
Reference-Based Multi-Level Features Fusion Deblurring Network for Optical Remote Sensing Images


Abstract
:
1. Introduction
- As a publicly available remote sensing image platform, Google Earth provides high-resolution satellite images from around the world. It is feasible to pick up images from Google Earth as reference images.
- The imaging process of many satellites is periodic and a large number of images of the same region at different time are accumulated, which can be used as reference images.
- To the best of our knowledge, we are one of the first to explore reference-based deblurring method on remote sensing images.
- We designed a novel MFFN module, which registers the reference image and the blurry image in the multi-level feature space and transfers the high-quality textures from registered reference features to assist image deblurring. Furthermore, the effectiveness of MFFN is demonstrated by the ablation experiments.
- We construct a dataset for blind remote sensing image deblurring with data from the United States Department of Agriculture (USDA). In the testing set, our algorithm outperforms all comparative methods in both quantitative evaluation and visual results, which proves the great potential of the reference-based deblurring approach in the field of remote sensing.
2. Related Works
2.1. Learning-Based Blind Deblurring Algorithms
2.2. Reference-Based SR Algorithms
3. Materials and Methods
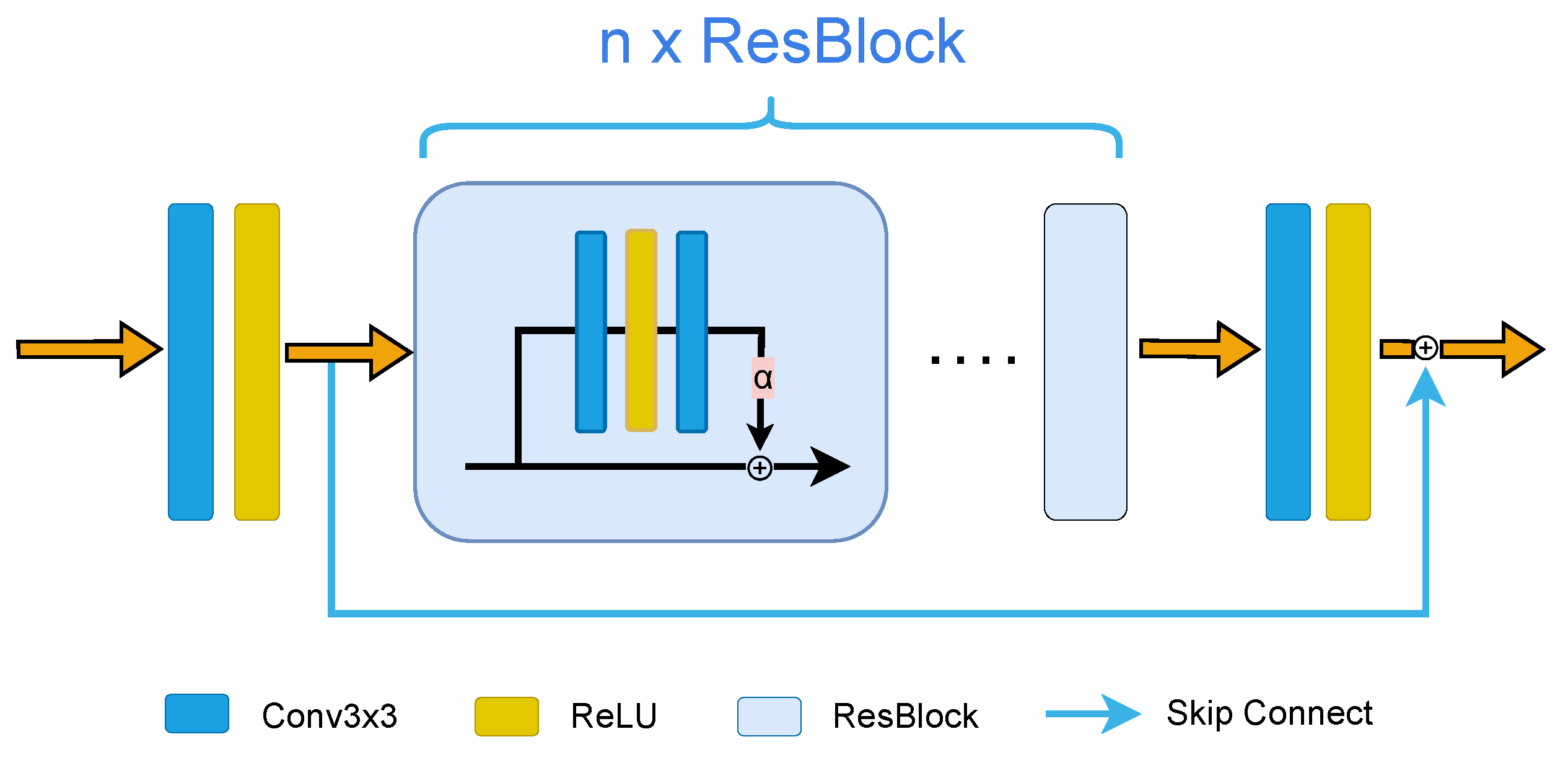
3.1. Multi-Level Features Fusion Network
3.2. Encoder Network
3.3. Decoder Network
3.4. Loss Function
3.5. Datasets and Metrics
3.6. Implementation Details
4. Results
4.1. Quantitative and Qualitative Evaluation
4.2. Ablation Study
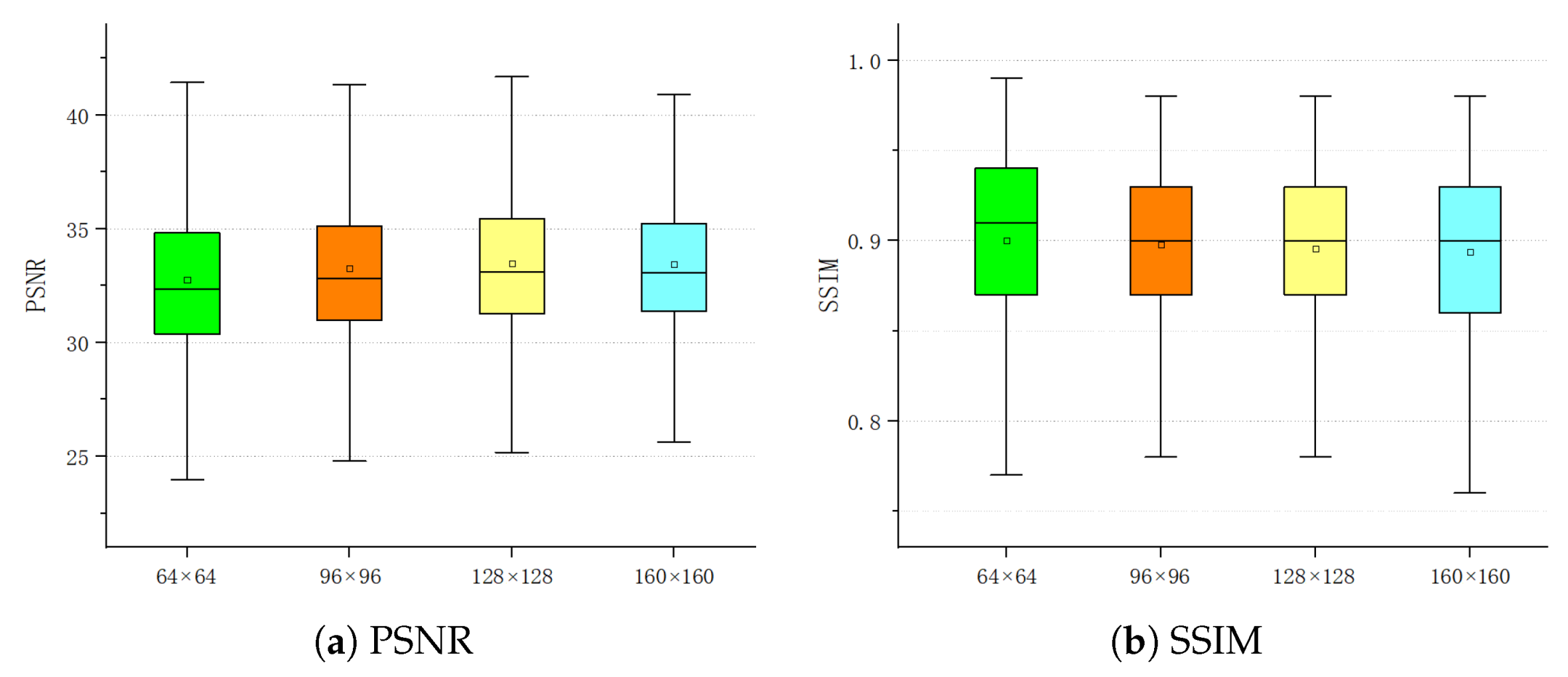
4.2.1. Robustness to Image Size
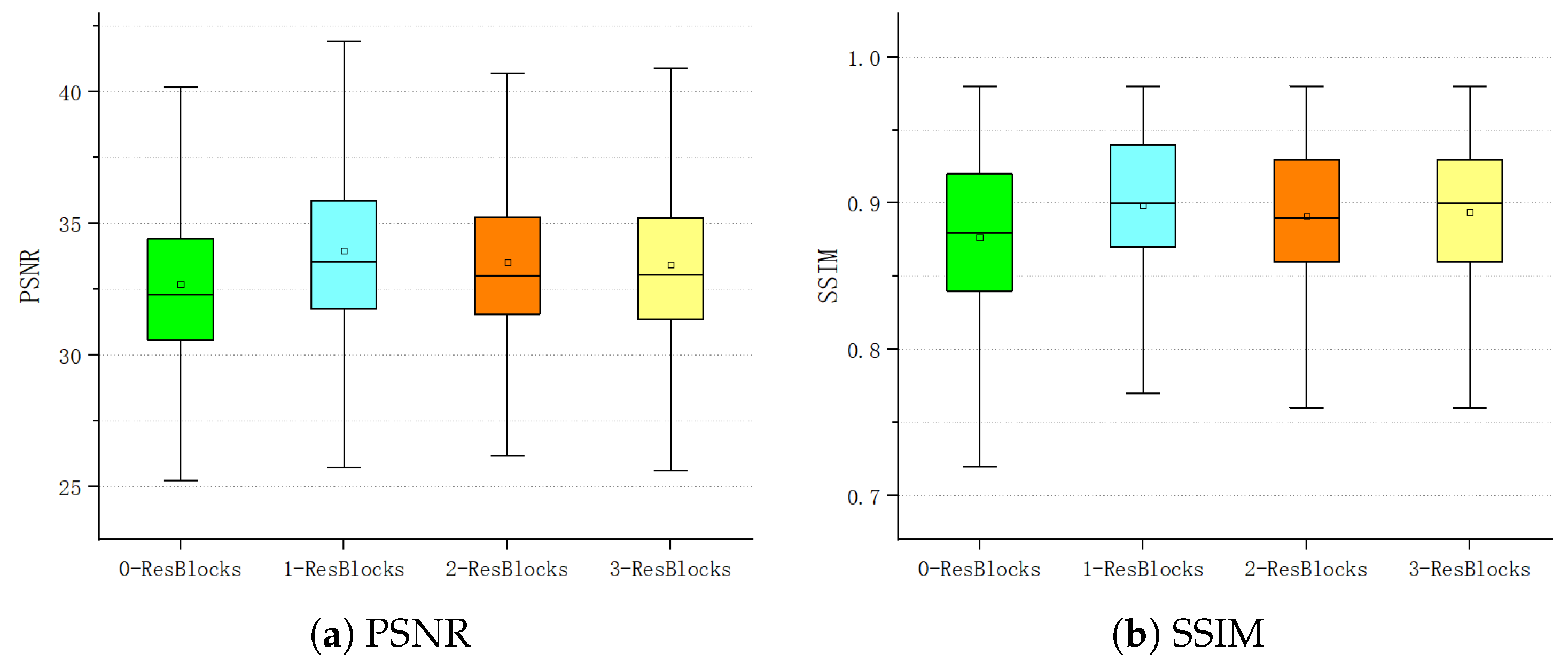
4.2.2. Effectiveness of MFFN and MFE
