2. Densification of 3D-GPR Data with Fourier Interpolation
2.1. General Overview of Trace Generation
A lateral data densification strategy is proposed as a complementary operation to standard processing. The methodology consists of the interpolation of GPR B-scans in the spectral domain after applying the Fourier transform. This mitigates the subsampling problem of 3D-GPR models. This method is widely used in seismic processing, allowing the estimation of missing traces from existing traces [
5,
6,
7,
8,
9,
10,
11].
The first aspect to consider, to densify a 3D-GPR dataset, is that the type of information available corresponds to a spatial distribution of amplitudes, , resulting from the detection of reflected EMW. However, this dataset is not equally distributed in space since represents a trace where corresponds to the number of samples, which generally has a value of 512 or 1024 samples, for spacing () between 0.05 and 0.5 ns. On the other hand, denotes the amplitude of the signal received at each point of a depth along the B-scan, where denotes the number of traces in that B-scan; this defines the B-scan direction. This value depends on its length and the spacing between traces (), usually between 1, 2, and 5 cm. Finally, refers to the amplitudes when fixing a plane in which corresponds to the total number of B-scans acquired during the survey, with a certain spacing between B-scans ().
When comparing the considered sampling intervals, it becomes evident that the dataset has subsampling in the y-direction, which results in a lack of information. Therefore, an excellent strategy to increase the quality of 3D images is to densify the whole set in this direction to generate new traces between the existing parallel B-scans.
2.2. Trace Estimation in Seismic Processing
For the estimation of traces from the existing traces, seismic exploration processing flows offer a variety of choices. One approach utilizes mathematical transformations (such as the Fourier and curvelet transforms) to estimate missing features in seismic data [
5,
12,
13,
14]. These transformations map the signal in a new domain to synthesize data in spatial locations that have not been recorded [
5]. Other methods rely on using the Fourier transform [
15,
16,
17,
18,
19]. Its coefficients are calculated from the input lines to estimate the data for any mesh dimension [
20]. In addition, there are other proposed algorithms, such as the irregular Fourier transform and sparse inversion, which are efficient methods in the case of regularly sampled data. All Fourier reconstruction methods require two conditions: the signal must be limited over a range of frequencies and represented by a distribution of Fourier coefficients.
The use of mathematical transforms [
8] and predictive filters [
21] in the
f-x domain [
22] is one of the interpolation strategies for estimating missing traces in seismic data. We can perform the data estimation using predictive filters as autoregressive operators since linear events overlap in the
f-x domain. We can also apply the method to
f-x random noise attenuation phenomena [
23,
24,
25]. For example, to interpolate data with a frequency of
2f, we can use predictive filters estimated from frequency
f. Predictive filters estimated from low signal frequencies, free from aliasing, are used to interpolate the content of high frequencies that suffer from aliasing and can also be used to reconstruct missing data [
22,
26,
27].
Automatic event identification is a technique that allows trace interpolation and the estimation of parameters or attributes [
28,
29]. We use the amplitudes corresponding to the reflections and arrival timings [
30]. The algorithm analyzes the attributes of the recorded datasets [
30,
31,
32] and converts the signal into reflection amplitudes and the cosine of the instantaneous phase. The algorithm uses the phase cosine to identify any event with lateral continuity of the phase value, connecting phases of the signal with the same polarities and close arrival times [
29]. Reflection impedance allows the system to identify events in which there is a lateral variation in amplitudes or changes in the configuration of the reflected wave. The algorithm automatically connects events that have lateral coherence, defining horizons, which are then analyzed by overlapping them with the initial seismic profile. The analysis of each horizon seeks nearby subparallel events to classify them as part of the exact reflection. When grouping events, it is possible to estimate the reflection points by calculating the mean cosine of the phase of each horizon, preserving the reflected signal, and removing unrelated events [
29].
We can apply automatic event identification to calculate spatial derivatives after applying the Fourier transform. Analogous to temporal derivatives, spatial derivatives also convert inflection points into zeros (in spatial terms), allowing any special discontinuity of seismic data to be highlighted [
33]. In addition, we can also apply spectral analysis to spatial derivatives, which denotes that differentiation in the horizontal direction increases the frequency content and applies a phase shift of π/2. As a result, we may employ derivatives to detect small changes in the seismic signal caused by interfaces such as meshes and cracks [
33].
Referring to the classical interpolation method, spatial interpolation can also be used in the B-scan and depth slice. Whichever grid method is used, the interpolation is performed through the analysis of neighboring pixels. Even with the great efficiency that applies most of the time, in certain situations, numerical artifacts are generated, an event that we aim to avoid.
The choice of Fourier interpolation is because this scheme maintains the spectral content of the data. The reason for the preference for B-scan interpolation considering 2D rather than 3D interpolation is that the acquisition of GPR B-scans is performed through 2D parallel B-scans. As the interpolation is performed at the trace level, it is not relevant to compare this interpolation scheme with others.
It is also necessary to say that a GPR B-scan, in the frequency domain, is limited by a range of values and must be able to be represented by a distribution of Fourier coefficients. These two conditions were previously verified in [
34,
35].
2.3. INT-FFT Algorithm to Interpolate GPR B-Scans
This study used the Fourier interpolation method to generate traces and densify the dataset in the frequency domain. The implementation is made through the
Suinterp algorithm [
36,
37], available in Seismic Unix (SU), a free access utility package from the Centre for Wave Phenomena of Colorado School of Mines (USA). This algorithm interpolates traces between each pair of existing traces by applying the discrete Fourier transform to each trace and calculating the spatial derivatives of each pair of adjacent traces. Then, it performs a linear interpolation between both traces in the frequency domain and applies the inverse of the Fourier transform, restoring the data to the time domain. We assume that the low-frequency content of the input signal does not suffer from aliasing and that the deeper amplitude peaks allow data interpolation across its entire bandwidth at the high frequencies that are subsampled.
The parameterization of the algorithm contains the number of lines to be interpolated between each pair of lines, the total number of traces in the B-scan, and corner frequency values corresponding to the GPR data frequency range.
