
Efficient Supervised Image Clustering Based on Density Division and Graph Neural Networks


Abstract
:1. Introduction
- We propose a novel time-efficient and effective GNN-based supervised clustering framework based on density division DDC-GNN. The main phrases are the density division phase, the GNN model inferring phase, and the cluster requiring phase. In GNN model inferring phase, any Plug-and-Play model for image similarity inferring can be applied. In this paper, we have tested GCN-based and GAE-based models.
- To reduce the high computation overhead in existing supervised image clustering algorithms, we present a novel density division method to split the face image instances into high-density parts and low-density parts, where only the low-density parts of the nodes need to perform the connectivity prediction. The density division strategy drastically reduces the computing overhead and unnecessary inferring.
- Extensive experiments are implemented to compare the DDC-GNN framework with other approaches using the MS-Celeb-1M and IJB-B face datasets. The results demonstrate that DDC-GNN is five times quicker than existing approaches with comparable accuracy in a fair comparison.
2. Related Work
2.1. Graph Neural Networks
2.2. Unsupervised Face Clustering
2.3. Supervised Face Clustering
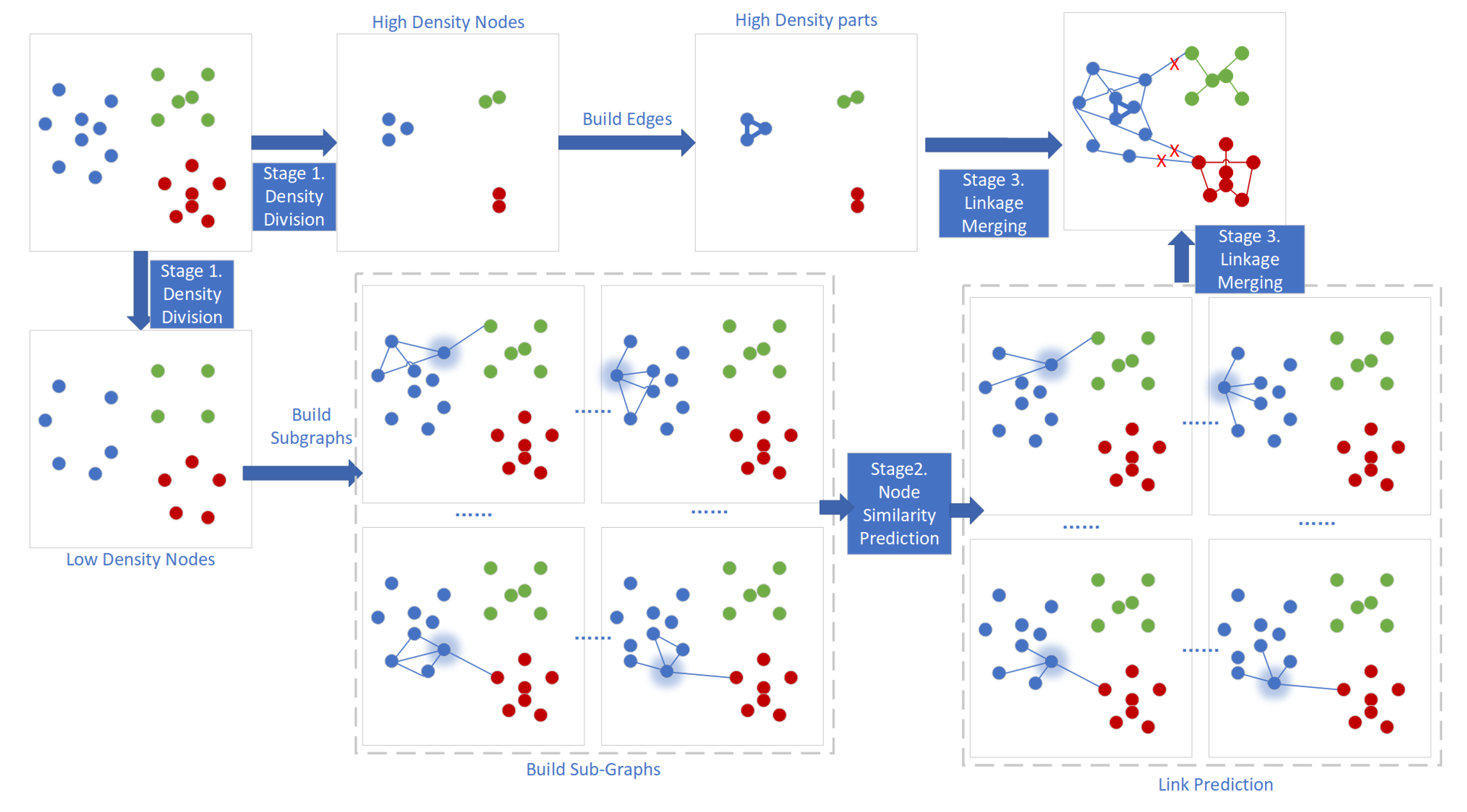
3. Supervised Clustering Based on Density Division
3.1. Overview
3.2. Notations and Descriptions
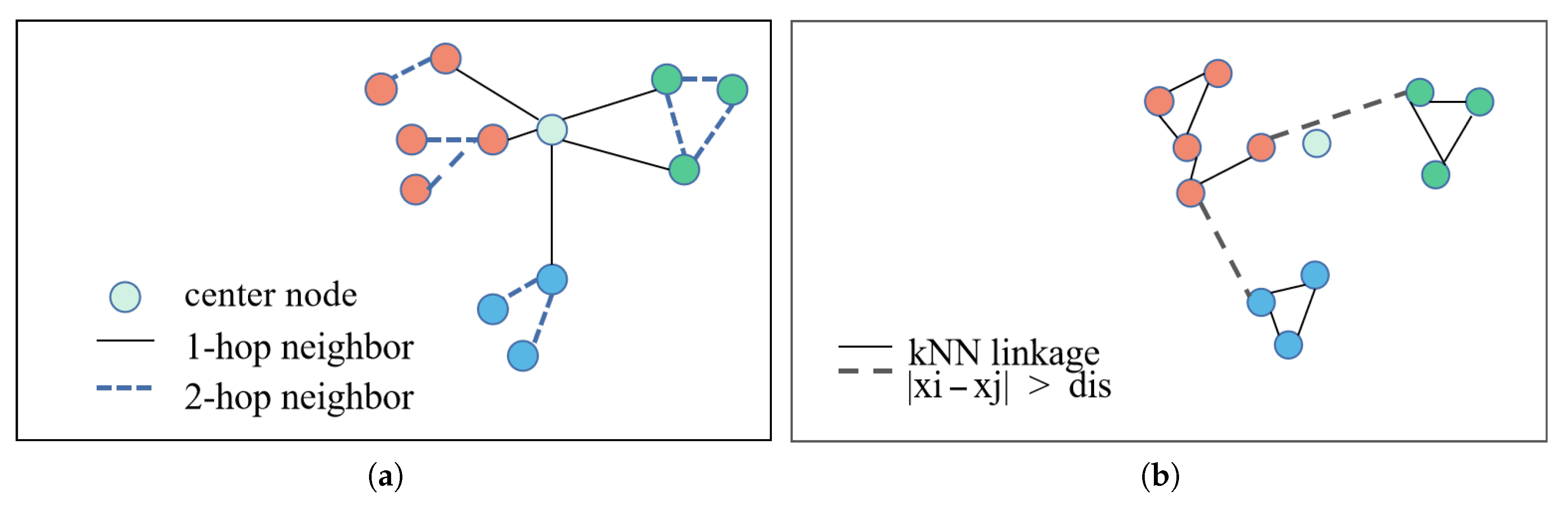
3.3. Connected Region Division
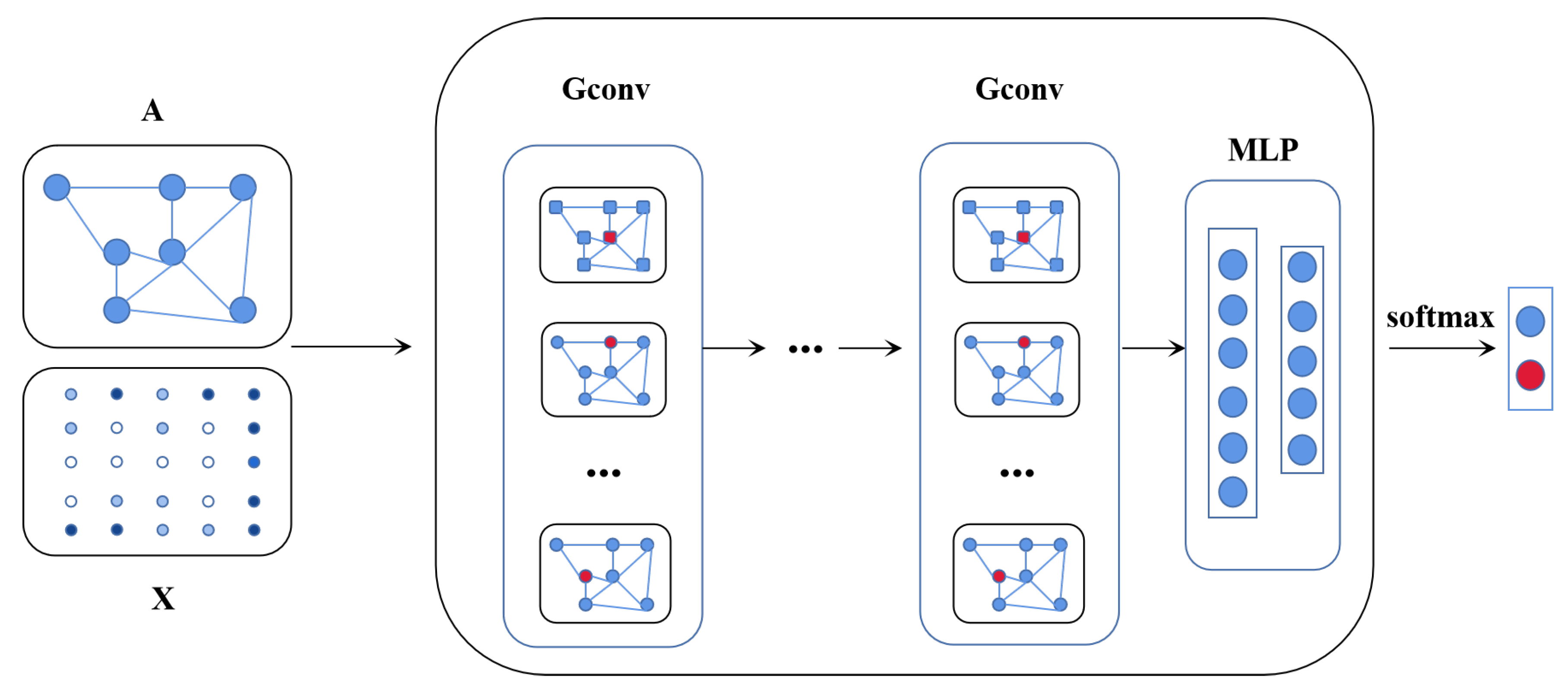
3.4. Node Similarity Prediction of Adaptive Subgraph in GNN
3.4.1. Node Classification Model for Connectivity Prediction
3.4.2. Link Prediction Model for Connectivity Prediction
3.5. Linkage Merging
3.6. Efficiency Analysis
| Algorithm 1: supervised clustering based on density division |
Input: the number of neighbors M, feature set F, distance threshold E, descending density set of all nodes d, Output: Clusters C
|
4. Experiments and Evaluations
4.1. Experiments Setting
4.1.1. Dataset
4.1.2. Metrics
4.1.3. Parameter Setting
4.1.4. Benchmarking
- K-Means [9]: K-Means divides a data set into several clusters according to how far between data instances. The cluster’s sample distances are reduced as much as possible via K-Means.
- Affinity Propagation (AP) [40]: All data points should be treated as potential clustering centers, and the information transmission between the data instances is taken into consideration during clustering, which is appropriate for high-dimensional, multi-class data clustering algorithms.
- DBSCAN [10]: By using appropriate density criteria, DBSCAN maintains the sparse background as noise.
- Approximate Rank-Order Clustering (ARO) [41]: ARO clusters data by an enhanced distance metric and approximative closest neighbor.
