
Deep Contrastive Self-Supervised Hashing for Remote Sensing Image Retrieval



Abstract
:
1. Introduction
- We present a novel deep unsupervised hashing method for remote sensing image retrieval. Motivated by contrast learning, we hypothesize that the hash codes for different views generated from the same image are similar, while the hash codes for views generated from different images are not similar. To the best of our knowledge, we are the first to implement this idea for remote sensing image retrieval. According to the hypothesis, we can build a deep unsupervised hash network with end-to-end training, which can learn discriminative hash codes from a large number of unlabeled data. It avoids the problem of annotating images compared to most deep hashing algorithms.
- We introduce a novel hashing objective loss to train our deep network. This gives each image a more effective hash code, improving the efficiency of image searching. Additionally, instead of the conventional relaxation strategy, we propose a continuous strategy that converges a non-differentiable sign function using a sequence of differentiable functions, allowing us to explicitly enforce binary constraints on hash codes.
- In contrast to existing unsupervised hashing methods for the retrieval of remote sensing images, we achieve the state-of-the-art results on benchmark datasets of the UC Merced Land Use Database and the Aerial Image Dataset.
2. Related Work
3. Proposed Method
3.1. Data Augmentation
3.2. Encoder
3.3. Hashing Layer
3.4. Loss Function
3.5. Optimization by Continuation
| Algorithm 1 DCSH’s main learning algorithm. |
Require: batch size M, initial and trainable encoder parameters , initial and trainable hash layer parameters , hyper-parameter of temperature and weighting parameter
|
4. Experiments
4.1. Datasets
- UCMD [69]: It is publicly free and provided by the University of California, which collected surface images from the United States national city map produced by the United States Geological Survey. This dataset comprises 21 challenging land cover concepts, where each concept consists of 100 images of size with a spatial resolution of 0.3 m per pixel. We show images from UCMD in Figure 4.
- AID [70]: It is a large-scale remote sensing publicly available dataset gathered by Wuhan University from Google Earth imagery. The images are completely annotated by specialists in the remote sensing image interpretation field. By contrast with the UC Merced dataset, AID is significantly more challenging. Specifically, the dataset comprises a total of 10,000 aerial images with a fixed size of pixels and a spatial resolution varying from 8 m to about 0.5 m. It is categorized into 