
SemiSANet: A Semi-Supervised High-Resolution Remote Sensing Image Change Detection Model Using Siamese Networks with Graph Attention


Abstract
:1. Introduction
- (1)
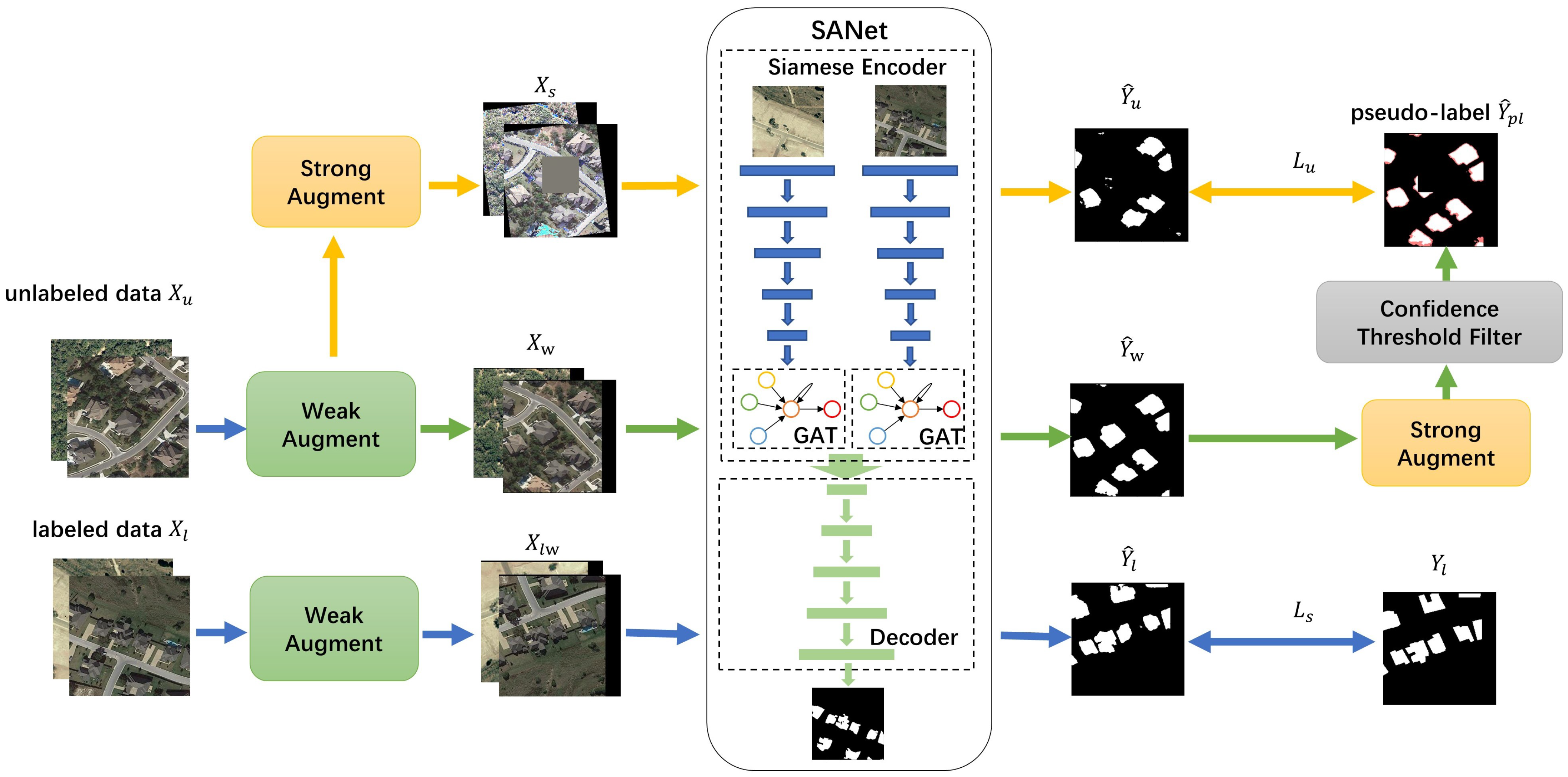
- A novel semi-supervised RS image change detection framework based on pseudo-label and consistency regularization is proposed. Firstly, labeled data is employed to train a network and with the help of a pixel-level threshold filter, high-confidence pseudo-labels for unlabeled RS images are generated. Then, by making the change detection results of distorted RS images consistent with the pseudo-label, the performance and robustness of our model are improved.
