
Multi-Scale Object Detection with the Pixel Attention Mechanism in a Complex Background




Abstract
:1. Introduction
- A bidirectional multi-scale feature fusion network was built for high-precision multi-scale object detection in remote sensing images. It is the first work that we are aware of that achieves high-precision object detection in complex backgrounds.
- The multi-feature selection module (MFSM) based on the attention mechanism is designed to reduce the influence of useless features in feature maps in complex backgrounds with a lot of noise.
- We propose a novel remote sensing image object detection algorithm that includes a bidirectional multi-scale feature fusion network and a multi-feature selection module. With extensive ablation experiments, we validate the effectiveness of our approach on the standard DOTA dataset and a customized dataset named DOTA-GF. Our proposed method achieves a mAP of 65.1% with the ResNet50 backbone in the DOTA dataset, and 64.1% with the ResNet50 backbone in the DOTA-GF dataset when compared to state-of-the-art methods.
2. Related Work
2.1. Object Detection Algorithms Based on Deep Learning
2.2. Arbitrary-Oriented Object Detection
3. The Proposed Algorithm
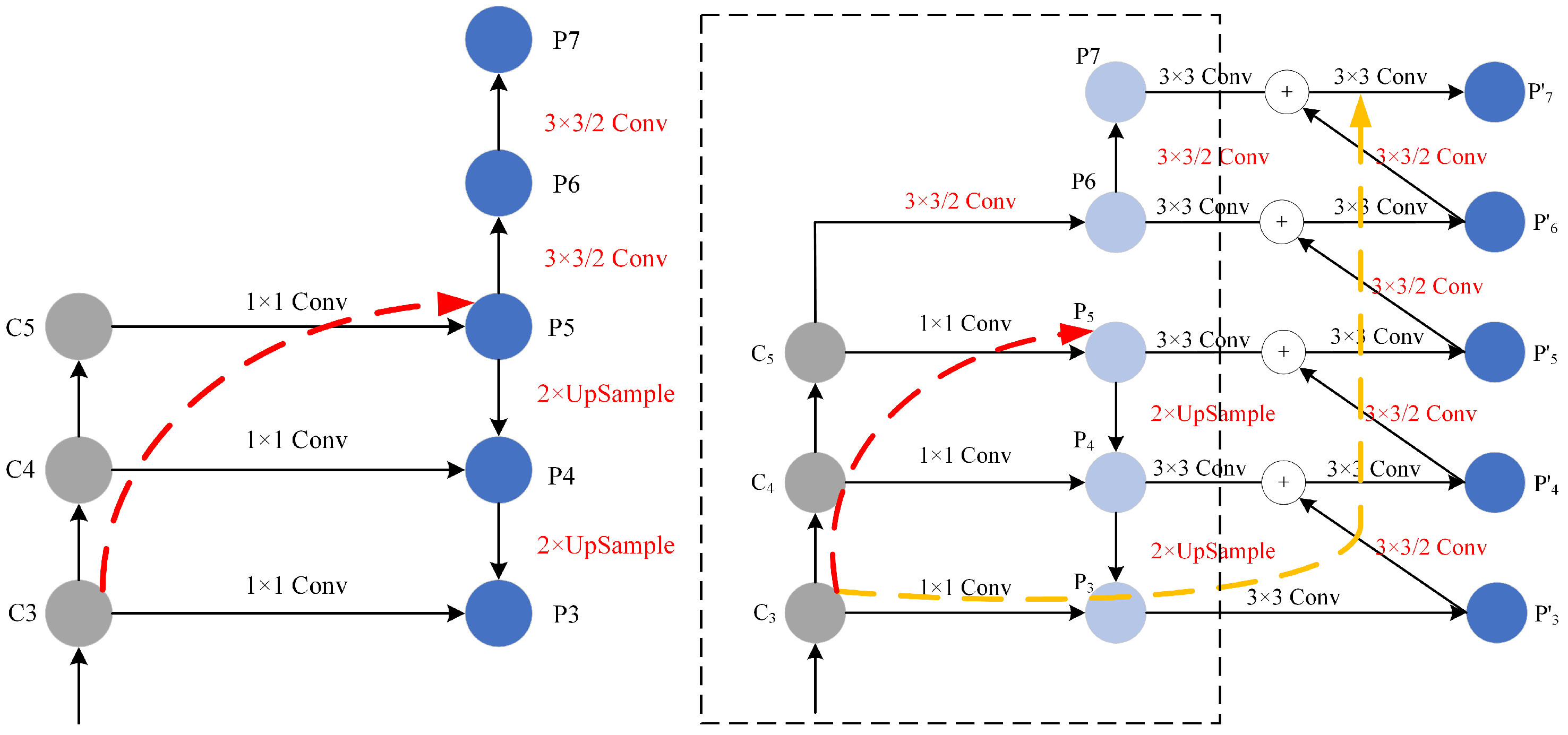
3.1. Bidirectional Multi-Scale Feature Fusion Network
3.2. Multi-Feature Selection Module Based on Attention Mechanism
3.3. Accurate Acquisition of Target Direction Based on Angle Classification
3.4. Loss Function
4. Experimental Results and Discussion
4.1. Ablation Studies
4.1.1. Bidirectional Multi-Scale Feature Fusion Network
4.1.2. Multi-Feature Selection Module Based on Attention Mechanism
4.1.3. Accurate Acquisition of Target Direction Based on Angle Classification
4.2. Results on DOTA
4.3. Results on DOTA-GF
4.4. Results of HRSC 2016
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Fatima, S.A.; Kumar, A.; Pratap, A.; Raoof, S.S. Object Recognition and Detection in Remote Sensing Images: A Comparative Study. In Proceedings of the 2020 International Conference on Artificial Intelligence and Signal Processing, AISP 2020, Amaravati, India, 10–12 January 2020. [Google Scholar]
- Ma, R.; Chen, C.; Yang, B.; Li, D.; Wang, H.; Cong, Y.; Hu, Z. CG-SSD: Corner guided single stage 3D object detection from LiDAR point cloud. ISPRS J. Photogramm. Remote Sens. 2022, 191, 33–48. [Google Scholar] [CrossRef]