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Ref-MFFDN | Reference-based Multi-level features fusion Deblurring Network |
| MFE | Multi-level features extractor |
| EN | Encoder network |
| DN | Decoder network |
| PSNR | Peak-Signal-to-Noise Ratio |
| SSIM | Structural-Similarity |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Layer Name |
|---|---|
| VGG19(1∼4) | Conv (3, 64, 3, 1, 1) |
| ReLU() | |
| Conv (3, 64, 3, 1, 1) | |
| ReLU() | |
| Conv(64, n_feats, 3, 1, 1) | |
| ResBlock-1 | Conv(n_feats, n_feats, 3, 1, 1) |
| ReLU() | |
| Conv(n_feats, n_feats, 3, 1, 1) | |
| ResBlock-2 | Conv(n_feats, n_feats, 3, 1, 1) |
| ReLU() | |
| Conv(n_feats, n_feats, 3, 1, 1) | |
| ResBlock-3 | Conv(n_feats, n_feats, 3, 1, 1) |
| ReLU() | |
| Conv(n_feats, n_feats, 3, 1, 1) |
| Stage | Layer Name |
|---|---|
| Conv_head | Conv (3, n_feats, 3, 1, 1) |
| ReLU() | |
| ResBlock × 16 | Conv(n_feats, n_feats, 3, 1, 1) |
| ReLU() | |
| Conv(n_feats, n_feats, 3, 1, 1) | |
| Conv_tail | Conv(n_feats, n_feats, 3, 1, 1) |
| ReLU() |
| Stage | Layer Name |
|---|---|
| Conv_head | Conv(5*n_feats, n_feats, 3, 1, 1) |
| ReLU() | |
| ResBlock × 16 | Conv(n_feats, n_feats, 3, 1, 1) |
| ReLU() | |
| Conv(n_feats, n_feats, 3, 1, 1) | |
| Conv_tail | Conv(n_feats, n_feats, 3, 1, 1) |
| ReLU() | |
| Merge_tail | Conv(n_feats, n_feats, 1, 1, 0) |
| ReLU() | |
| Conv(n_feats, n_feats, 3, 1, 1) | |
| ReLU() | |
| Conv(n_feats, n_feats/2, 3, 1, 1) | |
| Conv(n_feats/2, 3, 1, 1, 0) |
| ID | Layer Name |
|---|---|
| 0 | Conv(3, 32, 3, 1, 1) |
| 1 | LeakyReLU(0.2) |
| 2 | Conv(32, 32, 3, 2, 1) |
| 3 | LeakyReLU(0.2) |
| 4 | Conv(32, 64, 3, 1, 1) |
| 5 | LeakyReLU(0.2) |
| 6 | Conv(64, 64, 3, 2, 1) |
| 7 | LeakyReLU(0.2) |
| 8 | Conv(64, 128, 3, 1, 1) |
| 9 | LeakyReLU(0.2) |
| 10 | Conv(128, 128, 3, 2, 1) |
| 11 | LeakyReLU(0.2) |
| 12 | Conv(128, 256, 3, 1, 1) |
| 13 | LeakyReLU(0.2) |
| 14 | Conv(256, 256, 3, 2, 1) |