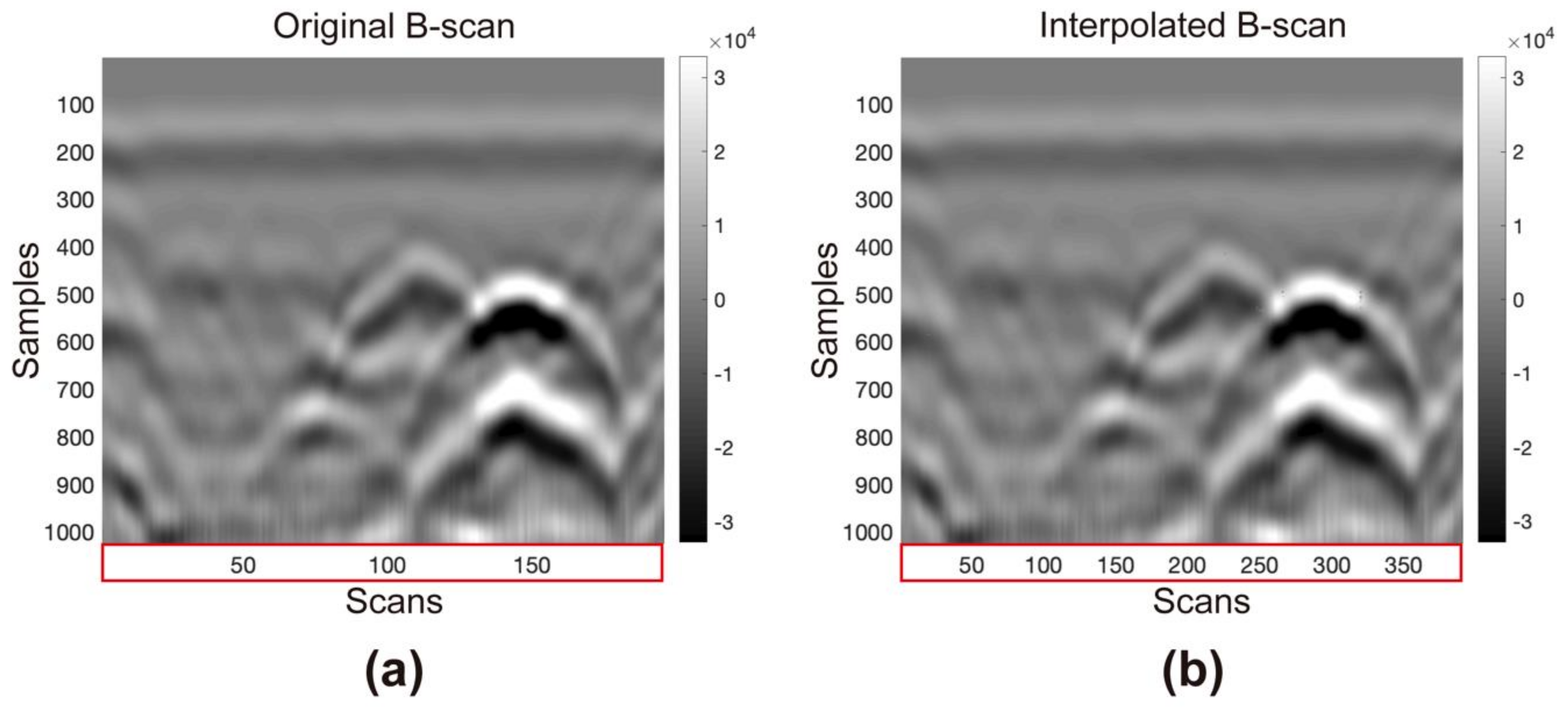
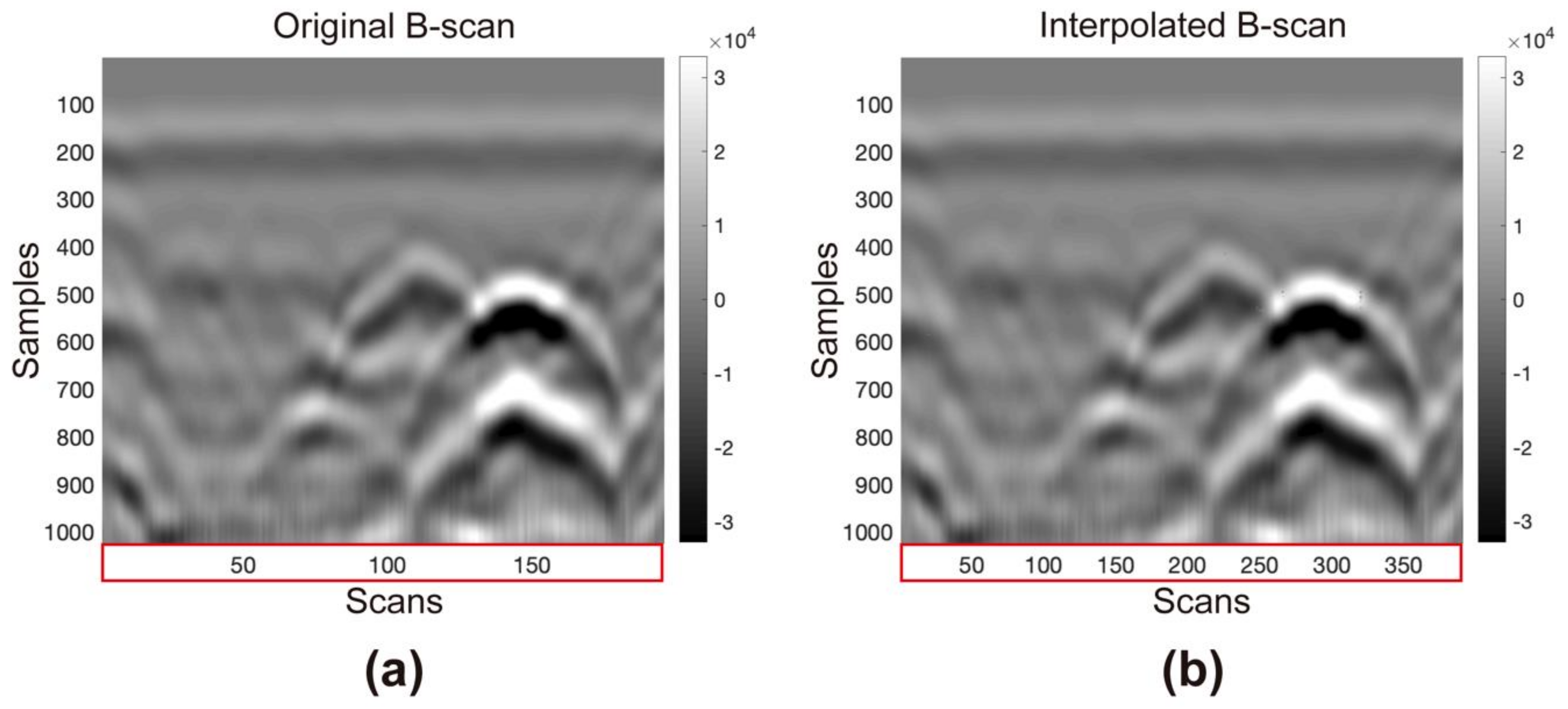
Before applying the methodology to the entire 3D-GPR dataset, it is necessary to test with a GPR B-scan to compare the input with the output using a B-scan acquired in a laboratory with a 1.6 GHz antenna. The acquisition parameters are as follows: 1024 samples per trace, 5 ns temporal range, 0.004888 ns sampling interval, 196 samples per trace, and 0.005 m equidistance of traces. The interpolated B-scan must have 391 traces, twice the traces minus one (proven information,
Figure 4). The time range remains the same, and the distance between the traces decreases to half of the initial value before interpolation, to 0.0025 m.