- Hu, Z.; Chen, C.; Yang, B.; Wang, Z.; Ma, R.; Wu, W.; Sun, W. Geometric feature enhanced line segment extraction from large-scale point clouds with hierarchical topological optimization. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102858. [Google Scholar] [CrossRef]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Liu, X.; Meng, G.; Pan, C.A. Scene text detection and recognition with advances in deep learning: A survey. Int. J. Doc. Anal. Recognit. (IJDAR) 2019, 22, 143–162. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Image-to-image translation with conditional adversarial networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. AUGFPN: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12592–12601. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. NAS-FPN: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7029–7038. [Google Scholar]
- Xiao, J.; Zhang, S.; Dai, Y.; Jiang, Z.; Yi, B.; Xu, C. Multiclass Object Detection in UAV Images Based on Rotation Region Network. IEEE J. Miniaturization Air Space Syst. 2020, 1, 188–196. [Google Scholar] [CrossRef]
- Yang, X.; Liu, Q.; Yan, J.; Li, A. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8231–8240. [Google Scholar]
- Zhang, Y.; Xiao, J.; Jinye, P.; Ding, Y.; Liu, J.; Guo, Z.; Xiaopeng, Z. Kernel Wiener Filtering Model with Low-Rank Approximation for Image Denoising. Inf. Sci. 2018, 462, 402–416. [Google Scholar] [CrossRef]
- Li, Q.; Mou, L.M.; Jiang, K.; Liu, Q.; Wang, Y.; Zhu, X. Hierarchical Region Based Convolution Neural Network for Multi-scale Object Detection in Remote Sensing Images. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4355–4358. [Google Scholar]
- Xie, H.; Wang, T.; Qiao, M.; Zhang, M.; Shan, G.; Snoussi, H. Robust object detection for tiny and dense targets in VHR aerial images. In Proceedings of the 2017 Chinese Automation Congress, Jinan, China, 20–22 October 2017; pp. 6397–6401. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Wang, J.; Li, K.; Xie, X.; Lang, C.; Yao, Y.; Han, J. Anchor-Free Oriented Proposal Generator for Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6450–6458. [Google Scholar]
- Hang, R.; Li, Z.; Liu, Q.; Ghamisi, P.; Bhattacharyya, S.S. Hyperspectral Image Classification With Attention-Aided CNNs. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2281–2293. [Google Scholar] [CrossRef]
- Zhong, Z.; Lin, Z.Q.; Bidart, R.; Hu, X.; Daya, I.B.; Li, Z.; Zheng, W.S.; Li, J.; Wong, A. Squeeze-and-attention networks for semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13062–13071. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Arbitrary-Oriented Object Detection with Circular Smooth Label. Yang Xue Yan Junchi 2020, 12353, 677–694. [Google Scholar]
- Yang, X.; Hou, L.; Zhou, Y.; Wang, W.; Yan, J. Dense Label Encoding for Boundary Discontinuity Free Rotation Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; pp. 15819–15829. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Pang, J.; Li, C.; Shi, J.; Xu, Z.; Feng, H. R2-CNN: Fast Tiny Object Detection in Large-Scale Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5512–5524. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AP (%) | mAP (%) | |||||