| 15 | LeakyReLU(0.2) |
| 16 | Conv(256, 512, 3, 1, 1) |
| 17 | LeakyReLU(0.2) |
| 18 | Conv(512, 512, 3, 2, 1) |
| 19 | LeakyReLU(0.2) |
| 20 | FC((in_size/8)**2*512, 1024) |
| 21 | LeakyReLU(0.2) |
| 22 | FC(1024, 1) |
References
- Kennedy, R.E.; Cohen, W.B.; Schroeder, T.A. Trajectory-based change detection for automated characterization of forest disturbance dynamics. Remote Sens. Environ. 2007, 110, 370–386. [Google Scholar] [CrossRef]
- Netzband, M.; Stefanov, W.L.; Redman, C.L. Remote sensing as a tool for urban planning and sustainability. In Applied Remote Sensing for Urban Planning, Governance and Sustainability; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1–23. [Google Scholar]
- Wellmann, T.; Lausch, A.; Andersson, E.; Knapp, S.; Cortinovis, C.; Jache, J.; Scheuer, S.; Kremer, P.; Mascarenhas, A.; Kraemer, R.; et al. Remote sensing in urban planning: Contributions towards ecologically sound policies? Landsc. Urban Plan. 2020, 204, 103921. [Google Scholar] [CrossRef]
- Mueller, N.; Lewis, A.; Roberts, D.; Ring, S.; Melrose, R.; Sixsmith, J.; Lymburner, L.; McIntyre, A.; Tan, P.; Curnow, S.; et al. Water observations from space: Mapping surface water from 25 years of Landsat imagery across Australia. Remote Sens. Environ. 2016, 174, 341–352. [Google Scholar] [CrossRef] [Green Version]
- Fisher, A.; Flood, N.; Danaher, T. Comparing Landsat water index methods for automated water classification in eastern Australia. Remote Sens. Environ. 2016, 175, 167–182. [Google Scholar] [CrossRef]
- Chan, T.F.; Wong, C.K. Total variation blind deconvolution. IEEE Trans. Image Process. 1998, 7, 370–375. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pan, J.; Hu, Z.; Su, Z.; Yang, M.H. Deblurring text images via L0-regularized intensity and gradient prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2901–2908. [Google Scholar]
