
Built-Up Area Extraction from GF-3 SAR Data Based on a Dual-Attention Transformer Model

 , , , ,
, , , ,
Abstract
:
1. Introduction
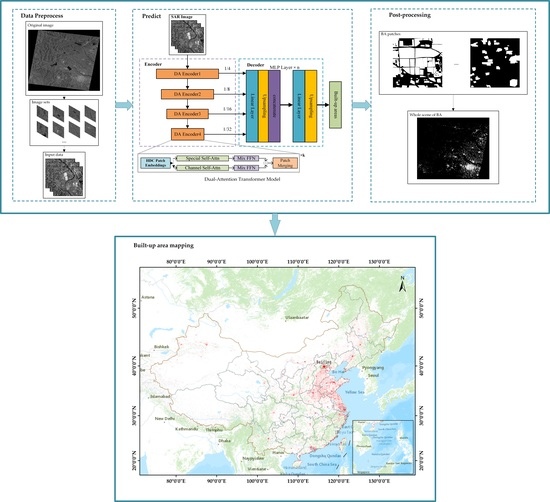
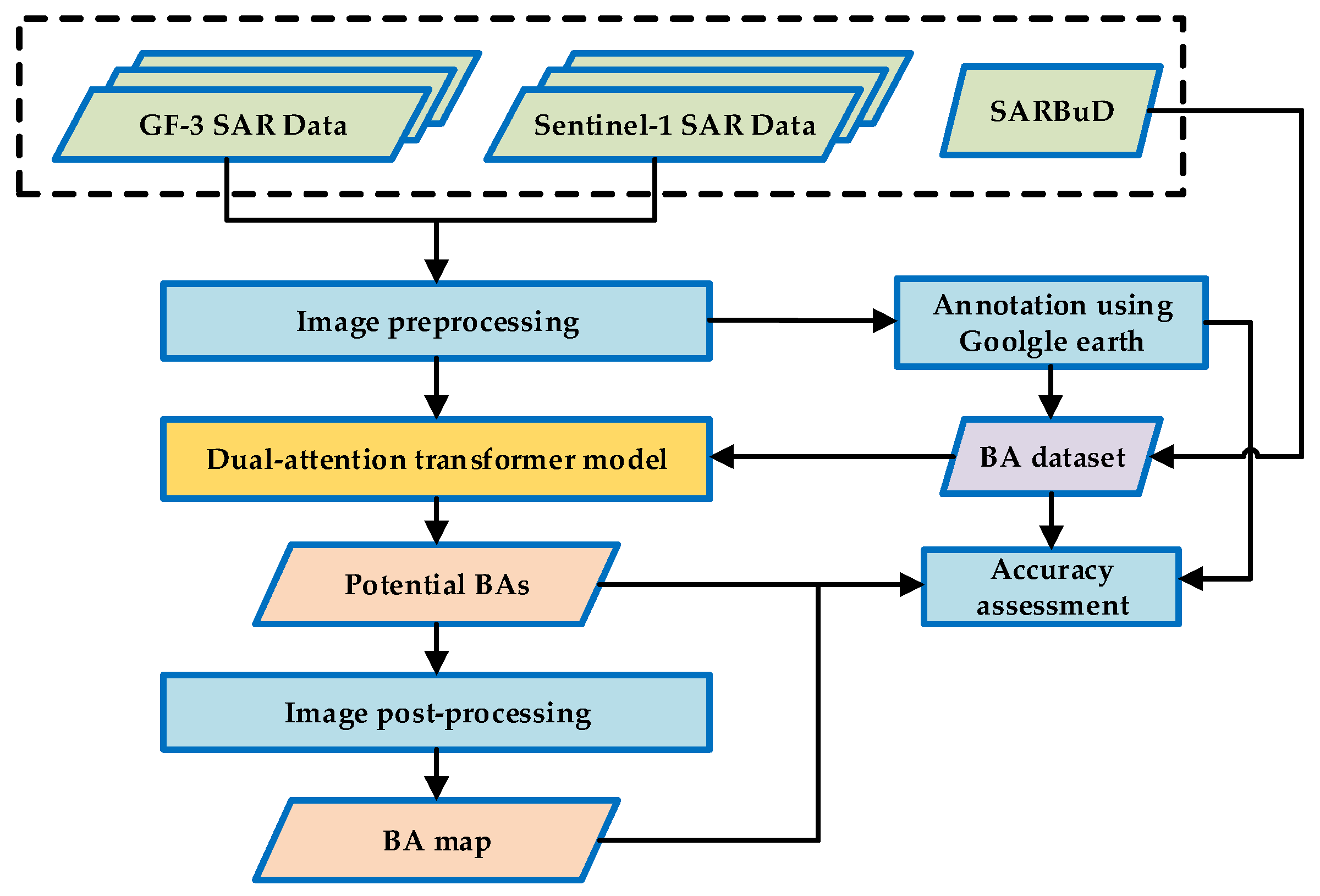
2. Methodology
2.1. Image Preprocessing
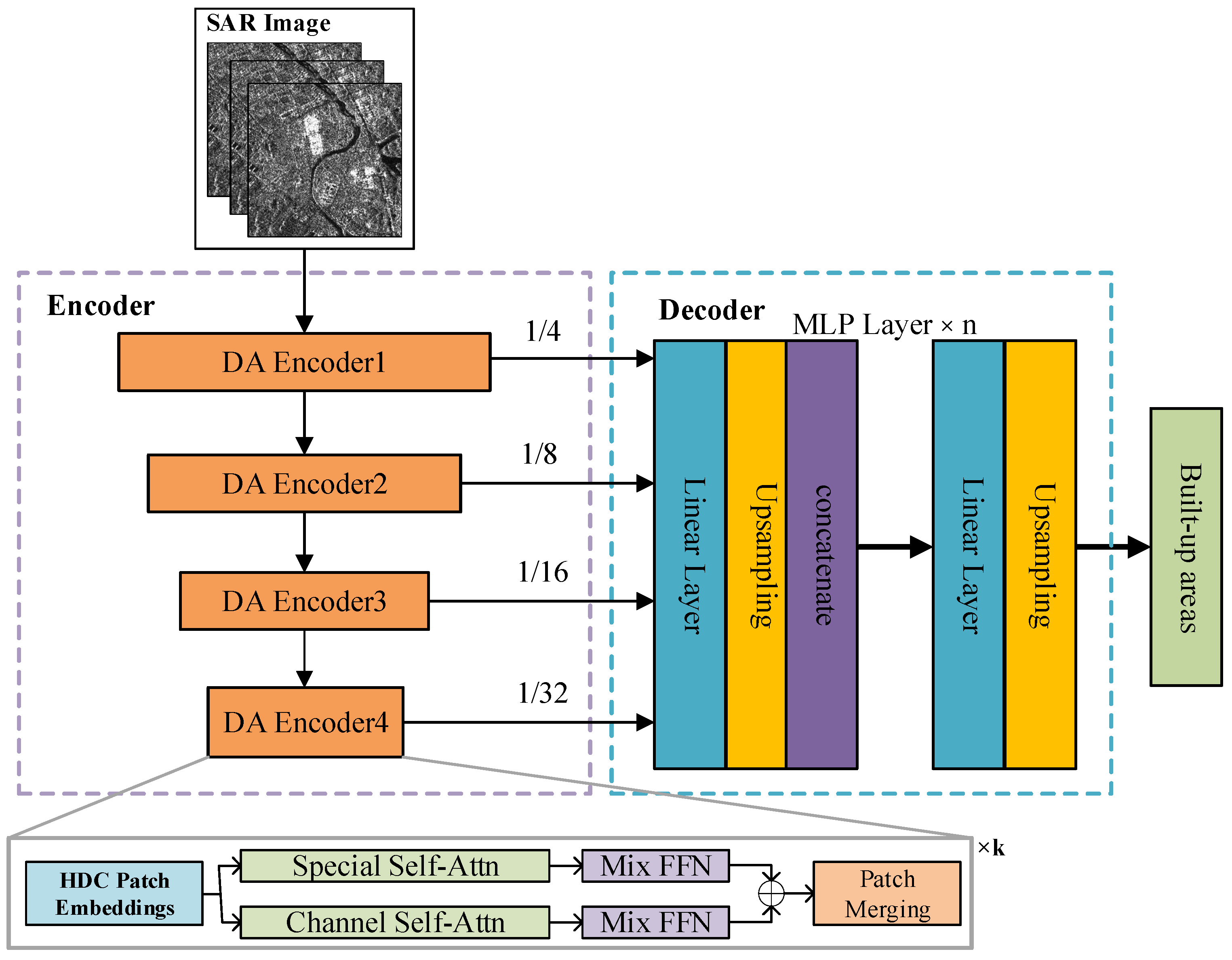
2.2. Built-Up Areas Extraction Model
2.2.1. Data Augmentation
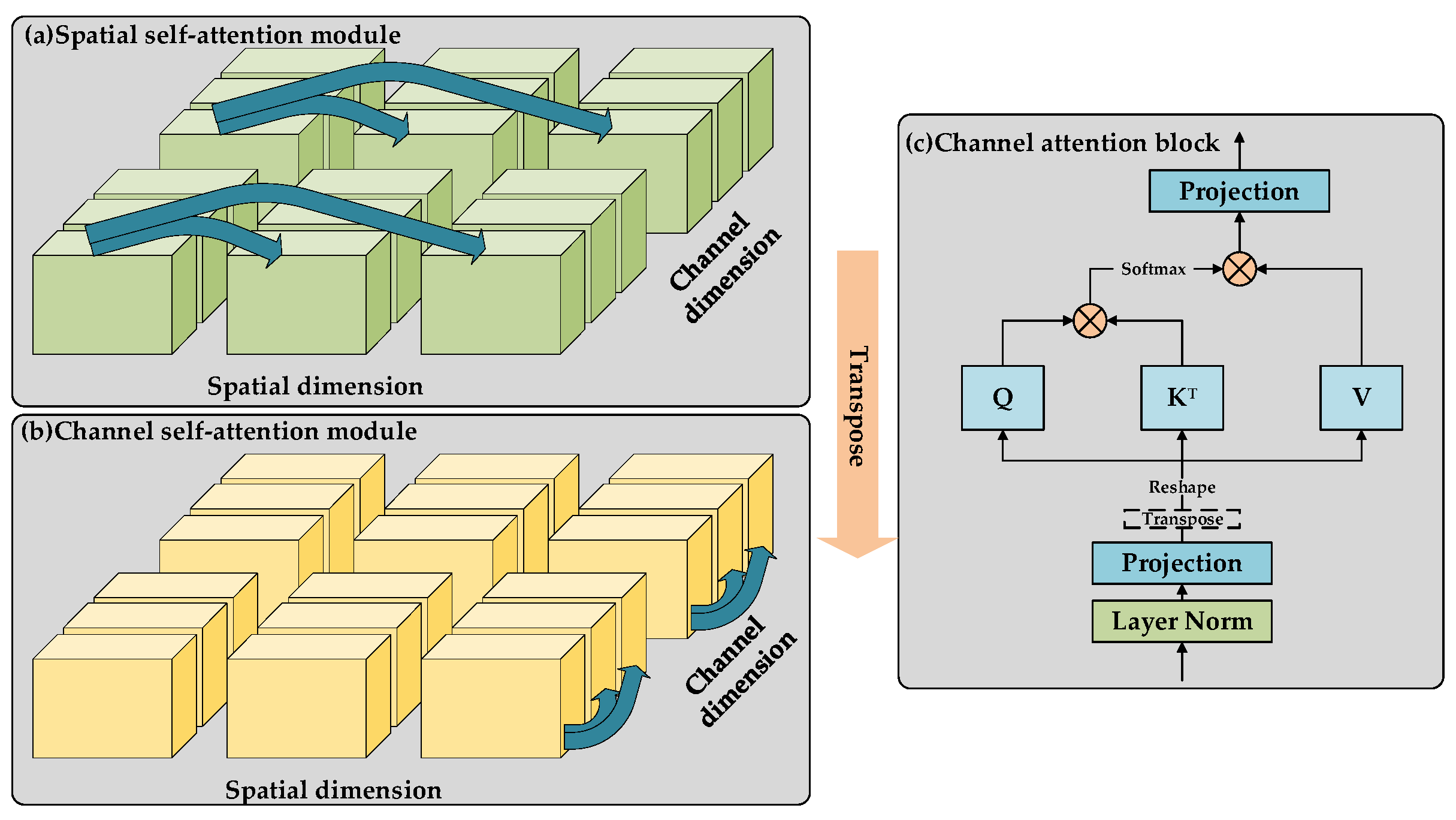
2.2.2. Multi-Level Dual-Attention Encoder
2.2.3. Lightweight Decoder
2.2.4. Combined Loss Function
2.3. Image Post-Processing
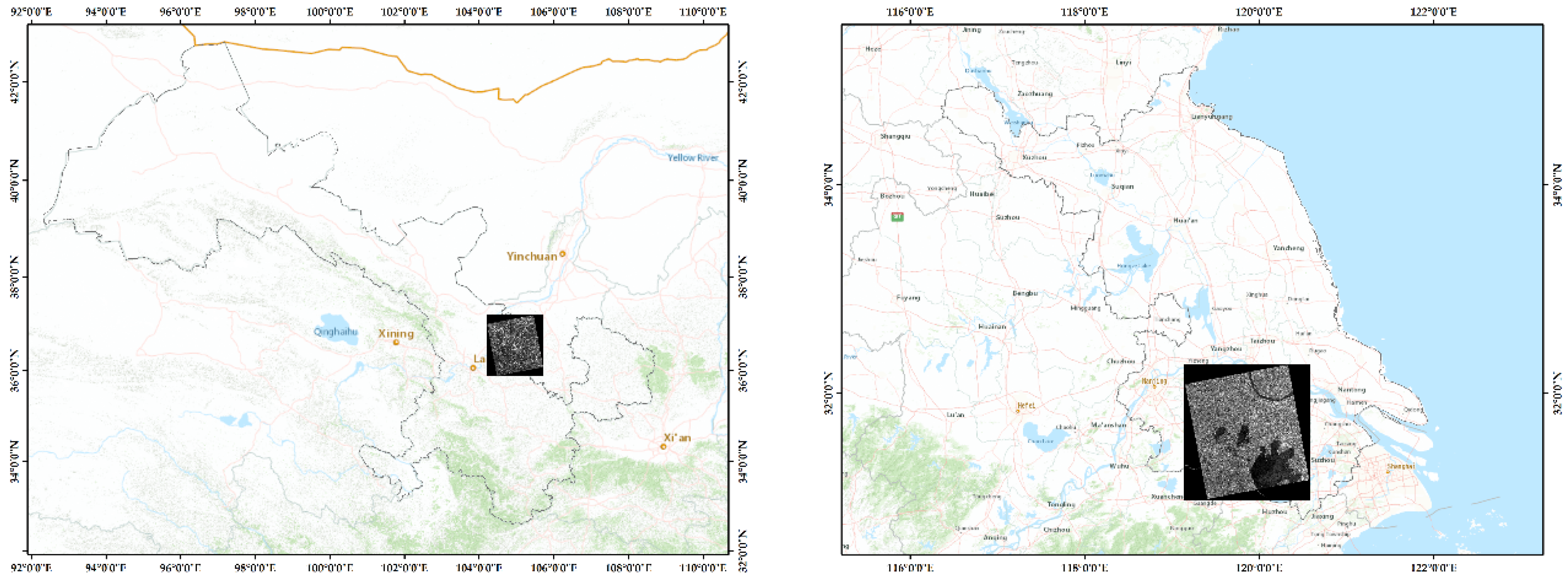
3. Dataset and Study Area
3.1. Dataset
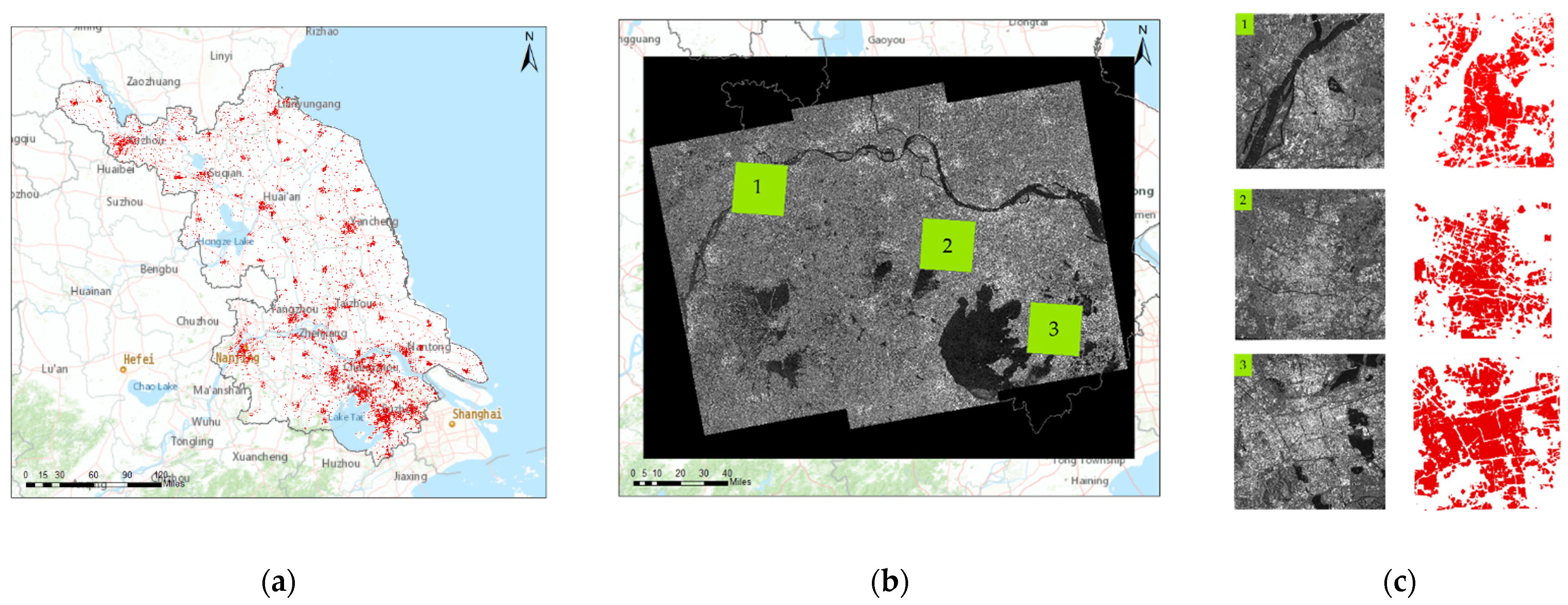
3.2. Data and Study Area
4. Experimental Results and Analysis
4.1. Quantitative Evaluation of the Proposed Method
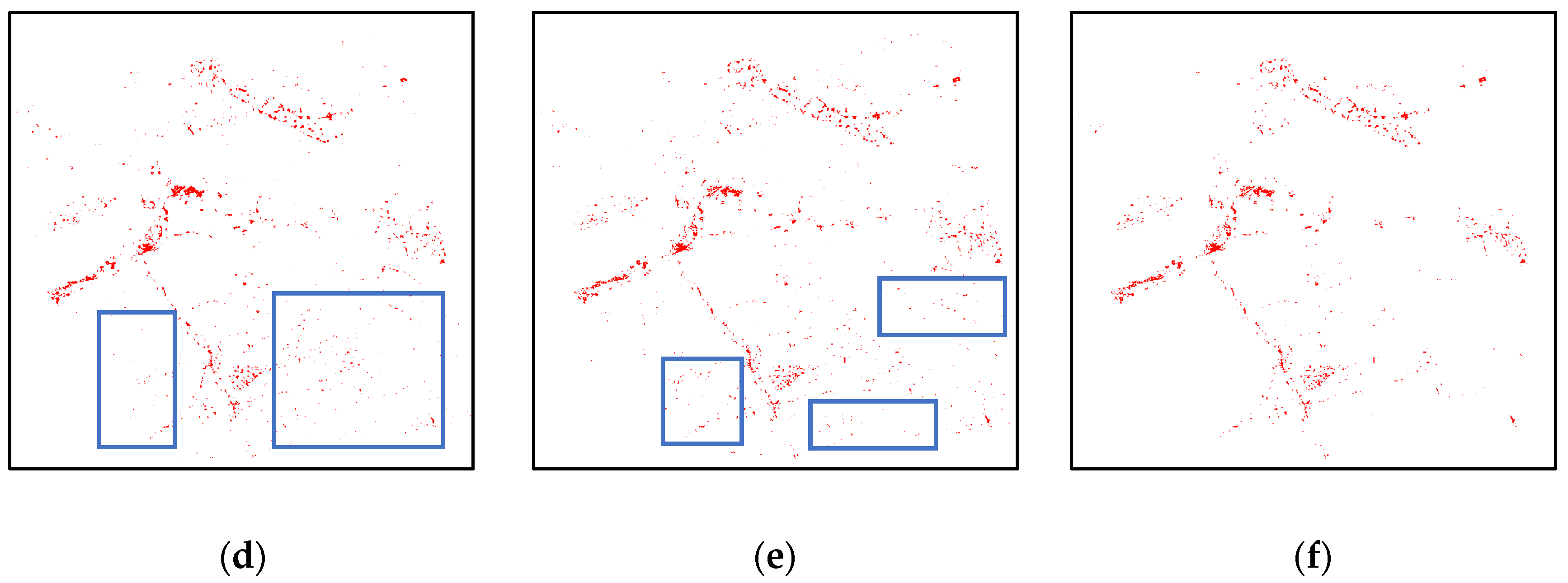
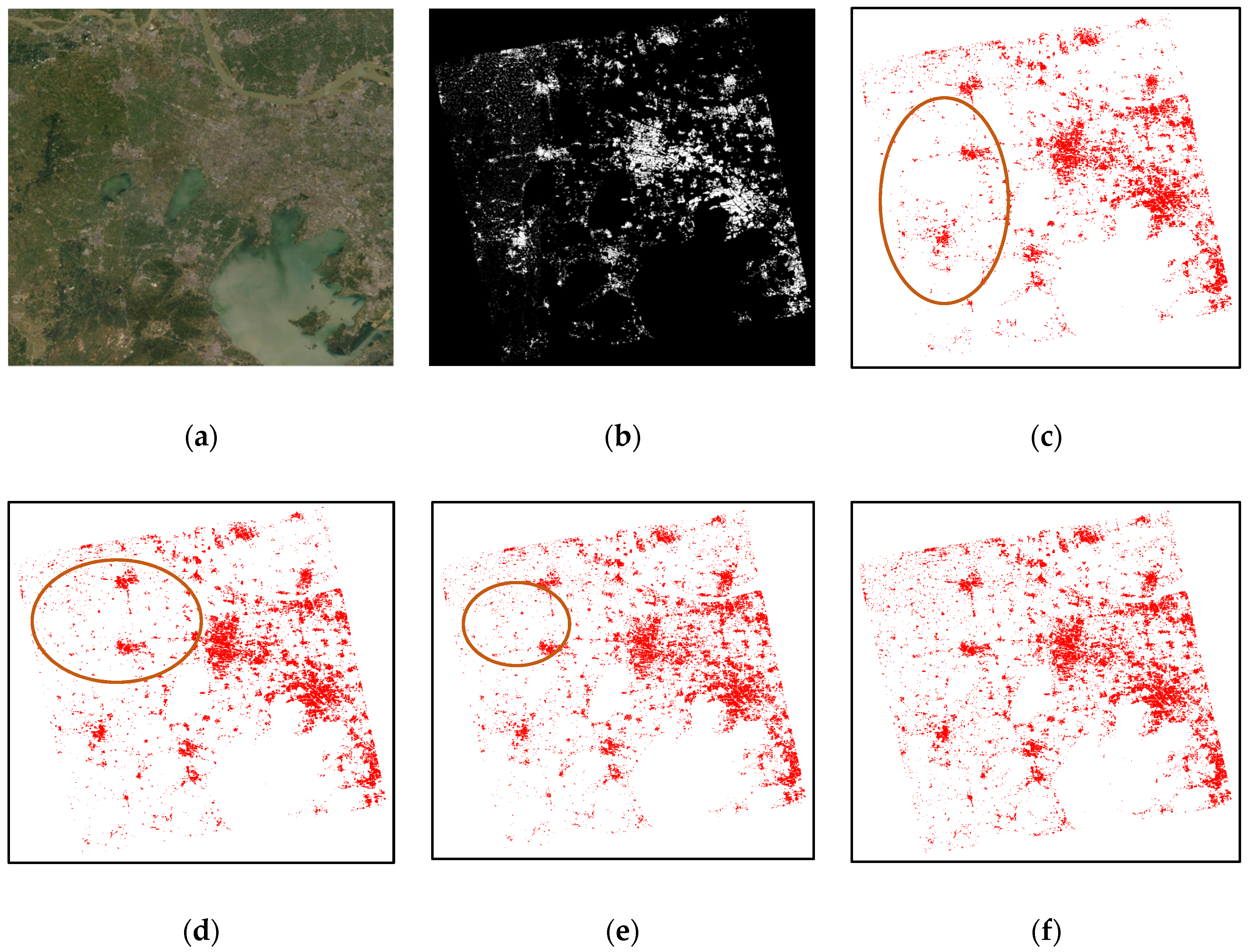
4.2. Robustness and Adaptability of the Proposed Method
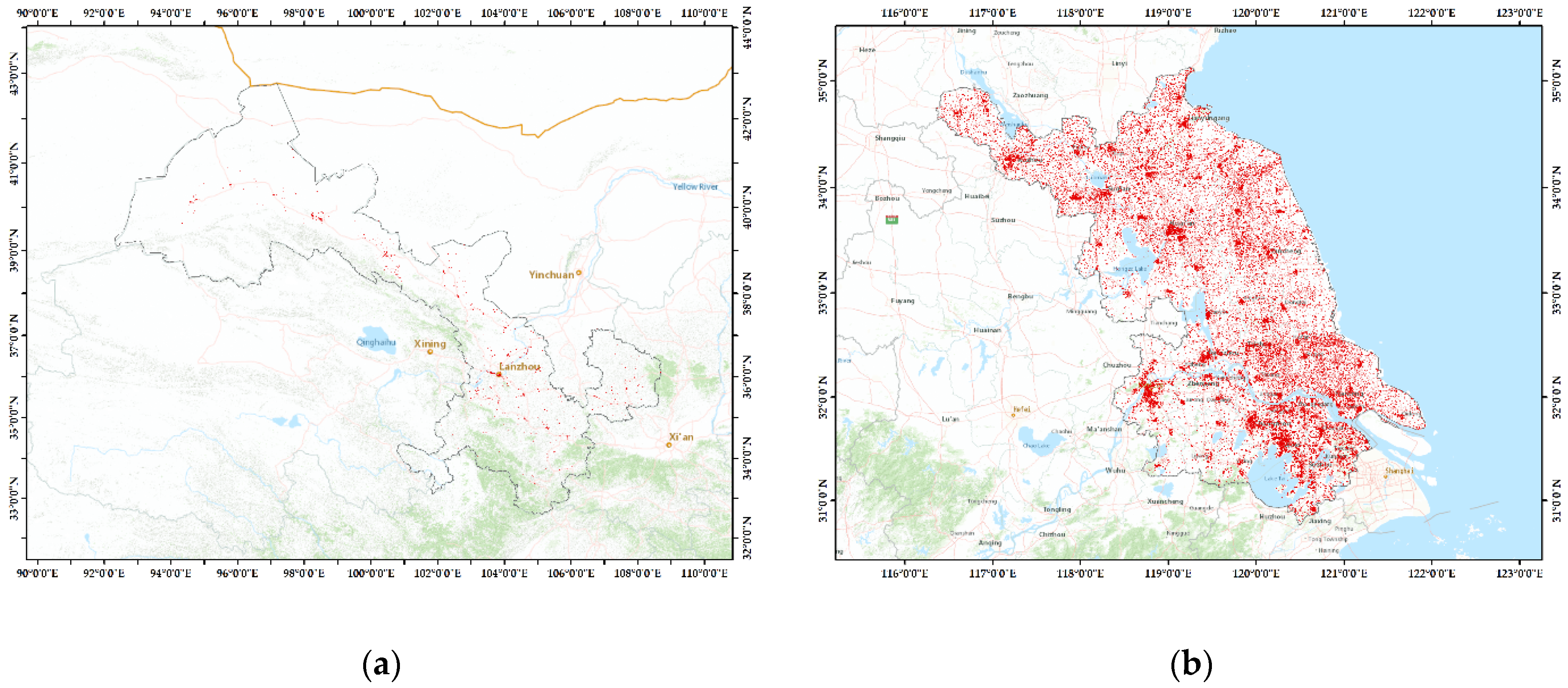
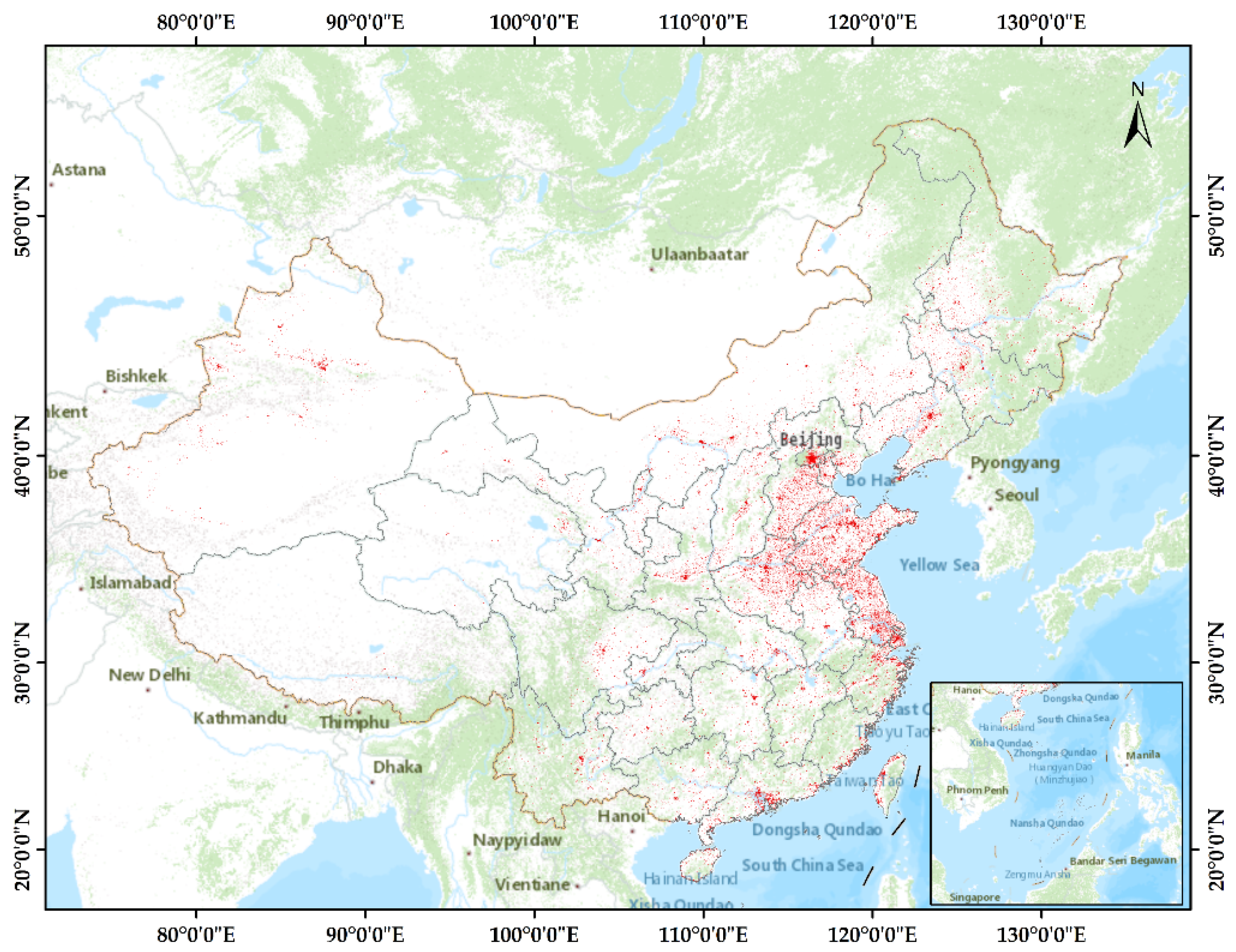
4.3. BA Map of China and Comparison with GUF
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- UN Department of Economic and Social Affairs. World Urbanization Prospects: The 2018 Revision; Technical Report; New York United Nations: New York, NY, USA, 2018. [Google Scholar]
- Melchiorri, M. Atlas of the Human Planet 2018—A World of Cities; EUR 29497 EN; Publications Office of the European Union: Luxembourg, 2018; pp. 9–24. [Google Scholar]
- United Nations Statistical Commission. Report on the Fifty-First Session (3–6 March 2020); Supplement No. 4, E/2020/24-E/CN.3/2020/37; Economic and Social Council Official Records; United Nations Statistical Commission: New York, NY, USA, 2020. [Google Scholar]
- Zhu, Z.; Zhou, Y.; Seto, K.C.; Stokes, E.C.; Deng, C.; Pickett, S.T.A.; Taubenböck, H. Understanding an urbanizing planet: Strategic directions for remote sensing. Remote Sens. Environ. 2019, 228, 164–182. [Google Scholar] [CrossRef]
