
MapCleaner: Efficiently Removing Moving Objects from Point Cloud Maps in Autonomous Driving Scenarios


Abstract
:1. Introduction
2. Related Work
3. Methodology
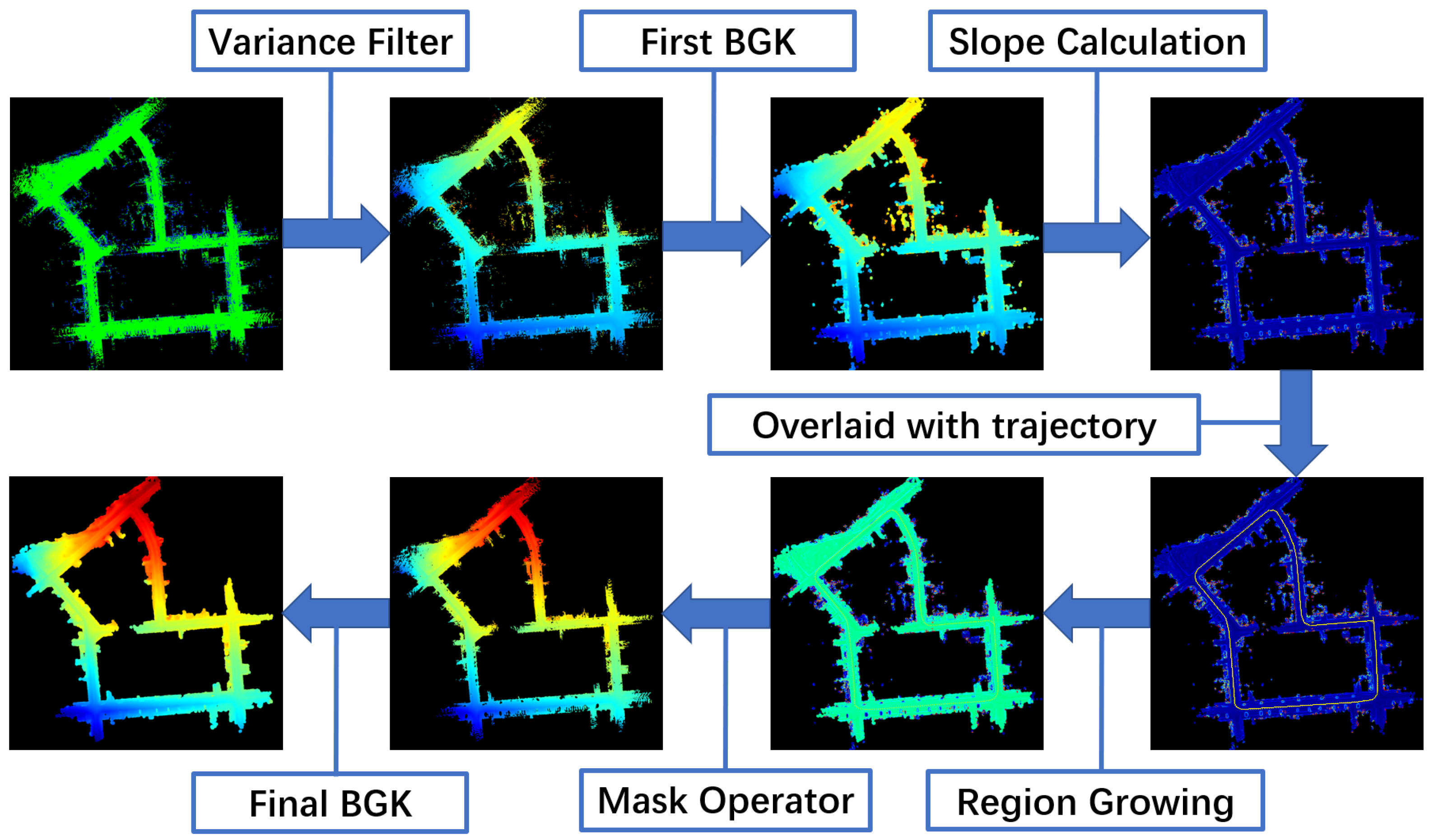
3.1. Terrain Modeling
- Preprocess with a variance filter.
- BGK inference with bilateral filtering.
- Region growing on the normal map.
