyperspectral images applying the combination of K-mean clustering and twin support vector machine. Appl. Sci. Technol. 2017, 44, 12–18. [Google Scholar]
- Okwuashi, O.; Ndehedehe, C.E. Deep support vector machine for hyperspectral image classification. Pattern Recognit. 2020, 103, 107298. [Google Scholar] [CrossRef]
- Kuhn, H.W.; Tucker, A.W. Nonlinear programming. In Traces and Emergence of Nonlinear Programming; Springer: Berlin/Heidelberg, Germany, 2014; pp. 247–258. [Google Scholar]
- Tian, Y.; Ju, X.; Qi, Z.; Shi, Y. Improved twin support vector machine. Sci. China Math. 2014, 57, 417–432. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Samples | Train | Test |
|---|---|---|---|
| Brocoli_green_weeds_1 | 391 | 39 | 352 |
| Corn_seesced_green_weeds | 1343 | 134 | 1109 |
| Lettuce_romaine_4wk | 616 | 61 | 555 |
| Lettuce_romaine_5wk | 1525 | 152 | 1373 |
| Lettuce_romaine_6wk | 674 | 67 | 607 |
| Experimental Method | SVM | TWSVM | AENSVM | AEBNSVM |
|---|---|---|---|---|
| OA | 99.29 | 99.11 | 99.43 | 99.43 |
| Kappa | 99.12 | 98.91 | 99.30 | 99.30 |
| Class | Samples | Train | Test |
|---|---|---|---|
| Water | 65,971 | 300 | 65,671 |
| Trees | 7598 | 300 | 7298 |
| Asphalt | 3090 | 300 | 2790 |
| Self-Blocking Bricks | 2685 | 300 | 2385 |
| Bitumen | 6584 | 300 | 6284 |
| Tiles | 9248 | 300 | 8948 |
| Shadows | 7287 | 300 | 6987 |
| Meadows | 42,826 | 300 | 42,526 |
| Bare Soil | 2863 | 300 | 2563 |
| Experimental Method | SVM | TWSVM | AENSVM | AEBNSVM |
|---|---|---|---|---|
| OA | 98.33 | 98.25 | 98.50 | 98.50 |
| Kappa | 97.62 | 97.50 | 97.86 | 97.86 |
| Class | Samples | Train | Test |
|---|---|---|---|
| Asphalt | 6631 | 300 | 6331 |
| Meadows | 18,649 | 300 | 18,349 |
| Gravel | 2099 | 300 | 1790 |
| Trees | 3064 | 300 | 2764 |
| Painted metal sheets | 1345 | 300 | 1045 |
| Bare Soil | 5029 | 300 | 4729 |
| Bitumen | 1330 | 300 | 1030 |
| Self-Blocking Bricks | 3682 | 300 | 3382 |
| Shadows | 947 | 300 | 647 |
| Experimental Method | SVM | TWSVM | AENSVM | AEBNSVM |
|---|---|---|---|---|
| OA | 91.49 | 91.53 | 92.53 | 92.43 |
| Kappa | 88.76 | 88.77 | 90.05 | 89.92 |
| Class | Samples | Train | Test |
|---|---|---|---|
| Scrub | 761 | 200 | 561 |
| Willow swamp | 243 | 194 | 49 |
| CP hammock | 256 | 200 | 56 |
| Slash pine | 252 | 200 | 52 |
| Oak/Broadleaf | 161 | 128 | 33 |
| Hardwood | 229 | 184 | 45 |
| Swamp | 105 | 84 | 21 |
| Graminoid marsh | 431 | 200 | 231 |
| Spartina marsh | 520 | 200 | 320 |
| Cattail marsh | 404 | 200 | 204 |
| Salt marsh | 419 | 200 | 219 |
| Mud flats | 503 | 200 | 303 |
| Water | 527 | 200 | 327 |
| Experimental Method | SVM | TWSVM | AENSVM | AEBNSVM |
|---|---|---|---|---|
| OA | 96.78 | 95.39 | 96.95 | 96.95 |
| Kappa | 96.22 | 94.72 | 96.51 | 96.51 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, G.; Wang, L.; Liu, D.; Fei, L.; Yang, J. Hyperspectral Image Classification Based on Non-Parallel Support Vector Machine. Remote Sens. 2022, 14, 2447. https://doi.org/10.3390/rs14102447
Liu G, Wang L, Liu D, Fei L, Yang J. Hyperspectral Image Classification Based on Non-Parallel Support Vector Machine. Remote Sensing. 2022; 14(10):2447. https://doi.org/10.3390/rs14102447
Chicago/Turabian StyleLiu, Guangxin, Liguo Wang, Danfeng Liu, Lei Fei, and Jinghui Yang. 2022. "Hyperspectral Image Classification Based on Non-Parallel Support Vector Machine" Remote Sensing 14, no. 10: 2447. https://doi.org/10.3390/rs14102447
APA StyleLiu, G., Wang, L., Liu, D., Fei, L., & Yang, J. (2022). Hyperspectral Image Classification Based on Non-Parallel Support Vector Machine. Remote Sensing, 14(10), 2447. https://doi.org/10.3390/rs14102447