
An Improved Apple Object Detection Method Based on Lightweight YOLOv4 in Complex Backgrounds


Abstract
:
1. Introduction
- Based on YOLOv4, a lightweight GhostNet is used as the feature extraction network. Depth-wise convolutions are introduced in the neck and YOLO head structures. In this way, the number of parameters in the model can be significantly reduced.
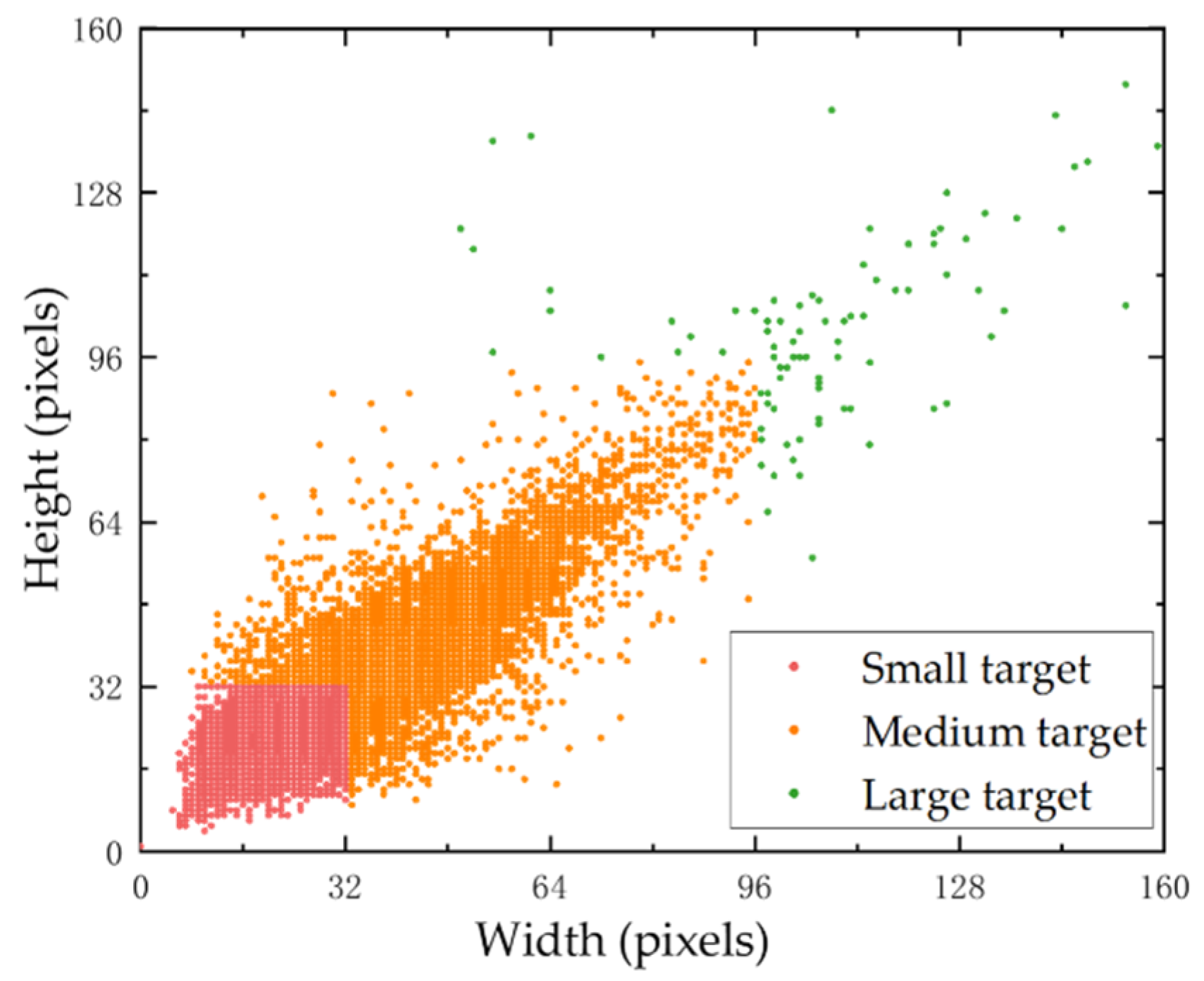
- Coordinate attention modules are added in the backbone, as well as before the 52 × 52 and 26 × 26 scale inputs of the FPN in the neck structure. The apple target detection capability of the model is enhanced, especially for targets with small- and medium-sized pixels.
- A screening strategy for long-range targets is proposed. The distant apples are screened out as not part of the harvestable target in the non-maximum suppression (NMS) stage. Thus, the detection efficiency is improved.
2. Related Work
2.1. Fruit Detection
2.2. Attention Mechanisms
2.3. Lightweight Models
3. Materials and Methods
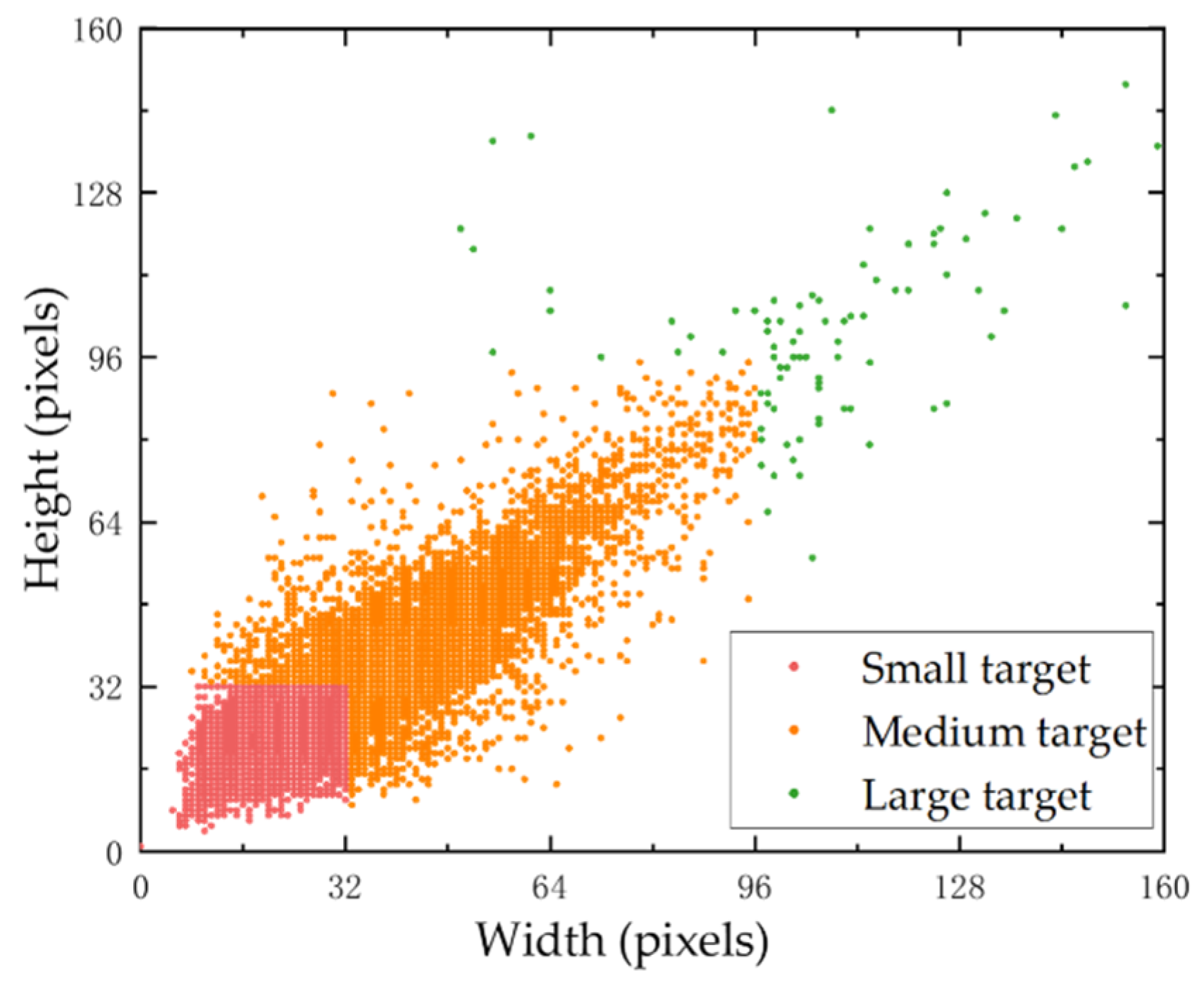
3.1. Introduction to the Data Set
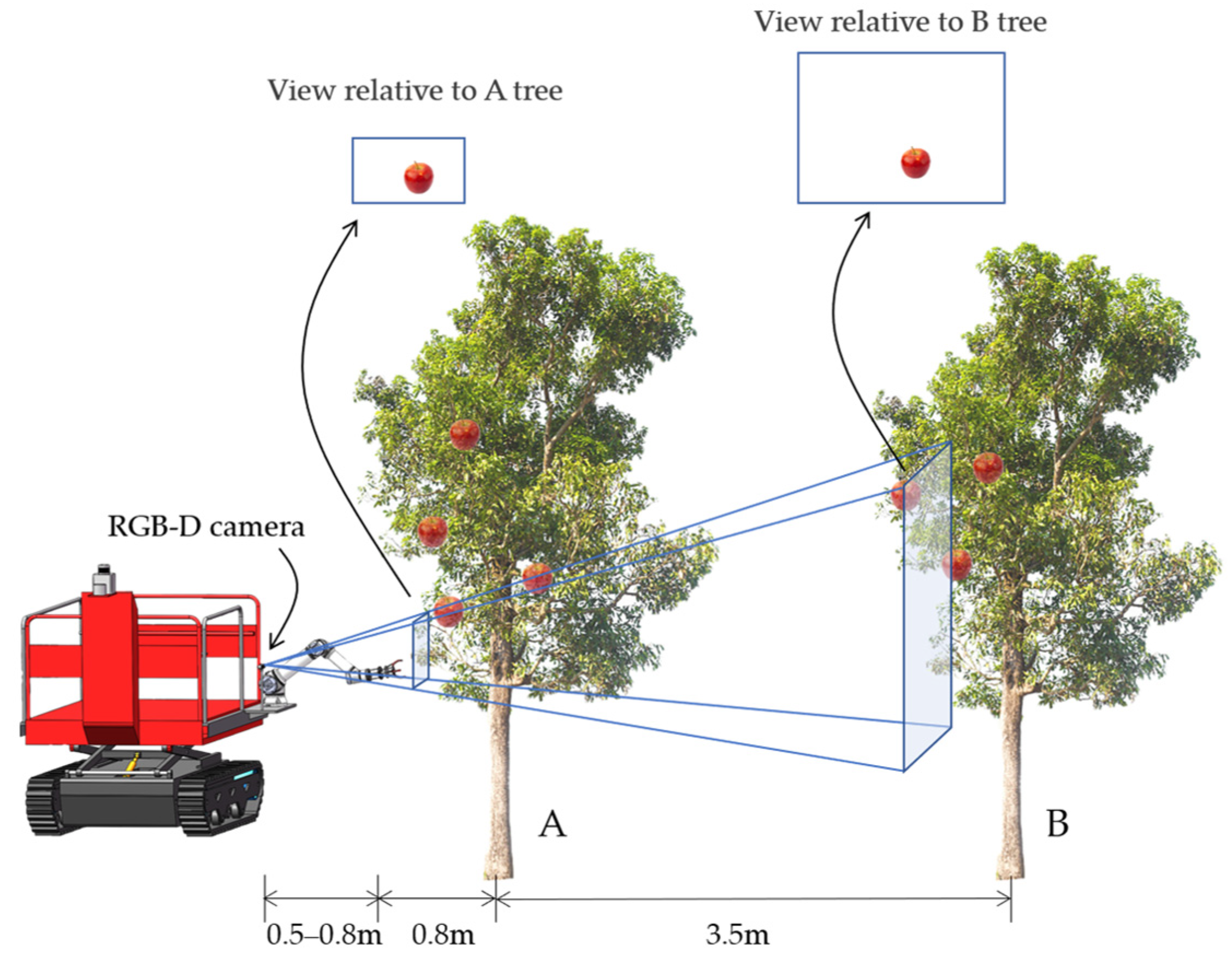
3.1.1. Image Acquisition
3.1.2. Data Set Production
3.1.3. Data Augmentation
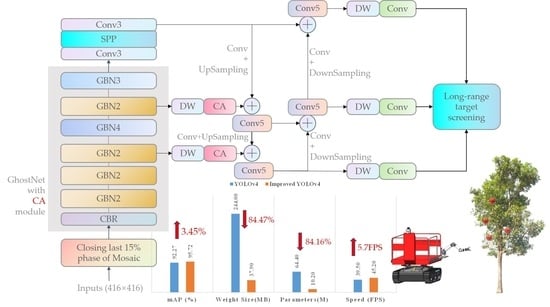
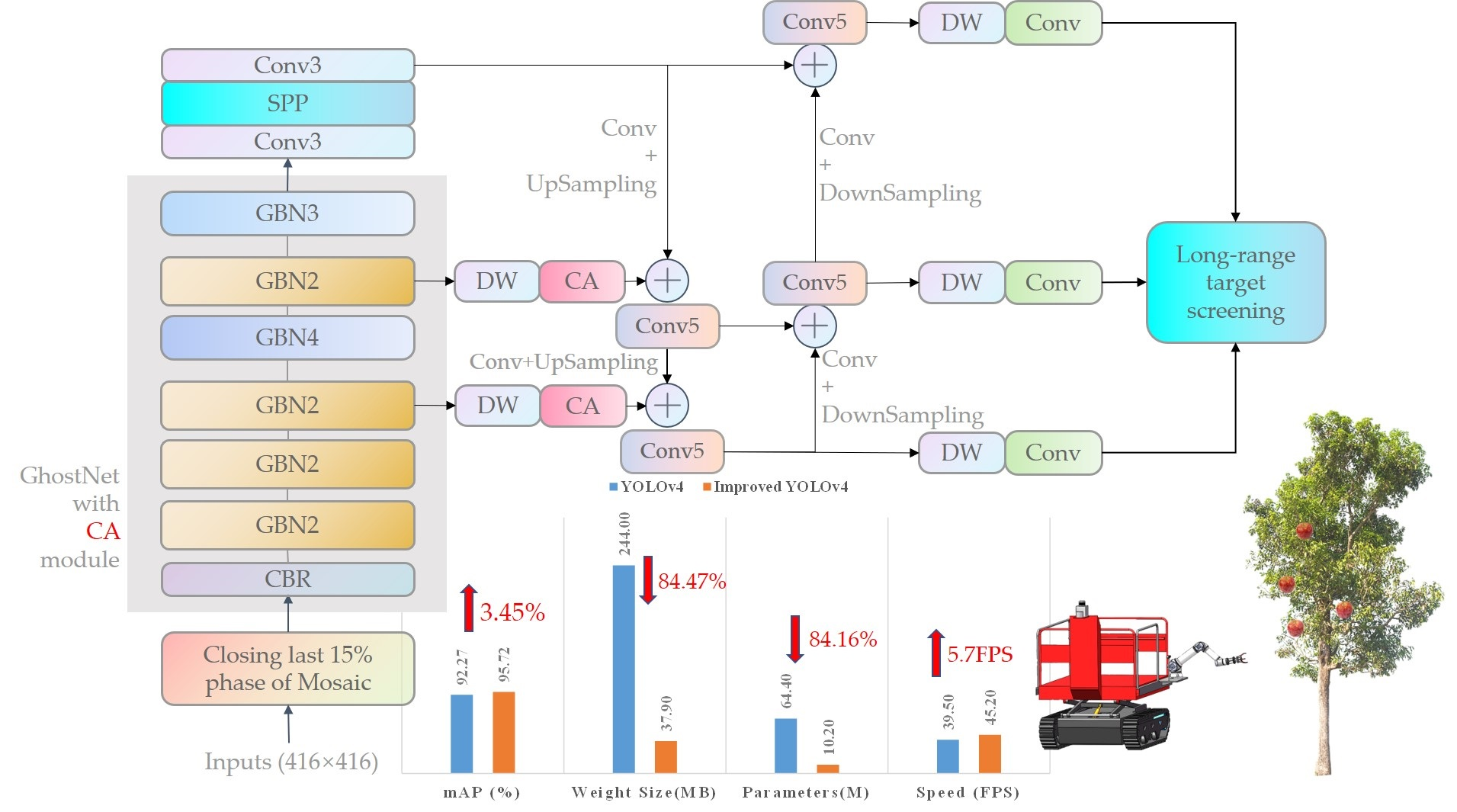
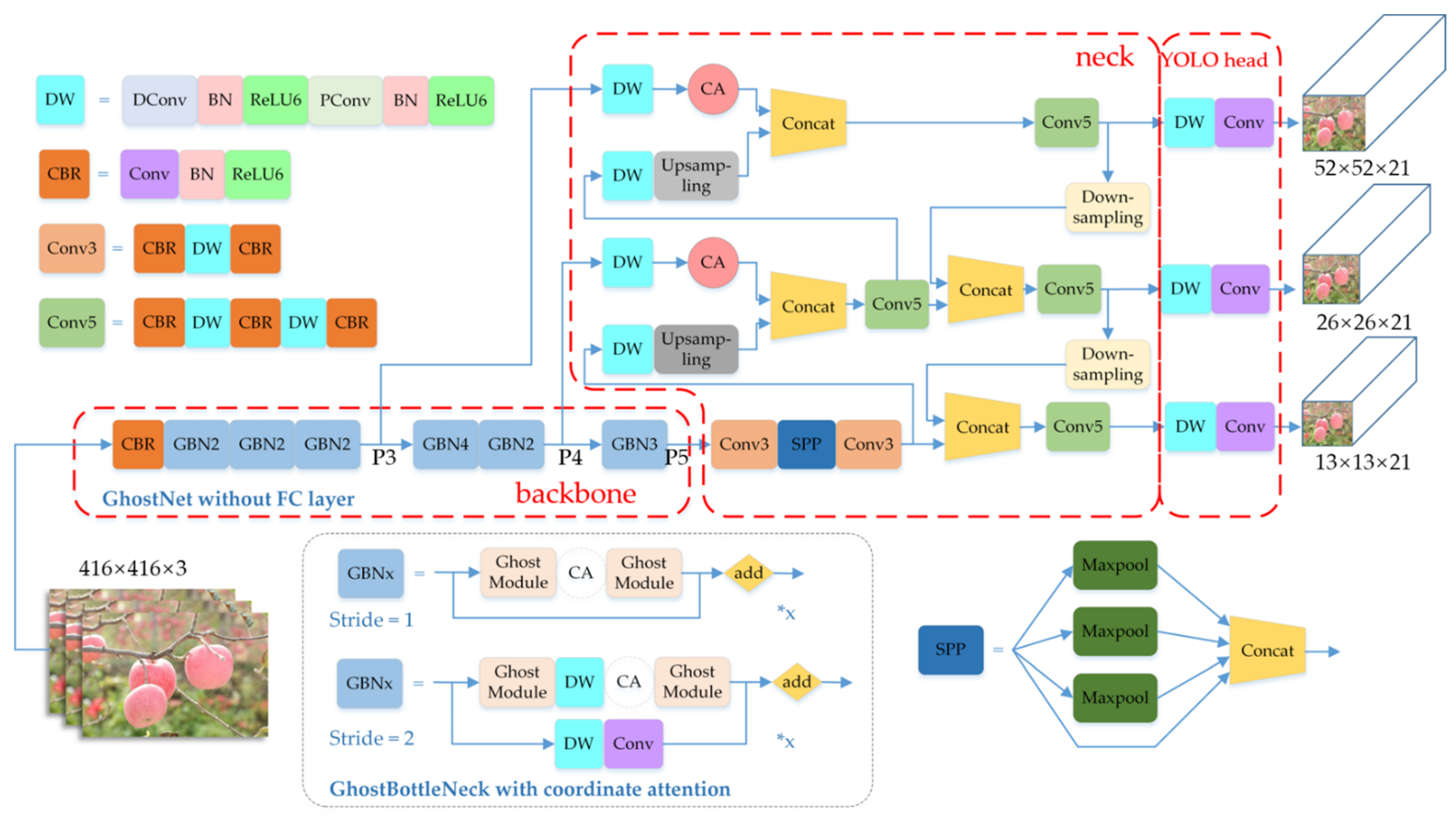
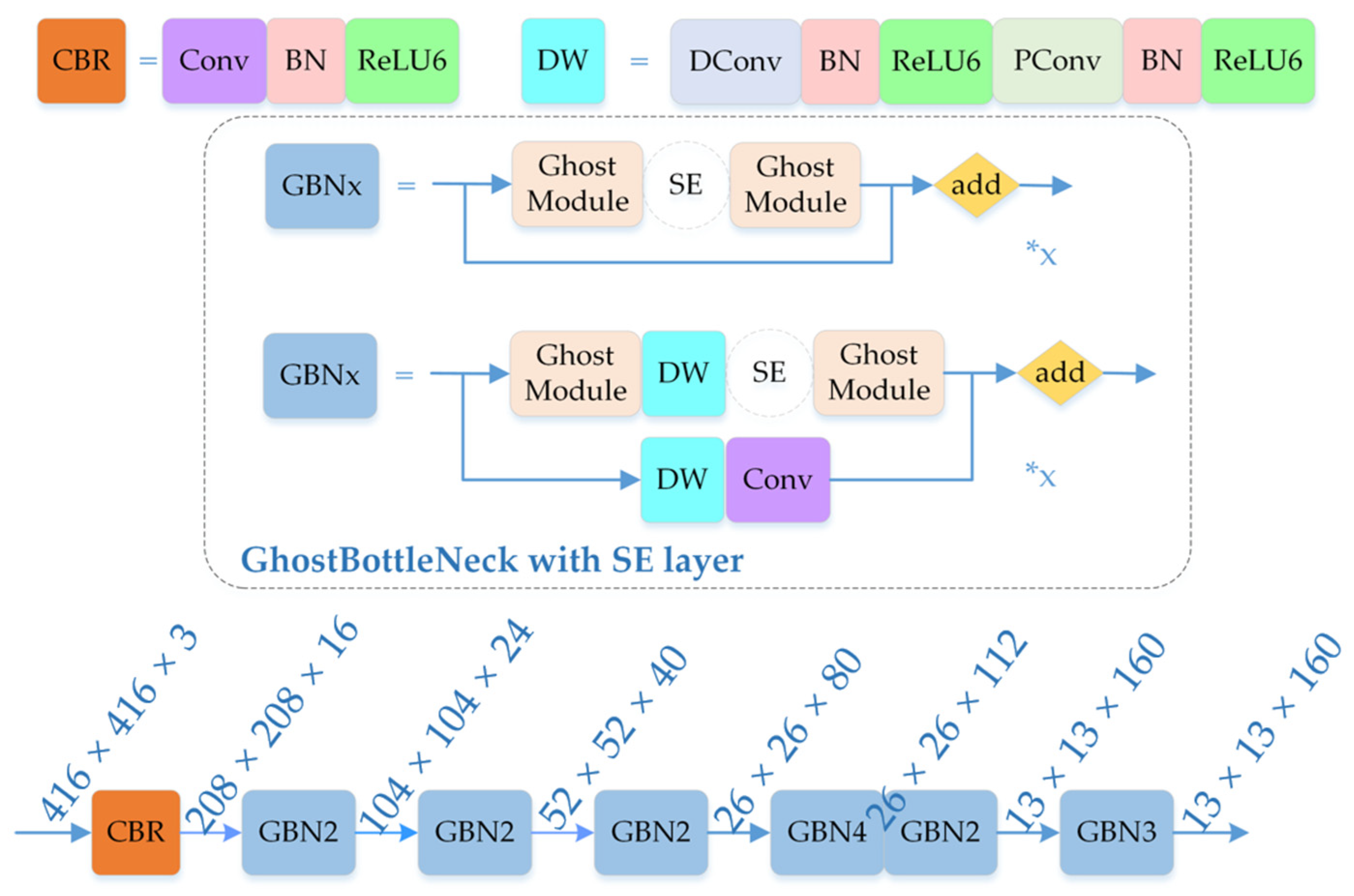
3.2. Framework of the Model
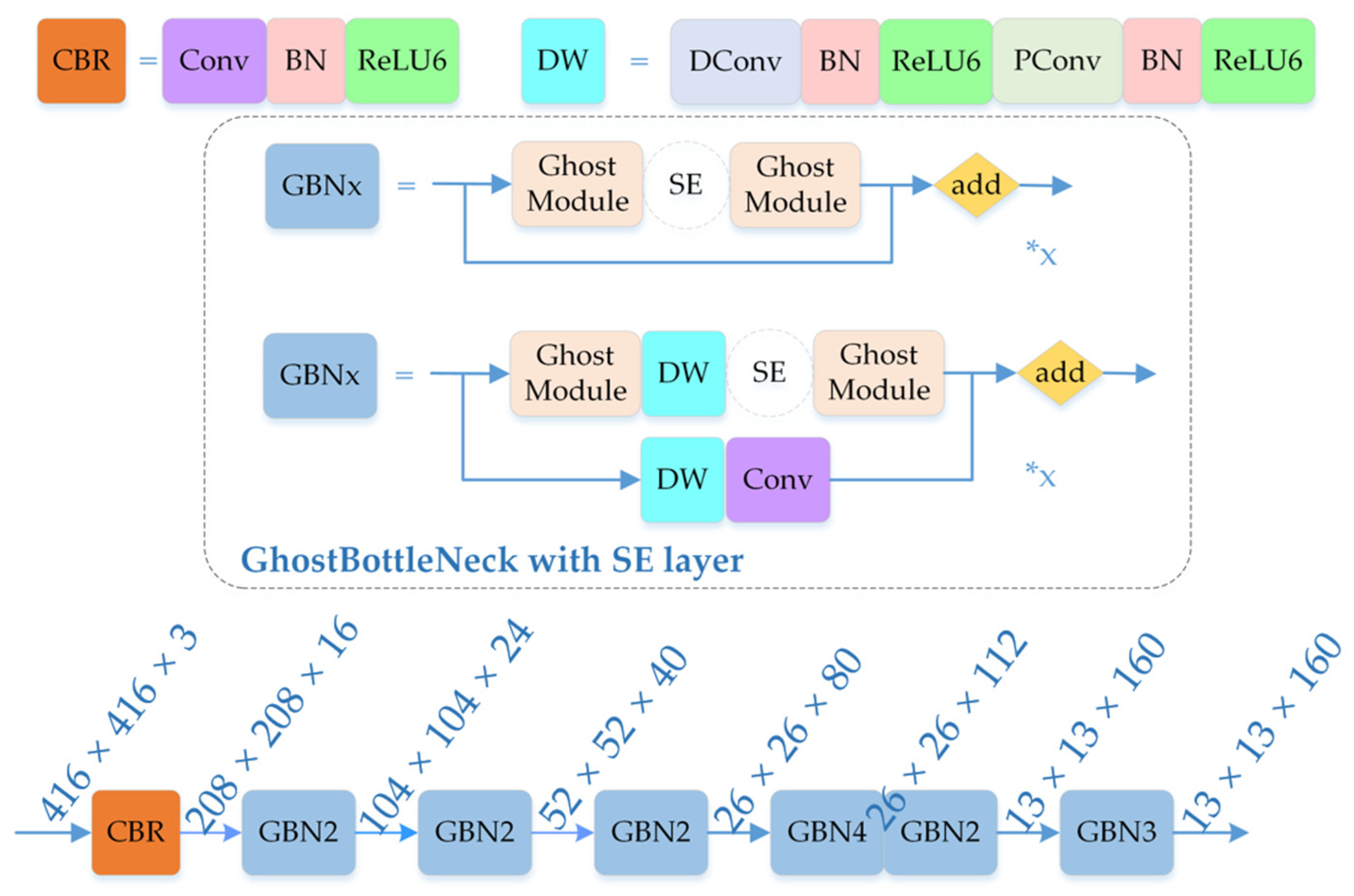
3.3. GhostNet Backbone Network
