
Mapping the Spatial Distribution of Fern Thickets and Vine-Laden Forests in the Landscape of Bornean Logged-Over Tropical Secondary Rainforests

 ,
,
Abstract
:
1. Introduction
2. Materials and Methods
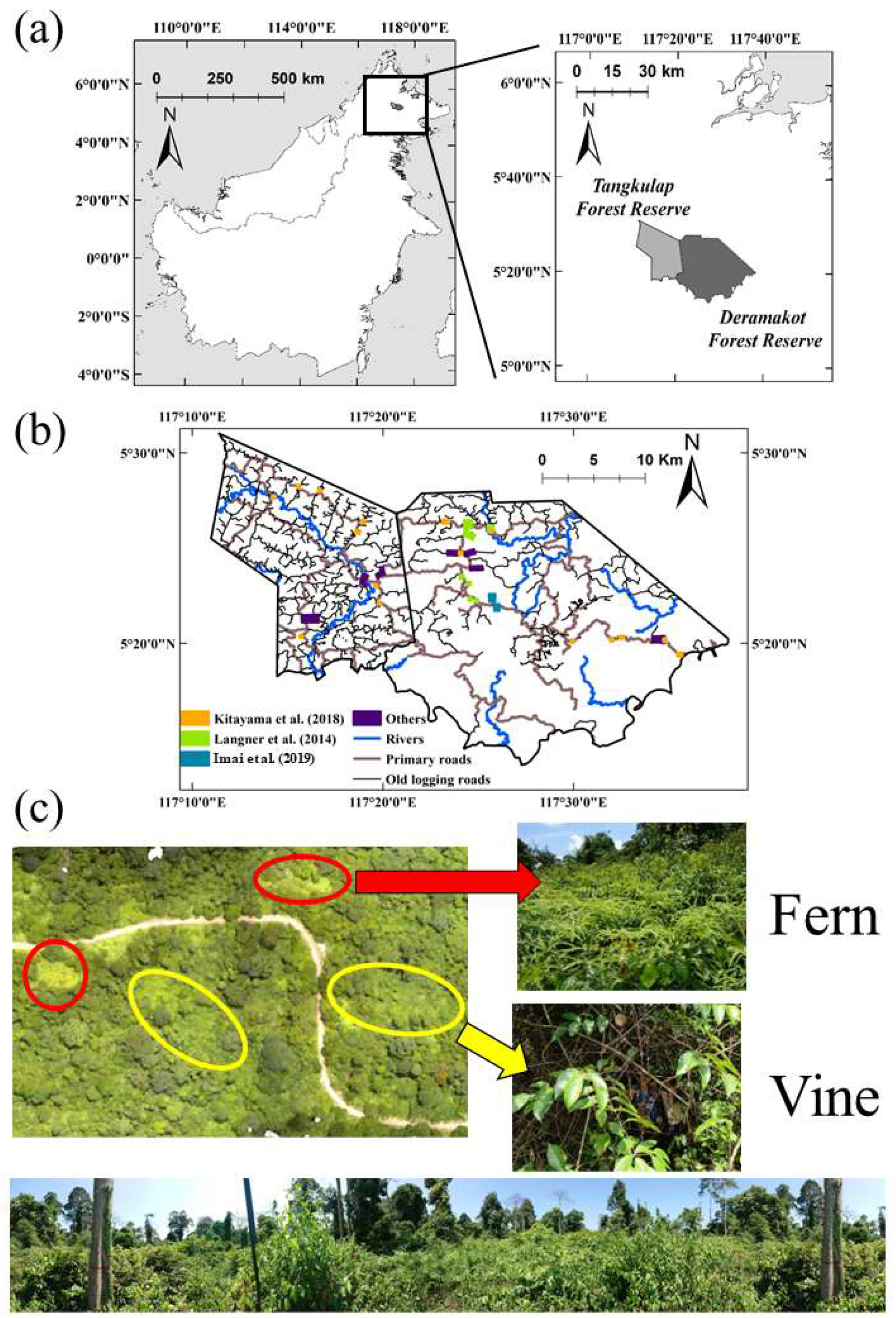
2.1. Study Site
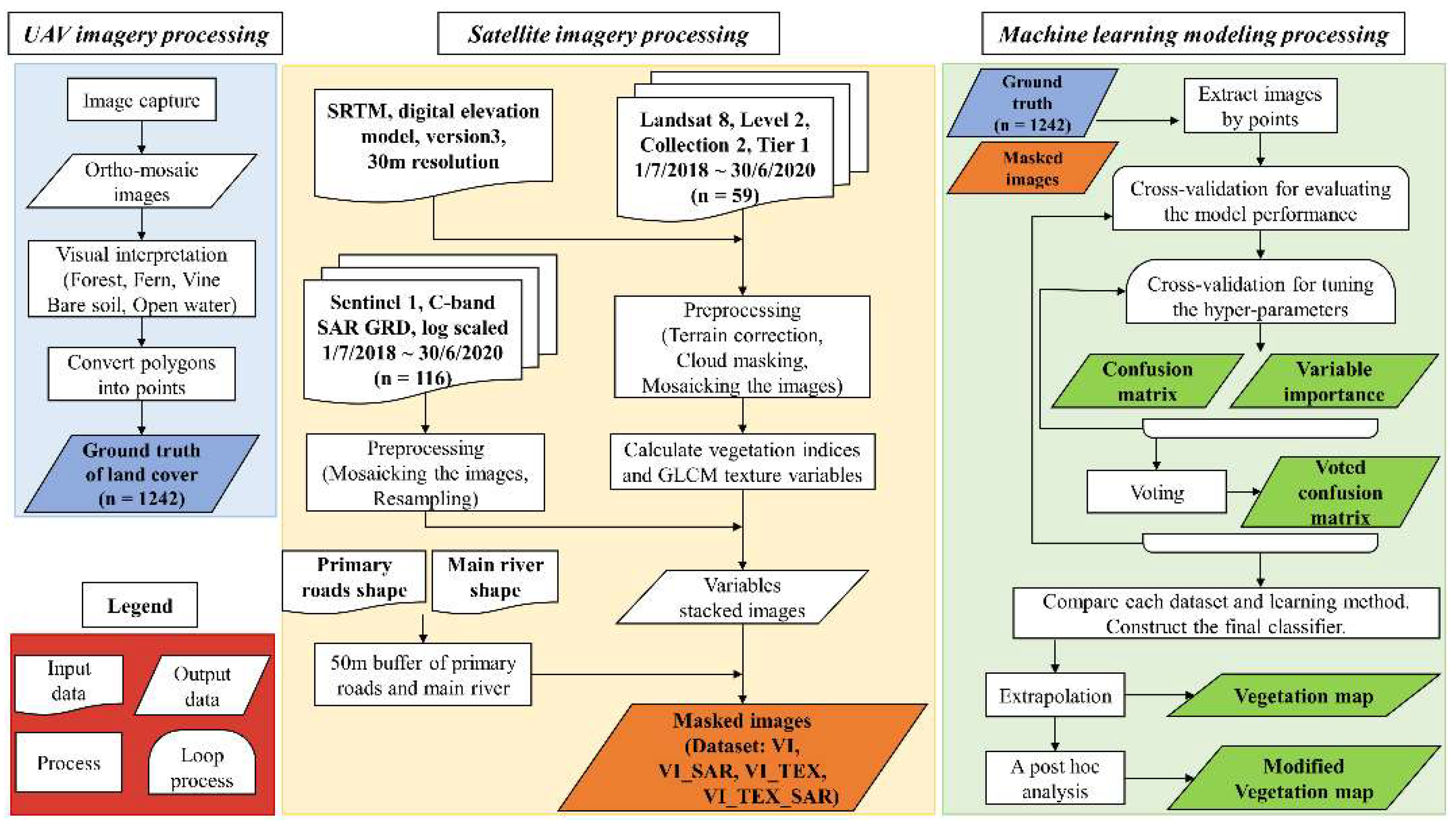
2.2. Mapping Procedure
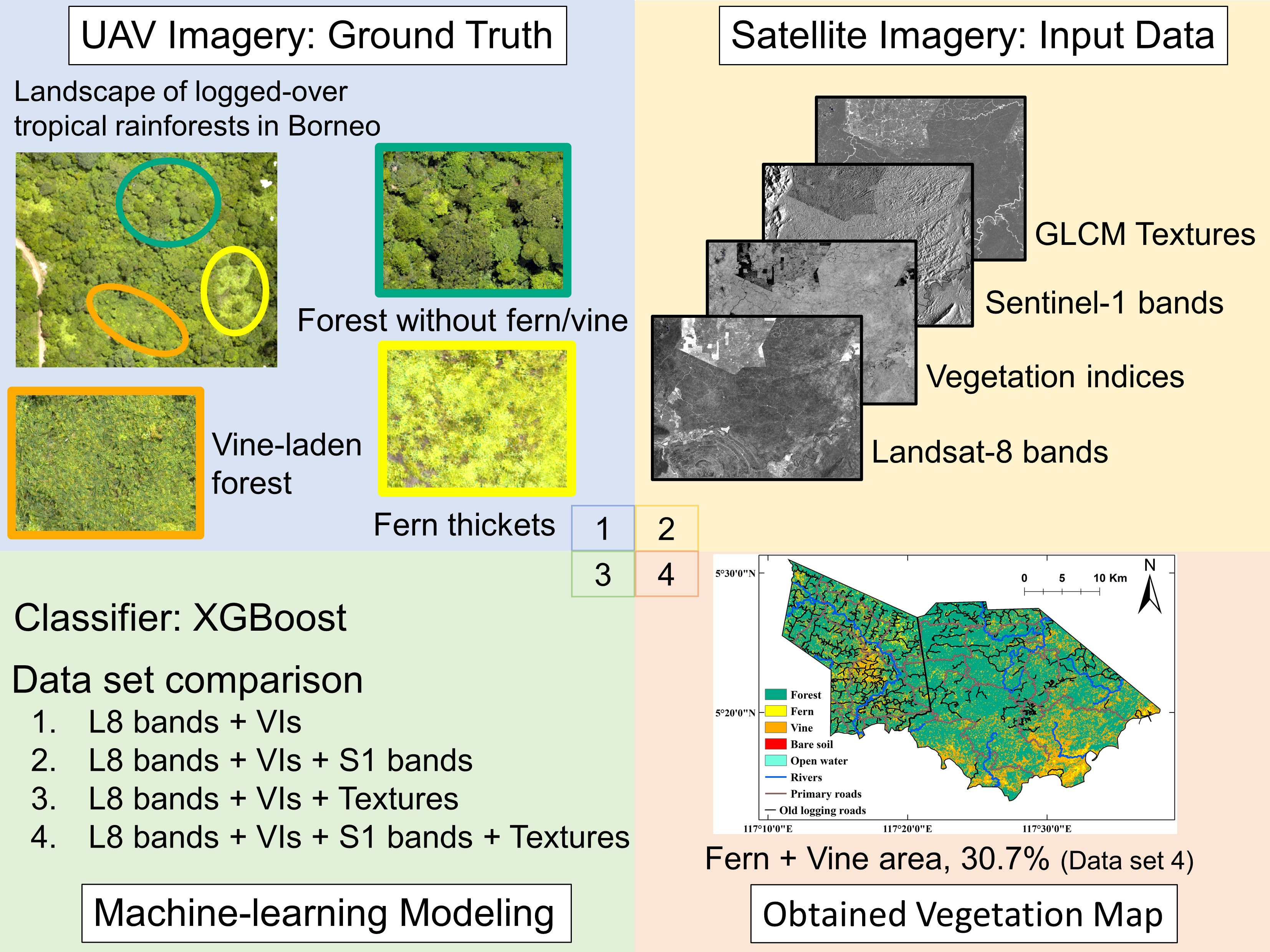
2.2.1. UAV Imagery Processing
2.2.2. Satellite Imagery Processing
2.2.3. Machine Learning Processing
Model Training and Evaluation Process
Comparison of the Data Set, Learning Method, and Creation of Vegetation Maps
3. Results
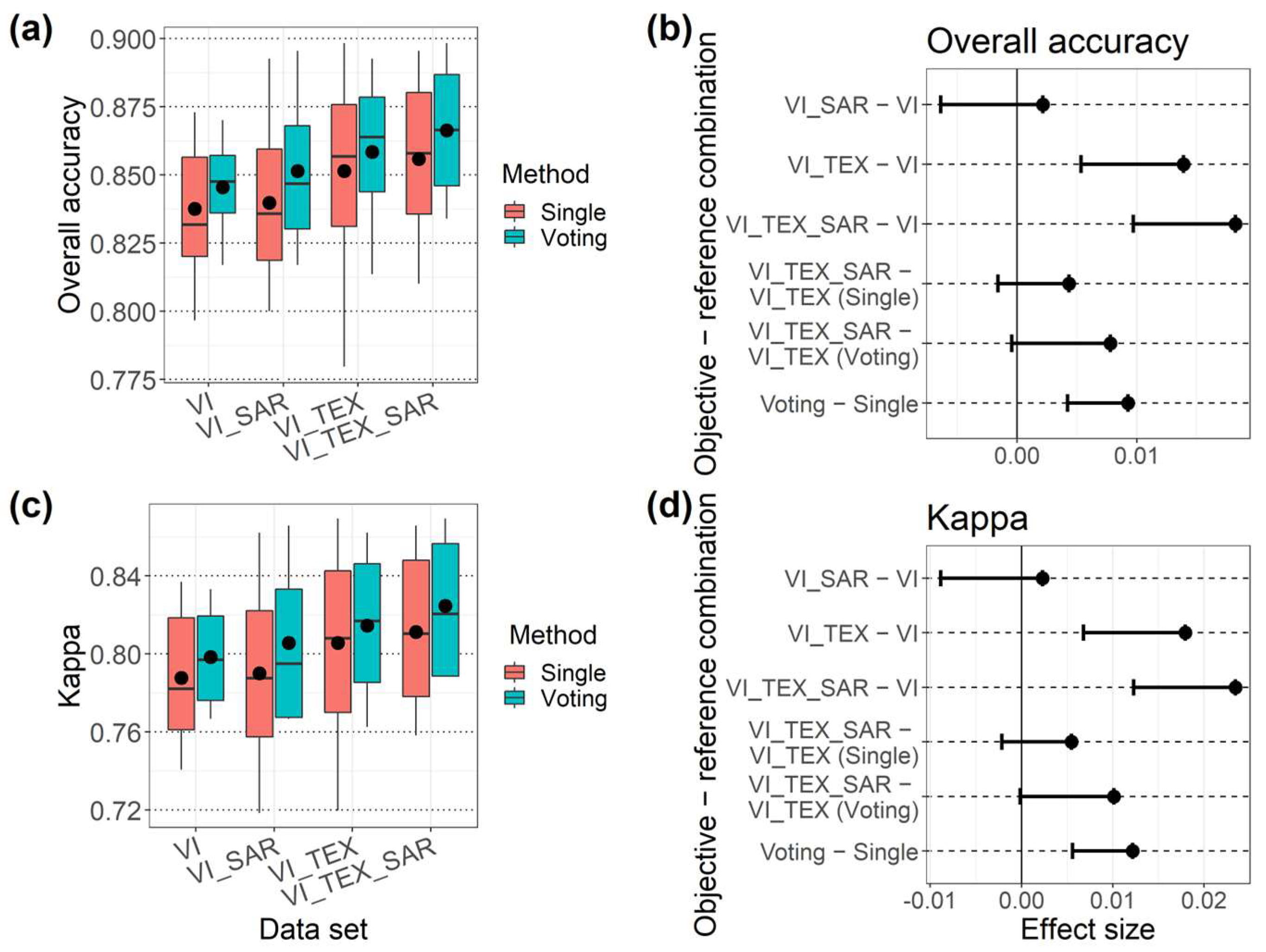
3.1. The Overall Classification Performance of Each Data Set and Learning Method
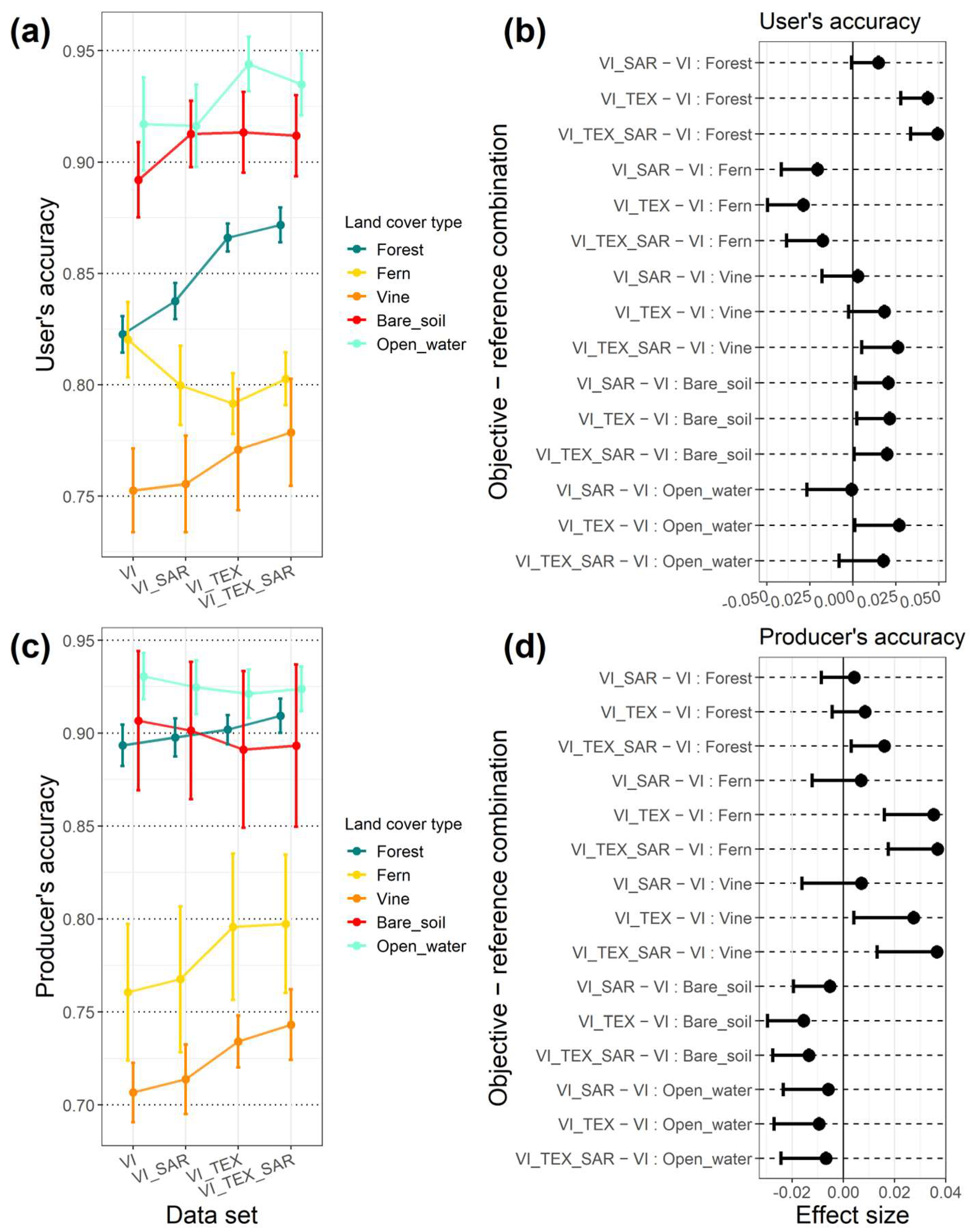
3.2. The Classification Performance for Each Vegetation Type
3.3. Feature Importance of the Classification Model
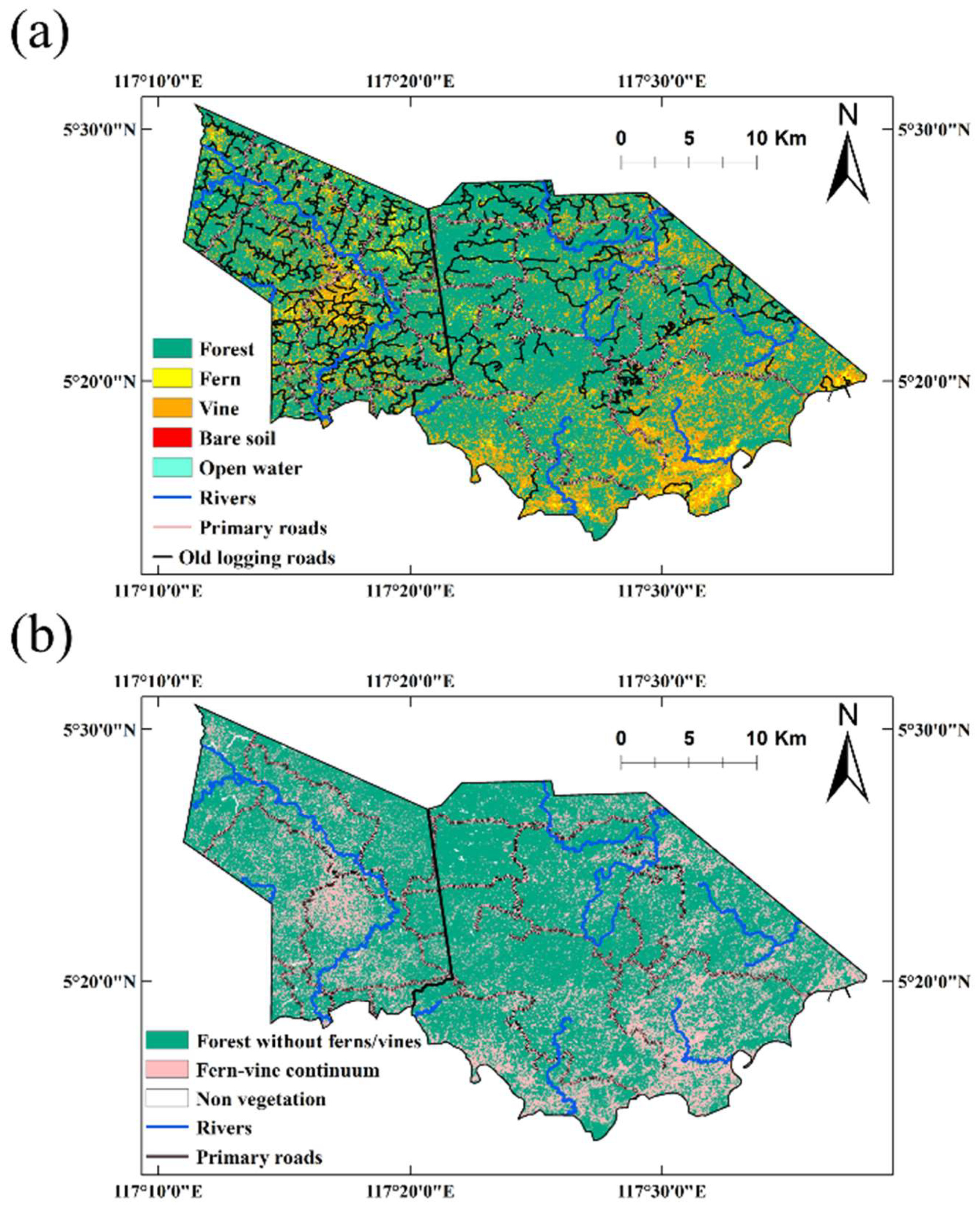
3.4. The Vegetation Maps
4. Discussion
4.1. Redefining Forest Degradation Mapping
4.2. The Important Variables for Detecting the Fern–Vine Continuum in a Landscape of Logged-Over Forest
4.3. Future Prospects and Implications for Forest Management
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pan, Y.; Birdsey, R.A.; Fang, J.; Houghton, R.; Kauppi, P.E.; Kurz, W.A.; Phillips, O.L.; Shvidenko, A.; Lewis, S.L.; Canadell, J.G.; et al. A Large and Persistent Carbon Sink in the World’s Forests. Science 2011, 333, 988–993. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.Y.; van Dijk, A.I.J.M.; de Jeu, R.A.M.; Canadell, J.G.; McCabe, M.F.; Evans, J.P.; Wang, G. Recent Reversal in Loss of Global Terrestrial Biomass. Nat. Clim. Chang. 2015, 5, 470–474. [Google Scholar] [CrossRef]
- Lewis, S.L.; Edwards, D.P.; Galbraith, D. Increasing Human Dominance of Tropical Forests. Science 2015, 349, 827–832. [Google Scholar] [CrossRef]
- Penman, J.; Gytarsky, M.; Hiraishi, T.; Krug, T.; Kruger, D.; Pipatti, R.; Buendia, L.; Miwa, K.; Ngara, T.; Tanabe, K.; et al. Definitions and Methodological Options to Inventory Emissions from Direct Human-Induced Degradation of Forests and Devegetation of Other Vegetation Types; IPCC National Greenhouse Gas Inventories Programme: Hayama, Japan, 2003; ISBN 4-88788-004-9. [Google Scholar]
- Jakovac, C.C.; Peña-Claros, M.; Kuyper, T.W.; Bongers, F. Loss of Secondary-forest Resilience by Land-use Intensification in the Amazon. J. Ecol. 2015, 103, 67–77. [Google Scholar] [CrossRef]
- Becknell, J.M.; Powers, J.S. Stand Age and Soils as Drivers of Plant Functional Traits and Aboveground Biomass in Secondary Tropical Dry Forest. Can. J. For. Res. 2014, 44, 604–613. [Google Scholar] [CrossRef]
- Flores, B.M.; Holmgren, M. Why Forest Fails to Recover after Repeated Wildfires in Amazonian Floodplains? Experimental Evidence on Tree Recruitment Limitation. J. Ecol. 2021, 109, 3473–3486. [Google Scholar] [CrossRef]