- Chen, L.; Fang, F.; Wang, T.; Zhang, G. Blind image deblurring with local maximum gradient prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1742–1750. [Google Scholar]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Blind image deblurring using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern RECOGNITION, Las Vegas, NV, USA, 27–30 June 2016; pp. 1628–1636. [Google Scholar]
- Wang, M.; Zhu, F.; Bai, Y. An improved image blind deblurring based on dark channel prior. Optoelectron. Lett. 2021, 17, 40–46. [Google Scholar] [CrossRef]
- Wen, F.; Ying, R.; Liu, Y.; Liu, P.; Truong, T.K. A simple local minimal intensity prior and an improved algorithm for blind image deblurring. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2923–2937. [Google Scholar] [CrossRef]
- Zhang, Z.; Zheng, L.; Piao, Y.; Tao, S.; Xu, W.; Gao, T.; Wu, X. Blind Remote Sensing Image Deblurring Using Local Binary Pattern Prior. Remote Sens. 2022, 14, 1276. [Google Scholar] [CrossRef]
- Bai, Y.; Jia, H.; Jiang, M.; Liu, X.; Xie, X.; Gao, W. Single-image blind deblurring using multi-scale latent structure prior. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2033–2045. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777. [Google Scholar]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Freeman, W.T.; Jones, T.R.; Pasztor, E.C. Example-based super-resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65. [Google Scholar] [CrossRef] [Green Version]
- Timofte, R.; De Smet, V.; Van Gool, L. Anchored neighborhood regression for fast example-based super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1920–1927. [Google Scholar]
- Zhang, Z.; Wang, Z.; Lin, Z.; Qi, H. Image super-resolution by neural texture transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7982–7991. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5791–5800. [Google Scholar]
