1. Introduction
Hyperspectral imaging, widely referred to as image spectroscopy, aims at capturing electromagnetic energy emitted off the land cover under observation, over hundreds of contiguous, narrow spectral bands between infrared and visible wavelength ranges. Hyperspectral remote sensing data thus collected with the aid of multiple unmanned aerial devices such as drones, satellites, etc. have strongly favored the emergence of numerous hyperspectral remote sensing applications built around land cover classification for farming [
1] for earth observation and monitoring, planning the cities [
2], aerial devices based supervision [
3], weather forecasting and climate monitoring [
4], observations on changes in climatic conditions [
5], etc. Over the last decade, breakthroughs in artificial intelligence (especially in machine learning and deep learning) have prompted the hyperspectral remote sensing community to focus on developing efficient hyperspectral image classification approaches for feature extraction [
6,
7], HSI data classification [
6,
8] and object detection for HSI based applications [
9].
With most of the aforementioned remote sensing application frameworks, classification of HSI data acts as the center piece. While traditional machine learning-based HSI data classification and object detection frameworks rely primarily on spectral information as features [
10,
11], spectral feature-based classification approaches are unable to capture and use the spatial variability present in high-dimensional HSI data [
6,
8]. Distance measure [
12], KNN (K-Nearest Neighbors) [
13], maximum likelihood criteria [
14], AdaBoost [
15] , random forest classification [
16], and logistic regression [
17] are some of the frameworks that operate on spectral-only features that have been described in the literature and have proven to be useful in categorizing HSI data. Furthermore, literature has shown that combining a large number of spectral and spatial data in a complementary form can considerably improve the efficacy of HSI classification frameworks [
18,
19,
20].
Over the past few years, deep learning based HSI classification frameworks with stratified feature learning ability have dominated the domain of computer vision, and have produced superlative results in various remote sensing applications [
21,
22,
23]. Not only do these deep learning-based models have the capability to learn more convoluted and abstract features in the data [
24,
25], they also hold the intrinsic capability of learning higher level features present in the shallow part of the network. Such models are typically not affected by the changes to the input, and have produced unprecedented results in spectral-spatial feature extraction-based HSI classification frameworks [
6,
8].
Unsupervised and supervised feature extraction and data analysis methodologies applying convolution operation based neural networks, recurrent neural networks, residual networks, and additional models are used in deep learning-based frameworks for HSI classification, which fosters process automation through progressive data-learning. These approaches generally operate on HSI data that are represented in a lower dimensional space in comparison with the raw HSI data which is high dimensional in nature through incorporation of an effective dimensionality reduction technique producing promising results. A few such dimensionality reduction techniques that we come across in literature are principal component analysis (PCA) [
26], linear discriminant analysis (LDA) [
27], local fisher discriminant analysis (LFDA) [
28], random projections (RPs) [
6,
8,
29,
30], etc. However, it is evidently noticeable in the hyperspectral remote sensing community that the following questions have not been addressed effectively in literature to date [
31]:
Do all the spatial and spectral information extracted contribute equally towards effectively classifying HSI data with a deep learning framework?
If no, is there a technique to discriminate between less informative and more informative spectral bands that contribute towards effective HSI classification?
Is there a strategy that can improve HSI data classification in a comprehensive classification methodology by emphasizing the contribution of data points which happen to be more informative in a local spatial windowed area around the data point of interest?
Is it possible to improve the efficacy of an HSI classification methodology based on deep learning by highlighting more informative features and suppressing less valuable ones?
These questions fuel our motivation to devise a novel functional methodology to efficiently emphasize more informative pixels in a spatial neighborhood and spectral bands in the temporal domain which aid in boosting the efficacy of a HSI data classification framework. This phenomenon has widely been recognised as “ATTENTION” in the machine learning and deep learning community [
7,
32,
33]. Attention methodologies have recently been used extensively in language modeling and computer vision applications. Its accomplishment is based mostly on the fair presumption that human vision only pivots on specific sections of the entire visual expanse when and where required. Researchers over the past few years have extensively worked on such attention-based methodologies in the remote sensing community and produced exceptional results. For instance, Zhang et al. in [
34] proposed a saliency detection technique to extract salient areas in the input data which can be used for data representation and sampling. In a similar work, Diao et al. [
35] proposed an alternative technique where norm gradient maps could be effectively used as saliency maps for data representation. However, Wang et al. in [
36] claim that salient areas are not necessarily cardinal in achieving exceptional results in applications related to remote sensing data classification. Following this claim, they proposed to use LSTM networks to recurrently extract attention maps from deep convolutional features of a CNN based architecture. However, combining LSTM and CNN to extract attention features made the proposed methodology too complex and introduces scaling issues [
36]. Later, Haut et al. in [
37] proposed a two-branch attention module, where one branch is utilized to generate an attention mask and the other branch is utilized to extract convolutional features. Then, attention features are obtained by multiplying the attention mask with the convolutional features which proved to be an effective technique for hyperspectral data analysis and classification. With this phenomenon as an inspiration, we propose dual branch spectral–spatial attention based methodology for hyperspectral image classification. We aim to use attention mechanisms to improve the classification framework’s representation capacity, allowing us to focus on more selective spectral bands and spatial positions while repressing those that are not.