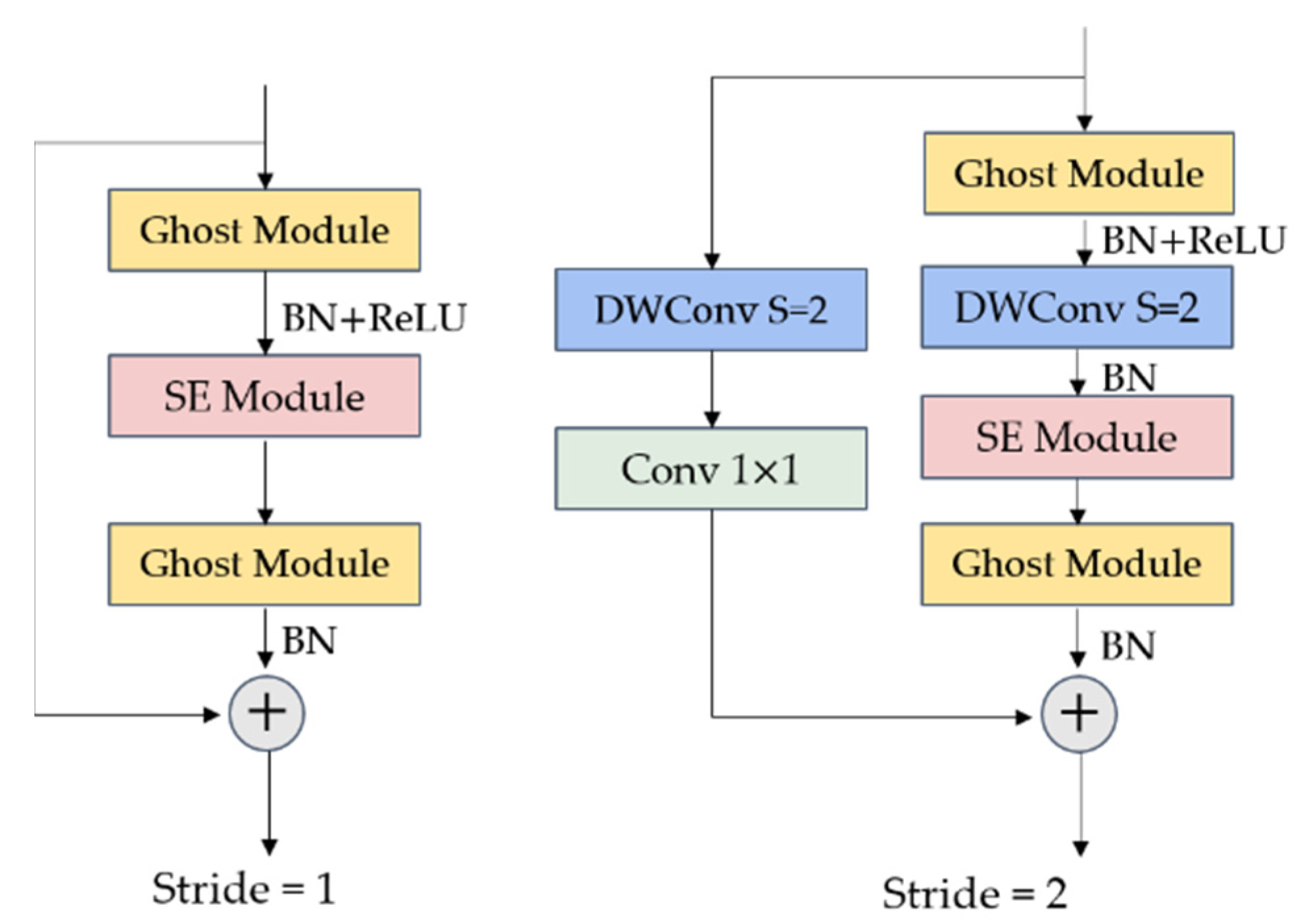
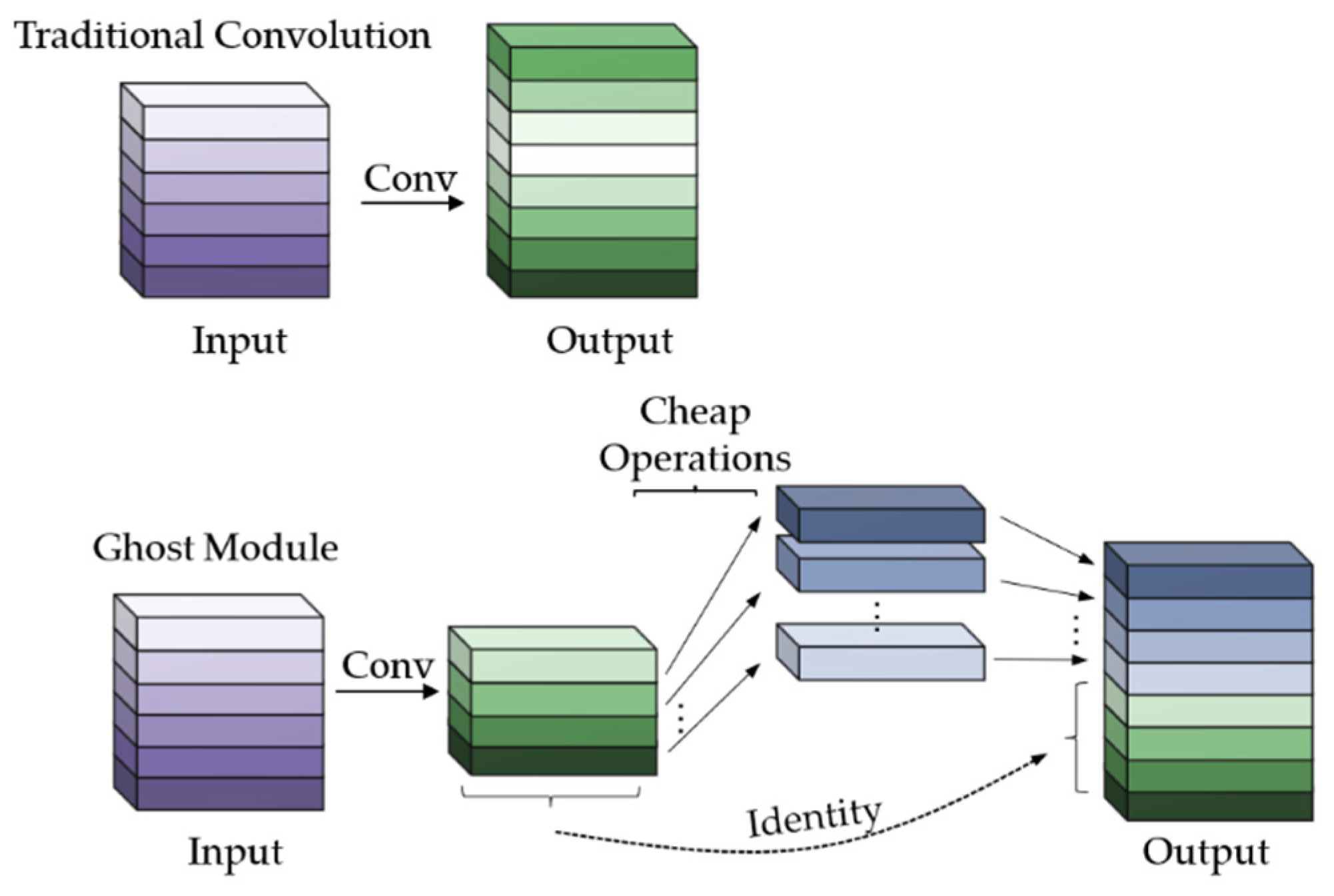
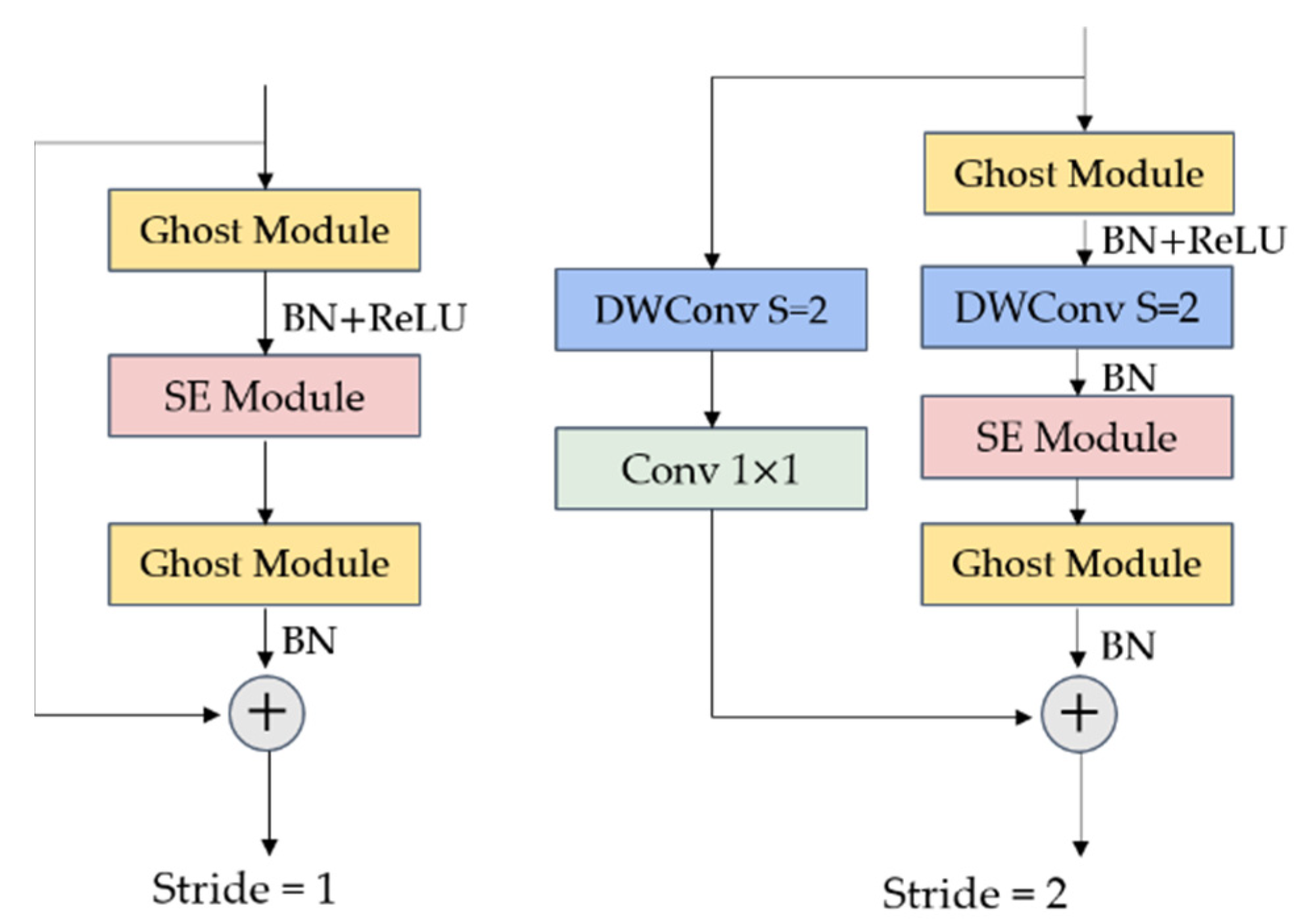
3.3.1. Ghost Convolution and Ghost Bottleneck Module
3.3.2. GhostNet
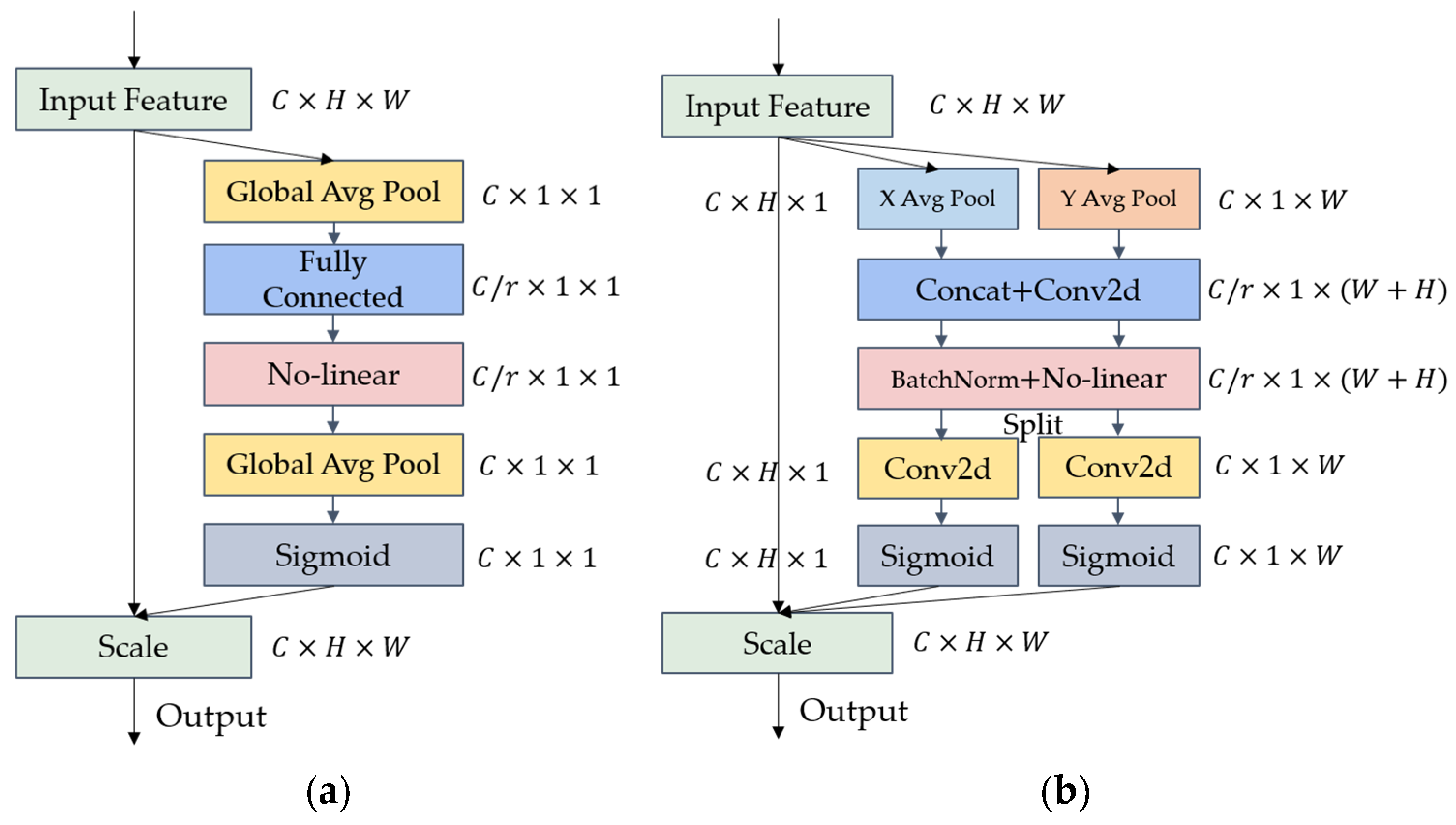
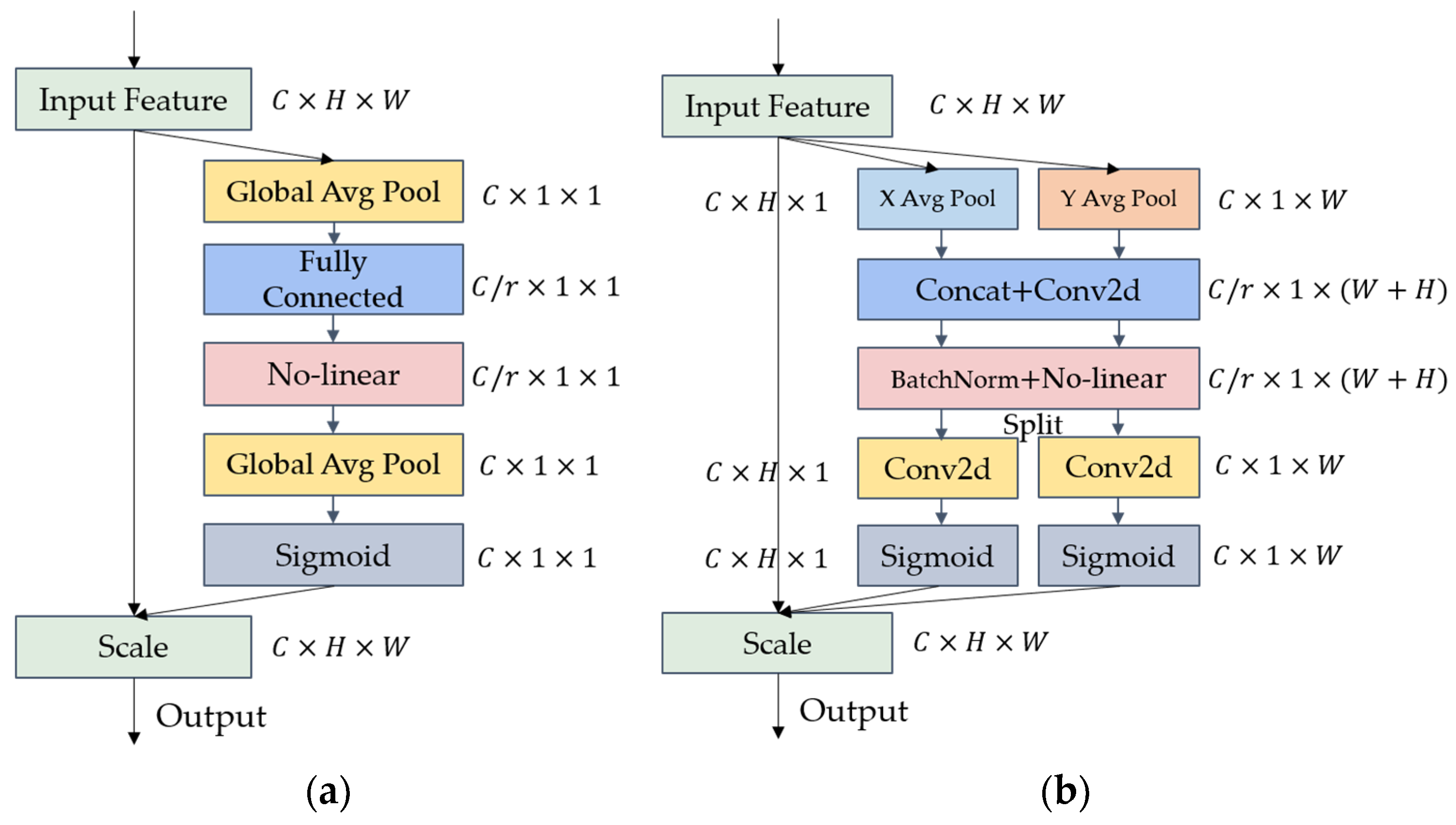
3.4. Coordinate Attention
3.5. Mosaic Closing Early Strategy
3.6. Long-Range Target Screening
4. Results
4.1. Experimental Environment
4.2. Model Evaluation Metrics
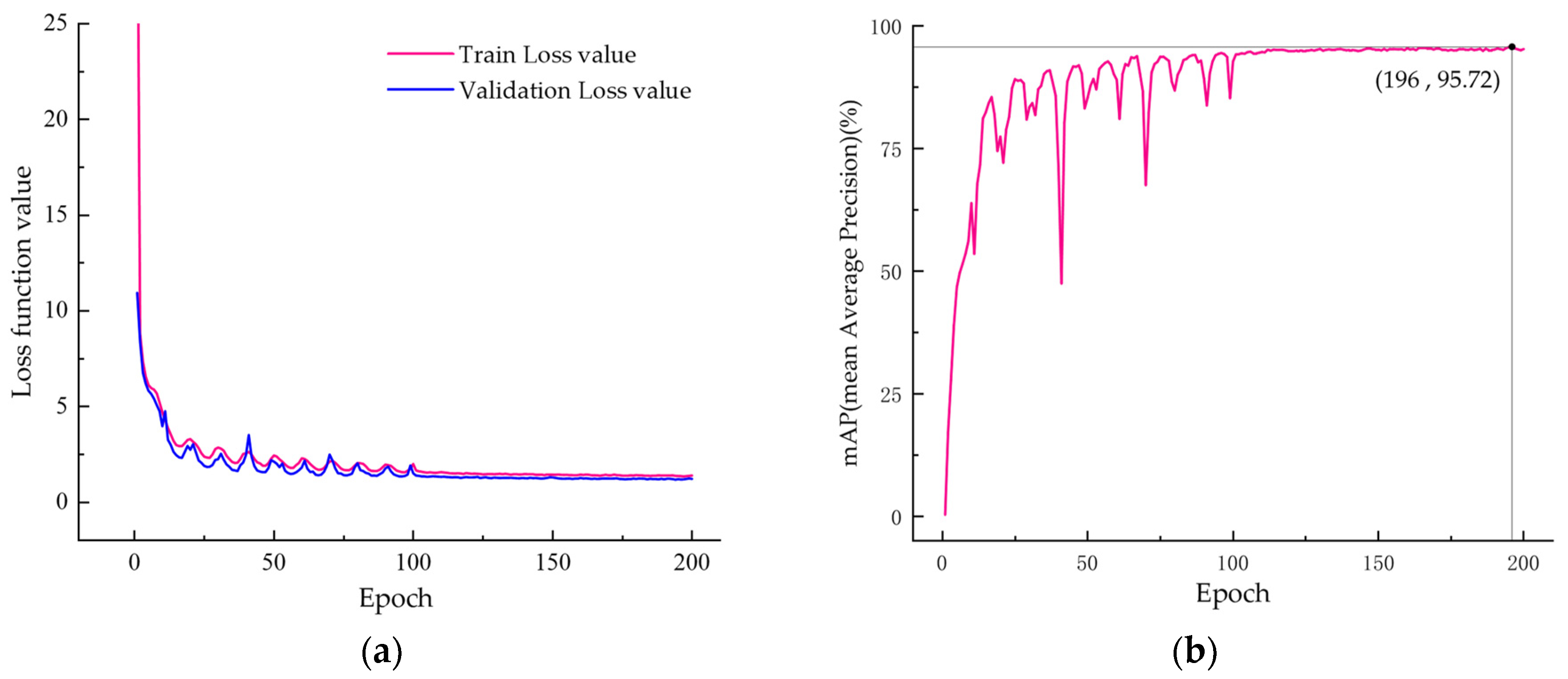
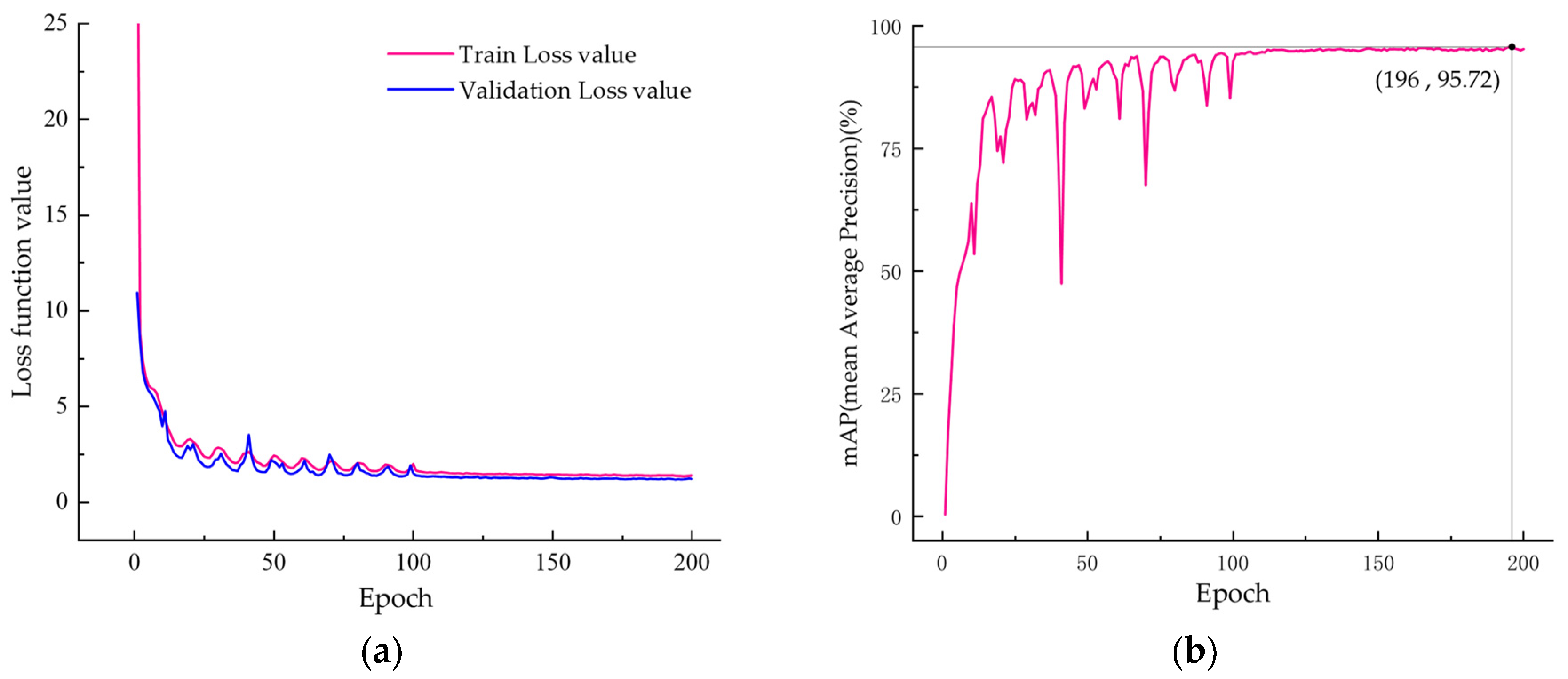
4.3. Experimental Results
4.3.1. Ablation Experiments
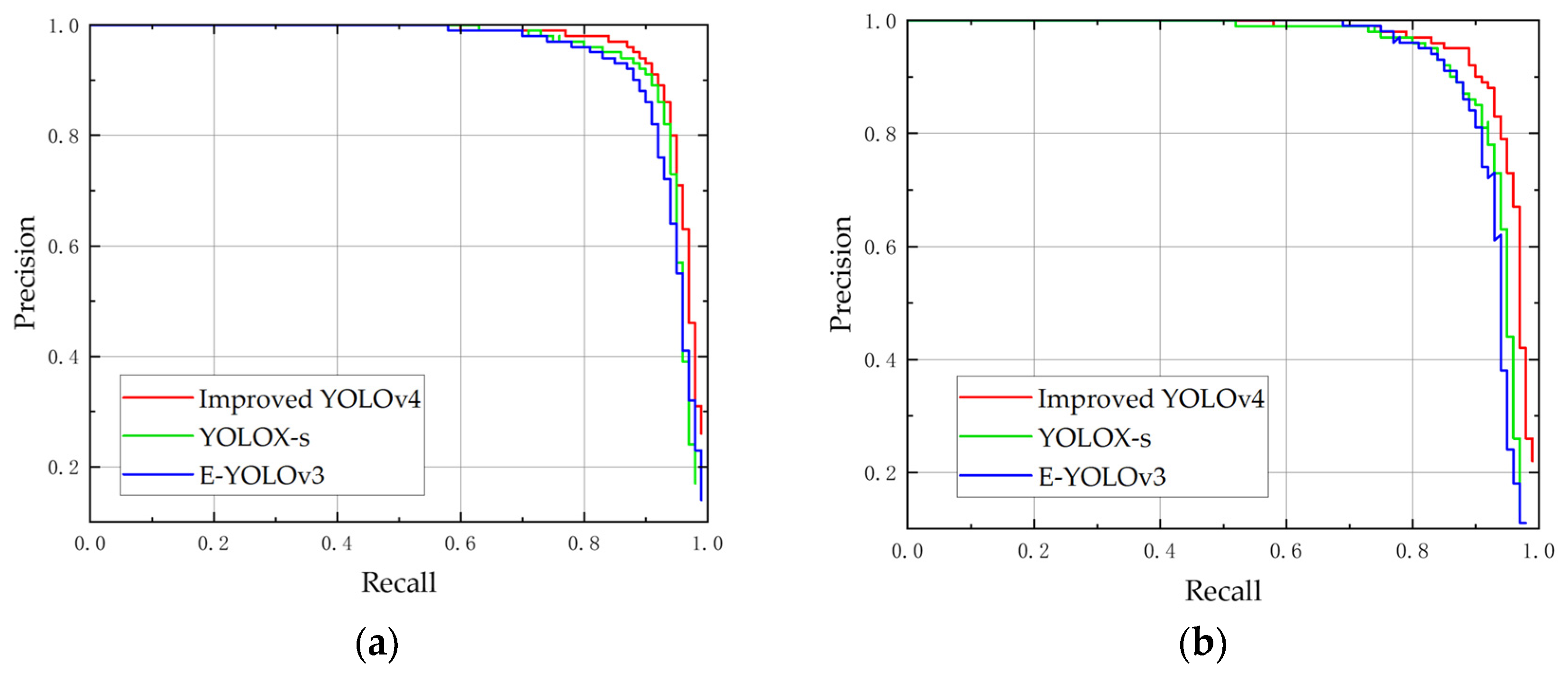
4.3.2. Comparison Experiment of the Same Type of Object Detection Algorithm
Comparison Experiments in the Total Test Set
Comparative Experiments with Different Illumination Conditions
4.3.3. Validation for the Improvement of Small and Medium Target Recognition Capability
4.3.4. Validation Experiments on Target Screening Strategy
5. Discussion
5.1. Improved YOLOv4
5.2. Algorithm Comparison
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Li, T.; Feng, Q.; Qiu, Q.; Xie, F.; Zhao, C. Occluded Apple Fruit Detection and Localization with a Frustum-Based Point-Cloud-Processing Approach for Robotic Harvesting. Remote Sens. 2022, 14, 482. [Google Scholar] [CrossRef]
