
Direction Estimation of Aerial Image Object Based on Neural Network


Abstract
:
1. Introduction
- (1)
- This paper presents a new object expression method, which uses two components of the direction angle to represent the direction of the object. Then, the geometric model of the object is constrained by combining the coordinates of the center point and the length and width of the object.
- (2)
- The change function is adopted, and the network conversion layer is introduced. Then, the output components of the neural network naturally meet the constraints and improve the adaptability of the network model.
- (3)
- This paper can realize object detection and direction estimation at the same time. Then, an accuracy index for quantitatively evaluating the accuracy of angle estimation is proposed.
2. Related Work
3. Algorithm Description
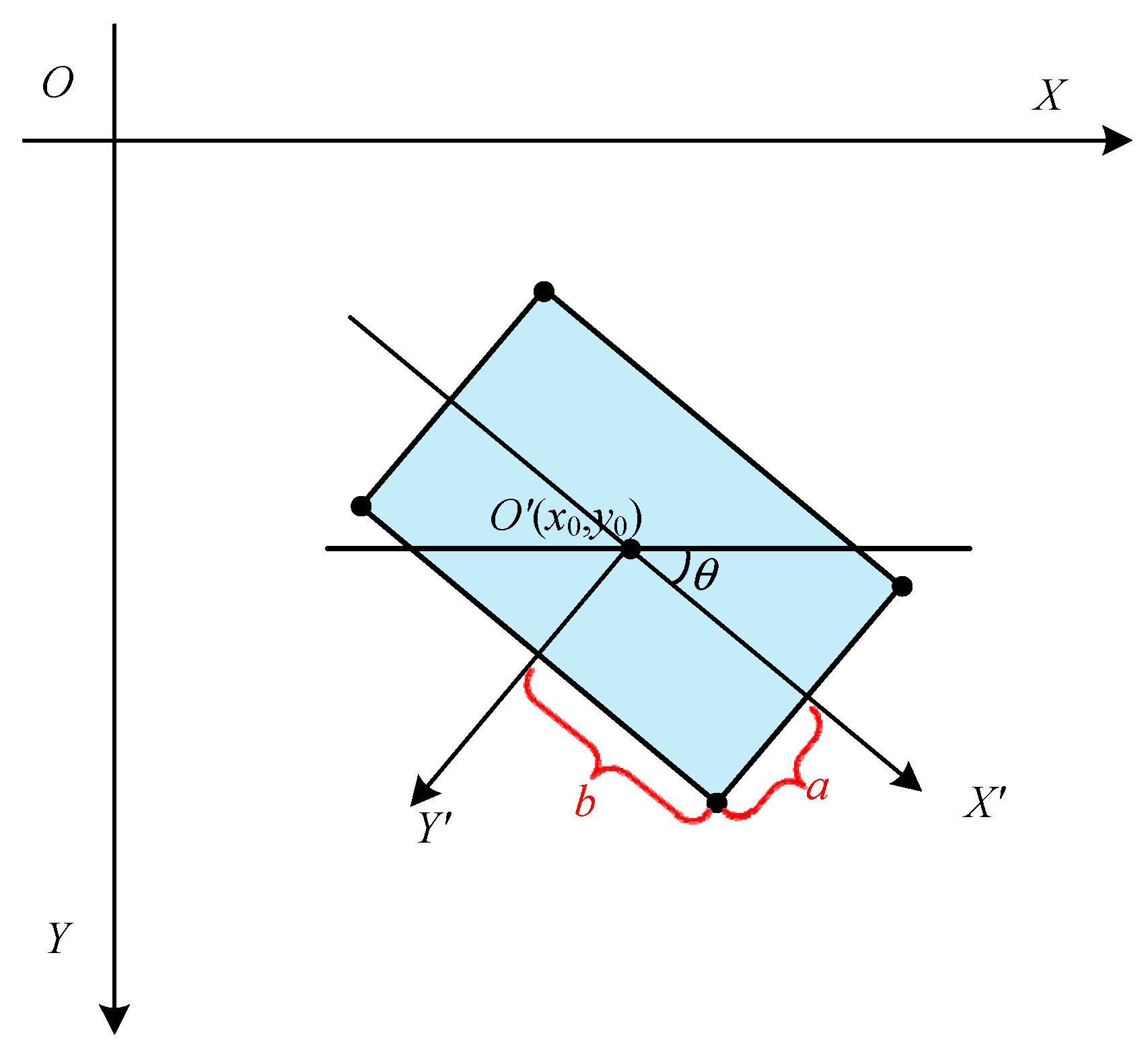
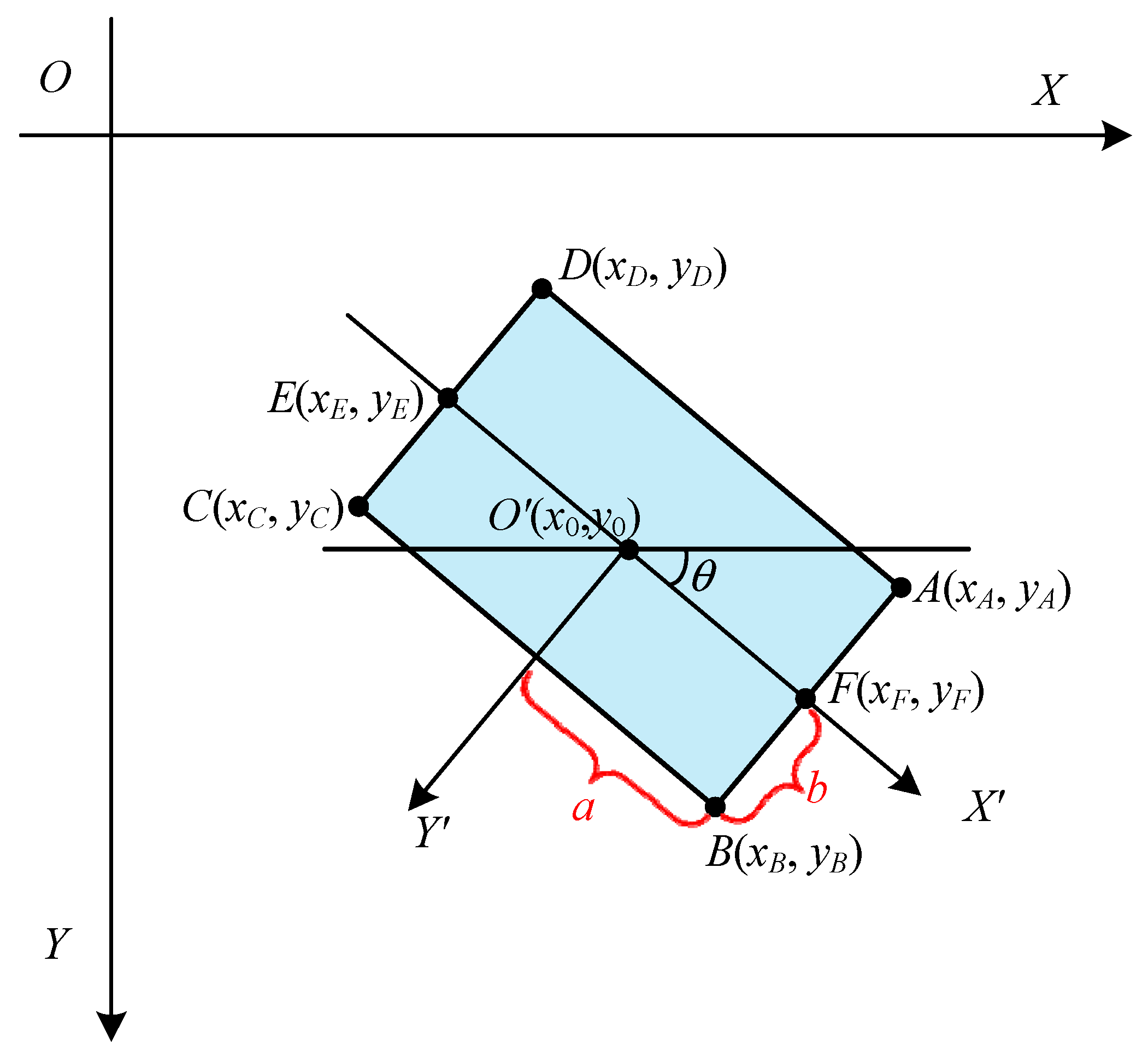
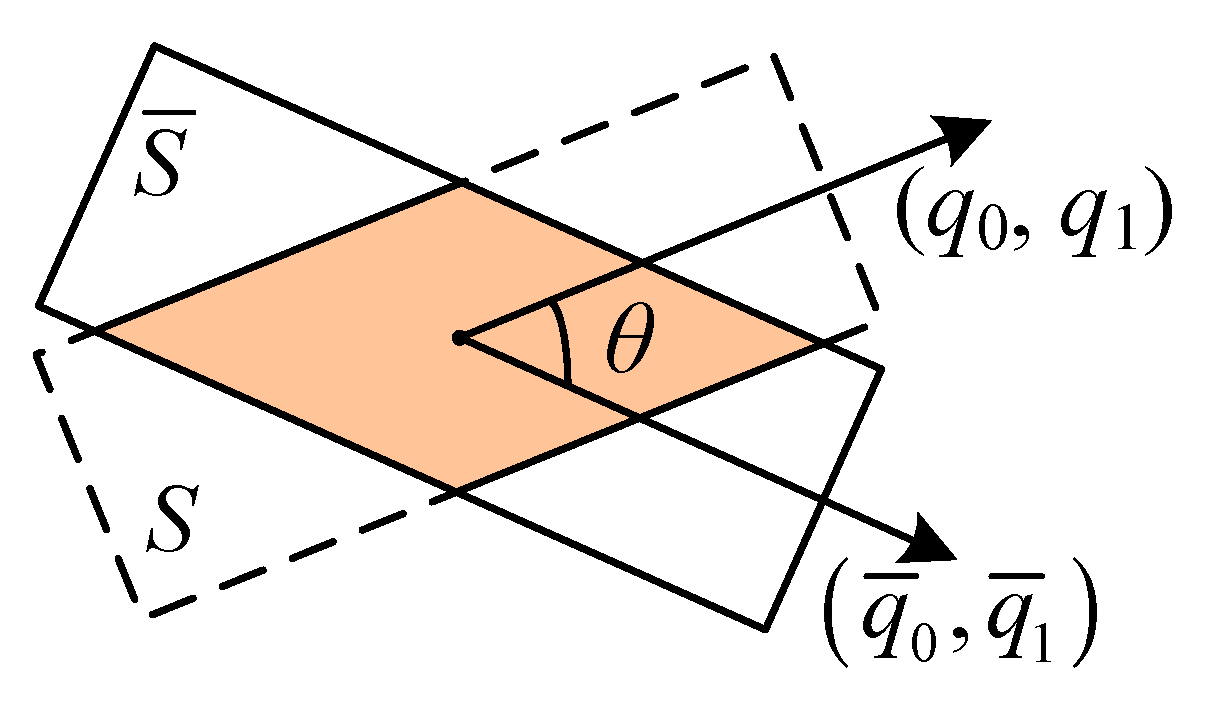
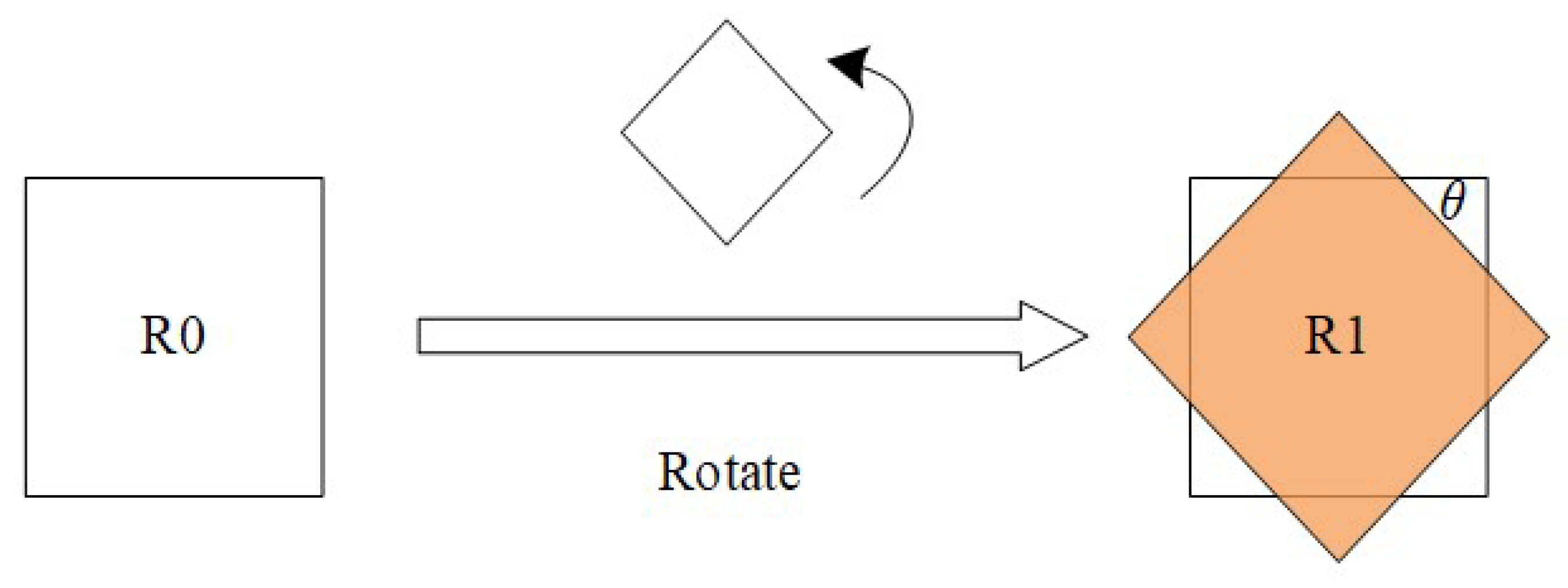
3.1. Representation of the Direction of the Object
3.2. Network Structure
4. Experiment and Discussion