- Lu, L.; Guo, H.; Corbane, C.; Li, Q. Urban sprawl in provincial capital cities in China: Evidence from multi-temporal urban land products using Landsat data. Sci. Bull. 2019, 64, 955–957. [Google Scholar] [CrossRef]
- Esch, T.; Heldens, W.; Hirner, A.; Keil, M.; Marconcini, M.; Roth, A.; Zeidler, J.; Dech, S.; Strano, E. Breaking new ground in mapping human settlements from space–The Global Urban Footprint. ISPRS J. Photogramm. Remote Sens. 2017, 134, 30–42. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Zhang, W.; et al. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Liu, X.; Hu, G.; Chen, Y.; Li, X. High-resolution multi-temporal mapping of global urban land using Landsat images based on the Google Earth Engine Platform. Remote Sens. Environ. 2018, 209, 227–239. [Google Scholar] [CrossRef]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef]
- Pesaresi, M.; Ehrlich, D.; Ferri, S.; Florczyk, A.; Freire, S.; Halkia, M.; Julea, A.; Kemper, T.; Soille, P.; Syrris, V. Operating Procedure for the Production of the Global Human Settlement Layer from Landsat Data of the Epochs 1975, 1990, 2000, and 2014; JRC Technical Report; European Commission, Joint Research Centre, Institute for the Protection and Security of the Citizen: Ispra, Italy, 2016. [Google Scholar]
- Freire, S.; Doxsey-Whitfield, E.; MacManus, K.; Mills, J.; Pesaresi, M. Development of new open and free multi-temporal global population grids at 250 m resolution. In Proceedings of the AGILE 2016, Helsinki, Finland, 14–17 June 2016. [Google Scholar]
- Sabo, F.; Corbane, C.; Florczyk, A.J.; Ferri, S.; Pesaresi, M.; Kemper, T. Comparison of built-up area maps produced within the global human settlement framework. Trans. GIS 2018, 22, 1406–1436. [Google Scholar] [CrossRef]
- Kompil, M.; Aurambout, J.P.; Ribeiro Barranco, R.; Barbosa, A.; Jacobs-Crisioni, C.; Pisoni, E.; Zulian, G.; Vandecasteele, I.; Trombetti, M.; Vizcaino, P.; et al. European Cities: Territorial Analysis of Characteristics and Trends—An Application of the LUISA Modelling Platform (EU Reference Scenario 2013—Updated Configuration 2014); JRC Technical Reports, European Union/JRC; Publications Office of the European Union: Luxembourg, 2015; p. 98. [Google Scholar]