Figure 4 shows the input and interpolated B-scans. There is a slight increase in sharpness after implementing Fourier interpolation with the
Suinterp algorithm. We also did not notice any change in the range of amplitude values. The quality of the initial data has not decreased. We can conclude that this interpolation method works for GPR data.
MATLAB was used to create the previous tests and the script. The Suinterp algorithm requires converting the GPR data to a compatible format. The adaptation of the data implies the manipulation of the matrices so that they are spatially related and so the desired information can perform the interpolation, and then the export of the matrices to the format allowed for import by the Suinterp algorithm.
As the data were acquired in
N equally spaced parallel lines, the import of all B-scans needs to store the data in the form of a 3D matrix,
A(xi,
yj,
zk), corresponding to the spatial distribution of the lines (
Figure 5a). The 3D matrix has dimensions
(Ni,
Nj,
Nk) in which
Ni and
Nj are each row and column of each B-scan, respectively, and
zk defines the sample number of the line corresponding to the pair (
xi,
yi).
To densify between the B-scans, first, it is necessary to redefine B-scans in the
y-direction, meaning that the B-scans to be considered are perpendicular to the initial direction (
Figure 5b). Each redefined B-scan consists of a trace from each original B-scan, sequentially ordered from
j = 1 to
Nj. This data rearrangement is necessary because the
Suinterp algorithm interpolates a trace between each pair of traces. As a result, we need to apply the parallel B-scan interpolation as many times as the number of traces in the perpendicular B-scan. The next step is to restore the original direction of the spatial reference, redefining the B-scans along the
x-direction, as in the original data (
Figure 5c). In total, the number of final B-scans is
2N − 1.
The entire sequence of operations is applied iteratively, which allows one to automate the entire procedure. The user must compile the algorithm and wait for the result.
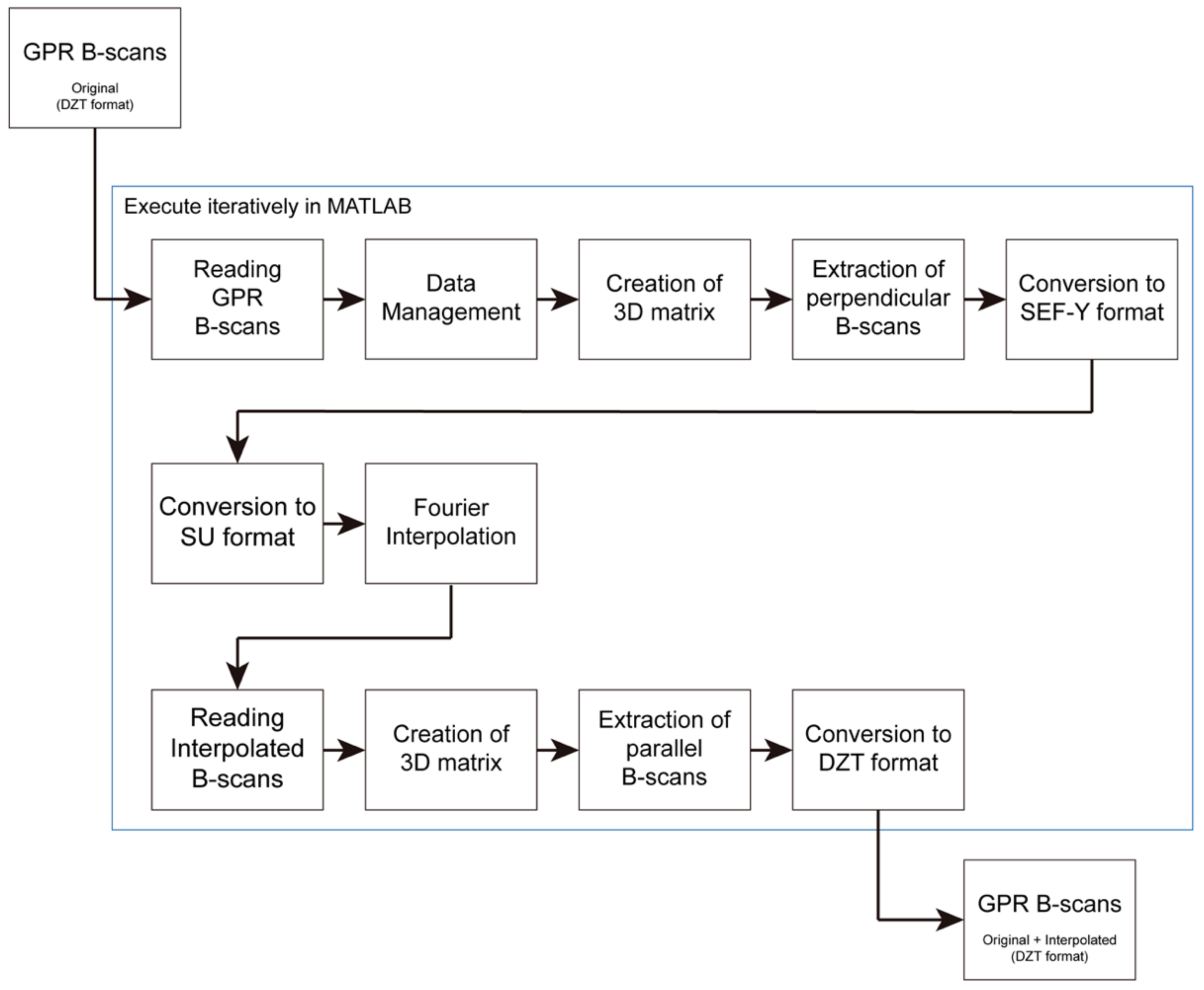
The following process sequence (
Figure 6) is the flow scheme to implement the densification technique in the MATLAB software:
Preliminary parameterization: introduction of the total number of parallel B-scans and the number of the initial B-scan.
Importing GPR B-scans in DZT format using routine readgssi, a MATLAB algorithm adapted to read files in DZT format.
Determination of the maximum length of the B-scans so that the 3D matrix is regular.
Importing complementary information about the geometry of the dataset (starting and ending position of each B-scan); all B-scans must be well located in space. During the survey, the user needs to collect all the information about the acquisition.
Determination of the extremes of the locations of each B-scan.
Removal of the effect of the acquisition in zigzag, if necessary.
Normalization of the length of the B-scans, if necessary, by adding traces of zeros at the start or end of the B-scan to make the matrix regular.
