
Building Change Detection Based on an Edge-Guided Convolutional Neural Network Combined with a Transformer

Abstract
:1. Introduction
2. Methods
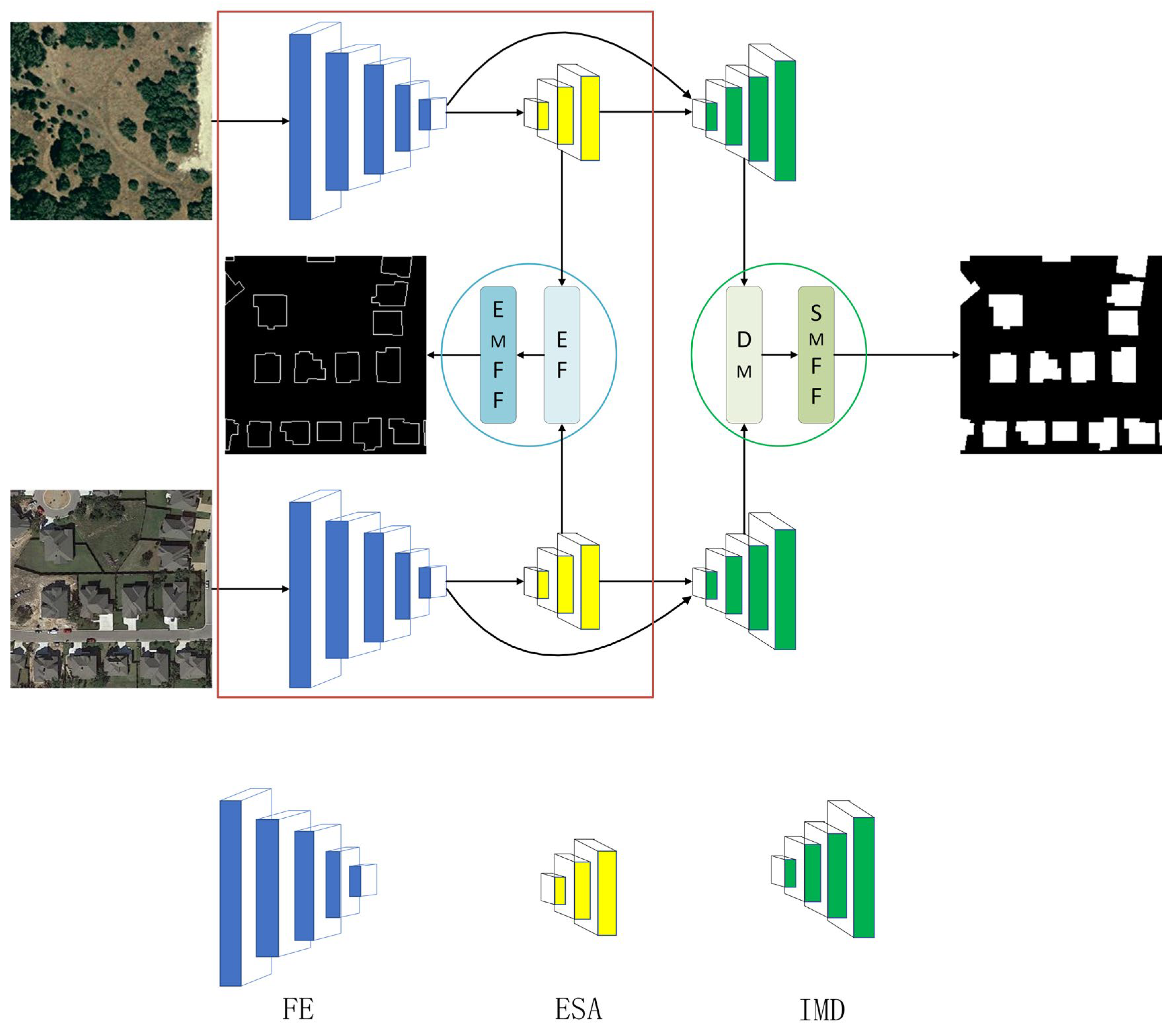
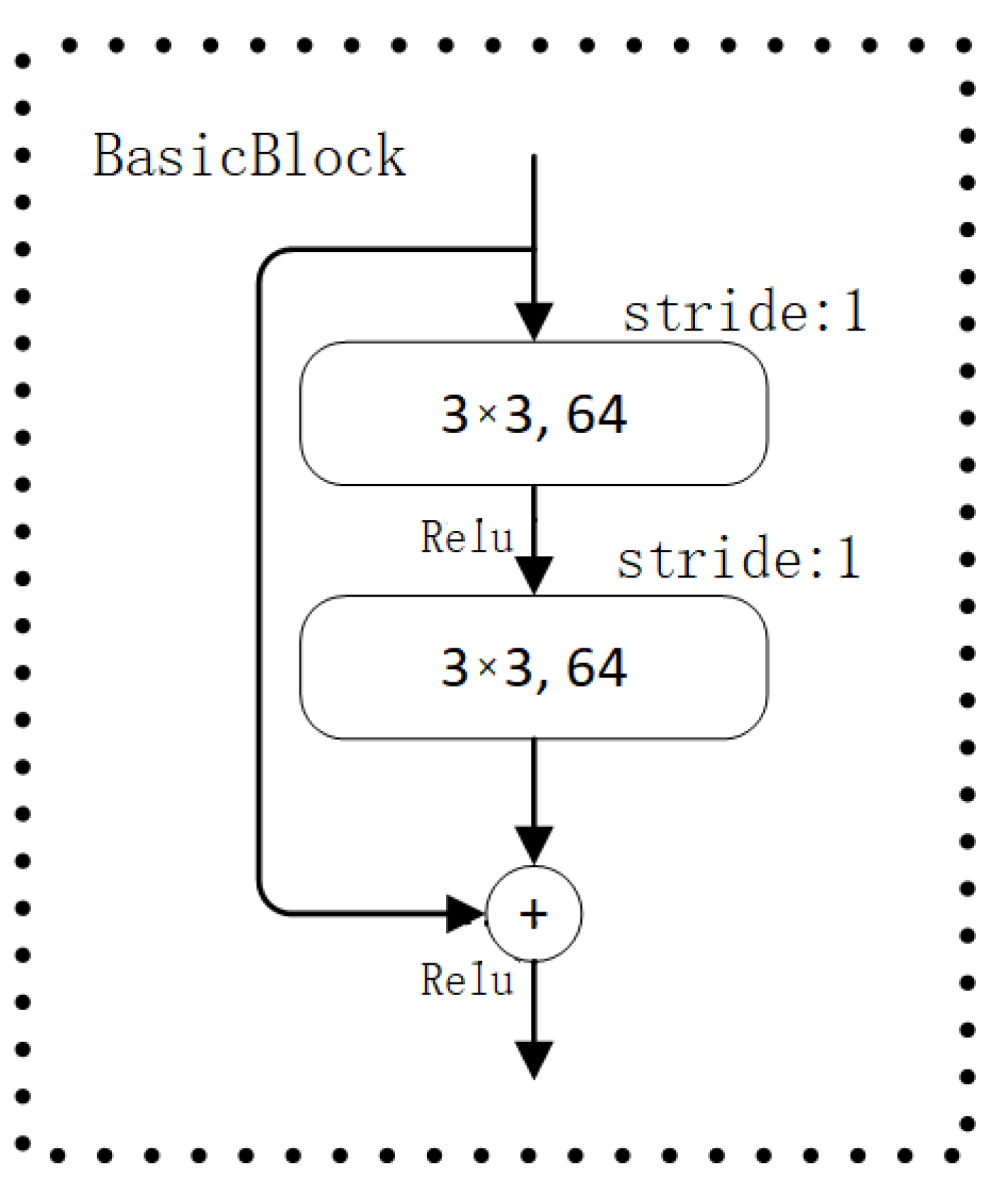