4.1. Calculate the Ground Truth
4.2. Accuracy Index
- (1)
- IoU
- (2)
- dot
- (3)
- mAP
- (4)
- f1
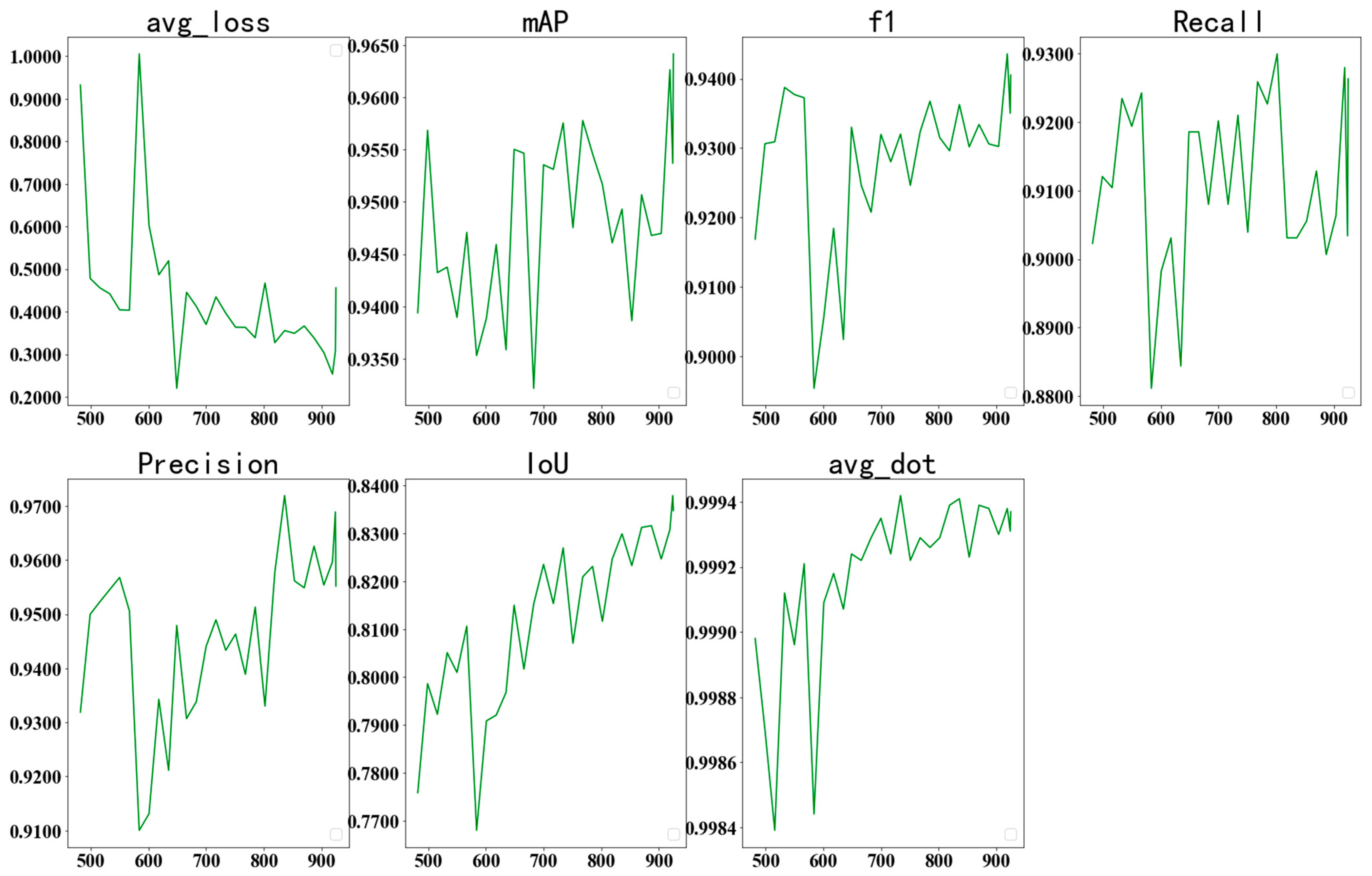
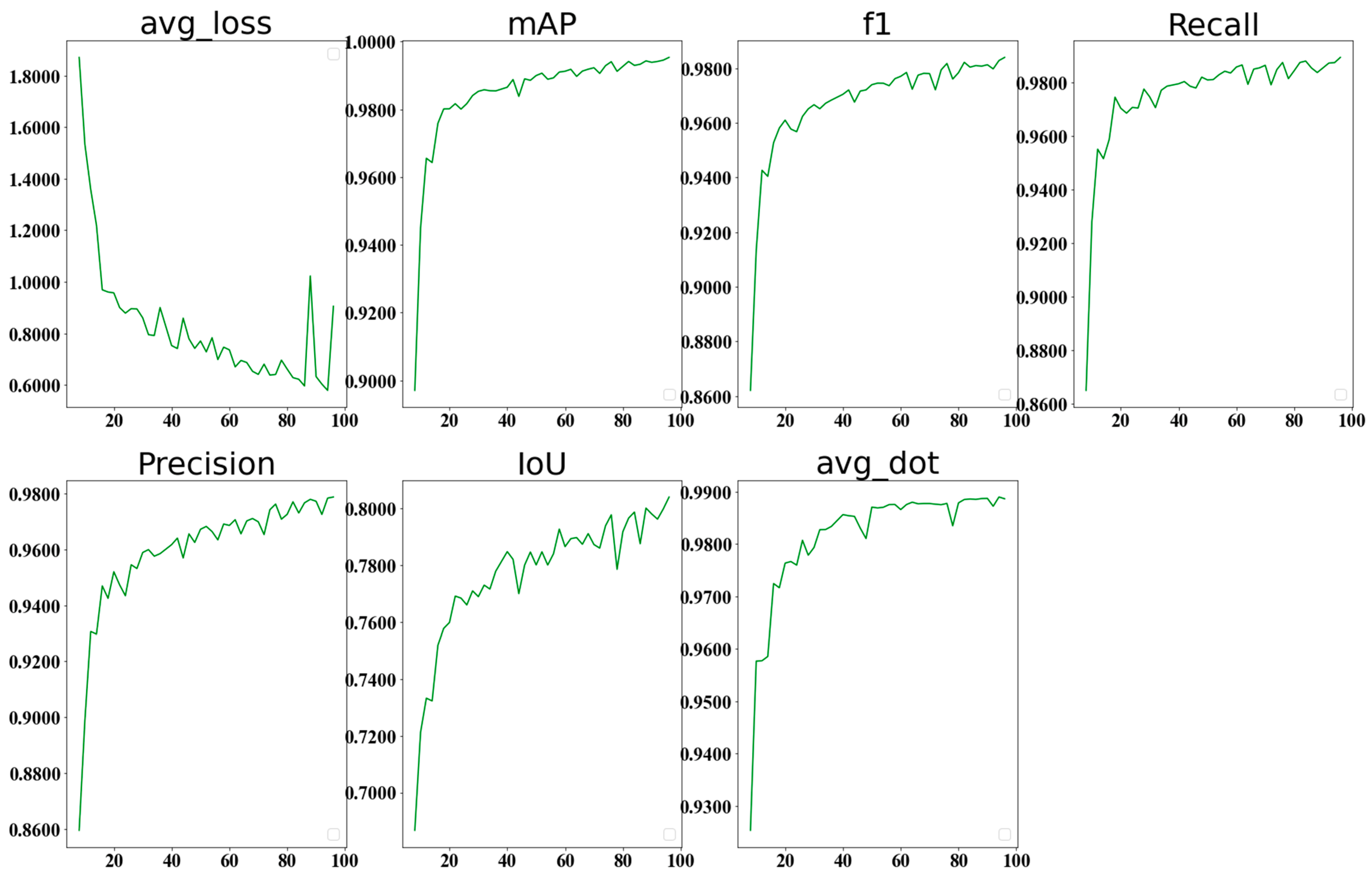
4.3. Result Analysis
- (1)
- DOTA 1.5
- (2)
- HRSC
- (3)
- UCAS-AOD
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Baroud, S.; Chokri, S.; Belhaous, S.; Mestari, M. A brief review of graph convolutional neural network based learning for classifying remote sensing images. Procedia Comput. Sci. 2021, 191, 349–354. [Google Scholar] [CrossRef]
- Varadarajan, V.; Garg, D.; Kotecha, K. An efficient deep convolutional neural network approach for object detection and recognition using a multi-Scale anchor box in real-Time. Future Internet 2021, 13, 307. [Google Scholar] [CrossRef]
- Liu, J.; Gao, Y. Field Network—A New Method to Detect Directional Object. Sensors 2020, 20, 4262. [Google Scholar] [CrossRef] [PubMed]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Vicente, S.; Carreira, J.; Agapito, L.; Batista, J. Reconstructing pascal voc. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washingtong, DC, USA, 23–28 June 2014; pp. 41–48. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? Adv. Neural Inf. Process. Syst. 2018, 31, 2488–2498. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lecun, Y.L.; Bottou, L.; Bengio, Y. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhev, A.; Suts, I.; Hinton, G.E. Image net classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates Inc.: Lake Tahoe, NV, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; Conference Track Proceedings: San Diego, CA, USA, 2015; pp. 1–13. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Jun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.; Dollár, P.; Girshick, R. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Honolulu, HI, USA, 2017; pp. 936–944. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 99, 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You Only Look Once: Unified, Real-Time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multi Box Detector. Comput. Vis. 2015, 9905, 21–37. [Google Scholar]
- Zhou, Y.; Ye, Q.; Qiu, Q.; Jiao, J. Oriented response networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 4961–4970. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational region CNN for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Tang, T.; Zhou, S.; Deng, Z.; Lei, L.; Zou, H. Arbitrary-oriented vehicle detection in aerial imagery with single convolutional neural networks. Remote Sens. 2017, 9, 1170. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4974–4983. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2786–2795. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 2849–2858. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, X.; Liu, Q.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. arXiv 2019, arXiv:1908.05612. [Google Scholar]
- Liao, M.; Zhu, Z.; Shi, B.; Xia, G.S.; Bai, X. Rotation-sensitive regression for oriented scene text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5909–5918. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 3735–3739. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolo9000, Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic anchor learning for arbitrary-oriented object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 2355–2363. [Google Scholar]