Placing the data for each B-scan in the 3D matrix (parallel B-scans).
Extraction of perpendicular B-scans and conversion to SEG-Y format using the routine MATLAB writesegy (SegyMat Library).
Conversion to SU format using internal Seismic Unix routines.
B-scan interpolation using the Seismic Unix Suinterp routine.
Importing interpolated B-scans in SU format using the MATLAB readsu routine (SegyMat Library).
Placing the interpolated data in the 3D matrix.
Extraction of parallel B-scans (original + interpolated).
Data conversion to DZT format, using the MATLAB writegssi routine, developed to write files in DZT format.
Figure 6.
Schematics of the numerical implementation of the INT-FFT algorithm.
Figure 6.
Schematics of the numerical implementation of the INT-FFT algorithm.
2.4. Parameters to Evaluate the Results
The evaluation of the results of this methodology is made by establishing a comparison between the different datasets graphically and by the values of parameters such as the structural similarity index and sharpness index.
The structural similarity index (SSI) quantifies the similarity between two datasets [
37]. The result can be represented graphically (displayed differences) and as a percentage (100% corresponds to the same data).
The sharpness index (SI) is a parameter that quantifies the sharpness of an image with dimensions (
mxn). To calculate it, we can use the Hudgin gradient (
dH) of the image [
38]; it is used in image fusion to select the sharpest pixels [
39] considering the neighboring pixels. The numerical implementation requires calculating the horizontal components of the Hudgin gradient
dxH and vertical
dyH. These coefficients are needed to calculate the gradient modulus used in the SI calculation [
40] through Equation (1).
where
is the dimension of the matrix and where
i,
j defines the coordinates of each cell.
The Hudgin gradient values of the image increase with increasing image contrast. We can consider that the sharpness of an image must be associated with the diversity of contrasts: the more significant and more abundant the contrasts are, the greater this index.
Both parameters are a way to quantify the improvement that Fourier interpolation can provide to the results. It should be noted that data densification increases noise levels, so the sharpness index must be analyzed carefully.