3.2. Moving Points Identification
| Algorithm 1 Moving Point Identification |
|
4. Results and Discussion
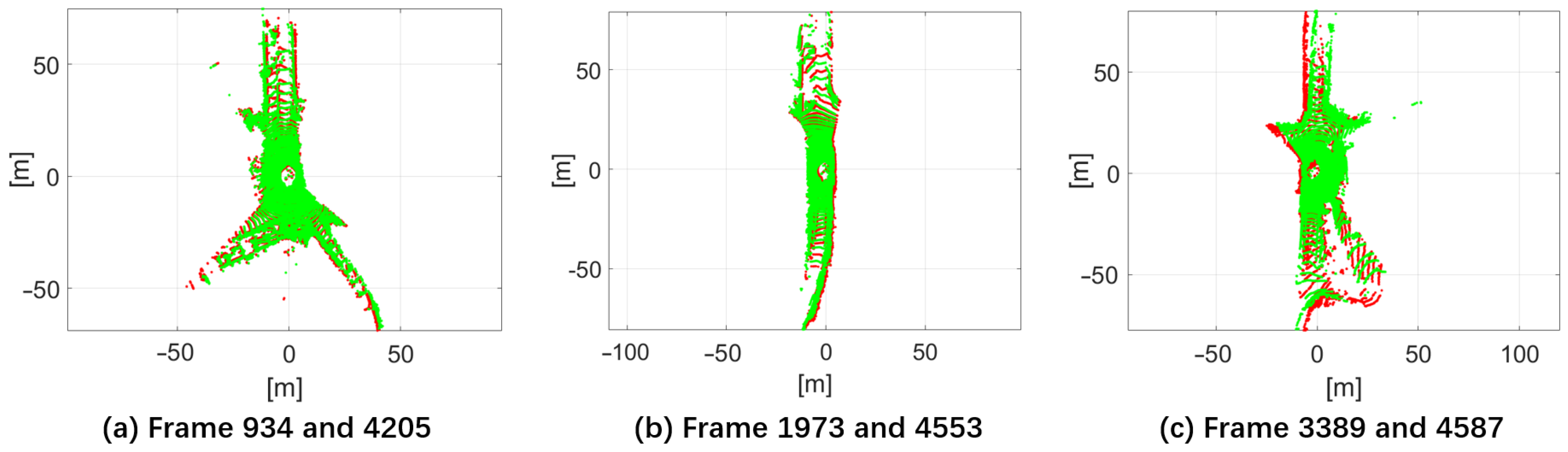
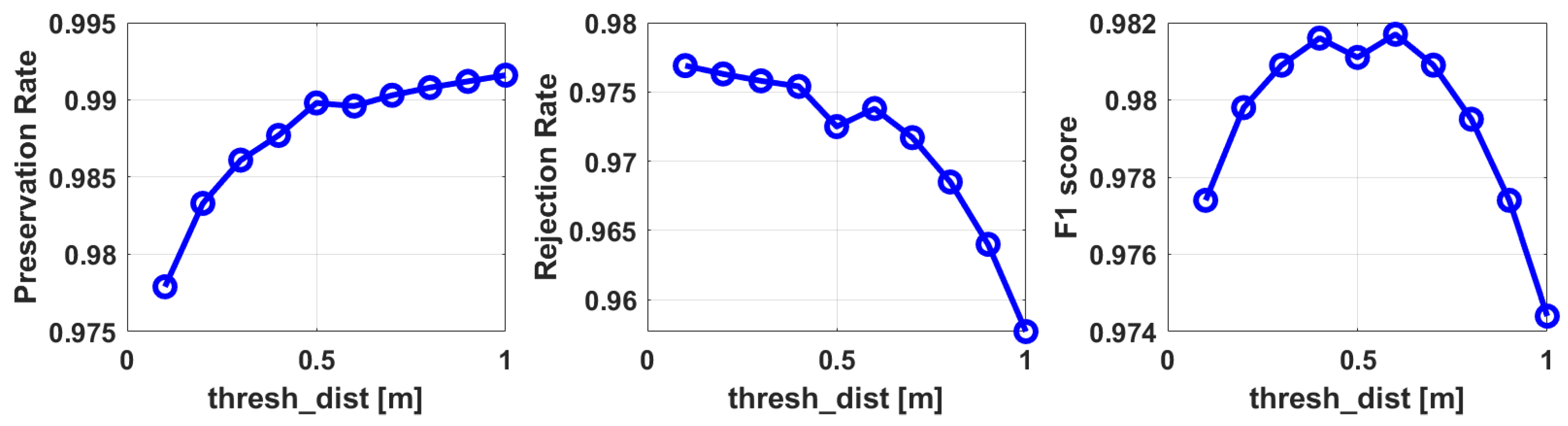
4.1. Evaluation on the Terrain Modeling Approach
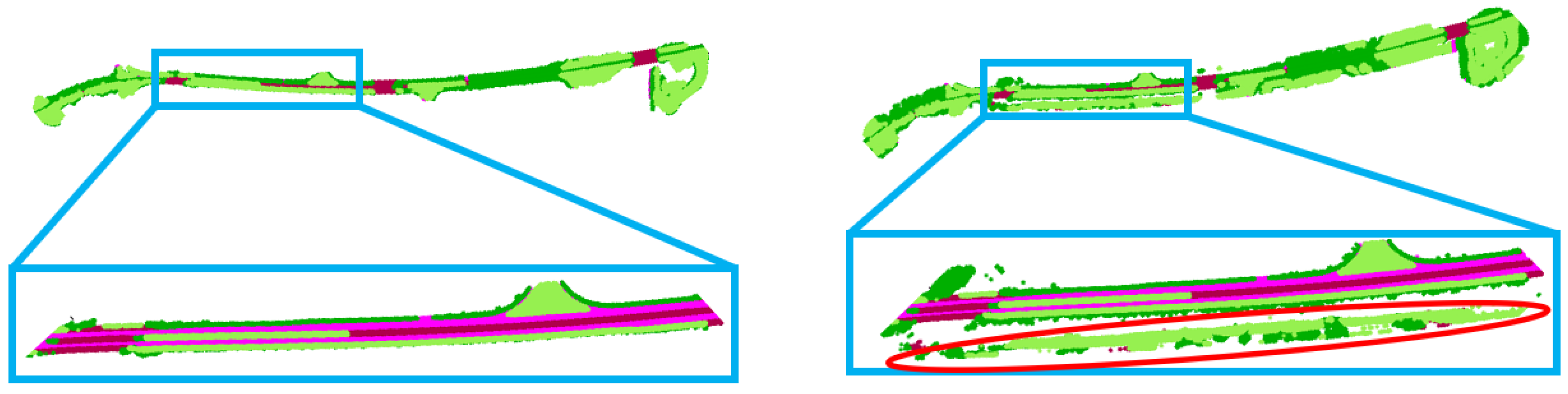
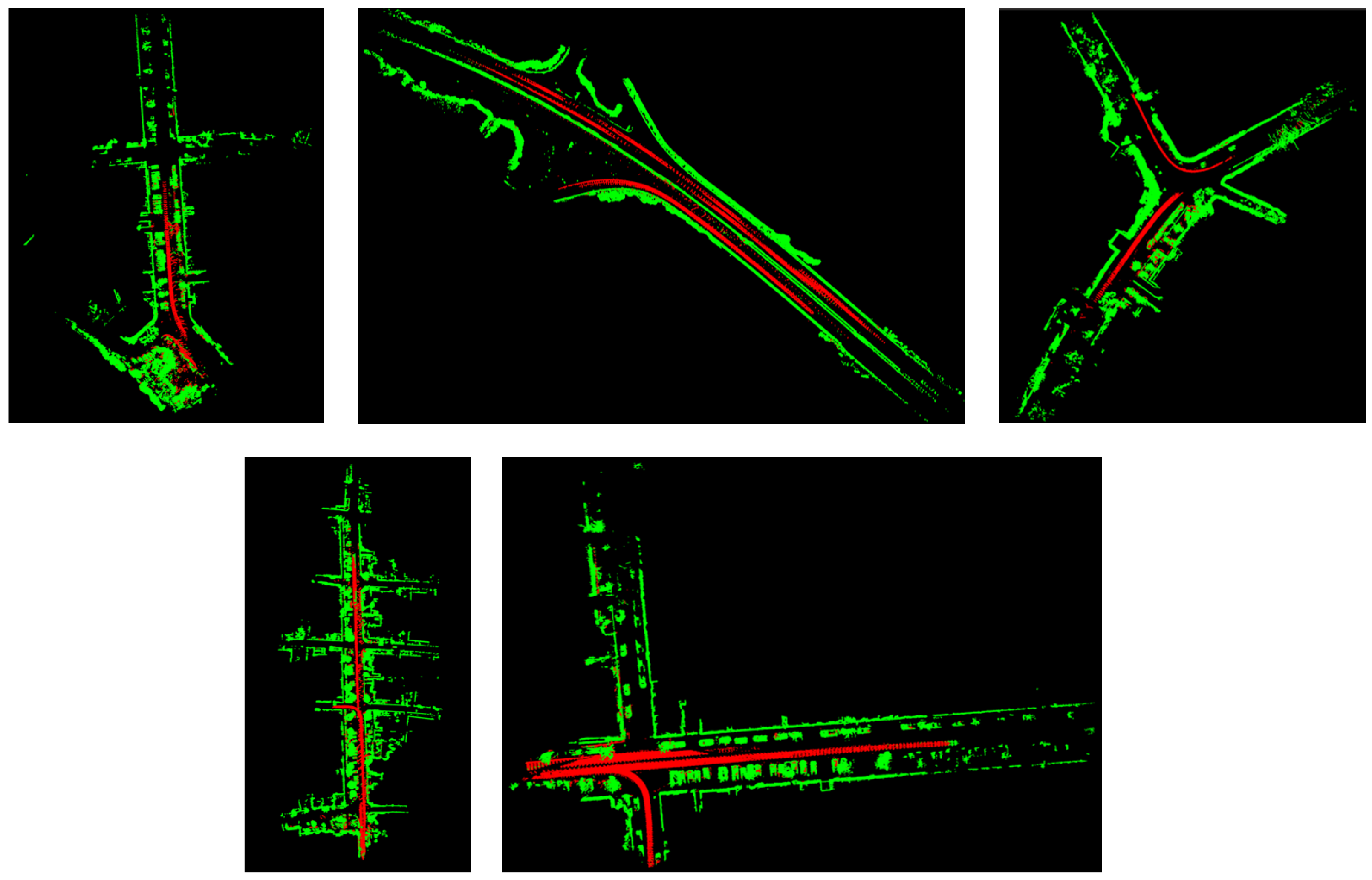
4.2. Evaluation on the Map Cleaning Performance
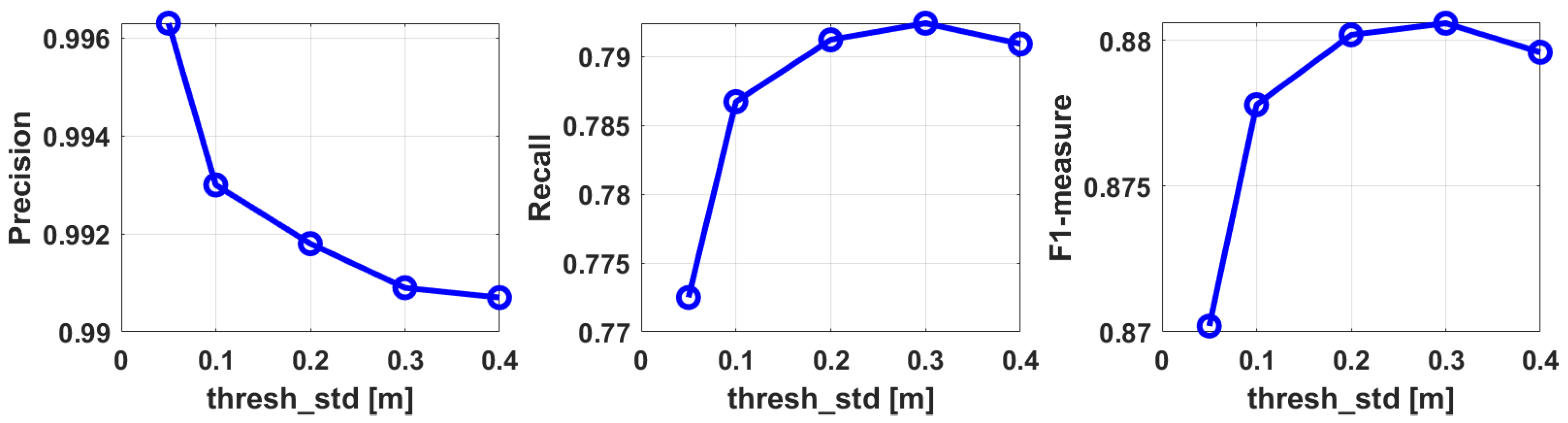
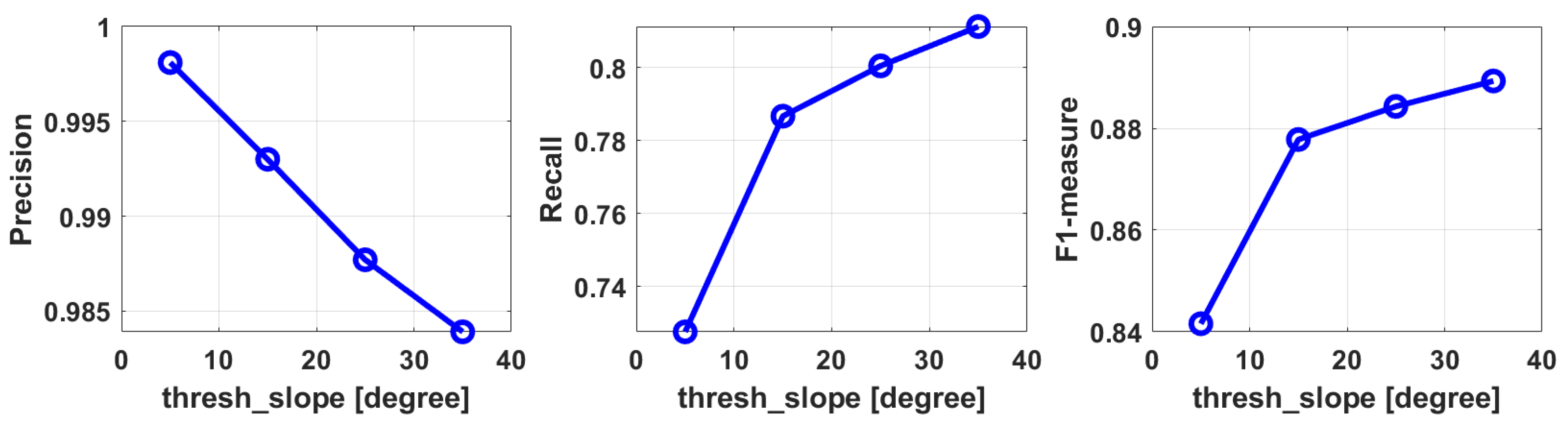
4.3. Ablation Studies
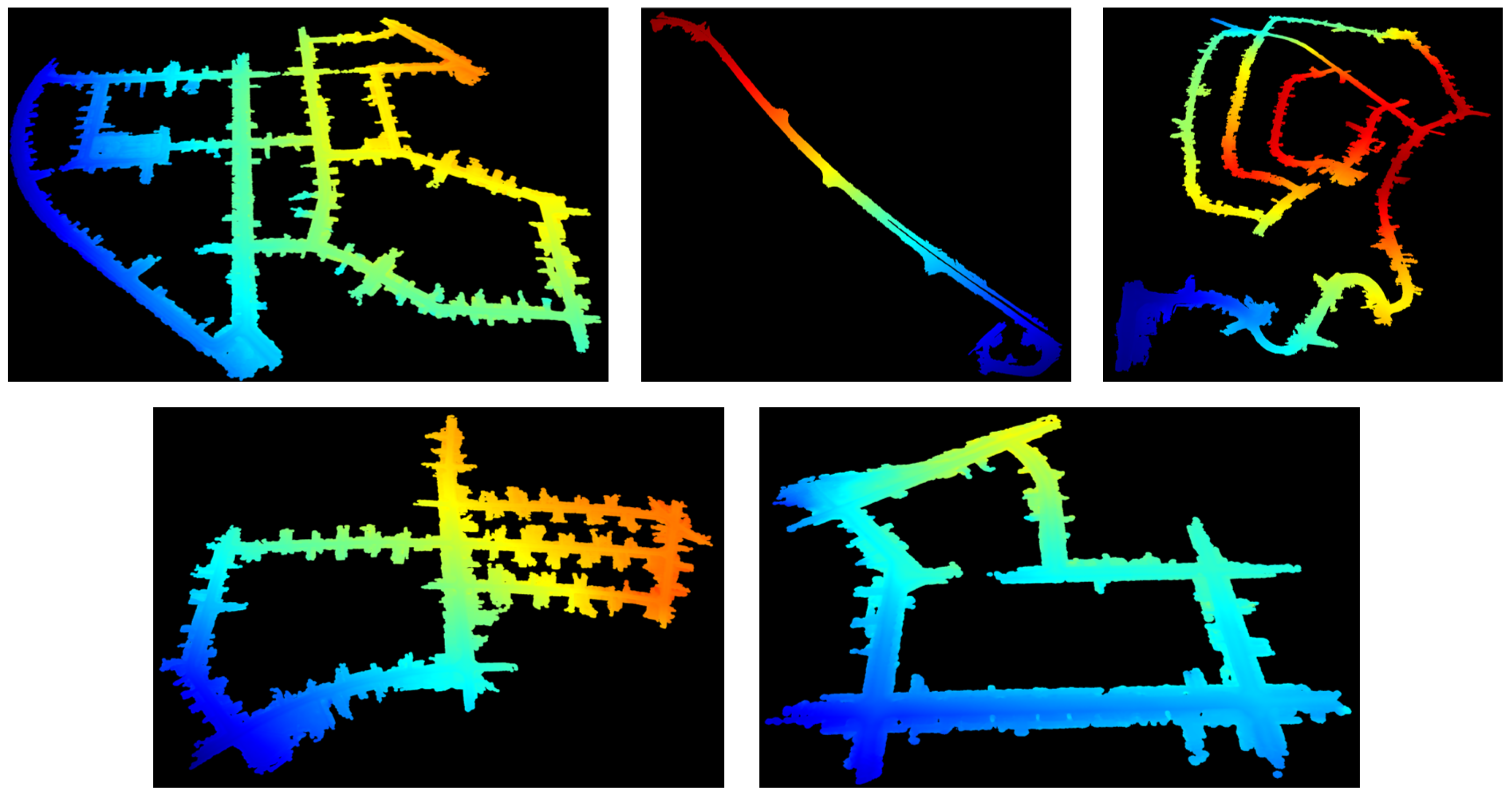
4.4. Experiments on Our Dataset
5. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fu, H.; Yu, R.; Wu, T.; Ye, L.; Xu, X. An Efficient Scan-to-Map Matching Approach based on Multi-channel Lidar. J. Intell. Robot. Syst. 2018, 91, 501–513. [Google Scholar] [CrossRef]
- Ren, R.; Fu, H.; Xue, H.; Sun, Z.; Ding, K.; Wang, P. Towards a fully automated 3d reconstruction system based on lidar and gnss in challenging scenarios. Remote Sens. 2021, 13, 1981. [Google Scholar] [CrossRef]
- Kim, G.; Kim, A. Remove, then revert: Static point cloud map construction using multiresolution range images. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 10758–10765. [Google Scholar]
- Lim, H.; Hwang, S.; Myung, H. ERASOR: Egocentric Ratio of Pseudo Occupancy-Based Dynamic Object Removal for Static 3D Point Cloud Map Building. IEEE Robot. Autom. Lett. 2021, 6, 2272–2279. [Google Scholar] [CrossRef]
