
Identifying Urban Functional Regions from High-Resolution Satellite Images Using a Context-Aware Segmentation Network




Abstract
:1. Introduction
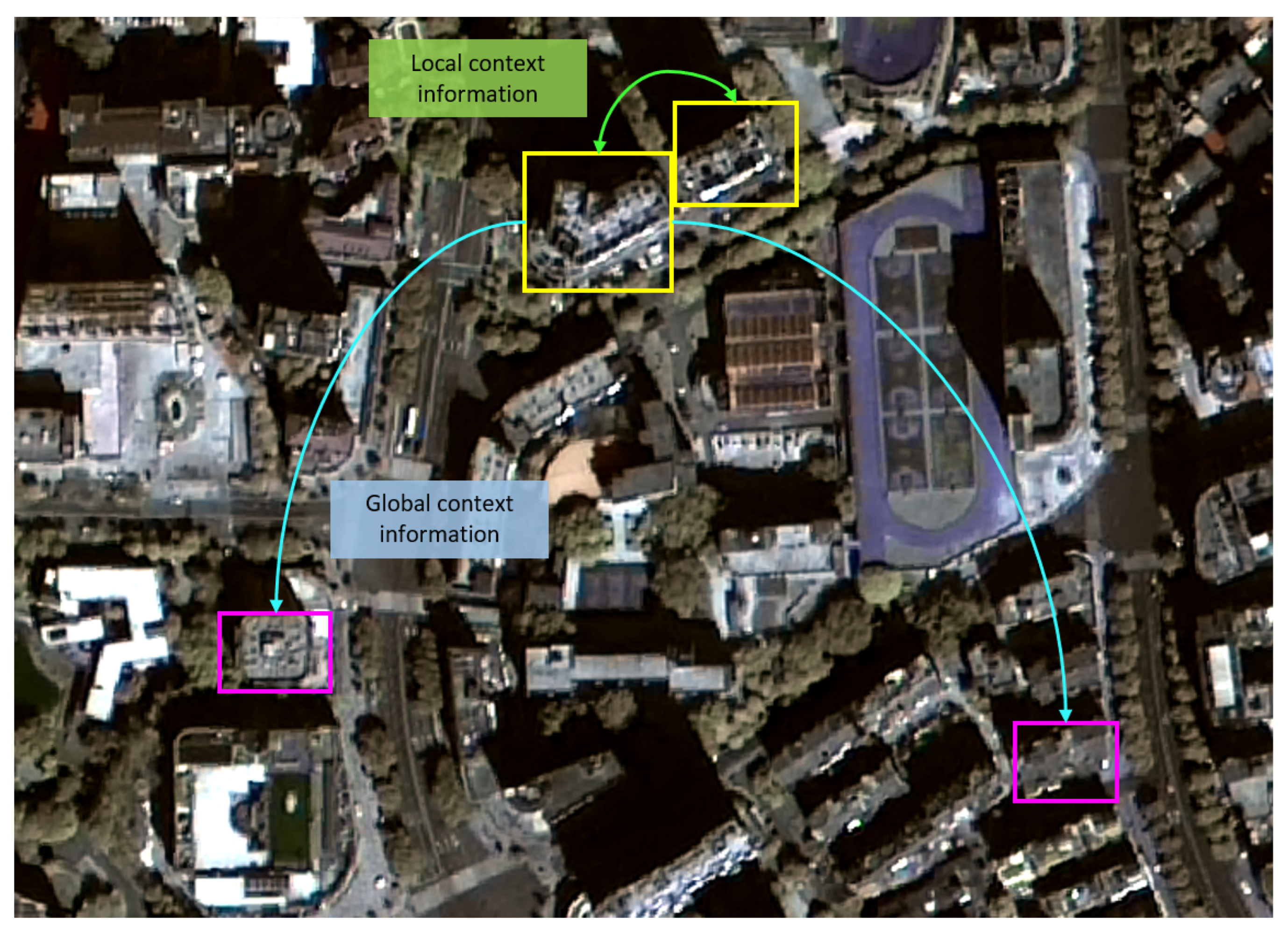
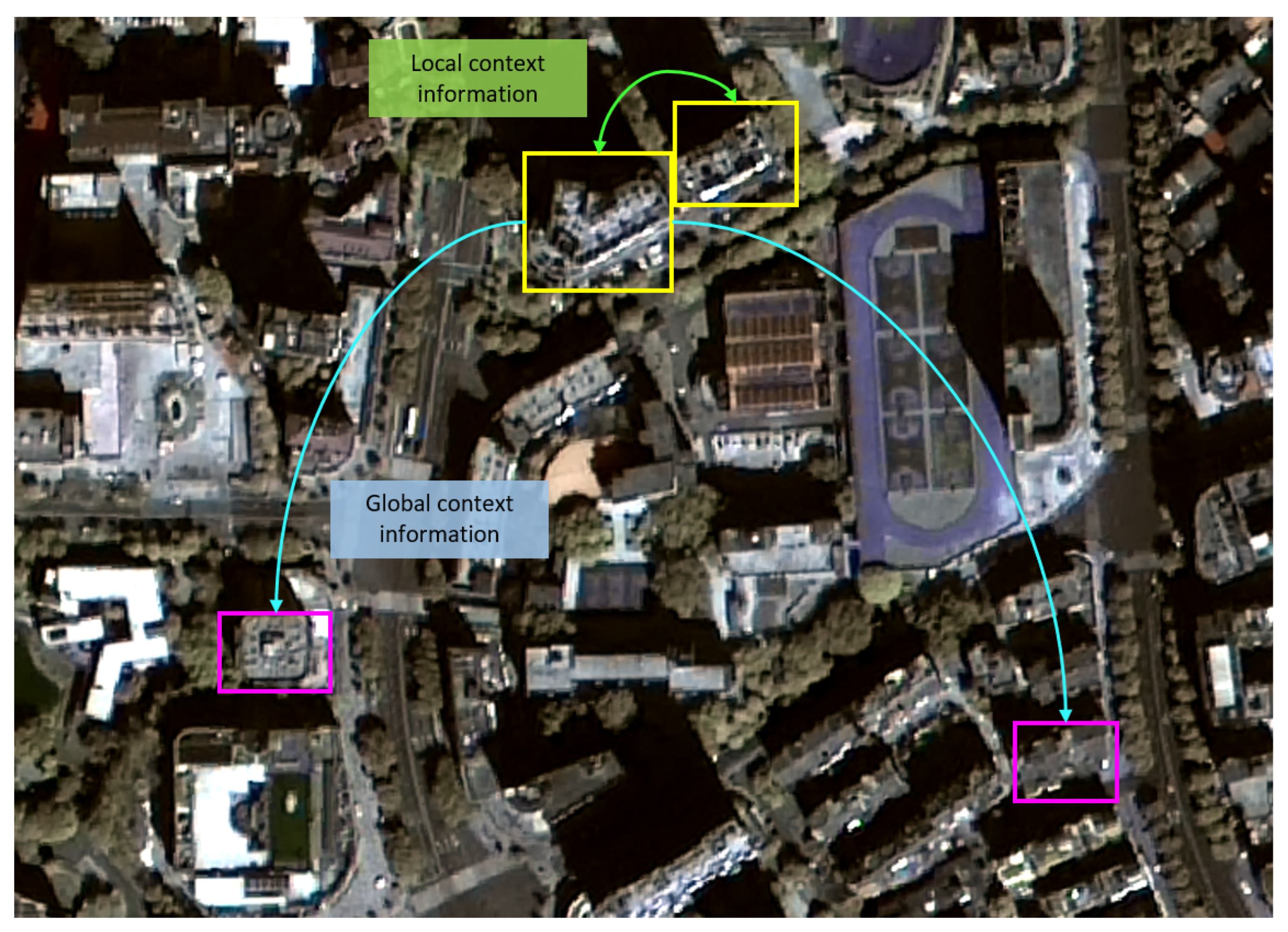
- Developing an efficient context-aware building and road segmentation network based upon a high-resolution feature conserving network and a region context module (RCM) for feature extraction. In addition, an affinity loss derived from the Region Affinity Map (RAM) is used to promote the network’s training.
- Presenting an end-to-end method for directly extracting urban function regions using high-resolution satellite images, based upon image-derived functional units (i.e., road blocks) and multi-scale building features.