- Hierarchical Agglomerative Clustering (HAC) [42]: HAC uses a bottom-up approach, combines clusters, and stops clustering under predetermined rules.
- Spectral Clustering [12]: Spectral Clustering separates the data into several related components based on the similarity matrix between the data.
- Deep Density Clustering (DDC) [28]: DDC is the clustering of local neighborhoods based on their similarity in terms of density in the feature space.
- Consensus-driven Propagation Clustering (CDP) [31]: CDP is a learnable clustering algorithm that uses committee networks to improve robustness.
- L-GCN [2]: L-GCN is a learnable clustering technique that makes use of GCN to extract contextual data from the network for linkage prediction.
- Non-density division-GCN Clustering (NDD-GCN): A method that constructs an adaptive graph for all nodes as context without density division parts, then applies GCN for reasoning on it.
- Density Division Clustering based on GAE (DDC-GAE): A method that constructs an adaptive graph for all nodes as context with density division parts, then applies GAE for reasoning on it.
4.2. Experimental Results
4.2.1. Results and Performance Analysis
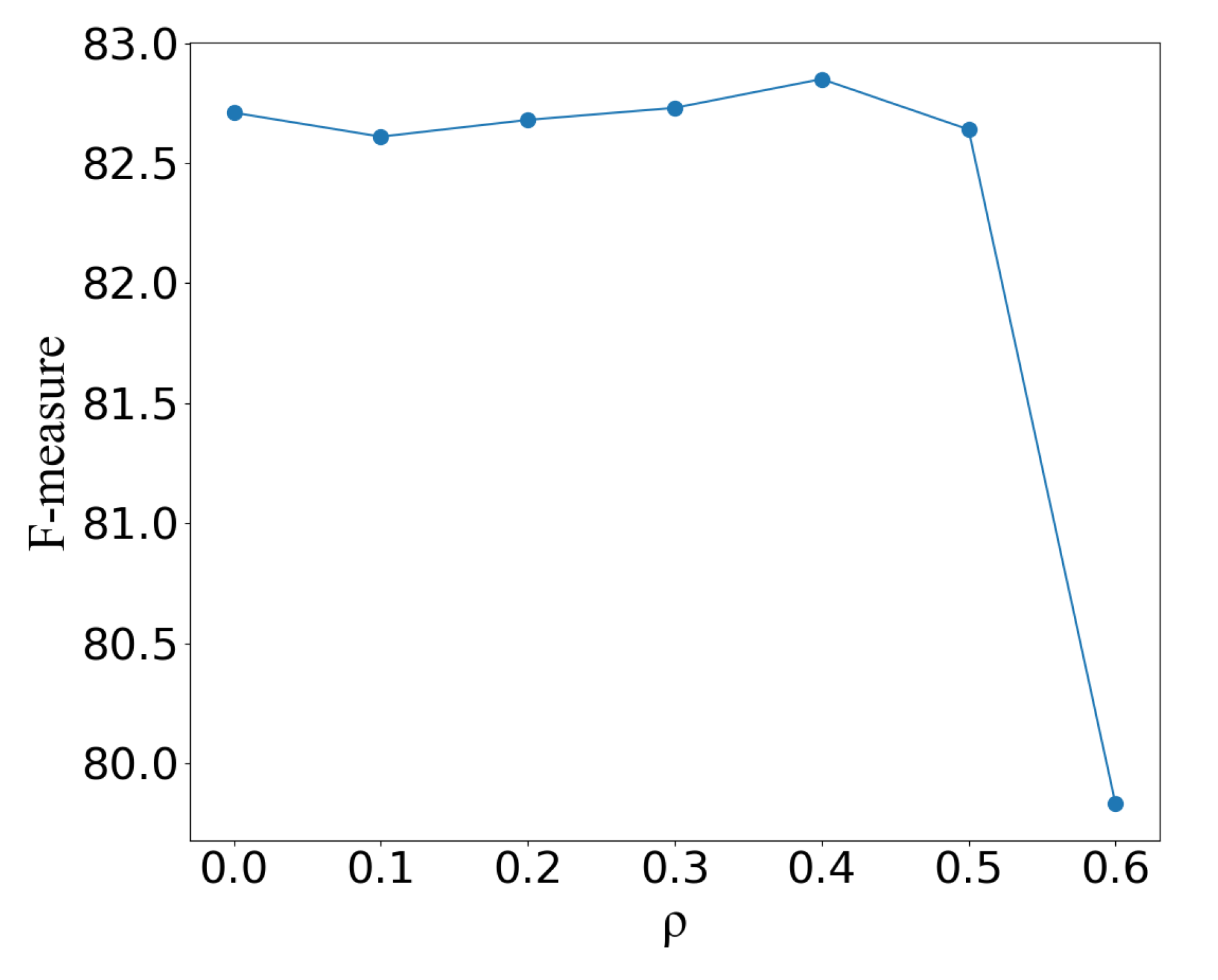
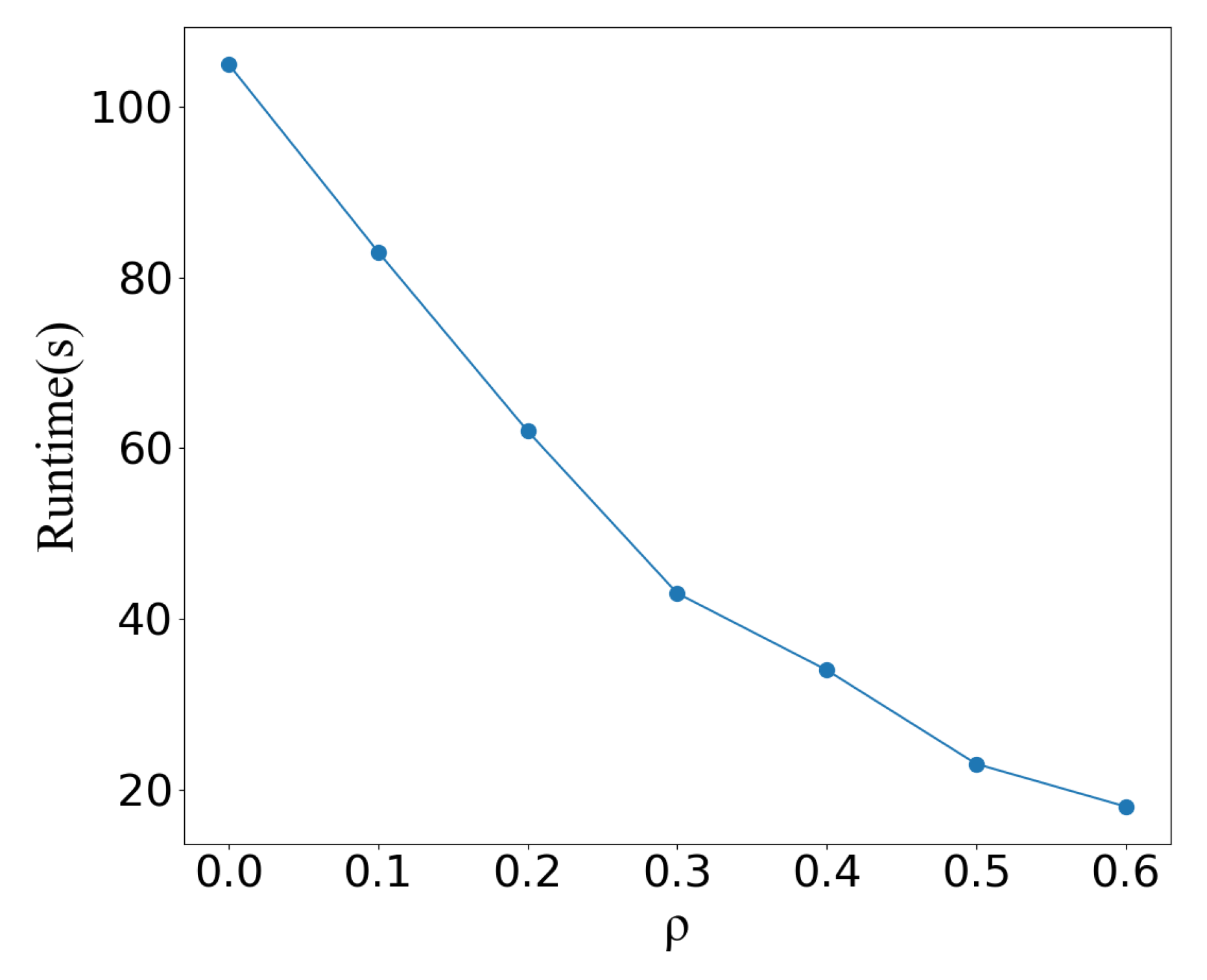
4.2.2. Ablation Study
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, L.; Huang, Q.; Huang, H.; Xu, L.; Lin, D. Learn to propagate reliably on noisy affinity graphs. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 447–464, Part XV 16. [Google Scholar]
- Wang, Z.; Zheng, L.; Li, Y.; Wang, S. Linkage based face clustering via graph convolution network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1117–1125. [Google Scholar]
- Tian, Y.; Liu, W.; Xiao, R.; Wen, F.; Tang, X. A face annotation framework with partial clustering and interactive labeling. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Xue, J.; Qu, S.; Li, J.; Chu, Y.; Wang, Z. TSC-GCN: A Face Clustering Method Based on GCN. In Proceedings of the 15th International Conference on Knowledge Science, Engineering and Management, Singapore, 6–8 August 2022; pp. 260–271. [Google Scholar]
- Li, P.; Zhao, H.; Liu, H. Deep fair clustering for visual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9070–9079. [Google Scholar]
