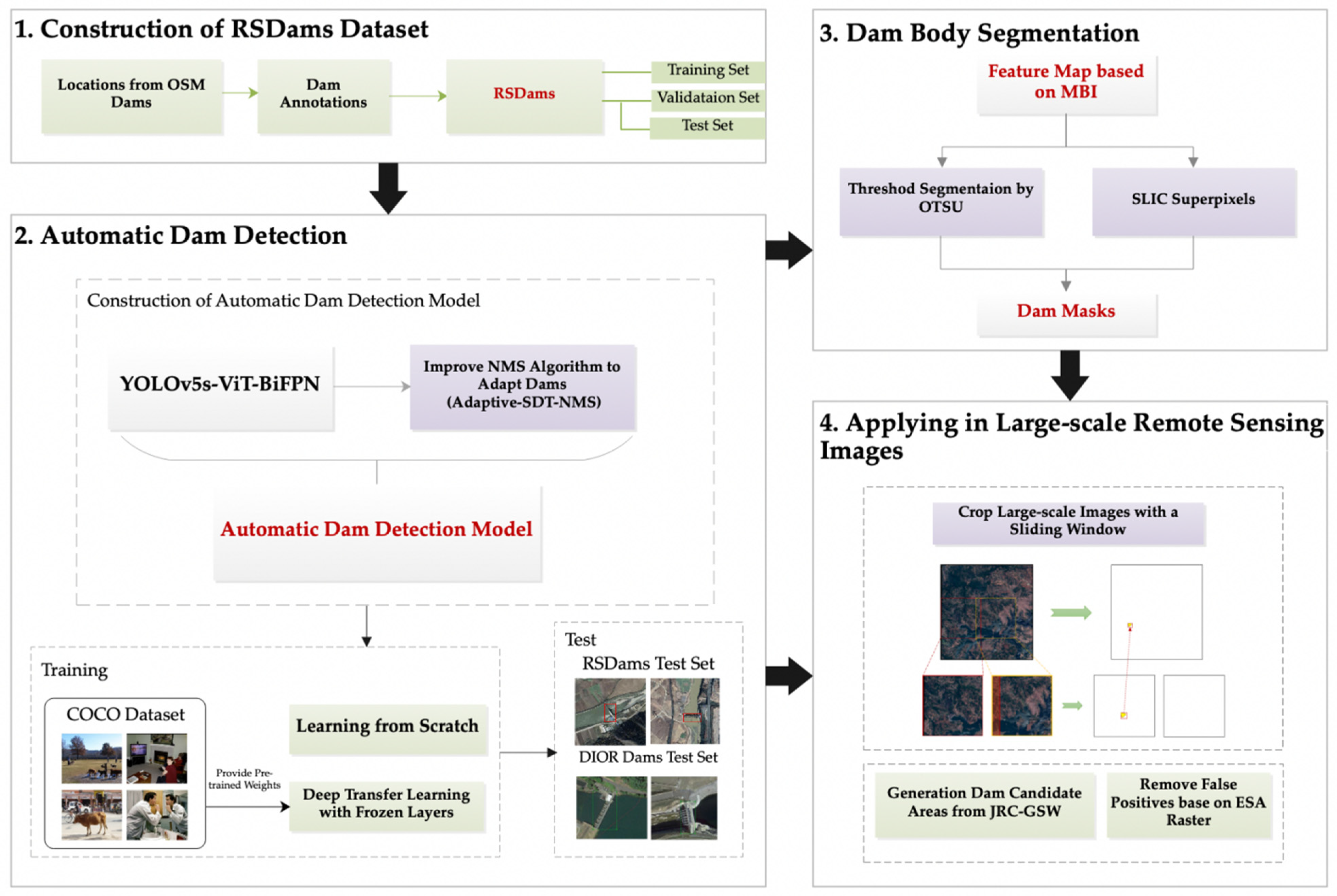
Figure 1.
The workflow of the proposed method for dam extraction.
Figure 1.
The workflow of the proposed method for dam extraction.
Figure 2.
Study areas were Yangbi County in Yunnan Province and Changping District in Beijing, China.
Figure 2.
Study areas were Yangbi County in Yunnan Province and Changping District in Beijing, China.
Figure 3.
Examples of the visualization of bounding boxes for dams in the RSDams dataset.
Figure 3.
Examples of the visualization of bounding boxes for dams in the RSDams dataset.
Figure 4.
An example of different results for the same dam dealing with no NMS, NMS, and Adaptive-SDT-NMS algorithms. (a) There were 21 bounding boxes without NMS; (b) two bounding boxes were left, and the other redundant bounding boxes were removed by NMS; (c) the bounding box with the highest score was selected by our Adaptive-SDT-NMS.