- Dong, R.; Zhang, L.; Fu, H. Rrsgan: Reference-based super-resolution for remote sensing image. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–17. [Google Scholar] [CrossRef]
- Xu, X.; Pan, J.; Zhang, Y.J.; Yang, M.H. Motion blur kernel estimation via deep learning. IEEE Trans. Image Process. 2017, 27, 194–205. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Pan, J.; Ren, J.; Song, Y.; Bao, L.; Lau, R.W.; Yang, M.H. Dynamic scene deblurring using spatially variant recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2521–2529. [Google Scholar]
- Li, Y.; Tofighi, M.; Geng, J.; Monga, V.; Eldar, Y.C. Efficient and interpretable deep blind image deblurring via algorithm unrolling. IEEE Trans. Comput. Imaging 2020, 6, 666–681. [Google Scholar] [CrossRef]
- Suin, M.; Purohit, K.; Rajagopalan, A. Spatially-attentive patch-hierarchical network for adaptive motion deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3606–3615. [Google Scholar]
- Yue, H.; Sun, X.; Yang, J.; Wu, F. Landmark image super-resolution by retrieving web images. IEEE Trans. Image Process. 2013, 22, 4865–4878. [Google Scholar] [PubMed]
- Zheng, H.; Ji, M.; Wang, H.; Liu, Y.; Fang, L. Crossnet: An end-to-end reference-based super resolution network using cross-scale warping. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 88–104. [Google Scholar]
- Zheng, H.; Ji, M.; Han, L.; Xu, Z.; Wang, H.; Liu, Y.; Fang, L. Learning Cross-scale Correspondence and Patch-based Synthesis for Reference-based Super-Resolution. Proc. BMVC 2017, 1, 2. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. Adv. Neural Inf. Process. Syst. 2017, 30, 5769–5779. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar]














| Hardware Environment | Single NVIDIA RTX 2080Ti GPU |
| AMD 5800X | |
| Memory 3200 MHz, 32G | |
| Software Environment | Torch 1.7.0 + cu110 |
| Torchvision 0.8.1 + cu110 | |
| Numpy 1.21.2 | |
| Python 3.8.5 | |
| Visdom 0.1.8.9 | |