4. Discussion of the Results
The results obtained after implementing the INT-FFT algorithm show that the proposed approach effectively increased the lateral resolution of the 3D-GPR datasets. Data densification through 2D Fourier interpolation allowed the creation of a new GPR B-scan between each pair of existent B-scans. This approach increased the general sharpness of the obtained GPR results.
The numerical implementation started with a test in a single B-scan to ascertain the applicability of the Suinterp algorithm to GPR data. The graphical aspect remained, with a change in the number of traces that increased from N to 2N − 1. In addition, we observed a slight increase in the sharpness of some reflectors. Therefore, the INT-FFT algorithm could densify the GPR data, and we could use it to interpolate the B-scans in a 3D dataset.
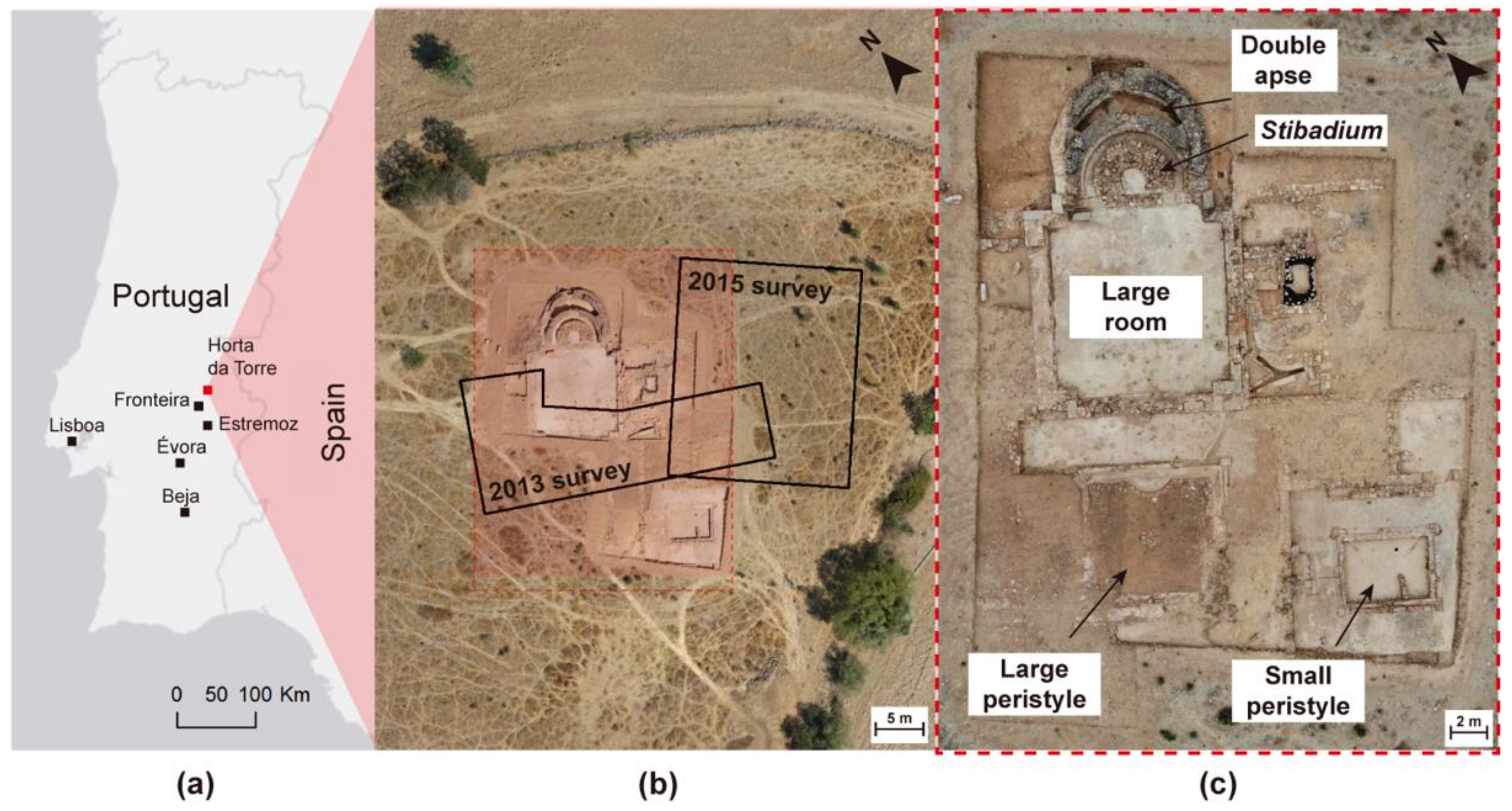
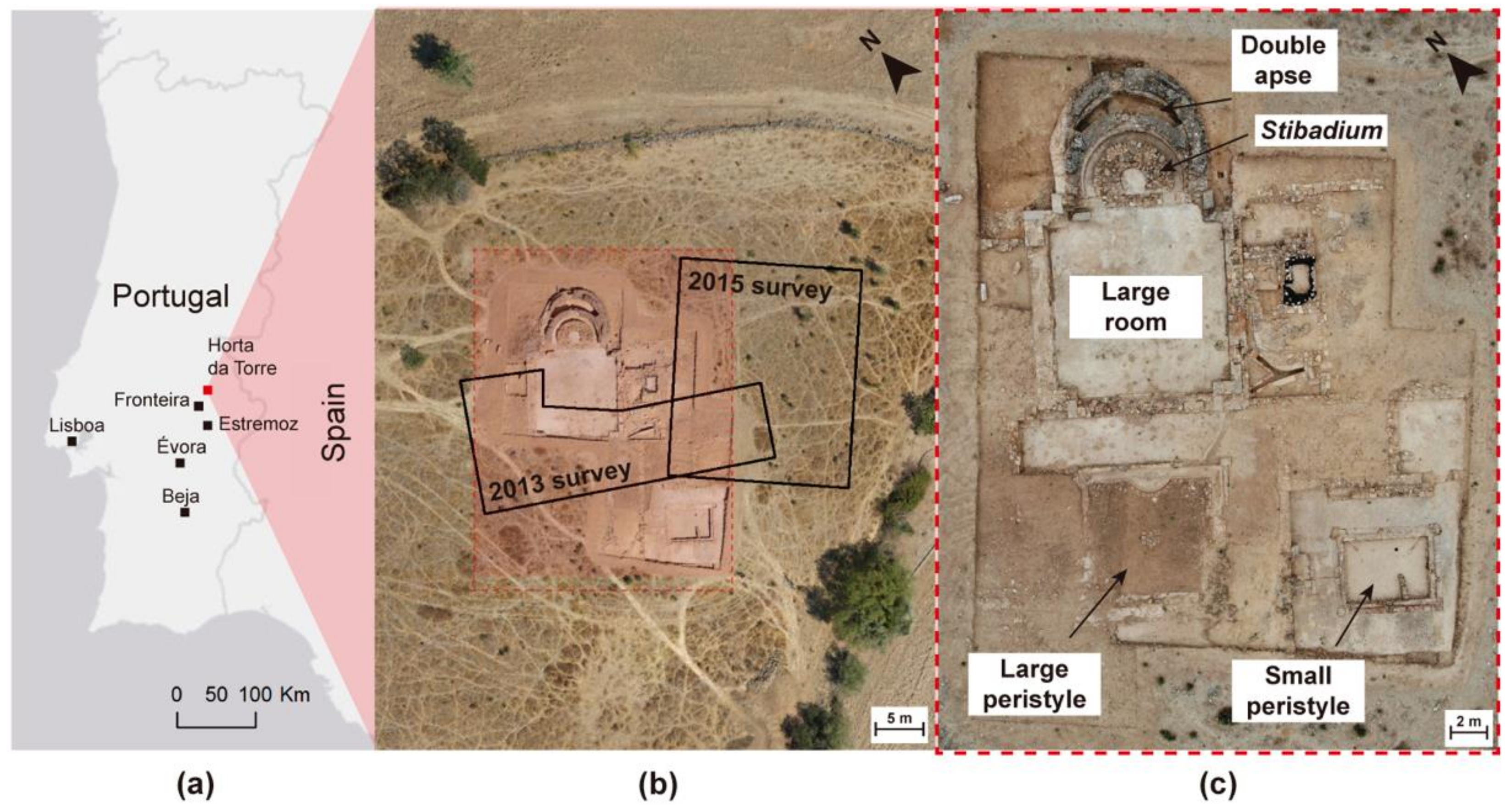
We created the algorithm based on the 2013 GPR data from the Roman villa of Horta da Torre. The survey with parallel B-scans spaced 0.25 m apart had an irregularly shaped area. The short distance between the B-scans gave the survey a high-density character, which increased the quality of the results. We performed several tests to determine the impact of data densification using this method. The evaluation of the results was performed by graphical analysis of depth slices at several depths and by calculating parameters such as the structural similarity index and sharpness index.
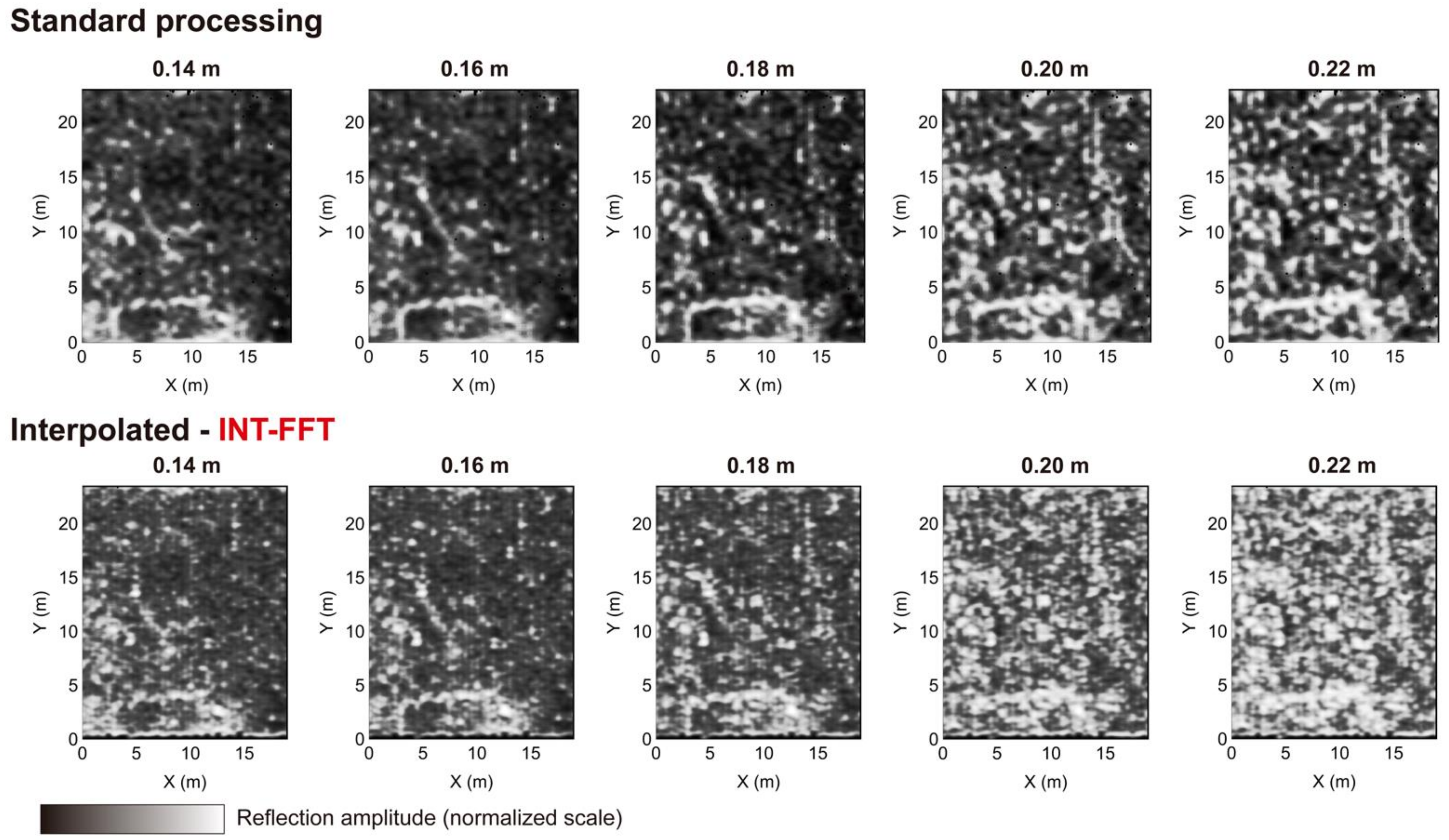
The first test aimed to study the efficiency of the proposed interpolation scheme by comparing the original data (C0) and the interpolated data (C1) after applying the standard processing flow to each one. The analysis of depth slices at several depths showed that the alignments of reflections became more defined and without the numerical artifacts produced by the interpolation. The mean value of the structural similarity index of this pair of results was 82.34%. The two datasets had similar characteristics, which were consistent with the depth slice analysis. The sharpness index increased from 11.44% (C0) to 15.30% (C1). We also note that the interpolated dataset showed an increase in