30 land-use scene classes such as airport, bare land, dense residential, desert, and so on; each class contains a number of images ranging from 220 to 420. Furthermore, the AID is derived from diverse remote sensing imaging sensors and chosen from different countries, under various times and distinct seasons, which makes the intra-class diversity larger and inter-class dissimilarity smaller as well. We show images from AID in Figure 5.
4.2. Evaluation Protocols
4.3. Implementation Details
4.4. Comparative Experiments with State-of-the-Art Methods
4.4.1. Results on UCMD
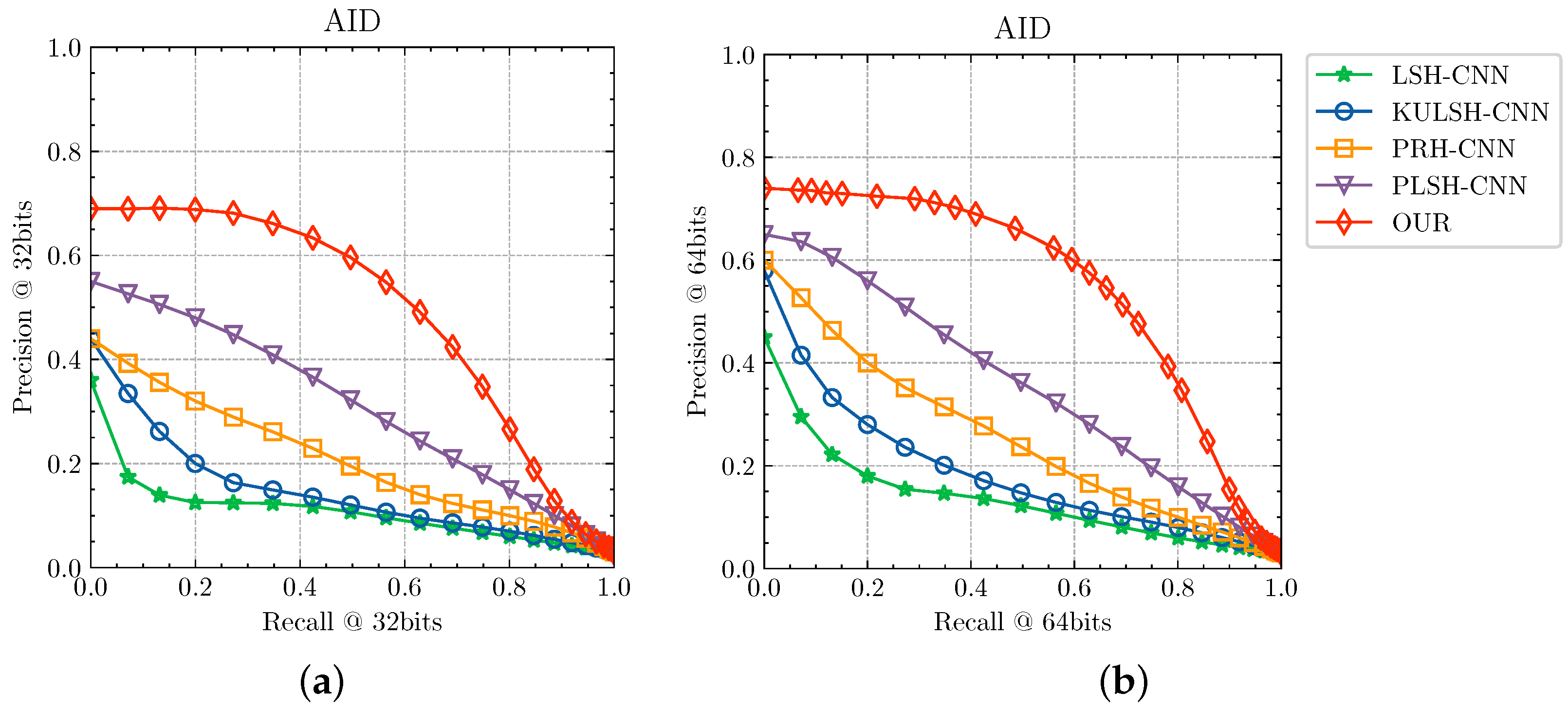
4.4.2. Results on AID
5. Discussion
5.1. The Analysis and Setting of Temperature
5.2. The Analysis and Setting of Training Batch Size
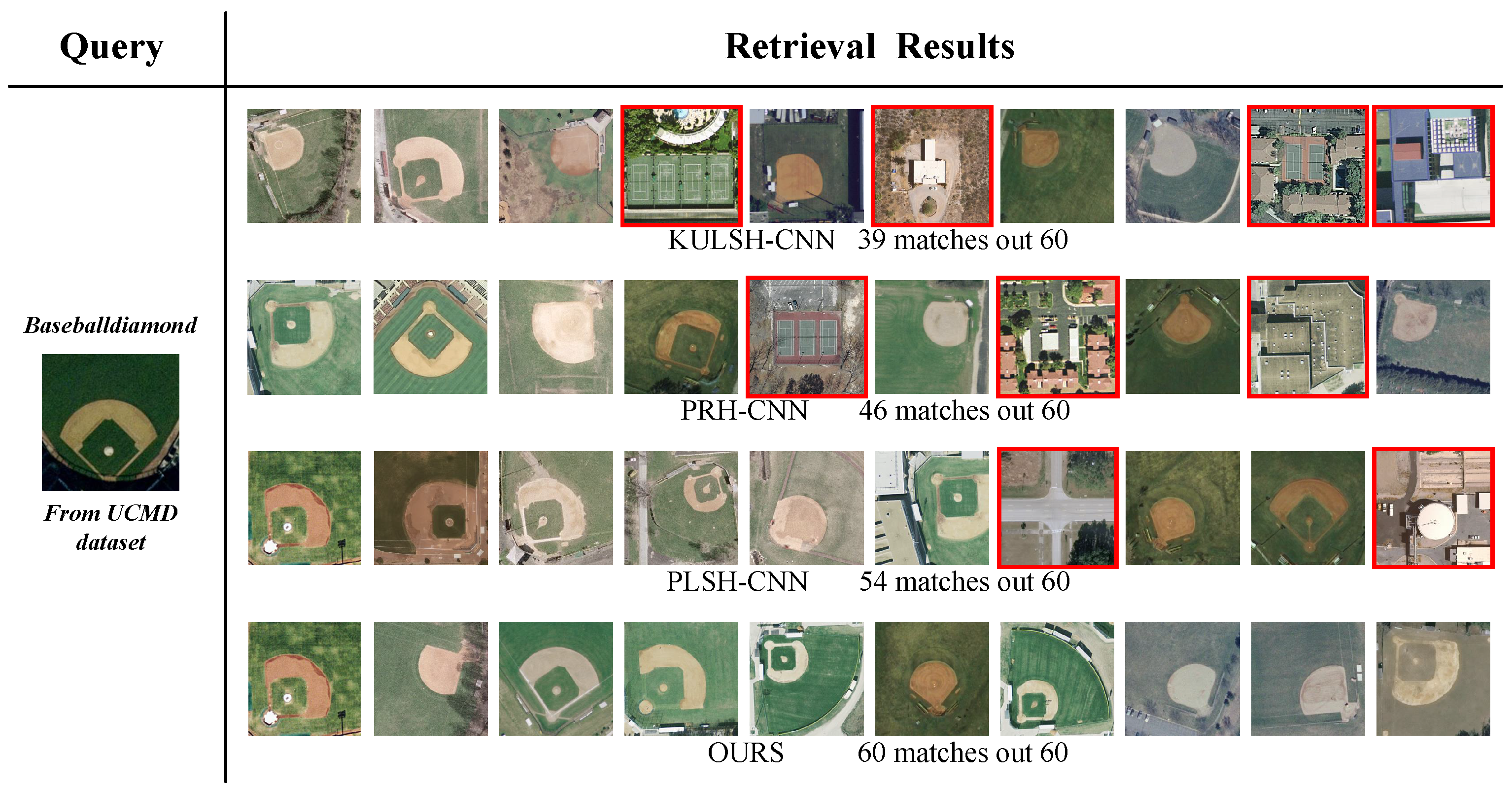
5.3. Visualization Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lu, H.; Su, H.; Hu, J.; Du, Q. Dynamic Ensemble Learning with Multi-View Kernel Collaborative Subspace Clustering for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2681–2695. [Google Scholar] [CrossRef]
- Li, Y.; Ma, J.; Zhang, Y. Image retrieval from remote sensing big data: A survey. Inf. Fusion 2021, 67, 94–115. [Google Scholar] [CrossRef]
- Tong, X.Y.; Xia, G.S.; Hu, F.; Zhong, Y.; Datcu, M.; Zhang, L. Exploiting deep features for remote sensing image retrieval: A systematic investigation. IEEE Trans. Big Data 2019, 6, 507–521. [Google Scholar] [CrossRef] [Green Version]
- Wolfmuller, M.; Dietrich, D.; Sireteanu, E.; Kiemle, S.; Mikusch, E.; Bottcher, M. Data flow and workflow organization—The data management for the TerraSAR-X payload ground segment. IEEE Trans. Geosci. Remote Sens. 2008, 47, 44–50. [Google Scholar] [CrossRef]
- Wang, X.; Chen, N.; Chen, Z.; Yang, X.; Li, J. Earth observation metadata ontology model for spatiotemporal-spectral semantic-enhanced satellite observation discovery: A case study of soil moisture monitoring. GISci. Remote Sens. 2016, 53, 22–44. [Google Scholar] [CrossRef]
- Peijun, D.; Yunhao, C.; Hong, T.; Tao, F. Study on content-based remote sensing image retrieval. In Proceedings of the IGARSS’05. 2005 IEEE International Geoscience and Remote Sensing Symposium, Seoul, Korea, 25–29 July 2005; Volume 2, p. 4. [Google Scholar]
- Datta, R.; Li, J.; Wang, J.Z. Content-based image retrieval: Approaches and trends of the new age. In Proceedings of the 7th ACM SIGMM International Workshop on Multimedia Information Retrieval, Singapore, 10–11 November 2005; pp. 253–262. [Google Scholar]
- Bretschneider, T.; Cavet, R.; Kao, O. Retrieval of remotely sensed imagery using spectral information content. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Toronto, ON, Canada, 24–28 June 2002; Volume 4, pp. 2253–2255. [Google Scholar]
