
Spatio-Temporal Knowledge Graph Based Forest Fire Prediction with Multi Source Heterogeneous Data

 ,
, 
Abstract
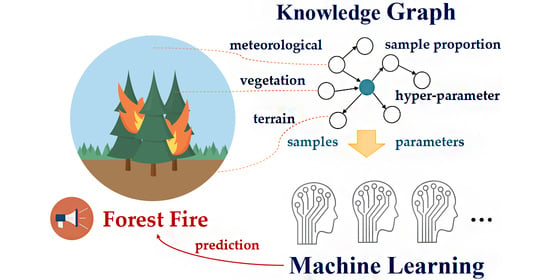
:
1. Introduction
2. Knowledge Graph-Based Forest Fire Prediction System (KGFFP)
2.1. Method Architecture
2.1.1. Conceptual Model for Forest Fire Prediction
2.1.2. Mapping between Forest Fire Prediction and KGFFP Architecture
2.2. Construction of Forest Fire Prediction Knowledge Graph
2.2.1. Design of Conceptual Layer
- Time ontology and space ontology
- Ontology for forest fire prediction
- Machine learning model concept ontology
2.2.2. Design of Instance Layer
- Instantiation of Multi-source spatio-temporal data
- Instantiation of machine learning-based forest fire prediction model
2.2.3. Design of Inference Rules of Forest Fire Predictions
2.3. Implementation of Spatio-Temporal Knowledge Graph for Forest Fire Prediction
2.3.1. Data Resource Layer
2.3.2. Knowledge Extraction Layer
2.3.3. Knowledge Storage Layer
2.3.4. Analysis Service Layer
3. Forest Fire Prediction Experiment Using KGFFP
3.1. Area of Experiment
3.2. Predictive Model
3.3. Construction of KGFFP
- Definition of spatio-temporal semantic rule set 1: Extracting spatio-temporal data from KGFFP to make labeled and unlabeled datasets.
- Definition of spatio-temporal semantic rule set 2: Inputting the data set into the machine learning model for model training or prediction with the support of inference rules.
- Definition of spatio-temporal semantic rule set 3: Calculating the accuracy based on the prediction results and real data and evaluating the accuracy of the prediction model.
3.4. Predicting Forest Fires
3.4.1. Sensitivity Analysis
3.4.2. Experimental Results
- Experiment 1
- 2.
- Experiment 2
4. Discussion
5. Conclusions
- (1)
- KGFFP integrates multi-source heterogeneous data through semantic technology from the perspective of cross-domain data integration;
- (2)
- This paper proposes a method to model the domain expertise. It can effectively represent multi-source expertise with a triples form that can facilitate optimization and prediction of the machine learning models for forest fire prediction scenarios;
- (3)
- Relying on the proposed method, the machine learning-based forest fire prediction methods can be optimized according to historical data with satisfied accuracies. In the case of providing future forest fire-related data, it is expected to obtain better forest fire prediction results.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Podur, J.; Martell, D.L.; Csillag, F. Spatial patterns of lightning-caused forest fires in Ontario, 1976–1998. Ecol. Model. 2003, 164, 1–20. [Google Scholar] [CrossRef]
- Hering, A.S.; Bell, C.L.; Genton, M.G. Modeling spatio-temporal wildfire ignition point patterns. Environ. Ecol. Stat. 2008, 16, 225–250. [Google Scholar] [CrossRef] [Green Version]
- Salavati, G.; Saniei, E.; Ghaderpour, E.; Hassan, Q.K. Wildfire Risk Forecasting Using Weights of Evidence and Statistical Index Models. Sustainability 2022, 14, 3881. [Google Scholar] [CrossRef]
- Chen, J.; Wang, X.; Yu, Y.; Yuan, X.; Quan, X.; Huang, H. Improved Prediction of Forest Fire Risk in Central and Northern China by a Time-Decaying Precipitation Model. Forests 2022, 13, 480. [Google Scholar] [CrossRef]
- Ge, X.; Yang, Y.; Chen, J.; Li, W.; Huang, Z.; Zhang, W.; Peng, L. Disaster Prediction Knowledge Graph Based on Multi-Source Spatio-Temporal Information. Remote Sens. 2022, 14, 1214. [Google Scholar] [CrossRef]
- Jaafari, A.; Gholami, D.M.; Zenner, E.K. A Bayesian modeling of wildfire probability in the Zagros Mountains, Iran. Ecol. Inform. 2017, 39, 32–44. [Google Scholar] [CrossRef]
- Sakr, G.E.; Elhajj, I.H.; Mitri, G.; Wejinya, U.C. Artificial intelligence for forest fire prediction. In Proceedings of the 2010 IEEE/ASME International Conference on Advanced Intelligent Mechatronics 2010, Montreal, QC, Canada, 6–9 July 2010; pp. 1311–1316. [Google Scholar]
- PPham, B.T.; Jaafari, A.; Avand, M.; Al-Ansari, N.; Dinh Du, T.; Yen, H.P.H.; Phong, T.V.; Nguyen, D.H.; Le, H.V.; Mafi-Gholami, D.; et al. Performance Evaluation of Machine Learning Methods for Forest Fire Modeling and Prediction. Symmetry 2020, 12, 1022. [Google Scholar] [CrossRef]
- Ma, W.Y.; Feng, Z.K.; Cheng, Z.X.; Wang, F.G. Study on driving factors and distribution pattern of forest fires in Shanxi province. J. Cent. South Univ. For. Technol. 2020, 40, 57–69. [Google Scholar]
- Singh, M.; Huang, Z. Analysis of Forest Fire Dynamics, Distribution and Main Drivers in the Atlantic Forest. Sustainability 2022, 14, 992. [Google Scholar] [CrossRef]
- Prapas, I.; Kondylatos, S.; Papoutsis, I.; Camps-Valls, G.; Ronco, M.; Fernández-Torres, M.; Guillem, M.P.; Carvalhais, N. Deep Learning Methods for Daily Wildfire Danger Forecasting. arXiv 2021, arXiv:2111.02736. [Google Scholar]
- Fire Map—NASA. Available online: https://firms2.modaps.eosdis.nasa.gov/map/ (accessed on 29 April 2022).