brightness. This effect was related to the dispersion created by collapses. The interpolation of the B-scans estimated the signal corresponding to buried structures and the surrounding environment. It was not possible to prevent this from happening; however, we knew that it was possible to eliminate this effect by applying filters dedicated to noise removal.
The second test aimed to assess the missing information estimated after the data decimation, followed by interpolation by comparing the original data (C0) and the decimated and interpolated data (C2). Fourier interpolation allowed us to estimate the missing data. However, it could not replace these data in full. When the distance between the B-scans was too large, the antenna footprint of the side data was not able to detect the information in the location of the data to be interpolated. Therefore, graphically, we observed a decrease in the definition of some reflector alignments. The average value of the structural similarity index decreased to 64.15%. Both datasets were similar, but interpolation failed to estimate the part of the missing information in the original decimated B-scans without significant expression in the adjacent B-scans kept. The estimation efficiency depended greatly on the object size. Objects smaller than the spacing between the B-scans could hardly be estimated. The average sharpness index of the decimated and interpolated data (C2) decreased to 10.68%.
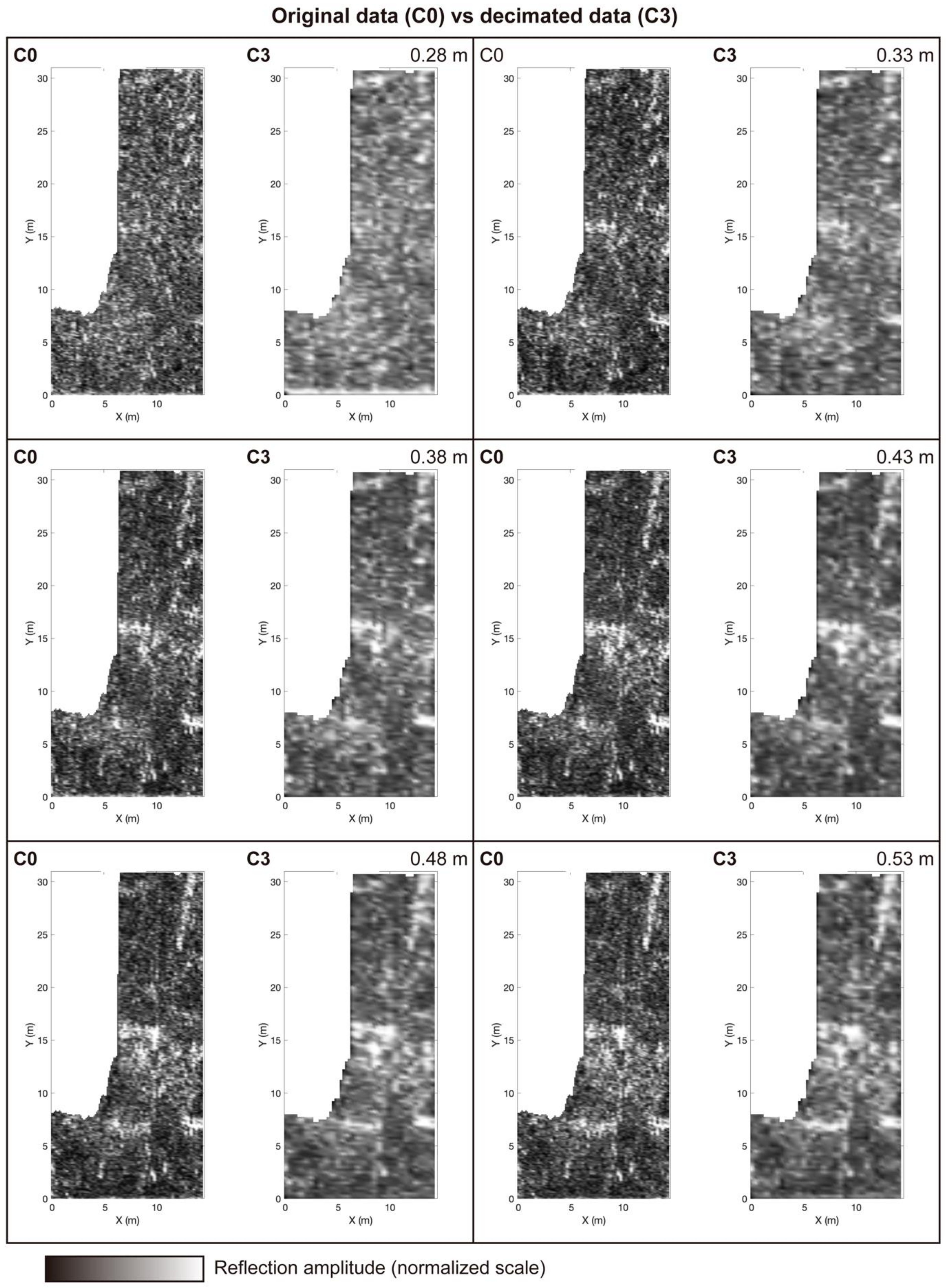
The third test evaluated the level of information lost when the spacing between the B-scans increased by comparing the results produced with the original data (C0) and those made with the decimated data (C3). The structural similarity index had an average value of 64.74%, identical to the previous comparison. We interpreted that the densification of very spaced B-scans could not estimate the missing data. However, the amount of information contained in the decimated dataset, compared to the original dataset, decreased considerably, especially the definition of the reflection alignments present in C0. The sharpness index for an average value fell to 8.63%. However, in the C3 case, the reflection alignments allowed the identification of alignments of reflections compatible with wall-type structures.