- Guo, S.; Xu, J.; Chen, D.; Zhang, C.; Wang, X.; Zhao, R. Density-aware feature embedding for face clustering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6698–6706. [Google Scholar]
- Siddiqui, A.; Mishra, N.; Verma, J.S. A survey on automatic image annotation and retrieval. Int. J. Comput. Appl. 2015, 118, 27–32. [Google Scholar] [CrossRef]
- Phillips, P.; Flynn, P.; Scruggs, T.; Bowyer, K.; Chang, J.; Hoffman, K.; Marques, J.; Min, J.; Worek, W. Overview of the face recognition grand challenge. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 947–954. [Google Scholar] [CrossRef]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef] [Green Version]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Müllner, D. Modern hierarchical, agglomerative clustering algorithms. arXiv 2011, arXiv:1109.2378. [Google Scholar]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 2019, 6, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Zhan, X.; Chen, D.; Yan, J.; Loy, C.C.; Lin, D. Learning to cluster faces on an affinity graph. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2298–2306. [Google Scholar]
- Yang, H.; Chen, X.; Zhang, F.; Hei, G.; Wang, Y.; Du, R. GCN-Based Linkage Prediction for Face Clustering on Imbalanced Datasets: An Empirical Study. arXiv 2021, arXiv:2107.02477. [Google Scholar]
- Zhao, Q.; Li, L.; Chu, Y.; Wang, Z.; Shan, W. Density Division Face Clustering Based on Graph Convolutional Networks. In Proceedings of the International Conference on Pattern Recognition, Montréal, QC, Canada, 21–25 August 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–7. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Andriyanov, N.; Dementiev, V. Developing and studying the algorithm for segmentation of simple images using detectors based on doubly stochastic random fields. Pattern Recognit. Image Anal. 2019, 29, 1–9. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the European Semantic Web Conference, Monterey, CA, USA, 8–12 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 593–607. [Google Scholar]
- Liu, X.; You, X.; Zhang, X.; Wu, J.; Lv, P. Tensor graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8409–8416. [Google Scholar]
- Kipf, T.; Welling, M. Variational Graph Auto-Encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Advances in Neural Information Processing Systems 30 (NIPS 2017); Curran Associates Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Chu, Y.; Yue, X.; Yu, L.; Sergei, M.; Wang, Z. Automatic image captioning based on ResNet50 and LSTM with soft attention. Wirel. Commun. Mob. Comput. 2020, 2020, 8909458. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef] [Green Version]