Figure 4.
An example of different results for the same dam dealing with no NMS, NMS, and Adaptive-SDT-NMS algorithms. (a) There were 21 bounding boxes without NMS; (b) two bounding boxes were left, and the other redundant bounding boxes were removed by NMS; (c) the bounding box with the highest score was selected by our Adaptive-SDT-NMS.
Figure 5.
Sketch map of the transferred 1–9 layers of YOLOv5s-ViT-BiFPN in this study. Source domain indicates the COCO dataset trained on the YOLOv5s network, of which the first nine layers were the same as those of YOLOv5s-ViT-BiFPN. The target domain was the RSDams dataset.
Figure 5.
Sketch map of the transferred 1–9 layers of YOLOv5s-ViT-BiFPN in this study. Source domain indicates the COCO dataset trained on the YOLOv5s network, of which the first nine layers were the same as those of YOLOv5s-ViT-BiFPN. The target domain was the RSDams dataset.
Figure 6.
An example of pre-processing on high-resolution satellite imagery and post-processing for the results of dam detection and segmentation. (a) The original image; (b) one image patch; (c) the image patch with a 10% overlap that is adjacent to (b); (d) dam extraction result of (b), which has a dam. The red rectangle is the result of dam detection, and the yellow irregular polygon is the result of dam segmentation. (e) Dam extraction result of (c), which has no dam targets; (f) dam extraction result of the original image.
Figure 6.
An example of pre-processing on high-resolution satellite imagery and post-processing for the results of dam detection and segmentation. (a) The original image; (b) one image patch; (c) the image patch with a 10% overlap that is adjacent to (b); (d) dam extraction result of (b), which has a dam. The red rectangle is the result of dam detection, and the yellow irregular polygon is the result of dam segmentation. (e) Dam extraction result of (c), which has no dam targets; (f) dam extraction result of the original image.
Figure 7.
Construction of dam candidate areas based on the JRC-GSW raster. (a) Original image; (b) JRC-GSW raster; (c) water polygon; (d) water points; (e) water buffer; (f) dam candidate areas.
Figure 7.
Construction of dam candidate areas based on the JRC-GSW raster. (a) Original image; (b) JRC-GSW raster; (c) water polygon; (d) water points; (e) water buffer; (f) dam candidate areas.
Figure 8.
Overlap dam image with built-up and bare land from the ESA Global Land Cover dataset.
Figure 8.
Overlap dam image with built-up and bare land from the ESA Global Land Cover dataset.
Figure 9.
Performance of deep transfer learning using different frozen layers on the RSDams validation set. (a) Column graphs for training time by different frozen layers. (b) Line and symbol graphs for accuracy using different frozen layers. Black circles represent the index of precision. Red squares represent the recall rate. Green diamonds represent the F1 score. Blue triangles represent mAP.
Figure 9.
Performance of deep transfer learning using different frozen layers on the RSDams validation set. (a) Column graphs for training time by different frozen layers. (b) Line and symbol graphs for accuracy using different frozen layers. Black circles represent the index of precision. Red squares represent the recall rate. Green diamonds represent the F1 score. Blue triangles represent mAP.
Figure 10.
Training losses and precision curves of YOLOv5s-ViT-BiFPN based on learning from scratch and transfer learning with pretrained weights over the COCO dataset. (a) Change curves of loss values for YOLOv5s-ViT-BiFPN based on learning from scratch (blue line) and deep transfer learning (red line). (b) The change curves of precision for YOLOv5s-ViT-BiFPN based on learning from scratch (blue line) and deep transfer learning (red line).
Figure 10.
Training losses and precision curves of YOLOv5s-ViT-BiFPN based on learning from scratch and transfer learning with pretrained weights over the COCO dataset. (a) Change curves of loss values for YOLOv5s-ViT-BiFPN based on learning from scratch (blue line) and deep transfer learning (red line). (b) The change curves of precision for YOLOv5s-ViT-BiFPN based on learning from scratch (blue line) and deep transfer learning (red line).
Figure 11.
Confusion matrixes for different NMS algorithms on the RSDams (left) and DIOR Dams (right) test sets.
Figure 11.
Confusion matrixes for different NMS algorithms on the RSDams (left) and DIOR Dams (right) test sets.
Figure 12.
Comparison of the post-processing results for the NMS and Adaptive-SDT-NMS algorithms. The examples in the first row contain the false positives of the original NMS of YOLOv5s, and the second row shows the real positive cases from the Adaptive-SDT-NMS algorithm.
Figure 12.