- (2)
- A novel RS image change detection network based on the Siamese Unet is proposed, and the addition of the graph attention mechanism gives the model the ability to extract long-range dependencies between latent features.
- (3)
- Extensive experimental results on two high-resolution remote sensing datasets demonstrate that our model can greatly improve change detection results in the case of an insufficient number of labels and outperform the state-of-the-art change detection methods. The optimal range of hyperparameter values for this semi-supervised CD method is given by extensive ablation experiments.
2. Related Work
2.1. DL Framework for CD
2.2. Attention Mechanism
2.3. Semi-Supervised Method Based on Consistency Regularization
3. Methods
3.1. Semi-Supervised Method Architecture
3.1.1. Data Augmentation in semiSANet
3.1.2. Confidence Threshold Filter
3.2. SANet
3.3. Loss Function
4. Experiments
4.1. Datasets
- The LEVIR dataset (https://justchenhao.github.io/LEVIR/, accessed on 3 May 2022) is a large-scale remote sensing building change detection dataset consisting of 637 Google Earth VHR images of size 1024 × 1024, each with a resolution of 0.5 m/pixel. The dual-temporal images of the LEVIR dataset come from 20 different areas in several cities in Texas, USA, and were taken from 2002 to 2018. The dataset focuses on land use changes, primarily in buildings, and covers various types of buildings such as cottage homes, high-rise apartments, small garages, and large warehouses. The images have many pseudo-changes caused by seasons and lighting, and the building-induced changes vary in shape and size, making it a very challenging dataset. Due to the limitation of GPU memory, we segment the image pairs into 256 × 256 pixels and then divide them randomly into a training set and a test set. The training set contains 7120 images while the test set contains 1024 images.
- The WHU dataset (https://study.rsgis.whu.edu.cn/pages/download/building_dataset.html, accessed on 3 May 2022) contains two remote sensing images and their change map taken in the same area of Christchurch, New Zealand in 2012 and 2016. Each image is 32,507 × 15,345 pixels in size with a resolution of 0.075 m/pixel, and the main change of interest is buildings. Due to GPU memory limitation, as with the LEVIR dataset, we segmented it by 256 × 256 pixels to obtain a training set with 2000 image pairs and a test set with 996 image pairs. The WHU dataset is a difficult dataset because of the large variation and extremely heterogeneous distribution of the change objects.
4.2. Evaluation Metrics
4.3. Experimental Setting
4.4. Baselines and Comparison
- FC-Conc [34] and FC-Diff [34]: FC-Conc and FC-Diff are the baseline methods for CD tasks, among which FC-Conc and FC-Diff are more effective, so they are cited as comparison methods in this paper. They are both based on the combination of UNet and Siamese networks. The difference is that in the deep feature fusion part, FC-Conc uses concatenation while FC-Diff uses difference.
- SNUNet-ECAM [37]: SNUNet-ECAM is a combination of Nested UNet and Siamese network with strong feature extraction and semantic information fusion capabilities. The ensemble channel attention mechanism (ECAM) is also incorporated, which enables the network to effectively fuse multi-level output information at the output side and achieve high accuracy in the CD task.
- s4GAN [49]: s4GAN is used for semi-supervised semantic segmentation. The semi-supervised approach is implemented using unsupervised data by setting the feature matching loss to minimize the difference between the predicted and true segmentation maps from semi-supervised data, while the self-training loss is used to balance the generator and discriminator to improve the model effectiveness.