- Cui, L.; Luo, C.; Yao, C.; Zou, Z.; Wu, G.; Li, Q.; Wang, X. The Influence of Climate Change on Forest Fires in Yunnan Province, Southwest China Detected by GRACE Satellites. Remote Sens. 2022, 14, 712. [Google Scholar] [CrossRef]
- Tavakkoli Piralilou, S.; Einali, G.; Ghorbanzadeh, O.; Nachappa, T.G.; Gholamnia, K.; Blaschke, T.; Ghamisi, P. A Google Earth Engine Approach for Wildfire Susceptibility Prediction Fusion with Remote Sensing Data of Different Spatial Resolutions. Remote Sens. 2022, 14, 672. [Google Scholar] [CrossRef]
- Schulte, L.A.; Mladenoff, D.J. Severe wind and fire regimes in northern forests: Historical variability at the regional scale. Ecology 2005, 86, 431–445. [Google Scholar] [CrossRef]
- Ali, A.A.; Carcaillet, C.; Bergeron, Y. Long-term fire frequency variability in the eastern Canadian boreal forest: The influences of climate vs. local factors. Glob. Chang. Biol. 2009, 15, 1230–1241. [Google Scholar] [CrossRef]
- Chen, J.; Ge, X.; Li, W.; Peng, L. Construction of spatio-temporal Knowledge Graph for Emergency Decision Making. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 3920–3923. [Google Scholar]
- O’Connor, M.J.; Das, A.K. A method for representing and querying temporal information in owl. In Proceedings of the In-ternational Joint Conference on Biomedical Engineering Systems and Technologies, Valencia, Spain, 20–23 January 2010; pp. 97–110. [Google Scholar]
- Chen, J.; Zhong, S.; Ge, X.; Li, W.; Zhu, H.; Peng, L. Spatio-Temporal Knowledge Graph for Meteorological Risk Analysis. In Proceedings of the 2021 IEEE 21st International Conference on Software Quality, Reliability and Security Companion (QRS-C), Hainan, China, 6–10 December 2021; pp. 440–447. [Google Scholar]
- What is Arcpy?-Help|ArcGIS for Desktop. Available online: https://desktop.arcgis.com/en/arcmap/10.3/analyze/arcpy/what-is-arcpy-.htm (accessed on 14 July 2022).
- ERA5-Land Hourly Data from 1950 to Present. Available online: https://cds.climate.copernicus.eu/ (accessed on 8 June 2022).
- LP DAAC—Homepage. Available online: https://lpdaac.usgs.gov/ (accessed on 8 June 2022).
- Esri_2020_Land_Cover_V2 ImageServer. Available online: https://tiledimageservices.arcgis.com/P3ePLMYs2RVChkJx/arcgis/rest/services/Esri_2020_Land_Cover_V2/ImageServer (accessed on 8 June 2022).
- National Forest Resources Intelligent Management Platform. Available online: http://www.stgz.org.cn/ (accessed on 8 June 2022).
- Data Center of Resources and Environment Science of Chinese Academy of Sciences. Available online: http://www.resdc.cn (accessed on 6 January 2022).