- Florczyk, A.J.; Melchiorri, M.; Zeidler, J.; Corbane, C.; Schiavina, M.; Freire, S.; Sabo, F.; Politis, P.; Esch, T.; Pesaresi, M. The Generalised Settlement Area: Mapping the Earth surface in the vicinity of built-up areas. Int. J. Dig. Earth 2020, 13, 45–60. [Google Scholar] [CrossRef]
- Geiß, C.; Leichtle, T.; Wurm, M.; Pelizari, P.A.; Standfus, I.; Zhu, X.X.; So, E.; Siedentop, S.; Esch, T.; Taubenbock, H. Large-area characterization of urban morphology—Mapping of built-up height and density using TanDEM-X and Sentinel-2 data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2912–2927. [Google Scholar] [CrossRef]
- Herold, M.; Roberts, D.A.; Gardner, M.E.; Dennison, P.E. Spectrometry for urban area remote sensing—Development and analysis of a spectral library from 350 to 2400 nm. Remote Sens. Environ. 2004, 91, 304–319. [Google Scholar] [CrossRef]
- Melchiorri, M.; Pesaresi, M.; Florczyk, A.J.; Corbane, C.; Kemper, T. Principles and applications of the global human settlement layer as baseline for the land use efficiency indicator—SDG 11.3.1. ISPRS J. Photogramm. Remote Sens. 2019, 8, 96. [Google Scholar] [CrossRef]
- Florczyk, A.J.; Corbane, C.; Ehrlich, D.; Freire, S.; Kemper, T.; Maffeini, L.; Melchiorri, M.; Pesaresi, M.; Politis, P.; Schiavina, M.; et al. GHSL Data Package 2019; EUR 29788 EN; Publications Office of the European Union: Luxembourg, 2019; pp. 3–28. [Google Scholar]
- DeFries, R.S.; Townshend, J.R.G. NDVI-derived land cover classifications at a global scale. Int. J. Remote Sens. 1994, 15, 3567–3586. [Google Scholar] [CrossRef]
- Kobayashi, T.; Satake, M.; Masuko, H.; Manabe, T.; Shimada, M. CRL/NASDA airborne dual-frequency polarimetric interferometric SAR system. In Proceedings of the SPIE—The International Society for Optical Engineering, San Jose, CA, USA, 26–28 January 1998. [Google Scholar]