The fourth test compared the decimated data (C3) and the decimated and interpolated data (C2). The proposed interpolation method could estimate some missing information from the information contained in the existing B-scans. However, it could not estimate data when adjacent traces do not have lateral details. Therefore, the methodology may allow the sacrifice of the density of data acquired in the field. Nevertheless, it could be estimated in the processing step using the present interpolation technique applied in the frequency domain. However, this applies only under conditions where the objects to be detected have dimensions that allow them to be detected by adjacent B-scans. In addition, the increase in B-scan spacing may cause under-sampling that cannot be solved.
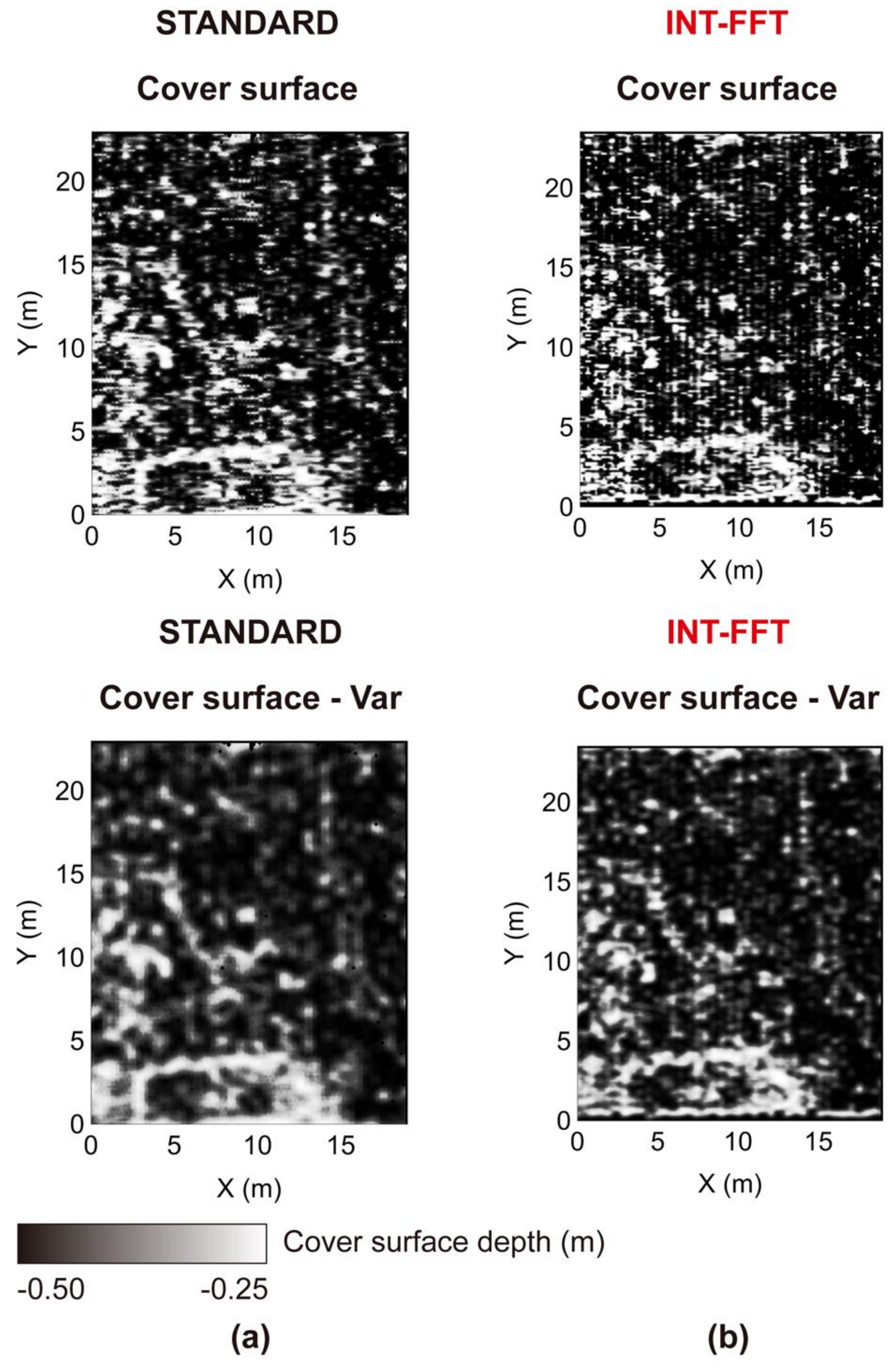
After applying the processing flow, we performed a final test on the 2013 GPR dataset by calculating the cover surfaces of the C0 and C1 datasets. Graphically, the C1 data became sharper than the existing reflection alignments. The value of the sharpness index increased from 13.37% to 26.19%. The cover surface showed that there was an increase in reflection alignments in the densified data. The brightness also increased, caused by the dispersions in the collapses. Overall, the result of the methodology in this dataset was better than the previous one.