- Poorter, L.; Bongers, F.; Aide, T.M.; Zambrano, A.M.A.; Balvanera, P.; Becknell, J.M.; Boukili, V.; Brancalion, P.H.S.; Broadbent, E.N.; Chazdon, R.L.; et al. Biomass Resilience of Neotropical Secondary Forests. Nature 2016, 530, 211–214. [Google Scholar] [CrossRef]
- Tymen, B.; Réjou-Méchain, M.; Dalling, J.W.; Fauset, S.; Feldpausch, T.R.; Norden, N.; Phillips, O.L.; Turner, B.L.; Viers, J.; Chave, J. Evidence for Arrested Succession in a Liana-infested Amazonian Forest. J. Ecol. 2016, 104, 149–159. [Google Scholar] [CrossRef]
- Goldsmith, G.R.; Comita, L.S.; Chua, S.C. Evidence for Arrested Succession within a Tropical Forest Fragment in Singapore. J. Trop. Ecol. 2011, 27, 323–326. [Google Scholar] [CrossRef]
- Flores, B.M.; Fagoaga, R.; Nelson, B.W.; Holmgren, M. Repeated Fires Trap Amazonian Blackwater Floodplains in an Open Vegetation State. J. Appl. Ecol. 2016, 53, 1597–1603. [Google Scholar] [CrossRef]
- Cohen, A.L.; Singhakumara, B.M.P.; Ashton, P.M.S. Releasing Rain Forest Succession: A Case Study in the Dicranopteris Linearis Fernlands of Sri Lanka. Restor. Ecol. 1995, 3, 261–270. [Google Scholar] [CrossRef]
- Dupuis, C.; Lejeune, P.; Michez, A.; Fayolle, A. How Can Remote Sensing Help Monitor Tropical Moist Forest Degradation?—A Systematic Review. Remote Sens. 2020, 12, 1087. [Google Scholar] [CrossRef] [Green Version]
- Ong, R.; Langner, A.; Imai, N.; Kanehiro, K. Management History of the Study Sites: The Deramakot and Tangkulap Forest Reserves. In Co-Benefits of Sustainable Forestry: Ecological Studies of a Certified Bornean Rain Forest (Ecological Research Monographs); Ecological Research Monographs; Kitayama, K., Ed.; Springer: Tokyo, Japan, 2013; ISBN 978-4-431-54141-7. [Google Scholar]
- Yap, S.W.; Chak, C.V.; Majuakim, L.; Anuar, M.; Putz, F.E. Climbing Bamboo (Dinochloa Spp.) in Deramakot Forest Reserve, Sabah: Biomechanical Characteristics, Modes of Ascent and Abundance in a Logged-over Forest. J. Trop. For. Sci. 1995, 8, 196–202. [Google Scholar]
- Ssali, F.; Moe, S.R.; Sheil, D. A First Look at the Impediments to Forest Recovery in Bracken-Dominated Clearings in the African Highlands. For. Ecol. Manag. 2017, 402, 166–176. [Google Scholar] [CrossRef]
- Chua, S.; Ramage, B.S.; Potts, M.D. Soil Degradation and Feedback Processes Affect Long Term Recovery of Tropical Secondary Forests. J. Veg. Sci. 2016, 27, 800–811. [Google Scholar] [CrossRef]
- Sawada, Y.; Imai, N.; Takeshige, R.; Kitayama, K. Relationships between Tree-Community Composition and Regeneration Potential of Shorea Trees in Logged-over Tropical Rain Forests. J. For. Res. 2022, 27, 222–229. [Google Scholar] [CrossRef]
- Foster, J.R.; Townsend, P.A.; Zganjar, C.E. Spatial and Temporal Patterns of Gap Dominance by Low-Canopy Lianas Detected Using EO-1 Hyperion and Landsat Thematic Mapper. Remote Sens. Environ. 2008, 112, 2104–2117. [Google Scholar] [CrossRef]