- Brunner, D.; Lemoine, G.; Bruzzone, L. Earthquake damage assessment of buildings using VHR optical and SAR imagery. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2403–2420. [Google Scholar] [CrossRef]
- Zhang, X.; Chan, N.W.; Pan, B.; Ge, X.; Yang, H. Mapping flood by the object-based method using backscattering coefficient and interference coherence of Sentinel-1 time series. Sci. Total Environ. 2021, 794, 148388. [Google Scholar] [CrossRef] [PubMed]
- Ao, D.; Li, Y.; Hu, C.; Tian, W.M. Accurate analysis of target characteristic in bistatic SAR images: A dihedral corner reflectors case. Sensors 2017, 18, 24. [Google Scholar] [CrossRef] [PubMed]
- Touzi, R.; Omari, K.; Sleep, B.; Jiao, X. Scattered and received wave polarization optimization for enhanced peatland classification and fire damage assessment using polarimetric PALSAR. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4452–4477. [Google Scholar] [CrossRef]
- Touzi, R. Target scattering decomposition in terms of roll-invariant target parameters. IEEE Trans. Geosci. Remote Sens. 2007, 45, 73–84. [Google Scholar] [CrossRef]
- Muhuri, A.; Manickam, S.; Bhattacharya, A. Scattering Mechanism Based Snow Cover Mapping Using RADARSAT-2 C-Band Polarimetric SAR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3213–3224. [Google Scholar] [CrossRef]
- Bhattacharya, A.; Muhuri, A.; De, S.; Manickam, S.; Frery, A.C. Modifying the Yamaguchi Four-Component Decomposition Scattering Powers Using a Stochastic Distance. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3497–3506. [Google Scholar] [CrossRef]
- Qin, Y.; Xiao, X.; Dong, J.; Chen, B.; Liu, F.; Zhang, G.; Zhang, Y.; Wang, J.; Wu, X. Quantifying annual changes in built-up area in complex urban-rural landscapes from analyses of PALSAR and Landsat images. ISPRS J. Photogramm. Remote Sens. 2017, 124, 89–105. [Google Scholar] [CrossRef] [Green Version]