Comparison of the post-processing results for the NMS and Adaptive-SDT-NMS algorithms. The examples in the first row contain the false positives of the original NMS of YOLOv5s, and the second row shows the real positive cases from the Adaptive-SDT-NMS algorithm.
Figure 13.
Processes of dam segmentation. (a) Original images: randomly selected from validation samples of RSDams. (b) Dam detection results: the bounding boxes are the visualizations of the results for dam detection. (c) MBI feature images: increasing MBI values from black to bright white. (d) SLIC images: visualization for superpixels using SLIC operation. (e) Dam segmentation results: the white areas are dam bodies, and the black ones are background. (f) The results according to a visual interpretation: the blue areas are dam bodies, and the black ones are background.
Figure 13.
Processes of dam segmentation. (a) Original images: randomly selected from validation samples of RSDams. (b) Dam detection results: the bounding boxes are the visualizations of the results for dam detection. (c) MBI feature images: increasing MBI values from black to bright white. (d) SLIC images: visualization for superpixels using SLIC operation. (e) Dam segmentation results: the white areas are dam bodies, and the black ones are background. (f) The results according to a visual interpretation: the blue areas are dam bodies, and the black ones are background.
Figure 14.
Performance of dam segmentation. The blue dots indicate the evaluation results of 100 test images, and the dark red dotted lines represent the trend lines for (a) overall accuracy, (b) Kappa, (c) omission errors, and (d) commission errors.
Figure 14.
Performance of dam segmentation. The blue dots indicate the evaluation results of 100 test images, and the dark red dotted lines represent the trend lines for (a) overall accuracy, (b) Kappa, (c) omission errors, and (d) commission errors.
Figure 15.
Results of dam extraction in the two study areas. (a) The results of dam extraction in Yangbi. (b) The results of dam extraction in Changping. (c) Examples of dam segmentation in Yangbi. (d) Examples of dam segmentation in Changping.
Figure 15.
Results of dam extraction in the two study areas. (a) The results of dam extraction in Yangbi. (b) The results of dam extraction in Changping. (c) Examples of dam segmentation in Yangbi. (d) Examples of dam segmentation in Changping.
Figure 16.
False positives in Yangbi (a,b) and Changping (c–e): (a) riverbank, (b) bridge, (c) building, (d) levee, and (e) bridge.
Figure 16.
False positives in Yangbi (a,b) and Changping (c–e): (a) riverbank, (b) bridge, (c) building, (d) levee, and (e) bridge.
Figure 17.
Grad-CAM maps of several critical layers in the dam detection process. The first column shows the original images. The middle three columns are the Grad-CAM maps, Backbone+ViT, and the BiFPN convolution layers. The last column is the visualization of the bounding boxes.
Figure 17.
Grad-CAM maps of several critical layers in the dam detection process. The first column shows the original images. The middle three columns are the Grad-CAM maps, Backbone+ViT, and the BiFPN convolution layers. The last column is the visualization of the bounding boxes.
Figure 18.
Performance of dam segmentation without the SLIC algorithm. The blue dots indicate the evaluation results of the 100 test images, and the dark red dotted lines represent the trend lines for (a) overall accuracy, (b) Kappa, (c) omission errors, and (d) commission errors.
Figure 18.
Performance of dam segmentation without the SLIC algorithm. The blue dots indicate the evaluation results of the 100 test images, and the dark red dotted lines represent the trend lines for (a) overall accuracy, (b) Kappa, (c) omission errors, and (d) commission errors.
Figure 19.
Comparison of dam segmentation without and with the SLIC algorithm. (a) Original images; (b) dam detection results; (c) dam segmentation results without the SLIC algorithm; (d) dam segmentation results with the SLIC algorithm.
Figure 19.
Comparison of dam segmentation without and with the SLIC algorithm. (a) Original images; (b) dam detection results; (c) dam segmentation results without the SLIC algorithm; (d) dam segmentation results with the SLIC algorithm.