2. Study Area and Dataset
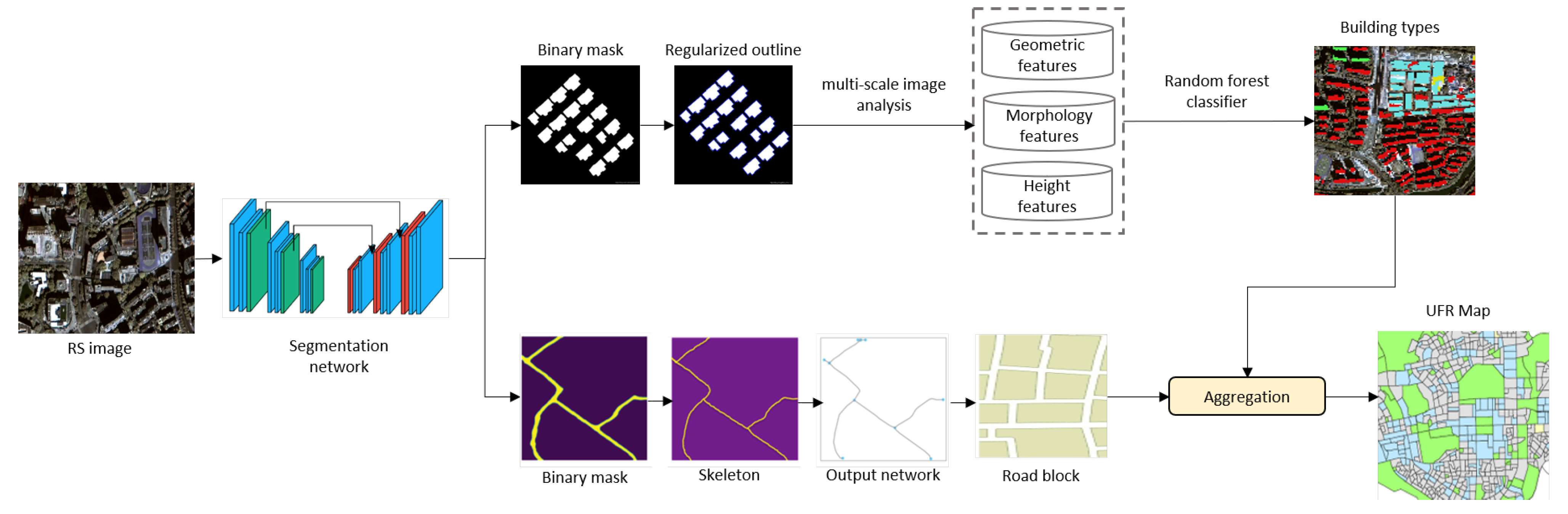
3. Methods
3.1. Building and Road Extraction
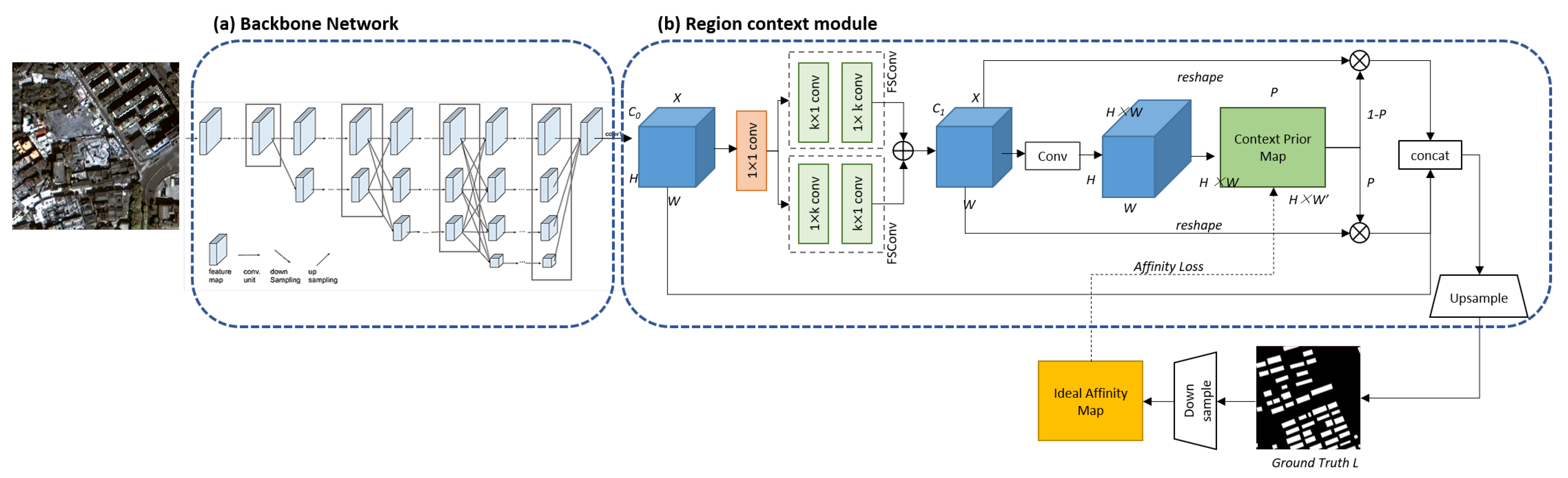
3.1.1. Semantic Segmentation Network for Building and Road Extraction
- a.
- Overall architecture
- b.
- Region context module
- c.