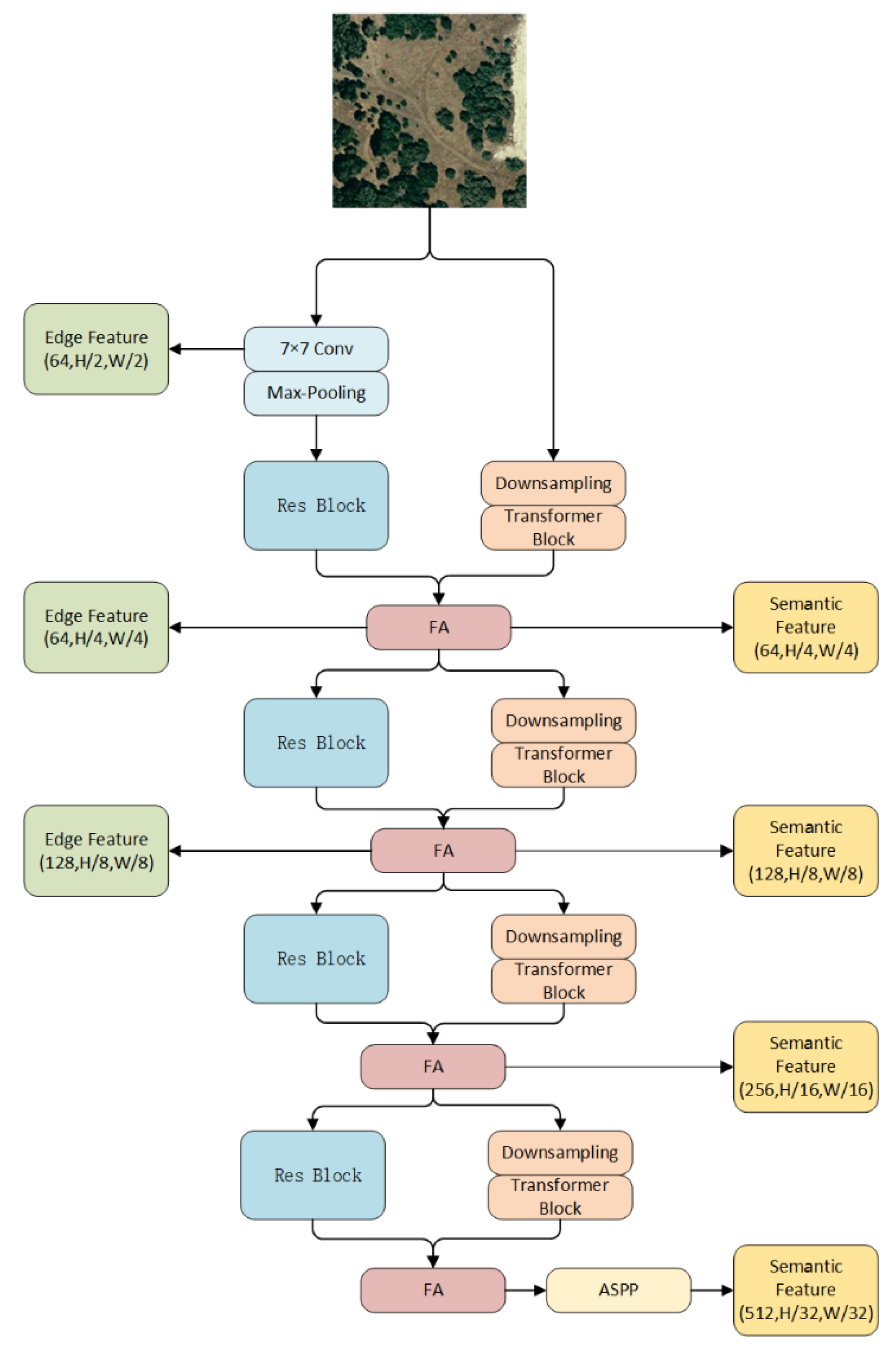
2.1. Network Architecture
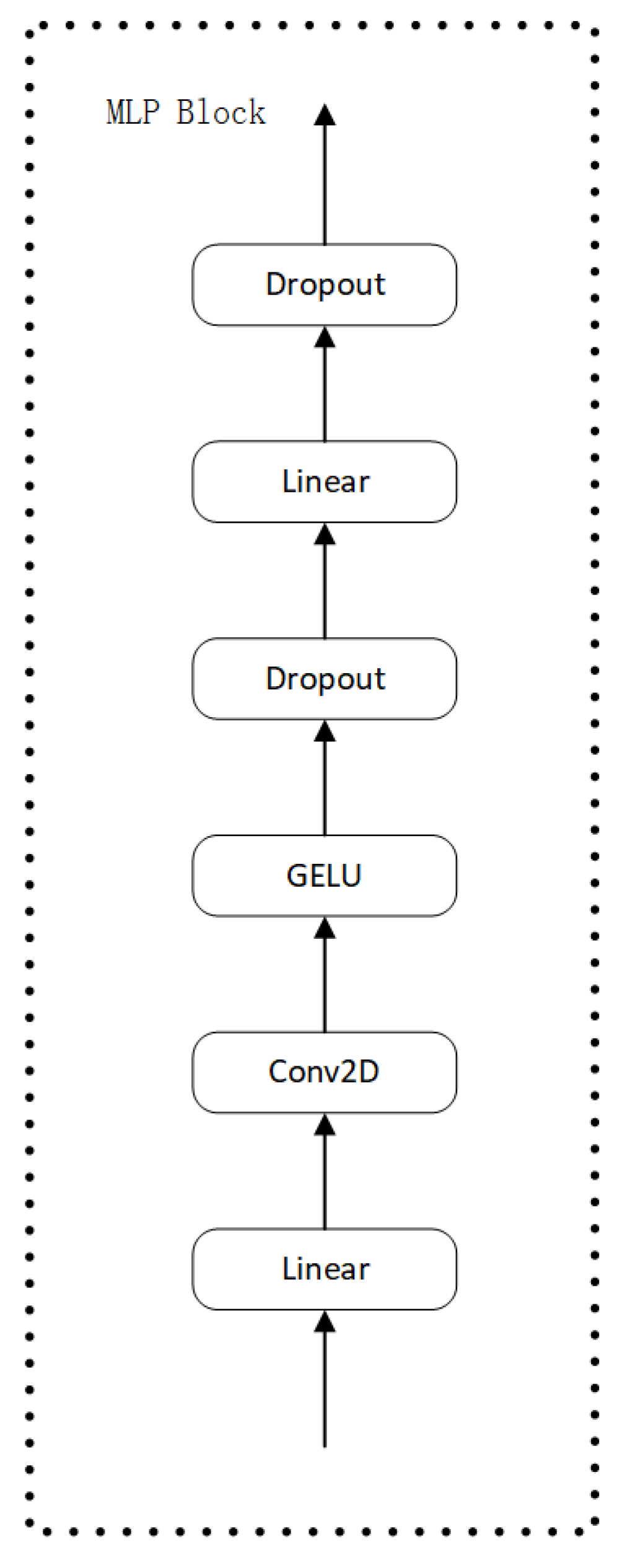
2.2. Fusion Encoder
2.3. Intermediate Decoder
- (1)
- We downsample the edge features to fit the multiscale fused mask feature structure at each layer; then, we add the features and convolve the output. The details are as follows:where Down is the downsampling operation, is an edge feature, and is a mask feature containing multiscale information.
- (2)
- To prevent gradient disappearance, we retain the direct fusion of the mask and edge features output by the last layer, as follows:where Upsamle is a bilinear interpolation algorithm, is an edge feature, and is a mask feature.