- Shao, Z.; Zhou, W.; Zhang, L.; Hou, J. Improved color texture descriptors for remote sensing image retrieval. J. Appl. Remote Sens. 2014, 8, 083584. [Google Scholar] [CrossRef] [Green Version]
- Byju, A.P.; Demir, B.; Bruzzone, L. A progressive content-based image retrieval in JPEG 2000 compressed remote sensing archives. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5739–5751. [Google Scholar] [CrossRef]
- Dell’Acqua, F.; Gamba, P. Query-by-shape in meteorological image archives using the point diffusion technique. IEEE Trans. Geosci. Remote Sens. 2001, 39, 1834–1843. [Google Scholar] [CrossRef]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Yang, Y.; Newsam, S. Geographic image retrieval using local invariant features. IEEE Trans. Geosci. Remote Sens. 2012, 51, 818–832. [Google Scholar] [CrossRef]
- Shan, X.; Liu, P.; Wang, Y.; Zhou, Q.; Wang, Z. Deep Hashing Using Proxy Loss on Remote Sensing Image Retrieval. Remote Sens. 2021, 13, 2924. [Google Scholar] [CrossRef]
- Kang, J.; Fernandez-Beltran, R.; Ye, Z.; Tong, X.; Plaza, A. Deep hashing based on class-discriminated neighborhood embedding. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5998–6007. [Google Scholar] [CrossRef]
- Liu, C.; Ma, J.; Tang, X.; Zhang, X.; Jiao, L. Adversarial hash-code learning for remote sensing image retrieval. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 4324–4327. [Google Scholar]
- Demir, B.; Bruzzo, L. Kernel-based hashing for content-based image retrval in large remote sensing data archive. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 3542–3545. [Google Scholar]
- Kong, J.; Sun, Q.; Mukherjee, M.; Lloret, J. Low-Rank Hypergraph Hashing for Large-Scale Remote Sensing Image Retrieval. Remote Sens. 2020, 12, 1164. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Ma, J.; Tang, X.; Liu, F.; Zhang, X.; Jiao, L. Deep hash learning for remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3420–3443. [Google Scholar] [CrossRef]
- Li, P.; Zhang, X.; Zhu, X.; Ren, P. Online hashing for scalable remote sensing image retrieval. Remote Sens. 2018, 10, 709. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Han, L.; Tao, X.; Zhang, X.; Grecos, C.; Plaza, A.; Ren, P. Hashing nets for hashing: A quantized deep learning to hash framework for remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7331–7345. [Google Scholar] [CrossRef]
- Song, W.; Li, S.; Benediktsson, J.A. Deep hashing learning for visual and semantic retrieval of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 9661–9672. [Google Scholar] [CrossRef]