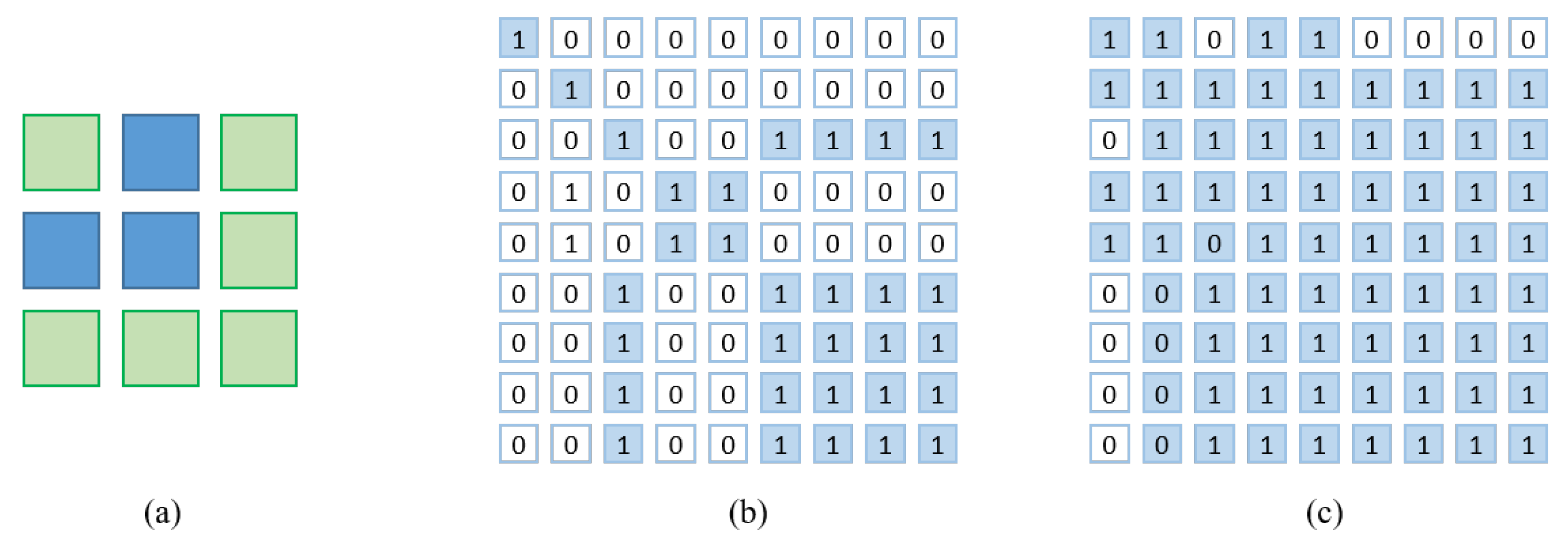
- Affinity loss
3.1.2. Post Processing
3.2. Building Types Classification and Urban Function Region Identification
3.2.1. Building Feature Extraction
3.2.2. Building Type Classification
3.2.3. Urban Function Region Identification
3.3. Evaluation Metrics
3.4. Implementation Details
4. Experiments and Results
4.1. Building and Road Extraction Results
4.1.1. Ablation Studies on Network Design
4.1.2. Comparison with Other Methods
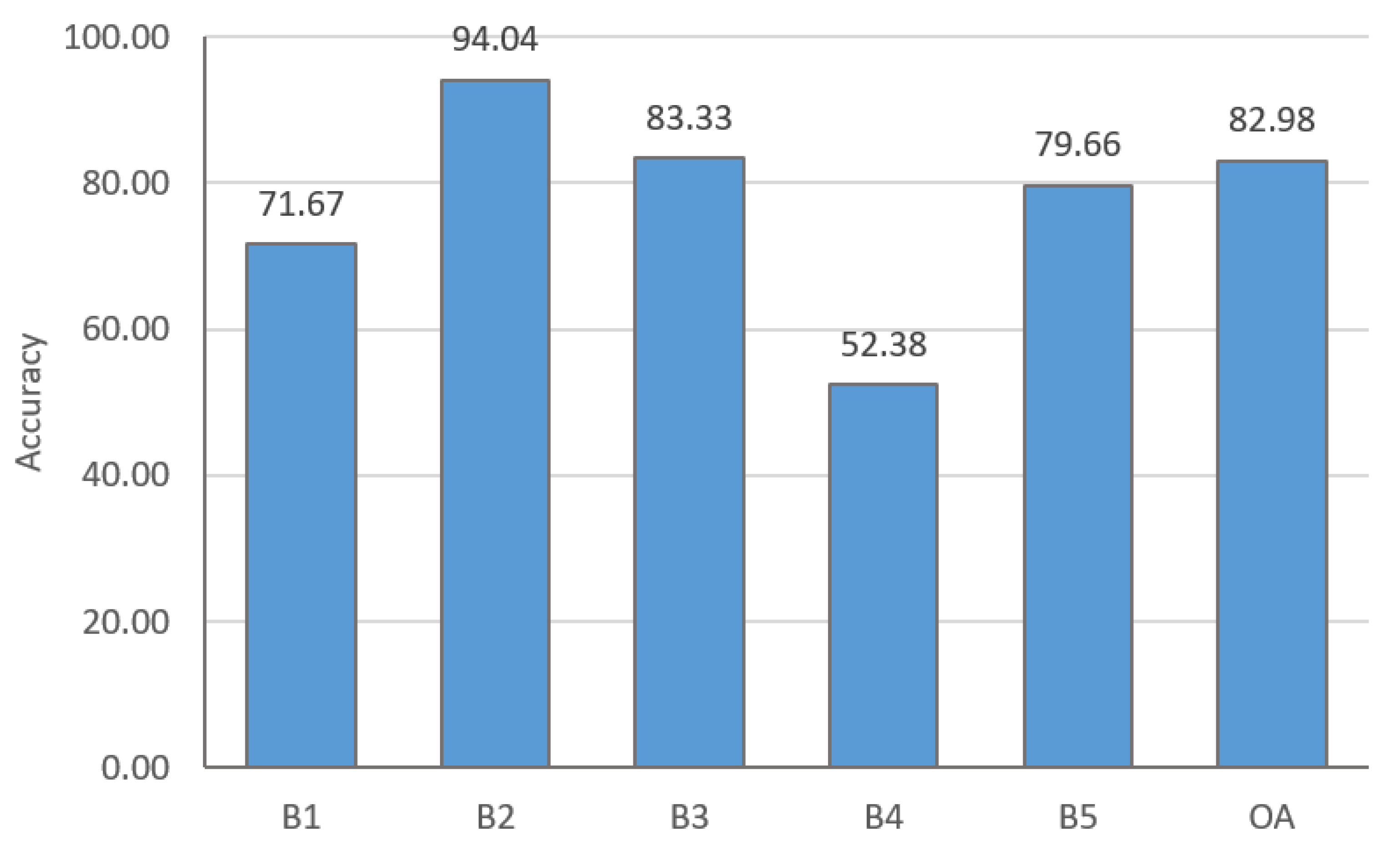
4.2. Building Types Classification Results
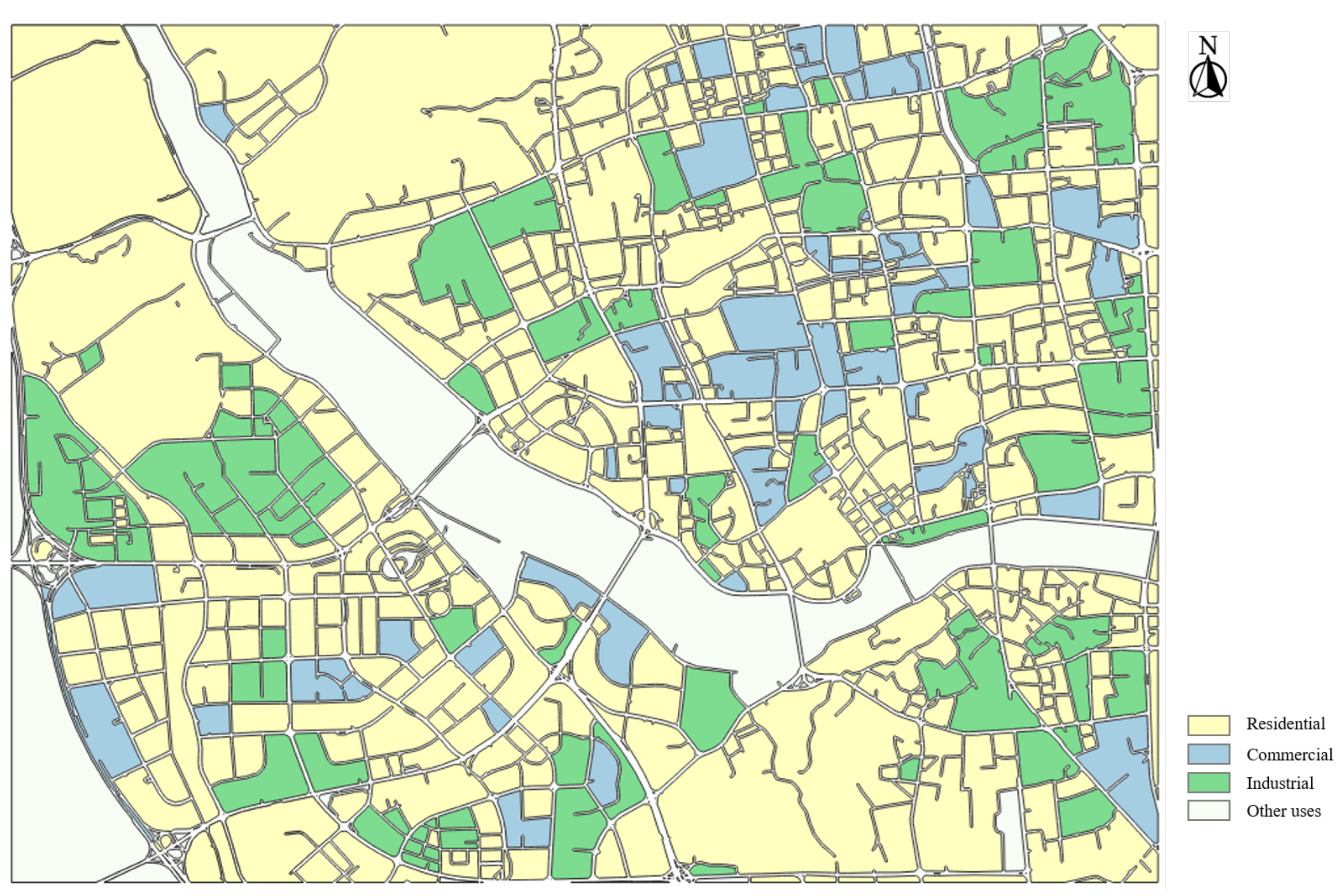
4.3. Urban Functional Region Classification Results
5. Discussion on the workflow and analysis unit
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, M.; Stein, A. Mapping land use from high resolution satellite images by exploiting the spatial arrangement of land cover objects. Remote Sens. 2020, 12, 4158. [Google Scholar] [CrossRef]
- Li, M.; Stein, A.; Bijker, W.; Zhan, Q. Urban land use extraction from Very High Resolution remote sensing imagery using a Bayesian network. ISPRS J. Photogramm. Remote Sens. 2016, 122, 192–205. [Google Scholar] [CrossRef]