- Bao, S.; Zhong, X.; Zhu, R.; Zhang, X.; Li, Z.; Li, M. Single shot anchor refinement network for oriented object detection in optical remote sensing imagery. IEEE Access 2019, 7, 87150–87161. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision Indexes | mAP | F1 | IoU | Dot |
|---|---|---|---|---|
| propose method | 67.52 | 70.61 | 72.64 | 89.13 |
| Dot | Plane | BD | Bridge | GRF | SV | LV | Ship | TC | BC | ST | SBF | RA | Harbor | SP | HC | CC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Propose method | 53.81 | - | 76.96 | 80.77 | 99.47 | 99.48 | 99.57 | 99.17 | 98.54 | - | 81.06 | - | 95.36 | - | 96.21 | - |
| Method | Plane | BD | Bridge | GRF | SV | LV | Ship | TC | BC | ST | SBF | RA | Harbor | SP | HC | CC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Propose method | 96.43 | 86.07 | 47.56 | 56.29 | 63.96 | 81.96 | 94.74 | 93.65 | 73.65 | 84.67 | 42.46 | 65.18 | 64.74 | 67.24 | 6117 | 0.56 | 67.52 |
| RetinaNet-O [25] | 71.43 | 77.64 | 42.12 | 64.65 | 44.53 | 56.79 | 73.31 | 90.84 | 76.02 | 59.96 | 46.95 | 69.24 | 59.65 | 64.52 | 48.06 | 0.83 | 59.16 |
| FR-O [15] | 71.89 | 74.47 | 44.45 | 59.87 | 51.28 | 68.98 | 79.37 | 90.78 | 77.38 | 67.50 | 47.75 | 69.72 | 61.22 | 65.28 | 60.47 | 1.54 | 62.00 |
| Mask R-CNN [17] | 76.84 | 73.51 | 49.90 | 57.80 | 51.31 | 71.34 | 79.75 | 90.46 | 74.21 | 66.07 | 46.21 | 70.61 | 63.07 | 64.46 | 57.81 | 9.42 | 62.67 |
| HTC [26] | 77.80 | 73.67 | 51.40 | 63.99 | 51.54 | 73.31 | 80.31 | 90.48 | 75.12 | 67.34 | 48.51 | 70.63 | 64.84 | 64.48 | 55.87 | 5.15 | 63.40 |
| ReDet [27] | 79.20 | 82.81 | 51.92 | 71.41 | 52.38 | 75.73 | 80.92 | 90.83 | 75.81 | 68.64 | 49.29 | 72.03 | 73.36 | 70.55 | 63.33 | 11.53 | 66.86 |
| Technical Indicators | mAP | Dot | F1 | IoU |
|---|---|---|---|---|
| propose method | 96.42 | 99.93 | 94.05 | 83.48 |
| RoI Trans. [28] | 86.2 | - | - | - |
| GV [29] | 88.2 | - | - | - |
| R3Det [30] | 89.33 | - | - | - |
| RRD [31] | 84.3 | - | - | - |
| CSL [3] | 89.62 | - | - | - |
| Method | AP | mAP | Dot (Each Class) | Dot | IoU | F1 | ||
|---|---|---|---|---|---|---|---|---|
| Plane | Car | Plane | Car | |||||