- Lin, W.A.; Chen, J.C.; Chellappa, R. A proximity-aware hierarchical clustering of faces. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017; pp. 294–301. [Google Scholar]
- Lin, W.A.; Chen, J.C.; Castillo, C.D.; Chellappa, R. Deep density clustering of unconstrained faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8128–8137. [Google Scholar]
- Zhu, H.; Chen, C.; Liao, L.Z.; Ng, M.K. Multiple graphs clustering by gradient flow method. J. Frankl. Inst. 2018, 355, 1819–1845. [Google Scholar] [CrossRef]
- Tapaswi, M.; Law, M.T.; Fidler, S. Video face clustering with unknown number of clusters. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5027–5036. [Google Scholar]
- Zhan, X.; Liu, Z.; Yan, J.; Lin, D.; Loy, C.C. Consensus-driven propagation in massive unlabeled data for face recognition. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 568–583. [Google Scholar]
- Zhao, X.; Wang, Z.; Gao, L.; Li, Y.; Wang, S. Incremental Face Clustering with Optimal Summary Learning Via Graph Convolutional Network. Tsinghua Sci. Technol. 2021, 26, 536–547. [Google Scholar] [CrossRef]
- Qi, C.; Zhang, J.; Jia, H.; Mao, Q.; Song, H. Deep face clustering using residual graph convolutional network. Knowl.-Based Syst. 2021, 211, 106561. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, L.; Hu, Y.; He, X.; Gao, J. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 87–102. [Google Scholar]
- Whitelam, C.; Taborsky, E.; Blanton, A.; Maze, B.; Adams, J.; Miller, T.; Kalka, N.; Jain, A.K.; Duncan, J.A.; Allen, K.; et al. Iarpa janus benchmark-b face dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 90–98. [Google Scholar]
- Yin, S.; Deng, H.; Xu, Z.; Zhu, Q.; Cheng, J. SD-UNet: A Novel Segmentation Framework for CT Images of Lung Infections. Electronics 2022, 11, 130. [Google Scholar] [CrossRef]