- Jia, W.; Tian, Y.; Luo, R.; Zhang, Z.; Lian, J.; Zheng, Y. Detection and Segmentation of Overlapped Fruits Based on Optimized Mask R-CNN Application in Apple Harvesting Robot. Comput. Electron. Agric. 2020, 172, 105380. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 Algorithm with Pre- and Post-Processing for Apple Detection in Fruit-Harvesting Robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Li, J.; Xiong, J. In-Field Citrus Detection and Localisation Based on RGB-D Image Analysis. Biosyst. Eng. 2019, 186, 34–44. [Google Scholar] [CrossRef]
- Fan, P.; Lang, G.; Yan, B.; Lei, X.; Guo, P.; Liu, Z.; Yang, F. A Method of Segmenting Apples Based on Gray-Centered RGB Color Space. Remote Sens. 2021, 13, 1211. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Proceedings of the 25th International Conference on Neural Information Processing Systems—Volume 1; Curran Associates Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Williams, H.A.M.; Jones, M.H.; Nejati, M.; Seabright, M.J.; Bell, J.; Penhall, N.D.; Barnett, J.J.; Duke, M.D.; Scarfe, A.J.; Ahn, H.S.; et al. Robotic Kiwifruit Harvesting Using Machine Vision, Convolutional Neural Networks, and Robotic Arms. Biosyst. Eng. 2019, 181, 140–156. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. arXiv 2014, arXiv:1311.2524. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; He, X.; Ge, X.; Wu, X.; Shen, J.; Song, Y. Detection of Key Organs in Tomato Based on Deep Migration Learning in a Complex Background. Agriculture 2018, 8, 196. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; He, L.; Karkee, M.; Zhang, Q.; Zhang, X.; Gao, Z. Branch Detection for Apple Trees Trained in Fruiting Wall Architecture Using Depth Features and Regions-Convolutional Neural Network (R-CNN). Comput. Electron. Agric. 2018, 155, 386–393. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J. Deep Fruit Detection in Orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3626–3633. [Google Scholar]
- Grilli, E.; Battisti, R.; Remondino, F. An Advanced Photogrammetric Solution to Measure Apples. Remote Sens. 2021, 13, 3960. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2016, arXiv:1512.02325. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple Detection during Different Growth Stages in Orchards Using the Improved YOLO-V3 Model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Lu, S.; Chen, W.; Zhang, X.; Karkee, M. Canopy-Attention-YOLOv4-Based Immature/Mature Apple Fruit Detection on Dense-Foliage Tree Architectures for Early Crop Load Estimation. Comput. Electron. Agric. 2022, 193, 106696. [Google Scholar] [CrossRef]
- Li, X.; Pan, J.; Xie, F.; Zeng, J.; Li, Q.; Huang, X.; Liu, D.; Wang, X. Fast and Accurate Green Pepper Detection in Complex Backgrounds via an Improved Yolov4-Tiny Model. Comput. Electron. Agric. 2021, 191, 106503. [Google Scholar] [CrossRef]
- Liu, M.; Jia, W.; Wang, Z.; Niu, Y.; Yang, X.; Ruan, C. An Accurate Detection and Segmentation Model of Obscured Green Fruits. Comput. Electron. Agric. 2022, 197, 106984. [Google Scholar] [CrossRef]