- Marvin, D.C.; Asner, G.P.; Schnitzer, S.A. Liana Canopy Cover Mapped throughout a Tropical Forest with High-Fidelity Imaging Spectroscopy. Remote Sens. Environ. 2016, 176, 98–106. [Google Scholar] [CrossRef] [Green Version]
- Chandler, C.J.; van der Heijden, G.M.F.; Boyd, D.S.; Cutler, M.E.J.; Costa, H.; Nilus, R.; Foody, G.M. Remote Sensing Liana Infestation in an Aseasonal Tropical Forest: Addressing Mismatch in Spatial Units of Analyses. Remote Sens. Ecol. Conserv. 2021, 7, 397–410. [Google Scholar] [CrossRef]
- Matongera, T.N.; Mutanga, O.; Dube, T.; Sibanda, M. Detection and Mapping the Spatial Distribution of Bracken Fern Weeds Using the Landsat 8 OLI New Generation Sensor. Int. J. Appl. Earth Obs. Geoinf. 2017, 57, 93–103. [Google Scholar] [CrossRef]
- Chandler, C.J.; van der Heijden, G.M.F.; Boyd, D.S.; Foody, G.M. Detection of Spatial and Temporal Patterns of Liana Infestation Using Satellite-Derived Imagery. Remote Sens. 2021, 13, 2774. [Google Scholar] [CrossRef]
- Heijden, G.M.F.; Proctor, A.D.C.; Calders, K.; Chandler, C.J.; Field, R.; Foody, G.M.; Moorthy, S.M.K.; Schnitzer, S.A.; Waite, C.E.; Boyd, D.S. Making (Remote) Sense of Lianas. J. Ecol. 2022, 110, 498–513. [Google Scholar] [CrossRef]
- Sánchez-Azofeifa, G.A.; Castro-Esau, K. Canopy Observations on the Hyperspectral Properties of a Community of Tropical Dry Forest Lianas and Their Host Trees. Int. J. Remote Sens. 2006, 27, 2101–2109. [Google Scholar] [CrossRef]
- Kalacska, M.; Bohlman, S.; Sanchez-Azofeifa, G.A.; Castro-Esau, K.; Caelli, T. Hyperspectral Discrimination of Tropical Dry Forest Lianas and Trees: Comparative Data Reduction Approaches at the Leaf and Canopy Levels. Remote Sens. Environ. 2007, 109, 406–415. [Google Scholar] [CrossRef]
- Asner, G.P.; Martin, R.E. Spectral and Chemical Analysis of Tropical Forests: Scaling from Leaf to Canopy Levels. Remote Sens. Environ. 2008, 112, 3958–3970. [Google Scholar] [CrossRef]
- Odindi, J.; Adam, E.; Ngubane, Z.; Mutanga, O.; Slotow, R. Comparison between WorldView-2 and SPOT-5 Images in Mapping the Bracken Fern Using the Random Forest Algorithm. J. Appl. Remote Sens. 2014, 8, 083527. [Google Scholar] [CrossRef]
- Schneider, L.C.; Fernando, D.N. An Untidy Cover: Invasion of Bracken Fern in the Shifting Cultivation Systems of Southern Yucatán, Mexico. Biotropica 2010, 42, 41–48. [Google Scholar] [CrossRef]
- Holland, J.; Aplin, P. Super-Resolution Image Analysis as a Means of Monitoring Bracken (Pteridium Aquilinum) Distributions. ISPRS J. Photogramm. Remote Sens. 2013, 75, 48–63. [Google Scholar] [CrossRef]