- Tang, X.; Zhang, X.; Liu, F.; Jiao, L. Unsupervised deep feature learning for remote sensing image retrieval. Remote Sens. 2018, 10, 1243. [Google Scholar] [CrossRef] [Green Version]
- Jin, S.; Yao, H.; Sun, X.; Zhou, S. Unsupervised semantic deep hashing. Neurocomputing 2019, 351, 19–25. [Google Scholar] [CrossRef] [Green Version]
- Reato, T.; Demir, B.; Bruzzone, L. An unsupervised multicode hashing method for accurate and scalable remote sensing image retrieval. IEEE Geosci. Remote Sens. Lett. 2018, 16, 276–280. [Google Scholar] [CrossRef] [Green Version]
- Fernandez-Beltran, R.; Demir, B.; Pla, F.; Plaza, A. Unsupervised remote sensing image retrieval using probabilistic latent semantic hashing. IEEE Geosci. Remote Sens. Lett. 2020, 18, 256–260. [Google Scholar] [CrossRef]
- Huang, Y.; Peng, J.; Ning, Y.; Sun, W.; Du, Q. Graph embedding and distribution alignment for domain adaptation in hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7654–7666. [Google Scholar] [CrossRef]
- Yang, B.; Li, H.; Guo, Z. Learning a deep similarity network for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1482–1496. [Google Scholar] [CrossRef]
- Deng, W.; Shi, Q.; Li, J. Attention-Gate-Based Encoder–Decoder Network for Automatical Building Extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2611–2620. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Zhu, H.; Ma, J. Large-scale remote sensing image retrieval by deep hashing neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 56, 950–965. [Google Scholar] [CrossRef]
- Han, L.; Li, P.; Bai, X.; Grecos, C.; Zhang, X.; Ren, P. Cohesion intensive deep hashing for remote sensing image retrieval. Remote Sens. 2020, 12, 101. [Google Scholar] [CrossRef] [Green Version]
- Roy, S.; Sangineto, E.; Demir, B.; Sebe, N. Metric-learning-based deep hashing network for content-based retrieval of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 226–230. [Google Scholar] [CrossRef] [Green Version]
- Cao, R.; Zhang, Q.; Zhu, J.; Li, Q.; Li, Q.; Liu, B.; Qiu, G. Enhancing remote sensing image retrieval using a triplet deep metric learning network. Int. J. Remote Sens. 2020, 41, 740–751. [Google Scholar] [CrossRef] [Green Version]
- Sumbul, G.; Ravanbakhsh, M.; Demir, B. Informative and Representative Triplet Selection for Multilabel Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Cheng, Q.; Huang, H.; Ye, L.; Fu, P.; Gan, D.; Zhou, Y. A Semantic-Preserving Deep Hashing Model for Multi-Label Remote Sensing Image Retrieval. Remote Sens. 2021, 13, 4965. [Google Scholar] [CrossRef]
- Demir, B.; Bruzzone, L. Hashing-based scalable remote sensing image search and retrieval in large archives. IEEE Trans. Geosci. Remote Sens. 2015, 54, 892–904. [Google Scholar] [CrossRef]