- Esch, T.; Thiel, M.; Schenk, A.; Roth, A.; Muller, A.; Dech, S. Delineation of urban footprints from TerraSAR-X data by analyzing speckle characteristics and intensity information. IEEE Trans. Geosci. Remote Sens. 2009, 48, 905–916. [Google Scholar] [CrossRef]
- Esch, T.; Taubenböck, H.; Roth, A.; Heldens, W.; Felbier, A.; Thiel, M.; Schmidt, M.; Müller, A.; Dech, S. Tandem-X Mission—New Perspectives for the Inventory and Monitoring of Global Settlement Patterns. J. Appl. Remote Sens. 2012, 6, 1702. [Google Scholar] [CrossRef]
- Esch, T.; Marconcini, M.; Felbier, A.; Roth, A.; Heldens, W.; Huber, M.; Schwinger, M.; Taubenbock, H.; Muller, A.; Dech, S. Urban footprint processor—Fully automated processing chain generating settlement masks from global data of the TanDEM-X mission. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1617–1621. [Google Scholar] [CrossRef]
- Felbier, A.; Esch, T.; Heldens, W.; Marconcini, M.; Zeidler, J.; Roth, A.; Klotz, M.; Wurm, M.; Taubenböck, H. The Global Urban Footprint—Processing Status and Cross Comparison to Existing Human Settlement Products. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec, QC, Canada, 13–18 July 2014; pp. 4816–4819. [Google Scholar]
- Gessner, U.; Machwitz, M.; Esch, T.; Bertram, A.; Naeimi, V.; Kuenzer, C.; Dech, S. Multi-sensor mapping of West African land cover using MODIS, ASAR and TanDEM-X/TerraSAR-X data. Remote Sens. Environ. 2015, 164, 282–297. [Google Scholar] [CrossRef]
- Klotz, M.; Kemper, T.; Geiß, C.; Esch, T.; Taubenböck, H. How good is the map? A multi-scale cross-comparison framework for global settlement layers: Evidence from Central Europe. Remote Sens. Environ. 2016, 178, 191–212. [Google Scholar] [CrossRef]
- Ban, Y.; Jacob, A.; Gamba, P. Spaceborne SAR data for global urban mapping at 30 m resolution using a robust urban extractor. ISPRS J. Photogramm. Remote Sens. 2015, 103, 28–37. [Google Scholar] [CrossRef]