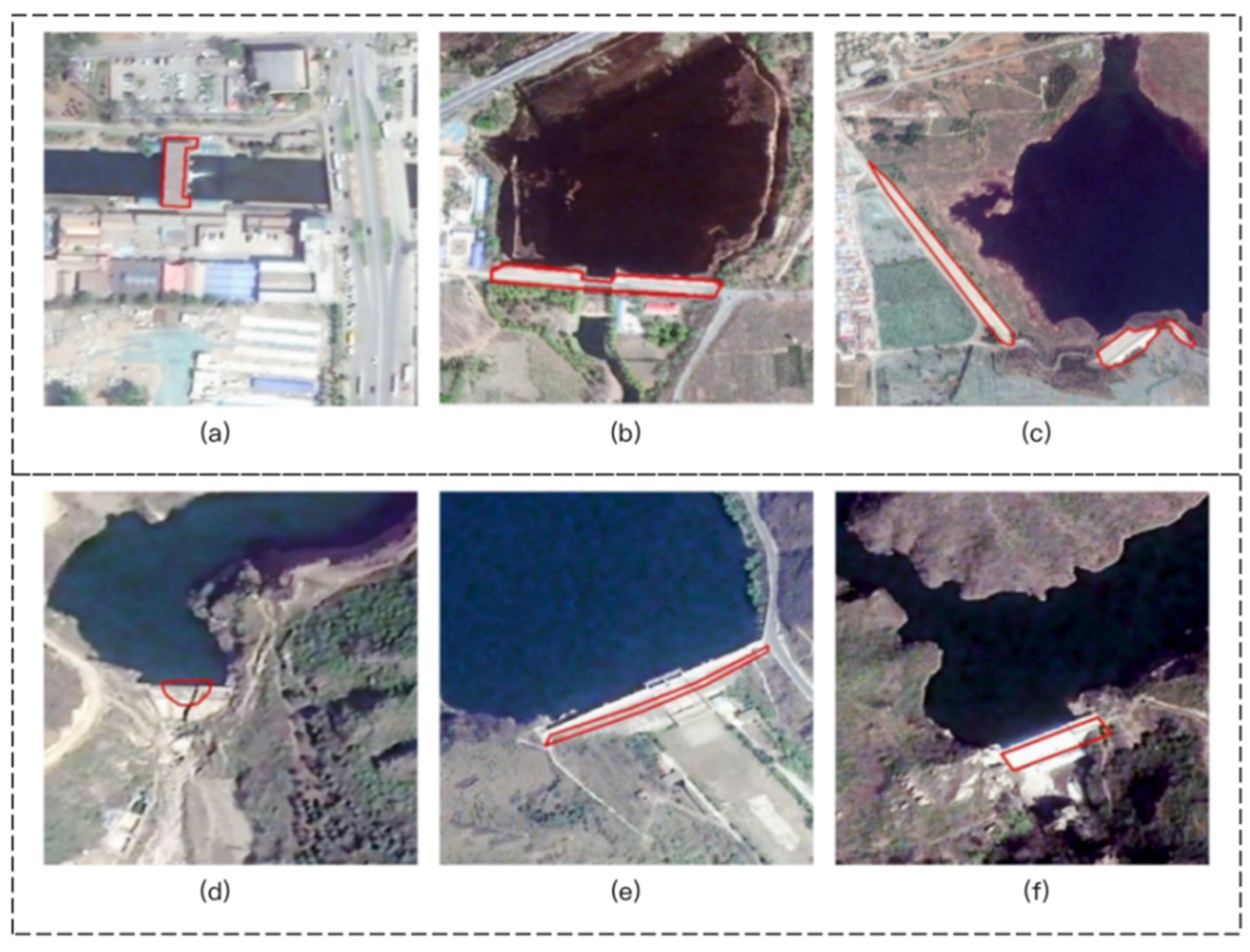
Figure 20.
Examples of OSM Dams overlapped by satellite images. (a–c) Well-matched dam masks; (d–f) poorly matched dam masks.
Figure 20.
Examples of OSM Dams overlapped by satellite images. (a–c) Well-matched dam masks; (d–f) poorly matched dam masks.
Table 1.
The allocation of samples in RSDams for training, validation, and testing.
Table 1.
The allocation of samples in RSDams for training, validation, and testing.
| Dataset | Categories | Training | Validation | Test | Total |
|---|
| RSDams | Image patches | 1280 | 320 | 400 | 2000 |
| Dam | 1330 | 326 | 416 | 2072 |
Table 2.
Comparison of the structures of YOLOv5s and YOLOv5s-ViT-BiFPN.
Table 2.
Comparison of the structures of YOLOv5s and YOLOv5s-ViT-BiFPN.
| | YOLOv5s | YOLOv5s-ViT-BiFPN |
|---|
| Input | Images or Patches | Images or Patches |
| Backbone | CSPDarknet53
(Focus, CSP, CBL, SPP) | CSPDarknet53
(Focus, CSP, CBL, SPP), ViT |
| Neck | PANet | BiFPN network |
| Head/Prediction | YOLOv3 head | YOLOv3 head |
Table 3.
Comparisons of accuracy and time for training with different detection models and training methods on the RSDams validation set.
Table 3.