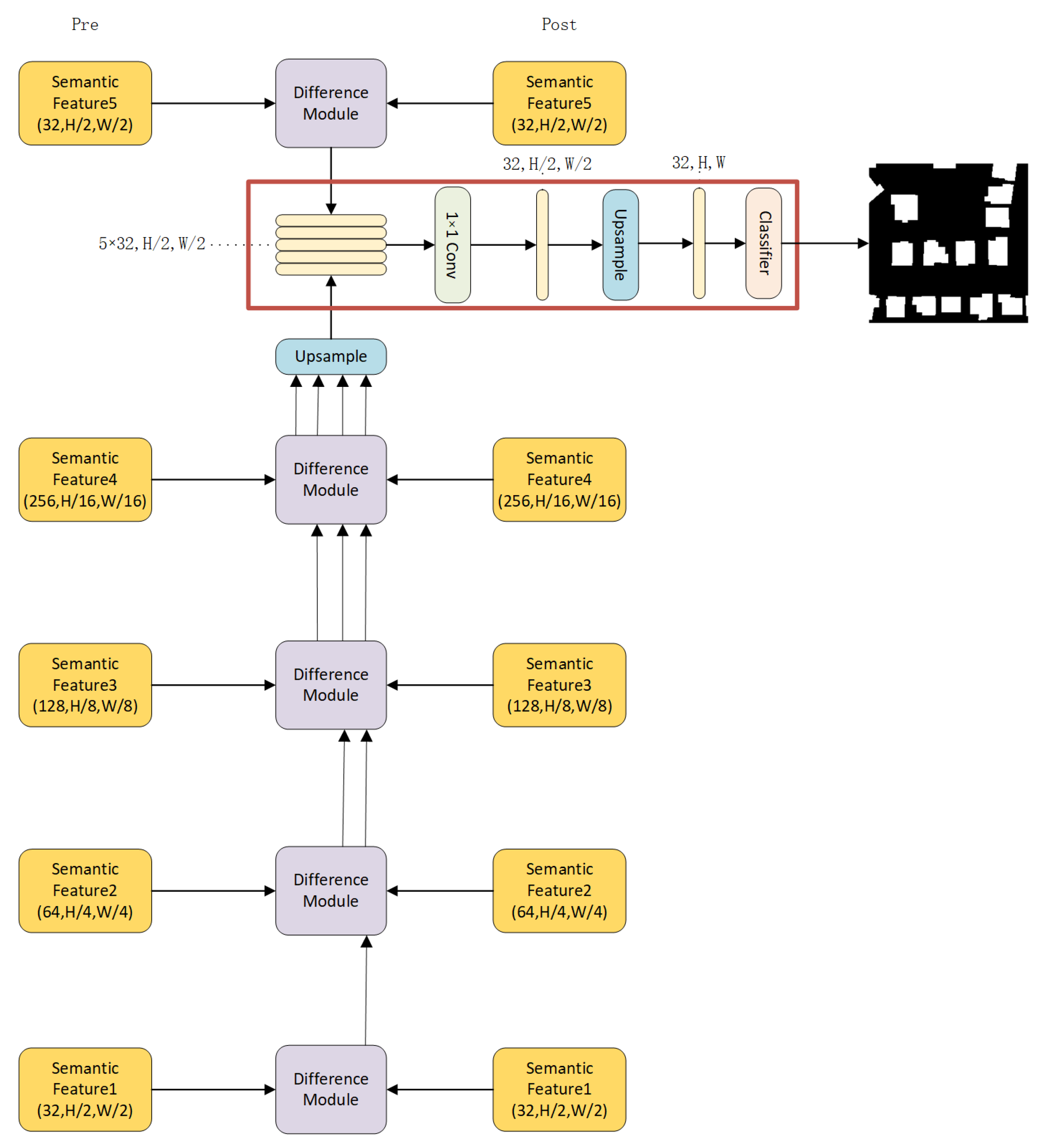
2.4. Change Decoder
2.5. Edge Detection Branch
2.6. Loss Function
3. Experiments
3.1. Datasets and Preprocessing, Implementation Details, Evaluation Metrics, and Comparison Methods
3.1.1. Datasets and Preprocessing
3.1.2. Implementation Details
3.1.3. Evaluation Metrics
3.1.4. Comparison Methods
3.2. Results on the LEVIR-CD Dataset
3.3. Results on the WHU Building Dataset
3.4. Ablation Studies
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jérôme, T. Change Detection. In Springer Handbook of Geographic Information; Springer: Berlin/Heidelberg, Germany, 2022; pp. 151–159. [Google Scholar]
- Lu, D.; Mausel, P.; Brondizio, E.; Moran, E. Change Detection Techniques. Int. J. Remote Sens. 2004, 25, 2365–2401. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, Y. Seasonal Change of Land-Use/Land-Cover (Lulc) Detection Using Modis Data in Rapid Urbanization Regions: A Case Study of the Pearl River Delta Region (China). IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1913–1920. [Google Scholar] [CrossRef]
- Jensen, J.R.; Im, J. Remote Sensing Change Detection in Urban Environments. In Geo-Spatial Technologies in Urban Environments; Springer: Berlin/Heidelberg, Germany, 2007; pp. 7–31. [Google Scholar]
- Zhang, J.-F.; Xie, L.-L.; Tao, X.-X. Change Detection of Earthquake-Damaged Buildings on Remote Sensing Image and Its Application in Seismic Disaster Assessment. In Proceedings of the IGARSS 2003. 2003 IEEE International Geoscience and Remote Sensing Symposium. Proceedings (IEEE Cat. No. 03CH37477), Toulouse, France, 21–25 July 2003. [Google Scholar]
- Bitelli, G.; Camassi, R.; Gusella, L.; Mognol, A. Image Change Detection on Urban Area: The Earthquake Case. In Proceedings of the XXth ISPRS Congress, Istanbul, Turkey, 12–23 July 2004. [Google Scholar]
- Dai, X.; Khorram, S. The Effects of Image Misregistration on the Accuracy of Remotely Sensed Change Detection. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1566–1577. [Google Scholar]
- Radke, R.J.; Andra, S.; Al-Kofahi, O.; Roysam, B. Image Change Detection Algorithms: A Systematic Survey. IEEE Trans. Image Process. 2005, 14, 294–307. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Su, Y.; Guo, Q.; Harmon, T. Unsupervised Object-Based Differencing for Land-Cover Change Detection. Photogramm. Eng. Remote Sens. 2017, 83, 225–236. [Google Scholar] [CrossRef]
- Ma, J.; Gong, M.; Zhou, Z. Wavelet Fusion on Ratio Images for Change Detection in Sar Images. IEEE Geosci. Remote Sens. Lett. 2012, 9, 1122–1126. [Google Scholar] [CrossRef]