- Sun, Q.; Chai, X.; Zeng, Z.; Zhou, G.; Sun, T. Noise-Tolerant RGB-D Feature Fusion Network for Outdoor Fruit Detection. Comput. Electron. Agric. 2022, 198, 107034. [Google Scholar] [CrossRef]
- Li, W.; Feng, X.S.; Zha, K.; Li, S.; Zhu, H.S. Summary of Target Detection Algorithms. J. Phys. Conf. Ser. 2021, 1757, 012003. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 19 June 2020; pp. 11531–11539. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. arXiv 2021, arXiv:2103.02907. [Google Scholar]
- Han, L.; Zhao, Y.; Lv, H.; Zhang, Y.; Liu, H.; Bi, G. Remote Sensing Image Denoising Based on Deep and Shallow Feature Fusion and Attention Mechanism. Remote Sens. 2022, 14, 1243. [Google Scholar] [CrossRef]
- Kim, M.; Jeong, J.; Kim, S. ECAP-YOLO: Efficient Channel Attention Pyramid YOLO for Small Object Detection in Aerial Image. Remote Sens. 2021, 13, 4851. [Google Scholar] [CrossRef]
- Jia, W.; Zhang, Z.; Shao, W.; Ji, Z.; Hou, S. RS-Net: Robust Segmentation of Green Overlapped Apples. Precis. Agric. 2022, 23, 492–513. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2019, arXiv:1801.04381. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. arXiv 2017, arXiv:1707.01083. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:1807.11164. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets. arXiv 2017, arXiv:1608.08710. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2017, arXiv:1610.02357. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Wu, L.; Ma, J.; Zhao, Y.; Liu, H. Apple Detection in Complex Scene Using the Improved YOLOv4 Model. Agronomy 2021, 11, 476. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Fruits 360. Available online: https://www.kaggle.com/datasets/moltean/fruits (accessed on 20 June 2022).
- Zhao, S.; Zhang, S.; Lu, J.; Wang, H.; Feng, Y.; Shi, C.; Li, D.; Zhao, R. A Lightweight Dead Fish Detection Method Based on Deformable Convolution and YOLOV4. Comput. Electron. Agric. 2022, 198, 107098. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An Attentive Survey of Attention Models. ACM Trans. Intell. Syst. Technol. (TIST) 2021, 12, 1–32. [Google Scholar] [CrossRef]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention Mechanisms in Computer Vision: A Survey. Comp. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Hao, J.; Li, X.; Yan, X.; Fen, J.; Suo, X. Apple Dwarf Rootstock Dense Planting and Rootstock Combination. Hebei Fruits 2021, 3, 27–28+30. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Set | Front Light | Side Light | Back Light | Total |
|---|---|---|---|---|
| Number of images | 60 | 60 | 60 | 180 |
| Number of ripe apples | 511 | 386 | 393 | 1290 |
| Number of unripe apples | 179 | 206 | 149 | 534 |
| Environment | Versions or Model Number |
|---|---|
| CPU | AMD Ryzen 5 3600X, 3.80 GHz |
| GPU | NVIDIA RTX 3060Ti, 8 GB memory |
| OS | Windows 10 |
| CUDA | CUDA 11.3 |
| PyTorch | v1.10 |
| Python | v3.8 |
| No. | Model | mAP (%) (*, *) | Weight Size (MB) (*) | Parameters (M) (*) | Speed (FPS) (*, *) |