- Fernández, G.F.C.; Silva, B.; Gawlik, J.; Thies, B.; Bendix, J. Bracken Fern Frond Status Classification in the Andes of Southern Ecuador: Combining Multispectral Satellite Data and Field Spectroscopy. Int. J. Remote Sens. 2013, 34, 7020–7037. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Laurin, G.V.; Puletti, N.; Hawthorne, W.; Liesenberg, V.; Corona, P.; Papale, D.; Chen, Q.; Valentini, R. Discrimination of Tropical Forest Types, Dominant Species, and Mapping of Functional Guilds by Hyperspectral and Simulated Multispectral Sentinel-2 Data. Remote Sens. Environ. 2016, 176, 163–176. [Google Scholar] [CrossRef] [Green Version]
- Erinjery, J.J.; Singh, M.; Kent, R. Mapping and Assessment of Vegetation Types in the Tropical Rainforests of the Western Ghats Using Multispectral Sentinel-2 and SAR Sentinel-1 Satellite Imagery. Remote Sens. Environ. 2018, 216, 345–354. [Google Scholar] [CrossRef]
- Alban, J.D.T.D.; Connette, G.M.; Oswald, P.; Webb, E.L. Combined Landsat and L-Band SAR Data Improves Land Cover Classification and Change Detection in Dynamic Tropical Landscapes. Remote Sens. 2018, 10, 306. [Google Scholar] [CrossRef] [Green Version]
- Attarchi, S.; Gloaguen, R. Classifying Complex Mountainous Forests with L-Band SAR and Landsat Data Integration: A Comparison among Different Machine Learning Methods in the Hyrcanian Forest. Remote Sens. 2014, 6, 3624–3647. [Google Scholar] [CrossRef] [Green Version]
- Imai, N.; Seino, T.; Aiba, S.; Takyu, M.; Titin, J.; Kitayama, K. Effects of Selective Logging on Tree Species Diversity and Composition of Bornean Tropical Rain Forests at Different Spatial Scales. Plant Ecol. 2012, 213, 1413–1424. [Google Scholar] [CrossRef] [Green Version]
- Sabah-Forestry-Department. Forest Management Plan 2: Deramakot Forest Reserve, Forest Management Unit No. 19; Sabah-Forestry-Department: Sandakan, Malaysia, 2005. [Google Scholar]
- Lagan, P.; Mannan, S.; Matsubayashi, H. Sustainable Use of Tropical Forests by Reduced-Impact Logging in Deramakot Forest Reserve, Sabah, Malaysia. Ecol. Res. 2007, 22, 414–421. [Google Scholar] [CrossRef]
- Imai, N.; Samejima, H.; Langner, A.; Ong, R.C.; Kita, S.; Titin, J.; Chung, A.Y.C.; Lagan, P.; Lee, Y.F.; Kitayama, K. Co-Benefits of Sustainable Forest Management in Biodiversity Conservation and Carbon Sequestration. PLoS ONE 2009, 4, e8267. [Google Scholar] [CrossRef]
- Langner, A.; Titin, J.; Kitayama, K. The Application of Satellite Remote Sensing for Classifying Forest Degradation and Deriving Above-Ground Biomass Estimates. In Co-Benefits of Sustainable Forestry: Ecological Studies of a Certified Bornean Rain Forest (Ecological Research Monographs); Ecological Research Monographs; Kitayama, K., Ed.; Springer: Tokyo, Japan, 2013; ISBN 9784431541400. [Google Scholar]
- Aoyagi, R.; Imai, N.; Kitayama, K. Ecological Significance of the Patches Dominated by Pioneer Trees for the Regeneration of Dipterocarps in a Bornean Logged-over Secondary Forest. Forest Ecol. Manag. 2013, 289, 378–384. [Google Scholar] [CrossRef]