- Zhou, W.; Ming, D.; Lv, X.; Zhou, K.; Bao, H.; Hong, Z. SO–CNN based urban functional zone fine division with VHR remote sensing image. Remote Sens. Environ. 2020, 236, 111458. [Google Scholar] [CrossRef]
- Li, M.; Stein, A.; De Beurs, K.M. A Bayesian characterization of urban land use configurations from VHR remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2020, 92, 102175. [Google Scholar] [CrossRef]
- Yang, M.; Kong, B.; Dang, R.; Yan, X. Classifying urban functional regions by integrating buildings and points-of-interest using a stacking ensemble method. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102753. [Google Scholar] [CrossRef]
- Liu, X.; Jiao, P.; Yuan, N.; Wang, W. Identification of multi-attribute functional urban areas under a perspective of community detection: A case study. Phys. A Stat. Mech. Its Appl. 2016, 462, 827–836. [Google Scholar] [CrossRef]
- Wu, C.; Smith, D.; Wang, M. Simulating the urban spatial structure with spatial interaction: A case study of urban polycentricity under different scenarios. Comput. Environ. Urban Syst. 2021, 89, 101677. [Google Scholar] [CrossRef]
- Dubrova, S.V.; Podlipskiy, I.I.; Kurilenko, V.V.; Siabato, W. Functional city zoning. Environmental assessment of eco-geological substance migration flows. Environ. Pollut. 2015, 197, 165–172. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S.; Wang, Q. Hierarchical semantic cognition for urban functional zones with VHR satellite images and POI data. ISPRS J. Photogramm. Remote Sens. 2017, 132, 170–184. [Google Scholar] [CrossRef]
- Song, J.; Lin, T.; Li, X.; Prishchepov, A.V. Mapping urban functional zones by integrating very high spatial resolution remote sensing imagery and points of interest: A case study of Xiamen, China. Remote Sens. 2018, 10, 1737. [Google Scholar] [CrossRef]
- Feng, Y.; Huang, Z.; Wang, Y.; Wan, L.; Liu, Y.; Zhang, Y.; Shan, X. An SOE-Based Learning Framework Using Multisource Big Data for Identifying Urban Functional Zones. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7336–7348. [Google Scholar] [CrossRef]
- NYC.gov. The Official Website of the City of New York. Available online: https://www1.nyc.gov/assets/finance/jump/hlpbldgcode.html (accessed on 20 July 2022).