- Li, P.; Ren, P. Partial randomness hashing for large-scale remote sensing image retrieval. IEEE Geosci. Remote Sens. Lett. 2017, 14, 464–468. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, H.; Zhao, S. Auto-encoder based dimensionality reduction. Neurocomputing 2016, 184, 232–242. [Google Scholar] [CrossRef]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef] [Green Version]
- Li, W.J.; Wang, S.; Kang, W.C. Feature learning based deep supervised hashing with pairwise labels. arXiv 2015, arXiv:1511.03855. [Google Scholar]
- Xia, R.; Pan, Y.; Lai, H.; Liu, C.; Yan, S. Supervised hashing for image retrieval via image representation learning. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Chen, Y.; Zhao, D.; Lu, X.; Xiong, S.; Wang, H. Unsupervised Balanced Hash Codes Learning With Multichannel Feature Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2816–2825. [Google Scholar] [CrossRef]
- Ye, D.; Li, Y.; Tao, C.; Xie, X.; Wang, X. Multiple feature hashing learning for large-scale remote sensing image retrieval. ISPRS Int. J. Geo-Inf. 2017, 6, 364. [Google Scholar] [CrossRef] [Green Version]
- Reato, T.; Demir, B.; Bruzzone, L. Primitive cluster sensitive hashing for scalable content-based image retrieval in remote sensing archives. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 2199–2202. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very deep convolutional networks for text classification. arXiv 2016, arXiv:1606.01781. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, Y.; Geng, L.; Lai, H.; Pan, Y.; Yin, J. Feature pyramid hashing. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 114–122. [Google Scholar]
- Sohn, K. Improved deep metric learning with multi-class n-pair loss objective. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 1857–1865. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Santoro, A.; Marris, L.; Akerman, C.J.; Hinton, G. Backpropagation and the brain. Nat. Rev. Neurosci. 2020, 21, 335–346. [Google Scholar] [CrossRef]
- Lai, H.; Pan, Y.; Liu, Y.; Yan, S. Simultaneous feature learning and hash coding with deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3270–3278. [Google Scholar]
- Cao, Y.; Long, M.; Liu, B.; Wang, J. Deep cauchy hashing for hamming space retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1229–1237. [Google Scholar]
- Shen, Y.; Qin, J.; Chen, J.; Yu, M.; Liu, L.; Zhu, F.; Shen, F.; Shao, L. Auto-encoding twin-bottleneck hashing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2818–2827. [Google Scholar]