- Holttum, R.E.; van Steenis, C.G.G.J. Flora Malesiana. Series II, Pteridophyta: Ferns and Fern Allies; Noordhoff: Leyden, The Netherlands, 1959. [Google Scholar]
- Kitayama, K.; Fujiki, S.; Aoyagi, R.; Imai, N.; Sugau, J.; Titin, J.; Nilus, R.; Lagan, P.; Sawada, Y.; Ong, R.; et al. Biodiversity Observation for Land and Ecosystem Health (BOLEH): A Robust Method to Evaluate the Management Impacts on the Bundle of Carbon and Biodiversity Ecosystem Services in Tropical Production Forests. Sustainability 2018, 10, 4224. [Google Scholar] [CrossRef] [Green Version]
- Langner, A.; Samejima, H.; Ong, R.C.; Titin, J.; Kitayama, K. Integration of Carbon Conservation into Sustainable Forest Management Using High Resolution Satellite Imagery: A Case Study in Sabah, Malaysian Borneo. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 305–312. [Google Scholar] [CrossRef]
- Imai, N.; Sugau, J.B.; Pereira, J.T.; Titin, J.; Kitayama, K. Impacts of Selective Logging on Spatial Structure of Tree Species Composition in Bornean Tropical Rain Forests. J. Forest Res. 2019, 24, 335–340. [Google Scholar] [CrossRef]
- Kasischke, E.S.; Melack, J.M.; Dobson, M.C. The Use of Imaging Radars for Ecological Applications—A Review. Remote Sens. Environ. 1997, 59, 141–156. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Soenen, S.A.; Peddle, D.R.; Coburn, C.A. SCS+C: A Modified Sun-Canopy-Sensor Topographic Correction in Forested Terrain. IEEE Trans. Geosci. Remote Sens. 2005, 43, 2148–2159. [Google Scholar] [CrossRef]
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Hughes, M.J.; Laue, B. Cloud Detection Algorithm Comparison and Validation for Operational Landsat Data Products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef] [Green Version]
- Van Wagtendonk, J.W.; Root, R.R.; Key, C.H. Comparison of AVIRIS and Landsat ETM+ Detection Capabilities for Burn Severity. Remote Sens. Environ. 2004, 92, 397–408. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Yang, Z.; Cohen, W.B. Detecting Trends in Forest Disturbance and Recovery Using Yearly Landsat Time Series: 1. LandTrendr—Temporal Segmentation Algorithms. Remote Sens. Environ. 2010, 114, 2897–2910. [Google Scholar] [CrossRef]
- Langner, A.; Miettinen, J.; Kukkonen, M.; Vancutsem, C.; Simonetti, D.; Vieilledent, G.; Verhegghen, A.; Gallego, J.; Stibig, H.-J. Towards Operational Monitoring of Forest Canopy Disturbance in Evergreen Rain Forests: A Test Case in Continental Southeast Asia. Remote Sens. 2018, 10, 544. [Google Scholar] [CrossRef] [Green Version]