- Li, M.; Bijker, W.; Stein, A. Use of binary partition tree and energy minimization for object-based classification of urban land cover. ISPRS J. Photogramm. Remote Sens. 2015, 102, 48–61. [Google Scholar] [CrossRef]
- Li, M.; De Beurs, K.M.; Stein, A.; Bijker, W. Incorporating open source data for Bayesian classification of urban land use from VHR stereo images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4930–4943. [Google Scholar] [CrossRef]
- Zhao, W.; Persello, C.; Stein, A. Building outline delineation: From aerial images to polygons with an improved end-to-end learning framework. ISPRS J. Photogramm. Remote Sens. 2021, 175, 119–131. [Google Scholar] [CrossRef]
- Zhao, W.; Persello, C.; Stein, A. Extracting planar roof structures from very high resolution images using graph neural networks. ISPRS J. Photogramm. Remote Sens. 2022, 187, 34–45. [Google Scholar] [CrossRef]
- Chen, X.; Jiang, K.; Zhu, Y.; Wang, X.; Yun, T. Individual tree crown segmentation directly from UAV-borne LiDAR data using the PointNet of deep learning. Forests 2021, 12, 131. [Google Scholar] [CrossRef]
- Sun, C.; Huang, C.; Zhang, H.; Chen, B.; An, F.; Wang, L.; Yun, T. Individual Tree Crown Segmentation and Crown Width Extraction From a Heightmap Derived From Aerial Laser Scanning Data Using a Deep Learning Framework. Front. Plant Sci. 2022, 13, 914974. [Google Scholar] [CrossRef]
- Xu, S.; Li, X.; Yun, J.; Xu, S. An Effectively Dynamic Path Optimization Approach for the Tree Skeleton Extraction from Portable Laser Scanning Point Clouds. Remote Sens. 2021, 14, 94. [Google Scholar] [CrossRef]
- Xu, S.; Zhou, K.; Sun, Y.; Yun, T. Separation of wood and foliage for trees from ground point clouds using a novel least-cost path model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6414–6425. [Google Scholar] [CrossRef]
- Li, S.; Hu, G.; Cheng, X.; Xiong, L.; Tang, G.; Strobl, J. Integrating topographic knowledge into deep learning for the void-filling of digital elevation models. Remote Sens. Environ. 2022, 269, 112818. [Google Scholar] [CrossRef]
- Xu, S.; Zhou, X.; Ye, W.; Ye, Q. Classification of 3D Point Clouds by a New Augmentation Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7003405. [Google Scholar] [CrossRef]
- Cao, R.; Tu, W.; Yang, C.; Li, Q.; Liu, J.; Zhu, J.; Zhang, Q.; Li, Q.; Qiu, G. Deep learning-based remote and social sensing data fusion for urban region function recognition. ISPRS J. Photogramm. Remote Sens. 2020, 163, 82–97. [Google Scholar] [CrossRef]
- Lu, W.; Tao, C.; Li, H.; Qi, J.; Li, Y. A unified deep learning framework for urban functional zone extraction based on multi-source heterogeneous data. Remote Sens. Environ. 2022, 270, 112830. [Google Scholar] [CrossRef]
- Du, S.; Du, S.; Liu, B.; Zhang, X. Mapping large-scale and fine-grained urban functional zones from VHR images using a multi-scale semantic segmentation network and object based approach. Remote Sens. Environ. 2021, 261, 112480. [Google Scholar] [CrossRef]
- Wang, J.; Luo, H.; Li, W.; Huang, B. Building Function Mapping Using Multisource Geospatial Big Data: A Case Study in Shenzhen, China. Remote Sens. 2021, 13, 4751. [Google Scholar] [CrossRef]
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3146–3154. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 173–190. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y. JointNet: A common neural network for road and building extraction. Remote Sens. 2019, 11, 696. [Google Scholar]
- Wei, S.; Ji, S.; Lu, M. Toward automatic building footprint delineation from aerial images using CNN and regularization. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2178–2189. [Google Scholar] [CrossRef]
- Bastani, F.; He, S.; Abbar, S.; Alizadeh, M.; Balakrishnan, H.; Chawla, S.; Madden, S.; DeWitt, D. Roadtracer: Automatic extraction of road networks from aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4720–4728. [Google Scholar]
- Hershberger, J.E.; Snoeyink, J. Speeding up the Douglas-Peucker Line-Simplification Algorithm; University of British Columbia: Vancouver, BC, Canada, 1992. [Google Scholar]
- Xie, Y.; Feng, D.; Xiong, S.; Zhu, J.; Liu, Y. Multi-scene building height estimation method based on shadow in high resolution imagery. Remote Sens. 2021, 13, 2862. [Google Scholar] [CrossRef]