- Schauer, J.; Nuchter, A. The Peopleremover-Removing Dynamic Objects from 3-D Point Cloud Data by Traversing a Voxel Occupancy Grid. IEEE Robot. Autom. Lett. 2018, 3, 1679–1686. [Google Scholar] [CrossRef]
- Chen, X.; Mersch, B.; Nunes, L.; Marcuzzi, R.; Vizzo, I.; Behley, J.; Stachniss, C. Automatic Labeling to Generate Training Data for Online LiDAR-Based Moving Object Segmentation. IEEE Robot. Autom. Lett. 2020, 7, 6107–6114. [Google Scholar] [CrossRef]
- Xue, H.; Fu, H.; Ren, R.; Zhang, J.; Liu, B.; Fan, Y.; Dai, B. LiDAR-based Drivable Region Detection for Autonomous Driving. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Prague, Czech Republic, 27 September–1 October 2021; pp. 1110–1116. [Google Scholar]
- Chen, C.; Yang, B. Dynamic occlusion detection and inpainting of in situ captured terrestrial laser scanning point clouds sequence. ISPRS J. Photogramm. Remote. Sens. 2016, 119, 90–107. [Google Scholar] [CrossRef]
- Gehrung, J.; Hebel, M.; Arens, M.; Stilla, U. An approach to extract moving objects from MLS data using a volumetric background representation. ISPRS Ann. Photogramm. Remote. Sens. Spatial Inf. Sci. 2017, 4, 107–114. [Google Scholar] [CrossRef]
- Fang, J.; Zhou, D.; Yan, F.; Zhao, T.; Zhang, F.; Ma, Y.; Wang, L.; Yang, R. Augmented LiDAR simulator for autonomous driving. IEEE Robot. Autom. Lett. 2020, 5, 1931–1938. [Google Scholar] [CrossRef]