- SemiCDNet [20]: SemiCDNet is a semi-supervised CD method using generative adversarial networks. The semi-supervised CD accuracy is improved by using two discriminators to enhance the consistency of the feature distribution of the segmentation and entropy graphs between labeled and unlabeled data thus improving the generalization ability of the generator by using a large amount of unlabeled data.
4.4.1. Prediction on LEVIR2000 Dataset
4.4.2. Prediction on WHU Dataset
4.5. Ablation Studies
4.5.1. Effect of the Semi-Supervised Method
4.5.2. Effect of Unsupervised Loss Weights
4.5.3. Effect of Confidence Threshold
4.5.4. Effect of Unlabeled Data Volume
4.5.5. Effect of the GAT Module
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change detection based on artificial intelligence: State-of-the-art and challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Willis, K.S. Remote sensing change detection for ecological monitoring in United States protected areas. Biol. Conserv. 2015, 182, 233–242. [Google Scholar] [CrossRef]
- Madasa, A.; Orimoloye, I.R.; Ololade, O.O. Application of geospatial indices for mapping land cover/use change detection in a mining area. J. Afr. Earth Sci. 2021, 175, 104108. [Google Scholar] [CrossRef]
- Huang, F.; Chen, L.; Yin, K.; Huang, J.; Gui, L. Object-oriented change detection and damage assessment using high-resolution remote sensing images, Tangjiao Landslide, Three Gorges Reservoir, China. Environ. Earth Sci. 2018, 77, 1–19. [Google Scholar] [CrossRef]
- Ji, S.; Shen, Y.; Lu, M.; Zhang, Y. Building instance change detection from large-scale aerial images using convolutional neural networks and simulated samples. Remote Sens. 2019, 11, 1343. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Cui, X.; Zhang, L. A post-classification change detection method based on iterative slow feature analysis and Bayesian soft fusion. Remote Sens. Environ. 2017, 199, 241–255. [Google Scholar] [CrossRef]
- Zhou, Z.H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef]
- Jiang, X.; Tang, H. Dense high-resolution Siamese network for weakly-supervised change detection. In Proceedings of the 2019 6th International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; pp. 547–552. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1635–1643. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Diaz-Pinto, A.; Colomer, A.; Naranjo, V.; Morales, S.; Xu, Y.; Frangi, A.F. Retinal image synthesis and semi-supervised learning for glaucoma assessment. IEEE Trans. Med Imaging 2019, 38, 2211–2218. [Google Scholar] [CrossRef]
- Zhao, G.; Peng, Y. Semisupervised SAR image change detection based on a siamese variational autoencoder. Inf. Process. Manag. 2022, 59, 102726. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, H.; Tao, S. Semi-Supervised Classification via Full-Graph Attention Neural Networks. Neurocomputing 2022, 476, 63–74. [Google Scholar] [CrossRef]
- Shaik, R.U.; Fusilli, L.; Giovanni, L. New approach of sample generation and classification for wildfire fuel mapping on hyperspectral (prisma) image. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 5417–5420. [Google Scholar]
