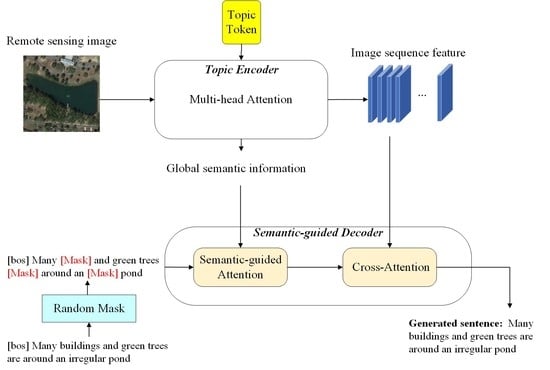
3.1. Topic Encoder
Faster-R-CNN has been widely used as a feature encoder in natural image captioning, but the extracted features from Transformer have been rarely explored. Further, the features obtained from Faster-R-CNN do not fit remote sensing images well, and we believe that the multi-head attention in Transformer may be a better fit with the characteristics of remote sensing images, as it can explore the relationships among different image regions. Based on this, we explore the use of Transformer to build the feature encoder for our remote sensing image captioning model.
Consider an input image of size . As the Transformer model takes the sequence as input, it is necessary to convert each image into a sequence composed of patches, where s is the size of the single patch. Note that s was set as 16 in our experiments. Then, the patches are input to the embedding layer in order to map the features to the same space as the word embedding.
For remote sensing image captioning, the captured global semantic information is crucial, as it is used to represent the complex relationships among objects and the whole scene. In
Figure 3, we show some images which illustrate the importance of global semantic information. In the figure, some different high-level semantic words (also called topics), such as the “industrial area”, the “commercial area”, and the “residential area”, have corresponding images which are all composed of many buildings with similar local characteristics, but different in the arrangement of buildings and the surrounding scene. Therefore, it is observed that the topics expressing global semantic information can be obtained from the large-scale scene, but not the local patch features.
To extract the global semantic information, we propose a topic token module (
). It is similar to [Class] token in Bert [
42] (Bidirectional encoder representations from Transformers) and Vit (Vision Transformer) [
43], the difference being that
is not only used for classification, but also guides word generation in the decoding stage. Compared with the mean pooling operation on image features [
6,
27] or the classification result of the softmax layer [
31],
is a trainable parameter and the self-attention calculates its attention value with each image path feature. Thus, its output
can better express global semantic information.
After adding the topic token in image patch features, it is necessary to add position encoding to represent the sequence order. Thus, the input of the encoder can be written as:
where
T is the topic token,
is the
image patch,
N is the number of image patches,
is the last image patch, and
is the position coding.
The structure of the topic encoder is shown in
Figure 4. The main part of the topic encoder is the multi-head attention layer, where the operation in this layer is calculated as:
where
denotes the multi-head attention;
H is the number of attention heads;
is the
ith attention head;
W is the weight vector in the multi-head attention;
are the query, key, and value vectors, respectively;
are trainable parameters; and
d is the scale factor.
In the final encoder, the output is separated into two parts, which can be expressed as:
where
is the first element in
and represents the topic feature, while
is the rest of
and represents the image feature,
N is the number of image patches, and
is the output of topic encoder.
As topics are based on the large-scale scene and the whole caption, it is difficult to directly train the topic token with image captioning data sets. Hence, in order to train the whole network faster and better, a remote sensing topic classification task is used to pre-train the encoder and the topic token. The first part involves setting topic labels, where annotators provide a class name set for the whole data set for further usage. In this sense, RSICD [
27] provides 30 category names, UCM [
6] provides 21 names, and Sydney [
6] provides 7 names (e.g., airport, parking lot, dense residential area). In the RSICD data set, there is a category name corresponding to each image, which we directly set as the topic label. For the UCM and Sydney data sets, we use the following strategy to find the topic label corresponding to the image: if a class name appears in more than three captions of an image, it is set as the topic label of the image. An example of this strategy is shown in
Figure 5. In this way, a remote sensing topic classification data set was built. In the pre-training classification task, to ensure that the topic token can extract the global semantic information, only the output feature of the topic token is used as input to the classification layer. Then, the pre-trained weights are used to initialize the encoder and topic token.
After pre-training the topic encoder, considering the modality gap between the image and the sentence, it is necessary to fine-tune the encoder for the image captioning task. However, we find that the accuracy is decreased if the encoder and decoder are fine tuned together. To solve this issue, we add an extra MLP (Multilayer Perceptron) layer [
44] after the encoder, freeze the encoder, and only train the extra MLP while fine-tuning. The extra MLP is a kind of embedding layer, which maps the image features to a deeper space so it can explore potential semantic associations between images and sentences.