- Baur, S.A.; Emmerichs, D.J.; Moosmann, F.; Pinggera, P.; Ommer, B.; Geiger, A. SLIM: Self-Supervised LiDAR Scene Flow and Motion Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 13106–13116. [Google Scholar]
- Pang, Z.; Li, Z.; Wang, N. Model-free Vehicle Tracking and State Estimation in Point Cloud Sequences. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Prague, Czech Republic, 27 September–1 October 2021; pp. 8075–8082. [Google Scholar]
- Vatavu, A.; Rahm, M.; Govindachar, S.; Krehl, G.; Mantha, A.; Bhavsar, S.R.; Schier, M.R.; Peukert, J.; Maile, M. From Particles to Self-Localizing Tracklets: A Multilayer Particle Filter-Based Estimation for Dynamic Grid Maps. IEEE Intell. Transp. Syst. Mag. 2020, 12, 149–168. [Google Scholar] [CrossRef]
- Fan, T.; Shen, B.; Chen, H.; Zhang, W.; Pan, J. DynamicFilter: An Online Dynamic Objects Removal Framework for Highly Dynamic Environments. In Proceedings of the 2022 IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2020; pp. 7988–7994. [Google Scholar]
- Yoon, D.; Tang, T.; Barfoot, T. Mapless online detection of dynamic objects in 3D lidar. In Proceedings of the 2019 16th Conference on Computer and Robot Vision, CRV 2019, Kingston, QC, Canada, 29–31 May 2019; pp. 113–120. [Google Scholar]