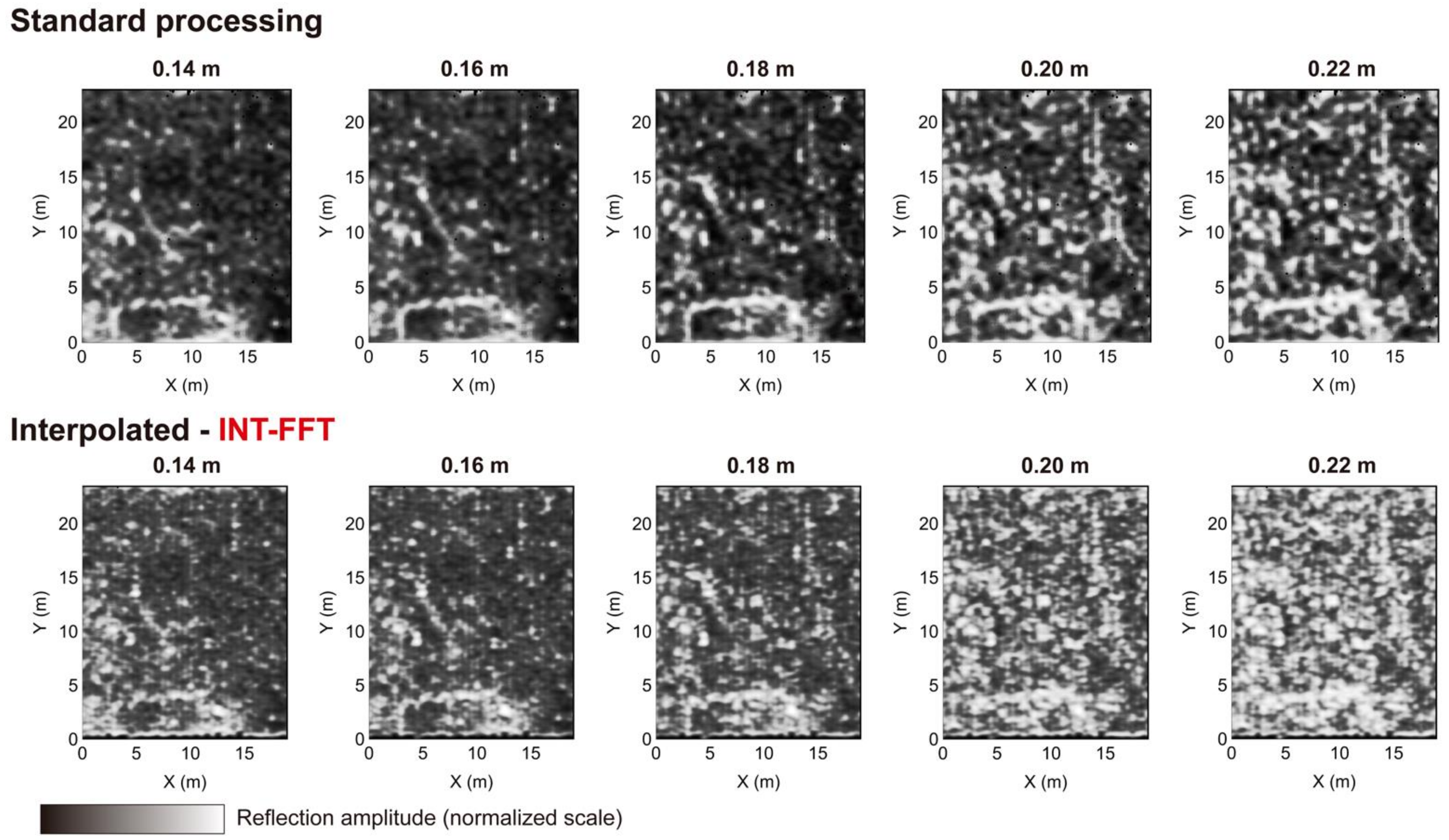
We also tested the INT-FFT algorithm on the GPR 2015 dataset obtained from the same archaeological site, with a B-scan spacing of 0.50 m. The results after standard processing flow showed reflection alignments that suggested the existence of buried structures of wall type, such as the 2013 dataset. However, the high spacing between the B-scans decreased the sharpness of the reflection alignments compared to the dense dataset. After applying the interpolation, the results showed an increase in the data density, making them sharper. The improvement was more accessible to understand by analyzing the cover surfaces obtained before and after the interpolation. The increase in the values of the sharpness index, from 21.03% to 27.19%, also supported this improvement. In these data, we also observed a striped effect in the direction of the B-scans (vertical). Using a directional filter to correct this effect allowed its elimination, improving the data.
The combination of GPR results and aerial orthophotos allowed us to increase the comprehension of the existence of buried structures at the site. In addition, it was possible to add interpretation schemes to highlight structures already excavated, and suggested structures only detected with GPR. Finally, this approach determined preferred directions that could help interpret the detected anomalies before proceeding with the excavation.
Despite the effectiveness of the approach, we noticed some limitations during the development of the method and the testing steps. Before the beginning of the interpolation process, the user must insert the locations of each B-scan. This step can be made by uploading a CSV file. However, the data input needs to be conducted by the user. This step implies a very well-defined knowledge of the geometry of data acquisition. Any failure of the geometric information promotes a lag of the interpolated B-scans that increases the striped effect on the interpolated outputs in the direction of the B-scans. This effect is not due to the Suinterp algorithm but to some misalignments of the B-scans, which, even with the utmost care, can occur, and maybe to the unevenness of the ground during the acquisition. This graphical effect can be successfully eliminated or reduced through a correction considering the semivariogram of the data. Another limitation is a possible slow implementation of the algorithm, even using robust hardware. The algorithm is optimized to implement the interpolation process iteratively with success. However, most of the algorithms consist of manipulating many data matrices. This process becomes slow even if the algorithm is optimized and requires the hardware to have enough memory for that much data to be loaded into memory at the same time.
Another limiting aspect refers to the parameters used to evaluate the interpolation methodology presented. Both are not the best parameters but are just a suggestion to analyze the data, different from what exists in standard software. The sharpness index is a measure that should be considered with caution since when estimating new GPR data, noise caused by the collapse of structures is also being interpolated. This effect is reflected in the increased brightness of the analyzed depth slices, as well as in the cover surface. However, the overall value of this index increases with the application of the methodology.
We also explored another aspect, determining the best processing step to implement B-scan interpolation. Its application was considered after completing the entire processing chain, although the results were not satisfactory. The best time to implement the INT-FFT algorithm is early with the raw data. This may be because the implemented interpolation is performed in the spectral domain, requiring that the frequency domain data have coherence. By applying some processing operations, such as filtering, the spectral content of the data changes.
The possible advantage of Fourier interpolation applied within each B-scan to increase the number of traces was also explored. This approach was successfully used in the GPR 2015 dataset along all B-scans, significantly improving the data obtained.
Considering all the aspects mentioned, we can verify that this interpolation scheme is effective in estimating profiles among the existing ones. We cannot say that this interpolation methodology is better than others since its application has a different premise from the others. Interpolation is applied to each trace, considering the adjacent traces. Spatial interpolation, performed in 2D, for example, in depth slices, is not capable of estimating information based on the spectral content of the data; it is performed at the pixel level, analyzing its neighborhood.
Regarding the use of this methodology to densify the GPR data and consequently increase the quality of the results, this improvement is expected to translate into a better understanding of reflection alignments that may correspond to buried structures. If the data are initially dense, this improvement will hardly be noticeable. In a scenario where the distance between B-scans is high but not too much to create under-sampling, densification will promote the sharpening of the results, and the user can be better guided to better interpret the results in the archaeological context.
The continuation of this study should focus on the complete automation of the iterative process, decreasing the user dependence, and optimizing the algorithm so that the computing time can be reduced.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}