| Opencv-python 4.4.0.44 |
| Methods | PSNR (dB) | SSIM | Runtime on CPU (s) | Runtime on GPU (s) |
|---|---|---|---|---|
| DeblurGAN [16] | 27.627 | 0.710 | 0.33 | 0.10 |
| DeblurGAN-V2 [36] | 24.293 | 0.601 | 0.17 | 0.07 |
| DeepDeblur [15] | 32.549 | 0.875 | 0.50 | 0.15 |
| PMP [11] | 21.488 | 0.406 | 40.41 | − |
| Ref-MFFDN | 33.436 | 0.894 | 25.33 | 0.36 |
| Image Shape | PSNR (dB) | SSIM |
|---|---|---|
| 32.77 | 0.900 | |
| 33.26 | 0.898 | |
| 33.47 | 0.896 | |
| 33.44 | 0.894 |
| Methods | PSNR (dB) | SSIM | Runtime on CPU (s) | Runtime on GPU (s) |
|---|---|---|---|---|
| No MFFN | 31.563 | 0.858 | 0.59 | 0.09 |
| With MFFN | 33.436 | 0.894 | 25.33 | 0.36 |
| Methods | PSNR (dB) | SSIM | Runtime on CPU (s) | Runtime on GPU (s) |
|---|---|---|---|---|
| 0-ResBlock | 32.691 | 0.877 | 6.67 | 0.19 |
| 1-ResBlock | 33.992 | 0.899 | 12.58 | 0.26 |
| 2-ResBlocks | 33.545 | 0.891 | 19.00 | 0.32 |
| 3-ResBlocks | 33.436 | 0.894 | 25.33 | 0.36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Guo, J.; Zhang, Y.; Li, J.; Wu, Y. Reference-Based Multi-Level Features Fusion Deblurring Network for Optical Remote Sensing Images. Remote Sens. 2022, 14, 2520. https://doi.org/10.3390/rs14112520
Li Z, Guo J, Zhang Y, Li J, Wu Y. Reference-Based Multi-Level Features Fusion Deblurring Network for Optical Remote Sensing Images. Remote Sensing. 2022; 14(11):2520. https://doi.org/10.3390/rs14112520
Chicago/Turabian StyleLi, Zhiyuan, Jiayi Guo, Yueting Zhang, Jie Li, and Yirong Wu. 2022. "Reference-Based Multi-Level Features Fusion Deblurring Network for Optical Remote Sensing Images" Remote Sensing 14, no. 11: 2520. https://doi.org/10.3390/rs14112520
APA StyleLi, Z., Guo, J., Zhang, Y., Li, J., & Wu, Y. (2022). Reference-Based Multi-Level Features Fusion Deblurring Network for Optical Remote Sensing Images. Remote Sensing, 14(11), 2520. https://doi.org/10.3390/rs14112520