- Collins, J.B.; Woodcock, C.E. An Assessment of Several Linear Change Detection Techniques for Mapping Forest Mortality Using Multitemporal Landsat Tm Data. Remote Sens. Environ. 1996, 56, 66–77. [Google Scholar] [CrossRef]
- Bovolo, F.; Bruzzone, L. A Theoretical Framework for Unsupervised Change Detection Based on Change Vector Analysis in the Polar Domain. IEEE Trans. Geosci. Remote Sens. 2006, 45, 218–236. [Google Scholar] [CrossRef]
- Chen, Q.; Chen, Y. Multi-Feature Object-Based Change Detection Using Self-Adaptive Weight Change Vector Analysis. Remote Sens. 2016, 8, 549. [Google Scholar] [CrossRef]
- Fung, T.; LeDrew, E. Application of Principal Components Analysis to Change Detection. Photogramm. Eng. Remote Sens. 1987, 53, 1649–1658. [Google Scholar]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change Detection from Remotely Sensed Images: From Pixel-Based to Object-Based Approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Chen, G.; Hay, G.J.; Carvalho, L.M.T.; Wulder, M.A. Object-Based Change Detection. Int. J. Remote Sens. 2012, 33, 4434–4457. [Google Scholar] [CrossRef]
- Lang, S. Object-Based Image Analysis for Remote Sensing Applications: Modeling Reality—Dealing with Complexity. In Object-Based Image Analysis; Springer: Berlin/Heidelberg, Germany, 2008; pp. 3–27. [Google Scholar]
- Chen, G.; Zhao, K.; Powers, R. Assessment of the Image Misregistration Effects on Object-Based Change Detection. ISPRS J. Photogramm. Remote Sens. 2014, 87, 19–27. [Google Scholar] [CrossRef]
- Wan, L.; Xiang, Y.; You, H. A Post-Classification Comparison Method for Sar and Optical Images Change Detection. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1026–1030. [Google Scholar] [CrossRef]
- Ye, S.; Chen, D.; Yu, J. A Targeted Change-Detection Procedure by Combining Change Vector Analysis and Post-Classification Approach. ISPRS J. Photogramm. Remote Sens. 2016, 114, 115–124. [Google Scholar] [CrossRef]
- Zhang, C.; Wei, S.; Ji, S.; Lu, M. Detecting Large-Scale Urban Land Cover Changes from Very High Resolution Remote Sensing Images Using Cnn-Based Classification. ISPRS Int. J. Geo-Inf. 2019, 8, 189. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Jiang, H.; Hu, X.; Li, K.; Zhang, J.; Gong, J.; Zhang, M. Pga-Siamnet: Pyramid Feature-Based Attention-Guided Siamese Network for Remote Sensing Orthoimagery Building Change Detection. Remote Sens. 2020, 12, 484. [Google Scholar] [CrossRef]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building Change Detection for Remote Sensing Images Using a Dual-Task Constrained Deep Siamese Convolutional Network Model. IEEE Geosci. Remote Sens. Lett. 2020, 18, 811–815. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, R.; Li, Z.; Li, Q. Optical Remote Sensing Image Change Detection Based on Attention Mechanism and Image Difference. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7296–7307. [Google Scholar] [CrossRef]