- McFeeters, S.K. The Use of the Normalized Difference Water Index (NDWI) in the Delineation of Open Water Features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Chaves, M.E.D.; Picoli, M.C.A.; Sanches, I.D. Recent Applications of Landsat 8/OLI and Sentinel-2/MSI for Land Use and Land Cover Mapping: A Systematic Review. Remote Sens. 2020, 12, 3062. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the Radiometric and Biophysical Performance of the MODIS Vegetation Indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Hall-Beyer, M. Practical Guidelines for Choosing GLCM Textures to Use in Landscape Classification Tasks over a Range of Moderate Spatial Scales. Int. J. Remote Sens. 2017, 38, 1312–1338. [Google Scholar] [CrossRef]
- R-Core-Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Hijmans, R.J. Terra: Spatial Data Analysis; CRAN: Vienna, Austria, 2021. [Google Scholar]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- John, E.; Bunting, P.; Hardy, A.; Silayo, D.S.; Masunga, E. A Forest Monitoring System for Tanzania. Remote Sens. 2021, 13, 3081. [Google Scholar] [CrossRef]
- Abdi, A.M. Land Cover and Land Use Classification Performance of Machine Learning Algorithms in a Boreal Landscape Using Sentinel-2 Data. GIScience Remote Sens. 2019, 57, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Filzmoser, P.; Liebmann, B.; Varmuza, K. Repeated Double Cross Validation. J. Chemometr. 2009, 23, 160–171. [Google Scholar] [CrossRef]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. In Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; Volume 14, pp. 1137–1145. [Google Scholar]
- Sechidis, K.; Tsoumakas, G.; Vlahavas, I. On the Stratification of Multi-Label Data. In Proceedings of the Machine Learning and Knowledge Discovery in Database, PT III, Athens, Greece, 5–9 September 2011; Springer: Berlin, Germany, 2011; Volume 6913, pp. 145–158. [Google Scholar] [CrossRef] [Green Version]
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.S.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schröder, B.; Thuiller, W.; et al. Cross-validation Strategies for Data with Temporal, Spatial, Hierarchical, or Phylogenetic Structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Molnar, C. Iml: An R Package for Interpretable Machine Learning. J. Open Source Softw. 2018, 3, 786. [Google Scholar] [CrossRef] [Green Version]
- Dunnett, C.W. A Multiple Comparison Procedure for Comparing Several Treatments with a Control. J. Am. Stat. Assoc. 1955, 50, 1096. [Google Scholar] [CrossRef]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using Lme4. J. Stat. Softw. 2014, 67, 1–48. [Google Scholar] [CrossRef]
- Hothorn, T.; Bretz, F.; Westfall, P. Simultaneous Inference in General Parametric Models. Biom. J. 2008, 50, 346–363. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Requena-Suarez, D.; Rozendaal, D.M.A.; Sy, V.D.; Phillips, O.L.; Alvarez-Dávila, E.; Anderson-Teixeira, K.; Araujo-Murakami, A.; Arroyo, L.; Baker, T.R.; Bongers, F.; et al. Estimating Aboveground Net Biomass Change for Tropical and Subtropical Forests: Refinement of IPCC Default Rates Using Forest Plot Data. Glob. Chang. Biol. 2019, 25, 3609–3624. [Google Scholar] [CrossRef] [PubMed]