To better extract image features, we utilize the multi-head attention in Transformer, which fits the characteristic of large-scale and numerous objects in remote sensing images. We also propose a topic token to extract the global semantic information, which is a trainable and independent vector and can interact with each image path feature.
3.2. Semantic-Guided Decoder
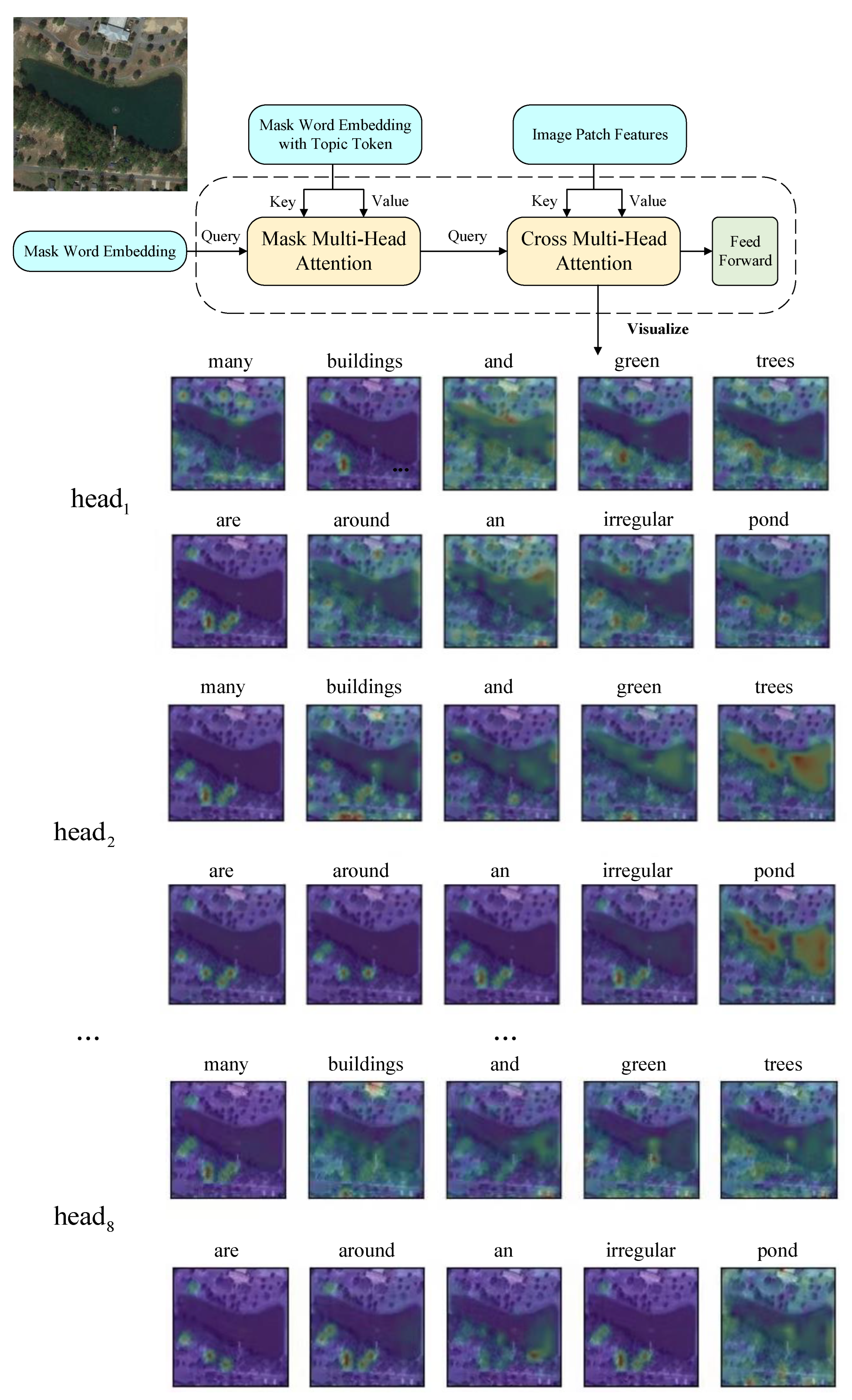
The semantic-guided decoder is mainly composed of two multi-head attention blocks.
Section 3.1 showed that using only local patch features cannot represent the global semantic information in remote sensing images. To generate better captions, we designed the semantic-guided attention and cross-attention modules. The two parts of the output in the encoder (in Equation (
3)) are used in the two attention modules, respectively. The semantic-guided decoder generates the next word token, based on the two parts above and the pre-predicted words.