- Li, X.H. Using “random forest” for classification and regression. Chin. J. Appl. Entomol. 2013, 50, 1190–1197. [Google Scholar]
- Zhang, L.; Wang, L.L.; Zhang, X.D.; Liu, S.R.; Sun, P.S.; Wang, T.L. The basic principle of random forest and its applications in ecology: A case study of Pinus yunnanensis. Acta Ecol. Sin. 2014, 34, 650–659. [Google Scholar]
- Fang, K.N.; Wu, J.B.; Zhu, J.P.; Xie, B.C. A review of random forest method research. Stat. Inf. Forum 2011, 26, 32–38. (In Chinese) [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Boser, B.; Denker, J.S. Handwritten digit recognition with a back-propagation network. In Advances in Neural Infor-mation Processing Systems; Morgan Kaufmann Publishers: San Francisco, CA, USA, 1990; pp. 396–404. [Google Scholar]
- Kontschieder, P.; Fiterau, M.; Criminisl, A. Deep neural decision forests. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1467–1475. [Google Scholar]
- Zhen, X.; Wang, Z.; Islam, A.; Bhaduri, M.; Chan, I.; Li, S. Multi-scale deep networks and regression forests for direct biventricular volume estimation. Med. Image Anal. 2016, 30, 120–129. [Google Scholar] [CrossRef] [PubMed]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Commonly Used Methods | The Method Proposed in This Paper |
|---|---|
| Through data processing, the time, space, type, resolution, and coordinate systems of data are unified. | From the semantic point of view, the temporal, spatial, and attribute features of the data are fused. |
| The spatio-temporal data is stored in a relational database and needs to be added, deleted, queried, and changed based on the graph database. | The spatio-temporal data is stored in the graph database and needs to be added, deleted, queried, and changed based on the graph database. |
| Multi-table joins are required for in-depth searches in relational databases, resulting in low query efficiency. | Based on the graph database, in-depth queries can be made from a limited space-time region. The efficiency of querying various geographic entities and the relationship between geographic entities in forest fire prediction scenarios is high. |
| Data | Sources | Spatial Resolution | Temporal Resolution | Satellite Sensor |
|---|---|---|---|---|
| Fire | Fire Map–NASA [12] | About 0.375 km × 0.375 km; about 1 km × 1 km | Mid-latitudes will experience 3–4 looks a day | VIIRS S-NPP; VIIRS NOAA-20; MODIS/Aqua; MODIS/Terra |
| Meteorological | ERA5-Land hourly data from 1950 to present [21] | 0.1° × 0.1°; Native resolution is 9 km | Update hourly | None |
| Terrain | Shuttle Radar Topography Mission DEM [22] | 30 m × 30 m | Acquired 11–22 February 2000 | STS Endeavour OV-105 |
| Land cover | Esri_2020_Land_Cover_V2 ImageServer [23] | 10 m × 10 m | Released in 2020 | Sentinel-2L2A/B |
| Vegetation | “One Map” of Forest Inspection and Forest Resource Management in 2020 [24] | 2 km × 2 km | Released in 2020 | None |
| Normalized Difference Vegetation Index (NDVI) | China Quarterly Vegetation Index (NDVI) Spatial Distribution Dataset [25] | 1 km × 1 km | Updated quarterly | SPOT; VEGETATION; MODIS |
| Training Data | Test Data | |||
|---|---|---|---|---|
| Positive Sample | Negative Sample | Positive Sample | Negative Sample | |
| 73 | 94 | 45 | 58 | |
| 73 | 109 | 45 | 67 | |
| Training Data | Test Data | |||
|---|---|---|---|---|
| Positive Sample | Negative Sample | Positive Sample | Negative Sample | |
| 659 | 724 | 45 | 49 | |
| Training Data | Test Data | |||
|---|---|---|---|---|
| Positive Sample | Negative Sample | Positive Sample | Negative Sample | |
| 150 | 180 | 45 | 54 | |
| 150 | 195 | 45 | 58 | |
| Experiment 1 | Experiment 2 | ||||
|---|---|---|---|---|---|
| The First Dataset | The Second Dataset | ||||
| F1 (RF) | F1 (DF) | F1 (RF) | F1 (DF) | F1 (RF) | F1 (DF) |
| 0.7839 | 0.7957 | 0.7973 | 0.8191 | 0.7960 | 0.7776 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, X.; Yang, Y.; Peng, L.; Chen, L.; Li, W.; Zhang, W.; Chen, J. Spatio-Temporal Knowledge Graph Based Forest Fire Prediction with Multi Source Heterogeneous Data. Remote Sens. 2022, 14, 3496. https://doi.org/10.3390/rs14143496
Ge X, Yang Y, Peng L, Chen L, Li W, Zhang W, Chen J. Spatio-Temporal Knowledge Graph Based Forest Fire Prediction with Multi Source Heterogeneous Data. Remote Sensing. 2022; 14(14):3496. https://doi.org/10.3390/rs14143496
Chicago/Turabian StyleGe, Xingtong, Yi Yang, Ling Peng, Luanjie Chen, Weichao Li, Wenyue Zhang, and Jiahui Chen. 2022. "Spatio-Temporal Knowledge Graph Based Forest Fire Prediction with Multi Source Heterogeneous Data" Remote Sensing 14, no. 14: 3496. https://doi.org/10.3390/rs14143496
APA StyleGe, X., Yang, Y., Peng, L., Chen, L., Li, W., Zhang, W., & Chen, J. (2022). Spatio-Temporal Knowledge Graph Based Forest Fire Prediction with Multi Source Heterogeneous Data. Remote Sensing, 14(14), 3496. https://doi.org/10.3390/rs14143496