|---|---|---|---|---|---|---|---|
| PL | SH | BG | SV | LV | ST | ||
| FPN | 83.4 | 62.2 | 32.3 | 65.7 | 48.3 | 74.9 | 61.1 |
| our-FPN | |||||||
| Method | AP (%) | mAP (%) | |||||
|---|---|---|---|---|---|---|---|
| PL | SH | BG | SV | LV | ST | ||
| Baseline | 83.4 | 62.2 | 32.3 | 65.7 | 48.3 | 74.9 | 61.1 |
| SE | 83.6 | 64.3 | 33.4 | 66.1 | 74.1 | 61.9 | |
| CBAM | 84.4 | 67.0 | 49.1 | 75.2 | 62.3 | ||
| MFSM | 63.4 | 33.6 | 49.5 | ||||
| Method | AP (%) | mAP (%) | |||||
|---|---|---|---|---|---|---|---|
| PL | SH | BG | SV | LV | ST | ||
| Regression | 83.4 | 62.2 | 32.3 | 65.7 | 48.3 | 74.9 | 61.1 |
| Classification | |||||||
| Category | CSL | RRPN | RetinaNet | Xiao | Proposed |
|---|---|---|---|---|---|
| PL | 84.2 | 83.9 | 83.4 | 78 | |
| SH | 64.9 | 47.2 | 62.2 | 65 | |
| BG | 34.5 | 32.3 | 32.3 | 38 | |
| LV | 51.5 | 49.7 | 48.3 | 59 | 54.2 |
| SV | 67.6 | 34.7 | 65.7 | 37 | |
| ST | 75.8 | 48.8 | 74.9 | 50 | |
| mAP (%) | 63.1 | 48.0 | 61.1 | 55 |
| Category | CSL | RRPN | RetinaNet | R3Det | Proposed |
|---|---|---|---|---|---|
| PL | 83.6 | 81.7 | 83.2 | 84.6 | |
| SH | 64.1 | 46.8 | 61.0 | 66.1 | |
| BG | 35.3 | 34.8 | 32.5 | 35.5 | |
| LV | 50.4 | 48.2 | 50.2 | 53.8 | |
| SV | 64.7 | 33.8 | 64.5 | 59.8 | |
| ST | 72.9 | 48.6 | 72.7 | 70.5 | |
| mAP(%) | 56.5 | 49.0 | 60.7 | 63.1 |
| Methods | Size | mAP (%) |
|---|---|---|
| R2CNN | 800 × 800 | 73.7 |
| RRPN | 800 × 800 | 79.1 |
| RetinaNet | 800 × 800 | 81.7 |
| RoI transformer | 512 × 800 | 86.2 |
| Proposed | 800 × 800 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, J.; Guo, H.; Yao, Y.; Zhang, S.; Zhou, J.; Jiang, Z. Multi-Scale Object Detection with the Pixel Attention Mechanism in a Complex Background. Remote Sens. 2022, 14, 3969. https://doi.org/10.3390/rs14163969
Xiao J, Guo H, Yao Y, Zhang S, Zhou J, Jiang Z. Multi-Scale Object Detection with the Pixel Attention Mechanism in a Complex Background. Remote Sensing. 2022; 14(16):3969. https://doi.org/10.3390/rs14163969
Chicago/Turabian StyleXiao, Jinsheng, Haowen Guo, Yuntao Yao, Shuhao Zhang, Jian Zhou, and Zhijun Jiang. 2022. "Multi-Scale Object Detection with the Pixel Attention Mechanism in a Complex Background" Remote Sensing 14, no. 16: 3969. https://doi.org/10.3390/rs14163969
APA StyleXiao, J., Guo, H., Yao, Y., Zhang, S., Zhou, J., & Jiang, Z. (2022). Multi-Scale Object Detection with the Pixel Attention Mechanism in a Complex Background. Remote Sensing, 14(16), 3969. https://doi.org/10.3390/rs14163969