Hence, in this work, we propose a dual branch attention and classification framework for HSI data in order to address the aforementioned problems. To begin, principal component analysis was used as a computationally efficient dimensionality reduction component in this study to effectively extract spectral information, to reduce noise, and to bring down the redundancy in spectral information. Then, using a 3D-convolution based automated feature engineering technique and a bi-directional long short term memory (LSTM) based gated attention mechanism, a spectral attention and feature encoding mechanism that delivers enhanced hyperspectral data learning that emphasizes spectral information that is important for hyperspectral data review. Another significant contribution of this work is the proposal of a 3D-convolutional neural network and softmax activation based spatial attention technique to adaptively diversify spatial information around the pixel of interest into features of higher importance and into features that contribute less towards making classification decisions on input data. This is followed by a ResNet based feature encoding mechanism to encode this spatial information into a feature vector for classification. In addition, to evaluate the efficacy of this automated hyperspectral image classification methodology, a FNN-based supervised classification on the feature vectors derived from the spatial and spectral attention blocks is included.
Therefore, the novel contributions of the proposed dual-branched spatial-spectral attention and classification framework are summarized as follows:
A novel framework of spectral attention mechanism and feature encoding scheme using 3D-convolutions for volumetric feature analysis and feature extraction jointly with bi-directional LSTMs for spectral features based attention is proposed for hyperspectral image classification. Bi-directional LSTMs, in our work, offer an effective means to discriminate between features that are of less importance and emphasize more principle spectral information through a gating mechanism with softmax activation function. This technique also presents an effective way to encode spectral information, thus aiding in restoration and enhancement of spectral relationship between spectral bands in hyperspectral imagery data.
A unique combination of 3D-CNN based spatial attention mechanism and a ResNet based information encoding scheme is proposed, which not only constructively preserves the spatial relationship between pixels in a windowed region around the input data point, but also accents the weightage for features which have a dominant contribution in the ground truth based decision-making process of a HSI classification framework.
This work also proposes a capable technique for combining encoded characteristics from the spectral and spatial attention frameworks before being produced as an input to a feed-forward neural network (FNN) based supervised classification network to demonstrate the efficacy of our approach. In this work, the proposed dual-branched spatial-spectral attention and classification architecture is aimed at improving automated hyperspectral data analysis.
This paper also introduces a number of unique spatial-only and spectral-only attention based approaches and frameworks to conduct a brief evaluation on the effects of incorporation of attention methodology in hyperspectral image classification.
The following is a summary of the remainder of this paper: The theoretical description of each component in the proposed design is presented in
Section 2. This is continued by a detailed discussion on the proposed architecture in
Section 3, followed by a brief discussion about all the other methodologies used in our work as a means to compare the efficacy of our proposed methodology in
Section 4, which are then evaluated in
Section 5. Finally, in the conclusion
Section 6, the analysis on the efficacy of our proposed work is summarized.