- Gong, Y.; Lazebnik, S.; Gordo, A.; Perronnin, F. Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2916–2929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Su, S.; Zhang, C.; Han, K.; Tian, Y. Greedy hash: Towards fast optimization for accurate hash coding in cnn. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Virtual, 6–14 December 2018; pp. 806–815. [Google Scholar]
- Lin, K.; Lu, J.; Chen, C.S.; Zhou, J. Learning compact binary descriptors with unsupervised deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1183–1192. [Google Scholar]
- Zhang, P.; Zhang, W.; Li, W.J.; Guo, M. Supervised hashing with latent factor models. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast, Australia, 6–11 July 2014; pp. 173–182. [Google Scholar]
- Chen, Z.; Yuan, X.; Lu, J.; Tian, Q.; Zhou, J. Deep hashing via discrepancy minimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6838–6847. [Google Scholar]
- Do, T.T.; Le, K.; Hoang, T.; Le, H.; Nguyen, T.V.; Cheung, N.M. Simultaneous feature aggregating and hashing for compact binary code learning. IEEE Trans. Image Process. 2019, 28, 4954–4969. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuan, X.; Ren, L.; Lu, J.; Zhou, J. Relaxation-free deep hashing via policy gradient. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 134–150. [Google Scholar]
- Zhang, R.; Lin, L.; Zhang, R.; Zuo, W.; Zhang, L. Bit-scalable deep hashing with regularized similarity learning for image retrieval and person re-identification. IEEE Trans. Image Process. 2015, 24, 4766–4779. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, Z.; Long, M.; Wang, J.; Yu, P.S. Hashnet: Deep learning to hash by continuation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5608–5617. [Google Scholar]
- Song, J.; He, T.; Gao, L.; Xu, X.; Hanjalic, A.; Shen, H.T. Unified Binary Generative Adversarial Network for Image Retrieval and Compression. Int. J. Comput. Vis. 2020, 128, 2243–2264. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Yang, K.; Zhou, W. Performance evaluation of single-label and multi-label remote sensing image retrieval using a dense labeling dataset. Remote Sens. 2018, 10, 964. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jin, Z.; Li, C.; Lin, Y.; Cai, D. Density sensitive hashing. IEEE Trans. Cybern. 2013, 44, 1362–1371. [Google Scholar] [CrossRef] [Green Version]
- Slaney, M.; Casey, M. Locality-sensitive hashing for finding nearest neighbors [lecture notes]. IEEE Signal Process. Mag. 2008, 25, 128–131. [Google Scholar] [CrossRef]
- Qiu, Z.; Su, Q.; Ou, Z.; Yu, J.; Chen, C. Unsupervised Hashing with Contrastive Information Bottleneck. arXiv 2021, arXiv:2105.06138. [Google Scholar]
- Wang, F.; Liu, H. Understanding the behaviour of contrastive loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2495–2504. [Google Scholar]


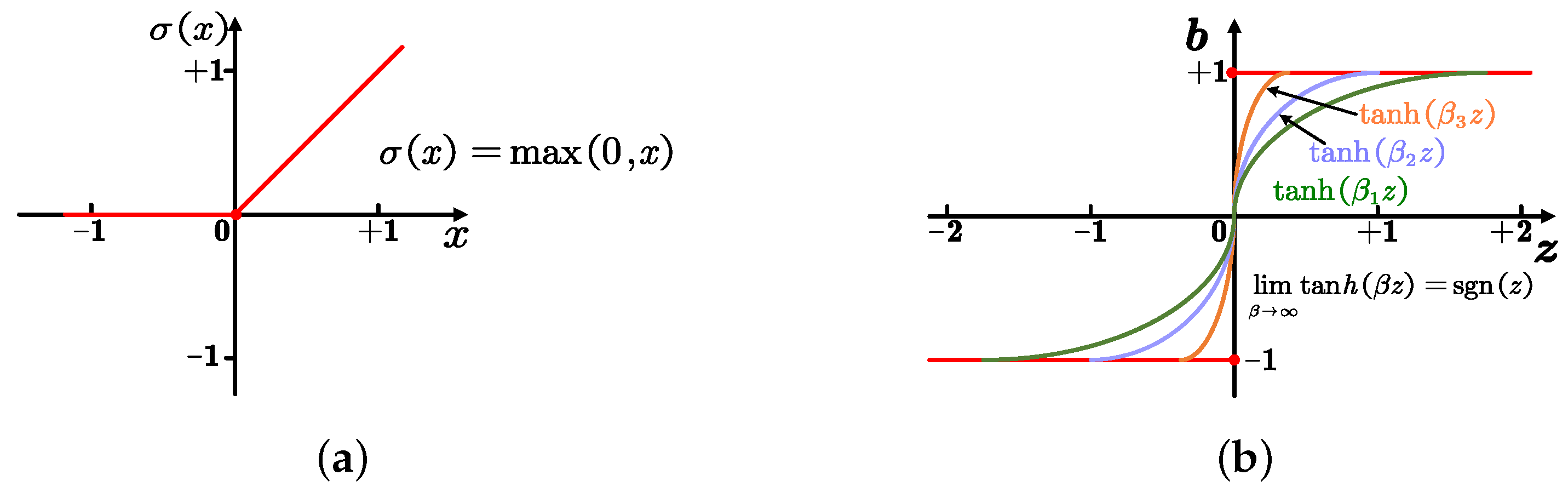