- Chen, X.; Li, S.; Mersch, B.; Wiesmann, L.; Gall, J.; Behley, J.; Stachniss, C. Moving Object Segmentation in 3D LiDAR Data: A Learning-based Approach Exploiting Sequential Data. IEEE Robot. Autom. Lett. 2021, 6, 6529–6536. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Behnke, S.; Stachniss, C.; Gall, J.; Quenzel, J. SemanticKITTI: A dataset for semantic scene understanding of LiDAR sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Peng, K.; Fei, J.; Yang, K.; Roitberg, A.; Zhang, J.; Bieder, F.; Heidenreich, P.; Stiller, C.; Stiefelhagen, R. MASS: Multi-Attentional Semantic Segmentation of LiDAR Data for Dense Top-View Understanding. IEEE Trans. Intell. Transp. Syst. 2022, 1–16. [Google Scholar] [CrossRef]
- Zhou, B.; Krähenbühl, P. Cross-view Transformers for real-time Map-view Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13760–13769. [Google Scholar]
- Wurm, K.M.; Hornung, A.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: A Probabilistic, Flexible, and Compact 3D Map Representation for Robotic Systems. In Proceedings of the International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020. [Google Scholar]
- Lim, H.; Oh, M.; Myung, H. Patchwork: Concentric Zone-Based Region-Wise Ground Segmentation with Ground Likelihood Estimation Using a 3D LiDAR Sensor. IEEE Robot. Autom. Lett. 2021, 6, 6458–6465. [Google Scholar] [CrossRef]