3. Proposed Classification Methodology (SPAT-SPEC-HYP-ATTN)
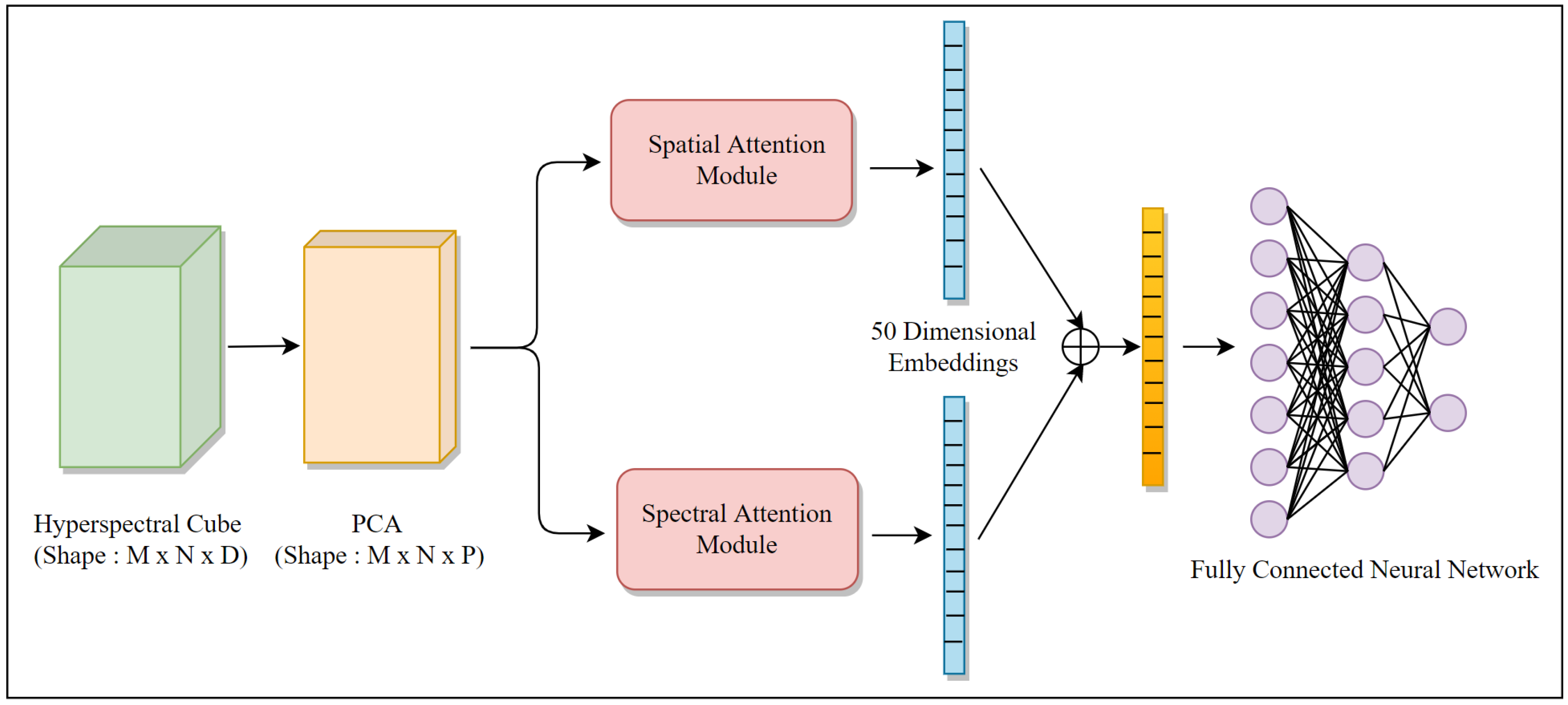
In our proposed methodology, the input high-dimensional hyperspectral cube is dimensionally reduced utilizing principal component analysis (PCA). PCA on raw input data minimizes noise, redundancy in data along the spectral dimension, and makes the process of mapping decision boundaries for classification easier. As a result, the input hyperspectral data cube, with a spatial resolution of
and a temporal resolution/dimension of
D, has been reduced in dimension to
, where
P is the new reduced spectral dimension. Furthermore, the result from PCA is now sent into two parallel attention modules as denoted in
Figure 1, one for spatial attention mechanism and the other for spectral attention mechanism where more informative spatial and spectral features are selectively emphasized and the less useful ones are suppressed respectively for a superior classification efficacy. The architectural details of the spatial and spectral attention modules are as follows.
3.1. Spectral Attention Module
In this module, we propose a 3D-convolution based feature extraction and a bi-directional LSTM based spectral attention methodology to emphasize data along spectral bands that are of greater importance in achieving higher classification accuracy and suppressing information from spectral bands that are of lesser importance. The input to the spectral attention module is of dimension from which 3D windows of data around the image pixel of interest ( in our work) are extracted to preserve closely related dependency between pixels in the windowed spatial area in tandem with the spectrally/temporally constructed features for the purpose of feature engineering with 3D convolutions. As a result, the shape of the modified input for the spectral attention model turns out to be .
This windowed information is now passed on to a 3D convolution layer as an input with 16 kernels of shape
, which is followed immediately by a 3D average pooling layer of size
. The resultant features from this pooling layer are forwarded into a second 3D convolution based feature extraction layer with 32 filters of the shape
, which efficiently extracts local spatial neighborhood information from the input data whilst conserving spectral band correlation. The output from this phase of the feature extraction and attention module is flattened to produce an output of shape
as denoted in
Figure 2.