- Shaik, R.U.; Laneve, G.; Fusilli, L. An Automatic Procedure for Forest Fire Fuel Mapping Using Hyperspectral (PRISMA) Imagery: A Semi-Supervised Classification Approach. Remote Sens. 2022, 14, 1264. [Google Scholar] [CrossRef]
- Zhao, Y.; Su, F.; Yan, F. Novel semi-supervised hyperspectral image classification based on a superpixel graph and discrete potential method. Remote Sens. 2020, 12, 1528. [Google Scholar] [CrossRef]
- Wang, J.; HQ Ding, C.; Chen, S.; He, C.; Luo, B. Semi-supervised remote sensing image semantic segmentation via consistency regularization and average update of pseudo-label. Remote Sens. 2020, 12, 3603. [Google Scholar] [CrossRef]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; Ding, H.; Huang, X. SemiCDNet: A semisupervised convolutional neural network for change detection in high resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5891–5906. [Google Scholar] [CrossRef]
- Dong, S.; Wang, P.; Abbas, K. A survey on deep learning and its applications. Comput. Sci. Rev. 2021, 40, 100379. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef]
- Michelsanti, D.; Tan, Z.H.; Zhang, S.X.; Xu, Y.; Yu, M.; Yu, D.; Jensen, J. An overview of deep-learning-based audio-visual speech enhancement and separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1368–1396. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning–based text classification: A comprehensive review. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Xu, Y.; Li, J.; Du, C.; Chen, H. NBR-Net: A Non-rigid Bi-directional Registration Network for Multi-temporal Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5620715. [Google Scholar] [CrossRef]
- Toriya, H.; Owada, N.; Saadat, M.; Inagaki, F.; Dewan, A.; Kawamura, Y.; Kitahara, I. Mutual superimposing of SAR and ground-level shooting images mediated by intermediate multi-altitude images. Array 2021, 12, 100102. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, H.; Du, C.; Li, J. MSACon: Mining Spatial Attention-Based Contextual Information for Road Extraction. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5604317. [Google Scholar] [CrossRef]
- Song, J.; Li, J.; Chen, H.; Wu, J. MapGen-GAN: A Fast Translator for Remote Sensing Image to Map Via Unsupervised Adversarial Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2341–2357. [Google Scholar] [CrossRef]
- Song, J.; Li, J.; Chen, H.; Wu, J. RSMT: A Remote Sensing Image-to-Map Translation Model via Adversarial Deep Transfer Learning. Remote Sens. 2022, 14, 919. [Google Scholar] [CrossRef]
- Zi, W.; Xiong, W.; Chen, H.; Li, J.; Jing, N. SGA-Net: Self-Constructing Graph Attention Neural Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2021, 13, 4201. [Google Scholar] [CrossRef]
- Khelifi, L.; Mignotte, M. Deep learning for change detection in remote sensing images: Comprehensive review and meta-analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Alexakis, E.B.; Armenakis, C. Evaluation of unet and unet++ architectures in high resolution image change detection applications. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 1507–1514. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Shao, R.; Du, C.; Chen, H.; Li, J. SUNet: Change Detection for Heterogeneous Remote Sensing Images from Satellite and UAV Using a Dual-Channel Fully Convolution Network. Remote Sens. 2021, 13, 3750. [Google Scholar] [CrossRef]