- Shan, T.; Wang, J.; Englot, B.; Doherty, K. Bayesian Generalized Kernel Inference for Terrain Traversability Mapping. In Proceedings of the 2nd Conference on Robot Learning, Zurich, Switzerland, 29–31 October 2018; pp. 829–838. [Google Scholar]
- Forkel, B.; Kallwies, J.; Wuensche, H.J. Probabilistic Terrain Estimation for Autonomous Off-Road Driving. In Proceedings of the IEEE International Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; pp. 13864–13870. [Google Scholar]
- Thrun, S. Learning Occupancy Grid Maps with Forward Sensor Models. Auton. Robot. 2003, 15, 111–127. [Google Scholar] [CrossRef]
- Fu, H.; Xue, H.; Ren, R. Fast Implementation of 3D Occupancy Grid for Autonomous Driving. In Proceedings of the 2020 12th International Conference on Intelligent Human-Machine Systems and Cybernetics, IHMSC 2020, Hangzhou, China, 22–23 August 2020; Volume 2, pp. 217–220. [Google Scholar]
- Roldão, L.; De Charette, R.; Verroust-Blondet, A. A Statistical Update of Grid Representations from Range Sensors. arXiv 2018, arXiv:1807.08483. [Google Scholar]
- Fu, H.; Xue, H.; Hu, X.; Liu, B. Lidar data enrichment by fusing spatial and temporal adjacent frames. Remote Sens. 2021, 13, 3640. [Google Scholar] [CrossRef]
- Wu, T.; Fu, H.; Liu, B.; Xue, H.; Ren, R.; Tu, Z. Detailed analysis on generating the range image for lidar point cloud processing. Electronics 2021, 10, 1224. [Google Scholar] [CrossRef]