|---|---|---|---|---|---|
| 1 | YOLOv4 baseline | 92.27 | 244.00 | 64.40 | 39.50 |
| 2 | +GhostNet | 93.83 (+1.56, +1.56) | 150.00 (61.48%) | 39.70 (61.65%) | 42.10 (+2.60, +2.60) |
| 3 | +Depth-wise separable convolution | 94.00 (+1.73, +0.17) | 42.50 (17.42%) | 11.40 (17.70%) | 44.50 (+5.00, +2.40) |
| 4 | +Coordinate Attention | 94.48 (+2.21, +0.48) | 37.80 (15.49%) | 10.20 (15.84%) | 45.30 (+5.80, +0.80) |
| 5 | +Improving S&M target detection | 94.77 (+2.50, +0.29) | 37.90 (15.53%) | 10.20 (15.84%) | 45.20 (+5.70, −0.10) |
| 6 | +Closing last 15% phase of Mosaic | 94.97 (+2.70, +0.20) | 37.90 (15.53%) | 10.20 (15.84%) | 45.10 (+5.60, −0.10) |
| 7 | +Long-range target screening | 95.72 (+3.45, +0.75) | 37.90 (15.53%) | 10.20 (15.84%) | 45.20 (+5.70, +0.10) |
| Model | Weight Size (MB) | mAP (%) | AP1 (%) | AP2 (%) | F1 | Precision (%) | Recall (%) | Speed (FPS) |
|---|---|---|---|---|---|---|---|---|
| YOLOX-s | 34.3 | 93.90 | 94.46 | 93.34 | 0.90 | 93.13 | 86.65 | 52.3 |
| E-YOLO v3 | 40.6 | 93.39 | 94.13 | 92.65 | 0.89 | 94.08 | 84.43 | 49.2 |
| Improved YOLOv4 | 37.9 | 95.72 | 95.91 | 95.54 | 0.91 | 95.32 | 86.54 | 45.2 |
| Illumination Condition | Model | mAP (%) (*) | F1 | Precision (%) | Recall (%) |
|---|---|---|---|---|---|
| Front light | YOLOX-s | 93.90 (−1.82) | 0.90 | 93.13 | 86.65 |
| E-YOLO v3 | 93.39 (−2.33) | 0.89 | 94.07 | 84.43 | |
| Improved YOLOv4 | 95.72 | 0.91 | 95.32 | 86.54 | |