- Wu, Q.; Feng, D.; Cao, C.; Zeng, X.; Feng, Z.; Wu, J.; Huang, Z. Improved Mask R-CNN for Aircraft Detection in Remote Sensing Images. Sensors 2021, 21, 2618. [Google Scholar] [CrossRef]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning face representation from scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Amigó, E.; Gonzalo, J.; Artiles, J.; Verdejo, F. A comparison of extrinsic clustering evaluation metrics based on formal constraints. Inf. Retr. 2009, 12, 461–486. [Google Scholar] [CrossRef] [Green Version]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [Green Version]
- Otto, C.; Wang, D.; Jain, A.K. Clustering millions of faces by identity. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 289–303. [Google Scholar] [CrossRef] [Green Version]
- Sibson, R. SLINK: An optimally efficient algorithm for the single-link cluster method. Comput. J. 1973, 16, 30–34. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Bo, D.; Wang, X.; Shi, C.; Zhu, M.; Lu, E.; Cui, P. Structural Deep Clustering Network. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; ACM: New York, NY, USA, 2020; pp. 1400–1410. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Descriptions |
|---|---|
| V, v | V is a set of nodes in the graph, and v is an instance that belongs to V. |
| A | A is the adjacency matrix of a graph. |
| F | F is the feature set of extracted features from the pre-trained model. |
| C | C is the cluster result. |
| D | D is the dimension of the features. |
| N | N is the number of face images. |
| is a diagonal matrix. | |
| d | d is a set of node density values. |
| W | W is a learnable weight matrix. |
| Z | Z is the hidden layer feature. |
| is the node set of the subgraph. | |
| is the edge set of the subgraph. | |
| is the input subgraph of GNN. | |
| is the feature set of the subgraph which is built for node p. |
| Method | Layers |
|---|---|
| GCN-based | 4 Layers GCN |
| 2 layers MLP | |
| Softmax Activate Function | |
| cross-entropy Loss Function |
| Method | Layers |
|---|---|
| GAE-based | Encoder: 2 Layers GCN |
| Decoder: Inner Product | |
| Sigmoid Activate Function | |
| cross-entropy Loss Function |
| Method | IJB-B-512 | IJB-B-1024 | IJB-B-1845 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F | NMI | ARI | SC(0.166) | Time | F | NMI | ARI | SC(0.170) | Time | F | NMI | ARI | SC(0.194) | Time | |
| K-Means [9] | 0.639 | 0.856 | 0.447 | 0.181 | 175 s | 0.603 | 0.865 | 0.415 | 0.166 | 699 s | 0.600 | 0.868 | 0.340 | 0.164 | 2307 s |
| AP [40] | 0.494 | 0.854 | - | - | - | 0.484 | 0.864 | - | - | - | 0.477 | 0.869 | - | - | - |