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Output Size (Width × Height × Channel) | Configuration |
|---|---|---|
| conv1 | 112 × 112 × 64 | 7 × 7, 64, stride 2 |
| conv2_x | 56 × 56 × 256 | 3 × 3 max pool, stride 2 |
| × 3 | ||
| conv3_x | 28 × 28 × 512 | × 4 |
| conv4_x | 14 × 14 × 1024 | × 6 |
| conv5_x | 7 × 7 × 2048 | × 3 |
| global average pooling layer | 2048 | global average pooling |
| Method | Hash Code Length | |||
|---|---|---|---|---|
| 16-bits | 32-bits | 48-bits | 64-bits | |
| DSH-GIST [74] | 16.38 | 17.09 | 19.24 | 19.18 |
| LSH-GIST [75] | 17.55 | 18.25 | 19.78 | 21.46 |
| ITQ-GIST [59] | 19.35 | 20.45 | 20.89 | 20.78 |
| KULSH-GIST [36] | 28.37 | 33.56 | 34.98 | 34.16 |
| PRH-GIST [37] | 31.77 | 33.38 | 35.76 | 36.92 |
| PLSH-GIST [26] | 40.49 | 44.17 | 47.32 | 46.37 |
| DSH-CNN | 28.35 | 33.90 | 34.24 | 34.66 |
| LSH-CNN | 32.44 | 38.58 | 45.48 | 51.67 |
| ITQ-CNN | 42.38 | 45.99 | 47.28 | 47.49 |
| KULSH-CNN | 53.68 | 55.37 | 58.23 | 64.58 |
| PRH-CNN | 55.39 | 59.45 | 61.89 | 67.77 |
| PLSH-CNN | 62.28 | 65.35 | 70.44 | 73.07 |
| OUR | 75.80 | 78.17 | 80.49 | 80.09 |
| Method | Hash Code Length | |||
|---|---|---|---|---|
| 16-bits | 32-bits | 48-bits | 64-bits | |
| DSH-GIST [74] | 9.42 | 9.87 | 10.06 | 10.35 |
| LSH-GIST [75] | 10.53 | 10.89 | 12.74 | 13.77 |
| ITQ-GIST [59] | 9.67 | 10.49 | 11.74 | 11.91 |
| KULSH-GIST [36] | 11.43 | 13.46 | 14.63 | 15.86 |
| PRH-GIST [37] | 13.42 | 15.37 | 15.74 | 17.26 |
| PLSH-GIST [26] | 13.26 | 17.32 | 18.64 | 18.99 |
| DSH-CNN | 16.25 | 18.74 | 19.63 | 19.57 |
| LSH-CNN | 25.44 | 29.79 | 35.58 | 40.66 |
| ITQ-CNN | 23.28 | 27.29 | 28.74 | 29.65 |
| KULSH-CNN | 38.47 | 41.37 | 46.64 | 50.62 |
| PRH-CNN | 43.89 | 47.58 | 50.27 | 55.74 |
| PLSH-CNN | 48.72 | 52.35 | 55.83 | 60.14 |
| OUR | 66.17 | 70.04 | 71.48 | 73.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, X.; Zou, Y.; Guo, Z.; Zhou, K.; Yuan, Q. Deep Contrastive Self-Supervised Hashing for Remote Sensing Image Retrieval. Remote Sens. 2022, 14, 3643. https://doi.org/10.3390/rs14153643
Tan X, Zou Y, Guo Z, Zhou K, Yuan Q. Deep Contrastive Self-Supervised Hashing for Remote Sensing Image Retrieval. Remote Sensing. 2022; 14(15):3643. https://doi.org/10.3390/rs14153643
Chicago/Turabian StyleTan, Xiaoyan, Yun Zou, Ziyang Guo, Ke Zhou, and Qiangqiang Yuan. 2022. "Deep Contrastive Self-Supervised Hashing for Remote Sensing Image Retrieval" Remote Sensing 14, no. 15: 3643. https://doi.org/10.3390/rs14153643
APA StyleTan, X., Zou, Y., Guo, Z., Zhou, K., & Yuan, Q. (2022). Deep Contrastive Self-Supervised Hashing for Remote Sensing Image Retrieval. Remote Sensing, 14(15), 3643. https://doi.org/10.3390/rs14153643