- Chini, M.; Hostache, R.; Giustarini, L.; Matgen, P. A hierarchical split-based approach for parametric thresholding of SAR images: Flood inundation as a test case. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6975–6988. [Google Scholar] [CrossRef]
- Cao, H.; Zhang, H.; Wang, C.; Zhang, B. Operational built-up areas extraction for cities in China using Sentinel-1 SAR data. Remote Sens. 2018, 10, 874. [Google Scholar] [CrossRef]
- Corbane, C.; Syrris, V.; Sabo, F.; Politis, P.; Melchiorri, M.; Pesaresi, M.; Soille, P.; Kemper, T. Convolutional neural networks for global human settlements mapping from Sentinel-2 satellite imagery. Neural Comput. Appl. 2021, 33, 6697–6720. [Google Scholar] [CrossRef]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep learning earth observation classification using ImageNet pretrained networks. IEEE Geosci. Remote Sens. Lett. 2015, 13, 105–109. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Zhang, R.; Li, Y. Multiscale convolutional neural network for the detection of built-up areas in high-resolution SAR images. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 910–913. [Google Scholar]
- Gao, D.L.; Zhang, R.; Xue, D.X. Improved Fully Convolutional Network for the Detection of Built-Up Areas in High Resolution SAR Images. In Image and Graphics; Zhao, Y., Kong, X., Taubman, D., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10668. [Google Scholar]
- Wu, Y.; Zhang, R.; Li, Y. The Detection of Built-up Areas in High-Resolution SAR Images Based on Deep Neural Networks. In Proceedings of the International Conference on Image and Graphics, Solan, India, 21–23 September 2017; pp. 646–655. [Google Scholar]
- Li, J.; Zhang, H.; Wang, C.; Wu, F.; Li, L. Spaceborne SAR data for regional urban mapping using a robust building extractor. Remote Sens. 2020, 12, 2791. [Google Scholar] [CrossRef]
- Wu, F.; Wang, C.; Zhang, H.; Li, J.; Li, L.; Chen, W.; Zhang, B. Built-up area mapping in China from GF-3 SAR imagery based on the framework of deep learning. Remote Sens. Environ. 2021, 262, 112515. [Google Scholar] [CrossRef]