| Side light | YOLOX-s | 94.33 (−1.66) | 0.89 | 91.90 | 86.36 |
| E-YOLO v3 | 94.02 (−1.97) | 0.90 | 94.43 | 84.88 | |
| Improved YOLOv4 | 95.99 | 0.91 | 94.78 | 86.74 | |
| Back light | YOLOX-s | 93.21 (−2.18) | 0.88 | 92.17 | 84.12 |
| E-YOLO v3 | 92.27 (−3.12) | 0.88 | 93.26 | 83.54 | |
| Improved YOLOv4 | 95.39 | 0.90 | 94.73 | 85.47 |
| Model | APS (%) | APM (%) | APL (%) | ARS (%) | ARM (%) | ARL (%) |
|---|---|---|---|---|---|---|
| Model 1 | 0.170 | 0.540 | 0.681 | 0.335 | 0.618 | 0.730 |
| Model 4 | 0.162 | 0.552 | 0.718 | 0.347 | 0.631 | 0.763 |
| Model 5 | 0.181 | 0.560 | 0.713 | 0.356 | 0.642 | 0.758 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Kang, F.; Wang, Y. An Improved Apple Object Detection Method Based on Lightweight YOLOv4 in Complex Backgrounds. Remote Sens. 2022, 14, 4150. https://doi.org/10.3390/rs14174150
Zhang C, Kang F, Wang Y. An Improved Apple Object Detection Method Based on Lightweight YOLOv4 in Complex Backgrounds. Remote Sensing. 2022; 14(17):4150. https://doi.org/10.3390/rs14174150
Chicago/Turabian StyleZhang, Chenxi, Feng Kang, and Yaxiong Wang. 2022. "An Improved Apple Object Detection Method Based on Lightweight YOLOv4 in Complex Backgrounds" Remote Sensing 14, no. 17: 4150. https://doi.org/10.3390/rs14174150
APA StyleZhang, C., Kang, F., & Wang, Y. (2022). An Improved Apple Object Detection Method Based on Lightweight YOLOv4 in Complex Backgrounds. Remote Sensing, 14(17), 4150. https://doi.org/10.3390/rs14174150