- Asner, G.P.; Brodrick, P.G.; Philipson, C.; Vaughn, N.R.; Martin, R.E.; Knapp, D.E.; Heckler, J.; Evans, L.J.; Jucker, T.; Goossens, B.; et al. Mapped Aboveground Carbon Stocks to Advance Forest Conservation and Recovery in Malaysian Borneo. Biol. Conserv. 2018, 217, 289–310. [Google Scholar] [CrossRef]
- Rutishauser, E.; Hérault, B.; Baraloto, C.; Blanc, L.; Descroix, L.; Sotta, E.D.; Ferreira, J.; Kanashiro, M.; Mazzei, L.; d’Oliveira, M.V.N.; et al. Rapid Tree Carbon Stock Recovery in Managed Amazonian Forests. Curr. Biol. 2015, 25, R787–R788. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sabah-Forestry-Department. 3rd Forest Management Plan: Deramakot Forest Reserve, Forest Management Unit No. 19; Sabah-Forestry-Department: Sandakan, Malaysia, 2014. [Google Scholar]
- Asner, G.P.; Martin, R.E. Canopy Phylogenetic, Chemical and Spectral Assembly in a Lowland Amazonian Forest. New Phytol. 2011, 189, 999–1012. [Google Scholar] [CrossRef]
- Lu, D.; Mausel, P.; Brondízio, E.; Moran, E. Relationships between Forest Stand Parameters and Landsat TM Spectral Responses in the Brazilian Amazon Basin. For. Ecol. Manag. 2004, 198, 149–167. [Google Scholar] [CrossRef]
- O’Brien, M.J.; Philipson, C.D.; Reynolds, G.; Dzulkifli, D.; Snaddon, J.L.; Ong, R.; Hector, A. Positive Effects of Liana Cutting on Seedlings Are Reduced during El Niño-induced Drought. J. Appl. Ecol. 2019, 56, 891–901. [Google Scholar] [CrossRef]
- Lussetti, D.; Kuljus, K.; Ranneby, B.; Ilstedt, U.; Falck, J.; Karlsson, A. Using Linear Mixed Models to Evaluate Stand Level Growth Rates for Dipterocarps and Macaranga Species Following Two Selective Logging Methods in Sabah, Borneo. For. Ecol. Manag. 2019, 437, 372–379. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite | Name | Abbreviation | Wave Length (nm)/Equation |
|---|---|---|---|
| Landsat-8 | Blue | 450–515 | |
| Green | 525–600 | ||
| Red | 630–680 | ||
| Near infrared | NIR | 845–885 | |
| Short wave infrared 1 | SWIR1 | 1560–1660 | |
| Short wave infrared 2 | SWIR2 | 2100–2300 | |
| Normalized burn ratio | NBR | (NIR − SWIR2)/(NIR + SWIR2) | |
| Normalized difference water index | NDWI | (Green − NIR)/(Green + NIR) | |
| Enhanced vegetation index | EVI | (NIR − Red)/[(NIR + 6 × Red − 7.5 × Blue) + 1] | |
| GLCM dissimilarity | _diss | ||
| GLCM correlation | _corr | ||
| Sentinel-1 | Vertical transmit and Vertical receive | VV | |
| Vertical transmit and Horizontal receive | VH |
| Data Set Code | The Number of the Variables | Variable Used for Each Data Set |
|---|---|---|
| VI (base data set) | 9 | Landsat surface reflectance + vegetation indices |