- Huang, Z.; Datcu, M.; Pan, Z.; Lei, B. Deep SAR-Net: Learning objects from signals. ISPRS J. Photogramm. Remote Sens. 2020, 161, 179–193. [Google Scholar] [CrossRef]
- Zhang, Q. System design and key technologies of the GF-3 satellite. Acta Geod. Cartogr. Sin. 2017, 46, 269. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Lvarez, J.E.M.A.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Online, 6–14 December 2021. [Google Scholar]
- Fang, H.; Zhang, B.; Chen, W.; Wu, F.; Wang, C. A research of fine process method for Gaofen-3 L1A-Level image. J. Univ. Chin. Acad. Sci. 2021, 535, 237. [Google Scholar]
- Mladenova, I.E.; Jackson, T.J.; Bindlish, R.; Hensley, S. Incidence angle normalization of radar backscatter data. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1791–1804. [Google Scholar] [CrossRef]
- Gamba, P.; Aldrighi, M.; Stasolla, M. Robust Extraction of Urban Area Extents in HR and VHR SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 27–34. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the 4th International Conference on Learning Representations (ICLR 2016), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahamdi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the Fourth International Conference on 3D-Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Parameters | Value |
|---|---|---|
| Random padding crop | Crop size | [224, 224] |
| Random horizontal flip | Prob | 0.5 |
| Random vertical flip | Prob | 0.1 |
| Random distort | Brightness, contrast, saturation | 0.6, 0.6, 0.6 |
| Province | Orbit Direction | Resolution (m) | Polarization | Num. | Acquisition Date |
|---|---|---|---|---|---|
| Jiangsu | Ascending | 10 | HH | 2 | 2 January 2019, 20 May 2019 |
| Gansu | Ascending | 10 | HH | 1 | 20 January 2019 |
| Yunnan | Ascending | 10 | HH | 1 | 10 July 2019 |
| Neimenggu | Ascending | 10 | HH | 1 | 3 March 2019 |
| Province | Sensors | Resolution (m) | Polarization | Number | Acquisition Date |