- Zheng, Z.; Wan, Y.; Zhang, Y.; Xiang, S.; Peng, D.; Zhang, B. Clnet: Cross-Layer Convolutional Neural Network for Change Detection in Optical Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 247–267. [Google Scholar] [CrossRef]
- Daudt, R.C.; Saux, B.L.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar]
- Chen, J.; Fan, J.; Zhang, M.; Zhou, Y.; Shen, C. Msf-Net: A Multiscale Supervised Fusion Network for Building Change Detection in High-Resolution Remote Sensing Images. IEEE Access 2022, 10, 30925–30938. [Google Scholar] [CrossRef]
- Bai, B.; Fu, W.; Lu, Y.; Li, S. Edge-Guided Recurrent Convolutional Neural Network for Multitemporal Remote Sensing Image Building Change Detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. A Transformer-Based Siamese Network for Change Detection. arXiv 2022, arXiv:2201.01293. [Google Scholar]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Wei, Y.; Zhao, Z.; Song, J. Urban Building Extraction from High-Resolution Satellite Panchromatic Image Using Clustering and Edge Detection. In Proceedings of the IGARSS 2004. 2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004. [Google Scholar]
- Jung, H.; Choi, H.-S.; Kang, M. Boundary Enhancement Semantic Segmentation for Building Extraction from Remote Sensed Image. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 26–30 June 2016. [Google Scholar]
- Sunkara, R.; Luo, T. No More Strided Convolutions or Pooling: A New Cnn Building Block for Low-Resolution Images and Small Objects. arXiv 2022, arXiv:2208.03641. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected Crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Yu, X.; Fan, J.; Chen, J.; Zhang, P.; Zhou, Y.; Han, L. Nestnet: A Multiscale Convolutional Neural Network for Remote Sensing Image Change Detection. Int. J. Remote Sens. 2021, 42, 4898–4921. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. Snunet-Cd: A Densely Connected Siamese Network for Change Detection of Vhr Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision | Recall | F1 | IoU | OA (%) |
|---|---|---|---|---|---|
| FC-Siam-Di | 0.8953 | 0.8331 | 0.8631 | 0.7592 | 98.67 |
| FC-Siam-Conc | 0.9199 | 0.7677 | 0.8369 | 0.7196 | 98.49 |
| NestUnet | 0.9190 | 0.8806 | 0.8994 | 0.8172 | 98.99 |