| DBSCAN [10] | 0.768 | 0.904 | 0.776 | 0.187 | 11 s | 0.765 | 0.877 | 0.152 | 0.141 | 42 s | 0.737 | 0.851 | 0.065 | 0.116 | 150 s |
| Spectral Clustering [43] | 0.538 | 0.774 | 0.177 | 0.143 | 285 s | 0.522 | 0.780 | 0.126 | 0.133 | 1692 s | 0.551 | 0.840 | 0.296 | 0.136 | 3252 s |
| ARO [41] | 0.685 | 0.887 | 0.747 | 0.077 | 267 s | 0.599 | 0.880 | 0.634 | 0.063 | 551 s | 0.523 | 0.874 | 0.448 | 0.055 | 1062 s |
| SDCN [44] | 0.474 | 0.836 | - | - | - | 0.452 | 0.830 | - | - | - | - | - | - | - | - |
| DDC [28] | 0.802 | 0.921 | - | - | - | 0.805 | 0.926 | - | - | - | 0.800 | 0.929 | - | - | - |
| L-GCN [2] | 0.821 | 0.920 | 0.826 | 0.206 | 108 s | 0.819 | 0.928 | 0.846 | 0.110 | 198 s | 0.810 | 0.926 | 0.676 | 0.187 | 362 s |
| NDD-GCN | 0.826 | 0.926 | 0.830 | 0.209 | 97 s | 0.819 | 0.931 | 0.846 | 0.111 | 192 s | 0.812 | 0.930 | 0.676 | 0.181 | 350 s |
| DDC-GAE | 0.823 | 0.906 | 0.829 | 0.226 | 46 s | 0.817 | 0.933 | 0.829 | 0.108 | 70 s | 0.809 | 0.919 | 0.675 | 0.167 | 98 s |
| DDC-GCN | 0.829 | 0.917 | 0.833 | 0.207 | 32 s | 0.822 | 0.935 | 0.848 | 0.118 | 51 s | 0.816 | 0.931 | 0.677 | 0.175 | 75 s |
| Methods | Precision | Recall | F-Score | NMI | Time |
|---|---|---|---|---|---|
| K-Means [9] | 52.52 | 70.45 | 60.18 | 94.56 | 13 h |
| DBSCAN [10] | 72.88 | 42.46 | 53.50 | 92.31 | 100 s |
| HAC [42] | 66.84 | 70.01 | 68.39 | 92.92 | 18 h |
| ARO [41] | 81.10 | 7.30 | 13.34 | 84.68 | 250 s |
| CDP [31] | 80.19 | 70.47 | 75.01 | 94.69 | 350 s |
| L-GCN [2] | 84.40 | 72.36 | 78.86 | 94.76 | 2500 s |
| NDD-GCN | 87.24 | 74.98 | 80.65 | 95.47 | 2042 s |
| DDC-GAE | 82.76 | 79.96 | 80.85 | 95.49 | 650 s |
| DDC-GCN | 84.78 | 77.56 | 80.95 | 95.53 | 420 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Q.; Li, L.; Chu, Y.; Yang, Z.; Wang, Z.; Shan, W. Efficient Supervised Image Clustering Based on Density Division and Graph Neural Networks. Remote Sens. 2022, 14, 3768. https://doi.org/10.3390/rs14153768
Zhao Q, Li L, Chu Y, Yang Z, Wang Z, Shan W. Efficient Supervised Image Clustering Based on Density Division and Graph Neural Networks. Remote Sensing. 2022; 14(15):3768. https://doi.org/10.3390/rs14153768
Chicago/Turabian StyleZhao, Qingchao, Long Li, Yan Chu, Zhen Yang, Zhengkui Wang, and Wen Shan. 2022. "Efficient Supervised Image Clustering Based on Density Division and Graph Neural Networks" Remote Sensing 14, no. 15: 3768. https://doi.org/10.3390/rs14153768