|---|---|---|---|---|---|
| Gansu | GF-3 | 10 | HH/VV | 71 | 1 January 2020–31 December 2020 |
| Jiangsu | GF-3 | 10 | HH/VV | 19 | 1 January 2020–31 December 2020 |
| Jiangsu | Sentinel-1 | 20 | HH | 8 | 1 January 2020–31 December 2020 |
| Model | mIoU | mAP |
|---|---|---|
| UNet | 0.7712 | 0.9273 |
| PSPNet | 0.8000 | 0.9379 |
| SegFormer | 0.8130 | 0.9423 |
| The proposed model | 0.8535 | 0.9475 |
| Models | OA | PA | UA | F1 Score | ||||
|---|---|---|---|---|---|---|---|---|
| T1 | T2 | T1 | T2 | T1 | T2 | T1 | T2 | |
| UNet | 0.7533 | 0.8627 | 0.6936 | 0.8114 | 0.5778 | 0.6896 | 0.63 | 0.75 |
| PSPNet | 0.8052 | 0.8854 | 0.7299 | 0.8053 | 0.6143 | 0.7448 | 0.67 | 0.77 |
| SegFormer | 0.8162 | 0.8938 | 0.7531 | 0.8557 | 0.6386 | 0.7645 | 0.69 | 0.81 |
| Our method | 0.8533 | 0.9152 | 0.8034 | 0.8606 | 0.7945 | 0.8854 | 0.80 | 0.87 |
| Sub Region | OA | PA | UA | F1 Score |
|---|---|---|---|---|
| 1 | 0.9681 | 0.9267 | 0.9386 | 0.93 |
| 2 | 0.9655 | 0.9271 | 0.9288 | 0.92 |
| 3 | 0.9275 | 0.9411 | 0.9126 | 0.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Wang, C.; Wu, F.; Zhang, H.; Tian, S.; Fu, Q.; Xu, L. Built-Up Area Extraction from GF-3 SAR Data Based on a Dual-Attention Transformer Model. Remote Sens. 2022, 14, 4182. https://doi.org/10.3390/rs14174182
Li T, Wang C, Wu F, Zhang H, Tian S, Fu Q, Xu L. Built-Up Area Extraction from GF-3 SAR Data Based on a Dual-Attention Transformer Model. Remote Sensing. 2022; 14(17):4182. https://doi.org/10.3390/rs14174182
Chicago/Turabian StyleLi, Tianyang, Chao Wang, Fan Wu, Hong Zhang, Sirui Tian, Qiaoyan Fu, and Lu Xu. 2022. "Built-Up Area Extraction from GF-3 SAR Data Based on a Dual-Attention Transformer Model" Remote Sensing 14, no. 17: 4182. https://doi.org/10.3390/rs14174182
APA StyleLi, T., Wang, C., Wu, F., Zhang, H., Tian, S., Fu, Q., & Xu, L. (2022). Built-Up Area Extraction from GF-3 SAR Data Based on a Dual-Attention Transformer Model. Remote Sensing, 14(17), 4182. https://doi.org/10.3390/rs14174182