Comparisons of accuracy and time for training with different detection models and training methods on the RSDams validation set.
| Training Method | Model | n | Accuracy (%) | Training Time (h) |
|---|
| Precision | Recall | F1 | mAP |
|---|
| Learning from Scratch | SSD | - | - | - | - | 80.1 | 1.3 |
| YOLOv3 | - | 78.4 | 77.9 | 78.1 | 71.3 | 9.3 |
| YOLOv5s | - | 81.2 | 78.7 | 79.9 | 76.6 | 4.2 |
| YOLOv5s-BiFPN | - | 83.2 | 81.6 | 82.4 | 78.5 | 4.3 |
| YOLOv5s-ViT-BiFPN | - | 84.8 | 82.7 | 83.7 | 80.2 | 4.4 |
| Transfer Learning with Different Frozen Layers | YOLOv5s-ViT-BiFPN | 0 | 83.2 | 80 | 81.6 | 73.1 | 3.1 |
| 1 | 85.3 | 82.8 | 84 | 79.2 | 1.0 |
| 2 | 84.9 | 84.1 | 84.5 | 80.1 | 1.0 |
| 3 | 88.2 | 85.3 | 86.7 | 81.8 | 1.0 |
| 4 | 87.8 | 82.5 | 85.1 | 79.3 | 1.0 |
| 5 | 87.7 | 83.8 | 85.7 | 80.1 | 0.9 |
| 6 | 87.1 | 81.2 | 84.1 | 78.8 | 0.9 |
| 7 | 86.1 | 79.4 | 82.6 | 77.3 | 0.9 |
| 8 | 84.7 | 80.6 | 82.6 | 76.5 | 0.9 |
| 9 | 83.1 | 77.8 | 80.4 | 70.4 | 0.9 |
Table 4.
Comparison of generalization errors on the RSDams and DIOR Dams test sets.
Table 4.
Comparison of generalization errors on the RSDams and DIOR Dams test sets.
| Model | NMS | RSDams Test Sets | DIOR Dams Test Sets |
|---|
| Omission Errors (%) | Commission Errors (%) | Omission Errors (%) | Commission Errors (%) |
|---|
| SSD | - | 8.4 | 5.0 | 20.1 | 1.7 |
| YOLOv3 | - | 10.1 | 5.3 | 18.7 | 2.7 |
| YOLOv5s-ViT-BiFPN | NMS | 3.6 | 12.6 | 16.3 | 8.4 |
| Adaptive-SDT-NMS | 3.6 | 4.1 | 16.3 | 0 |
Table 5.
Evaluation results of dam detection in two study areas. (A check mark means the method is used.)
Table 5.
Evaluation results of dam detection in two study areas. (A check mark means the method is used.)
| Study Area | JCR-GSW | ESA | Numbers of Predicted Bounding Boxes | True Positives | False Negatives | Precision (%) | Recall (%) |
|---|
| Yangbi | | | 105 | 10 | 3 | 9.5 | 76.9 |
| √ | | 48 | 9 | 4 | 18.8 | 69.2 |
| | √ | 83 | 10 | 3 | 10.8 | 76.9 |
| √ | √ | 44 | 9 | 4 | 20.5 | 69.2 |
| Changping | | | 1708 | 23 | 4 | 1.4 | 85.2 |
| √ | | 650 | 22 | 5 | 3.9 | 81.5 |
| | √ | 1471 | 22 | 5 | 1.5 | 81.5 |
| √ | √ | 620 | 22 | 5 | 3.6 | 81.5 |
Table 6.
Accuracy comparison of dam segmentation results with and without the SLIC algorithm. (A check mark means the method is used.)
Table 6.
Accuracy comparison of dam segmentation results with and without the SLIC algorithm. (A check mark means the method is used.)
| SLIC Algorithm | Average Overall Accuracy
(%) | Average Kappa (%) | Average Omission Errors (%) | Average Commission Errors (%) |
|---|
| | 97.5 | 0.4 | 60.2 | 44.7 |
| √ | 97.4 | 0.7 | 7.1 | 44.3 |
Table 7.
Comparison of the number of dams in Yangbi and Changping from different datasets with visual interpretation results.
Table 7.
Comparison of the number of dams in Yangbi and Changping from different datasets with visual interpretation results.
| Dataset | Data Format | Number of Dams in Yangbi | Number of Dams in Changping |
|---|
| Visual Interpretation Results | Geographical Point | 13 | 27 |
| Our Method | Dam Masks Raster | 9 | 22 |
| GOODD | Geographical Point | 4 | 2 |
| GRanD | Geographical Point | 0 | 0 |
| OSM Dams | Dam Polygon Vector | 2 | 11 |
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}