- Peng, D.; Zhang, Y.; Guan, H. End-to-end change detection for high resolution satellite images using improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A densely connected siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8007805. [Google Scholar] [CrossRef]
- Treisman, A.M.; Gelade, G. A feature-integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Liu, Q.; Kampffmeyer, M.; Jenssen, R.; Salberg, A.B. Scg-net: Self-constructing graph neural networks for semantic segmentation. arXiv 2020, arXiv:2009.01599. [Google Scholar]
- Laine, S.; Aila, T. Temporal ensembling for semi-supervised learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. arXiv 2017, arXiv:1703.01780. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. Mixmatch: A holistic approach to semi-supervised learning. arXiv 2019, arXiv:1905.02249. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. Adv. Neural Inf. Process. Syst. 2020, 33, 6256–6268. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- Mittal, S.; Tatarchenko, M.; Brox, T. Semi-supervised semantic segmentation with high-and low-level consistency. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1369–1379. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Augmentation | Degree | Description |
|---|---|---|
| Brightness | [0.05, 0.95] | Control the brightness of an image |
| Color | [0.05, 0.95] | Adjust the color balance of an image |
| Contrast | [0.05, 0.95] | Control the contrast of an image |
| Equalize | / | Equalize the image histogram |
| Identity | / | Return the original image |
| Posterize | [4, 8] | Reduce the number of bits for each color channel |
| Rotate | [−30, 30] | Rotate the image |
| Sharpness | [0.05, 0.95] | Adjust the sharpness of an image |
| ShearX | [−0.3, 0.3] | Shears the image along the horizontal axis |
| ShearY | [−0.3, 0.3] | Shears the image along the vertical axis |
| Solarize | [0, 256] | Invert all pixel values above a threshold |
| TranslateX | [−0.3, 0.3] | Translates the image horizontally |
| TranslateY | [−0.3, 0.3] | Translates the image vertically |
| Cutout | [0.25, 0.35] | Cutout an area of an image |
| Method | Labeled Ratio | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2.5% | 5% | 10% | 20% | |||||||||||||
| F1 | OA | Kappa | IoU | F1 | OA | Kappa | IoU | F1 | OA | Kappa | IoU | F1 | OA | Kappa | IoU | |
| Fc-Diff | 0.2801 | 0.9416 | 0.2497 | 0.1629 | 0.2846 | 0.9570 | 0.2660 | 0.1659 | 0.3553 | 0.9536 | 0.3319 | 0.2160 | 0.6261 | 0.9728 | 0.6123 | 0.4557 |
| Fc-Conc | 0.4702 | 0.9592 | 0.4491 | 0.3074 | 0.5092 | 0.9632 | 0.4903 | 0.3415 | 0.6437 | 0.9725 | 0.6295 | 0.4746 | 0.7472 | 0.9807 | 0.7373 | 0.5964 |
| SNUNet-ECAM | 0.5398 | 0.9679 | 0.5238 | 0.3696 | 0.5787 | 0.9694 | 0.5632 | 0.4072 | 0.7410 | 0.9725 | 0.7306 | 0.5886 | 0.8010 | 0.9843 | 0.7929 | 0.6681 |
| s4GAN | 0.4430 | 0.9657 | 0.4277 | 0.2845 | 0.5654 | 0.9716 | 0.5520 | 0.3941 | 0.7728 | 0.9823 | 0.7784 | 0.6490 | 0.8076 | 0.9846 | 0.7995 | 0.6772 |
| semiCDNet | 0.5409 | 0.9657 | 0.5234 | 0.3707 | 0.6451 | 0.9736 | 0.6317 | 0.4762 | 0.7947 | 0.9840 | 0.7864 | 0.6593 | 0.8181 | 0.9852 | 0.8104 | 0.6922 |
| semiSANet | 0.7875 | 0.9835 | 0.7790 | 0.6494 | 0.8095 | 0.9852 | 0.8019 | 0.6800 | 0.8532 | 0.9881 | 0.8470 | 0.7440 | 0.8699 | 0.9895 | 0.8644 | 0.7698 |