In the semantic-guided attention module, as the new words should only rely on the previously predicted words, the mask attention is applied; that is, the attention weights of the words not generated should be quite small, and the new words are not influenced by them.
The difference of the semantic-guided attention module, compared to the conventional mask self-attention module, is that we add the topic semantic features
in the key and value vectors. While using the Vit features as the backbone feature extractors to carry out downstream tasks, the two parts in Equation (
3) are not separated, as we mainly use the image features. However, in remote sensing image captioning, the global semantic information is also necessary. Based on this, considering that the number of topic features is only 1 and there are
N local patch features, the important topic features will be hard to notice if not separated from patch features. Additionally, the topic features are high-level semantic word-embedding vectors, containing the information in word space, so we incorporate the topic features into the mask multi-head attention module.
Specifically,
is concatenated with the word embedding vector to form the key and value vector. When each word embedding vector performs the mask attention operation, the extra
will not be influenced and will be noticed at each time step, which is helpful in generating words specific to the global semantic information. After adding
, the new semantic-guided attention block can be expressed as
where
X represents the output of the previous decoder (corresponding to the sentence word-embedding in the first decoder layer) and
denotes the concatenate operation. Compare with the conventional self-attention block (whose
have the same value and are all equal to
X), extra global semantic information is added in Equation (
4).
is taken as prior knowledge and is a high-level semantic word-embedding vector based on the large scene. On this basis, the sequence can be used to obtain the global semantic information early and correctly, rather than mining in the later large-scale image patch features. For example, in two similar scenes, such as the ‘dense residential area’ and ‘commercial area’ shown in
Figure 3, where there are many buildings in the two images, the topic token can help to generate some high-semantic-level words, such as ‘dense residential’ and ‘commercial.’ In the model without the topic token, the model needs to excavate the inner information, and the final result may not be accurate.
The second multi-head attention layer is a cross-modal attention between words and the image features. It aims to generate the corresponding description according to a given image feature. The cross-modal attention is expressed as
where
X represents the output of the semantic-guided attention block and
is the image feature. The output is used as the input to the next decoder. In the final decoder, the caption is obtained using a fully connected layer and a soft-max layer.
To guide the decoder generates high-level semantic words, we modify the conventional self-attention by using the topic feature. In the proposed semantic-guided decoder, the global semantic information from topic token can be utilized and guide the word generation.
3.3. Mask–Cross-Entropy Training Strategy
For remote sensing image captioning, dense and multiple objects are hard to express using a common sentence pattern. Furthermore, as the description is simpler than that for natural images, when the model generates sentences with limited diversity, the lack of diversity among sentences will be more obvious. Therefore, improving the diversity of captioning is urgent, but has been rarely explored in the past. We address this problem in this section.
Masking is an effective learning strategy which has already been used in MAE [
45] (Masked autoencoders) and BEIT [
46] (bidirectional encoder representation from image Transformers) to enhance the model learning ability and to explore the relationships among objects. Inspired by this, to suppress the
exposure bias [
20] in CE, we propose a Mask–Cross-Entropy (Mask-CE) training strategy. The main idea of Mask-CE is randomly masking some words in the ground truth. Specifically, in each iteration, we randomly replace some words in the sequence with [Mask] before the word-embedding layer, where the [Mask] is another word token, similar to [bos] (beginning of a sequence). The loss function of Mask-CE is written as:
where the
y denotes the ground-truth words,
is the model parameter, and
is the mask sentence, T is the length of ground-truth sentence. For each predicted time step, the probability
of the next word
is obtained according to the given previous mask-sentence words.
The difference of Mask-CE from the Mask strategies used in MAE and BEIT is that the [Mask] token only affects the words behind it but not itself while predicting words, and the model needs to predict all words, not only words with the [Mask] token. In comparison, in MAE and BEIT, the model mainly reconstructs the masked patches, and the normal patches will not be affected.
Moreover, different from the exposure bias problem in CE, in the training stage of Mask-CE, some ground-truth words are unknown; thus, the model needs to predict the word based on some noisy words ([Mask]) and fewer ground-truth words. In the actual prediction, the model can also only rely on its own prediction, which may not be the ground truth. Therefore, the training environment of Mask-CE is closer to the actual prediction, such that the exposure bias can be suppressed.
The key point of the [Mask] operation is to explore the word relations, and it can be observed that the predicted word often relies on some keywords. If keywords are replaced with [Mask], Mask-CE will enforce the model to predict the word from other words, whose relation may not yet be explored, but which is useful. As the position of [Mask] is random, with an increasing number of iterations, the [Mask] token will cover every word in the sentence, which means that the relationships between words are better explored. In short, Mask-CE can overcome the exposure bias in CE and combines some of the core context of SC, and so it can ensure that the model generates captions with high accuracy and diversity.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}