- Behley, J.; Stachniss, C. Efficient Surfel-Based SLAM using 3D Laser Range Data in Urban Environments. Robot. Sci. Syst. 2018, 2018, 59. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | Approach | Precision [%] | Recall [%] | F1-Measure |
|---|---|---|---|---|
| 00 | Patchwork [21] | 72.94 | 92.00 | 0.8137 |
| Ours | 94.78 | 78.20 | 0.8570 | |
| 01 | Patchwork [21] | 89.96 | 80.94 | 0.8521 |
| Ours | 98.40 | 69.25 | 0.8129 | |
| 02 | Patchwork [21] | 82.27 | 93.72 | 0.8763 |
| Ours | 97.80 | 85.18 | 0.9105 | |
| 05 | Patchwork [21] | 72.64 | 94.67 | 0.8221 |
| Ours | 92.10 | 85.19 | 0.8851 | |
| 07 | Patchwork [21] | 71.92 | 92.03 | 0.8074 |
| Ours | 99.30 | 78.67 | 0.8778 |
| Sequence | Approach | PR [%] | RR [%] | Score |
|---|---|---|---|---|
| 00 | Octomap [20] | 76.73 | 99.12 | 0.865 |
| Peopleremover [5] | 37.52 | 89.12 | 0.528 | |
| Removert [3] | 85.50 | 99.35 | 0.919 | |
| ERASOR [4] | 93.98 | 97.08 | 0.955 | |
| Ours | 98.89 | 98.18 | 0.9853 | |
| 01 | Octomap [20] | 53.16 | 99.66 | 0.693 |
| Peopleremover [5] | 94.22 | 93.61 | 0.939 | |
| Removert [3] | 85.50 | 99.35 | 0.919 | |
| ERASOR [4] | 91.48 | 95.38 | 0.934 | |
| Ours | 99.74 | 94.98 | 0.9730 | |
| 02 | Octomap [20] | 54.11 | 98.77 | 0.699 |
| Peopleremover [5] | 29.04 | 94.53 | 0.444 | |
| Removert [3] | 76.32 | 96.79 | 0.853 | |