| STANet | 0.8381 | 0.9100 | 0.8726 | 0.7740 | 98.66 |
| DTCDSCN | 0.8853 | 0.8683 | 0.8767 | 0.7805 | 98.77 |
| SNUNet | 0.8918 | 0.8717 | 0.8816 | 0.7883 | 98.82 |
| BIT | 0.8924 | 0.8937 | 0.8931 | 0.8068 | 98.92 |
| ChangeFormer | 0.9205 | 0.8880 | 0.9040 | 0.8248 | 99.04 |
| Ours | 0.9220 | 0.8921 | 0.9068 | 0.8295 | 99.06 |
| Method | Precision | Recall | F1 | IoU | OA (%) |
|---|---|---|---|---|---|
| FC-Siam-Di | 0.8454 | 0.7973 | 0.8206 | 0.6959 | 98.50 |
| FC-Siam-Conc | 0.8596 | 0.7726 | 0.8138 | 0.6860 | 98.48 |
| NestUnet | 0.9285 | 0.8300 | 0.8765 | 0.7801 | 98.99 |
| STANet | 0.8234 | 0.8293 | 0.8263 | 0.7041 | 98.50 |
| DTCDSCN | 0.9315 | 0.8690 | 0.8991 | 0.8168 | 99.16 |
| SNUNet | 0.9143 | 0.8762 | 0.8948 | 0.8097 | 99.11 |
| BIT | 0.9176 | 0.8731 | 0.8948 | 0.8096 | 99.12 |
| ChangeFormer | 0.8841 | 0.8769 | 0.8805 | 0.7865 | 98.98 |
| Ours | 0.9347 | 0.8808 | 0.9070 | 0.8298 | 99.22 |
| Method | FE | IMD | EDB | WHU-CD (Partial) | ||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | IoU | OA (%) | ||||
| Base | × | × | × | 0.9117 | 0.8644 | 0.8874 | 0.7976 | 96.34 |
| CTNet | ✓ | × | × | 0.9050 | 0.8821 | 0.8934 | 0.8074 | 96.49 |
| CTINet | ✓ | ✓ | × | 0.9068 | 0.8854 | 0.8960 | 0.8116 | 96.57 |
| EGCTNet | ✓ | ✓ | ✓ | 0.9060 | 0.8905 | 0.8982 | 0.8152 | 96.63 |
| Method | FE | IMD | EDB | Params. (M) | FLOPs (G) |
|---|---|---|---|---|---|
| Base | × | × | × | 32.02 | 14.04 |
| CTNet | ✓ | × | × | 57.25 | 21.96 |
| CTINet | ✓ | ✓ | × | 62.80 | 30.02 |
| EGCTNet | ✓ | ✓ | ✓ | 63.26 | 33.52 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, L.; Chen, J.; Luo, J.; Zhang, J.; Yang, D.; Shen, Z. Building Change Detection Based on an Edge-Guided Convolutional Neural Network Combined with a Transformer. Remote Sens. 2022, 14, 4524. https://doi.org/10.3390/rs14184524
Xia L, Chen J, Luo J, Zhang J, Yang D, Shen Z. Building Change Detection Based on an Edge-Guided Convolutional Neural Network Combined with a Transformer. Remote Sensing. 2022; 14(18):4524. https://doi.org/10.3390/rs14184524
Chicago/Turabian StyleXia, Liegang, Jun Chen, Jiancheng Luo, Junxia Zhang, Dezhi Yang, and Zhanfeng Shen. 2022. "Building Change Detection Based on an Edge-Guided Convolutional Neural Network Combined with a Transformer" Remote Sensing 14, no. 18: 4524. https://doi.org/10.3390/rs14184524
APA StyleXia, L., Chen, J., Luo, J., Zhang, J., Yang, D., & Shen, Z. (2022). Building Change Detection Based on an Edge-Guided Convolutional Neural Network Combined with a Transformer. Remote Sensing, 14(18), 4524. https://doi.org/10.3390/rs14184524