| VI_SAR | 11 | Landsat surface reflectance + vegetation indices + Sentinel back-scatter signal |
| VI_TEX | 17 | Landsat surface reflectance + vegetation indices + GLCM texture variables |
| VI_TEX_SAR | 19 | Landsat surface reflectance + vegetation indices + GLCM texture variables + Sentinel back-scatter signal |
| Hyper-Parameter | Description of Each Parameter | Candidate Values |
|---|---|---|
| eta | Shrinkage of each step | 0.01, 0.05, 0.1, 0.2, 0.3 |
| subsample | The ratio of sub-sampling of the number of samples at each tree | 0.5, 0.7, 0.9, 1.0 |
| colsample_bytree | The ratio of sub-sampling of the number of variables at each tree | 0.5, 0.7, 0.9, 1.0 |
| max_depth | Maximum depth of each tree | 2, 4, 8, 10, 20 |
| min_child_weight | The threshold of the weight of the terminal node | 0, 1, 2, 5, 10, 20 |
| nrounds | The number of trees | Set 50,000 as default and sequentially determined based on the multi-class cross-entropy loss value. We adopted the number of trees when the metric was minimized within 100 trials before and after. |
| Forest Reserve | Land-Cover Type | Total (ha) | ||||
|---|---|---|---|---|---|---|
| Forest (ha, %) | Fern (ha, %) | Vine (ha, %) | Bare Soil (ha, %) | Open Water (ha, %) | ||
| Deramakot | 36,564.0 (70.8) | 1662.1 (3.2) | 13,090.6 (25.3) | 59.7 (0.1) | 277.5 (0.5) | 51,653.9 |
| Tangkulap | 16,083.3 (63.3) | 2258.6 (8.9) | 6654.4 (26.2) | 127.1 (0.5) | 291.9 (1.1) | 25,415.2 |
| Overall | 52,608.9 (68.3) | 3916.5 (5.1) | 19,733.8 (25.6) | 186.8 (0.2) | 568.5 (0.7) | 77,014.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Takeshige, R.; Onishi, M.; Aoyagi, R.; Sawada, Y.; Imai, N.; Ong, R.; Kitayama, K. Mapping the Spatial Distribution of Fern Thickets and Vine-Laden Forests in the Landscape of Bornean Logged-Over Tropical Secondary Rainforests. Remote Sens. 2022, 14, 3354. https://doi.org/10.3390/rs14143354
Takeshige R, Onishi M, Aoyagi R, Sawada Y, Imai N, Ong R, Kitayama K. Mapping the Spatial Distribution of Fern Thickets and Vine-Laden Forests in the Landscape of Bornean Logged-Over Tropical Secondary Rainforests. Remote Sensing. 2022; 14(14):3354. https://doi.org/10.3390/rs14143354
Chicago/Turabian StyleTakeshige, Ryuichi, Masanori Onishi, Ryota Aoyagi, Yoshimi Sawada, Nobuo Imai, Robert Ong, and Kanehiro Kitayama. 2022. "Mapping the Spatial Distribution of Fern Thickets and Vine-Laden Forests in the Landscape of Bornean Logged-Over Tropical Secondary Rainforests" Remote Sensing 14, no. 14: 3354. https://doi.org/10.3390/rs14143354
APA StyleTakeshige, R., Onishi, M., Aoyagi, R., Sawada, Y., Imai, N., Ong, R., & Kitayama, K. (2022). Mapping the Spatial Distribution of Fern Thickets and Vine-Laden Forests in the Landscape of Bornean Logged-Over Tropical Secondary Rainforests. Remote Sensing, 14(14), 3354. https://doi.org/10.3390/rs14143354