- Burnett, C.; Blaschke, T. A multi-scale segmentation/object relationship modelling methodology for landscape analysis. Ecol. Model. 2003, 168, 233–249. [Google Scholar] [CrossRef]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; IEEE: Piscataway, NJ, USA, 1995; Volume 1, pp. 278–282. [Google Scholar]
- Feng, Y.; Du, S.; Myint, S.W.; Shu, M. Do urban functional zones affect land surface temperature differently? A case study of Beijing, China. Remote Sens. 2019, 11, 1802. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Building Types | Sample Image | Description |
|---|---|---|
| Intensive building (B1) |  | Mainly refers to a group of closely adjacent buildings. Usually, the open space and vegetation cover density around this type of building is low. |
| Middle and low-rise residential buildings (B2) |  | Mainly refers to middle and low-rise residential buildings, which usually have similar shapes and sizes in the image, with more regular spatial arrangement and higher density of vegetation cover and open space than intensive buildings. |
| High-rise commercial and residential buildings (B3) |  | Mainly refers to high-rise residential and commercial buildings, which have similar visual effects to middle and low-rise residential buildings in images, but with more floors and often adjacent to complete regular shadows. |
| Commercial buildings (B4) |  | Mainly refers to composite buildings used for commercial services or offices, which tend to have irregular shapes, staggered heights, larger areas than residential buildings, and more open spaces. |
| Factory-type buildings (B5) |  | Mainly refers to industrial or warehouse storage factories with a larger area than residential buildings. Compared to commercial buildings, factory-type buildings have more regular shapes and homogeneous spectral responses. |
| UFR Types | Description |
|---|---|
| Residential region (R1) | The absence of B3 or B5 in the block with more than of B1 and B2. |
| Commercial region (R2) | The presence of B3 in the block, or the proportion of B4 exceeds . |
| Industrial region (R3) | The presence of B5 in the block. |
| Other uses (R4) | Other blocks, including green areas, water bodies, etc. |
| RCM | Affinity Loss | OA | F1 Score | Gain |
|---|---|---|---|---|
| - | - | 89.12 | 80.52 | - |
| ✓ | - | 90.63 | 81.15 | 1.51/0.63 |
| ✓ | ✓ | 91.45 | 82.25 | 0.82/1.10 |
| Methods | Roads | Buildings | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| OA | Recall | F1 Score | mIOU | FPS | OA | Recall | F1 Score | mIOU | FPS | |
| PSPNet | 78.65 | 73.69 | 67.12 | 64.78 | 5.6 | 80.64 | 77.64 | 76.86 | 64.64 | 5.2 |
| DeepLab v3+ | 79.36 | 75.48 | 68.60 | 65.97 | 1.2 | 82.45 | 78.25 | 78.91 | 65.45 | 0.9 |
| DANet | 81.07 | 78.64 | 71.08 | 69.63 | 7.3 | 88.78 | 82.16 | 81.06 | 71.04 | 7.1 |
| Joint-Net | 80.64 | 77.12 | 70.16 | 68.74 | 11.4 | 86.80 | 80.76 | 80.17 | 69.87 | 11.0 |
| Our method | 82.87 | 80.36 | 72.45 | 70.29 | 13.9 | 91.45 | 84.36 | 82.25 | 72.68 | 13.5 |
| Classified | Reference | ||||
|---|---|---|---|---|---|
| R1 | R2 | R3 | R4 | UA | |
| R1 | 246 | 12 | 4 | 0 | 94.06 |
| R2 | 10 | 38 | 2 | 0 | 78.53 |
| R3 | 8 | 3 | 35 | 0 | 80.00 |
| R4 | 0 | 0 | 0 | 92 | 100 |
| PA | 93.27 | 75.34 | 86.21 | 100 | % |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, W.; Li, M.; Wu, C.; Zhou, W.; Chu, G. Identifying Urban Functional Regions from High-Resolution Satellite Images Using a Context-Aware Segmentation Network. Remote Sens. 2022, 14, 3996. https://doi.org/10.3390/rs14163996
Zhao W, Li M, Wu C, Zhou W, Chu G. Identifying Urban Functional Regions from High-Resolution Satellite Images Using a Context-Aware Segmentation Network. Remote Sensing. 2022; 14(16):3996. https://doi.org/10.3390/rs14163996
Chicago/Turabian StyleZhao, Wufan, Mengmeng Li, Cai Wu, Wen Zhou, and Guozhong Chu. 2022. "Identifying Urban Functional Regions from High-Resolution Satellite Images Using a Context-Aware Segmentation Network" Remote Sensing 14, no. 16: 3996. https://doi.org/10.3390/rs14163996
APA StyleZhao, W., Li, M., Wu, C., Zhou, W., & Chu, G. (2022). Identifying Urban Functional Regions from High-Resolution Satellite Images Using a Context-Aware Segmentation Network. Remote Sensing, 14(16), 3996. https://doi.org/10.3390/rs14163996