| Propose method | 99.80 | 99.26 | 99.53 | 98.29 | 99.43 | 98.86 | 80.41 | 98.39 |
| YOLO-v2 [33] | 96.60 | 79.20 | 87.90 | - | - | - | - | - |
| R-DFPN [34] | 95.90 | 82.50 | 89.20 | - | - | - | - | - |
| DAL [35] | 90.49 | 89.25 | 89.87 | - | - | - | - | - |
| DRBox [17] | 94.90 | 85.00 | 89.95 | - | - | - | - | - |
| S2ARN [36] | 97.60 | 92.20 | 94.90 | - | - | - | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Liu, J. Direction Estimation of Aerial Image Object Based on Neural Network. Remote Sens. 2022, 14, 3523. https://doi.org/10.3390/rs14153523
Zhang H, Liu J. Direction Estimation of Aerial Image Object Based on Neural Network. Remote Sensing. 2022; 14(15):3523. https://doi.org/10.3390/rs14153523
Chicago/Turabian StyleZhang, Hongyun, and Jin Liu. 2022. "Direction Estimation of Aerial Image Object Based on Neural Network" Remote Sensing 14, no. 15: 3523. https://doi.org/10.3390/rs14153523
APA StyleZhang, H., & Liu, J. (2022). Direction Estimation of Aerial Image Object Based on Neural Network. Remote Sensing, 14(15), 3523. https://doi.org/10.3390/rs14153523