As explained in Equations (
6)–(
11), this vector of size
was successively passed as an input to a bi-directional LSTM-based spectral attention gating mechanism. This attention gating technique highlights relevant informative pixels while suppressing data from less informative spectral regions. Using forward and backward hidden state implementation of a bi-directional LSTM, where
represents the forward hidden state implementation and
represents the backward hidden state implementation, and their outputs are defined in Equations (
6) and (
7), where the number of hidden units is represented by
h and the number of inputs is denoted by
n; the attention gating mechanism is mathematically represented as follows:
The output of the final hidden state output, defined as
, is obtained as a result of element-wise multiplication between
and
, which is depicted in Equation (
10). The mathematical calculations outlined in Equations (
6), (
7), and (
10) are performed twice before the attention gating mechanism’s final output
is achieved, as illustrated in Equations (
11) and (
12). The notation ⊗ in Equations (
10) and (
12) denotes element-wise multiplication, and ⊕ in Equation (
12) denotes element-wise addition.
For a 50-dimensional feature embedding vector, these produced input data representations are now utilized as an input for a two dense layer based feed forward neural network (FNN) with 100 and 50 nodes in the first and second layer, respectively, with an inclusion of a dropout layer between these two dense layers and has a value of 0.2. The complete proposed spectral feature extraction and bi-directional LSTM-based attention module is denoted in
Figure 2:
3.2. Spatial Attention Module
In this module, we propose a 3D-convolution based spatial attention paradigm which selectively amplifies weightage to specific areas of feature maps through a softmax activation-based gating mechanism which effectively captures the spatial relationship between data pixels in a window, boosting the feature representation capability. In addition, a ResNet-based feature extraction and encoding methodology has been discussed in this work, which effectively extracts spatial information and encodes it into a 50-dimensional vector to achieve superior classification performance.
Firstly, a spatial window of
around every data point is extracted which transforms the input shape of the spatial attention module to
, from
, which was the output shape from the PCA implementation block. Furthermore, this input is forwarded to a 3D-convolution-based feature extraction layer with 1 filter of shape
, which is serially followed by a second 3d-convolution layer with 1 filter of shape
. The choice of the number of convolutional kernels and their shape are astutely made to ensure that the output spectral dimension of the convolution operations precisely matches the spectral dimension of the input data block. These convolution operations are followed by a softmax activation layer which produces an attention map which produces the probabilistic weightage of pixels in the feature map ranging between 0 and 1. Consequently, the spatial attention gating mechanism proposed in our work is clearly described in
Figure 3.
If
is the input to the spatial attention module, then the output of the first and the second 3D-convolution operations are obtained as shown in Equations (
13) and (
14):
where
and
are the outputs of the first and the second 3D-convolution operations, respectively,
and
are the weights of the first and second convolution layer in the defined network, the nonlinear activation function is denoted by
f, while the convolution operator is denoted by ∗. Furthermore, Equations (
15) and (
16) denote the gated weighting spatial attention mechanism implemented in our work where
is the final output. The notation ⊗ denotes element-wise multiplication and ⊕ denotes element-wise addition as seen in Equation (
16):
The resultant output from the 3D-CNN based attention mechanism is produced as an input to a set of three identical and sequential residual blocks for spatial feature extraction. An advantage that residual blocks brings to the table is their ability to solve the vanishing gradient problem when the depth of neural network increases by allowing an alternate path through skip connections for the gradient to flow through. In addition, these skip connections aid in facilitating the underlying neural network framework to learn the identity functions which ensure that the deeper layers in the network perform equally as well as the shallow layers in the network. This proposed 3D-CNN-based attention methodology and ResNet-based feature extraction mechanism is shown in
Figure 3. The three 2D-convolution layers in every residual block are equipped with 32 feature extraction filters of shape
, 64 kernels of shape
and 64 filters with a dimension of
. The features extracted from the residual blocks are now input to FNN for 50-dimensional feature encoding. The number of layers in the FNN used is two, which consists of 100 neurons in the first hidden layer of the FNN and 50 neurons in the second layer of the FNN network.
Finally, the encoded features from both the spatial attention module and spectral attention module and added together element-wise and input to another FNN for classification are depicted in
Figure 1. This FNN based network has two fully connected layers where the first layer has 25 neurons and the second fully connected layer, which is the final layer of the network, consists of
C neurons with an added dropout functionality between the two layers with a dropout value of
.
C here denotes the total number of classes present in the datasets used for assessing the efficacy of our proposed methodology.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}