| ERASOR [4] | 87.73 | 97.01 | 0.921 | |
| Ours | 99.37 | 99.03 | 0.9920 | |
| 05 | Octomap [20] | 76.34 | 96.78 | 0.854 |
| Peopleremover [5] | 38.49 | 90.63 | 0.540 | |
| Removert [3] | 86.90 | 87.88 | 0.874 | |
| ERASOR [4] | 88.73 | 98.26 | 0.933 | |
| Ours | 99.14 | 97.92 | 0.9852 | |
| 07 | Octomap [20] | 77.84 | 96.94 | 0.863 |
| Peopleremover [5] | 34.77 | 91.98 | 0.505 | |
| Removert [3] | 80.69 | 98.82 | 0.888 | |
| ERASOR [4] | 90.62 | 99.27 | 0.948 | |
| Ours | 98.98 | 97.25 | 0.9811 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, H.; Xue, H.; Xie, G. MapCleaner: Efficiently Removing Moving Objects from Point Cloud Maps in Autonomous Driving Scenarios. Remote Sens. 2022, 14, 4496. https://doi.org/10.3390/rs14184496
Fu H, Xue H, Xie G. MapCleaner: Efficiently Removing Moving Objects from Point Cloud Maps in Autonomous Driving Scenarios. Remote Sensing. 2022; 14(18):4496. https://doi.org/10.3390/rs14184496
Chicago/Turabian StyleFu, Hao, Hanzhang Xue, and Guanglei Xie. 2022. "MapCleaner: Efficiently Removing Moving Objects from Point Cloud Maps in Autonomous Driving Scenarios" Remote Sensing 14, no. 18: 4496. https://doi.org/10.3390/rs14184496
APA StyleFu, H., Xue, H., & Xie, G. (2022). MapCleaner: Efficiently Removing Moving Objects from Point Cloud Maps in Autonomous Driving Scenarios. Remote Sensing, 14(18), 4496. https://doi.org/10.3390/rs14184496