| Method | Labeled Ratio | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2.5% | 5% | 10% | 20% | |||||||||||||
| F1 | OA | Kappa | IoU | F1 | OA | Kappa | IoU | F1 | OA | Kappa | IoU | F1 | OA | Kappa | IoU | |
| Fc-Diff | 0.4667 | 0.9177 | 0.4250 | 0.3044 | 0.4117 | 0.9122 | 0.3684 | 0.2592 | 0.4462 | 0.8250 | 0.3609 | 0.2872 | 0.4654 | 0.8322 | 0.3833 | 0.3032 |
| Fc-Conc | 0.3713 | 0.8089 | 0.2764 | 0.2280 | 0.4932 | 0.8678 | 0.4233 | 0.3273 | 0.3702 | 0.7248 | 0.2594 | 0.2272 | 0.3969 | 0.7324 | 0.2902 | 0.2476 |
| SNUNet-ECAM | 0.5407 | 0.8809 | 0.4776 | 0.3705 | 0.5175 | 0.8476 | 0.4432 | 0.3491 | 0.5830 | 0.9118 | 0.5342 | 0.4115 | 0.4467 | 0.7960 | 0.3552 | 0.2875 |
| s4GAN | 0.4624 | 0.8172 | 0.3766 | 0.3007 | 0.4484 | 0.8022 | 0.3583 | 0.2890 | 0.4405 | 0.7842 | 0.3463 | 0.2824 | 0.4251 | 0.7894 | 0.3303 | 0.2699 |
| semiCDNet | 0.5401 | 0.8837 | 0.4780 | 0.3699 | 0.5864 | 0.8934 | 0.5279 | 0.4130 | 0.6247 | 0.9252 | 0.5833 | 0.4543 | 0.6025 | 0.9266 | 0.5622 | 0.4312 |
| semiSANet | 0.7808 | 0.9579 | 0.7576 | 0.6405 | 0.7944 | 0.9611 | 0.7729 | 0.6589 | 0.8353 | 0.9693 | 0.8184 | 0.7172 | 0.8786 | 0.9778 | 0.8664 | 0.7834 |
| Method | Labeled Ratio | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2.5% | 5% | 10% | 20% | |||||||||||||
| F1 | OA | Kappa | IoU | F1 | OA | Kappa | IoU | F1 | OA | Kappa | IoU | F1 | OA | Kappa | IoU | |
| SANet | 0.5399 | 0.9682 | 0.5243 | 0.3698 | 0.6548 | 0.9745 | 0.6419 | 0.4868 | 0.7872 | 0.9831 | 0.7784 | 0.6490 | 0.8139 | 0.9848 | 0.8060 | 0.6862 |
| semi-SANet | 0.7875 | 0.9835 | 0.7790 | 0.6494 | 0.8095 | 0.9852 | 0.8019 | 0.6800 | 0.8532 | 0.9881 | 0.8470 | 0.7440 | 0.8699 | 0.9895 | 0.8644 | 0.7698 |
| Method | Labeled Ratio | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2.5% | 5% | 10% | 20% | |||||||||||||
| F1 | OA | Kappa | IoU | F1 | OA | Kappa | IoU | F1 | OA | Kappa | IoU | F1 | OA | Kappa | IoU | |
| SANet | 0.5651 | 0.8846 | 0.5044 | 0.3938 | 0.4644 | 0.8313 | 0.3820 | 0.3024 | 0.5693 | 0.8798 | 0.5073 | 0.3979 | 0.5151 | 0.8682 | 0.4464 | 0.3469 |
| semi-SANet | 0.7808 | 0.9579 | 0.7576 | 0.6405 | 0.7944 | 0.9611 | 0.7729 | 0.6589 | 0.8353 | 0.9693 | 0.8184 | 0.7172 | 0.8786 | 0.9778 | 0.8664 | 0.7834 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, C.; Wu, J.; Chen, H.; Du, C. SemiSANet: A Semi-Supervised High-Resolution Remote Sensing Image Change Detection Model Using Siamese Networks with Graph Attention. Remote Sens. 2022, 14, 2801. https://doi.org/10.3390/rs14122801
Sun C, Wu J, Chen H, Du C. SemiSANet: A Semi-Supervised High-Resolution Remote Sensing Image Change Detection Model Using Siamese Networks with Graph Attention. Remote Sensing. 2022; 14(12):2801. https://doi.org/10.3390/rs14122801
Chicago/Turabian StyleSun, Chengzhe, Jiangjiang Wu, Hao Chen, and Chun Du. 2022. "SemiSANet: A Semi-Supervised High-Resolution Remote Sensing Image Change Detection Model Using Siamese Networks with Graph Attention" Remote Sensing 14, no. 12: 2801. https://doi.org/10.3390/rs14122801
APA StyleSun, C., Wu, J., Chen, H., & Du, C. (2022). SemiSANet: A Semi-Supervised High-Resolution Remote Sensing Image Change Detection Model Using Siamese Networks with Graph Attention. Remote Sensing, 14(12), 2801. https://doi.org/10.3390/rs14122801